11. 2.4 确定性上下文无关语言
📜 [原文1]
回想一下,确定性有限自动机和非确定性有限自动机在语言识别能力上是等价的。相比之下,非确定性下推自动机比它们的确定性对应物更强大。我们将证明某些上下文无关语言不能被确定性下推自动机 (DPDA) 识别——这些语言需要非确定性下推自动机。能够被确定性下推自动机 (DPDA) 识别的语言称为确定性上下文无关语言 (DCFL)。这个上下文无关语言的子类与实际应用相关,例如编程语言编译器中解析器的设计,因为对于 DCFL 而言,解析问题通常比对于 CFL 而言更容易。本节简要概述了这个重要而优美的主题。
这段引言为我们即将学习的确定性上下文无关语言(Deterministic Context-Free Language, DCFL)搭建了舞台。它通过对比我们已经熟悉的自动机模型,引出了核心概念。
首先,它让我们回忆有限自动机(Finite Automata, FA)的世界。在有限自动机中,无论是确定性有限自动机(Deterministic Finite Automaton, DFA)还是非确定性有限自动机(Nondeterministic Finite Automaton, NFA),它们识别语言的能力是完全相同的。这意味着任何一个NFA能够识别的语言(即正则语言),我们总能构造出一个等价的DFA来识别它,反之亦然。这个“等价性”是计算理论中的一个基础且重要的结论。
接着,文章话锋一转,进入了下推自动机(Pushdown Automata, PDA)的领域。这里情况发生了根本性的变化。与有限自动机不同,非确定性下推自动机(Nondeterministic Pushdown Automaton, NPDA)的能力要比确定性下推自动机(Deterministic Pushdown Automaton, DPDA)更强。这构成了本节的核心论点。所谓“更强”,指的是存在一些语言,我们可以构造出NPDA来识别它们,但无论如何都无法设计出一个DPDA来完成同样的任务。这些语言就是非确定性的“专属领域”。
这就自然引出了本节的主角:那些可以被确定性下推自动机识别的语言。这类语言被赋予了一个专门的名字——确定性上下文无关语言(DCFL)。从这个定义我们可以立即得出一个结论:DCFL的集合是上下文无关语言(Context-Free Language, CFL)集合的一个子集。因为所有的CFL都能被NPDA识别,而只有一部分能被DPDA识别。
最后,文章点明了研究DCFL的实践意义。为什么我们要关心这个能力“较弱”的子类呢?因为它在现实世界中,尤其是在计算机科学的核心领域——编译器设计中,扮演着至关重要的角色。编程语言(如C++, Java, Python)的语法结构,大部分都可以被设计成DCFL。这么做的好处是,为DCFL构建解析器(Parser,编译器中负责语法分析的部分)要比为一般的CFL构建解析器“更容易”。这里的“更容易”不仅指设计上的简洁,更关键的是指解析的效率。确定性的解析算法通常比非确定性的快得多(例如,线性时间复杂度 vs 立方时间复杂度),这对于需要快速编译大量代码的现代软件开发来说是不可或缺的。
所以,本节的目标就是探索这个“更受限制”但“更实用”的CFL子类,理解它的定义、性质以及它与非确定性世界的边界。
- 示例1:FA中确定性与非确定性的等价
- 语言: 所有以 "01" 结尾的二进制字符串。这是一个正则语言。
- NFA: 我们可以设计一个简单的3状态NFA。状态 $q_0$ 是开始状态,看到任意0或1都停留在 $q_0$。同时,从 $q_0$ 看到0可以“猜测”这是结尾的开始,跳转到 $q_1$。在 $q_1$ 看到1,跳转到接受状态 $q_2$。这个NFA是非确定性的,因为在 $q_0$ 看到0时,它有两个选择:留在 $q_0$ 或跳到 $q_1$。
- DFA: 我们可以通过子集构造法将上述NFA转换为一个DFA。这个DFA会有更多的状态,但它的每一步都是确定的。例如,它的一个状态可能是 $\{q_0, q_1\}$,表示NFA可能处于这两个状态中的任意一个。对于任何输入,这个DFA都能明确地转移到下一个状态。最终,我们能构造一个识别相同语言的DFA。这体现了它们能力的等价性。
- 示例2:PDA中确定性与非确定性的能力差异
- 语言: 回文语言 $L_{pal} = \{ w w^R \mid w \in \{0, 1\}^* \}$,其中 $w^R$ 是 $w$ 的反串。例如 "0110", "101", "" 都在这个语言里。这是一个非确定性上下文无关语言。
- NPDA: 我们可以设计一个NPDA来识别它。基本思路是:读取输入的前半部分 $w$,并将其压入栈。然后,“非确定性地猜测”已经到达了字符串的中心点。之后,开始读取输入的后半部分 $w^R$,每读取一个字符,就与栈顶字符进行匹配,如果匹配成功就弹出栈顶。如果在读取完整个字符串后,栈恰好变空,则接受该字符串。这里的关键在于“猜测中心点”这一步,这是纯粹的非确定性行为。
- DPDA的困境: 如果我们试图设计一个DPDA,它会遇到一个无法解决的难题。当它读取字符串时,比如 "0110",它无法确定性地知道 "11" 是字符串的中心。它不知道应该在什么时候从“压栈”模式切换到“弹栈匹配”模式。如果它在第二个 "1" 之后切换,对于 "0110" 是正确的;但如果输入是 "01010",它就应该在第三个 "0" 之后切换。由于没有明确的标记来指示中心位置,DPDA无法做出唯一的、正确的决定。因此,这个语言不能被DPDA识别,证明了NPDA比DPDA更强大。
- 混淆“更强大”的含义: “NPDA比DPDA更强大”不是指NPDA计算得更快或更有效率,而是指它能识别的语言集合更大。事实上,由于非确定性的存在,模拟一个NPDA通常比运行一个DPDA要慢得多。
- 对“等价”的误解: 在FA的世界里,DFA和NFA的“等价”是识别能力的等价,不代表它们的结构或状态数相同。一个NFA对应的等价DFA可能状态数呈指数级增长。
- 认为所有CFL都是非确定性的: 这是一个常见的误区。DCFL本身就是CFL的一部分。例如,语言 $L = \{0^n 1^n \mid n \ge 0\}$ 既是CFL,也是DCFL,因为我们可以很容易地设计一个DPDA来识别它(先数0并压栈,然后数1并弹栈)。只有那些“本质上”需要猜测的CFL才不是DCFL。
本段是引言,通过对比有限自动机和下推自动机的确定性与非确定性版本,阐明了两者在能力上的一个核心差异:DFA与NFA等价,但DPDA比NPDA弱。基于这个差异,定义了确定性上下文无关语言 (DCFL)为可被DPDA识别的语言类,并指出DCFL是CFL的一个真子集。最后,强调了DCFL在编译器解析器设计中的重要实际应用价值,因其解析过程更高效。
本段的目的是建立学习DCFL的动机和背景。它回答了“我们为什么要单独学习一个更弱的模型?”这个问题。通过以下几点实现目的:
- 建立对比: 将新知识(PDA的能力差异)与旧知识(FA的能力等价)进行对比,突出新知识的特殊性。
- 引出定义: 逻辑地从“DPDA识别的语言”引出“DCFL”这个核心术语。
- 赋予意义: 解释了DCFL虽然在理论模型上能力受限,但在实际应用(如编译器)中具有巨大的优势,从而证明了学习它的必要性。
想象一个岔路口:
- DFA/DPDA (确定性): 你来到一个路口,只有一个路牌明确指向你的下一个目的地。你别无选择,只能跟着路牌走。你的路线是唯一确定的。
- NFA/NPDA (非确定性): 你来到一个路口,面前有多条路。你有一个神奇的能力,可以同时派出无数个分身,每个分身走一条路。只要其中任何一个分身最终到达了目的地,就算你成功了。
本段的核心思想是:对于有限自动机(在平地上行走),有没有分身能力最终能到达的地方是一样的。但对于下推自动机(背着一个只能操作顶部的背包/栈行走),拥有分身能力可以让你探索到一些单打独斗无法到达的地方。
想象你在解一个迷宫。
- DFA: 这是一个非常简单的迷宫,每个岔路口都有一个箭头告诉你该往哪走。你只要跟着箭头,就能确定地走出迷宫或判定走不出去。
- NFA: 迷宫的某些岔路口没有箭头,或者有多个箭头。你被允许在这些路口“分身”,同时探索所有可能的路径。
- PDA: 现在,迷宫的规则变复杂了。你背着一个栈(像一摞盘子)。某些墙上写着“如果你栈顶是红色盘子,你可以推开这堵墙,并把一个蓝色盘子放到栈顶”。
- NPDA vs DPDA: DPDA的迷宫里,每种情况(你在哪里,墙上写什么,你栈顶盘子颜色)最多只有一条路可走。而NPDA的迷宫里,某些情况下可能有多条路供你选择(例如,“你可以推开A墙并放个蓝盘子”或者“你可以推开B墙并放个绿盘子”)。本段告诉我们,存在一些特别设计的“背包迷宫”,只有允许你“分身”探索(NPDA),才能找到出口。而那些不需要分身能力就能解的迷宫,其路径解法对应于DCFL。
22. DPDA的定义
📜 [原文2]
在定义 DPDA 时,我们遵循确定性的基本原则:在计算的每一步,DPDA 根据其转移函数最多只有一种方式可以进行。定义 DPDA 比定义 DFA 更复杂,因为 DPDA 可以在不弹出栈符号的情况下读取输入符号,反之亦然。因此,我们允许 DPDA 的转移函数中包含 $\varepsilon$ 移动,尽管 DFA 中禁止 $\varepsilon$ 移动。这些 $\varepsilon$ 移动有两种形式:对应于 $\delta(q, \boldsymbol{\varepsilon}, x)$ 的 $\boldsymbol{\varepsilon}$ 输入移动,以及对应于 $\delta(q, a, \boldsymbol{\varepsilon})$ 的 $\boldsymbol{\varepsilon}$ 栈移动。一个移动可能结合这两种形式,对应于 $\delta(q, \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon})$。如果一个 DPDA 在特定情况下可以进行 $\varepsilon$ 移动,则它被禁止在该相同情况下进行涉及处理符号而不是 $\varepsilon$ 的移动。否则可能会出现多个有效的计算分支,导致非确定性行为。形式化定义如下。
这段内容详细阐述了定义确定性下推自动机 (DPDA)时的核心思想和挑战。
核心原则非常明确:确定性。这意味着在自动机运行的任何时刻,给定当前的状态、下一个输入符号以及栈顶的符号,自动机最多只有一条唯一的路径可以走。它不能有“选择困难症”。
挑战在于,下推自动机 (PDA) 的操作比有限自动机 (DFA) 复杂得多。一个DFA的转移只依赖于当前状态和当前输入符号。而一个PDA的转移依赖三样东西:当前状态、当前输入符号、栈顶符号。更复杂的是,输入符号和栈顶符号都可以是“空的”,即 $\varepsilon$。
这就引出了所谓的 “$\varepsilon$ 移动”。在DFA中,我们通常不允许 $\varepsilon$ 移动(或者说,带 $\varepsilon$ 移动的NFA需要转换成DFA)。但在DPDA中,为了模型的灵活性和表达能力,我们必须允许 $\varepsilon$ 移动。文章将这些 $\varepsilon$ 移动分为几种情况:
- $\delta(q, \varepsilon, x)$: $\varepsilon$ 输入移动。这意味着自动机不消耗任何输入符号,但它会查看并消耗栈顶的符号 $x$,然后进行状态转移和栈操作。这就像自动机“停下来思考一下”,根据栈里的东西做点内部整理,然后再去看输入。
- $\delta(q, a, \varepsilon)$: $\varepsilon$ 栈移动。这意味着自动机消耗一个输入符号 $a$,但它不关心栈顶是什么,也不消耗栈顶符号。这在PDA的定义里比较少见,通常PDA的转移至少要查看栈顶。但这里的 $\varepsilon$ 意味着“栈为空”或者“不依赖栈顶符号”。更准确地说,是“不弹出任何东西”的移动。
- $\delta(q, \varepsilon, \varepsilon)$: 纯粹的内部状态转移。不消耗输入,也不依赖或消耗栈顶符号,仅仅进行状态转换和可能的压栈操作。
那么,如何在允许这些灵活的 $\varepsilon$ 移动的同时,又保证确定性呢?这就是定义中最关键的约束:
“如果一个 DPDA 在特定情况下可以进行 $\varepsilon$ 移动,则它被禁止在该相同情况下进行涉及处理符号而不是 $\varepsilon$ 的移动。”
这句话是理解DPDA确定性的关键。让我们把它拆解开:
假设自动机当前处于状态 $q$,下一个输入是 $a$,栈顶是 $x$。
- 如果存在一个“正常”的转移 $\delta(q, a, x)$,即消耗输入 $a$ 和栈顶 $x$,那么就不能再有任何其他选择。例如,不能同时存在一个 $\delta(q, \varepsilon, x)$ 的转移(不消耗输入 $a$),因为这样机器就面临选择了:是消耗 $a$ 走这条路,还是不消耗 $a$ 走另一条路?这就是非确定性。
- 同理,如果存在一个 $\delta(q, a, x)$,就不能同时存在 $\delta(q, a, \varepsilon)$,因为这会让机器在“看栈顶”和“不看栈顶”之间产生选择。
- 更普遍地说,对于任何一个确定的三元组(状态,输入,栈顶),$\delta$ 函数的输出必须是唯一的。这里的“输入”可以是真实符号 $a$ 或 $\varepsilon$,“栈顶”可以是真实符号 $x$ 或 $\varepsilon$(表示栈空或不关心栈)。为了保证唯一性,DPDA的定义要求,对于一个状态 $q$,如果有一个基于 $\varepsilon$ 的转移(比如 $\delta(q, \varepsilon, x)$),那么就不能有任何基于真实输入符号的转移(比如 $\delta(q, a, x)$)。
这个约束有效地消除了所有可能的非确定性来源,确保了DPDA在每一步都“行为良好”,只有一条路可走。
- 示例1:一个合法的DPDA转移规则
- 状态: $q_1$
- 输入符号: '0'
- 栈顶符号: 'Z'
- 规则集:
- $\delta(q_1, '0', 'Z') = (q_2, 'A'Z)$ (读取'0',弹出'Z',压入'A'再压入'Z',进入$q_2$)
- $\delta(q_1, \varepsilon, 'B') = (q_3, \varepsilon)$ (不读输入,如果栈顶是'B',弹出'B',进入$q_3$)
- 分析: 这组规则是确定性的。当处于 $q_1$,输入为'0',栈顶为'Z'时,只有第一条规则适用,路径唯一。当处于 $q_1$,栈顶为'B'时,无论输入是什么,只有第二条规则适用(因为它不消耗输入)。这两条规则的触发条件(输入和栈顶的组合)是互斥的,不会产生冲突。
- 示例2:一个非法的(非确定性的)PDA转移规则集
- 状态: $q_{confused}$
- 输入符号: 'a'
- 栈顶符号: 'X'
- 规则集:
- 规则A: $\delta(q_{confused}, 'a', 'X') = (q_{path1}, 'Y')$ (读取'a',弹出'X',压入'Y')
- 规则B: $\delta(q_{confused}, \varepsilon, 'X') = (q_{path2}, 'Z')$ (不读输入,弹出'X',压入'Z')
- 分析: 这个规则集是非确定性的,因此不属于DPDA。当自动机处于状态 $q_{confused}$,下一个输入是 'a',栈顶是 'X' 时,它面临一个选择:
- 执行规则A:消耗 'a' 和 'X',进入 $q_{path1}$。
- 执行规则B:不消耗 'a',只消耗 'X',进入 $q_{path2}$。
- 由于存在两个可能的、合法的计算分支,这违反了确定性原则。一个DPDA的定义会禁止这样的规则集同时存在。
- 对 $\varepsilon$ 移动的误解: $\varepsilon$ 移动在DPDA中是允许的,甚至是必要的,但必须受到严格的限制。不是说有 $\varepsilon$ 移动就是非确定性的。关键在于是否存在选择。
- 忽略组合: 确定性的约束是针对“组合”的。例如,$\delta(q, a, x)$ 和 $\delta(q, b, x)$ 可以同时存在,因为它们的触发条件(输入符号 $a$ vs $b$)不同。冲突只发生在当一个“具体”转移(如 $\delta(q, a, x)$)和一个“通用”或“$\varepsilon$”转移(如 $\delta(q, \varepsilon, x)$ 或 $\delta(q, a, \varepsilon)$)可以同时被触发时。
- 栈空的情况: 当栈为空时,任何需要弹出非 $\varepsilon$ 符号的转移(如 $\delta(q, a, x)$)都无法执行。此时,只有形如 $\delta(q, a, \varepsilon)$ 或 $\delta(q, \varepsilon, \varepsilon)$ 的转移才可能发生。这也是确定性约束需要考虑的一部分。
本段解释了定义确定性下推自动机 (DPDA)的关键约束。其核心是严格维护确定性原则,即在任何时刻,机器的下一步行动必须是唯一的。由于PDA的转移依赖于状态、输入和栈顶这三个因素,并且输入和栈操作都可能涉及 $\varepsilon$,这使得定义比DFA复杂。为了解决这个问题,DPDA的定义引入了一条核心规则:如果一个状态存在基于 $\varepsilon$ 的转移(无论是 $\varepsilon$ 输入还是 $\varepsilon$ 栈操作),那么就不能存在与之冲突的、基于具体符号的转移。这条规则从根本上杜绝了非确定性选择的出现。
本段的目的是在给出DPDA的形式化定义之前,建立一个清晰、直观的理解。它预先解决了读者可能会有的最大困惑:“如何在允许灵活的 $\varepsilon$ 移动的同时保持确定性?”。通过详细解释约束条件背后的逻辑,为接下来更为抽象的形式化定义铺平了道路,使得读者能够更好地理解定义中每一条规则的必要性。
想象一个非常守规矩的机器人。它的操作手册(转移函数)写得非常精确,绝无歧义。
- 手册上的一条指令可能是:“当你站在A点(状态),看到红色信号灯(输入),且你左手拿着一个苹果(栈顶),你必须向前走一步,并把苹果换成香蕉(状态转移和栈操作)。”
- 另一条指令可能是:“当你站在A点,且左手拿着一个橘子,无论信号灯是什么颜色($\varepsilon$ 输入),你都必须原地跳一下,并把橘子扔掉。”
- 确定性约束就意味着,手册上绝不会同时出现两条让你困惑的指令。比如,不会有:“当你站在A点,看到红色信号灯,左手拿着苹果时,你可以向前走一步” 和 “当你站在A点,左手拿着苹果时,你可以原地跳一下”。这两条指令在“站在A点,左手拿苹果,看到红灯”的情况下都适用,机器人就会“死机”,因为它不知道该听哪条。DPDA的定义就是为了确保这种“死机”情况不会发生。
想象你在一个自动化工厂里操作一台机器。
- DFA: 机器上只有一个按钮,每次来一个零件,你按一下按钮,机器自动处理,然后等待下一个零件。
- PDA: 机器变得复杂了。它有一个传送带(输入),还有一个垂直的零件堆放架(栈),你只能操作最上面的零件。现在机器上有好几个按钮。
- DPDA的确定性: 控制面板的设计非常精妙。在任何时刻,根据传送带上来的零件型号,以及堆放架顶部是什么零件,最多只有一个按钮会亮起,告诉你“按我”。你永远不需要做选择。可能在某种情况下,一个“紧急处理”按钮会亮起($\varepsilon$ 移动),它让你暂停传送带,先处理堆放架上的零件。但一旦这个“紧急处理”按钮有可能亮起,那么针对该情况的“常规处理”按钮(需要传送带零件的那个)就一定是被设计成锁死的,不会亮。这种设计保证了操作的唯一性。
33. 定义 2.39
📜 [原文3]
一个确定性下推自动机是一个 6 元组 ( $Q, \Sigma, \Gamma, \delta, q_{0}, F$ ),其中 $Q, \Sigma, \Gamma$ 和 $F$ 都是有限集,且
- $Q$ 是状态集,
- $\Sigma$ 是输入字母表,
- $\Gamma$ 是栈字母表,
- $\delta: Q \times \Sigma_{\varepsilon} \times \Gamma_{\varepsilon} \longrightarrow\left(Q \times \Gamma_{\varepsilon}\right) \cup\{\emptyset\}$ 是转移函数,
- $q_{0} \in Q$ 是开始状态,且
- $F \subseteq Q$ 是接受状态集。
转移函数 $\delta$ 必须满足以下条件。对于每个 $q \in Q, a \in \Sigma$, 和 $x \in \Gamma$, 以下值中只有一个不为 $\emptyset$:
这是确定性下推自动机 (DPDA)的严格数学定义。我们来逐项拆解。
一个DPDA被定义为一个包含六个元素的集合,称为6元组。这六个元素共同描述了DPDA的全部结构和行为。
- $Q$ (状态集): 这是一个有限的集合,包含了自动机所有可能的状态。你可以把它想象成机器内部所有可能的“模式”或“记忆”。例如,一个用于识别 $\{0^n 1^n\}$ 的DPDA可能有一个“正在读取0”的状态和一个“正在读取1”的状态。
- $\Sigma$ (输入字母表): 这是一个有限的集合,包含了所有允许出现在输入字符串中的符号(字符)。例如,对于二进制字符串,$\Sigma = \{0, 1\}$。
- $\Gamma$ (栈字母表): 这是一个有限的集合,包含了所有可以被压入栈中的符号。栈字母表可以和输入字母表有交集,也可以包含一些特殊的辅助符号。例如,在识别 $\{0^n 1^n\}$ 时,我们可能会用符号 'X' 来代表一个 '0' 被压入栈,或者用一个特殊的初始栈符号 '$' 来标记栈底。所以 $\Gamma$ 可能是 $\{X, \$\}$。
- $\delta$ (转移函数): 这是DPDA定义的核心,也是它与NPDA区别的所在。它描述了机器如何从一个配置转移到下一个配置。我们来详细分析它的定义:
- 输入: $\delta$ 的输入是一个三元组 $(q, s, \gamma)$,其中 $q \in Q$ (当前状态),$s \in \Sigma_{\varepsilon}$ (当前输入符号或 $\varepsilon$),$\gamma \in \Gamma_{\varepsilon}$ (当前栈顶符号或 $\varepsilon$)。这里的下标 $\varepsilon$ 表示集合包含了空符号 $\varepsilon$。例如,$\Sigma_{\varepsilon} = \Sigma \cup \{\varepsilon\}$。
- 输出: $\delta$ 的输出要么是一个二元组 $(r, \omega)$,其中 $r \in Q$ (下一个状态),$\omega \in \Gamma_{\varepsilon}$ (要压入栈的字符串);要么是 $\emptyset$ (空集符号),表示在这种情况下没有定义转移,机器会“卡住”。
- 映射关系: $\delta: Q \times \Sigma_{\varepsilon} \times \Gamma_{\varepsilon} \longrightarrow\left(Q \times \Gamma_{\varepsilon}\right) \cup\{\emptyset\}$ 的意思是,$\delta$ 函数将一个(状态、输入、栈符号)的组合映射到一个(新状态、压栈字符串)的组合,或者映射到“无路可走”($\emptyset$)。注意这里的输出是一个单元素集合或者空集,这正是确定性的体现——最多只有一个结果。而在NPDA中,输出会是一个包含零个或多个可能转移的集合。
- $q_0 \in Q$ (开始状态): 这是机器在处理任何输入之前所处的初始状态。
- $F \subseteq Q$ (接受状态集): 这是一个状态的子集。如果在读取完所有输入后,机器恰好停在这些状态中的任何一个,那么输入字符串就被“接受”。
关键的确定性条件:
定义中最核心的部分是对转移函数 $\delta$ 的附加约束。这个约束用数学语言精确地描述了我们在上一节讨论的“无歧义”原则。
“对于每个 $q \in Q, a \in \Sigma$, 和 $x \in \Gamma$, 以下值中只有一个不为 $\emptyset$”
这句话需要仔细解读。它考虑了一个具体的、非空的情境:机器处于状态 $q$,下一个输入是 $a$,栈顶是 $x$。在这种情况下,机器可能有哪些选择呢?
