11. COMS3261: Computer Science Theory
Spring 2026
Mihalis Yannakakis
Lecture 1, 1/21/26
📜 [原文1]
COMS3261: <br> Computer Science Theory
Spring 2026<br>Mihalis Yannakakis
Lecture 1, 1/21/26
这部分是课程讲义的标题页,提供了最核心的背景信息。
- COMS3261: Computer Science Theory:这是课程的编号和全名。“COMS”是计算机科学(Computer Science)的缩写,W3261是哥伦比亚大学内部用于标识这门课程的代码,通常W代表本科课程,3000-level的课程意味着它是一门中级本科课程,适合已经有一定计算机基础(如数据结构、离散数学)的学生。课程名称“Computer Science Theory”(计算机科学理论)明确了本课程的重点,将要探讨的是计算机科学的理论基础,而不是具体的编程技巧或应用开发。这门课将关注“计算”这一概念本身的性质、能力和限制。
- Spring 2026:这指的是课程开设的学期,即2026年的春季学期。
- Mihalis Yannakakis:这是授课教授的名字。Mihalis Yannakakis是理论计算机科学领域的著名学者,他在计算复杂性理论、数据库理论、算法和组合优化等领域做出了杰出贡献。知道授课教授可以帮助学生了解课程的风格和深度。
- Lecture 1, 1/21/26:这表示这是该课程的第一次讲座,日期是2026年1月21日。这为讲义内容提供了时间上的定位。
- 示例1 (课程编号):如果一个学生想在学校系统中注册这门课,他需要查找的代码就是“COMS W3261”。如果他只搜索“Computer Science Theory”,可能会找到其他学校或不同学期的版本。
- 示例2 (学期):一个学生在2025年秋季学期看到这份讲义,他应该明白这份讲义是针对未来一个学期的,其中的课程安排(如考试日期)在2025年秋季是不适用的。
- 易错点:学生可能会误以为这是一门编程课,期望学习如何用某种新语言写代码。但“Theory”一词表明,重点在于数学化的证明和抽象模型的理解,代码实现通常不是主要考察点。
- 边界情况:这份讲义是针对特定学期特定教授的。如果其他教授在其他学期教这门课,尽管核心内容(如自动机、图灵机)可能相似,但课程结构、评分标准、教科书选择和侧重点可能会有很大不同。
这部分内容简洁地标明了课程的身份、授课教师、学期和讲座次序,是整个讲义的“封面”,为所有后续内容设定了基本背景。
标题页的存在是为了提供清晰的上下文,确保学生、教师和任何阅读此文档的人都能立刻了解这份材料所属的课程、时间及主讲人。这在学术材料的组织和归档中至关重要,避免了信息的混淆。
可以把这部分想象成一本书的封面。封面上有书名(课程名称)、作者(教授)、出版年份(学期)和第几版(第几次讲座)。它不包含具体知识,但告诉你这本书是关于什么的,是谁写的,什么时候写的。
想象你走进一间教室,黑板上用粉笔写着这几行字。这是教授在开始讲课前写下的,目的是让所有学生都明确“我们在哪”、“这是什么课”、“谁在讲课”,然后才开始进入正题。
22. 课程概况 (Course Introduction)
12.1. 课程信息
📜 [原文2]
- 网站: Courseworks
文件:
-课程信息: 一般信息,包括后勤、政策、评分方案、办公时间等。
-暂定时间表
- 作业 ...
这部分介绍了课程的管理和资源信息,告诉学生去哪里找资料以及能找到什么资料。
- 网站: Courseworks:Courseworks是哥伦比亚大学使用的在线课程管理系统(类似于其他大学的Canvas, Blackboard, Moodle)。教授会在这里发布通知、上传课程材料(讲义、作业)、公布成绩等。这是学生获取课程信息最主要的官方渠道。
- 文件: 这部分列出了在Courseworks上可以找到的关键文件类型。
- 课程信息 (Course Information / Syllabus):这是一个非常重要的文件,通常是一个PDF或Word文档,被称为“教学大纲”。它包含了课程的“游戏规则”。
- 后勤 (Logistics):上课的地点、时间等。
- 政策 (Policies):关于迟交作业、学术诚信等的规定。
- 评分方案 (Grading Scheme):作业、期中、期末各占多少分。
- 办公时间 (Office Hours):教授和助教(TA)提供答疑的时间和地点。
- 暂定时间表 (Tentative Schedule):这个文件会列出整个学期每周计划讲授的主题,以及重要的日期,如作业截止日期、期中和期末考试的日期。称之为“暂定”是因为教授可能会根据实际教学进度进行微调。
- 作业 (Assignments / Homework):这里会发布具体的作业题目和要求。
- 示例1 (Courseworks):学生想下载第二次讲座的PPT,他应该登录Courseworks系统,进入COMS W3261的课程页面,在“文件”或“资料”区找到对应的文件。
- 示例2 (暂定时间表):一个学生计划在三月份春假去旅行,他应该查阅“暂定时间表”,确保旅行时间不会与期中考试(Midterm Exam)或重要的作业截止日期冲突。
- 易错点:“暂定时间表”中的“暂定” (Tentative) 很重要。学生不能100%依赖于学期初发布的时间表来做长期规划,尤其是一些具体日期。比如,教授可能因为某章内容学生普遍感觉困难而多花一周时间讲解,导致后续所有安排顺延。最重要的日期(如期中/期末考试)通常不会变,但小的作业DDL可能会微调。
- 边界情况:如果Courseworks系统宕机,学生可能无法访问课程资料。在这种情况下,教授通常会通过邮件等其他方式发布紧急通知。
本节指明了课程的官方信息平台是Courseworks,并概述了在该平台上可以找到的三类核心文件:教学大纲、课程日历和作业。
这部分内容的目的是为了让学生从一开始就清楚如何管理自己的学习,知道去哪里获取权威信息,了解课程的各项规定和期望,从而能够顺利地参与到课程中来。
把Courseworks想象成这门课的“中央枢纽”或“大本营”。所有指令(作业)、地图(时间表)和规则手册(教学大纲)都存放在这里。你需要经常访问这个大本营来获取最新情报。
想象一个公告栏,上面贴着几张关键的通知。一张是“课程总览”,告诉你这门课怎么上、怎么评分。一张是“学期日历”,标出了所有重要的日子。还有一块区域专门用来贴每周的“新任务”。这个公告栏就是Courseworks。
22.2. 课程工作
📜 [原文3]
- 作业、期中考试、期末考试
- 政策
- 迟交作业(每迟交一天或不足一天扣10%)
- 舍弃最低分作业
- 合作政策
- 学术诚信
- 评分:作业20%,期中考试40%,期末考试40%
- 考试:期中考试(3/25),期末考试(5/4)课堂进行
这部分详细说明了学生的学业任务、相关政策和最终成绩的计算方式。
- 作业、期中考试、期末考试:明确了课程的考核方式由这三部分组成。
- 政策 (Policies):
- 迟交作业(每迟交一天或不足一天扣10%): 这是一条非常严格的规定。例如,如果作业满分100分,你得了90分,但迟交了1分钟,那么你的分数就会变成 $90 \times (1-10\%) = 81$ 分。如果迟交了25小时(超过一天但不足两天),就会被扣20%,分数变成 $90 \times (1-20\%) = 72$ 分。
- 舍弃最低分作业 (Drop the lowest homework score):这是一项人性化的政策。如果一学期有10次作业,你的第3次作业因为生病或其他原因做得非常差,只得了20分,而其他作业都在90分以上,那么在计算总作业平均分时,这次20分的作业成绩将被剔除,不计入总分。这给了学生一次犯错或遭遇意外的机会。
- 合作政策 (Collaboration Policy):理论课程通常允许学生讨论思路,但要求独立完成作业的最终书写。这条政策会明确界定“讨论”和“抄袭”的界限。例如,可以和同学讨论“这道题应该用哪种证明方法”,但不可以看同学写的具体证明步骤。
- 学术诚信 (Academic Integrity):这是对合作政策的延伸和强调,严禁任何形式的作弊或抄袭。违反学术诚信的后果通常非常严重,可能导致课程失败甚至被学校处分。
- 评分 (Grading):
- 作业20%,期中考试40%,期末考试40%:清晰地列出了最终成绩的构成比例。这意味着期中和期末考试对最终成绩的影响远大于作业。
- 考试 (Exams):
- 期中考试(3/25),期末考试(5/4)课堂进行:明确了两次关键考试的日期和形式。“课堂进行”(in-class)意味着考试是在正常的上课时间和地点举行的闭卷考试。
- 示例1 (迟交作业):假设一次作业满分是50分,你的原始得分是45分。作业的截止时间是周三下午5:00。
- 如果你在周三下午5:01提交,迟交不足一天,扣10%,最终得分是 $45 \times (1 - 0.10) = 40.5$ 分。
- 如果你在周四晚上6:00提交,迟交超过一天但不足两天,扣20%,最终得分是 $45 \times (1 - 0.20) = 36$ 分。
- 示例2 (评分计算):一个学生学期末的各项得分如下:
- 作业平均分(已经舍弃了最低分之后):92分
- 期中考试:85分
- 期末考试:88分
- 他的最终总成绩将是:$92 \times 20\% + 85 \times 40\% + 88 \times 40\% = 18.4 + 34 + 35.2 = 87.6$ 分。
- 易错点1 (迟交不足一天):学生可能会误以为“迟交一天”是指24小时后。但政策明确“或不足一天”,意味着只要超过了DDL一秒钟,10%的扣分就开始计算了。
- 易错点2 (合作与抄袭):学生在讨论时很容易越界。一个好的经验法则是“白板讨论”:可以和同学在白板上一起推导,但讨论结束后,各自凭借记忆和理解去独立写作业,期间不能再看讨论的笔记或照片。
- 边界情况 (舍弃最低分):如果某次作业你没有提交,得分为0,这个0分通常会被当作你的“最低分”而被舍弃。但如果你有两次作业没交,只能舍弃其中一次的0分,另一次的0分仍然会计入总成绩。
本节是课程的“法律条款”,规定了学生的责任、各项任务的权重、奖惩机制(迟交扣分、舍弃最低分)以及最重要的学术行为准则。
这部分内容的目的是建立一个清晰、公平的评估体系。通过明确规定,避免了学期中可能出现的关于评分和政策的争议,让学生从一开始就知道成功的标准和行为的底线。
可以把这部分看作一个游戏的计分规则。你知道完成哪些任务(作业、考试)可以得分,每个任务的权重是多少,以及违反规则(迟交、作弊)会受到什么惩罚。同时,游戏也提供了一个“复活”机会(舍弃最低分)。
想象你正在签署一份合同。这份合同详细说明了你的工作内容(作业和考试),报酬如何计算(评分比例),以及违约的后果(迟交扣分、学术诚信处分)。在开始工作前,你必须仔细阅读并同意这些条款。
32.3. 教科书
2. 3.1. Introduction to the Theory of Computation, by M. Sipser
📜 [原文4]
- 必读:
1. 3.1 Introduction to the Theory of Computation, by M. Sipser
这部分指定了课程的主要教科书。
- 必读 (Required): 这表明这本教科书是课程的核心材料,学生必须拥有并阅读它。课程的讲授顺序、概念定义、符号表示以及大部分作业题和示例,都将紧密围绕这本书展开。
- Introduction to the Theory of Computation, by M. Sipser: 这是教科书的全名和作者。这本书通常被简称为“Sipser”。它是计算机理论领域的经典教材,以其清晰的讲解、直观的示例和对证明思想的强调而著称。这本书分为三个主要部分:自动机与语言、可计算性理论、计算复杂性理论,这恰好是这类课程的标准结构。
- 示例1:教授在讲课时说“大家可以参考书中第三章关于下推自动机的例子”,他指的就是Sipser这本书的第三章。
- 示例2:作业里有一道题是“完成Sipser书中P125页的练习题2.15”,学生就需要找到这本书的对应页码来做题。
- 版本问题:像Sipser这样的经典教材通常会有多个版本(如第一版、第二版、第三版)。教授通常会指定使用哪个版本,因为不同版本之间页码、习题编号甚至部分内容可能会有差异。学生买错版本可能会导致做错作业或复习错章节。
- 国际版 vs. 北美版:有些教材有国际版,可能内容相同但价格更便宜,不过习题编号等也可能存在差异。学生需要确认教授是否允许使用国际版。
本节明确指定了Michael Sipser的《计算理论导论》是课程的必读核心教科书。
指定一本必读教科书是为了给课程提供一个坚实的、一致的理论框架和内容来源。这确保了所有学生都有一个共同的参考标准,也为教授的讲授和作业布置提供了便利。
Sipser这本书就是这门理论课程的“圣经”或“法典”。所有的教义(理论)、寓言(例子)和诫律(证明)都源自于此。当你在课堂上感到困惑时,回到这本书中去寻找最权威的解释。
想象你在学习一门手艺,比如木工。Sipser这本书就是你师傅给你的那本最古老、最权威的《木工技法大全》。你学习的所有技巧——如何使用锯子(有限自动机)、如何搭建框架(上下文无关文法)、什么木头能雕刻什么不能(可计算性)——都可以在这本书里找到最根本的原理。
2. 3.2. Introduction to Automata Theory, Languages and Computation, by Hopcroft, Motwani, Ullman
📜 [原文5]
- 其他:
1. 3.2 Introduction to Automata Theory, Languages and Computation, by Hopcroft, Motwani, Ullman
这部分提供了另一本参考书。
- 其他 (Other / Optional / Recommended):这表示这本书不是强制要求购买或阅读的,而是作为补充材料。
- Introduction to Automata Theory, Languages and Computation, by Hopcroft, Motwani, Ullman: 这本书通常被它的作者姓氏首字母简称为“HU”或“HMU”(早期版本是Hopcroft和Ullman,后来加入了Motwani)。这也是计算理论领域的一本里程碑式的经典教材,甚至比Sipser的书历史更悠久。
- 与Sipser的区别:相比于Sipser,HMU这本书通常被认为在某些主题上更具深度和数学上的形式化,内容也更详尽。但对于初学者来说,它的表述可能不如Sipser那么平易近人。
- 示例1:学生在学习“正则表达式到有限自动机的转换”时,觉得Sipser书中的某个证明步骤太简略,他可以去查找HMU这本书中对应的章节,可能会找到一个更详细、更形式化的证明过程。
- 示例2:一个对理论计算机科学有浓厚兴趣并计划深入研究的学生,可能会被教授建议在学有余力的情况下阅读HMU,以拓宽其知识面和加深理解。
- 符号和定义差异:不同的教科书可能对同一个概念使用略微不同的符号或形式化定义。例如,对图灵机的定义,两本书在细节上(如磁带是单向无限还是双向无限)可能有细微差别。当学生交叉参考两本书时,需要注意这些差异,并以课程(即Sipser和教授的讲义)采用的定义为准。
本节推荐了Hopcroft, Motwani, Ullman的《自动机理论、语言和计算导论》作为选读的补充参考书。
提供补充教材的目的是为了满足不同学习风格和需求的学生。对于那些觉得Sipser讲解不够深入或者希望从不同角度理解同一概念的学生,HMU提供了一个极佳的替代视角和更丰富的内容库。这有助于培养学生主动探索和深入研究的学术习惯。
如果说Sipser是官方的、必修的“课本”,那么HMU就是一本“拓展阅读”的“参考书”或“百科全书”。课本教你基础,而参考书在你需要更深入的细节或不同解释时提供帮助。
想象你在上一门历史课。Sipser是老师指定的教科书,涵盖了所有考试要点。而HMU就像是图书馆里的一套更庞大、更详细的《世界通史》。你不需要通读它,但当你对某个历史事件(比如某个定理)的来龙去脉特别感兴趣时,可以去翻阅它,获得教科书上没有的丰富细节。
33. 课程核心主题 (Core Topics)
13.1. 基本问题:可计算性
📜 [原文6]
- 可计算性:哪些计算问题可以由计算机解决?
- 并非所有!
- 示例:给定程序P(比如Java)和一个输入x,P会在输入x上终止还是会永远运行下去?
- 语法正确的程序(即合法的Java)与语义正确的程序(即做它应该做的事情)
- 给定一个数学陈述(例如所有整数都具有某种属性,如Fermat's last theorem),它是一个真定理吗?
这部分引出了计算理论的第一个核心问题:可计算性 (Computability)。
- 可计算性:哪些计算问题可以由计算机解决?:这是本课程要探讨的根本问题之一。这里的“计算机”不是指你桌上的笔记本电脑,而是一个理想化的、数学上精确定义的计算模型(如图灵机)。“解决”意味着是否存在一个算法,对于问题的任何一个实例,都能在有限的时间内给出正确的“是”或“否”的答案。
- 并非所有!:这是一个令人震惊但至关重要的结论。存在一些定义清晰的、我们很想解决的问题,但已经被数学证明是“不可计算的”(uncomputable) 或“不可判定的”(undecidable),即不存在任何算法能解决它们的所有实例。
- 示例1:停机问题 (The Halting Problem)
- 给定程序P(比如Java)和一个输入x,P会在输入x上终止还是会永远运行下去?:这就是著名的停机问题。我们非常希望能有一个通用的“程序分析器”,它能分析任何程序P和任何输入x,然后告诉我们这个程序会不会死循环。然而,阿兰·图灵在1936年证明了这样的通用分析器是不可能存在的。停机问题是第一个被证明的不可计算问题。
- 语法正确 vs. 语义正确
- 语法正确的程序(即合法的Java)与语义正确的程序(即做它应该做的事情):这里通过类比帮助理解问题的难度。编译器可以轻易检查一个程序是否“语法正确”(比如括号是否匹配,变量是否声明),但无法判断这个程序是否“语义正确”(比如一个排序程序是否真的能正确排序所有数组)。停机问题,以及更广泛的程序行为分析,都属于语义范畴,因此非常困难。
- 示例2:希尔伯特第十问题/定理证明
- 给定一个数学陈述...它是一个真定理吗?:这也是一个不可计算的问题。我们无法制造一个“万能定理证明机”,输入任何数学猜想(如费马大定理),它都能自动判断这个猜想是否为真。虽然对于某些特定的陈述(如费-马大定理本身),数学家可以找到证明,但不存在一个能解决所有这类问题的通用算法。
- 停机问题示例:
- 程序 P1: def P1(x): while(x > 0): x = x - 1; return; 输入 x=5。这个程序会终止。
- 程序 P2: def P2(x): while(True): pass; 输入 x=5。这个程序会永远运行。
- 停机问题问的是:是否存在一个超级程序 HaltChecker(P, x),对于上面两个例子,能分别输出 "会终止" 和 "永远运行"?答案是,对于个别简单的程序P1和P2,我们人脑可以判断,但不存在一个 HaltChecker 能对 所有 可能的程序 P 和输入 x 都能给出正确答案。
- 误解“不可计算”:不可计算 不等于 “我们目前还不知道怎么解决”。它是一个数学上的绝对证明,意味着 永远 不可能存在一个通用的算法来解决它。它不是技术水平问题,而是逻辑上的根本限制。
- 个例 vs. 通用解:对于停机问题,我们当然可以解决很多 个例。但不可计算性说的是,不存在一个 通用 的算法能解决 所有 实例。
本节介绍了计算理论的第一个核心领域——可计算性理论。它探讨了计算的根本极限,并揭示了存在一些原则上无法由任何计算机解决的问题,其中最经典的例子是停机问题。
引入可计算性理论的目的是为了让学生理解“算法”和“计算”这两个概念的边界。在学习如何设计算法解决问题之前,首先要认识到并非所有问题都有算法解。这为计算机科学的理论体系划定了基石,让我们知道能做什么,不能做什么。
[直觉心-智模型]
把所有计算问题想象成一个巨大的海洋。可计算问题是海洋中的岛屿,我们可以造船(算法)登陆。不可计算问题是海洋中的海市蜃楼,我们能看见它(问题的定义很清晰),但永远无法到达。可计算性理论就是绘制这张海图,标出哪些是岛屿,哪些是海市蜃楼。
想象你有一台神奇的“问题分析仪”。你把一个写着问题的纸条放进去,它就会亮绿灯(可解决)或红灯(不可解决)。可计算性理论告诉我们,这台机器本身是造不出来的。更有趣的是,我们甚至无法造出一台机器来判断“一个问题是否能被分析仪判断”。这就是计算世界中深刻的逻辑限制。
23.2. 基本问题:复杂性
📜 [原文7]
- 复杂性:哪些问题可以高效计算(在合理的时间内)?
- 并非所有!
- 示例:排序、加法、乘法数字的快速算法,但没有因式分解的。因式分解的难度是当前加密协议的基础。
- 许多优化问题——调度、网络设计、资源分配等。
这部分引出了计算理论的第二个核心问题:计算复杂性 (Computational Complexity)。
- 复杂性:哪些问题可以高效计算(在合理的时间内)?:在确定一个问题是“可计算的”之后,我们下一个关心的问题是:解决它需要花费多少资源?这里的“高效”通常指算法的运行时间(或所需内存)是输入规模的多项式函数(polynomial time),而不是指数函数(exponential time)。这个问题比可计算性更贴近实际应用。
- 并非所有!:即使一个问题是可计算的,也不意味着我们有实际可行的解决方案。许多可计算问题的最优解法需要指数级的时间,当输入规模稍大时,其计算时间可能比宇宙的年龄还长,这在实践中等同于无法解决。
- 示例1:高效 vs. 低效
- 排序、加法、乘法数字的快速算法:这些问题都有高效的多项式时间算法。例如,对n个数字排序可以在 $O(n \log n)$ 时间内完成。
- 但没有因式分解的:将一个大整数分解成质因数,目前已知的最快算法都需要超多项式时间(接近指数时间)。虽然它是可计算的(最笨的方法是一个个试除),但对于几百位的数字,这个过程极其缓慢。
- 因式分解的难度是当前加密协议的基础:现代公钥密码体系(如RSA)的安全性,正是建立在“将两个大素数相乘很容易,但将它们的乘积分解回那两个素数非常困难”这一计算复杂性的不对称性之上的。
- 示例2:优化问题
- 许多优化问题——调度、网络设计、资源分配等:这些问题通常属于“NP-hard”问题类。例如,旅行商问题(TSP):找到访问n个城市并返回起点的最短路径。这类问题目前没有已知的多项式时间算法。我们能找到近似解,但找到最优解非常困难。
- 多项式时间 vs. 指数时间:假设输入规模 $n=50$。
- 一个多项式时间算法,复杂度为 $n^2$,需要计算 $50^2 = 2500$ 次操作,计算机瞬间完成。
- 一个指数时间算法,复杂度为 $2^n$,需要计算 $2^{50}$ 次操作。$2^{10} \approx 10^3$,所以 $2^{50} = (2^{10})^5 \approx (10^3)^5 = 10^{15}$。假设一台计算机每秒执行 $10^9$ 次操作,完成这个计算需要 $10^{15} / 10^9 = 10^6$ 秒,大约是11.5天。如果 $n$ 增加到100,计算时间将是天文数字。
- RSA加密示例:
- 加密(容易):选择两个大素数 $p$ 和 $q$(例如,各有200位),计算它们的乘积 $N=p \times q$。这个乘法操作非常快。
- 破解(困难):给你一个400位的数字 $N$,让你找出其质因数 $p$ 和 $q$。这就是因式分解问题,目前被认为是极其困难的。
- P vs. NP 问题:复杂性理论中最核心的未解之谜是“P是否等于NP?”。P类问题是能被高效解决的问题。NP类问题是其解的正确性可以被高效验证的问题。所有P类问题都是NP类问题,但我们不知道反过来是否成立。因式分解(的判定版本)在NP类,但不在P类(据我们所知)。如果有一天有人证明了P=NP,那么所有NP问题(包括TSP等)都将有高效解法,这将彻底改变世界,同时也会使现有的大部分加密体系失效。
- “高效”是相对的:一个 $O(n^{100})$ 的算法理论上是多项式时间,但实践中比许多指数算法还要慢。通常我们关心的是低阶多项式,如 $O(n)$, $O(n^2)$, $O(n^3)$。
本节介绍了计算理论的第二个核心领域——计算复杂性理论。它关注可计算问题的“效率”,将问题分为“高效可解”(多项式时间)和“低效可解”(指数时间)等类别,并探讨了这种划分对密码学和优化等实际领域的重要影响。
在知道一个问题能被解决后,我们必须关心解决它的成本。复杂性理论为我们提供了一套语言和框架来分析和比较算法的效率,指导我们在设计算法时追求效率,并让我们认识到某些问题固有的困难性,从而在面对这些问题时采取更现实的策略(如寻找近似解而非最优解)。
[直觉心-智模型]
如果可计算性理论是区分“可能”与“不可能”,那么复杂性理论就是区分“可行”与“不可行”。可计算性是哲学层面,复杂性是工程层面。
- P类问题:像在平坦的操场上跑步,很容易。
- NP-hard 问题:像在没有地图的、布满悬崖峭壁的喜马拉雅山区寻找最高峰,极其困难。虽然你知道山顶就在那里(问题有解),但找到它可能需要你耗尽一生。
想象你在一个巨大的图书馆里找一本书。
- P类问题:图书馆的书是按字母顺序排列的。你使用二分查找法,很快就能找到(对数时间)。
- 指数时间问题:图书馆的书是完全随机堆放的。你唯一的办法是把书一本一本地翻看,直到找到你想要的那本(线性时间,但在这里相当于指数级搜索空间)。
- NP类问题:有人告诉你,“你要找的书在第三排书架的第五层,是红色的”。你去核实这个信息非常容易。但如果没有这个提示,让你自己去找,就回到了上一种情况,非常困难。
33.3. 计算模型
📜 [原文8]
- 计算模型
- 形式化的数学基础
- 建模和抽象在科学和工程中的重要性
- 图灵机 [Turing 1936]
- 简单的“朴素”模型,但其能力 ⇔ 计算机
- 精确捕捉可计算性
- 捕捉复杂性的粗略差异
这部分解释了为什么我们需要一个形式化的“计算模型”来研究上述问题。
- 计算模型 (Model of Computation):这是一个抽象的、数学化的机器,它定义了什么是“计算”以及计算是如何一步步执行的。它不是物理设备,而是一个思想实验的工具。
- 形式化的数学基础:为了能够严格地证明一个问题是不可计算的,或者一个算法是多项式时间的,我们不能依赖于模糊的“计算机”概念或者具体的编程语言(如Java、Python),因为它们太复杂且不断变化。我们需要一个简单、稳定、可以用数学语言精确描述的模型。
- 建模和抽象在科学和工程中的重要性:这是一个普遍的科学方法论。例如,在物理学中,研究物体运动时,我们常常将其抽象为没有大小的“质点”,忽略空气阻力,这样才能应用牛顿定律进行简洁的数学分析。计算模型也是对真实计算机的一种高度抽象。
- 图灵机 (Turing Machine) [Turing 1936]:这是由阿兰·图灵提出的计算模型,是理论计算机科学的基石。它非常简单,主要由三部分组成:
- 一条无限长的纸带 (tape),划分为一个个格子,每个格子可以写入一个符号。
- 一个读写头 (head),可以在纸带上左右移动,并读取或写入格子中的符号。
- 一个有限状态控制器 (finite state control),它根据当前状态和读到的符号,来决定下一步要写入什么符号、向左还是向右移动,以及进入哪个新状态。
- 简单的“朴素”模型,但其能力 ⇔ 计算机:尽管图灵机看起来非常原始和低效,但它的计算能力被认为等同于任何现实中或理论上可能的计算设备。这就是著名的丘奇-图灵论题 (Church-Turing Thesis)。它声称,任何能被直觉上认为是“算法”的过程,都可以由一台图灵机来执行。这意味着,如果一个问题图灵机不能解决,那么任何计算机(包括未来的量子计算机,在标准模型下)都不能解决。
- 精确捕捉可计算性:由于丘奇-图灵论题,“可计算的”问题被形式化地定义为“可以被一台图灵机解决的”问题。这为可计算性理论提供了坚实的数学基础。
- 捕捉复杂性的粗略差异:我们也可以在图灵机模型上分析复杂性,例如计算图灵机解决一个问题需要走多少步(时间复杂性)或用多少纸带格子(空间复杂性)。虽然图灵机的一步操作比真实CPU的一个时钟周期慢得多,但它能很好地区分大的复杂性类别,比如多项式时间和指数时间。一个在真实计算机上是多项式时间的问题,在图灵机上通常也是多项式时间(尽管多项式的次数可能不同)。
- 图灵机加法示例:要在图灵机上计算 $2+3$,纸带上可能初始为 ...B11B111B...(B代表空白,用两个'1'代表2,三个'1'代表3)。图灵机通过一系列预设的规则(状态转移),来回移动读写头,最终可能将纸带变为 ...B11111B...(五个'1'),然后停机。这个过程的每一步(移动、读、写、改变状态)都是精确定义的。
- 丘奇-图灵论题不是一个定理:它是一个“论题”或“假说”,因为它联系了数学形式化的概念(图灵机)和非形式化的直觉概念(算法)。它不能被数学证明,但经过几十年的验证,它被广泛接受为真理,没有任何反例被发现。
- 图灵机 vs. 现实计算机:不要混淆图灵机的理论能力和实际效率。图灵机在理论上无所不能(只要是可计算的),但在实践中极其低效。它的价值在于理论分析,而不是工程实现。
本节强调了使用形式化计算模型的重要性,并介绍了作为标准模型的图灵机。图灵机以其简单性,为精确定义和研究可计算性和复杂性提供了理论基石。
引入计算模型的目的是为了将关于“计算”的讨论从模糊的、经验性的层面,提升到精确的、数学的层面。没有这样一个公认的模型,我们就无法对“什么是可计算的”或“一个问题有多难”这类基本问题给出严格的、普适的答案。
[直觉心-智模型]
图灵机就像是计算世界的“氢原子”。它是最简单的、可以构建出一切(可计算宇宙)的基本单元。通过研究这个最简单的模型,我们可以揭示所有复杂计算现象背后的普遍规律,就像物理学家通过研究氢原子来理解更复杂的原子结构一样。
想象一个非常笨拙但不知疲倦的机器人,它面前有一条无限长的收银条。它的任务手册(状态控制器)非常简单,只包含这样的指令:“如果你看到符号'A'并且你处于状态'S1',那么就把它改成'B',然后向右移动一格,并切换到状态'S2'”。尽管规则简单,但只要给予足够多的规则和时间,这个机器人可以完成任何你现在电脑能完成的计算任务,比如渲染一部电影(理论上)。
43.4. 模型和规范形式化
📜 [原文9]
- 其他规范形式化
- 更受限制的模型
- 文法和形式语言 [Chomsky 1950年代]
- 最初是自然(人类)语言的模型
- 允许在高级别(而非低级别机器语言)指定计算,自动编译方法,新语言等。
这部分介绍了除了图灵机之外的其他计算模型,特别是那些能力“较弱”但同样重要的模型。
- 其他规范形式化 (Other Formalisms):计算理论中不止图灵机一种模型。我们还会研究其他模型。
- 更受限制的模型 (More Restricted Models):有些模型的能力不如图灵机强大,它们不能解决所有图灵机能解决的问题。研究这些受限模型非常有价值,因为:
- 它们的结构更简单,某些性质(如停机问题)对于它们来说可能是可判定的。
- 它们恰好能描述某些特定的、在现实世界中很重要的任务。
- 文法 (Grammars) 和 形式语言 (Formal Languages) [Chomsky 1950年代]:这是另一套非常重要的形式化体系,由语言学家诺姆·乔姆斯基提出。
- 形式语言:不是指英语或中文,而是指一个由特定规则生成的字符串的集合(这个概念后面会详细定义)。
- 文法:是一套用于生成(或识别)一个形式语言中所有字符串的产生式规则 (production rules)。
- 最初是自然(人类)语言的模型:乔姆斯基的初衷是希望能用数学上精确的文法规则来描述和分析人类语言(如英语)的句子结构。例如,一个简单的英语句子结构规则可以是:句子 -> 名词短语 + 动词短语。
- 用于编程语言:这个思想被计算机科学家迅速采纳,并成为描述和实现编程语言的基石。几乎所有编程语言的语法都是通过一种叫做上下文无关文法 (Context-Free Grammar) 的形式化文法来定义的。
- 允许在高级别...指定计算...:
- 高级别指定计算:使用文法,我们可以从一个高的、抽象的层次来描述我们想要的“合法字符串”的结构(例如,所有合法的C++程序),而不需要去描述一台图灵机如何一步步地去检查这些字符串的每一个字符。
- 自动编译方法:基于文法的形式化定义,计算机科学家开发出了能够自动生成解析器 (parser) 的工具(如 YACC, Bison)。解析器是编译器的一个核心组件,其任务是检查输入的代码是否符合语言的语法规则。
- 新语言:这套理论极大地简化了设计和实现新编程语言的过程。
- 一个简单的文法 G:
- 规则1:S -> aSb (S可以被改写为aSb)
- 规则2:S -> ε (S可以被改写为空字符串)
- 这个文法能生成什么样的语言 L(G) 呢?