- $\delta(q, a, x)$: 消耗输入 $a$ 和栈顶 $x$。
- $\delta(q, a, \varepsilon)$: 消耗输入 $a$,但不消耗栈顶 $x$ (或者说,栈是空的)。
- $\delta(q, \varepsilon, x)$: 不消耗输入 $a$,但消耗栈顶 $x$。
- $\delta(q, \varepsilon, \varepsilon)$: 既不消耗输入 $a$,也不消耗栈顶 $x$。
确定性要求是,在任何一个具体的情境下,这四种可能的操作中,最多只能有一个是有效的(即其结果不是 $\emptyset$)。
让我们看看这个条件如何防止非确定性:
- 如果 $\delta(q, a, x)$ 有定义(不为 $\emptyset$),那么 $\delta(q, \varepsilon, x)$ 就必须是 $\emptyset$。否则,当输入是 $a$ 且栈顶是 $x$ 时,机器就会面临“消耗 $a$”还是“不消耗 $a$”的选择。
- 如果 $\delta(q, a, x)$ 有定义,那么 $\delta(q, a, \varepsilon)$ 就必须是 $\emptyset$。否则,机器会面临“消耗栈顶 $x$”还是“不消耗栈顶”的选择。
- 这个约束覆盖了所有潜在的冲突,确保了对于任何给定的(状态,输入,栈)配置,机器的下一步动作是唯一预定的。
- 6元组 $(Q, \Sigma, \Gamma, \delta, q_0, F)$
- $Q$: State set (状态集). A finite set of states.
- $\Sigma$: Input alphabet (输入字母表). A finite set of allowed input symbols.
- $\Gamma$: Stack alphabet (栈字母表). A finite set of symbols that can be pushed onto the stack.
- $\delta$: Transition function (转移函数). The rulebook of the automaton.
- $q_0$: Start state (开始状态). The initial state, $q_0 \in Q$.
- $F$: Set of accept states (接受状态集). A subset of $Q$, $F \subseteq Q$.
- 转移函数 $\delta: Q \times \Sigma_{\varepsilon} \times \Gamma_{\varepsilon} \longrightarrow\left(Q \times \Gamma_{\varepsilon}\right) \cup\{\emptyset\}$
- $Q \times \Sigma_{\varepsilon} \times \Gamma_{\varepsilon}$: 这是函数的定义域 (domain)。它表示函数接受的输入是一个三元组,由一个状态、一个输入符号(或 $\varepsilon$)、一个栈符号(或 $\varepsilon$)组成。
- $\left(Q \times \Gamma_{\varepsilon}\right) \cup\{\emptyset\}$: 这是函数的值域 (range)。它表示函数的输出。
- $Q \times \Gamma_{\varepsilon}$: 一个二元组,代表(下一个状态,要压入栈的字符串)。注意在原文中,这个二元组被包装在一个单元素集合中来强调确定性,但这里为了简化,我们直接看这个元组。
- $\{\emptyset\}$: 空集,表示没有合法的转移。
- 这个定义在技术上与某些教科书略有不同,有些会将输出定义为 $P(Q \times \Gamma^*)$ 的一个子集,该子集的大小最多为1。这里的写法 $\left(Q \times \Gamma_{\varepsilon}\right) \cup\{\emptyset\}$ 是一种等价且更直观的表达确定性的方式。
- 确定性条件
- 条件: For every $q \in Q, a \in \Sigma, x \in \Gamma$, at most one of the above can be non-$\emptyset$.
- 推导: 这个条件是DPDA定义的核心。它不是一个可以从其他地方推导出来的公式,而是定义本身的一部分,是确保“确定性”的公理。它强制规定了在任何一个非空的(即输入和栈都不为空)场景下,所有可能与之竞争的 $\varepsilon$ 移动都必须被禁用,从而保证了转移的唯一性。
假设我们正在设计一个DPDA来识别语言 $L = \{a^n b^n \mid n \ge 0\}$。
- $Q = \{q_0, q_1, q_2, q_{trap}\}$ (开始,读a,读b,陷阱)
- $\Sigma = \{a, b\}$
- $\Gamma = \{A, \$\}$ ($A$代表一个a, $\$$是栈底符号)
- $q_0$ 是开始状态
- $F = \{q_2\}$ (唯一的接受状态)
- 转移函数 $\delta$:
- $\delta(q_0, \varepsilon, \varepsilon) = (q_1, \$)$ (初始化,进入读a状态,压入栈底符)
- $\delta(q_1, a, \varepsilon) = (q_1, A)$ (读a时,压入一个A)
- $\delta(q_1, b, A) = (q_2, \varepsilon)$ (第一次读到b,必须有A可消,进入读b状态)
- $\delta(q_2, b, A) = (q_2, \varepsilon)$ (继续读b,消A)
- $\delta(q_2, \varepsilon, \$) = (q_2, \varepsilon)$ (输入结束,栈里只剩栈底,接受)
我们来检查确定性条件:
- 在状态 $q_1$,输入是 $a$ 时: 存在 $\delta(q_1, a, \varepsilon)$。那么,根据条件,$\delta(q_1, \varepsilon, \varepsilon)$, $\delta(q_1, a, A)$, $\delta(q_1, \varepsilon, A)$, $\delta(q_1, a, \$)$, $\delta(q_1, \varepsilon, \$)$ 等都必须是 $\emptyset$。在我们的设计中,确实如此。
- 在状态 $q_1$,输入是 $b$ 时: 存在 $\delta(q_1, b, A)$。那么,$\delta(q_1, \varepsilon, A)$, $\delta(q_1, b, \varepsilon)$ 等必须是 $\emptyset$。这也满足。
- 注意 $\delta(q_1, a, \varepsilon)$ 和 $\delta(q_1, b, A)$ 不冲突,因为它们的输入不同 ($a$ vs $b$) 或者栈顶要求不同 ($\varepsilon$ vs $A$)。
一个不满足条件的例子:
如果我们错误地添加一条规则 $\delta(q_1, \varepsilon, A) = (q_{trap}, A)$。现在,当机器在状态 $q_1$,输入是 $b$,栈顶是 $A$ 时,它有两个选择:
- 使用 $\delta(q_1, b, A) = (q_2, \varepsilon)$
- 使用 $\delta(q_1, \varepsilon, A) = (q_{trap}, A)$
这就产生了非确定性,所以这个修改后的自动机不再是DPDA。
- 对 $\Gamma_\varepsilon$ 的误解: 在 $\delta$ 的定义域中,$x \in \Gamma_\varepsilon$ 意味着自动机可以检查栈顶符号,或者在栈为空时行动(对应 $x=\varepsilon$)。
- 对 $\Gamma_\varepsilon$ 在值域中的误解: 在 $\delta$ 的值域中,$(r, y)$ 里的 $y \in \Gamma_\varepsilon$ 表示压入一个字符串 $y$。如果 $y=\varepsilon$,意思是什么都不压,等效于只做了一次弹出操作。如果 $y$ 是一个符号,例如 $A$,就是压入一个 $A$。
- 最右边的 $\varepsilon$: $\delta(q, \varepsilon, \varepsilon)$ 是一个非常特殊的转移。它只能在没有其他任何转移(包括读输入或看栈)可以进行时才能被定义,否则几乎肯定会引起冲突。它通常用于初始化或者在计算的确定性终点进行清理。
定义2.39给出了确定性下推自动机 (DPDA) 的形式化定义,它是一个六元组。其核心在于对转移函数 $\delta$ 的严格约束:对于任何一个确定的(状态、输入、栈顶)组合,最多只能有一个有效的转移规则。这个约束通过禁止在一个具体场景下,一个消耗具体符号的转移与一个消耗 $\varepsilon$ 的转移同时存在,从而在数学上根除了所有非确定性的来源,保证了DPDA的每一步计算路径都是唯一的。
本段的目的是提供一个精确、无歧义的数学框架来定义DPDA。形式化定义是计算机科学理论的基石,它使得我们能够:
- 精确交流: 避免自然语言的模糊性,确保所有研究者在讨论DPDA时指的是同一个数学对象。
- 严格证明: 基于这个定义,我们可以构建关于DCFL性质的数学证明,例如证明DCFL类在某些运算下是否封闭。
- 算法设计: 这个定义是设计和实现DPDA模拟器或基于DPDA的解析器的基础。
这个6元组定义就像是为一个机器人编写的“宪法”。
- $Q, \Sigma, \Gamma$: 定义了机器人的世界观(它能处于什么状态,能看懂什么输入,能使用什么工具)。
- $q_0, F$: 定义了它的“出厂设置”和“成功标准”。
- $\delta$ (转移函数): 这是机器人行为的“根本大法”。
- 确定性条件: 这是“大法”中的“第一修正案”,至关重要,它规定:“任何一条法则都不能与其他法则在适用条件上产生重叠或歧义,以确保机器人永远不会陷入逻辑悖论(选择困难)”。
想象你在组装一台乐高机器人,这份定义就是它的设计蓝图。
- $Q$: 蓝图上所有可能的主板模式(状态)。
- $\Sigma$: 机器人摄像头能识别的颜色卡片(输入)。
- $\Gamma$: 机器人机械臂能抓取的积木块类型(栈)。
- $q_0, F$: 机器人的开机默认模式和任务完成时会亮的绿灯模式。
- $\delta$: 这是最核心的电路板接线图。它规定了“当主板处于模式A,摄像头看到红色卡片,且机械臂抓着一块蓝色积木时,主板必须切换到模式B,并用一块黄色积木替换掉蓝色积木”。
- 确定性条件就是蓝图上的一条红色警告:“警告:对于任何一种情况(模式、卡片颜色、积木类型),接线图上绝对不允许有两条不同的线从同一点引出。必须保证电流(计算路径)只有一条路可走!”
44. DPDA的转移与接受
📜 [原文4]
转移函数可以输出形式为 $(r, y)$ 的单个移动,也可以通过输出 $\emptyset$ 表示没有动作。为了说明这些可能性,让我们考虑一个例子。假设一个 DPDA $M$ 带有转移函数 $\delta$,处于状态 $q$,其下一个输入符号是 $a$,并且其栈顶是符号 $x$。如果 $\delta(q, a, x)=(r, y)$,那么 $M$ 读取 $a$,将 $x$ 从栈中弹出,进入状态 $r$,并将 $y$ 压入栈中。或者,如果 $\delta(q, a, x)=\emptyset$,那么当 $M$ 处于状态 $q$ 时,它没有读取 $a$ 并弹出 $x$ 的移动。在这种情况下,$\delta$ 的条件要求 $\delta(q, \varepsilon, x), \delta(q, a, \varepsilon)$, 或 $\delta(q, \varepsilon, \varepsilon)$ 中的一个非空,然后 $M$ 相应地移动。该条件通过阻止 DPDA 在相同情况下采取两种不同的动作来强制确定性行为,例如如果 $\delta(q, a, x) \neq \emptyset$ 和 $\delta(q, a, \varepsilon) \neq \emptyset$ 都成立。当栈非空时,DPDA 在每种情况下都只有一个合法的移动。如果栈为空,DPDA 只有当转移函数指定一个弹出 $\varepsilon$ 的移动时才能移动。否则 DPDA 没有合法的移动,它会在不读取剩余输入的情况下拒绝。
这段文字是对DPDA如何工作的具体解释,它将形式化的定义翻译成了实际的操作步骤。
首先,它重申了转移函数 $\delta$ 的两种输出结果:
- 一个有效的移动: 形式为 $(r, y)$,表示转移到新状态 $r$,并用字符串 $y$ 替换栈顶符号。
- 没有动作: 输出 $\emptyset$,表示“此路不通”。
接着,通过一个生动的例子来描述一个典型的转移过程:
- 场景: 自动机 $M$ 当前在状态 $q$,输入磁带头指向符号 $a$,栈顶的符号是 $x$。
- 查找规则: $M$ 在其规则手册 $\delta$ 中查找对应于 $(q, a, x)$ 的指令。
- 情况一:找到规则: 假设查到 $\delta(q, a, x) = (r, y)$。这个指令告诉 $M$ 执行一系列动作:
- 读取 (消耗) 输入: 输入磁带头向右移动一格,越过 $a$。
- 弹出 (消耗) 栈顶: 栈顶的 $x$ 被移除。
- 进入新状态: 内部状态从 $q$ 变为 $r$。
- 压入新符号: 将字符串 $y$ 的符号逐个压入栈中。如果 $y = y_1y_2...y_k$,那么 $y_k$ 会先被压入,成为新的栈顶。如果 $y = \varepsilon$,则表示不压入任何东西。
- 情况二:未找到规则: 假设查到 $\delta(q, a, x) = \emptyset$。这意味着没有针对“读$a$并弹$x$”这个组合的直接指令。
- 此时,DPDA的确定性约束就发挥作用了。定义保证了,在这种情况下,机器必须去查找其他可能的 $\varepsilon$ 移动。具体来说,它会去检查 $\delta(q, \varepsilon, x)$, $\delta(q, a, \varepsilon)$ 或 $\delta(q, \varepsilon, \varepsilon)$。
- 根据确定性定义,这三者中最多只有一个是非空的。如果其中一个(比如 $\delta(q, \varepsilon, x)$)有定义,机器就会执行那个移动(不读输入,只操作栈)。
- 如果所有相关的转移(包括具体的和 $\varepsilon$ 的)都返回 $\emptyset$,那么机器就“卡住”了,无法继续进行。
这段解释进一步强调了确定性是如何通过禁止冲突来实现的。它明确指出,像 $\delta(q, a, x) \neq \emptyset$ 和 $\delta(q, a, \varepsilon) \neq \emptyset$ 这样的情况是不可能同时发生的。因为如果发生了,机器在状态 $q$ 看到输入 $a$ 时,就会困惑于“我应该关心栈顶的 $x$ 呢,还是不应该关心呢?”。
最后,它提到了两个重要的边界情况:
- 栈非空时: 只要栈不是空的,DPDA在任何情况下都只有一个合法的移动(如果有的话)。
- 栈为空时: 如果栈已经空了,任何需要弹出具体符号(非 $\varepsilon$)的转移都无法执行。此时,机器只能执行那些“弹出 $\varepsilon$”的转移,即形式为 $\delta(q, a, \varepsilon)$ 或 $\delta(q, \varepsilon, \varepsilon)$ 的转移。如果连这样的转移都没有定义,机器就会卡住,并且会拒绝输入,因为它没能读完整个字符串。
让我们继续使用识别 $L = \{a^n b^n \mid n \ge 1\}$ 的DPDA的例子,并追踪输入 "ab" 的处理过程。
- 初始配置: 状态 $q_0$, 输入 "ab", 栈 [ ] (空)
- Step 1:
- 当前: $q_0$, 输入 'a', 栈顶 $\varepsilon$。
- 查找: $\delta(q_0, a, \varepsilon)$? 未定义。$\delta(q_0, \varepsilon, \varepsilon)$? 也未定义。假设我们的DPDA启动时有一个初始化步骤 $\delta(q_{start}, \varepsilon, \varepsilon) = (q_0, \$)$。
- 新初始配置: 状态 $q_0$, 输入 "ab", 栈 [\$]。
- Step 2:
- 当前: $q_0$, 输入 'a', 栈顶 \$。
- 查找: 存在规则 $\delta(q_0, a, \varepsilon) = (q_0, A)$。但更具体的规则 $\delta(q_0, a, \$)$ 优先。假设我们定义 $\delta(q_0, a, \$)=(q_0, A\$)$。
- 动作: 消耗 'a',弹出 \$,压入 A\$。
- 新配置: 状态 $q_0$, 输入 "b", 栈 [A, \$]。
- Step 3:
- 当前: $q_0$, 输入 'b', 栈顶 A。
- 查找: 存在规则 $\delta(q_0, b, A) = (q_1, \varepsilon)$。这是唯一适用的规则。
- 动作: 消耗 'b',弹出 A。
- 新配置: 状态 $q_1$, 输入 "" (空), 栈 [\$]。
- Step 4:
- 当前: $q_1$, 输入 $\varepsilon$, 栈顶 \$。
- 查找: 假设有规则 $\delta(q_1, \varepsilon, \$) = (q_{accept}, \varepsilon)$。
- 动作: 不消耗输入,弹出 \$。
- 新配置: 状态 $q_{accept}$, 输入 "", 栈 [ ]。
- 结束: 输入已读完,且机器处于接受状态 $q_{accept}$。所以字符串 "ab" 被接受。
拒绝的例子: 输入 "a"
- ... 经过 Step 2后,配置为:状态 $q_0$, 输入 "" (空), 栈 [A, \$]。
- 当前: $q_0$, 输入 $\varepsilon$, 栈顶 A。
- 查找: 没有任何为 $(q_0, \varepsilon, A)$ 定义的转移。机器卡住了。
- 结果: 由于输入已读完,但机器不在接受状态(它卡在了 $q_0$),字符串 "a" 被拒绝。另一种可能是,如果输入没读完就卡住了,也算拒绝。
- 压栈顺序: 当转移函数指示压入一个字符串 $y = y_1y_2...y_k$ 时,压栈的顺序是 $y_k, y_{k-1}, ..., y_1$。这样,$y_1$ 就会成为新的栈顶。这是一个非常容易搞错的细节。
- 卡住即拒绝: DPDA只要在任何一步没有合法的转移可走,计算就会立即停止。如果此时输入还没有被完全读取,该输入字符串就被拒绝。
- $\varepsilon$ 循环: 一个设计不佳的DPDA可能会陷入一个无限的 $\varepsilon$ 移动循环中,例如 $\delta(q, \varepsilon, x) = (q, x)$。这种情况下,机器永远不会再读取新的输入,也无法正常结束。这种情况也等同于拒绝。
本段详细描述了DPDA的动态操作过程。它解释了转移函数的输出如何指导机器进行一系列原子操作:读输入、弹栈、状态转换和压栈。关键点在于,由于确定性的约束,在任何给定情况下,适用的转移规则最多只有一个。如果没有任何规则适用(包括所有可能的 $\varepsilon$ 变体),机器就会“卡住”。最后,文章明确了DPDA的接受和拒绝条件:接受发生在读完所有输入并停在接受状态;其他所有情况,如停在非接受状态、未能读完输入就卡住、或陷入无限循环,都视为拒绝。
本段的目的是将前一段静态、形式化的定义“激活”,赋予其生命。它通过一个操作实例和对各种情况的讨论,展示了DPDA作为一个计算模型的动态行为。这有助于读者从一个被动的定义理解者转变为一个能主动推演计算过程的思考者,为后续理解更复杂的DPDA构造和证明打下基础。
想象你在玩一个桌游,规则书就是转移函数 $\delta$。
- 你的棋子位置是状态 $q$。
- 你面前的事件卡片是输入 $a$。
- 你手里的特殊道具卡是栈顶 $x$。
- 游戏规则(确定性)保证了:对于任何(棋子位置,事件卡,道具卡)的组合,规则书上最多只有一条指令。
- 指令可能是:“移动你的棋子到Y格,丢弃这张事件卡和道具卡,并抽取一张新的Z道具卡。” (对应 $\delta(q, a, x) = (r, z)$)
- 如果针对你当前的情况没有任何指令,你就出局了(拒绝)。
- 如果你按指令走完了所有事件卡,并且棋子最终停在了“胜利”格子上(接受状态),你就赢了。
你是一个严谨的化学实验员。
- 状态: 你的实验进行到了第几步($q$)。
- 输入: 你要加入的下一种化学试剂($a$)。
- 栈: 你试管里最上层的液体($x$)。
- 转移函数: 你的实验手册。
- 确定性: 手册写得非常清晰,绝无歧义。例如:“步骤3时,若顶层液体为酸性,则加入5毫升A试剂”。手册里绝不会同时写“步骤3时,若顶层液体为酸性,也可以不加试剂,先摇晃10秒”。
- 操作: 你根据手册执行操作:加入试剂(读输入),可能消耗掉顶层液体(弹栈),然后试管状态改变,你进入实验的下一步(新状态和压栈)。
- 卡住/拒绝: 如果手册上说“加入B试剂”,但你的试剂架上没有B试剂,或者手册对于当前情况根本没写该怎么做,实验就失败了。