- 从 S 开始,用规则2,得到 ε。所以 ε 在 L(G) 中。
- 从 S 开始,用规则1,得到 aSb。再对中间的 S 用规则2,得到 ab。所以 ab 在 L(G) 中。
- 从 S 开始,用规则1,得到 aSb。再对中间的 S 用规则1,得到 a(aSb)b,即 aaSb_b。再对中间的 S 用规则2,得到 aabb。所以 aabb 在 L(G) 中。
- 依此类推,这个文法生成的语言是 ${a^n b^n | n \ge 0}$,即任意数量的'a'后面跟着相同数量的'b'的字符串集合。
- 文法 vs. 自动机:课程后面会揭示,文法和自动机之间存在深刻的对应关系。例如,正则文法 (Regular Grammars) 精确地对应有限自动机 (Finite Automata),而上下文无关文法 (Context-Free Grammars) 精确地对应下推自动机 (Pushdown Automata)。它们是从不同角度描述同一种计算能力的方式:自动机是“识别器”,文法是“生成器”。
本节介绍了作为计算理论另一大支柱的“文法和形式语言”体系。它提供了一种从生成规则的角度来定义和研究字符串集合(语言)的方法,这在编程语言的设计和编译中具有至关重要的应用。
引入文法和形式语言的目的是提供一种不同于“机器”模型的视角来看待计算。这种基于规则和生成的视角,在处理具有层级和嵌套结构的数据(如编程语言代码、XML文件、自然语言句子)时,显得更为自然和强大。
[直觉心-智模型]
- 自动机像一个保安,站在门口检查每个进来的人(字符串)的证件是否合格。
- 文法像一个工厂,根据一套蓝图(规则)能源源不断地生产出所有合格的产品(字符串)。
保安和工厂的能力是匹配的:工厂能生产出来的,保安都会放行;工厂生产不出来的,保安也绝不会放行。
想象你在玩乐高积木。
- 文法就是你的那本搭建手册。手册里写着规则,比如“一个‘车’是由一个‘底盘’和四个‘轮子’组成的”,“一个‘底盘’是...”。
- 语言就是所有你能按照这本手册搭建出来的合法作品(各种各样的车)的集合。
- 解析就相当于给你一堆搭好的乐高,让你反向工程,判断它是不是严格按照某本手册搭建出来的。这就是编译器的工作。
44. 自动机理论导论 (Introduction to Automata Theory)
14.1. 自动机(状态机)定义
📜 [原文10]
- 描述系统(硬件和软件)的行为,建模设备、世界的一部分等。
- 系统状态通过动作/事件/输入以离散步骤改变
- 特别关注有限自动机(有限个状态)
- McCulloch, Pitts, 神经网络(大脑模型)1943
- Mealy, Moore, Huffman 1954-56: 顺序开关电路
- 随后,许多其他应用
这部分开始正式介绍本课程的第一个主要模型:自动机 (Automata),也常被称为状态机 (State Machines)。
- 描述系统...的行为...:自动机是一个非常强大的、通用的建模工具,它可以用来描述任何一个其行为可以被分解为“状态”和“状态之间转换”的系统。这个系统可以是物理的(如一个自动售货机),也可以是抽象的(如一个通信协议)。
- 系统状态通过动作/事件/输入以离散步骤改变:这是自动机的核心思想。
- 状态 (State):系统在某个时间点的快照或配置。例如,一个交通信号灯的状态可以是“红灯”、“黄灯”或“绿灯”。
- 动作/事件/输入 (Action/Event/Input):触发状态改变的原因。例如,对于交通信号灯,一个“计时器超时”的事件会触发它从“绿灯”状态变为“黄灯”状态。
- 离散步骤 (Discrete steps):状态的变化是瞬时发生的,不存在中间状态。
- 特别关注有限自动机 (Finite Automata):这是自动机中最简单的一种,其“状态”的数量是有限的。尽管简单,但它的应用极其广泛。
- 历史渊源:这里提到了有限自动机思想的几个早期来源,展示了其跨学科的重要性。
- McCulloch, Pitts, 神经网络(大脑模型)1943:最早的自动机思想之一源于早期对人脑神经元工作的数学建模,他们试图用简单的逻辑单元(神经元)来模拟思维过程。
- Mealy, Moore, Huffman 1954-56: 顺序开关电路 (Sequential Switching Circuits):在电子工程领域,工程师们用状态机的模型来设计和分析数字电路,特别是那些有记忆功能的电路(如计数器、寄存器)。Mealy机和Moore机是两种稍微不同的有限自动机模型,至今仍是数字逻辑设计的基础。
- 随后,许多其他应用:这个模型很快就被发现有更广泛的应用价值,远不止于大脑模型或电路设计。
- 一个简单的自动售货机模型:
- 状态集合: {“待机 (0元)”, “已投5角”, “已投1元”} (这是一个有3个状态的有限自动机)
- 输入/事件集合: {“投入5角硬币”, “投入1元硬币”, “按下退款按钮”}
- 状态转换:
- 在“待机 (0元)”状态,如果“投入5角硬币”,则进入“已投5角”状态。
- 在“已投5角”状态,如果“投入5角硬币”,则进入“已投1元”状态,并掉出一瓶可乐。
- 在任何状态,如果“按下退款按钮”,则退还相应金额的硬币,并回到“待机 (0元)”状态。
- 有限 vs. 无限状态:图灵机可以看作是一种无限状态的自动机,因为它的“状态”不仅包括其内部控制器的有限状态,还包括其无限长纸带上的全部内容。而本章关注的有限自动机,其记忆能力是严格有限的,因为它只有有限个状态来记录历史信息。
本节将自动机定义为一个通过离散事件在有限个状态之间转换的系统模型,并追溯了其在神经网络和电路设计中的历史起源。
这部分旨在为“自动机”这一核心概念建立一个高层次的、直观的理解。在深入其形式化定义之前,首先让学生明白它是一个普适的、用于描述动态行为的建模工具。
自动机就像一个棋盘游戏。
- 棋盘上的格子就是状态。
- 你的棋子在某一时刻只能位于一个格子上。
- 骰子或指令卡片就是输入/事件。
- 游戏的规则告诉你,当你的棋子在某个格子上,并且你掷出了某个点数,你的棋子应该移动到哪个新的格子上。这就是状态转移。
这个游戏是“有限的”,因为棋盘上的格子数量是有限的。
想象一个只有几个按钮的简单电器,比如一个微波炉。它的当前状态可能是“待机”、“设置时间”、“加热中”、“完成”。你每按下一个按钮(比如“开始”或“取消”),或者等待一段时间(计时器事件),它的状态就会发生明确的改变。这个微波炉的控制逻辑就可以用一个有限自动机来精确描述。
24.2. 自动机应用
📜 [原文11]
- 编译器中的词法分析
- 模式匹配:搜索关键字或更复杂的模式(grep, awk等)
- 语音、语言处理
- 协议建模——例如通信协议、安全协议
- 软件和硬件系统的验证:自动机用于建模系统和/或正确性属性
- ...
这部分列举了有限自动机在计算机科学中的一系列重要应用,以展示其强大的实用价值。
- 编译器中的词法分析 (Lexical Analysis in Compilers):
- 编译器在处理源代码时,第一步就是“词法分析”,即把一长串的字符流(你的代码)分解成一个个有意义的“词法单元”(tokens)。例如,对于代码 if (x > 10),词法分析器会输出:IF, LEFT_PAREN, IDENTIFIER(x), GREATER_THAN, NUMBER(10), RIGHT_PAREN。
- 用来识别这些词法单元(如标识符、数字、关键字)的程序,其核心逻辑就是一个有限自动机。这个自动机读取字符流,根据预设的规则在不同状态间转换,最终识别出一个个token。
- 模式匹配 (Pattern Matching):
- 像grep这样的命令行工具,可以在大量文本中快速搜索一个特定的字符串或一个更复杂的模式(由正则表达式定义)。例如,搜索所有以'http'开头,以'.com'结尾的网址。
- 实现这种高效搜索的算法,其底层正是将正则表达式首先转换成一个等价的有限自动机,然后用这个自动机来“过”一遍文本。
- 语音、语言处理 (Speech and Language Processing):
- 在自然语言处理的某些层面,有限状态模型也很有用。例如,可以用它来建模词语的形态变化(如 walk, walks, walked, walking),或者用于简单的对话系统(客服机器人),根据用户的输入在不同的对话状态中跳转。
- 协议建模 (Protocol Modeling):
- 通信协议(如TCP/IP)本质上就是状态机。例如,一个TCP连接有“建立中”、“已建立”、“关闭中”、“已关闭”等多种状态。当收到一个特定的数据包(如SYN, ACK, FIN)时,连接状态就会按照协议规定进行转移。
- 安全协议(如TLS握手)也同样可以用状态机来描述其复杂的交互流程。
- 软件和硬件系统的验证 (Verification of Systems):
- 这是理论计算机科学的一个重要应用领域,称为“模型检测”(Model Checking)。
- 思路是:首先,用一个大的自动机 $M$ 来对我们要验证的系统(比如一个复杂的芯片设计或一个多线程程序)的所有可能行为进行建模。然后,用另一个自动机 $P$ 来描述我们期望系统满足的“正确性属性”(例如,“系统永远不会进入死锁状态”)。
- 验证过程就变成了一个数学问题:自动机 $M$ 的行为是否总是包含在自动机 $P$ 所允许的行为之内?这个问题可以通过算法自动进行检查。
- 词法分析识别数字的自动机:
- 状态: {S0 (初始), S1 (整数部分), S2 (看到小数点), S3 (小数部分), E (错误)}
- 输入: 数字0-9,小数点'.',其他字符
- 转换:
- 从S0,看到数字,到S1。
- 从S1,看到数字,留在S1;看到小数点,到S2。
- 从S2,看到数字,到S3。
- 从S3,看到数字,留在S3。
- 任何时候看到其他字符,都到E状态。
- 这样,字符串12.34会被正确识别,而12.或.34或1.2.3会被引导到合适的处理或错误状态。
- 模型的能力限制:有限自动机虽然用途广泛,但其“记忆力”有限,无法处理需要无限记忆的任务。例如,它无法判断一个字符串中的括号是否正确匹配(如 ((()))),因为这需要一个计数器,而有限的状态无法实现无限的计数。这类任务需要更强大的模型,如下推自动机。
本节通过一系列具体的、重要的实例,展示了有限自动机不仅是一个理论模型,更是一个在编译器、文本处理、网络、系统验证等多个核心计算机领域都有着深刻应用的实用工具。
这部分内容的目的是为了激发学生的学习兴趣,并建立理论与实践的联系。通过展示理论知识(自动机)如何解决实际问题(词法分析、协议验证),让学生明白学习这些抽象概念的意义和价值所在。
[直觉心-智模型]
有限自动机就像一个多功能的“瑞士军刀”。尽管它看起来很简单,但你可以用它来做很多不同的事情:
- 当作筛子用(词法分析,过滤出tokens)。
- 当作探雷器用(模式匹配,在文本中发现特定模式)。
- 当作交通规则手册用(协议建模,规定状态如何转换)。
- 当作质量检测标准用(系统验证,检查系统行为是否合规)。
想象你在玩一个桌面游戏,地图上有不同的地点(状态),地点之间有道路(状态转移)。你可以设计不同的游戏规则(不同的自动机)来玩不同的游戏:
- 寻宝游戏:规则设计为沿着特定路径(匹配特定模式)才能找到宝藏。
- 外交游戏:规则设计为国家之间如何宣战、结盟、和平(通信协议)。
- 解谜游戏:你需要按照特定顺序访问地点才能解开谜题(验证一个正确的执行序列)。
同一个地图(自动机模型),可以应用到各种不同的场景中。
34.3. 课程更一般的目标
📜 [原文12]
- 发展有用的抽象和模型
- 严谨地推理论证它们的能力
无论你之后做什么,这都是重要的技能。
这部分从更高的层次总结了这门课程旨在培养学生的核心能力,超越了具体的知识点。
- 发展有用的抽象和模型 (Develop useful abstractions and models):
- 抽象:是指从复杂的事物中剥离出核心特征,忽略不重要的细节。例如,当我们用“状态”和“转移”来描述一个复杂的微波炉时,我们就忽略了它的物理材质、电路板的具体布局等细节,只关注其逻辑行为。
- 模型:是抽象的结果,是一个简化的、形式化的系统,可以用来分析和预测原始系统的行为。
- 这门课程会教你如何看待一个计算问题,然后为其建立合适的数学模型(如有限自动机、下推自动机、图灵机)。
- 严谨地推理论证它们的能力 (Rigorously reason about their capabilities):
- 在建立了模型之后,下一步就是用数学的语言(逻辑、集合论、证明技巧)来精确地分析这个模型。
- “能力”包括:这个模型能解决什么问题?(计算能力)它的局限性在哪里?(例如,有限自动机无法计数)解决问题需要多少资源?(复杂性)
- “严谨地推理论证”意味着你的结论不能是基于直觉或猜测,而必须是基于一步步无懈可击的逻辑推导(即证明)。
- 无论你之后做什么,这都是重要的技能:教授强调,这两种能力(抽象建模和严谨论证)是具有普适性的。
- 如果你成为一名软件工程师,你需要将模糊的客户需求抽象成清晰的软件架构,并能论证你的设计为何能满足需求且性能达标。
- 如果你成为一名科研人员(任何领域),你需要为研究对象建立模型,并用严谨的实验和逻辑来验证你的理论。
- 即使在日常生活中,将复杂问题分解、抓住要点、并有条理地论证自己的观点,也是一种宝贵的思维能力。
本节指出了课程的两个核心培养目标:学会创建和使用抽象模型来理解复杂系统,以及学会运用严谨的数学和逻辑来分析这些模型。这两种能力是计算机科学乃至所有科学和工程领域的基础。
这部分是为了提升课程的格局,告诉学生他们在这里学到的不仅仅是一些关于自动机和图灵机的孤立知识,更是一种根本的、可迁移的思维方式。这有助于增强学生的学习动机,并指导他们将注意力放在掌握方法论上,而不仅仅是记忆结论。
[直觉心-智模型]
这门课就像是在训练你成为一个“思想侦探”。
- 发展抽象和模型:面对一个复杂的案发现场(问题),你忽略掉所有无关的细节,提炼出关键线索,构建出案件的可能模型(“我认为这是密室杀人,凶手利用了A、B、C三个要素”)。
- 严谨地推理论证:你根据已有线索和逻辑规则,一步步证明你的模型是唯一合理的解释,排除所有其他可能性(“如果凶手是从窗户进来的,那么地面上必然有脚印,但现在没有,所以排除...”)。
这种思维训练对任何需要解决复杂问题的职业都至关重要。
想象你是一个城市规划师。
- 发展抽象和模型:面对一个真实的、混乱的城市,你不会去考虑每一块砖、每一棵树。你会把它抽象成一张地图,上面只有关键元素:居民区、商业区、道路网络、地铁线路(这就是模型)。
- 严谨地推理论证:基于这个模型,你可以进行数学分析:“如果我们在A点和B点之间新建一条地铁,根据我们的人口流动模型,它能否将市中心的交通拥堵率降低15%?” 你需要用数据和算法来证明你的规划是有效的。
这门课就是在教你如何成为一个好的“计算系统”的规划师和分析师。
55. 预备知识与实例 (Prerequisites & Examples)
15.1. 数学基础(书中第0章)
📜 [原文13]
- 基本数学概念和定义
4. 1.1 基础概念
集合
函数和关系
图
字符串和语言
布尔逻辑
4. 1.2 证明方法
- 证明
通过构造
通过反证法
通过归纳法
这部分概述了学习本课程所必需的数学预备知识,这些内容通常在Sipser教科书的第0章有详细介绍,作为“热身”。
- 基本数学概念和定义 (Basic Mathematical Concepts and Definitions):
- 集合 (Sets):是这门课的基石。状态的集合、字母表的集合、语言(字符串的集合)等等,所有东西都是用集合来定义的。你需要熟悉集合的表示法({...})、基本运算(并、交、差、补)和概念(子集、幂集)。
- 函数和关系 (Functions and Relations):自动机的转移函数 $\delta$ 就是一个函数。状态之间的可达性是一种关系。你需要理解函数的定义域、值域,以及关系的性质(自反、对称、传递)。
- 图 (Graphs):自动机通常用有向图来可视化表示,其中节点是状态,带标签的边是转移。图论中的概念(路径、连通性)会很有用。
- 字符串和语言 (Strings and Languages):这是本课程的核心研究对象。你需要理解字符串的定义(符号的序列)、操作(连接、长度)和相关概念(前缀、后缀)。“语言”在这里特指“字符串的集合”。
- 布尔逻辑 (Boolean Logic):逻辑运算(与、或、非、蕴含)是所有数学证明的基础。
- 证明方法 (Proof Methods):理论计算机科学是一门以证明为核心的学科。你不仅要知道结论,更要知道如何推导出结论。
- 证明 (Proof):一个令人信服的、展示某个陈述为真的逻辑论证过程。
- 通过构造 (Proof by Construction):要证明“某种东西存在”,最直接的方法就是把它构造出来。例如,要证明“存在一个能识别所有偶数的自动机”,你就直接画出这个自动机。
- 通过反证法 (Proof by Contradiction):要证明“陈述P为真”,可以先假设P为假(即“非P”为真),然后从这个假设出发,通过一系列逻辑推导,得出一个荒谬的、自相矛盾的结论(比如 $1=0$)。这就说明最初的假设“非P”是错误的,因此P必须为真。这在证明“某事不可能”时特别有用。
- 通过归纳法 (Proof by Induction):通常用于证明一个关于所有自然数 $n$(或所有长度为 $n$ 的字符串)的陈述。它包含两步:
- 基础步骤 (Base Case):证明当 $n=0$ 或 $n=1$ 时陈述成立。
- 归纳步骤 (Inductive Step):假设当 $n=k$ 时陈述成立(归纳假设),然后利用这个假设证明当 $n=k+1$ 时陈述也成立。
- 归纳法示例:证明对于所有 $n \ge 1$, $1+2+...+n = n(n+1)/2$。
- 基础步骤: 当 $n=1$ 时,左边是1,右边是 $1(1+1)/2 = 1$。成立。
- 归纳步骤: 假设当 $n=k$ 时成立,即 $1+2+...+k = k(k+1)/2$。
- 我们要证明当 $n=k+1$ 时也成立。看 $n=k+1$ 的情况:
$1+2+...+k+(k+1) = (1+2+...+k) + (k+1)$
根据归纳假设,括号里的部分等于 $k(k+1)/2$。
所以上式 $= k(k+1)/2 + (k+1) = (k+1)(k/2 + 1) = (k+1)(k+2)/2$。
这正是当 $n=k+1$ 时代入 $n(n+1)/2$ 得到的形式。证明完毕。
- 证明的书写:一个常见的错误是证明过程跳步或逻辑不清晰。一个好的证明应该像一个故事一样,清晰地引导读者从前提到结论,每一步都有理有据。
- 归纳假设的使用:在使用归纳法时,必须明确地写出并使用归纳假设。忘记使用归纳假设通常意味着你的证明思路是错误的。
本节强调了扎实的离散数学基础(集合、图、逻辑)和熟练掌握基本证明方法(构造、反证、归纳)是学好本课程的先决条件。
这部分起到了“预警”和“复习指引”的作用。它告诉学生:“这门课是数学密集型的,如果你对这些基础感到生疏,请立刻回到Sipser的第0章去复习,否则你将寸步难行。”
- 基础数学概念就像是你要用来搭建理论大厦的砖块、水泥和钢筋。
- 证明方法就像是你的施工工具和建造技术(砌墙、焊接、吊装)。
没有好的材料和工具,你无法建起任何坚固的建筑。
想象你正在学习法律。
- 基础数学概念相当于法律术语、基本法理(如“无罪推定”)。
- 证明方法相当于法律论证的技巧(如何组织证据、进行逻辑辩护、引用判例)。
不掌握这些,你无法成为一个合格的律师,同样,不掌握数学基础和证明,你也无法成为一个合格的理论计算机科学家。
25.2. 有限自动机示例:开关
📜 [原文14]
- 开关

操作:当你按下按钮时,如果灯亮着则关掉,如果灯灭着则打开
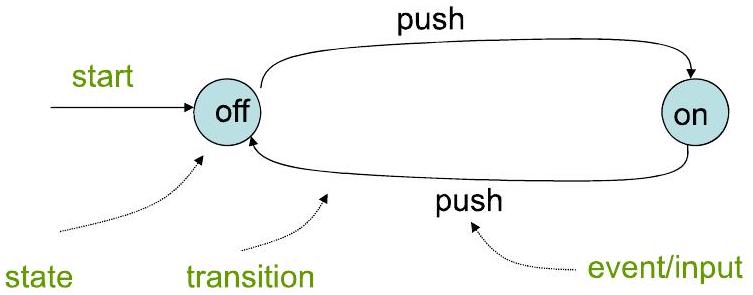
这是一个用有限自动机对一个非常简单的物理设备——开关——进行建模的例子。
- 系统: 一个带按钮的灯。
- 状态: 这个系统最核心的特性是灯的两种状态:“开 (on)” 和 “关 (off)”。因此,我们可以定义一个包含两个状态的集合 $Q = \{on, off\}$。
- 输入/事件: 改变系统状态的动作是“按下按钮 (push)”。因此,输入字母表 $\Sigma = \{push\}$。
- 状态转移:
- 如果当前状态是“off”,收到输入“push”,下一个状态应该是什么?根据操作描述“如果灯灭着则打开”,下一个状态是“on”。
- 如果当前状态是“on”,收到输入“push”,下一个状态应该是什么?根据操作描述“如果灯亮着则关掉”,下一个状态是“off”。
- 图示:
- 图片中画了两个圈,分别标记为 on 和 off,代表两个状态。
- 从 off 状态画了一个箭头指向 on 状态,箭头上标记着 push。这表示:在 off 状态,发生 push 事件,转移到 on 状态。
- 从 on 状态画了一个箭头指向 off 状态,箭头上也标记着 push。这表示:在 on 状态,发生 push 事件,转移到 off 状态。
- 我们可以任意指定一个初始状态,比如假设灯一开始是关着的,那么 off 就是初始状态。
- 输入序列1: push
- 初始状态: off
- 读取 push -> 转移到 on
- 最终状态: on (灯亮了)
- 输入序列2: push, push, push
- 初始状态: off
- 1. 读取第一个 push -> 转移到 on
- 2. 读取第二个 push -> 转移到 off
- 3. 读取第三个 push -> 转移到 on
- 最终状态: on (灯还是亮的)
- 我们可以观察到一个规律:经过奇数次 push,灯的状态会与初始状态相反;经过偶数次 push,灯的状态会回到初始状态。