- 接受: 严格按照手册一步步做完,最后得到了预期的产物,并且实验记录显示你处于“已完成”状态。
55. DPDA的语言与示例
📜 [原文5]
DPDA 的接受方式与 PDA 相同。如果 DPDA 在读取完输入字符串的最后一个输入符号后进入一个接受状态,它就接受该字符串。在所有其他情况下,它拒绝该字符串。拒绝发生的情况是 DPDA 读取了整个输入,但在结束时没有进入接受状态,或者 DPDA 未能读取整个输入字符串。后一种情况可能出现,如果 DPDA 试图弹出空栈,或者如果 DPDA 进行了一系列无休止的 $\varepsilon$ 输入移动,而没有读取输入超过某一点。
DPDA 的语言称为确定性上下文无关语言。
示例 2.40
示例 2.14 中的语言 $\left\{0^{n} 1^{n} \mid n \geq 0\right\}$ 是一个 DCFL。我们可以通过为任何缺失的状态、输入符号和栈符号组合添加转移到一个不可能接受的“死”状态来轻松修改其 PDA $M_{1}$,使其成为一个 DPDA。
示例 2.16 和 2.18 给出了 CFLs $\left\{\mathrm{a}^{i} \mathrm{~b}^{j} \mathrm{c}^{k} \mid i, j, k \geq 0 \text{ 且 } i=j \text{ 或 } i=k\right\}$ 和 $\left\{w w^{\mathcal{R}} \mid w \in\{0,1\}^{*}\right\}$,它们不是 DCFLs。问题 2.27 和 2.28 表明识别这些语言需要非确定性。
这部分内容总结了DPDA的接受/拒绝条件,正式命名了它所识别的语言类别,并通过正反两方面的例子来巩固理解。
DPDA的接受与拒绝
首先,文章明确了DPDA的接受标准与通用的PDA是一致的,即“通过状态接受”。具体来说:
- 接受条件: 必须同时满足两个条件:
- 读完输入: 自动机必须成功处理(读取)完输入字符串中的每一个符号。
- 停在接受状态: 在读完最后一个符号后,机器的最终状态必须是接受状态集 $F$ 中的一员。
- 拒绝条件: 任何不满足上述接受条件的情况都算作拒绝。文章列举了三种主要的拒绝情景:
- 读完但状态不对: 机器成功读完了整个输入字符串,但最后停在了一个非接受状态。
- 未读完就卡住: 机器在处理过程中,遇到了一个没有定义转移的(状态,输入,栈顶)组合,导致计算提前终止。这种情况称为“Hanging”或“Crashing”。一个典型的例子是,当栈已经为空时,却执行了一个需要弹出非 $\varepsilon$ 符号的转移。
- 陷入无限循环: 机器进入了一系列只涉及 $\varepsilon$ 输入的转移,并且永远无法跳出这个循环。这导致它永远无法读取下一个真实的输入符号,因此也永远无法读完整个输入字符串。
确定性上下文无关语言 (DCFL)
接着,文章给出了一个关键的定义:由一个DPDA所识别的全部字符串构成的语言,被称为确定性上下文无关语言 (Deterministic Context-Free Language, DCFL)。这正式地将DPDA这个机器模型与DCFL这个语言类别绑定在了一起。
示例 2.40: 正面例子
- 语言: $L_1 = \{0^n 1^n \mid n \ge 0\}$。这个语言包含 "ε" (空串), "01", "0011", "000111" 等。
- 结论: 这个语言是一个DCFL。
- 解释: 我们可以构造一个DPDA来识别它。这个DPDA的策略是确定性的:
- 开始时,如果看到 '0',就将其(或一个代表'0'的符号)压入栈。只要还在接收 '0',就一直这样做。
- 当第一次看到 '1' 时,切换到一个新状态,并开始弹栈。
- 只要还在接收 '1',就继续弹栈。
- 如果在读 '0' 的阶段看到 '1',或者在读 '1' 的阶段看到 '0',或者 '0' 和 '1' 的数量不匹配(导致栈提前变空或输入结束后栈非空),都进入一个“陷阱”状态。
- 如果输入读完,且栈正好变空(只剩栈底符号),则进入接受状态。
- 修改PDA为DPDA: 文中提到,可以将一个已有的识别该语言的PDA $M_1$(可能某些转移未定义)修改成一个完全的DPDA。方法很简单:对于所有未明确定义的转移组合,都让它们转移到一个特殊的“死状态”(trap state)。这个死状态是一个非接受状态,并且任何输入都会让它继续停留在自身。这样就保证了机器对任何情况都有唯一的、定义好的转移,从而满足DPDA的定义。
反面例子
- 语言1: $L_2 = \{a^i b^j c^k \mid i,j,k \ge 0 \text{ 且 } i=j \text{ 或 } i=k\}$。这个语言包含 "abc" ($i=j=k=1$), "aabbc" ($i=j=2, k=1$), "abbcc" ($i=1, j=2, k=2$)。
- 语言2: $L_3 = \{ww^R \mid w \in \{0,1\}^*\}$ (前面提过的偶数长度回文)。
- 结论: 这两个语言都是CFL,但不是DCFL。
- 解释: 它们都需要非确定性来识别。
- 对于 $L_2$,当机器读完所有的 'a' (假设有 $i$ 个)并开始读 'b' 时,它需要做一个选择:是应该用 'b' 来匹配之前数过的 'a' (为了满足 $i=j$),还是应该忽略 'b' 的数量,把 'a' 的计数信息保留下来,等着后面用 'c' 来匹配 (为了满足 $i=k$)?一个DPDA无法提前知道哪个选择是正确的,因为它还没看到 'c'。它必须“猜”一个。
- 对于 $L_3$,如前所述,DPDA无法确定性地找到字符串的中点,因此不知道何时从压栈模式切换到弹栈匹配模式。
- DCFL示例 $L_1 = \{0^n 1^n \mid n \ge 0\}$:
- 输入 "0011":
- 读'0', 压栈。栈: [X]。
- 读'0', 压栈。栈: [X, X]。
- 读'1', 弹栈。栈: [X]。
- 读'1', 弹栈。栈: [ ] (空)。
- 输入结束,栈空。接受。整个过程是完全确定的。
- 输入 "010":
- 读'0', 压栈。栈: [X]。
- 读'1', 弹栈。栈: [ ]。
- 读'0'。此时机器处于“期望读1或输入结束”的状态,看到'0'没有合法的转移。卡住/进入陷阱状态。拒绝。
- 非DCFL示例 $L_2 = \{a^i b^j c^k \mid i=j \text{ 或 } i=k\}$:
- 输入 "abbc":
- 一个NPDA可以这样工作:
- 分支1 (猜测 i=j):
- 读'a', 压栈。栈: [A]。
- 读'b', 弹栈。栈: [ ]。
- 读'b', 栈空,无法匹配。此分支失败。
- 分支2 (猜测 i=k):
- 读'a', 压栈。栈: [A]。
- 读'b',不操作栈(或做其他标记)。
- 读'b', 继续不操作栈。
- 读'c', 弹栈。栈: [ ]。
- 输入结束,栈空。此分支成功。
- 因为至少有一个分支成功,所以NPDA接受 "abbc"。
- 一个DPDA的困境: 读完'a'后,栈里有一个'A'。当它看到第一个'b'时,它必须做出一个确定的决定:是现在就用'b'消耗掉'A',还是保留'A'等着后面的'c'?它没有足够的信息做这个决定。如果它选择消耗'A',那么当输入是 "ac" 这种 $i=k$ 的情况时它就会出错。如果它选择保留'A',那么当输入是 "ab" 这种 $i=j$ 的情况时它又会出错。
- 空串 $\varepsilon$: 对于 $L_1 = \{0^n 1^n \mid n \ge 0\}$,空串是语言的一部分 ($n=0$)。一个正确的DPDA必须能接受空串。这通常通过从开始状态直接有一条路径(可能是 $\varepsilon$ 移动)到接受状态来实现。
- “死状态”也是确定性的一部分: 将所有未定义的转移指向一个陷阱状态,这并不是一种妥协,而是实现一个“完全定义的”DPDA的标准技术。这确保了机器在任何情况下都有事可做,即使是“走向失败”。
- 非DCFL不代表“无法解析”: 说一个语言不是DCFL,只意味着不能用确定性的、线性的算法来解析。仍然可以用更通用的、但效率较低的算法(如CYK算法)来解析,这些算法本质上是在模拟非确定性。
本节明确了DPDA的接受和拒绝机制,其核心是“读完输入并停在接受状态”。任何偏离此路径的情况,如中途卡住或陷入死循环,都算作拒绝。由DPDA识别的语言类被正式命名为确定性上下文无关语言 (DCFL)。通过示例,文章展示了 $\{0^n 1^n\}$ 是一个典型的DCFL,而 $\{a^i b^j c^k \mid i=j \text{ 或 } i=k\}$ 和 $\{ww^R\}$ 是典型的非DCFL,因为它们内在地需要非确定性的“猜测”能力来解决识别过程中的歧义。
此部分的目的是通过实例来具体化DCFL的概念。在给出了抽象的定义和操作规则后,读者需要具体的例子来建立直观感受。通过展示一个“是”DCFL的例子和一个“不是”DCFL的例子,本段划清了确定性和非确定性上下文无关语言之间的边界,让读者明白非确定性在识别某些CFL时为何是不可或缺的。
想象你是一个只懂一条路走到黑的机器人。
- DCFL $\{0^n 1^n\}$: 你的任务是检查一堆货物是不是先来了一批苹果,然后来了一批数量完全相同的橘子。你的策略很简单:来一个苹果,你就在本子上画个勾。等橘子来了,来一个橘子,你就划掉一个勾。这个策略是完全确定的,没有歧义。
- 非DCFL $\{a^i b^j c^k \mid i=j \text{ 或 } i=k\}$: 你的任务变复杂了。检查一批货物是不是(苹果数=香蕉数)或者(苹果数=樱桃数)。你数完了苹果,画了 $i$ 个勾。现在香蕉来了,你面临抉择:是现在就用香蕉去销账(核对 $i=j$),还是留着账本等樱桃来了再销(核对 $i=k$)?作为一个“一条路走到黑”的机器人,你无法做出选择。而一个有“分身”能力的NPDA机器人则可以派两个分身,一个去执行第一种策略,一个去执行第二种。
你是一位法官,正在审理一个案子。
- DCFL: 案情非常清晰,证据链完整,每一步推理都指向唯一的结论。你可以确定地判定被告有罪或无罪。这就像识别一个DCFL。
- 非DCFL: 案情扑朔迷离,在某个关键点上,有两种完全不同但都看似合理的解释。例如,根据证据A,可以推断出嫌疑人X是凶手;但根据证据B,可以推断出嫌疑人Y是凶手。作为一个确定性的法官,你无法在没有更多信息的情况下做出判决,案子会“卡住”。而一个“非确定性”的系统,就像是同时对X和Y两条线索进行“有罪推定”,分别向下推演,看哪一条能最终形成完美的逻辑闭环。这种需要“分头探索”的案子,就类似于一个非DCFL。
66. DPDA论证的复杂性
📜 [原文6]
涉及 DPDA 的论证往往在技术上有些复杂,尽管我们努力强调构造背后的主要思想,但读者可能会发现本节比前几章的其他节更具挑战性。本书后面的材料不依赖本节,因此如果需要可以跳过。
这是一个作者写给读者的“友情提示”或“免责声明”。它的主要内容可以分解为以下几点:
- 难度预警: 作者坦诚地告诉读者,接下来要讨论的关于确定性下推自动机 (DPDA) 的证明和构造(例如,如何证明某些性质,或者如何将一个DPDA转换成另一个具有特定属性的DPDA)在技术细节上会比较复杂和繁琐。这比之前章节(如有限自动机或正则表达式)的内容要更具挑战性。
- 教学方法说明: 作者表示,尽管内容复杂,他们会尽力突出每个构造和证明背后的“主要思想”或“核心直觉”。这意味着他们会尝试先用更通俗的语言解释“我们想做什么”以及“我们的大致思路是什么”,然后再深入到具体的、形式化的步骤中。这是一种很好的教学策略,旨在帮助读者在不被技术细节淹没的情况下抓住主线。
- 可选内容声明: 最重要的一点是,作者明确指出,本节(2.4节)的内容在本书的后续章节中不会被作为前置知识依赖。这意味着,如果读者觉得这部分内容过于困难,或者时间有限,可以选择跳过本节,而不会影响对后面章节(如可计算性、复杂性理论)的学习。
这段话本身是描述性的,不包含技术内容,因此不适用“具体数值示例”。但我们可以举例说明它所指的“技术上复杂”是什么意思:
- 简单的论证(如DFA): 证明正则语言对并集运算封闭。思路很简单:并行运行两个DFA。构造一个新的DFA,其状态是原两个DFA状态的笛卡尔积。这个构造直观且易于理解。
- 复杂的论证(如DPDA): 后面将要证明的“DCFL对补集运算封闭”。这个证明的思路就复杂得多。不能简单地交换接受和非接受状态,因为DPDA可能因为卡住或无限循环而拒绝,这些情况在交换状态后行为不会改变。因此,需要先将DPDA标准化(例如,确保它总能读完输入),这个标准化过程本身就需要一系列精巧的构造,充满了技术细节。作者在这里就是在为这类复杂的论证打预防针。
- 错误地跳过: 对于希望深入理解形式语言和编译器理论的读者来说,跳过这一节可能会留下知识空白。虽然不影响后续章节,但DPDA和DCFL是解析理论(如LR解析)的理论基础,对于有志于编译器方向的学生来说是核心内容。
- 只看思想不看细节: 作者虽然强调主要思想,但计算机科学理论的精髓往往在于严谨的细节。只理解“大致思路”可能会导致在应用或解决相关问题时出错。正确的学习方法是,先理解主要思想,然后耐心地跟随技术细节,搞懂每一步构造的必要性。
本段是作者设置的一个路标,告知读者前方的道路(本节剩余内容)将变得崎岖。作者预警了DPDA相关证明的技术复杂性,但承诺会侧重于解释核心思想,并给予读者一个“安全出口”——即本节内容是独立的,可以选择性跳过,不影响学习后续章节。
本段的存在体现了优秀的教材编写理念,其目的有三:
- 管理读者预期: 避免读者因突然遇到的难度飙升而感到挫败或自我怀疑,提前告知他们“这部分确实很难”,从而调整学习心态。
- 提供学习路径指导: 明确指出本节的依赖关系,帮助读者根据自己的学习目标和时间来决定是否深入研究。对于课程学习者,可以根据教学大纲决定;对于自学者,可以根据个人兴趣决定。
- 增强教材亲和力: 这种与读者的直接“对话”,拉近了作者与读者的距离,使冰冷的理论知识变得更具人情味。
这就像在玩一个大型角色扮演游戏。你刚打通了新手村(有限自动机),现在进入了一个新的大地图(下推自动机)。
- 主线任务是继续前进到最终的Boss(图灵机)。
- 作者(游戏设计师)在地图入口处放了一个告示牌:“前方有一个名为‘确定性沼泽’的高难度可选副本。里面的怪物(证明)机制复杂,道路(构造)曲折。我们会在攻略(书中解释)里尽量标出捷径和Boss弱点(主要思想)。如果你只是想通关主线,可以绕过这个副本。但如果你是追求100%完成度的核心玩家,打通这个副本将让你对游戏机制有更深的理解。”
你是一位登山队的领队,正在向队员们介绍今天的路线。
- “各位,我们之前翻越的‘正则小山丘’和‘CFL山脉’风景不错,难度适中。今天,我们要挑战的是‘DPDA陡壁’。”
- “这面陡壁的技术要求很高,有很多复杂的绳索操作和攀爬技巧(技术细节)。我会先给大家讲解关键的攀爬策略和路线规划(主要思想)。”
- “不过请注意,这次攀登是一次可选的训练活动。我们的最终目标是远处的‘图灵高峰’,今天的活动不影响我们后续的主线行程。所以,如果大家感觉体力或技术储备不足,可以在山脚下的营地休整,这完全没问题。”
77. 引理2.41及其证明思路
📜 [原文7]
我们将从一个技术性引理开始,它将简化后面的讨论。如前所述,DPDA 可能会因为未能读取整个输入而拒绝输入,但这样的 DPDA 会引入混乱的情况。幸运的是,下一个引理表明我们可以将 DPDA 转换为一个避免这种不便行为的 DPDA。
引理 2.41
每个 DPDA 都有一个等价的 DPDA,它总是读取整个输入字符串。
证明思路 如果 DPDA 尝试弹出一个空栈,或者因为它进行了一系列无休止的 $\varepsilon$ 输入移动,它可能无法读取整个输入。我们将第一种情况称为挂起 (hanging),第二种情况称为循环 (looping)。我们通过用一个特殊符号初始化栈来解决挂起问题。如果该符号在输入结束前从栈中弹出,DPDA 会读取到输入末尾并拒绝。我们通过识别循环情况,即那些永远不再读取输入符号的情况,并重新编程 DPDA,使其读取并拒绝输入而不是循环来解决循环问题。我们必须调整这些修改以适应在输入最后一个符号处发生挂起或循环的情况。如果 DPDA 在读取完最后一个符号后进入接受状态,则修改后的 DPDA 接受而不是拒绝。
这部分内容介绍了一个重要的“标准化”引理及其证明的核心思想。这个引理旨在清除DPDA行为中的一些“烂摊子”,为后续更复杂的证明铺路。
引理的目的
首先,文章指出,一个“行为不端”的DPDA可能会在没读完输入时就停下来(拒绝)。这会给分析带来很多麻烦。比如,后面我们要证明DCFL对补集封闭,我们需要能够清晰地判定一个字符串是“接受”还是“拒绝”。如果一个字符串因为中途卡住而被拒绝,那么它的补集语言应该如何处理这个字符串呢?情况会变得非常混乱。因此,我们需要一个方法,把任何DPDA都改造成一个“行为良好”的DPDA,这个新DPDA保证总能“坚持”读完所有输入,然后再给出它的判决(接受或拒绝)。
引理 2.41 的陈述
“每个DPDA都有一个等价的DPDA,它总是读取整个输入字符串。”
- 每个DPDA: 这个引理是普适的,适用于任何一个合法的DPDA。
- 等价的: “等价”意味着新的DPDA和旧的DPDA识别完全相同的语言。对于任何输入字符串,如果旧的接受,新的也接受;如果旧的拒绝,新的也拒绝。
- 总是读取整个输入字符串: 这是新的DPDA的核心特性。它绝不会在中途停下。
证明思路的拆解
证明思路部分是整个证明的精华,它告诉我们如何一步步地改造旧的DPDA。作者将“未读完输入”的原因归结为两种:
- 挂起 (hanging): 指的是DPDA试图从一个空栈中弹出一个非 $\varepsilon$ 符号。这就像想从一个空盘子堆里拿走一个盘子,是不可能的操作,所以机器卡住了。
- 循环 (looping): 指的是DPDA陷入了一个无限的、只涉及 $\varepsilon$ 输入的转移序列。机器在原地“空转”,永远不会去读下一个输入符号。
针对这两种情况,证明思路提出了相应的解决方案:
- 解决“挂起”问题:
- 方法: 在计算开始前,先在栈底放一个特殊的、独一无二的栈底标记(比如 $)。这个符号就像是盘子堆最下面的那个托盘。
- 效果: 现在栈永远不会“真正”变空。如果旧的DPDA会因为栈空而挂起,那么新的DPDA会在同样的情况下看到这个特殊的 $ 符号。
- 新规则: 我们添加规则:一旦看到 $ 符号(意味着正常计算的栈已经空了),就进入一个特殊的“清场”模式。在这个模式下,机器不再执行任何复杂的逻辑,只是一个劲儿地把输入磁带上剩下的所有符号都读完,然后停在一个拒绝状态。这样就保证了输入总能被读完。
- 解决“循环”问题:
- 方法: 这部分更精巧。我们需要能够“预先识别”出哪些情况会导致无限循环。一个“循环情况”被定义为:当机器处于某个状态 $q$,栈顶是某个符号 $x$ 时,从这个配置开始,机器将永远不会再读入任何符号,也永远不会弹出 $x$ 下面的符号。
- 识别: 我们可以通过分析DPDA的图结构来找到所有这样的“循环情况”(这是一个可以被算法解决的静态分析问题)。
- 新规则: 一旦识别出 $(q, x)$ 是一个循环情况,我们就修改转移函数。不再让它进入循环,而是直接添加一条新规则,让它从 $(q, x)$ 这个配置通过一个 $\varepsilon$ 移动,直接跳转到我们之前提到的“清场”拒绝模式。
- 处理边界情况:
- 最后,思路提到了一个微妙的细节。挂起或循环可能恰好发生在读取完最后一个输入符号之后。
- 调整: 如果旧的DPDA在读完输入后,通过一系列 $\varepsilon$ 移动,最终能到达一个接受状态,那么即使这个过程中发生了(会发生)挂起或循环,我们也应该判定为接受。因此,我们的改造需要考虑到这一点。在识别出“循环情况”时,我们需要进一步判断这个循环是“拒绝循环”(永远到不了接受状态)还是“接受循环”(在循环路径上或终点能到达接受状态)。对于“接受循环”,我们应该让它转移到一个特殊的接受状态,而不是拒绝状态。对于挂起也是同理,如果在弹出栈底符号 $ 时,机器的当前状态本身就是一个接受状态,那么也应该导向接受。
- 解决挂起示例:
- 语言: $\{a^n b^{n+1} \mid n \ge 0\}$
- 有问题的DPDA:
- 读 $a$ 并压栈。
- 读 $b$ 并弹栈。
- 读完所有匹配的 $b$ 后,再读一个 $b$,此时栈空。
- 比如输入 "ab", 读'a'压'A',读'b'弹'A',栈空了。但输入还没完,还有个'b'。机器想读'b'但没有规则,挂起。
- 改造后的DPDA:
- 启动时压入 `$`。栈: [\$]。
- 读'a'压'A'。输入 "ab", 栈: [A, \$]。
- 读'b'弹'A'。输入 "b", 栈: [\$]。
- 读'b',此时栈顶是 `$`。触发新规则 $\delta(q, 'b', \$) = (q_{reject}, \varepsilon)$。
- 进入拒绝状态 $q_{reject}$,它会一直读完剩下的所有输入。
- 最终,输入 "ab" 被读完,停在 $q_{reject}$,所以拒绝。这是正确的结果。
- 解决循环示例:
- 有问题的DPDA: 包含规则 $\delta(q_{loop}, \varepsilon, X) = (q_{loop}, X)$。
- 场景: 当机器进入状态 $q_{loop}$ 且栈顶是 X 时,它会无限次地执行这个动作,卡住不动。
- 改造后的DPDA:
- 静态分析: 我们识别出 $(q_{loop}, X)$ 是一个“循环情况”。我们还分析出这个循环不会经过任何接受状态,所以是“拒绝循环”。