- 模型的简化:这个模型非常简单,它只关心灯的开关状态。它没有对按钮的物理机制、电流、灯泡寿命等进行建模。这就是抽象的力量,只关注我们感兴趣的核心逻辑。
本节通过一个极其简单的开关例子,直观地展示了如何将一个物理系统的行为抽象成一个具有状态、输入和状态转移的有限自动机模型。
这个例子的目的是在引入形式化定义之前,给学生一个关于“有限自动机”是什么以及它如何工作的最直观、最简单的印象。通过联系日常生活中熟悉的物品,降低了学习抽象概念的门槛。
[直觉心-智模型]
这个模型就是一个乒乓球在两个半场(on, off)之间来回弹跳。每一次击球(push),球就会从一个半场跳到另一个半场。
就想象你手里有一个电视遥控器的电源按钮。你按一下,电视打开(进入on状态)。再按一下,电视关闭(进入off状态)。这个按钮的内部逻辑就是一个双状态的自动机。
35.3. 有限自动机示例:3槽缓冲区
📜 [原文15]
- 操作:可以插入一个项(如果缓冲区未满)或删除一个项(如果非空)
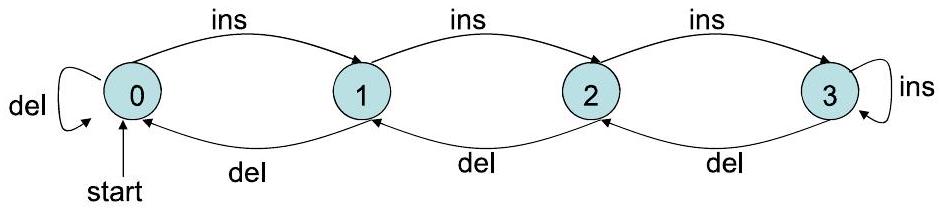
- 另外,对于满缓冲区中的插入或空缓冲区中的删除,可以转换为错误状态。
- 这个FA只跟踪缓冲区中项目的数量。如果我们还想跟踪项目本身的身份,我们需要一个更详细的自动机,并且还需要建模删除规则。
这是一个稍微复杂一点的例子,用有限自动机(FA)对一个容量为3的缓冲区进行建模。
- 系统: 一个先进先出(FIFO)的队列,最多能容纳3个项目。
- 核心特性: 我们关心的系统核心特性是缓冲区里“有多少个项目”。
- 状态: 因此,状态可以定义为缓冲区中项目的数量。由于容量为3,可能的项目数是0, 1, 2, 3。所以状态集合 $Q = \{0, 1, 2, 3\}$。
- 输入/事件: 操作有两种:“插入 (insert, 简写为 ins)” 和 “删除 (delete, 简写为 del)”。所以输入字母表 $\Sigma = \{ins, del\}$。
- 状态转移:
- 插入 (ins):
- 如果当前在状态 $i$ 且 $i < 3$(缓冲区未满),收到输入 ins,项目数增加1,转移到状态 $i+1$。
- 例如,从状态 0,输入 ins,到状态 1。从状态 2,输入 ins,到状态 3。
- 删除 (del):
- 如果当前在状态 $i$ 且 $i > 0$(缓冲区非空),收到输入 del,项目数减少1,转移到状态 $i-1$。
- 例如,从状态 3,输入 del,到状态 2。从状态 1,输入 del,到状态 0。
- 边界情况的处理:
- 在状态3(满)时插入: 图片中的模型采取了“忽略”策略。从状态3出发,标有 ins 的箭头指回了状态3本身。这意味着在一个满的缓冲区上执行插入操作,什么也不会发生,状态不变。
- 在状态0(空)时删除: 同样,从状态0出发,标有 del 的箭头指回了状态0。在一个空的缓冲区上执行删除操作,状态不变。
- 可选的错误状态: 讲义中提到,另一种处理边界情况的方法是引入一个“错误”状态。
- 比如,从状态3,如果输入ins,可以转移到一个专门的Error状态。一旦进入Error状态,就永远停留在那里。这在需要明确标识非法操作的场景中很有用。
- 模型的抽象层次:
- 这个FA只跟踪数量: 这是一个关键的抽象。这个模型并不知道缓冲区里存的具体是什么项目(比如是数字5还是字符串"hello"),也不知道它们的顺序。它只知道有“几个”项目。
- 如果想跟踪身份: 如果需要跟踪每个项目的内容,状态就需要变得复杂得多。例如,一个状态可能需要表示为 (item1, item2, item3)。如果项目可以是任何整数,那么状态的数量就会变成无限的,这就超出了有限自动机的范畴了。
- 输入序列: ins, ins, del, ins, ins, ins, del
- 初始状态: 0 (空缓冲区)
- 1. ins -> 状态 1
- 2. ins -> 状态 2
- 3. del -> 状态 1
- 4. ins -> 状态 2
- 5. ins -> 状态 3 (缓冲区满了)
- 6. ins -> 状态 3 (忽略操作,状态不变)
- 7. del -> 状态 2
- 最终状态: 2 (缓冲区里有两个项目)
本节使用一个3槽缓冲区的例子,展示了如何用有限自动机来建模一个具有多个状态和多种输入的系统,并讨论了如何处理边界条件以及模型抽象层次的选择。
这个例子比开关更进了一步,它有更多的状态和输入,更好地展示了有限自动机在描述稍复杂系统行为时的能力。同时,通过讨论“只跟踪数量”这一抽象,它也巧妙地引入了模型能力局限性的思想,为后续更强大的计算模型埋下伏笔。
[直觉心-智模型]
把这个自动机想象成一个有4个台阶的楼梯,台阶编号为0, 1, 2, 3。
- ins 操作就像是向上走一步。
- del 操作就像是向下走一步。
规则是:你不能走到3号台阶之上(在第3阶想往上走,只能原地踏步),也不能走到0号台阶之下(在第0阶想往下走,也只能原地踏步)。你所在的台阶编号,就代表了缓冲区中的项目数。
想象一个弹珠轨道,有四个并排的凹槽,代表状态0, 1, 2, 3。一个小球代表系统的当前状态。
- 如果你按下一个“+1”按钮(ins),轨道会倾斜,让小球滚到下一个编号的凹槽。如果小球已经在最右边的凹槽(状态3),它会被一个挡板挡住,只能留在原地。
- 如果你按下一个“-1”按钮(del),轨道会向反方向倾斜,让小球滚到前一个编号的凹槽。如果小球在最左边的凹槽(状态0),它也会被挡住,留在原地。
这个物理装置的行为完美地复现了这个有限自动机。
66. 形式化基础:字符串与语言 (Formal Strings & Languages)
16.1. 字符串、语言的基本概念
📜 [原文16]
- 字母表 $\Sigma=$ 有限非空符号集
示例:$\{0,1\}$(二进制字符串,二进制数),$\{0,1, \ldots, 9\}$(十进制数),$\{a, b, \ldots, z\}$,ASCII characters,\{push\},\{ins,del\},\{up,down,left,right\}
- 字符串:由 $\Sigma$ 中的符号组成的有限序列
示例:010010, 2022, abba, then
- 空字符串 $\varepsilon=$ 不含符号的字符串
- 字符串的长度 = 符号的数量,表示法:$|\sigma|$
示例:$|\varepsilon|=0,|0100|=4$
这部分开始为计算理论建立最基础的形式化定义,从“字母表”和“字符串”开始。
- 字母表 (Alphabet):
- 定义:一个有限的、非空的符号 (symbols) 集合。用大写希腊字母 $\Sigma$ (Sigma) 表示。
- 有限: 字母表里的符号数量必须是有限的,不能是无限的。
- 非空: 字母表里至少要有一个符号。
- 符号: 符号是构成字符串的最基本、不可再分的单位。
- 示例:
- $\Sigma = \{0, 1\}$: 二进制字母表,是计算机科学中最常见的字母表。
- $\Sigma = \{0, 1, \ldots, 9\}$: 十进制数字字母表。
- $\Sigma = \{a, b, \ldots, z\}$: 小写英文字母表。
- $\Sigma = \{ins, del\}$: 在缓冲区例子中,ins和del本身被看作是不可分割的符号。
- 字符串 (String):
- 定义:由字母表 $\Sigma$ 中的符号组成的一个有限序列。
- 有限: 字符串的长度必须是有限的。我们不研究无限长的字符串。
- 序列: 符号的顺序很重要。字符串 ab 和 ba 是不同的字符串。
- 示例:
- 如果 $\Sigma = \{0, 1\}$,那么 010010 是一个字符串。
- 如果 $\Sigma = \{a, b, \ldots, z\}$,那么 abba 和 then 都是字符串。
- 空字符串 (Empty String):
- 定义:一个特殊的、不包含任何符号的字符串。
- 符号:用小写希腊字母 $\varepsilon$ (epsilon) 表示。(有时也用 $\lambda$ (lambda))
- 字符串的长度 (Length of a String):
- 定义:字符串中包含的符号的数量。
- 符号:对于字符串 $w$,其长度表示为 $|w|$。
- 示例:
- $|\varepsilon| = 0$ (空字符串的长度是0)。
- $|0100| = 4$。
- 如果 $\Sigma = \{ins, del\}$,那么字符串 $w = \text{ins, del, ins}$ 的长度 $|w| = 3$。
- 字母表: $\Sigma = \{a, b, c\}$
- 字符串:
- a, b, c 是长度为1的字符串。
- ab, ac, ba, bb, bc, ca, cb, cc 是所有长度为2的字符串。
- baca 是一个长度为4的字符串。
- 长度计算:
- $|abacaba| = 7$
- $|\varepsilon| = 0$
- 符号 vs. 字符串: 字母表中的单个元素是“符号”。由一个或多个符号组成的序列是“字符串”。长度为1的字符串(如a)和符号a在概念上是不同的,但通常可以混用。
- 空字符串 $\varepsilon$: 它是一个字符串,而不是一个符号。它不属于任何字母表 $\Sigma$,但它是由任何字母表 $\Sigma$ 生成的字符串集合的一部分。
- 集合 vs. 序列: 字母表是集合,元素没有顺序($\{0,1\}$ 和 $\{1,0\}$ 是同一个字母表)。字符串是序列,元素的顺序至关重要(01 和 10 是不同的字符串)。
本节定义了计算理论的原子单位:字母表(允许使用的符号集合)和字符串(由这些符号构成的有限序列),以及两个基本属性:空字符串 $\varepsilon$ 和字符串长度 $|w|$。
这些形式化定义是构建整个理论体系的基石。没有对“字符串”的精确定义,我们就无法精确地定义“语言”(字符串的集合),也就无法精确地讨论自动机“接受”或“拒绝”什么。这是从自然语言描述转向数学语言描述的第一步。
[直觉心-智模型]
- 字母表 $\Sigma$:一盒乐高积木的所有不同种类的砖块(比如,有红色的2x2方块,蓝色的1x4长条,黄色的2x1斜面块)。
- 字符串 $w$:你用这些砖块拼出来的一个具体的、有限的作品,比如一辆小车。砖块的排列顺序很重要。
- 空字符串 $\varepsilon$:一个空的底板,上面什么也没拼。
- 字符串长度 $|w|$:你的作品一共用了多少块砖。
- 字母表 $\Sigma$:英语中的26个字母。
- 字符串 $w$:用这些字母拼写出的一个单词,如 theory。
- 空字符串 $\varepsilon$:一张白纸上的空白位置。
- 字符串长度 $|w|$:单词 theory 的长度是6。
26.2. 字符串操作
📜 [原文17]
- 字符串的前缀,字符串的后缀:字符串开头/结尾的子字符串
示例:abcd的前缀包括 $\varepsilon, a, ab, abc, abcd$,后缀包括 $\varepsilon, d, cd$等。
- 字符串 $x=a_{1} \ldots a_{i}$ 和 $y=b_{1} \ldots b_{j}$ 的连接是 $x \cdot y$ 或简写为 $xy=a_{1} \ldots a_{i} b_{1} \ldots b_{j}$
- 示例:$x=abra, y=cadabra \rightarrow xy=abracadabra$
对于每个字符串 $x, \varepsilon x=x \varepsilon=x$
- 字母表 $\Sigma$ 的幂
$\Sigma^{0}=\{\varepsilon\}, \Sigma^{1}=\Sigma, \Sigma^{k}=$ 长度为 $k$ 的 $\Sigma$ 上的字符串
$\Sigma^{*}=$ 任意长度的字符串 $=\Sigma^{0} \cup \Sigma^{1} \cup \Sigma^{2} \cup \cdots$
$\Sigma^{+}=$正长度的字符串 $=\Sigma^{1} \cup \Sigma^{2} \cup \cdots$
这部分定义了处理字符串的几种基本操作和符号。
- 前缀 (Prefix) 和 后缀 (Suffix):
- 前缀: 字符串开头部分的一个子串。如果 $w = uv$,那么 $u$ 就是 $w$ 的一个前缀。
- 后缀: 字符串结尾部分的一个子串。如果 $w = uv$,那么 $v$ 就是 $w$ 的一个后缀。
- 示例: 对字符串 abcd
- 前缀有: ε (空串是任何串的前缀), a, ab, abc, abcd (本身也是自己的前缀)。
- 后缀有: ε (空串是任何串的后缀), d, cd, bcd, abcd (本身也是自己的后缀)。
- 连接 (Concatenation):
- 定义:将两个字符串首尾相接,形成一个更长的字符串。
- 符号:用一个点 · 表示,但通常省略。如果 $x$ 和 $y$ 是字符串,它们的连接是 $xy$。
- 示例: $x = abra, y = cadabra \Rightarrow xy = abracadabra$。
- 单位元: 空字符串 $\varepsilon$ 是连接操作的单位元(Identity Element),就像数字0是加法的单位元,1是乘法的单位元一样。任何字符串与空字符串连接,都等于其本身。即 $x\varepsilon = \varepsilon x = x$。
- 字母表的幂 (Powers of an Alphabet):
- $\Sigma^k$: 表示由字母表 $\Sigma$ 中符号构成的、所有长度恰好为k的字符串的集合。
- $\Sigma^0 = \{\varepsilon\}$: 所有长度为0的字符串的集合,里面只有一个元素,就是空字符串。
- $\Sigma^1 = \Sigma$: 所有长度为1的字符串的集合,就是字母表本身。
- $\Sigma^2$: 是将 $\Sigma^1$ 中的每个字符串与 $\Sigma^1$ 中的每个字符串连接起来得到的所有结果。例如,如果 $\Sigma = \{0, 1\}$, 那么 $\Sigma^2 = \{00, 01, 10, 11\}$。
- $\Sigma^*$ (Kleene Star, 克林星号):
- 定义:所有任意有限长度(包括零)的字符串的集合。
- 它是 $\Sigma^k$ 的并集:$\Sigma^* = \Sigma^0 \cup \Sigma^1 \cup \Sigma^2 \cup \cdots$
- 这是理论计算机科学中最重要的符号之一,代表了“所有可能的字符串”。
- $\Sigma^+$ (Kleene Plus, 克林加号):
- 定义:所有正长度(大于零)的字符串的集合。
- $\Sigma^+ = \Sigma^1 \cup \Sigma^2 \cup \cdots = \Sigma^* - \{\varepsilon\}$。
- 设字母表 $\Sigma = \{a, b\}$
- 连接: $x = ab, y = ba \Rightarrow xy = abba, yx = baab$。注意连接不满足交换律。
- 幂:
- $\Sigma^0 = \{\varepsilon\}$
- $\Sigma^1 = \{a, b\}$
- $\Sigma^2 = \{aa, ab, ba, bb\}$
- $\Sigma^3 = \{aaa, aab, aba, abb, baa, bab, bba, bbb\}$
- 克林星号: $\Sigma^* = \{\varepsilon, a, b, aa, ab, ba, bb, aaa, \ldots\}$
- 克林加号: $\Sigma^+ = \{a, b, aa, ab, ba, bb, aaa, \ldots\}$
- $\Sigma$ vs $\Sigma^1$: $\Sigma$ 是符号的集合,$\Sigma^1$ 是长度为1的字符串的集合。它们包含的“东西”本质上是一一对应的,但在形式化系统中是不同类型的对象。
- $\Sigma^*$ 是无限集合: 即使字母表 $\Sigma$ 是有限的(比如只有两个符号),$\Sigma^*$ 也包含无限多个字符串。
- 字符串的幂 vs 字母表的幂: $x^k$ 表示字符串 $x$ 自我连接 $k$ 次,如 $a^3 = aaa$。而 $\Sigma^k$ 是一个字符串的集合。不要混淆。
本节定义了字符串的基本操作(前缀、后缀、连接)和基于字母表的强大符号($\Sigma^k, \Sigma^*, \Sigma^+$),这些符号为我们描述和操作字符串的集合提供了简洁的数学语言。
这些操作和符号是形式语言理论的“语法”。没有它们,我们在描述一个语言(比如“所有由偶数个0组成的二进制串”)时,将会非常冗长和不精确。$\Sigma^*$ 给了我们一个全集的概念,而其他操作和符号帮助我们从这个全集中精确地划定出我们感兴趣的子集。
[直觉心-智模型]
继续用乐高积木的例子:
- 连接: 把你拼好的小车A和你朋友拼好的小车B,用一个连接件接在一起,形成一个更长的组合车AB。
- $\Sigma^k$: 所有可以用正好k块积木拼出来的作品的集合。
- $\Sigma^*$: 所有可能的乐高作品的集合,无论用多少块积木(包括0块,即空的底板)。这是一个无限的、充满想象力的集合。
- $\Sigma^+$: 所有至少用了一块积木的作品的集合。
- 字母表: $\Sigma = \{'Go', ' '\}$
- 字符串: $w = \text{'Go Go'}$ (长度为3,符号是'Go'和' ')
- 连接: $x = \text{'Go'}, y = \text{' '}, z = \text{'Go'} \Rightarrow xyz = \text{'Go Go'}$
- $\Sigma^2$: {'GoGo', 'Go ', ' Go', ' '}
- $\Sigma^*$: 所有由 'Go' 和空格组成的标语的集合。
36.3. 语言
📜 [原文18]
- 字母表 $\Sigma$ 上的语言 $L=$ $\Sigma^{*}$ 的任意子集,即 $\Sigma$ 上的任意字符串集
- 示例:$\varnothing, \Sigma, \Sigma^{*}$
- 英文字典中的所有单词($\Sigma=\{\mathrm{a}, \ldots, \mathrm{z}\}$)
- 所有有效的C程序($\Sigma=$ ASCII characters incl. newline CR)
- 十进制表示的所有偶数($\Sigma=\{0, \ldots, 9\}$)
- 二进制表示的所有素数($\Sigma=\{0,1\}$)
- 可以用二进制表示法(或ASCII)编码图、矩阵等 -> 所有平面图编码的集合
这部分给出了计算理论中“语言”的形式化定义。
- 语言 (Language):
- 定义: 对于一个给定的字母表 $\Sigma$,一个语言 $L$ 是 $\Sigma^*$ 的任意一个子集。
- 换句话说: 一个语言就是一个字符串的集合。这个定义非常宽泛。任何你能想到的字符串的集合,无论多么奇怪,只要这些字符串都构建于同一个字母表之上,它就是一个语言。
- 示例:
- 平凡的例子:
- $\varnothing$ (空集): 不包含任何字符串的语言。
- $\Sigma$ (字母表本身): 是一个语言,包含了所有长度为1的字符串。
- $\Sigma^*$: 包含了所有可能字符串的语言。
- 来自现实世界的例子:
- 英文字典: 字母表是 $\Sigma=\{a, ..., z\}$。字典里所有单词的集合是一个语言。cat 在这个语言里,但 catt 不在。
- 所有有效的C程序: 字母表是ASCII字符集。所有能被C语言编译器成功编译的源文件(字符串)的集合,构成一个非常复杂的语言。
- 数学定义的例子:
- 所有偶数: 字母表是 $\Sigma=\{0, ..., 9\}$。语言 $L = \{w \in \Sigma^* | w \text{ 代表一个偶数}\}$。所以 10, 24, 0 在 $L$ 中, 但 13, 2.5 不在。
- 所有素数: 字母表是 $\Sigma=\{0, 1\}$。语言 $L = \{w \in \{0,1\}^* | w \text{ 是一个素数的二进制表示}\}$。所以 10(2), 11(3), 101(5) 在 $L$ 中, 但 100(4) 不在。
- 编码表示的例子:
- 任何离散的数学对象(如图、矩阵、甚至自动机本身)都可以被编码 (encode) 成一个字符串。例如,一个图可以用其邻接矩阵的二进制表示来编码。
- 所有平面图的编码集合: 这是一个语言。它的成员是所有代表“可以画在平面上而边不交叉的图”的字符串。判断一个给定的字符串是否属于这个语言,是一个重要的算法问题。
- 字母表 $\Sigma = \{a, b\}$
- 以下都是合法的语言:
- $L_1 = \{a, aa, aaa\}$ (一个有限语言)
- $L_2 = \{w \in \Sigma^* | |w| \text{ is even}\}$ (所有长度为偶数的字符串的集合,是无限语言)
- $L_3 = \{a^n b^n | n \ge 0\} = \{\varepsilon, ab, aabb, aaabbb, \ldots\}$ (所有a的数量等于b的数量,且a在b前面的字符串,是无限语言)
- $L_4 = \varnothing$ (空语言)
- $L_5 = \{\varepsilon\}$ (只包含空字符串的语言)
- 语言 vs. 字符串: 语言是集合,字符串是这个集合里的元素。a 是一个字符串,而 {a} 是一个只包含一个字符串的语言。
- 空语言 vs. 只包含空字符串的语言:
- $\varnothing$ (空语言) 是一个不包含任何元素的集合。
- $\{\varepsilon\}$ 是一个包含一个元素的集合,这个元素恰好是空字符串。
- 这就像一个空钱包和一个只装了一张“0元”假币的钱包的区别。
- 本课程的核心任务: 本课程的一个核心任务,就是研究不同类型的计算模型(自动机、图灵机等)识别不同类型的语言的能力。例如,我们会证明,有限自动机可以识别上面例子中的 $L_2$,但无法识别 $L_3$。
本节将“语言”精确地定义为“一个字母表上所有可能字符串 ($\Sigma^*$) 的任意子集”。这个定义异常宽泛,囊括了从英文字典到所有C程序,再到数学对象的编码等各种各样、复杂度天差地别的字符串集合。
这个定义将计算理论的核心问题——“一个问题是否可计算/高效计算”——转化为了一个关于集合成员资格的问题。任何一个“是/否”问题(例如,“一个数是素数吗?”)都可以被重新表述为:给定一个字符串(对问题的编码,如数字的二进制串),判断该字符串是否属于某个特定的语言(所有代表“是”的答案的编码的集合,如所有素数的二进制串集合)。
[直觉心-智模型]
- $\Sigma^*$: 整个宇宙中所有可能说出的话(字符串)。
- 一个语言 L: 一群人约定只说某些特定的话(比如,只说符合英语语法的话,或者只说暗号)。这个约定下所有“合法”的话的集合,就是一个语言。
- 自动机/计算模型: 一个“裁判”,他能听懂某一种约定(语言),当他听到一句话,他能判断这句话是否符合这个约定。
想象一张巨大的世界地图,上面有无数的点($\Sigma^*$)。
- 一个语言 L 就是你在地图上画的一个圈,圈里的点属于这个语言,圈外的点不属于。
- 这个圈的边界可以非常简单(比如一个正圆形),也可以无比复杂、扭曲、支离破碎。
- 计算理论就是要研究:
- 我们可以用什么样的“笔”(计算模型)来画出这些圈?
- 有些圈(语言)是不是太复杂了,以至于任何笔都画不出来(不可计算的语言)?
- 画一个特定的圈需要多长时间(计算复杂性)?
77. 确定性有限自动机 (DFA) (Deterministic Finite Automata)
17.1. 定义
📜 [原文19]
- $A=(Q, \Sigma, \delta, q_{0}, F)$
- $Q=$ 有限状态集
- $\Sigma=$ 有限(输入)字母表
- $\delta=$ 转移函数:$\delta: Q \times \Sigma \rightarrow Q$
即,对于 $Q$ 中的每个 $q$ 和 $\Sigma$ 中的每个 $a, \delta(q, a) \in Q$
(该函数为所有输入对 $(q, a)$ 完全且唯一地定义:确定性FA)
- $q_{0}=$ 开始(或初始)状态
- $F \subseteq Q$ 是接受(或最终)状态集
这部分给出了确定性有限自动机 (Deterministic Finite Automaton, DFA) 的严格数学定义。DFA是一个五元组 $(Q, \Sigma, \delta, q_0, F)$。
- $Q$ (Q is a finite set of states):
- 一个有限的状态集合。这是“有限自动机”中“有限”一词的来源。机器的记忆力被限制在它当前处于哪个状态。
- $\Sigma$ (Sigma is a finite input alphabet):
- 一个有限的输入字母表,定义了所有机器可以读取的符号。
- $\delta$ (delta is the transition function):
- 转移函数,是DFA的“程序”或“逻辑核心”。
- 它的形式是 $\delta: Q \times \Sigma \to Q$。
- 解读: 这个函数的输入是一个序对 (当前状态, 当前读取的输入符号),输出是一个 下一个状态。
- 确定性 (Deterministic) 的含义就体现在这里:对于任何给定的当前状态和当前输入符号,下一个状态是唯一确定的。没有选择的余地,路径是唯一的。
- 完全定义: $\delta$ 函数必须为 $Q \times \Sigma$ 中的每一个可能的输入对都指定一个输出。不允许出现“在状态q,读到符号a,不知道该去哪”的情况。
- $q_0$ (q_0 is the start (or initial) state):
- $q_0 \in Q$,是 $Q$ 中的一个特殊状态,规定了机器在读取任何输入之前所处的初始位置。
- $F$ (F is the set of accept (or final) states):
- $F \subseteq Q$,是 $Q$ 的一个子集(可以是空集)。
- 这些状态是“好”的或“成功的”终止状态。如果机器在读完整个输入字符串后,恰好停在了 $F$ 中的某个状态,那么我们就说这个字符串被接受 (accepted) 了。
- 以之前的开关为例进行形式化:
- $Q = \{q_{off}, q_{on}\}$
- $\Sigma = \{push\}$
- $\delta$:
- $\delta(q_{off}, push) = q_{on}$
- $\delta(q_{on}, push) = q_{off}$
- $q_0 = q_{off}$ (假设初始是关的)
- $F = \{q_{on}\}$ (假设我们关心的是“最终灯是亮的”这个结果)
- 一个识别所有以'1'结尾的二进制串的DFA:
- $Q = \{q_A, q_B\}$ (状态A代表"最近一个读到的是0或还没读",状态B代表"最近一个读到的是1")
- $\Sigma = \{0, 1\}$
- $\delta$:
- $\delta(q_A, 0) = q_A$ (读到0,继续停在“最近是0”的状态)
- $\delta(q_A, 1) = q_B$ (读到1,进入“最近是1”的状态)
- $\delta(q_B, 0) = q_A$ (在“最近是1”后读到0,变回“最近是0”的状态)
- $\delta(q_B, 1) = q_B$ (在“最近是1”后又读到1,继续保持)
- $q_0 = q_A$
- $F = \{q_B\}$ (只要最后停在“最近是1”的状态,就算接受)
- 五元组缺一不可: 定义一个DFA必须完整地说明这五个部分。
- F可以是空集: $F = \varnothing$ 是允许的。这样的DFA不接受任何字符串,其语言是空语言 $\varnothing$。
- F可以是全集: $F = Q$ 也是允许的。这样的DFA接受所有字符串,其语言是 $\Sigma^*$。
- “确定性”的严格性: 必须是 (状态, 符号) -> 单个状态 的映射。后面会学到的非确定性有限自动机 (NFA) 会放宽这个限制。
本节给出了DFA的精确数学定义,它由五个部分组成:有限的状态集Q,有限的字母表Σ,完全且确定性的转移函数δ,唯一的开始状态q0,以及一个接受状态的集合F。
这个形式化定义是进行任何严谨分析的基础。有了它,我们就可以脱离画图和直觉,纯粹用数学符号来描述、操作和证明关于DFA的性质。例如,我们可以基于这个定义来形式化地定义“DFA如何计算”以及“DFA的语言是什么”。
[直觉心-智模型]
DFA五元组就像是一份“寻宝游戏”的完整规则书。
- $Q$: 所有的藏宝地点(有限个)。
- $\Sigma$: 所有可能的指令卡片(比如“向东走”、“向南走”)。
- $\delta$: 规则的核心,说明“在任何地点,抽到任何指令卡,你下一步必须去哪个地点”。
- $q_0$: 游戏的起点。
- $F$: 最终的宝藏所在地(可能不止一个)。
游戏玩法:你从起点出发,按顺序抽取一串指令卡(输入字符串),严格按照规则书移动,走完所有指令后,如果你恰好在某个宝藏所在地,你就赢了(接受字符串)。
想象一个老式的投币电话。
- $Q$: {“挂机”, “待拨号”, “拨号中”, “通话中”, “对方占线”}
- $\Sigma$: {“拿起听筒”, “挂上听筒”, “投币”, “拨数字0-9”}
- $\delta$: 电话的内部电路逻辑,决定了在任何状态下,做了任何动作后,会进入什么新状态。例如,在“待拨号”状态“投币”,会继续留在“待拨号”状态(但内部可能有个计数器变了)。在“待拨号”状态“拨数字”,会进入“拨号中”。
- $q_0$: “挂机”状态。
- $F$: 我们可以定义“通话中”为接受状态,如果我们关心的是“成功打通电话”这个事件。
27.2. 转移图表示
📜 [原文20]
- 转移图:带有标记边的有向图