- 修改规则: 我们将原来的 $\delta(q_{loop}, \varepsilon, X) = (q_{loop}, X)$ 删除或替换为 $\delta(q_{loop}, \varepsilon, X) = (q_{reject}, \varepsilon)$。
- 效果: 现在,当机器进入 $(q_{loop}, X)$ 这个配置时,它会直接跳转到拒绝状态 $q_{reject}$,然后由 $q_{reject}$ 负责读完剩下的所有输入并最终拒绝。
- 等价性: 改造的核心是保持语言的等价性。所有这些修改(加$, 修改循环)都不能改变对任何一个字符串的最终“接受”或“拒绝”的判决,只能改变“如何”拒绝(中途挂掉 vs. 读完再拒绝)。
- 识别循环的复杂性: 在实践中,静态地、完全准确地识别出所有的“循环情况”是一个不平凡的任务。证明思路中只是概念性地提出了这一点,实际算法会更复杂。
- 接受循环: 最容易被忽略的边界情况是,一个无限循环本身可能是一个“接受”行为。例如,如果 $q_{loop}$ 本身就是一个接受状态,那么陷入这个循环(在读完输入之后)应该被视为接受。改造时必须区分这种情况。
本节介绍了引理2.41,它声明任何DPDA都可以被转换成一个等价的、总能读完整个输入字符串的“标准化”DPDA。证明思路指出了导致DPDA提前终止的两个主要原因——“挂起”(访问空栈)和“循环”(无限$\varepsilon$移动),并提出了相应的解决方案:使用特殊的栈底符号$来处理“挂起”,以及通过静态分析识别并重定向“循环”路径。这些改造确保了新的DPDA在拒绝一个字符串时,是通过读完它并停在非接受状态,而不是中途“崩溃”,从而极大地简化了后续的理论分析。
这个引理的存在是为了“净化”DPDA的行为模型,使其更易于分析。它是一个典型的理论工具,一个“引理”(lemma),其主要作用是为后续更重要的定理(如DCFL的闭包性质)的证明服务。通过将所有DPDA都标准化为“总能读完输入”,后续的证明就不需要分情况讨论那些因“挂起”或“循环”而拒绝的复杂情况,可以默认自动机总能给出一个“体面”的、在输入末尾的回答。
这就像是在给一个软件打补丁,修复它的崩溃bug。
- 旧软件 (原始DPDA): 可能会因为各种奇怪的输入而崩溃(挂起)或卡死(循环)。
- 引理2.41 (补丁): 这个补丁做两件事:
- 异常处理 (解决挂起): 它给软件的核心数据结构(栈)加了一个“保护层”($)。如果软件试图进行非法操作(访问空栈),保护层会捕获这个异常,然后让软件进入一个安全的“仅读取、不处理”的模式,直到数据流结束,最后报告一个“处理失败”的错误,而不是直接崩溃。
- 死循环检测 (解决循环): 补丁里包含一个分析工具,能扫描代码,找到所有可能导致死循环的逻辑。然后它修改代码,在进入死循环之前,直接跳转到上面那个安全的“处理失败”流程。
- 新软件 (标准化DPDA): 打了补丁之后,软件变得非常健壮。它再也不会崩溃或卡死了,对于任何输入,它总能运行到最后,然后明确地告诉你“成功”或“失败”。
你正在训练一个机器人去完成一项复杂的任务。
- 原始机器人: 有时候会出故障。比如,它的零件盒空了,它还想去拿,结果手臂卡住了(挂起)。或者它的程序有个bug,让它在一个地方不停地转圈(循环)。
- 你的改造 (引理2.41):
- 解决零件问题: 你在每个零件盒底部都涂上了红色。你给机器人加了一条新指令:“如果你看到了红色盒底,说明你需要的零件没了。立刻停止当前任务,切换到‘打扫卫生’模式,直到下班,然后记录任务失败。”
- 解决转圈问题: 你用高速摄像机分析了机器人的所有动作,发现只要它以“姿势A”去够“B号零件”,就会开始转圈。你修改了它的核心程序:“警告:禁止以姿势A去够B号零件。一旦检测到此意图,立刻放弃任务,切换到‘打扫卫生’模式。”
- 改造后的机器人: 这个机器人现在非常可靠。它要么成功完成任务,要么在遇到无法解决的问题时,会优雅地放弃,并去做些别的事情直到结束,而不是在原地出故障。
88. 引理 2.41的证明
📜 [原文8]
证明 令 $P=\left(Q, \Sigma, \Gamma, \delta, q_{0}, F\right)$ 为一个 DPDA。首先,添加一个新开始状态 $q_{\text {start}}$、一个额外的接受状态 $q_{\text {accept}}$、一个新状态 $q_{\text {reject}}$,以及其他如所述的新状态。对每个 $r \in Q, a \in \Sigma_{\varepsilon}$, 和 $x, y \in \Gamma_{\varepsilon}$ 执行以下更改。
首先修改 $P$,使其一旦进入接受状态,就保持在接受状态直到读取下一个输入符号。对于每个 $q \in Q$,添加一个新接受状态 $q_{\mathrm{a}}$。对于每个 $q \in Q$,如果 $\delta(q, \boldsymbol{\varepsilon}, x)=(r, y)$,则设置 $\delta\left(q_{\mathrm{a}}, \boldsymbol{\varepsilon}, x\right)=\left(r_{\mathrm{a}}, y\right)$,然后如果 $q \in F$,也将 $\delta$ 更改为 $\delta(q, \varepsilon, x)=\left(r_{\mathrm{a}}, y\right)$。对于每个 $q \in Q$ 和 $a \in \Gamma$,如果 $\delta(q, a, x)=(r, y)$,则设置 $\delta\left(q_{\mathrm{a}}, a, x\right)=(r, y)$。令 $F^{\prime}$ 为新旧接受状态的集合。
接下来,修改 $P$,使其在尝试弹出空栈时拒绝,通过用一个特殊的栈符号 $\%%MATH_BLOCK_460%%,它会进入 $q_{\text {reject}}$ 并扫描输入直到结束。如果 $P$ 在接受状态检测到 $\$$,它会进入 $q_{\text {accept}}$。然后,如果仍有未读取的输入,它会进入 $q_{\text {reject}}$ 并扫描输入直到结束。形式上,设置 $\delta\left(q_{\text {start}}, \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon}\right)=\left(q_{0}, \$\right)$。对于 $x \in \Gamma$ 和 $\delta(q, a, x) \neq \emptyset$,如果 $q \notin F^{\prime}$,则设置 $\delta(q, a, \$)=\left(q_{\text {reject}}, \varepsilon\right)$,如果 $q \in F^{\prime}$,则设置 $\delta(q, a, \$)=\left(q_{\text {accept}}, \boldsymbol{\varepsilon}\right)$。对于 $a \in \Sigma$,设置 $\delta\left(q_{\text {reject}}, a, \boldsymbol{\varepsilon}\right)=\left(q_{\text {reject}}, \boldsymbol{\varepsilon}\right)$ 和 $\delta\left(q_{\text {accept}}, a, \boldsymbol{\varepsilon}\right)=\left(q_{\text {reject}}, \boldsymbol{\varepsilon}\right)$。
最后,修改 $P$,使其拒绝而不是在输入结束前进行一系列无休止的 $\varepsilon$ 输入移动。对于每个 $q \in Q$ 和 $x \in \Gamma$,如果当 $P$ 在状态 $q$ 启动且栈顶为 $x \in \Gamma$ 时,它从不弹出 $x$ 下方的任何内容,也从不读取输入符号,则称 $(q, x)$ 为循环情况 (looping situation)。如果 $P$ 在其随后的移动中进入接受状态,则称该循环情况为接受的,否则为拒绝的。如果 $(q, x)$ 是一个接受的循环情况,设置 $\delta(q, \boldsymbol{\varepsilon}, x)=\left(q_{\text {accept}}, \boldsymbol{\varepsilon}\right)$,而如果 $(q, x)$ 是一个拒绝的循环情况,设置 $\delta(q, \boldsymbol{\varepsilon}, x)=\left(q_{\text {reject}}, \boldsymbol{\varepsilon}\right)$。
为简化起见,我们此后假设 DPDA 读取其输入直到结束。
这是对引理2.41的正式构造性证明。它详细描述了如何将任意一个DPDA $P$ 改造为一个新的、等价的、总能读完输入的DPDA $P'$。证明分为三个主要步骤,并引入了几个新的状态来辅助改造。
新状态介绍:
- $q_{\text{start}}$: 新的唯一开始状态,用于初始化。
- $q_{\text{accept}}$: 一个特殊的接受状态,用于处理“接受并清场”的情况。
- $q_{\text{reject}}$: 一个特殊的拒绝状态(陷阱状态),用于处理“拒绝并清场”的情况。
第一步:修改接受行为(状态记忆)
- 问题: 原始DPDA可能在一个 $\varepsilon$ 移动后进入接受状态,然后马上又在另一个 $\varepsilon$ 移动后离开它。这使得在某个时间点“是否处于接受状态”变得很模糊。
- 目标: 让“接受”这个事实被“记住”,直到下一个真实输入符号被读取。
- 构造:
- 为每个原始状态 $q \in Q$,创建一个“影子”接受状态 $q_a$。可以把 $q_a$ 理解为“在状态q,并且刚刚达到了一个接受点”。
- 复制转移:如果原来有从 $q$ 到 $r$ 的转移,我们就添加一条从 $q_a$ 到 $r_a$(如果是 $\varepsilon$ 移动)或 $r$(如果是读符号移动)的平行转移。这样,一旦进入“影子”世界($q_a$状态),就会尽量停留在里面。
- 修改进入“影子”世界的规则:如果一个 $\varepsilon$ 移动 $\delta(q, \varepsilon, x)$ 的目标状态 $r$ 原本是接受状态 ($r \in F$),那么我们现在让这个转移直接进入影子状态 $r_a$,即 $\delta(q, \varepsilon, x) = (r_a, y)$。
- $F'$ 成为所有旧的接受状态和所有新的影子状态 $q_a$ 的集合。
- 效果: 经过这一步,一旦机器因为某个计算而达到接受条件,它会进入一个对应的 $q_a$ 状态,并在这个“接受模式”下继续模拟原始机器的行为,直到下一个输入符号被消耗,它才会回到“普通模式”。
第二步:解决“挂起”问题(栈底标记)
- 目标: 防止因试图弹出空栈而导致的计算中止。
- 构造:
- 初始化: 从新的开始状态 $q_{\text{start}}$,通过一个 $\varepsilon$ 移动进入原始的开始状态 $q_0$,并同时在空栈上压入一个特殊的栈底标记 `$`。即 $\delta(q_{\text{start}}, \varepsilon, \varepsilon) = (q_0, \$)$。
- 检测栈底: 现在,原始的计算逻辑会在 $` 之上进行。如果计算导致栈被清空,栈顶就会暴露出 `$。我们为这种情况添加新规则。
- 处理检测到 $ 的情况:
- 如果机器在一个非接受状态 ($q \notin F'$) 看到了 `$`,这意味着计算本应“挂起”且结果是拒绝。我们定义 $\delta(q, a, \$) = (q_{\text{reject}}, \varepsilon)$。机器进入 $q_{\text{reject}}$。
- 如果机器在一个接受状态 ($q \in F'$) 看到了 `$`,这意味着计算在接受点结束。我们定义 $\delta(q, a, \$) = (q_{\text{accept}}, \varepsilon)$。机器进入 $q_{\text{accept}}$。
- 清场模式:
- 一旦进入 $q_{\text{reject}}$,它会像一个黑洞一样,吞噬掉所有剩下的输入符号,并保持在 $q_{\text{reject}}$ 状态。即 $\delta(q_{\text{reject}}, a, \varepsilon) = (q_{\text{reject}}, \varepsilon)$ for all $a \in \Sigma$。
- $q_{\text{accept}}$ 稍微不同。它代表“我已经接受了,但得把手续办完”。如果此时后面还有输入,说明输入格式不对(例如,对于 $\{0^n1^n\}$,输入 "00110" 在处理完 "0011" 时达到接受点,但后面还有个 '0')。所以,如果 $q_{\text{accept}}$ 后面还有输入,它会转移到 $q_{\text{reject}}$ 去“拒绝性地”读完输入。即 $\delta(q_{\text{accept}}, a, \varepsilon) = (q_{\text{reject}}, \varepsilon)$。
第三步:解决“循环”问题(静态分析与重定向)
- 目标: 防止因无限 $\varepsilon$ 移动而无法读完输入。
- 定义“循环情况”: 一个配置 $(q, x)$(状态 $q$,栈顶 $x$)被称为“循环情况”,如果从这个配置开始,机器在后续的任意多步 $\varepsilon$ 移动中,既不消耗任何输入,也不弹出 $x$ 下方的任何东西。
- 构造:
- 分析: 我们可以(在理论上)静态分析 $P$ 的所有配置,找出所有的“循环情况”。
- 分类: 对于每个循环情况 $(q, x)$,我们再判断它最终是“接受的”还是“拒绝的”。如果在它无限循环的路径上能达到一个接受状态,它就是“接受的循环情况”;否则是“拒绝的”。
- 重定向:
- 如果 $(q, x)$ 是一个接受的循环情况,我们直接修改规则,让它一步到位:$\delta(q, \varepsilon, x) = (q_{\text{accept}}, \varepsilon)$。
- 如果 $(q, x)$ 是一个拒绝的循环情况,我们也让它一步到位:$\delta(q, \varepsilon, x) = (q_{\text{reject}}, \varepsilon)$。
- 效果: 所有可能导致无限循环的路径都被“短路”了,直接导向最终的 $q_{\text{accept}}$ 或 $q_{\text{reject}}$ 状态,从而避免了循环。
最后的小结
“为简化起见,我们此后假设 DPDA 读取其输入直到结束。” 这句话是本证明的结论。它告诉我们,因为我们已经证明了任何DPDA都可以被改造成这种“行为良好”的模式,所以在后续的讨论中,我们可以不必再考虑那些中途卡住或循环的复杂情况,可以直接假设我们面对的DPDA总是能读完输入的。这大大简化了后续的证明。
这部分是纯粹的构造描述,不直接产生可计算的数值。例子已在上一节“证明思路”中给出,这里的构造是那些例子的形式化实现。我们可以再想象一个例子来理解第一步的改造:
- 原始DPDA $P$:
- $F = \{q_f\}$
- $\delta(q_1, \varepsilon, \varepsilon) = (q_f, \varepsilon)$
- $\delta(q_f, \varepsilon, \varepsilon) = (q_2, \varepsilon)$ (其中 $q_2 \notin F$)
- 问题: 机器在 $(q_1, \varepsilon, \varepsilon)$ 之后瞬间进入 $q_f$ (接受状态),但又马上离开进入 $q_2$ (非接受状态),这使得“接受”这个事实没有被稳定地保持。
- 第一步改造后的 $P'$:
- 创建新状态 $q_{f,a}$ 和 $q_{2,a}$。
- 新 $F' = \{q_f, q_{f,a}\}$。
- $\delta(q_1, \varepsilon, \varepsilon)$ 被修改为 $\delta(q_1, \varepsilon, \varepsilon) = (q_{f,a}, \varepsilon)$,因为它原来的目标 $q_f$ 是接受状态。
- 为 $q_{f,a}$ 添加平行转移:$\delta(q_{f,a}, \varepsilon, \varepsilon) = (q_{2,a}, \varepsilon)$。
- 效果: 现在,机器从 $q_1$ 会进入 $q_{f,a}$。因为它停在了一个接受状态 ($q_{f,a} \in F'$),这个“接受”的事实被记录下来了。之后它再转移到 $q_{2,a}$,这仍然是一个接受状态(虽然原始的 $q_2$ 不是),“接受”的事实得以保持,直到下一个真实输入符号被读取。
- 状态爆炸: 这个构造过程会引入很多新状态(每个原始状态的影子状态,加上 $q_{\text{start}}, q_{\text{accept}}, q_{\text{reject}}$),在实践中可能会导致状态数量急剧增加。
- 静态分析的可行性: “识别循环情况”在理论上是可行的,但在实践中实现一个完全正确的分析器是复杂的。证明本身依赖于这个分析是可行的这一事实。
- 顺序的重要性: 证明中的三个修改步骤最好按顺序进行,因为后面的步骤可能依赖于前面步骤完成的标准化。
该证明提供了一个三步构造法,将任何给定的DPDA $P$ 转换为一个等价的、总能读完输入的DPDA $P'$。第一步通过引入“影子”接受状态来稳定接受行为;第二步通过引入栈底符号$和专用的接受/拒绝“清场”状态来处理“挂起”;第三步通过静态分析和重定向来消除无限“循环”。这个构造性的证明表明,DPDA提前终止的“不便行为”并非其模型的内在缺陷,而是可以通过标准化手段消除的,因此在后续理论推导中可以安全地忽略这些情况。
本证明的目的是为引理2.41提供一个严谨的、构造性的支持。它不仅仅是说“可以做到”,而是详细地展示了“如何做到”。这种构造性证明在计算理论中非常重要,因为它:
- 提供了算法基础: 这个构造本身就是一个算法的蓝图,可以用来实际地将一个DPDA程序转换为更健壮的版本。
- 奠定了理论基石: 通过这个引理,后续关于DCFL性质的证明(如补集封闭性)可以建立在一个更简单、更清晰的模型之上,大大降低了证明的复杂性。
这就像是对一个国家的法律体系进行一次彻底的改革。
- 原始DPDA: 原始的法律体系,可能存在漏洞(导致挂起)和逻辑死循环(导致循环)。
- 第一步改造: 设立“荣誉公民”身份。一旦某人因重大贡献被授予此身份(进入接受状态),此身份将被保留并体现在其所有后续行为中,直到下一年评定(读取新输入)。
- 第二步改造: 设立“破产法”(处理挂起)。任何个人或公司(计算过程)在耗尽所有资产(栈)后,不得凭空操作。其资产底部有一个“最终清算”标记 (`$`)。一旦触及此标记,必须进入“破产清算程序”($q_{\text{reject}}$或$q_{\text{accept}}$),有序地处理完所有剩余事务(读完输入),然后宣布最终结果(破产或重组成功)。
- 第三步改造: 废除所有会导致议会陷入无限扯皮的议事规则(处理循环)。通过分析发现某些议题组合会导致永久性僵局,立法直接规定,一旦出现此类组合,立刻启动快速表决通道,得出“通过”($q_{\text{accept}}$)或“否决”($q_{\text{reject}}$)的最终结果。
- 改造后的DPDA: 改革后的法律体系变得非常健全,任何案件都能走到终审判决,不会中途搁置或无限期拖延。
你是一位城市交通系统的总设计师,正在升级一个老旧的自动化地铁系统。
- 原始系统 (P): 有时会出问题。列车可能开到一条没有电的盲肠线尽头然后停运(挂起),或者在某个环形轨道上不停地绕圈(循环)。
- 第一步改造: 你给所有“终点站”(接受状态)都装上了闪亮的霓虹灯。一旦列车进站,霓虹灯就会亮起,并且列车在后续的站内调度中也会带着这种“已到达终点”的标记,直到它接到新的发车指令去往别的线路(读取新输入)。
- 第二步改造: 你在所有轨道的尽头都安装了一个强制弹射装置 (`$`)。如果列车开到了这里,说明它走错了路。弹射装置会把它弹射到一条专用的“回收轨道”($q_{\text{reject}}$)上。这条轨道非常长,会经过所有剩下的车站(读完输入),最终把列车送回车库并记录一次失败。如果列车是在终点站完成任务后才不小心开到这里,弹射装置会把它送到“荣誉回库轨道”($q_{\text{accept}}$)。
- 第三步改造: 你通过计算机模拟,找到了所有会让列车陷入绕圈的轨道组合。你在这些环线的入口处安装了智能道岔。一旦系统检测到有列车要进入这个“死亡漩涡”,道岔会自动把它掰到上面说的“回收轨道”或“荣誉回库轨道”。
- 新系统 (P'): 升级后的地铁系统100%可靠。任何一班列车,要么正常跑完全程到达目的地,要么在出问题时被导向回收轨道,跑完剩余路程后回库。绝不会有车在中途失踪或卡住。
99. DCFL的性质
📜 [原文9]
我们将探讨 DCFL 类的闭包和非闭包性质,并利用这些性质展示一个不是 DCFL 的 CFL。
定理 2.42
DCFL 类在补运算下是闭合的。
这部分开始探讨确定性上下文无关语言 (DCFL) 的一个非常重要的数学性质——闭包性 (closure property)。
闭包性是什么?
在形式语言理论中,一个语言类(比如正则语言、CFL、DCFL)如果在某个运算下是“闭合的”,意味着对该类中的任何一个或两个语言进行该运算,得到的结果仍然属于这个类。
- 例如,正则语言在并集运算下是闭合的。这意味着,如果你有两个正则语言 $L_1$ 和 $L_2$,那么它们的并集 $L_1 \cup L_2$ 也一定是一个正则语言。
- 这就好比说“整数在加法下是闭合的”,因为任何两个整数相加,结果仍然是整数。但“奇数在加法下不是闭合的”,因为两个奇数相加结果是偶数。
文章预告了将要讨论DCFL的闭包性质(在哪些运算下封闭)和非闭包性质(在哪些运算下不封闭)。这些性质不仅是理论上有趣的,更重要的是,它们是强大的工具,可以用来证明某些语言“不是”DCFL。
定理 2.42 的陈述
“DCFL 类在补运算下是闭合的。”
- 补运算: 对于一个在字母表 $\Sigma$ 上定义的语言 $L$,它的补语言(记作 $\bar{L}$ 或 $L^c$)是所有不属于 $L$ 的、由 $\Sigma$ 中的符号构成的字符串的集合。即 $\bar{L} = \Sigma^* - L$。
- 定理的含义: 这个定理声明,如果你有一个DCFL语言 $L$,那么它的补语言 $\bar{L}$ 也一定是一个DCFL。换句话说,如果你能找到一个DPDA来识别 $L$,那么一定也存在另一个DPDA来识别 $\bar{L}$。
这个性质为什么重要?
这个定理非常强大。我们回想一下:
- 正则语言在补运算下是闭合的。证明很简单:拿一个识别该语言的DFA,把它的接受状态和非接受状态互换,得到的新DFA就识别其补语言。
- 上下文无关语言 (CFL) 在补运算下是不闭合的!这是一个非常关键的区别。存在一些CFL,它们的补语言不是CFL。
定理2.42表明,DCFL 在这一点上表现得更像正则语言,而不像更广泛的CFL。这个性质成为了区分DCFL和非DCFL的CFL的一把利器。
如何利用这个性质?
假设你想证明某个语言 $L$ 不是DCFL。你可以使用反证法:
- 假设 $L$ 是一个DCFL。
- 根据定理2.42,如果 $L$ 是DCFL,那么它的补语言 $\bar{L}$ 也必须是DCFL。
- 因为所有的DCFL也都是CFL,所以 $\bar{L}$ 也必须是一个CFL。
- 接下来,你运用其他已知工具(比如CFL的泵引理,或者CFL在交集运算下的非闭包性)来证明 $\bar{L}$ 不是一个CFL。
- 这就产生了矛盾!第3步说 $\bar{L}$ 必须是CFL,第4步证明了它不是。
- 这个矛盾说明,我们最初的假设——“$L$是一个DCFL”——是错误的。
- 结论: $L$ 不是一个DCFL。
文章的引言部分“利用这些性质展示一个不是 DCFL 的 CFL”正是预告了将要使用上述逻辑。
- 示例1: 正则语言的补集闭包性
- 语言 L: 在 $\Sigma=\{0,1\}$ 上,所有以 '1' 结尾的字符串。这是一个正则语言。
- DFA for L: 一个双状态DFA。$q_0$ (非接受), $q_1$ (接受)。在$q_0$看到'0'留在$q_0$,看到'1'到$q_1$。在$q_1$看到'0'到$q_0$,看到'1'留在$q_1$。
- 补语言 $\bar{L}$: 所有不以 '1' 结尾的字符串(即空串,或以 '0' 结尾的字符串)。
- DFA for $\bar{L}$: 交换L的DFA的接受与非接受状态。新DFA中,$q_0$变成接受状态,$q_1$变成非接受状态。这个新DFA恰好识别 $\bar{L}$。
- 示例2: 应用定理2.42(预演)
- 目标: 证明 $L = \{a^i b^j c^k \mid i \ne j \text{ or } j \ne k\}$ 不是一个DCFL。
- 思路:
- 假设 $L$ 是 DCFL。
- 根据定理2.42,$\bar{L}$ 也必须是 DCFL。
- $\bar{L}$ 是什么?它是 $L$ 的反面,即 $\{a^i b^j c^k \mid \neg (i \ne j \text{ or } j \ne k) \}$.
- 逻辑上, $\neg(P \text{ or } Q) \equiv (\neg P \text{ and } \neg Q)$。所以 $\neg (i \ne j \text{ or } j \ne k) \equiv (i=j \text{ and } j=k)$。
- 因此, $\bar{L} = \{a^n b^n c^n \mid n \ge 0\}$。(这里忽略了不符合 $a^*b^*c^*$ 形式的字符串,可以通过与 $a^*b^*c^*$ 求交集来处理,后面会讲到)。
- 我们知道 $\{a^n b^n c^n\}$ 是一个经典的非上下文无关语言。
- 这就产生了矛盾:如果 $L$ 是DCFL,那么 $\bar{L}$ 必须是CFL,但我们知道 $\bar{L}$ 不是CFL。
- 结论:我们的假设错误,所以 $L$ 不是DCFL。
- CFL vs DCFL: 一定要分清,是CFL类对补运算不封闭,而它的子类DCFL却对补运算封闭。这是一个非常精妙和重要的区分。
- 证明的复杂性: 证明DCFL对补运算封闭并不像DFA那样简单地交换状态。证明需要用到前文的引理2.41,将DPDA标准化,确保它总能读完输入,这是关键一步。直接交换状态是行不通的。
- 运算的封闭性是语言类的性质: 闭包性是针对一个“集合的集合”的性质,而不是单个语言的性质。
本段引入了语言类的闭包性这一重要概念,并提出了一个核心定理:DCFL类在补运算下是闭合的。这意味着任何DCFL的补语言也必然是DCFL。这个性质本身非常重要,因为它将DCFL与更广泛的、对补运算不封闭的CFL类区分开来,并且它提供了一个强有力的工具,可以通过反证法来证明某些CFL不是DCFL。
本段的目的是从一般性质的层面来研究DCFL,为后续的理论分析和语言分类提供工具。它起到了承上启下的作用:
- 承上: 基于已经定义的DPDA模型。
- 启下: 预告了将要进行的证明(定理2.42的证明)以及该定理的应用(证明某个语言不是DCFL)。这为本节后续的内容设置了清晰的目标。
想象一个“语言俱乐部”:
- DCFL俱乐部: 这个俱乐部的会员(语言)都很有“纪律性”(确定性)。俱乐部有一条规定:“如果一个人是我们的会员,那么所有‘不是他’的人组成的群体,也能组成一个符合我们俱乐部纪律的团体。” 这就是补集闭包性。
- CFL俱乐部: 这个俱乐部的会员范围更广,有些比较“随性”(非确定性)。它就没有上面那条规定。可能一个会员 $L$ 的“反面”群体 $\bar{L}$ 会变得非常“混乱”,不符合CFL俱乐部最基本的章程(甚至不是CFL)。
- 定理2.42: 就是DCFL俱乐部的那条严格的会员规定。
你有一台精密的“语言分类机”。
- 你把一门语言 $L$ 的语法书喂给它,它亮起了“DCFL”的绿灯。
- 定理2.42告诉你:现在,如果你编写一本新的语法书,规定“所有不符合 $L$ 语法的句子都是合法的”,然后把这本新的“反语”语法书喂给机器,它也一定会亮起“DCFL”的绿灯。
- 这个特性非常可靠。因此,如果你以后遇到一门语言 $X$,你把它取反得到 $\bar{X}$,然后发现机器对 $\bar{X}$ 亮了红灯(甚至“无法识别”的警报),你就可以百分之百确定,原来的语言 $X$ 肯定不是“DCFL”类的。
1010. 定理 2.42的证明
📜 [原文10]
证明思路 交换 DFA 的接受状态和非接受状态会产生一个识别补语言的新 DFA,从而证明正则语言类在补运算下是闭合的。同样的方法也适用于 DPDA,只是有一个问题。DPDA 可能会通过在输入字符串末尾的一系列移动中同时进入接受和非接受状态来接受其输入。在这种情况下,交换接受和非接受状态仍然会接受。
我们通过修改 DPDA 来限制接受发生的时间来解决这个问题。对于输入的每个符号,修改后的 DPDA 只有在即将读取下一个符号时才能进入接受状态。换句话-说,只有读取状态——总是读取输入符号的状态——可以是接受状态。然后,通过仅在这些读取状态之间交换接受和非接受,我们反转了 DPDA 的输出。
证明 首先按照引理 2.41 的证明中所述修改 $P$,并令 $\left(Q, \Sigma, \Gamma, \delta, q_{0}, F\right)$ 为所得的机器。该机器总是读取整个输入字符串。此外,一旦进入接受状态,它会保持在接受状态直到读取下一个输入符号。
为了实现证明思路,我们需要识别读取状态。如果 DPDA 在状态 $q$ 读取输入符号 $a \in \Sigma$ 而不弹出栈,即 $\delta(q, a, \varepsilon) \neq \emptyset$,则将 $q$ 指定为读取状态。但是,如果它既读取又弹出,读取的决定可能取决于弹出的符号,因此将该步骤分为两步:先弹出然后读取。因此,如果对于 $a \in \Sigma$ 和 $x \in \Gamma$,$\delta(q, a, x)=(r, y)$,则添加一个新状态 $q_x$ 并修改 $\delta$,使 $\delta(q, \boldsymbol{\varepsilon}, x)=\left(q_{x}, \boldsymbol{\varepsilon}\right)$ 和 $\delta\left(q_{x}, a, \boldsymbol{\varepsilon}\right)=(r, y)$。将 $q_x$ 指定为读取状态。状态 $q_x$ 从不弹出栈,因此它们的动作与栈内容无关。如果 $q \in F$,则将 $q_x$ 指定为接受状态。最后,从任何不是读取状态的状态中移除接受状态的指定。修改后的 DPDA 等价于 $P$,但它在每个输入符号最多进入一次接受状态,即在即将读取下一个符号时。
现在,反转哪些读取状态被归类为接受状态。所得的 DPDA 识别补语言。
这是对“DCFL对补运算封闭”这一重要定理的证明。证明过程非常精妙,分为几个关键步骤。
第一部分:证明思路
核心思想是模仿证明正则语言对补运算封闭的方法:交换接受与非接受状态。但作者立刻指出了这个简单方法在DPDA上的一个致命缺陷。
- DFA的成功之处: 一个DFA在读完输入后,会停在一个唯一的状态。这个状态要么是接受状态,要么是非接受状态,二者必居其一。所以交换它们能完美地反转接受/拒绝的结果。
- DPDA的问题: 一个DPDA在读完输入后,可能还会进行一系列的 $\varepsilon$ 移动。在这个过程中,它的状态可能会不断变化。它可能先进入一个非接受状态,然后又进入一个接受状态。只要它在这个过程中曾经进入过接受状态,整个输入就被视为接受。
- 例子: 假设输入读完后,机器从 $q_1$ (非接受) $\rightarrow$ $q_2$ (接受) $\rightarrow$ $q_3$ (非接受)。由于它经过了 $q_2$,所以结果是接受。
- 如果我们简单地交换接受/非接受状态,那么在新机器中,$q_1$ 和 $q_3$ 变成接受状态,$q_2$ 变成非接受状态。新机器的路径是 $q_1$(接受) $\rightarrow$ $q_2$(非接受) $\rightarrow$ $q_3$(接受)。由于它经过了 $q_1$ 和 $q_3$,结果仍然是接受!我们没能成功地反转结果。
- 解决方案: 为了解决这个问题,证明思路提出了一种“标准化”接受时刻的策略。我们不应该在任何时候都可以宣布“接受”,而应该把“宣布判决”的时刻统一起来。
- 新策略: 我们将DPDA改造成只在即将读取下一个输入符号的那一瞬间才判断是否接受。我们将这些特殊的、负责读取符号的状态称为“读取状态”。
- 效果: 这样一来,对于输入中的每个位置,机器只有一个唯一的时刻来决定“到目前为止,我是否接受这个前缀?”。在这些明确的、离散的检查点上,接受和非接受的界限是清晰的。
- 最终步骤: 一旦我们将DPDA改造成这种“检查点”模式,我们就可以安全地在这些“读取状态”中交换接受与非接受的身份,从而完美地反转DPDA的行为,识别其补语言。
第二部分:形式化证明
证明过程严格地执行了上述思路。
步骤1:初始标准化 (使用引理2.41)
- 动作: 首先,应用引理2.41的结论和构造方法。我们拿到一个原始的DPDA $P$,将它改造成一个新的等价DPDA。
- 效果: 这个新的DPDA有两个关键的“好”性质:
- 它总能读完整个输入字符串。
- 它具有“接受记忆”:一旦进入接受状态,会保持接受,直到下一个输入符号被读取。
- 目的: 这一步解决了“中途卡住”和“无限循环”的拒绝情况,并部分解决了“接受时刻模糊”的问题,为下一步精细化改造铺平了道路。
步骤2:识别并隔离“读取状态”
- 目标: 精确地创造出我们想要的“检查点”,即“读取状态”。
- 定义: 什么是“读取状态”?一个理想的读取状态应该只做一件事:消耗一个输入符号。它的行为不应该依赖于栈顶是什么。也就是说,它的转移应该是 $\delta(q, a, \varepsilon)$ 这种形式。
- 问题: 原始的转移可能是 $\delta(q, a, x)$,即“读取”和“弹栈”这两个动作捆绑在一起了。读取的决定依赖于弹出的符号 $x$。
- 构造 (解耦操作): 为了解决这个问题,证明采用了一个非常漂亮的外科手术式操作——将一个复杂的动作分解为两个简单的动作。
- 如果原来有一个转移 $\delta(q, a, x) = (r, y)$,它同时读 $a$ 又弹 $x$。
- 我们引入一个全新的中间状态 $q_x$。
- 我们将原来的转移拆成两步:
- 第一步 (弹栈): $\delta(q, \varepsilon, x) = (q_x, \varepsilon)$。这是一个纯粹的弹栈操作,不读输入。从 $q$ 看到栈顶是 $x$ 时,弹出 $x$ 并进入中间状态 $q_x$。
- 第二步 (读取): $\delta(q_x, a, \varepsilon) = (r, y)$。现在,在中间状态 $q_x$,我们执行一个纯粹的读取操作,不依赖栈。读取 $a$,然后完成原来要做的后续事情(进入 $r$ 并压入 $y$)。
- 指定读取状态: 我们将所有这些新引入的中间状态 $q_x$(以及那些原本就是 $\delta(q, a, \varepsilon)$ 形式的原始状态)正式指定为“读取状态”。
- 效果: 经过这个改造,所有读取输入的动作都被集中到了这些“读取状态”上,并且这些状态的读取行为与栈内容无关。我们成功地创造出了干净的“检查点”。
步骤3:最终翻转
- 动作:
- 首先,我们取消所有非读取状态的“接受”资格。即使它们原来是接受状态,现在也不算了。判决权只属于“读取状态”。
- 然后,在所有“读取状态”中,我们进行交换:原来是接受的,现在变成非接受;原来是非接受的,现在变成接受。
- 结论: 经过这一系列精巧的改造,我们得到的最终DPDA,其接受的语言恰好是原始语言的补集。由于我们能为任何DCFL的DPDA完成这个构造,这就证明了DCFL类在补运算下是封闭的。
这个证明是高度抽象的构造,很难用一个简单的数值例子完整展示。但我们可以模拟一下“解耦”这个关键步骤:
- 原始DPDA: 识别 $\{a^n b^n \mid n \ge 1\}$。
- 一个复杂转移: $\delta(q_0, b, A) = (q_1, \varepsilon)$。这里,$q_0$是读完 $a$ 的状态,看到第一个 $b$ 时,需要弹栈。这个状态既要“看输入b”,又要“看栈顶A”,是一个“读+弹”的混合操作。
- 解耦改造:
- 引入新状态: 创建一个中间状态,叫它 $q_A$ (表示“我刚刚看到了一个A在栈顶并把它弹出了”)。
- 拆分转移:
- 旧 $\rightarrow$ 新1 (弹栈): $\delta(q_0, \varepsilon, A) = (q_A, \varepsilon)$。在 $q_0$ 状态,不看输入,只要栈顶是 $A$,就弹出它并进入 $q_A$。
- 新2 (读取): $\delta(q_A, b, \varepsilon) = (q_1, \varepsilon)$。在 $q_A$ 状态,不看栈,只要输入是 $b$,就消耗它并进入 $q_1$。
- 指定读取状态: 状态 $q_A$ 现在是一个纯粹的“读取状态”。
- 翻转: 假设 $q_A$ 在原始逻辑中(例如,如果它是第一个b)是一个非接受的读取状态。在构造补语言的DPDA时,我们就会把它标记为接受状态。这意味着,如果一个字符串在这一点上(弹出了A,看到了b)就结束了(比如输入是"ab"),在新机器里它会被接受,这正是补语言想要的行为(因为"ab"本身不是 $\{a^n b^n\}$ 的补集的一部分,但一个像 "a" 这样的前缀,它的补集行为是在读到b时就失败,所以翻转后应该接受)。这个例子很微妙,但展示了解耦和翻转的核心机制。
- 忘记第一步标准化: 如果不在一个总能读完输入的DPDA上进行后续操作,整个证明的基础就是不牢固的。因为如果机器中途卡住拒绝,交换状态并不能改变这个“卡住”的事实。
- 对“读取状态”的理解: 并非所有消耗输入的状态都是我们想要的“读取状态”。关键在于该状态的读取行为是否“纯粹”,即不依赖于弹栈。这就是为什么需要进行解耦操作。
- 状态的继承: 在解耦 $\delta(q, a, x) = (r, y)$ 时,新状态 $q_x$ 的“接受”属性应该如何确定?证明中提到,“如果 $q \in F$,则将 $q_x$ 指定为接受状态”。这其实是一个简化的说法,更准确地是, $q_x$ 的接受/非接受性质应该反映了从 $q$ 到 $q_x$ 这一步完成时,是否达到了一个接受点。
定理2.42的证明是一个精妙的构造性证明。它通过三个核心步骤将任何DPDA $P$ 转换为识别其补语言的DPDA $P'$。
- 标准化: 利用引理2.41,确保 $P$ 总能读完输入且具有“接受记忆”。
- 解耦与隔离: 通过引入新状态,将“读+弹”的混合操作分解为纯粹的“弹栈”和纯粹的“读取”两步,从而隔离出了一组“读取状态”作为唯一的“判决点”。
- 翻转: 在这些唯一的、清晰的“判决点”(读取状态)上,交换接受与非接受的身份,从而精确地反转了机器的语言识别行为。
这个过程证明了DCFL类对补运算是封闭的。
本证明的存在是为了给“DCFL对补运算封闭”这个强大的理论断言提供一个坚实的、无可辩驳的逻辑基础。它展示了计算理论中典型的证明风格:不是直接计算或推演,而是通过设计一个通用的“机器改造算法”来证明一种性质的存在性。这个证明本身就是对DPDA模型进行深入操作和理解的典范,体现了理论计算机科学的构造之美。
这就像修改一部法律的判决流程,使其能够审理“反向案件”。
- 原始法律: 规定了各种“有罪”的条件。但判决时刻很随意,法官可能在庭审的任何时候宣布有罪。
- 改造流程:
- 标准化 (步骤1): 首先规定,所有案件必须完整听证结束,不能中途退庭。
- 设立“判决时刻” (步骤2): 废除随意判决的权力。规定只有在控辩双方完成一轮完整的交叉质证后(相当于读取一个符号),法官才能敲下小木槌,就是否有罪做一个临时判断(进入读取状态)。这个敲槌子的动作本身不看证据细节(不依赖栈),只看质证是否完成。
- 审理“反向案件” (步骤3): 现在,我们要审理“无罪”案件。流程不变,只是在每个法官敲小木槌的“判决时刻”,我们把规则反过来:原来判断“有罪”的,现在判断“无罪”;原来判断“无罪”的,现在判断“有罪”。
- 由于判决时刻是唯一的、标准化的,这种翻转才能精确地得到相反的结果。
你正在重新设计一个投票系统,以计算“反对票”而不是“赞成票”。
- 旧系统: 投票者可以在会议的任何时候举手表示赞成,很混乱。
- 新设计:
- 标准化: 规定会议必须进行到底,不能中途离场。
- 设立“投票时刻”: 取消随时举手的做法。规定每当一位发言人完成发言(读取一个符号),主持人会按下一个按钮,所有投票者的投票器会同时亮起一秒钟。只有在这一秒钟内按下的才算有效投票。这个“按按钮”的动作(进入读取状态)是独立于发言内容的(不依赖栈)。
- 计算“反对票”: 现在,我们想统计反对票。系统完全一样,只是在后台服务器上,我们把逻辑反转:把所有在“投票时刻”投了“赞成”的票,都记为“反对”;没投“赞成”的,都记为“赞成”。
- 因为投票的时刻被严格地、唯一地规定了,这种简单的逻辑反转才能准确地计算出反对票总数。
1111. 定理2.42的应用与其他性质
📜 [原文11]
这个定理意味着一些 CFLs 不是 DCFLs。任何其补集不是 CFL 的 CFL 都不是 DCFL。因此,$\underline{A}=\left\{\mathrm{a}^{i} \mathrm{~b}^{j} \mathrm{c}^{k} \mid i \neq j \text{ 或 } j \neq k \text{ 其中 } i, j, k \geq 0\right\}$ 是一个 CFL 但不是 DCFL。否则 $\bar{A}$ 将是一个 CFL,那么问题 2.30 的结果将错误地暗示 $\bar{A} \cap \mathrm{a}^{*} \mathrm{~b}^{*} \mathrm{c}^{*}=\left\{\mathrm{a}^{n} \mathrm{~b}^{n} \mathrm{c}^{n} \mid n \geq 0\right\}$ 是上下文无关的。
问题 2.23 要求您证明 DCFL 类不封闭于其他熟悉的运算,例如并集、交集、星运算和逆运算。
这部分内容展示了刚刚证明的定理2.42的威力,并对DCFL的其他闭包性质做了预告。
定理的应用:证明一个CFL不是DCFL
文章的核心论证逻辑如下,这是一个经典的反证法:
- 引出推论: 首先,从定理2.42(DCFL对补运算封闭)得出一个直接的推论:“任何其补集不是CFL的CFL都不是DCFL”。
- 为什么? 假设有一个语言 $L$,它本身是CFL,但它的补集 $\bar{L}$ 不是CFL。现在我们用反证法证明 $L$ 不是DCFL。
- 假设 $L$ 是 DCFL。
- 根据定理2.42,如果 $L$ 是DCFL,那么 $\bar{L}$ 也必须是DCFL。
- 我们知道,所有DCFL都是CFL(因为DPDA是NPDA的特例)。所以,如果 $\bar{L}$ 是DCFL,那么它也必然是CFL。
- 这就产生了矛盾!我们已知的前提是 $\bar{L}$ 不是CFL。
- 因此,最初的假设“$L$是DCFL”是错误的。
- 结论: $L$ 不是DCFL。
- 应用实例: 文章将这个强大的推论应用到了一个具体的语言上。
- 目标语言: $A = \{a^i b^j c^k \mid i \ne j \text{ or } j \ne k, \text{ where } i,j,k \ge 0\}$。这个语言是CFL(可以构造一个NPDA来识别它,它需要非确定性地猜测是验证 $i \ne j$ 还是 $j \ne k$)。
- 证明:
DCFL的其他非闭包性质
最后,文章作为一个练习题或者预告,指出了DCFL类不像正则语言那样“完美”。虽然它对补运算封闭,但它在其他一些常见的运算下是不封闭的,包括:
- 并集 (Union)
- 交集 (Intersection)
- 星运算 (Kleene Star)
- 逆运算 (Reversal)
这意味着,你可以找到两个DCFL,它们的并集或交集不再是DCFL(而只是一个普通的、非确定性的CFL)。
- DCFL对并集不封闭的例子:
- $L_1 = \{a^i b^j c^k \mid i=j, i,j,k \ge 0\}$。这是一个DCFL。DPDA可以数 $a$ 压栈,然后用 $b$ 销账,忽略 $c$。
- $L_2 = \{a^i b^j c^k \mid j=k, i,j,k \ge 0\}$。这也是一个DCFL。DPDA可以忽略 $a$,然后数 $b$ 压栈,用 $c$ 销账。
- $L_1 \cup L_2 = \{a^i b^j c^k \mid i=j \text{ or } j=k\}$。我们在前面已经知道(或可以证明)这个语言不是DCFL,因为它需要非确定性地猜测是验证 $i=j$ 还是 $j=k$。
- 这个例子表明,两个DCFL的并集不一定是DCFL。
- DCFL对交集不封闭的例子:
- DCFL对交集也不封闭。虽然如果一个语言 $L$ 是DCFL,它的补集 $\bar{L}$ 也是DCFL。如果DCFL对交集也封闭,那么根据德摩根定律 $L_1 \cup L_2 = \overline{\bar{L_1} \cap \bar{L_2}}$,DCFL就必须对并集也封闭,这与上面的例子矛盾。所以DCFL对交集不封闭。
- 混淆闭包性质: 学生很容易记混不同语言类的闭包性质。制作一个表格来对比正则语言、DCFL、CFL和递归可枚举语言等的闭包性会很有帮助。
- 交集和并集: CFL对并集封闭,但对交集和补集不封闭。DCFL对补集封闭,但对并集和交集不封闭。这是一个非常鲜明的对比。
- 证明的严谨性: 在应用“交集”技巧时,要记住是“CFL与正则语言的交集是CFL”,而不是“两个CFL的交集是CFL”(后者不成立)。在上面的证明中,$a^*b^*c^*$ 正是一个正则语言,所以这一步是合法的。
本段是定理2.42的直接应用。它首先推导出一个重要的判别准则:如果一个CFL的补集不是CFL,那么它肯定不是DCFL。然后,它运用这个准则,结合CFL与正则语言交集的闭包性,成功地证明了语言 $A = \{a^i b^j c^k \mid i \ne j \text{ or } j \ne k\}$ 虽然是CFL,但不是DCFL。最后,它指出了DCFL类在并集、交集、星运算和逆运算下是不封闭的,揭示了其相比于正则语言在代数性质上的“不完美”。
本段的目的是展示理论的实践价值。定理2.42不再是一个孤立的数学结论,而是变成了一把可以用来解剖和分类语言的“手术刀”。通过一个具体的、非平凡的例子,本段让读者亲眼看到理论工具是如何被用来解决实际问题的,这极大地加深了对定理本身重要性的理解,并巩固了多个相关知识点(补集、交集、闭包性、泵引理结论等)。
这就像是用“基因检测”来做“亲子鉴定”。
- 定理2.42: 告诉你“DCFL家族”有一个独特的遗传标记:“补集”基因也是“DCFL”型的。
- 待检测语言 A: 一个疑似“DCFL家族”成员的语言。
- 检测过程:
- 我们不对 A 本身做检测,而是检测它的“反面”——$\bar{A}$。
- 我们发现,$\bar{A}$ 的一个近亲($\bar{A} \cap a^*b^*c^*$)携带一个明确的“非CFL”遗传病($\{a^n b^n c^n\}$)。
- 因为“非CFL”比“非DCFL”还要严重,这说明 $\bar{A}$ 的基因肯定不是“DCFL”型的。
- 结论: 根据“亲子鉴定”法则(定理2.42),既然 $\bar{A}$ 没有“DCFL”基因,那么 A 也绝对不可能是“DCFL家族”的成员。
你是一名侦探,正在调查一个案件。
- 定理2.42: 你有一条铁证如山的线索:“如果嫌疑人是‘确定帮’(DCFL)的成员,那么他的‘影子’(补集)也一定是‘确定帮’的成员。”
- 嫌疑人 L: 一个语言L,它有“上下文无关帮”(CFL)的背景,但你想知道它是不是更核心的“确定帮”成员。
- 调查: 你不去直接调查 L,而是去调查它的“影子” $\bar{L}$。你在影子的活动区域($\Sigma^*$)里,找到了一个与“正则帮”(正则语言)的交叉点(交集),在这个交叉点发现了一具尸体($\{a^n b^n c^n\}$)。法医鉴定(泵引理)报告说,这具尸体的特征表明,它绝对不属于“上下文无关帮”。
- 推理: 既然尸体连“上下文无关帮”的都不是,那么发现尸体的这个“影子”$\bar{L}$,也就不可能是更高级的“确定帮”成员了。
- 破案: 根据你的铁证线索,既然影子不是“确定帮”的,那么嫌疑人 L 本人也肯定不是“确定帮”的成员。案件告破!
1212. 带结束标记的DPDA
📜 [原文12]
为了简化论证,我们偶尔会考虑带结束标记的输入,其中特殊结束标记符号 $\dashv$ 附加到输入字符串的末尾。在这里,我们将 $\dashv$ 添加到 DPDA 的输入字母表中。正如我们在下一个定理中所示,添加结束标记不会改变 DPDA 的能力。然而,设计带结束标记输入的 DPDA 通常更容易,因为我们可以利用知道输入字符串何时结束的优势。对于任何语言 $A$,我们用带结束标记语言 $A \dashv$ 表示字符串 $w \dashv$ 的集合,其中 $w \in A$。
定理 2.43
$A$ 是一个 DCFL 当且仅当 $A \dashv$ 是一个 DCFL。
这部分引入了一个非常实用的技术工具——结束标记 (end-marker),并提出了一个关于它的重要定理。
引入“结束标记”
- 是什么: 结束标记是一个特殊的、不会出现在原始语言中的符号(这里用 $\dashv$ 表示,可以想象成一个向下的箭头或者一个句号)。我们将这个符号附加在每个输入字符串的末尾。
- 例子: 如果原始语言 $A = \{ "ab", "abc" \}$,那么带结束标记的语言 $A \dashv$ 就是 $\{ "ab\dashv", "abc\dashv" \}$。
- 技术处理: 为了让DPDA能处理这个新符号,我们需要把它加入到输入字母表 $\Sigma$ 中。
为什么引入结束标记?
文章指出了核心原因:“设计带结束标记输入的DPDA通常更容易”。
- 优势: 一个普通的DPDA在处理输入时,每一步都不知道自己是不是在处理最后一个符号。它只能通过“下一个输入是空”来判断输入结束。但结束标记提供了一个明确的信号。当DPDA读取到 $\dashv$ 时,它就确切地知道“正文内容到此结束,现在是做最终检查和清算的时候了”。
- 应用: 这个“知道结束”的能力非常强大。例如,在接受前,DPDA可以利用这个结束信号来清空栈、检查栈的状态,或者进行一些最终的确认操作,而不用担心后面还有意外的输入。这使得DPDA的设计逻辑可以更清晰、更简单。
定理 2.43 的陈述
“$A$ 是一个 DCFL 当且仅当 $A \dashv$ 是一个 DCFL。”
- 这是一个“当且仅当”的命题: 意味着它包含两个方向的证明。
- 正向 ($\Rightarrow$): 如果语言 $A$ 是一个DCFL,那么给它的每个字符串末尾加上 $\dashv$ 后得到的新语言 $A \dashv$ 也一定是DCFL。
- 反向 ($\Leftarrow$): 如果带结束标记的语言 $A \dashv$ 是一个DCFL,那么去掉结束标记后的原始语言 $A$ 也一定是DCFL。
- 定理的含义: 这个定理的本质是说,添加或移除结束标记,不会改变一个语言是否是‘确定性上下文无关’这一根本属性。它告诉我们,结束标记只是一个方便设计的“拐杖”,它不会增强或削弱DPDA的内在识别能力。
定理的重要性
这个定理赋予了我们在设计和证明中极大的自由。当我们需要证明某个语言 $A$ 是DCFL时,如果直接构造识别 $A$ 的DPDA很困难,我们可以退一步,去尝试构造一个识别 $A \dashv$ 的DPDA。因为识别 $A \dashv$ 通常更容易,只要我们成功了,根据定理2.43,我们就可以直接断言 $A$ 也是DCFL。反之亦然。这个定理就像一个合法的“作弊”工具,让我们可以选择更容易的战场。
- 示例1: 利用结束标记简化设计
- 语言 A: $\{ w \in \{a,b\}^* \mid w \text{ 中a的数量等于b的数量} \}$。这是一个经典的DCFL。
- 不带结束标记的DPDA设计:
- 看到'a'压'A',看到'b',如果栈顶是'A'就弹出。
- 看到'b'压'B',看到'a',如果栈顶是'B'就弹出。
- 栈空时看到'a'压'A',看到'b'压'B'。
- 输入结束后,需要检查栈是否为空。这个“检查”需要通过 $\varepsilon$ 移动来完成,而且要在读完输入后才能触发。
- 带结束标记的DPDA设计 ($A \dashv$):
- 与上面逻辑相同。
- 当读取到结束标记 $\dashv$ 时,我们进入一个“最终检查”状态。
- 在这个状态里,我们检查栈。如果栈顶是栈底符号 $,说明不多不少,我们转移到接受状态。如果栈里还有'A'或'B',说明数量不等,我们转移到拒绝状态。
- 这个逻辑非常清晰:用 $\dashv$ 作为明确的触发器来执行收尾工作。
- 示例2: 从 $A \dashv$ 推断 A
- 假设我们已经成功为 $A \dashv$ 设计了一个DPDA,记为 $M_{\dashv}$。
- 根据定理2.43,我们知道 $A$ 肯定是DCFL。我们不需要真的去构造识别 $A$ 的DPDA $M_A$ 也能得出这个结论。
- (后面证明思路会讲如何具体构造 $M_A$:$M_A$ 会在内部“模拟”$M_{\dashv}$,并且在每一步都“假装”下一个输入是 $\dashv$,看看 $M_{\dashv}$ 会不会接受,从而决定自己当前是否应该处于接受状态。)
- $\dashv$ 不是语言的一部分: 结束标记是一个外部添加的、用于辅助分析的工具符号,它不属于原始语言 $A$ 的字母表。
- 能力不变,难度变: 定理的核心是DPDA的理论“能力”不变。但在实践中,设计的“难度”确实降低了。不要混淆这两点。
- “当且仅当”的重要性: 理解双向箭头 $\Leftrightarrow$ 的含义至关重要。它表明这是一种本质上的等价关系,而不是单向的推导。
本节引入了结束标记 $\dashv$ 这一辅助工具。它是一个附加在输入字符串末尾的特殊符号,通过明确地告知DPDA输入何时结束,从而简化了DPDA的设计。核心结论是定理2.43,它声明一个语言 $A$ 是DCFL与它的带结束标记版本 $A \dashv$ 是DCFL互为充要条件。这个定理的意义在于,它证明了结束标记只是一个方便的构造技巧,不改变语言的DCFL本质,因此允许我们在证明和设计中自由地使用或移除它。
本段和定理2.43的存在,是为了给后续更复杂的构造(特别是DPDA和DCFG之间的转换)提供一个更便利的工作平台。很多关于DPDA的精妙构造,在“知道输入何时结束”这个前提下会变得更容易表述和理解。这个定理就是为了合法化这个“便利前提”,告诉我们这样做在理论上是等价和安全的。
这就像给一本书加上了“The End”这一页。
- 没有“The End”的书 (普通输入): 你读到最后一页的最后一个字,书就突然结束了。你可能需要回想一下整本书的情节才能判断它是不是一个好故事。
- 有“The End”的书 (带结束标记): 在故事结束后,有一页白纸,上面写着大大的“The End”。当你看到这一页时,你知道故事已经讲完,现在是你可以写读后感、做总结的时候了。你可以从容地回顾整个故事,给出你的最终评价。
- 定理2.43: 这个定理说,一本书是不是“确定性的好故事”(DCFL),和它最后有没有那一页“The End”没有关系。书的内在品质决定了这一点。但对于读者(DPDA设计者)来说,有那一页“The End”能让写读后感的过程更从容、更有条理。
你正在参加一场考试。
- 普通考试: 监考老师在考试结束时会突然喊“停笔!”。你必须在那一瞬间停下,你手头的题目可能只写了一半。
- 带结束标记的考试: 考试手册上说:“最后1分钟,你将收到一张红色卡片(结束标记 $\dashv$)。收到卡片后,不允许再做新题,但你可以用这一分钟时间来检查你的姓名、准考证号,并整理卷面。”
- 定理2.43: 你最终的考试成绩(语言是否被接受)取决于你真正掌握的知识,而不是最后有没有那1分钟的整理时间。那1分钟的整理时间只是让考试流程更人性化、更不容易出错(DPDA设计更容易),但它不会让你从不及格变成及格。一个学生是不是学霸(语言是不是DCFL),和考试最后有没有发红色卡片无关。
1313. 定理2.43的证明
📜 [原文13]
证明思路 证明这个定理的正向是常规的。假设 DPDA $P$ 识别 $A$。那么 DPDA $P^{\prime}$ 识别 $A \dashv$,通过模拟 $P$ 直到 $P^{\prime}$ 读取 $\dashv$。此时,$P^{\prime}$ 接受,如果 $P$ 在前一个符号期间进入了接受状态。$P^{\prime}$ 在 $\dashv$ 之后不读取任何符号。
为了证明反向,让 DPDA $P$ 识别 $A \dashv$,并构造一个 DPDA $P^{\prime}$ 来识别 $A$。当 $P^{\prime}$ 读取其输入时,它模拟 $P$。在读取每个输入符号之前,$P^{\prime}$ 确定如果该符号是 $\dashv$, $P$ 是否会接受。如果是, $P^{\prime}$ 进入接受状态。请注意,$P$ 在读取 $\dashv$ 后可能会操作栈,因此确定它在读取 $\dashv$ 后是否接受可能取决于栈内容。当然,$P^{\prime}$ 不能在每个输入符号处弹出整个栈,因此它必须确定 $P$ 在读取 $\dashv$ 后会做什么,但不能弹出栈。相反,$P^{\prime}$ 在栈上存储额外的信息,允许 $P^{\prime}$ 立即确定 $P$ 是否会接受。这些信息表明 $P$ 会从哪些状态最终接受,同时(可能)操纵栈,但不再读取更多的输入。
证明 我们只给出反向的证明细节。如我们在证明思路中所述,令 DPDA $P=\left(Q, \Sigma \cup\{\dashv\}, \Gamma, \delta, q_{0}, F\right)$ 识别 $A \dashv$,并构造一个 DPDA $P^{\prime}=\left(Q^{\prime}, \Sigma, \Gamma^{\prime}, \delta^{\prime}, q_{0}{ }^{\prime}, F^{\prime}\right)$ 来识别 $A$。首先,修改 $P$,使其每个移动都只执行以下操作之一:读取一个输入符号;将一个符号压入栈;或将一个符号从栈中弹出。通过引入新状态,进行此修改是直接的。
$P^{\prime}$ 模拟 $P$,同时在栈上维护其栈内容的副本,并交错有附加信息。每当 $P^{\prime}$ 压入 $P$ 的一个栈符号时,$P^{\prime}$ 都会紧接着压入一个表示 $P$ 状态子集的符号。因此,我们设置 $\Gamma^{\prime}=\Gamma \cup \mathcal{P}(Q)$。 $P^{\prime}$ 中的栈交错包含 $\Gamma$ 的成员和 $\mathcal{P}(Q)$ 的成员。如果 $R \in \mathcal{P}(Q)$ 是栈顶符号,那么通过在 $P$ 的任何一个状态中启动 $P$, $P$ 最终将在不读取任何更多输入的情况下接受。
最初,$P^{\prime}$ 将集合 $R_0$ 压入栈中,$R_0$ 包含每个状态 $q$,使得当 $P$ 在空栈的状态 $q$ 启动时,它最终会在不读取任何输入符号的情况下接受。然后 $P^{\prime}$ 开始模拟 $P$。为了模拟弹出移动,$P^{\prime}$ 首先弹出并丢弃作为栈顶符号出现的状态集合,然后再次弹出以获得 $P$ 在此时会弹出的符号,并使用它来确定 $P$ 的下一个移动。模拟压入移动 $\delta(q, \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon})=(r, x)$,其中 $P$ 在从状态 $q$ 到状态 $r$ 的过程中压入 $x$,如下进行。首先 $P^{\prime}$ 检查栈顶的状态集合 $R$,然后它压入 $x$,之后压入集合 $S$,其中 $q \in S$ 如果 $q \in F$ 或者如果 $\delta(q, \varepsilon, x)=(r, \varepsilon)$ 并且 $r \in R$。换句话说,$S$ 是那些要么立即接受,要么在弹出 $x$ 后会导致状态 $R$ 的状态集合。最后,$P^{\prime}$ 模拟读取移动 $\delta(q, a, \varepsilon)=(r, \varepsilon)$,通过检查栈顶的集合 $R$ 并在 $r \in R$ 时进入接受状态。如果 $P^{\prime}$ 在进入此状态时处于输入字符串的末尾,它将接受输入。如果它不在输入字符串的末尾,它将继续模拟 $P$,因此此接受状态还必须记录 $P$ 的状态。因此,我们将此状态创建为 $P$ 原始状态的第二个副本,并将其标记为 $P^{\prime}$ 中的接受状态。
这部分是定理2.43的证明。它分为两个方向,但重点阐述了更复杂的反向证明。
正向证明 ($\Rightarrow$) 的思路
- 目标: 证明如果 $A$ 是DCFL,那么 $A \dashv$ 也是DCFL。
- 思路: 这个方向比较直接。假设我们有一个识别 $A$ 的DPDA,记为 $P_A$。我们可以构造一个识别 $A \dashv$ 的新DPDA,记为 $P_{A\dashv}$。
- 构造:
- $P_{A\dashv}$ 基本上就是模拟 $P_A$ 的所有行为来处理输入字符串 $w$ 的部分。
- 当 $P_{A\dashv}$ 读取到结束标记 $\dashv$ 时,它停止模拟。
- 此时,它检查 $P_A$ 在处理完 $w$ 的最后一个字符后,是否处于一个接受状态。
- 如果是,那么 $P_{A\dashv}$ 就进入一个接受状态。否则,进入拒绝状态。
- 结论: 这个构造是确定性的,所以 $A \dashv$ 也是DCFL。这个方向的证明相对简单,所以原文省略了细节。
反向证明 ($\Leftarrow$) 的思路 (重点)
- 目标: 证明如果 $A \dashv$ 是DCFL,那么 $A$ 也是DCFL。这是更难的一方。
- 挑战: 假设我们有识别 $A \dashv$ 的DPDA,记为 $P_{A\dashv}$。我们要构造一个识别 $A$ 的DPDA $P_A$。$P_A$ 在处理输入 $w$ 时,没有结束标记 $\dashv$ 可用。但是,它的接受/拒绝行为必须和 $P_{A\dashv}$ 处理 $w\dashv$ 的结果一致。这意味着 $P_A$ 在读完 $w$ 的最后一个字符时,必须能“预测”出如果此时给 $P_{A\dashv}$ 一个 $\dashv$,它最终会接受还是拒绝。
- 核心问题: 这个“预测”很困难。因为 $P_{A\dashv}$ 在看到 $\dashv$ 后,可能会进行一系列依赖于当前栈内容的 $\varepsilon$ 移动。$P_A$ 为了做出预测,似乎需要知道整个栈的内容,但它不能为了预测就把栈清空,否则后续计算就无法进行了。
- 解决方案 (天才之处): $P_A$ 不需要真的去模拟 $P_{A\dashv}$ 的后续步骤。它采用一种“信息增强”的策略。$P_A$ 的栈不仅存储 $P_{A\dashv}$ 的栈内容,还额外存储一些预计算好的信息。这些信息能够让 $P_A$ 立即知道预测结果。
- 额外信息是什么?: 在栈的每一个“层级”上,都附带一个状态集合。这个集合的含义是:“如果 $P_{A\dashv}$ 的计算进行到这里,并且此时输入突然结束(即看到 $\dashv$),那么从这个集合中的哪些状态出发,最终能够(只通过 $\varepsilon$ 移动)达到接受状态?”