- 节点集 = $Q$(状态集),
- 边:对于每个 $q \in Q, a \in \Sigma$,如果 $\delta(q, a)=p$,则有边 $q \rightarrow p$ 标记为 $a$。(如果对于许多符号 $a, \delta(q, a)=p$,则我们通常画一条边并放置许多标记,而不是画许多平行边)
- “开始”箭头指向开始状态 $q_{0}$
- 接受状态 ($F$) 用双圈标记
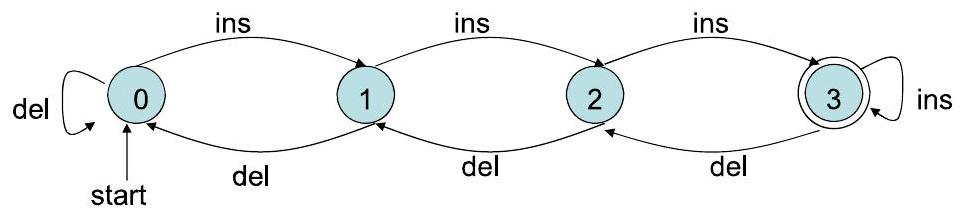
这部分介绍了如何将DFA的抽象五元组定义可视化为一张转移图 (Transition Diagram)。
- 转移图: 本质上就是一个有向图 (directed graph),图的各个部分对应DFA五元组的各个部分。
- 节点 (Nodes/Vertices): 图中的每个节点(通常画成一个圆圈)代表DFA状态集 $Q$ 中的一个状态。
- 边 (Edges/Arcs): 图中的箭头代表状态之间的转移。
- 边的规则: 如果转移函数规定 $\delta(q, a) = p$,那么就在图上从节点 $q$ 画一个箭头指向节点 $p$,并在这个箭头上标记符号 $a$。
- 边的合并: 如果从状态 $q$ 出发,读入好几个不同的符号 $a, b, c$ 都转移到同一个状态 $p$,我们通常只画一条从 $q$ 到 $p$ 的边,然后在边上写上 $a,b,c$。
- 开始状态的表示: 用一个没有起点的、“凭空”出现的箭头指向开始状态 $q_0$。
- 接受状态的表示: 接受状态集 $F$ 中的所有状态,都用双层圆圈来表示,以区别于普通的单圈状态。
- 图例分析:
- 图中有三个状态,我们可以叫它们 $q_1, q_2, q_3$。所以 $Q=\{q_1, q_2, q_3\}$。
- 边上标记的符号有 a 和 b。所以 $\Sigma=\{a,b\}$。
- 有一个箭头指向 $q_1$,所以 $q_1$ 是开始状态 $q_0$。
- $q_2$ 是用双圈画的,所以 $q_2$ 是接受状态。$F=\{q_2\}$。
- 转移函数 $\delta$ 可以从图中读出:
- $\delta(q_1, a) = q_2$
- $\delta(q_1, b) = q_1$
- $\delta(q_2, a) = q_2$
- $\delta(q_2, b) = q_3$
- $\delta(q_3, a) = q_2$
- $\delta(q_3, b) = q_1$
- 画出之前“识别以1结尾的二进制串”DFA的转移图:
- 状态: $Q=\{q_A, q_B\}$。画两个圈,标上 $q_A, q_B$。
- 开始状态: $q_A$。画一个箭头指向 $q_A$。
- 接受状态: $F=\{q_B\}$。把 $q_B$ 的圈画成双圈。
- 转移:
- $\delta(q_A, 0) = q_A$: 从 $q_A$ 画一个指回自己的箭头,标上 0。
- $\delta(q_A, 1) = q_B$: 从 $q_A$ 画一个指向 $q_B$ 的箭头,标上 1。
- $\delta(q_B, 0) = q_A$: 从 $q_B$ 画一个指向 $q_A$ 的箭头,标上 0。
- $\delta(q_B, 1) = q_B$: 从 $q_B$ 画一个指回自己的箭头,标上 1。
- 最终的图会非常清晰地展示这个DFA的行为。
- 检查完备性: 对于一个DFA的转移图,每个状态都必须有对应字母表中每个符号的出边。例如,如果 $\Sigma=\{a,b\}$,那么每个状态都必须正好有一条标a的出边和一条标b的出边。这是“确定性”和“完全定义”在图上的体现。
本节介绍了将DFA的五元组形式化定义翻译成直观的转移图的方法:状态是节点,转移是带标签的边,开始状态有特殊箭头,接受状态是双圈。
人类是视觉动物。纯粹的数学符号(五元组)虽然严谨,但不直观。转移图提供了一种强大而直观的方式来理解和设计DFA。在思考和交流关于DFA的问题时,我们通常首先画出它的转移图。
[直觉心-智模型]
转移图就是之前提到的“寻宝游戏”的地图。
- 节点是地点。
- 带标签的边是连接地点的、标有指令的单行道。
- 起始箭头是“玩家起点”的标记。
- 双圈是“宝藏”的标记。
看着这张地图,你就可以模拟任何一串指令(输入字符串)会把你带到哪里。
想象一个地铁线路图。
- 站点就是状态。
- 不同颜色的线路(比如1号线、2号线)就是不同的输入符号。
- 地图规定了在任何一个站,乘坐任何一条线,你会到达哪一站。这就是转移函数。
- 某个站被标记为“起点站”,另一个(或几个)站被标记为“目的地”。
- 给你一串换乘指令(比如“先坐2号线,再坐1号线,再坐1号线”),你可以很容易地在图上模拟出你的路径,并看到最终会停在哪一站。
37.3. 转移表表示
📜 [原文21]
- 行对应状态,列对应输入符号,对于 $q, a$ 的条目是 $\delta(q, a)$,开始状态用 → 标记,接受状态用 * 标记
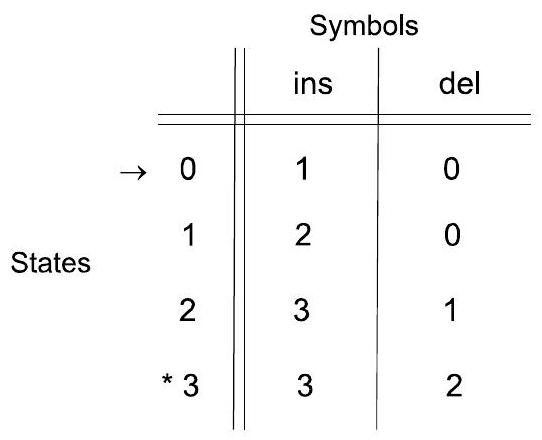
这部分介绍了表示DFA的第三种方式:转移表 (Transition Table)。这是对转移函数 $\delta$ 最直接的描述。
- 表格结构:
- 行 (Rows): 表的每一行对应DFA状态集 $Q$ 中的一个状态。
- 列 (Columns): 表的每一列对应输入字母表 $\Sigma$ 中的一个符号。
- 单元格 (Entries): 在“状态q”行和“符号a”列交叉处的单元格里,填入的就是 $\delta(q,a)$ 的结果,即下一个状态。
- 特殊状态的标记:
- 开始状态 ($q_0$): 在表示开始状态的那一行的行首,画一个箭头 →。
- 接受状态 ($F$): 在表示接受状态的那些行的行首,画一个星号 。如果一个状态既是开始状态又是接受状态,就同时画上 → 和 。
- 图例分析:
- 这个表格表示的正是上一节转移图所表示的同一个DFA。
- 行: 有三行,分别对应状态 $q_1, q_2, q_3$。
- 列: 有两列,分别对应输入符号 a 和 b。
- 标记:
- $q_1$ 行前有 →,所以 $q_1$ 是开始状态。
- $q_2$ 行前有 *,所以 $q_2$ 是接受状态。
- 单元格内容:
- $(q_1, a)$ 单元格是 $q_2$,表示 $\delta(q_1, a) = q_2$。
- $(q_1, b)$ 单元格是 $q_1$,表示 $\delta(q_1, b) = q_1$。
- ...依此类推,表格完整地定义了整个转移函数 $\delta$。
- 之前“识别以1结尾的二进制串”DFA的转移表:
| 0 | 1 | |
|---|---|---|
| → $q_A$ | $q_A$ | $q_B$ |
| * $q_B$ | $q_A$ | $q_B$ |
- 这张表清晰地展示了所有的转移规则。
- 表示的等价性: 五元组、转移图、转移表是描述同一个DFA的三种完全等价的方式。必须能够熟练地在三者之间进行转换。
- 从五元组到表/图:直接按定义填写/绘制。
- 从图到表/五元组:观察节点和边,读出信息。
- 从表到图/五元z-组:观察行、列和单元格,读出信息。
本节介绍了用二维表格(转移表)来表示DFA的方法。这是一种介于纯数学符号和图形化表示之间的、结构化且清晰的表示方式。
转移表非常适合在计算机程序中实现一个DFA。一个二维数组或哈希表可以很自然地存储转移表的信息,使得模拟DFA的运行变得非常高效。相比于解析图形,或者处理抽象的五元组,表格在代码实现上是最直接的。
[直觉心-智模型]
转移表就像一张火车时刻表。
- 行是出发站。
- 列是车次类型(比如“快车”、“慢车”)。
- 单元格里写着乘坐对应车次会到达的下一站。
- 表格上还用特殊符号标出了“你的旅程起点站”和“哪些站是风景名胜(接受状态)”。
想象一个简单的选择题游戏。
- 每一页(状态)上都有几个问题(输入符号)。
- 比如在第1页(状态 $q_1$):
- 问题A: "你选择左边的门(a)还是右边的门(b)?"
- 规则写着:选(a)则翻到第2页,选(b)则留在第1页。
- 这个规则就可以记录在转移表里:$(q_1, a) \to q_2$, $(q_1, b) \to q_1$。
整个游戏的跳转逻辑,就是一张转移表。
47.4. 符号表示
📜 [原文22]
示例:k-槽缓冲区自动机
这部分展示了如何用数学符号(五元组)来精确地、概括性地描述一个具有参数k的DFA家族。
- 系统: 一个容量为k的缓冲区。这里的k是一个参数,而不是一个具体的数字(如之前的3)。
- 五元组定义:
- $Q=\{0,1,2, \ldots, k\}$: 状态集是从0到k的k+1个整数,每个整数代表缓冲区中的项目数。这是一个依赖于参数k的集合。
- $\Sigma=\{\mathrm{ins}, \mathrm{del}\}$: 字母表是固定的,包含插入和删除两个操作。
- $\delta$: 转移函数是用带有条件的数学表达式来定义的,而不是像之前那样一一列举。
- $\delta(i, \mathrm{ins}) = i+1 \text{ if } i<k \text{ else } k$:
- 解读: 如果当前状态是 $i$ (有i个项目),并且 $i<k$ (缓冲区未满),那么在收到ins输入后,下一个状态是 $i+1$。
- 否则 (else),如果 $i=k$ (缓冲区已满),那么下一个状态仍然是 $k$ (状态不变)。
- 这可以用更紧凑的数学函数 min(i+1, k) 来表示。
- $\delta(i, \mathrm{del}) = i-1 \text{ if } i>0 \text{ else } 0$:
- 解读: 如果当前状态是 $i$ 且 $i>0$ (缓冲区非空),在收到del输入后,下一个状态是 $i-1$。
- 否则 (else),如果 $i=0$ (缓冲区已空),那么下一个状态仍然是 $0$ (状态不变)。
- 这可以用更紧凑的数学函数 max(i-1, 0) 来表示。
- $q_{0}=0$: 初始状态是0,代表缓冲区一开始是空的。
- $F=\{k\}$: 接受状态被定义为状态 $k$。这意味着这个DFA的目的是识别那些“恰好能把缓冲区填满”的操作序列。
- 公式: $\delta(i, \mathrm{ins})=i+1 \text { if } i<k \text { else }=k$
- $\delta(i, \mathrm{ins})$: 这是函数的调用。$i$ 是代表当前状态的变量,$\mathrm{ins}$ 是输入符号。
- if $i < k$: 这是一个条件判断。检查当前状态 $i$ 是否小于缓冲区的容量 $k$。
- then $i+1$: 如果条件为真,函数返回 $i+1$。
- else $k$: 如果条件为假(即 $i=k$),函数返回 $k$。
- 公式: $\delta(i, \mathrm{del})=i-1 \text { if } i>0 \text { else }=0$
- $\delta(i, \mathrm{del})$: 函数调用。
- if $i > 0$: 条件判断,检查缓冲区是否为空。
- then $i-1$: 如果非空,返回 $i-1$。
- else $0$: 如果为空,返回 $0$。
- 设 k=2 (一个2槽缓冲区)
- $Q = \{0, 1, 2\}$
- $\Sigma = \{\mathrm{ins}, \mathrm{del}\}$
- $q_0 = 0$
- $F = \{2\}$
- $\delta$ 函数的具体值:
- $\delta(0, \text{ins}) = 1$
- $\delta(1, \text{ins}) = 2$
- $\delta(2, \text{ins}) = 2$
- $\delta(0, \text{del}) = 0$
- $\delta(1, \text{del}) = 0$
- $\delta(2, \text{del}) = 1$
- 我们可以为这个 k=2 的DFA画出转移图或转移表。这个符号表示法是生成所有k值对应的DFA的一个“模板”。
本节展示了使用数学公式来定义转移函数 $\delta$ 的方法,这种方法能够简洁地描述一个参数化的、有规律的DFA家族,而无需为每个具体的参数值都画一张图或表。
这种表示法对于理论分析和证明至关重要。当我们要证明关于所有k-槽缓冲区的某个通用性质时,我们必须基于这个符号化的定义来进行推导,而不能只依赖于k=3时的特例。它展示了从“实例”到“普适规律”的抽象过程。
[直觉心-智模型]
这就像是用一个代数公式来代替一个长长的数字表格。
- 转移表就像是函数 $y=x^2$ 的一张值对应表:x=1, y=1; x=2, y=4; x=3, y=9...
- 符号表示就像是直接写出 $y=x^2$ 这个公式本身。
公式更简洁、更通用,并且揭示了背后的规律。
想象你在编写一个计算机程序来模拟这个缓冲区。
- 你不会为k=1, k=2, k=3... 分别写一套代码。
- 你会写一个通用的函数,它接受 k 作为参数。函数内部的逻辑就会是:
```python
def delta(i, input_char, k):
if input_char == 'ins':
return min(i + 1, k)
elif input_char == 'del':
return max(i - 1, 0)
```
这个程序的核心逻辑,就是对DFA符号表示的直接翻译。
57.5. DFA处理输入
📜 [原文23]
- 给定输入字符串 $x=a_{1} a_{2} \ldots a_{n}$,DFA从状态 $q_{0}$ 开始,读取 $a_{1}$ 并移动到状态 $\delta(q_{0}, a_{1})=$ 比如 $q_{1}$,然后读取 $a_{2}$ 并移动到状态 $\delta(q_{1}, a_{2})=$ 比如 $q_{2}$,依此类推,即 DFA 经历一个状态序列 $q_{1} q_{2} q_{3} \ldots q_{n}$(不一定不同),使得对于每个 $i=1, \ldots, n$,都有 $\delta(q_{i-1}, a_{i})=q_{i}$。
- 当且仅当最终状态 $q_{n}$ 在 $F$ 中时,自动机接受输入,否则拒绝。
- 自动机 $A$ 的语言,表示为 $L(A)$,是自动机 $A$ 接受的所有输入字符串的集合。
这部分形式化地定义了DFA的计算过程以及它如何接受或拒绝一个字符串,并最终定义了DFA的语言。
- 计算过程 (Computation):
- 输入是一个字符串,比如 $x = a_1 a_2 \ldots a_n$。
- 1. 初始化: 计算从起始状态 $q_0$ 开始。
- 2. 迭代处理: DFA像一个处理器,一个接一个地“消耗”输入字符串中的符号。
- 第1步: 读取第一个符号 $a_1$。根据转移函数,从当前状态 $q_0$ 移动到新状态 $q_1 = \delta(q_0, a_1)$。
- 第2步: 读取第二个符号 $a_2$。从当前状态 $q_1$ 移动到新状态 $q_2 = \delta(q_1, a_2)$。
- ...