- 如何工作: $P_A$ 在模拟 $P_{A\dashv}$ 的每一步时,不仅更新模拟的栈,还同步更新这个附带的状态集合。当 $P_A$ 读取一个真实输入符号时,它会查看当前栈顶附带的状态集合,如果它模拟的 $P_{A\dashv}$ 的下一步状态恰好在这个集合里,那就意味着“如果输入到此结束,就能接受”。于是,$P_A$ 就会进入一个接受状态。
形式化证明细节的解释 (反向)
- 标准化: 首先,对已有的 $P_{A\dashv}$ 做一些标准化处理,比如将每个转移分解为纯粹的“读”、“压”、“弹”三种基本操作。这使得后续的模拟和信息更新更容易定义。
- 增强的栈: $P_A$ 的栈字母表 $\Gamma'$ 是原始栈字母表 $\Gamma$ 和 $Q$ 的所有子集(幂集 $\mathcal{P}(Q)$)的并集。$P_A$ 的栈看起来像这样:$[\text{原始符号}_1, \text{状态集}_1, \text{原始符号}_2, \text{状态集}_2, ...]$。
- 状态集的含义: 栈顶的状态集 $R$ 代表了一个“承诺”:如果 $P_{A\dashv}$ 的状态 $q$ 在 $R$ 中,那么从配置 $(q, \text{当前栈})$ 开始,只进行 $\varepsilon$ 移动(模拟看到 $\dashv$ 后的行为),最终能被接受。
- 初始化: $P_A$ 启动时,压入一个初始的状态集合 $R_0$。$R_0$ 包含所有那些在 $P_{A\dashv}$ 中,即使栈是空的,也能仅通过 $\varepsilon$ 移动达到接受状态的起始状态。
- 模拟弹出: 当 $P_A$ 需要模拟 $P_{A\dashv}$ 的一次弹栈时,它实际上要弹出两次:第一次弹出顶部的状态集(丢弃),第二次弹出真正的原始符号。
- 模拟压栈: 这是最复杂的部分。当 $P_{A\dashv}$ 要压入一个符号 $x$ 时, $P_A$ 不仅要压入 $x$,还要计算并压入一个新的状态集合 $S$。这个 $S$ 是如何计算的呢?
- 一个状态 $q$ 会被放入 $S$ 中,需要满足以下条件之一:
- 这个计算是自底向上的,保证了状态集信息的正确传递。
- 做出接受/拒绝决定: 当 $P_A$ 模拟 $P_{A\dashv}$ 读取一个输入符号 $a$ 时,它会检查 $P_{A\dashv}$ 将要进入的新状态 $r$。然后,它查看当前栈顶的状态集 $R$。如果 $r \in R$,那么 $P_A$ 就知道“此刻可以接受”。于是 $P_A$ 进入一个特殊的接受状态。
- 这个特殊的接受状态需要“记住”当前模拟到哪了,所以它实际上是原始状态的一个副本,即 $(q_{original}, \text{is_accepting})$。
- 如果此时输入恰好结束,那么 $P_A$ 就接受了。如果输入还没结束,它会继续模拟,但它已经处于一个接受状态中了。
这个证明的构造极为抽象,很难用简单的数值例子来说明,但我们可以尝试描绘其核心思想:
- 语言 A: $\{a\}$
- 带结束标记语言 A$\dashv$: $\{a\dashv\}$
- 一个简单的 $P_{A\dashv}$:
- $\delta(q_0, a, \$) = (q_1, \$)$
- $\delta(q_1, \dashv, \$) = (q_f, \varepsilon)$, 其中 $q_f$ 是接受状态。
- 构造 $P_A$ 来识别 A:
- $P_A$ 的栈: 它会存储类似 $[\$, R_0, \text{...}]$ 的东西。
- 计算 $R$: 我们需要预计算。例如,对于状态 $q_1$,如果接下来是 $\dashv$,它会进入 $q_f$ 并接受。所以,在模拟 $P_{A\dashv}$ 进入 $q_1$ 时,$P_A$ 栈顶的状态集里就会包含 $q_1$。
- $P_A$ 的模拟:
- $P_A$ 读入 'a'。它模拟 $P_{A\dashv}$ 的 $\delta(q_0, a, \$)$,使其内部模拟状态变为 $q_1$。
- 此时,$P_A$ 查看它维护的栈顶状态集 $R$。它发现 $q_1 \in R$。
- 这告诉 $P_A$:“如果输入就此结束,原机器是会接受的!”
- 于是,$P_A$ 进入一个接受状态。
- 由于输入 'a' 此时确实结束了,所以 $P_A$ 接受 'a'。成功!
- 构造的复杂性: 这个证明是出了名的难以完全手动实现。关键在于理解其思想:通过在栈上存储“未来可能接受的状态集”来代替实际的模拟。
- 信息的更新: 状态集的计算和更新是整个构造中最核心也最容易出错的部分。它是一种动态规划或自底向上的信息传播过程。
- 接受状态的定义: $P_A$ 的接受状态与 $P_{A\dashv}$ 的接受状态没有直接关系。$P_A$ 是否接受,取决于它在读取输入时,根据其增强栈所做的“预测”是否成功。
定理2.43的证明分为两个方向。简单的正向证明指出,可以通过模拟并在看到结束标记时检查状态来将识别 $A$ 的DPDA转换为识别 $A \dashv$ 的DPDA。困难的反向证明则展示了如何将识别 $A \dashv$ 的DPDA $P_{A\dashv}$ 转换为识别 $A$ 的DPDA $P_A$。其核心技术是一种“信息增强栈”:$P_A$ 在模拟 $P_{A\dashv}$ 的同时,在栈上维护一个预计算的“未来可接受状态集”,使得它在每一步都能立即“预测”出如果输入在此刻结束,是否能够被接受,从而决定自身的接受状态,而无需真正看到结束标记。
本证明的目的是为定理2.43的两个方向都提供严格的、构造性的论证。尤其是对于反向证明,它展示了一种非常高级和通用的模拟技术:当一个机器(A)需要模拟另一个机器(B)的未来行为,但又不能实际执行时,可以通过在自己的数据结构中“缓存”或“预计算”B的某些性质来实现。这种思想在计算理论和算法设计中都具有重要意义。
这就像一个高水平的棋手在下盲棋。
- $P_{A\dashv}$: 一个正常的棋手,看着棋盘下棋。他在最后一步(看到 $\dashv$)将军吃掉对方的王,赢了。
- $P_A$ (下盲棋的棋手): 他看不到棋盘,只能通过口述来模拟棋局。他没有“最后一步”(没有 $\dashv$)。
- 他的策略 (信息增强栈): 他不仅在大脑里记住了当前棋子的位置(模拟的栈),他还在大脑的另一个区域(增强信息)为棋盘上的每个棋子标注了一个“威胁值”或“潜力值”(状态集)。这个值是他预先计算好的,代表了“如果棋局在此刻突然结束,这个子有多大可能成为致胜的关键”。
- 做决定: 在每一步棋后,他不仅更新棋子位置,还重新计算所有棋子的“潜力值”。他通过查看当前关键棋子的“潜力值”来判断自己是否处于“胜势”。如果潜力值足够高(模拟的状态在状态集里),他就在自己的计分板上记为“优势”(进入接受状态)。这样,即使没有真正的“最后一步”,他也能在棋局的任何阶段评估自己的胜算。
你正在驾驶一艘没有油量表的潜艇 ($P_A$),要去完成一项任务。但设计图纸是为一艘有油量表的姊妹舰 ($P_{A\dashv}$) 设计的。
- 姊妹舰 $P_{A\dashv}$: 它的任务手册说:“当你到达目标点后,检查油量表(看到 $\dashv$)。如果油量高于5%,任务成功。”
- 你的困境: 你没有油量表。你怎么知道到达目标点时,油量是否高于5%?
- 你的解决方案 (信息增强栈): 你是一个天才工程师。你在潜艇里安装了一套复杂的声纳和引擎监控系统。这套系统(增强信息)并不能直接告诉你油量,但它能根据你已经航行的距离、引擎的功率输出、当前的水流等信息,实时计算出一个“理论剩余油量百分比区间”(状态集)。
- 执行任务: 你一边按照姊妹舰的任务手册开船(模拟),一边看着你的监控系统。当你到达目标点时,你看了一眼监控系统,它告诉你“理论剩余油量在[10%, 15%]之间”。因为这个区间完全在5%以上,你就可以自信地宣布“任务成功”(进入接受状态),而根本不需要一个真实的油量表。
1414. 确定性上下文无关文法介绍
📜 [原文14]
确定性上下文无关文法
本节定义确定性上下文无关文法,它是确定性下推自动机的对应物。我们将证明这两个模型在能力上是等价的,前提是我们只关注带结束标记的语言,其中所有字符串都以 $\dashv$ 终止。因此,这种对应关系不如我们在正则表达式和有限自动机,或在 CFG 和 PDA 中看到的那样强,后者中的生成模型和识别模型在不需要结束标记的情况下描述了完全相同的语言类。然而,在 DPDA 和 DCFG 的情况下,结束标记是必要的,因为如果没有这个限制,等价性就不成立。
这段引言部分为我们介绍了本节的第二个主角——确定性上下文无关文法 (Deterministic Context-Free Grammar, DCFG),并阐明了它与DPDA之间的关系以及这种关系的特殊性。
- DCFG的身份:
- 定义: DCFG是DPDA在“文法”世界里的对应物。正如CFL由CFG生成、由PDA识别一样,我们期望DCFL由DCFG生成、由DPDA识别。
- 这个“对应”关系是本节的核心,作者将要证明这两个模型(DCFG和DPDA)在识别/生成语言的能力上是等价的。
- 一个重要的前提条件:
- 等价性的限制: DPDA和DCFG的等价性并不是无条件的。它成立的前提是,我们只考虑带结束标记的语言。这意味着我们讨论的所有字符串都必须以一个特殊的符号 $\dashv$ 结尾。
- 为什么需要这个限制?: 作者在这里埋下了一个伏笔,指出如果没有这个限制,DPDA和DCFG之间的等价关系就不成立。这暗示了DPDA在处理输入结束时的一些微妙行为,需要结束标记 $\dashv$ 来帮助文法模型(DCFG)进行精确的匹配。
- 与其它模型的对比:
- 更强的对应关系: 作者将 DPDA-DCFG 的关系与我们之前学过的两组“完美搭档”进行了对比:
- 正则表达式 (Regex) vs 有限自动机 (FA): 这两者是完全等价的。任何正则语言都可以用正则表达式描述,也都可以用DFA或NFA识别。它们之间不需要任何额外的“拐杖”(如结束标记)。
- 上下文无关文法 (CFG) vs 下推自动机 (PDA): 这两者也是完全等价的。任何CFL都可以由一个CFG生成,也都可以由一个NPDA识别。它们之间的转换和等价性证明也不需要结束标记。
- 较弱的对应关系: 相比之下,DPDA和DCFG的对应关系被描述为“不那么强”。这个“弱”就体现在它对结束标记的依赖上。这说明确定性这个约束给模型带来了某种结构上的微妙差异,使得生成模型(文法)和识别模型(自动机)不能像在非确定性世界或更简单的正则世界里那样“无缝”对接。
这段是概念性介绍,不涉及具体计算,但我们可以用语言例子来理解“结束标记”的必要性。
- 一个需要结束标记的例子 (可能): 考虑语言 $L = \{a^n b^n \mid n \ge 1\} \cup \{a^n b^{2n} \mid n \ge 1\}$。我们知道这不是一个DCFL。但是,如果我们考虑带结束标记的语言 $L' = \{1w\dashv \mid w \in \{a^n b^n\}\} \cup \{2w\dashv \mid w \in \{a^n b^{2n}\}\}$。这个新的语言 $L'$ 是一个DCFL,因为开头的 '1' 或 '2' 明确地告诉了DPDA应该采用哪种匹配策略。而结束标记 $\dashv$ 则明确地告诉它何时检查栈是否为空。这个例子展示了标记(无论是开始还是结束)如何帮助实现确定性。DCFG和DPDA之间的等价性问题,也与这种对明确边界信号的依赖有关。
- 误认为DCFG就是无歧义文法: 所有的DCFG都必须是无歧义的,但反过来不成立。一个文法可能是无歧义的,但仍然不是DCFG。DCFG的要求比无歧义更严格。后面会讲到,它要求在“自底向上”归约的每一步都是确定性的。
- 忽略结束标记的重要性: 在处理DPDA和DCFG相关问题时,一定要注意题目或上下文是否假设了结束标记的存在。这直接关系到你能否应用它们之间的等价性定理。
本段介绍了确定性上下文无关文法 (DCFG),它是DPDA的生成模型对应物。作者预告了将证明DCFG和DPDA在能力上是等价的,但特别强调了这个等价性有一个重要前提:只适用于带结束标记的语言。这种对结束标记的依赖,使得DCFG-DPDA的对应关系不如Regex-FA或CFG-PDA的对应关系那样“完美”或“直接”。
本段的目的是设定本节后半部分的研究舞台和边界。它明确了:
- 研究对象: DCFG。
- 核心任务: 证明DCFG与DPDA的等价性。
- 关键约束: 这个等价性依赖于结束标记。
通过预先声明这个约束,作者管理了读者的预期,并为后续定义和证明中出现 $\dashv$ 符号提供了理由。
这就像在比较两种不同的建筑方法。
- FA/Regex 和 PDA/CFG: 这就像是“设计图纸”(文法/正则)和“施工队”(自动机)之间的关系。对于常规建筑,图纸和施工队的语言是完全通用的,不需要额外约定。
- DPDA/DCFG: 这就像是在建造一座需要极高精度的“精密仪器”。
- DPDA (施工队): 这支施工队非常“死板”,每一步都必须有明确指令,而且他们习惯于在所有建材都运到后(读完输入),最后再根据一个“项目结束”的旗帜($\dashv$)来进行最终的质检。
- DCFG (设计图纸): 为了能和这支死板的施工队合作,设计图纸也必须画得极其明确,并且图纸的最后必须有一页明确标明“全图结束”($\dashv$),这样施工队才能正确理解并完成整个项目。
- 对应关系: 只有在这种双方都依赖“结束标记”的约定下,图纸和施工队才能完美匹配。
你正在写一封非常重要的信,并把它交给一个只会严格按指令执行的机器人邮差。
- PDA/CFG: 你写完信,交给一个聪明的邮差。他能自己判断信在哪里结束,然后把它送到目的地。
- DPDA/DCFG:
- 邮差 (DPDA): 这个机器人邮差非常机械。它会一个字一个字地读信,但它不知道什么时候信结束了。你必须在信的末尾明确地写上一个特殊的符号“【信件结束】”($\dashv$)。当它看到这个符号,它才知道“哦,信读完了,我可以去送信了”。
- 你写的信 (DCFG): 为了配合这个机器人,你的写作风格(文法)也必须非常“确定”。更重要的是,你写的每一封信都必须以“【信件结束】”结尾。
- 等价性: 只有在你写的信(DCFG)和机器人邮差(DPDA)都遵循这个“必须有结束标记”的规则时,你的信才能被准确无误地投递。
1515. 确定性文法的归约方法
📜 [原文15]
在确定性自动机中,计算的每一步都决定了下一步。自动机不能对如何进行做出选择,因为在每一点上只有一个可能性。为了在文法中定义确定性,我们观察到自动机中的计算对应于文法中的推导。在确定性文法中,推导是受约束的,正如您将看到的。
CFG 中的推导从开始变量开始,通过一系列根据文法规则的替换“自上而下”进行,直到推导得到一个终结符串。为了定义 DCFG,我们采取“自下而上”的方法,从一个终结符串开始,然后反向处理推导,采用一系列规约步骤,直到达到开始变量。每个规约步骤都是一个反向替换,其中规则右侧的终结符和变量字符串被相应左侧的变量替换。被替换的字符串称为规约字符串。我们将整个反向推导称为归约 (reduction)。确定性上下文无关文法是根据具有特定属性的归约定义的。
这段内容引入了定义确定性上下文无关文法 (DCFG) 的核心视角——自下而上 (bottom-up) 的归约 (reduction) 过程。
类比与视角转换
- 自动机的确定性: 首先,文章回顾了“确定性”在自动机中的直观含义:每一步的计算都是唯一确定的,没有选择。
- 文法的确定性: 为了将这个概念移植到文法中,作者建立了一个类比:自动机的“计算”过程,对应于文法的“推导”过程。因此,一个确定性文法的“推导”过程也必须是受到严格约束的。
- 视角的根本转变:
- 常规CFG视角 (自上而下): 我们通常从开始变量 $S$ 出发,像一棵树从根向叶生长一样,不断应用规则(如 $A \rightarrow \alpha$)来替换变量,直到得到一串终结符。这个过程称为推导 (derivation)。例如: $S \Rightarrow aAb \Rightarrow a(cd)b \Rightarrow acdb$。
- DCFG的新视角 (自下而上): 为了定义确定性,我们反过来看这个过程。我们从最终的终结符串(树叶)开始,一步步地把小的结构“收缩”或“组合”成更大的结构(变量),直到最终回到开始变量(树根)。这个逆过程称为归约 (reduction)。例如: $acdb \Leftarrow a(cd)b \Leftarrow aAb \Leftarrow S$。
归约的核心概念
- 归约步骤 (Reduction Step): 一个归约步骤是推导步骤的逆过程。在推导中,我们用规则 $A \rightarrow \beta$ 把 $A$ 替换成 $\beta$。在归约中,我们找到一个子串 $\beta$,如果存在规则 $A \rightarrow \beta$,我们就用 $A$ 把它替换掉。
- 规约字符串 (Reduction String): 在一个归约步骤中,那个被替换掉的子串 $\beta$ 就被称为规约字符串。
- 归约 (Reduction): 从一个终结符串开始,经过一系列归约步骤,最终得到开始变量的整个过程,就称为对该终结符串的一次归约。
DCFG定义的方向
最后,文章明确指出,DCFG的定义将是基于这个“归约”过程的。它的“确定性”就体现在,对于一个给定的字符串,其“归约”过程的每一步都必须是唯一确定的。这为后续引入“句柄(handle)”等概念,并最终给出DCFG的形式化定义铺平了道路。
考虑一个简单的算术表达式文法:
- 文法规则:
- $E \rightarrow E + T$
- $E \rightarrow T$
- $T \rightarrow T \times F$
- $T \rightarrow F$
- $F \rightarrow (E)$
- $F \rightarrow \mathbf{id}$ (id代表标识符,如x, y)
- 示例字符串: id + id * id
- 自上而下的推导 (Derivation):
$E \Rightarrow E + T \Rightarrow T + T \Rightarrow F + T \Rightarrow \mathbf{id} + T \Rightarrow \mathbf{id} + T \times F \Rightarrow \mathbf{id} + F \times F \Rightarrow \mathbf{id} + \mathbf{id} \times F \Rightarrow \mathbf{id} + \mathbf{id} \times \mathbf{id}$
(这是一个最左推导的例子)
- 自下而上的归约 (Reduction): 这是上述推导的逆过程。
- id + id * id (开始字符串)
- 找到子串 id (最左边的),它匹配规则 $F \rightarrow \mathbf{id}$ 的右侧。我们将 id 归约为 $F$。
- 规约字符串: id
- F + id * id
- 找到子串 F,它匹配规则 $T \rightarrow F$ 的右侧。将 F 归约为 $T$。
- 规约字符串: F
- T + id * id
- 找到子串 T,它匹配规则 $E \rightarrow T$ 的右侧。将 T 归约为 $E$。
- 规约字符串: T
- E + id * id
- ... 以此类推,下一步是把第二个 id 归约为 F。
- E + F * id
- ... 再把第三个 id 归约为 F。
- E + F * F
- 找到子串 F * F。这不匹配任何规则的右侧。但是 F 可以归约为 T。
- 这里体现了选择问题:是先归约中间的 F 为 T,还是归约右边的 F 为 T?或者应该找 FF 里的 F?这正是确定性要解决的问题。一个正确的自底向上解析器(如LR解析器)会知道,此时应该先处理乘法,所以它会识别出 id id 对应的 T * F 是一个需要优先归约的结构。
- 正确的归约序列(逆最右推导)应该是:
id + id id $\leftarrow$ id + id F $\leftarrow$ id + T * F $\leftarrow$ id + T $\leftarrow$ F + T $\leftarrow$ T + T $\leftarrow$ E + T $\leftarrow$ E (归约到开始变量,成功)
- 推导 vs 归约: 初学者容易混淆这两个方向相反的过程。推导是“展开”,从抽象到具体;归约是“收缩”,从具体到抽象。
- 归约的顺序: 对于一个字符串,可能存在多个可以被归约的子串。选择哪个子串进行归约,以及使用哪条规则进行归约,是自底向上解析的核心问题。DCFG的定义就是要保证这个选择在任何时候都是唯一的。
- 最左/最右: 最左推导 (leftmost derivation) 和 最右推导 (rightmost derivation) 是自上而下过程中的概念。有趣的是,一个最右推导的逆过程,恰好对应着一种规范的自下而上归约过程(称为最左归约,canonical reduction)。
本段是定义DCFG前的一个重要铺垫。它首先将自动机的“确定性计算”类比到文法的“确定性推导”。然后,它引入了一种与传统“自上而下推导”相反的“自下而上归约”的视角。在这个新视角下,解析一个字符串的过程,是从字符串本身出发,通过一系列“归约”(逆向应用规则)步骤,逐步将其收缩,直至得到开始变量。文章明确指出,DCFG的“确定性”将被定义在这一“归约”过程之上,即要求归约的每一步都是唯一确定的。