- 第i步: 读取第 $i$ 个符号 $a_i$。从当前状态 $q_{i-1}$ 移动到新状态 $q_i = \delta(q_{i-1}, a_i)$。
- 3. 结束: 这个过程一直持续到字符串的所有符号都被读取完毕。当最后一个符号 $a_n$ 被处理后,DFA会停在一个最终状态 $q_n$。
- 状态序列: 整个计算过程产生了一个状态序列 $q_0, q_1, q_2, \ldots, q_n$。注意,这些状态不一定是互不相同的,DFA可能在某些状态之间来回访问。
- 接受与拒绝 (Acceptance and Rejection):
- 判断标准: 判断一个字符串是被接受还是拒绝,只看处理完所有符号后DFA所在的最终状态 $q_n$。
- 接受 (Accept): 如果最终状态 $q_n$ 是接受状态集合 $F$ 中的一个成员 (即 $q_n \in F$),那么输入字符串 $x$ 被DFA接受。
- 拒绝 (Reject): 如果最终状态 $q_n$ 不在 $F$ 中 (即 $q_n \notin F$),那么输入字符串 $x$ 被DFA拒绝。
- DFA的语言 (Language of a DFA):
- 定义: 一个DFA $A$ 的语言,记作 $L(A)$,是所有能被 $A$ 接受的字符串的集合。
- 形式化: $L(A) = \{ w \in \Sigma^* \mid \text{DFA } A \text{ 接受字符串 } w \}$。
- 凡是被 $A$ 接受的字符串,都是 $L(A)$ 的成员。凡是被 $A$ 拒绝的字符串,都不是 $L(A)$ 的成员。因此,每个DFA都精确地定义了一个语言。
- 使用之前“识别以1结尾的二进制串”的DFA A:
- $Q=\{q_A, q_B\}, \Sigma=\{0,1\}, q_0=q_A, F=\{q_B\}$
- $\delta(q_A,0)=q_A, \delta(q_A,1)=q_B, \delta(q_B,0)=q_A, \delta(q_B,1)=q_B$
- 示例1:输入字符串 w = "101"
- 开始于 $q_0 = q_A$。
- 读 '1': 状态变为 $\delta(q_A, 1) = q_B$。
- 读 '0': 状态变为 $\delta(q_B, 0) = q_A$。
- 读 '1': 状态变为 $\delta(q_A, 1) = q_B$。
- 字符串结束。最终状态是 $q_B$。
- 检查: $q_B \in F$ 吗?是的。
- 结论: 字符串 "101" 被DFA A接受。
- 示例2:输入字符串 w = "010"
- 开始于 $q_0 = q_A$。
- 读 '0': 状态变为 $\delta(q_A, 0) = q_A$。
- 读 '1': 状态变为 $\delta(q_A, 1) = q_B$。
- 读 '0': 状态变为 $\delta(q_B, 0) = q_A$。
- 字符串结束。最终状态是 $q_A$。
- 检查: $q_A \in F$ 吗?不是。
- 结论: 字符串 "010" 被DFA A拒绝。
- DFA A的语言: $L(A) = \{w \in \{0,1\}^* \mid w \text{以1结尾}\}$。
- 中间状态不重要: 接受或拒绝只取决于最后一个状态。即使计算路径中经过了接受状态,但只要最后停在非接受状态,整个字符串仍然被拒绝。
- 空字符串的处理: 如何处理输入 $\varepsilon$?DFA不读取任何符号,所以它停在起始状态 $q_0$。因此,$\varepsilon$ 被接受当且仅当 $q_0 \in F$(起始状态本身就是一个接受状态)。
本节描述了DFA的动态行为:它如何按部就班地处理输入字符串并引发一系列状态转移,以及如何根据最终停留的状态来决定接受或拒绝该字符串。一个DFA所接受的所有字符串的集合,就定义了该DFA的语言。
这部分内容将DFA的静态定义(五元组)和它的动态功能(语言识别)联系起来,是整个自动机理论的核心。它回答了“我们定义这个DFA是为了什么?”这个问题。答案是:为了定义/识别一个特定的语言。这为后续章节探讨“什么样的语言可以被DFA识别?”奠定了基础。
[直觉心-智模型]
DFA的计算过程就像是在一个迷宫里寻路。
- 输入字符串:一张写着前进方向的指令序列(比如“左转,右转,直行”)。
- 你(处理器):从迷宫的入口($q_0$)出发。
- 一步计算:你读取一个指令,然后按照迷宫墙上的路标($\delta$)走到下一个路口(状态)。
- 接受/拒绝:当你用完所有指令后,你停在一个路口。如果这个路口有一个“出口”标记(属于$F$),你就成功走出了迷宫(接受)。否则,你就被困在了迷宫里(拒绝)。
- DFA的语言:所有那些能让你成功走出迷宫的指令序列的集合。
想象一个简单的密码锁,密码是“132”。
- 状态:可以看作“已输入正确密码的长度”,即 $Q=\{S_0, S_1, S_2, S_3\}$。$S_0$是初始状态,$S_3$是开锁状态。
- 输入:你按下的数字键。
- 计算过程:
- 在 $S_0$,你按下'1',进入$S_1$(密码对了第一个)。按下其他任何数字,都留在$S_0$。
- 在 $S_1$,你按下'3',进入$S_2$(对了第二个)。按下其他数字,则回到$S_0$(密码错,从头开始)。
- 在 $S_2$,你按下'2',进入$S_3$(密码全对),锁开了!
- 在 $S_3$(开锁状态),按任何键都可能让锁保持开启。
- 接受/拒绝: 只有输入"132"这个序列能让你最终停在 $S_3$ (接受状态)。任何其他序列都会让你停在非接受状态,锁打不开。
- 语言: 这个密码锁DFA的语言就是 $L = \{"132"\}$。
67.6. 综合示例
📜 [原文24]
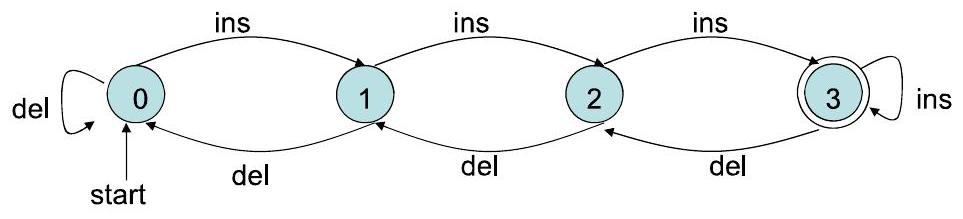
inputstring: ins ins ins del ins
path: $0 \longrightarrow 1 \longrightarrow 2 \longrightarrow 3 \longrightarrow 2 \longrightarrow 3$
- 这个自动机的语言:
$L(A)=$ 使缓冲区变满的操作序列集合
这部分通过一个完整的例子,将前面介绍的3槽缓冲区DFA、输入处理和语言定义串联起来。
- DFA回顾:
- 这是k=3时的缓冲区自动机。
- $Q=\{0, 1, 2, 3\}$, $\Sigma=\{\text{ins, del}\}$, $q_0=0$, $F=\{3\}$。
- 接受状态是3,代表缓冲区的“满”状态。
- 处理输入字符串:
- 输入: ins ins ins del ins
- 路径 (Path): 演示了DFA如何一步步处理这个输入。
- 开始: 状态 0
- 读 'ins': $0 \to 1$ (从状态0,$\delta(0, \text{ins})=1$)
- 读 'ins': $1 \to 2$ (从状态1,$\delta(1, \text{ins})=2$)
- 读 'ins': $2 \to 3$ (从状态2,$\delta(2, \text{ins})=3$)
- 读 'del': $3 \to 2$ (从状态3,$\delta(3, \text{del})=2$)
- 读 'ins': $2 \to 3$ (从状态2,$\delta(2, \text{ins})=3$)
- 结束: 字符串读取完毕,最终状态是 3。
- 判断: 最终状态 3 是否在接受状态集 $F=\{3\}$ 中?是的。
- 结论: 字符串 ins ins ins del ins 被这个DFA接受。
- 自动机的语言 (Language of the Automaton):
- $L(A) = $ 使缓冲区变满的操作序列集合:
- 解读: 这个DFA的目的是识别所有那些执行完之后、能让缓冲区恰好处于满(即含有3个项目)状态的操作序列。
- 换句话说: 一个字符串 $w$ 在语言 $L(A)$ 中,当且仅当 $w$ 中 ins 的数量减去 del 的数量(考虑到边界条件)最终等于3。
- 属于 L(A) 的字符串:
- ins ins ins: $0 \to 1 \to 2 \to 3$。最终在3,接受。
- ins ins ins ins: $0 \to 1 \to 2 \to 3 \to 3$。最终在3,接受。
- del ins ins ins: $0 \to 0 \to 1 \to 2 \to 3$。最终在3,接受。
- 不属于 L(A) 的字符串:
- ins del: $0 \to 1 \to 0$。最终在0,拒绝。
- ins ins: $0 \to 1 \to 2$。最终在2,拒绝。
- ε: $0$。最终在0,拒绝。
- 路径 vs. 语言: 路径是DFA处理一个特定字符串的过程。语言是DFA能接受的所有字符串的集合。不要混淆过程和结果集合。
- 语言的描述: “使缓冲区变满的操作序列集合”是一个非形式化的、便于人类理解的描述。形式化的语言定义是 $L(A) = \{ w \in \{\text{ins, del}\}^* \mid \text{DFA A在输入w后停在状态3} \}$。
这个综合示例完整地走了一遍DFA的核心流程:给定一个DFA(以转移图形式),模拟它处理一个具体输入字符串的过程,得出接受/拒绝的结论,并最终概括出这个DFA所识别的语言的性质。
这个例子的目的是巩固本章所有新引入的概念,将DFA的静态定义(图、表、五元组)、动态计算过程和最终目标(语言识别)有机地结合在一起,帮助学生形成一个完整、连贯的知识体系。
[直觉心-智模型]
这就像是做一道完整的数学应用题。
- 题目给出: 一个系统模型(DFA图)。
- 第一问: 给定一个具体场景(输入字符串 ins...),模拟系统的行为,并给出最终结果(在状态3,接受)。
- 第二问: 总结这个系统在何种情况下会达到“成功”状态(概括出语言 $L(A)$ 的特征)。
想象你在玩一个电子游戏,目标是把一个水箱(容量3升)灌满。
- 操作: ins (倒一升水进去),del (舀一升水出来)。
- 游戏规则: 水箱满了不能再倒,空了不能再舀。
- 输入: ins, ins, ins, del, ins
- 游戏过程: 水位从0升 $\to$ 1升 $\to$ 2升 $\to$ 3升 (满了) $\to$ 2升 $\to$ 3升 (又满了)。
- 游戏结束: 指令执行完,水位是3升。屏幕上显示“成功!”(接受)。
- 这个游戏的“攻略集”: 所有能让你在游戏结束时水箱正好是满的的操作序列,就是这个DFA的语言。
8行间公式索引
- k-槽缓冲区自动机的符号定义:
这个公式使用数学五元组的形式,精确且通用地定义了一个容量为k的缓冲区的确定性有限自动机模型。
17.6. 综合示例
📜 [原文25]
inputstring: ins ins ins del ins
path: $0 \longrightarrow 1 \longrightarrow 2 \longrightarrow 3 \longrightarrow 2 \longrightarrow 3$
- 这个自动机的语言:
$L(A)=$ 使缓冲区变满的操作序列集合
这部分通过一个完整的例子,将前面介绍的3槽缓冲区DFA、输入处理和语言定义串联起来。
- DFA回顾:
- 这是k=3时的缓冲区自动机。
- $Q=\{0, 1, 2, 3\}$, $\Sigma=\{\text{ins, del}\}$, $q_0=0$, $F=\{3\}$。
- 接受状态是3,代表缓冲区的“满”状态。
- 处理输入字符串:
- 输入: ins ins ins del ins
- 路径 (Path): 演示了DFA如何一步步处理这个输入。
- 开始: 状态 0
- 读 'ins': $0 \to 1$ (从状态0,$\delta(0, \text{ins})=1$)
- 读 'ins': $1 \to 2$ (从状态1,$\delta(1, \text{ins})=2$)
- 读 'ins': $2 \to 3$ (从状态2,$\delta(2, \text{ins})=3$)
- 读 'del': $3 \to 2$ (从状态3,$\delta(3, \text{del})=2$)
- 读 'ins': $2 \to 3$ (从状态2,$\delta(2, \text{ins})=3$)
- 结束: 字符串读取完毕,最终状态是 3。
- 判断: 最终状态 3 是否在接受状态集 $F=\{3\}$ 中?是的。
- 结论: 字符串 ins ins ins del ins 被这个DFA接受。
- 自动机的语言 (Language of the Automaton):
- $L(A) = $ 使缓冲区变满的操作序列集合:
- 解读: 这个DFA的目的是识别所有那些执行完之后、能让缓冲区恰好处于满(即含有3个项目)状态的操作序列。
- 换句话说: 一个字符串 $w$ 在语言 $L(A)$ 中,当且仅当 $w$ 中 ins 的数量减去 del 的数量(考虑到边界条件)最终等于3。
- 属于 L(A) 的字符串:
- ins ins ins: $0 \to 1 \to 2 \to 3$。最终在3,接受。
- ins ins ins ins: $0 \to 1 \to 2 \to 3 \to 3$。最终在3,接受。
- del ins ins ins: $0 \to 0 \to 1 \to 2 \to 3$。最终在3,接受。
- 不属于 L(A) 的字符串:
- ins del: $0 \to 1 \to 0$。最终在0,拒绝。
- ins ins: $0 \to 1 \to 2$。最终在2,拒绝。
- ε: $0$。最终在0,拒绝。
- 路径 vs. 语言: 路径是DFA处理一个特定字符串的过程。语言是DFA能接受的所有字符串的集合。不要混淆过程和结果集合。
- 语言的描述: “使缓冲区变满的操作序列集合”是一个非形式化的、便于人类理解的描述。形式化的语言定义是 $L(A) = \{ w \in \{\text{ins, del}\}^* \mid \text{DFA A在输入w后停在状态3} \}$。
这个综合示例完整地走了一遍DFA的核心流程:给定一个DFA(以转移图形式),模拟它处理一个具体输入字符串的过程,得出接受/拒绝的结论,并最终概括出这个DFA所识别的语言的性质。
这个例子的目的是巩固本章所有新引入的概念,将DFA的静态定义(图、表、五元组)、动态计算过程和最终目标(语言识别)有机地结合在一起,帮助学生形成一个完整、连贯的知识体系。
[直觉心-智模型]
这就像是做一道完整的数学应用题。
- 题目给出: 一个系统模型(DFA图)。
- 第一问: 给定一个具体场景(输入字符串 ins...),模拟系统的行为,并给出最终结果(在状态3,接受)。
- 第二问: 总结这个系统在何种情况下会达到“成功”状态(概括出语言 $L(A)$ 的特征)。
想象你在玩一个电子游戏,目标是把一个水箱(容量3升)灌满。
- 操作: ins (倒一升水进去),del (舀一升水出来)。
- 游戏规则: 水箱满了不能再倒,空了不能再舀。
- 输入: ins, ins, ins, del, ins
- 游戏过程: 水位从0升 $\to$ 1升 $\to$ 2升 $\to$ 3升 (满了) $\to$ 2升 $\to$ 3升 (又满了)。
- 游戏结束: 指令执行完,水位是3升。屏幕上显示“成功!”(接受)。
- 这个游戏的“攻略集”: 所有能让你在游戏结束时水箱正好是满的的操作序列,就是这个DFA的语言。
9行间公式索引
- k-槽缓冲区自动机的符号定义:
这个公式使用数学五元组的形式,精确且通用地定义了一个容量为k的缓冲区的确定性有限自动机模型。
[[END_OF_RESPONSE]]所有解释内容已全部输出完毕。