本段的目的是进行一次关键的“范式转移”。直接在“自上而下”的推导过程中定义确定性是困难且不直观的,因为它涉及到预测未来的选择。而切换到“自下而上”的归约视角,问题就变成了“根据已看到的内容做出唯一决策”,这与DPDA从左到右读取输入并做决策的行为模式更为吻合。因此,引入“归约”是为了找到一个更适合定义“确定性”的数学框架,并为后续将DCFG与DPDA(一种典型的自左向右、自底向上解析的抽象模型)联系起来打下基础。
这就像两种不同的拼图玩法。
- 自上而下推导: 你拿到一张完整的拼图效果图(开始变量),然后你根据效果图,一块一块地把拼图从盒子里拿出来放到正确的位置(替换),直到拼出完整的图案(终结符串)。
- 自下而上归约: 你面前散落着一堆拼图碎片(终结符串)。你不断地寻找那些可以明确拼在一起的小块(规约字符串),把它们拼成一个小组件(变量),然后把这个小组件看作一整块,再去和其他碎片或小组件继续拼接,直到最终拼出完整的图画,并发现它和你盒子上的效果图(开始变量)完全一样。
- DCFG的确定性: 在玩第二种拼法时,在任何一步,你面前都只有唯一一对(或一组)可以确定无疑地拼在一起的碎片。你永远不会面临“这两块好像能拼,但那两块好像也能拼,我该先拼哪个?”的困境。
你是一名考古学家,正在复原一个破碎的古代花瓶。
- 自上而下推导: 你有一张花瓶的完整设计图。你根据设计图,从一堆陶土开始,一步步捏造、烧制,最终复原出和设计图一模一样的花瓶。
- 自下而上归约: 你面前是一堆花瓶的碎片。你仔细观察,发现两块碎片A和B的断裂面可以完美地契合在一起,于是你把它们粘了起来,形成了一个更大的部件X(归约)。然后你拿着部件X,又发现它可以和碎片C完美契合,于是把它们粘在一起形成部件Y。你不断重复这个过程,最终把所有碎片都用上了,复原出了一个完整的花瓶。你拿起复原的花瓶,对照博物馆的藏品录(开始变量),确认这就是那件失传已久的珍品。
- DCFG的确定性: 在这个复原过程中,你每一步都非常有把握。在任何时候,都只有唯一一组碎片的断面是“天作之合”,可以让你毫不犹豫地粘合。你永远不会遇到好几组碎片看起来都能粘,让你无从下手的情况。
1616. 归约的形式化与最左归约
📜 [原文16]
更形式化地,如果 $u$ 和 $v$ 是变量和终结符字符串,写 $u \succ v$ 表示 $v$ 可以通过一个规约步骤从 $u$ 获得。换句话说,$u \succ v$ 的含义与 $v \Rightarrow u$ 相同。从 $u$ 到 $v$ 的归约是一个序列
我们说 $u$ 可以归约为 $v$,写作 $u \stackrel{*}{\rightarrow} v$。因此 $u \stackrel{*}{\rightarrow} v$ 只要 $v \xrightarrow{*} u$。从 $u$ 的归约是从 $u$ 到开始变量的归约。在最左归约中,每个规约字符串仅在其左侧的所有其他规约字符串都已被归约后才被归约。稍加思考,我们可以看到最左归约是反向的最右推导。
这段内容对上一节引入的“归约”概念给出了更形式化的定义,并介绍了一个关键的、规范化的归约方式——最左归约。
形式化定义
- 单步归约 ($\succ$): 符号 $\succ$ 被用来表示“单步归约”。$u \succ v$ 读作 “$u$ 归约为 $v$”。它精确地定义为单步推导 ($\Rightarrow$) 的逆关系。如果 $v \Rightarrow u$ 成立(即可以从 $v$ 一步推导出 $u$),那么 $u \succ v$ 就成立。
- 例子: 在算术文法中,因为 $E \Rightarrow E+T$,所以 $E+T \succ E$。
- 多步归约 ($\stackrel{*}{\rightarrow}$): 就像 $\xrightarrow{*}$ 代表零步或多步推导一样,$\stackrel{*}{\rightarrow}$ 代表零步或多步归约。一个从 $u$ 到 $v$ 的归约被定义为一个字符串序列 $u_1, u_2, \dots, u_k$,其中 $u=u_1$, $v=u_k$,并且序列中每一步都是单步归约,即 $u_i \succ u_{i+1}$。
- 关系: $u \stackrel{*}{\rightarrow} v$ 成立,当且仅当 $v \xrightarrow{*} u$ 成立。它们是完全的逆关系。
- 对一个字符串的归约: 当我们说对字符串 $w$ 进行“归约”时,通常特指将其归约到文法的开始变量 $S$ 的过程,即 $w \stackrel{*}{\rightarrow} S$。如果这个过程能够成功,就说明 $w$ 是这个文法生成的一个合法句子。
引入“最左归约”
这是本段最核心的概念。在一个字符串中,可能同时存在多个可以被归约的子串(规约字符串)。那么应该先归约哪一个呢?这会导致归约路径的不唯一。为了建立一个标准,我们引入了“最左归约”。
- 定义: “在最左归约中,每个规约字符串仅在其左侧的所有其他规约字符串都已被归约后才被归约。”
- 这个定义有点绕,让我们来解读一下。它实际上是在说,在每一步归约时,我们总是选择最右边的那个可以被归约的子串进行归约。
- 为什么“选择最右”会被称为“最左归约”?这就要回到它与推导的对应关系上。
- 与最右推导的关系: “最左归约是反向的最右推导。”
- 让我们来理解这一点。在一个最右推导 (rightmost derivation) 中,我们每一步总是替换最右边的那个变量。
- 例子 (最右推导): $E \Rightarrow \underline{E+T} \Rightarrow E+\underline{T \times F} \Rightarrow E+T \times \underline{\mathbf{id}} \Rightarrow E+\underline{F} \times \mathbf{id} \Rightarrow ...$ (下划线表示被替换的部分)
- 现在,我们把这个过程完全倒过来,就得到了一个归约序列。在 E+F*id 中,我们首先把 id 归约为 F,这个 id 正是原来推导中最后被展开的,也是字符串中最右边的部分。然后我们把 F 归约为 T...
- 结论: 归约的顺序恰好与最右推导的顺序相反。在最右推导中,我们是“从左到右”地生成终结符的(右边的变量先被展开成终结符)。那么在反向的归约中,我们就是“从左到右”地处理这些终结符,把它们归约成变量。这就是它被称为“最左归约”的直观原因——我们优先处理(归约)位于字符串左侧的结构。更准确地说,我们选择的归约串,是整个句型中最左边的简单短语。
- 因此,最左归约这个名字是从解析器(parser)的角度来看的。解析器从左到右读取输入,当它读到足够的信息,形成一个可以被归约的串(这个串在最右推导中是最后一个被生成的)时,它就执行归约。这个可以被归约的串就是“句柄”(handle),它就是最左归约要找的目标。
- 这是一个序列的通用表示法。在这里,它被用来定义一个多步的归约过程。
- $u$ 或 $u_1$: 归约的起始字符串。
- $v$ 或 $u_k$: 归约的终点字符串。
- $\longrightarrow$: 在这个上下文中,作者用一个简单的箭头来表示序列中的一步。更严谨的写法应该是 $u_1 \succ u_2 \succ \ldots \succ u_k$。
- 这个公式本身不是一个计算公式,而是一种记法,定义了从 $u$ 到 $v$ 的一个“路径”。如果这条路径存在,我们就说 $u \stackrel{*}{\rightarrow} v$。
继续使用算术文法和字符串 id + id * id。
- 最右推导:
- $E$
- $\Rightarrow E + T$ (规则 $E \rightarrow E+T$)
- $\Rightarrow E + T \times F$ (规则 $T \rightarrow T \times F$)
- $\Rightarrow E + T \times \mathbf{id}$ (规则 $F \rightarrow \mathbf{id}$)
- $\Rightarrow E + F \times \mathbf{id}$ (规则 $T \rightarrow F$)
- $\Rightarrow E + \mathbf{id} \times \mathbf{id}$ (规则 $F \rightarrow \mathbf{id}$)
- $\Rightarrow T + \mathbf{id} \times \mathbf{id}$ (规则 $E \rightarrow T$)
- $\Rightarrow F + \mathbf{id} \times \mathbf{id}$ (规则 $T \rightarrow F$)
- $\Rightarrow \mathbf{id} + \mathbf{id} \times \mathbf{id}$ (规则 $F \rightarrow \mathbf{id}$)
- 最左归约 (上述过程的逆序):
- id + id * id (归约最左边的 id) $\succ$
- F + id * id (归约 F) $\succ$
- T + id * id (归约 T) $\succ$
- E + id * id (归约中间的 id) $\succ$
- E + F * id (归约 id) $\succ$
- E + F * F (归约 F) $\succ$
- E + T F (归约 T F) $\succ$
- E + T (归约 E + T) $\succ$
- E (归约到开始符号)
注意: 上面的归约步骤展示了在每一步中选择哪个子串进行归约。例如,在第6步 E + F F 到第7步 E + T F,我们选择了 F (中间的) 进行归约,这是因为在最右推导中,它是倒数第4步才被 T 推导出来的。这个例子说明了寻找正确归约串的复杂性,而“最左归约”提供了一个规范化的顺序。真正的最左归约(逆最右推导)是:
id + id * id $\succ$
id + id * F $\succ$
id + T * F $\succ$
id + T $\succ$
F + T $\succ$
T + T $\succ$
E + T $\succ$
E
在这个正确的序列中,我们总是归约在最右推导中“最后”出现的那一步。例如,在 id + id * id 中,最右推导最后一步是 F -> id 得到最左边的 id,但我们反过来看,最右推导中,最右边的 id 是由 F 最早生成的终结符之一,所以最左归约会从最左边开始扫描,找到第一个可以归约的句柄。这个过程与LR解析器的移入-归约过程紧密相关。
- 最左归约 vs 最右归约: “最左归约”是“最右推导”的逆。同样,也存在“最右归约”,它是“最左推导”的逆。在编译器理论中,自底向上的LR解析器执行的是最左归约,而自顶向下的LL解析器执行的是最左推导。这两个是标准方法。
- 定义和直觉的差异: “最左归约”这个名字听起来像是“总是归约最左边的子串”,但它的形式化定义是“最右推导的逆”,这在实际操作中意味着寻找一个被称为“句柄”的特定子串,这个句柄不一定在字符串的最左端。
本段为“归约”提供了形式化的符号($\succ$ 和 $\stackrel{*}{\rightarrow}$),明确了它们与推导符号($\Rightarrow$ 和 $\xrightarrow{*}$)的逆关系。核心贡献是引入了最左归约的概念,它是一种规范化的、无歧义的归约顺序。通过揭示最左归约与最右推导的逆向关系,本段为后续定义基于此过程的确定性文法建立了坚实的基础。
本段的目的是标准化“归约”过程。在一个字符串中,可能同时存在多个可归约的子串,这会导致混乱和不确定性。通过指定一个唯一的归约策略——最左归约,我们为讨论“确定性”提供了一个共同的、无歧V义的平台。后续DCFG的定义将直接建立在“一个字符串的最左归约过程的每一步都是确定性的”这一思想之上。
这就像给之前的“拼图”游戏增加了一条规则。
- 之前的游戏: 你面前散落着一堆碎片,你可以随便找两块能拼的拼起来。
- 新规则 (最左归约): 现在,规则变了。你必须从拼图的最右下角开始拼(对应最右推导的最后一步)。你找到构成最右下角的那几块碎片,把它们拼成一个小组件。然后,你再寻找构成这个小组件“左边”或“上边”的下一个组件... 你必须按照一个严格的、从右到左、从下到上的顺序来复原整个拼图。
- 这个严格的顺序就是最左归约。它保证了无论谁来拼,只要遵守规则,拼的顺序都是完全一样的。
你正在观看一段视频的倒放。
- 正常播放 (最右推导): 视频里,一个画家正在画画。他先画好了背景,然后画了左边的树,最后在右边画上了一个太阳(每一步替换最右的“待画”部分)。
- 倒放 (最左归约): 你倒着看这段视频。你会先看到太阳被“擦掉”,变回一块空白(一次归约)。然后看到树被“擦掉”,变回空白。最后背景也被“擦掉”。
- 最左归约的含义: 因为画家是最后画的太阳,所以在倒放时,你是最先看到太阳被归约的。这个“倒放最右作画过程”的顺序,就是最左归约。
1717. 确定性推导的约束与句柄
📜 [原文17]
这是 CFG 中确定性背后的思想。在一个带有开始变量 $S$ 且字符串 $w$ 属于其语言的 CFG 中,假设 $w$ 的最左归约是
首先,我们规定每个 $u_i$ 决定了下一个规约步骤,从而决定了 $u_{i+1}$。因此 $w$ 决定了其完整的最左归约。这个要求只意味着文法是无歧义的。为了获得确定性,我们需要更进一步。在每个 $u_i$ 中,下一个规约步骤必须由 $u_i$ 的前缀(包括并直到该规约步骤的规约字符串 $h$)唯一确定。换句话说,$u_i$ 中的最左规约步骤不依赖于 $u_i$ 中在其规约字符串右侧的符号。
这段内容深入阐述了确定性上下文无关文法 (DCFG) 对“确定性”的要求,将其从“无歧义”提升到了一个更严格的层次。
第一层要求:无歧义
- 规定: 对于一个合法的字符串 $w$,它的最左归约路径 $w \succ u_2 \succ \dots \succ S$ 必须是唯一的。
- 含义: 这等同于说,这个字符串 $w$ 只能通过唯一的一棵分析树 (parse tree) 来生成。如果一个字符串有多棵分析树,那么它就会有多种最右推导方式,从而也就有多种最左归约路径。
- 结论: 所以,DCFG的第一个、最基本的要求是,它必须是一个无歧义文法 (unambiguous grammar)。如果一个文法本身就是有歧义的,那它谈不上确定性。
第二层要求:真正的确定性 (LR属性)
这是本段的核心,也是DCFG与普通无歧义文法的关键区别。
- 更进一步的要求: 仅仅保证归约路径唯一还不够。DCFG要求,在归约过程的任何一步 $u_i$ 中,我们要决定下一步该怎么走(即找到要归约的子串和规则),这个决定不能依赖于我们还没看到的信息。
- 类比DPDA: 这完全是在模仿DPDA的行为。DPDA从左到右读取输入,在任何时刻,它只能根据已经读过的前缀和栈内容来做决定,它无法“预知”后面还没读的输入是什么。
- 形式化表述: “下一个规约步骤必须由 $u_i$ 的前缀(包括并直到该规约步骤的规约字符串 $h$)唯一确定。”
- 让我们拆解这句话。假设在 $u_i$ 中,下一步要被归约的子串是 $h$(后面会称之为“句柄”)。$u_i$ 可以写成 $xhy$ 的形式,其中 $x$ 是 $h$ 前面的部分,$y$ 是 $h$ 后面的部分。
- 这个要求的意思是:我们仅凭扫描完 $xh$ 这一部分,就必须能够百分之百确定:“是的,这个 $h$ 就是现在应该被归约的子串,并且应该用规则 $A \rightarrow h$ 来归约。”
- 关键点: 我们做出这个决定时,完全不需要去看 $y$ 是什么。$y$ 中的内容对我们的决策没有任何影响。
- 总结: DCFG的确定性是一种“局部确定性”或“前缀确定性”。它不仅要求全局路径唯一(无歧义),还要求在每一步做决策时,仅根据已经处理过的信息就足够了,无需“向右看”或“未卜先知”。这种性质在编译器理论中被称为 LR(k) 性质,其中 $k$ 代表可以向右看的符号数量。这里讨论的理想DCFG(通常指LR(1)或LR(0)文法)就是要求仅凭已读前缀做出归约决策。
- 这与上一节的公式相同,代表一个从字符串 $w$ 到开始变量 $S$ 的完整归约序列。
- $w=u_1$: 归约的起点,即待解析的字符串。
- $u_i$: 归约过程中的一个中间字符串形式,称为一个“句型”(sentential form)。
- $\succ$: 单步归约符号。
- $u_k=S$: 归约的终点,即文法的开始变量。
- 这个公式在这里的作用是建立一个讨论的框架,后续的确定性要求都是施加在这个序列的每一步 $u_i \succ u_{i+1}$ 上的。
考虑两个无歧义文法:
- 文法1 (是DCFG): $S \rightarrow aSb \mid ab$
- 语言: $\{a^n b^n \mid n \ge 1\}$
- 归约 "aabb": aabb $\succ$ a(S)b $\succ$ S
- 分析确定性: 当解析器从左到右读到 aa...ab 时,一旦它看到了 ab 这个子串,它就可以立即确定地知道:这个 ab 就是当前要归约的句柄,应该用规则 $S \rightarrow ab$ 来归约。它做出这个决定时,根本不需要关心 ab 右边还有没有更多的 b。这种性质使得它是一个DCFG。
- 文法2 (无歧义,但不是DCFG): $L = \{a^n b^n \mid n \ge 1\} \cup \{a^n b^{2n} \mid n \ge 1\}$。假设有一个(虚构的)无歧义文法来描述它。
- 归约 "aabb": 路径可能是 aabb $\succ$ aSb $\succ$ S。
- 归约 "aabbbb": 路径可能是 aabbbb $\succ$ aTbb $\succ$ T。
- 确定性问题: 当解析器读到 aab 时,它无法做出唯一的决定。
- 如果它认为 ab 是一个句柄,那么它就走向了识别 $a^nb^n$ 的路径。
- 但也许完整的输入是 aabbbb,正确的句柄应该是 abb (如果文法是 $T \rightarrow abb$) 。
- 为了决定 aab 之后的部分 (ab 还是 abb) 哪个是句柄,解析器必须向右看,看到 b 后面是另一个 b 还是输入结束。
- 因为决策依赖于句柄右侧的符号,所以这个文法不是DCFG。
- 无歧义 $\neq$ 确定性: 这是最重要的易错点。一个文法可以保证每个字符串只有一棵分析树,但找到这棵树的过程可能需要“反复试探”或“向右看很远”,这样的文法就不是DCFG。DCFG要求找到树的过程是“一条路走到黑”的。
- 归约的选择: 确定性不仅在于归约路径唯一,更在于在每个中间步骤 $u_i$ 中,找到那个要被归约的子串 $h$ 的过程是确定的,且不依赖于 $h$ 的右侧内容。
本段将DCFG的“确定性”要求分解为两个层次。第一层是基础要求,即文法必须是无歧义的,保证每个合法的字符串有唯一的归约路径。第二层是更严格的核心要求,即在归约过程的每一步,识别出要被归约的子串(句柄)及其对应的规则,这一决策必须仅依赖于到该子串结束为止的已扫描前缀,而不能依赖于该子串右侧的任何未扫描符号。这种“不向右看”的局部决策能力,是DCFG的精髓,也是它能与DPDA行为模式相匹配的原因。
本段的目的是精确地定义DCFG的本质特征,将其与更宽泛的“无歧义文法”区分开来。通过强调“仅凭前缀做决策”这一点,它为下一节引入“句柄”(handle)和“强制句柄”(forced handle)这些形式化工具奠定了概念基础。这是从直觉理解迈向严格数学定义的关键一步。
你是一名只看左边、从不回头的流水线工人。
- 无歧义文法: 传送带上过来一堆零件,你知道这堆零件最终能且只能组装成一部手机,但组装顺序可能需要你把零件拿起来反复比对。
- DCFG (确定性): 传送带上的零件经过了精心排序。你作为工人,眼睛只盯着你左手边的区域。每当左手边凑齐了一组特定的零件(比如一个屏幕和一块主板),你就可以想都不想,立刻把它们组装成一个“屏幕组件”,然后继续看左边新凑齐的零件。你完全不需要关心你右手边(传送带下游)还有些什么零件。你的每一步操作都是由你眼前已有的东西唯一决定的。
你正在阅读一篇用从右到左书写的语言(如阿拉伯语)写成的文章,但你习惯从左到右读。
- 归约过程: 你从左到右一个词一个词地读。
- DCFG的确定性: 这种语言的语法非常特别。你每读完一个词组,就能立刻判断出这个词组在句子中扮演的成分(比如“这是一个主语”),并把它在脑子里“打包”成一个整体。你做出这个判断时,完全不需要去看这个词组后面的词是什么。
- 非DCFG的情况: 而在普通语言中,你可能读完一个词组后,还需要再往后读一两个词,才能确定前面那个词组的确切含义和成分。例如,英语中 "I know that...",在读完 "that" 之后,你不知道它是一个代词(I know that.)还是一个连词(I know that you are right.),你需要看后面的内容。这种需要“向右看”的语法,就不符合DCFG的严格要求。
1818. 句柄的定义与图示
📜 [原文18]
引入术语将帮助我们精确地阐述这个想法。设 $w$ 是 CFG $G$ 语言中的一个字符串,并设 $u_i$ 出现在 $w$ 的最左归约中。在规约步骤 $u_i \rightarrow u_{i+1}$ 中,假设规则 $T \rightarrow h$ 被反向应用。这意味着我们可以写 $u_i=xhy$ 和 $u_{i+1}=xTy$,其中 $h$ 是规约字符串,$x$ 是 $u_i$ 中出现在 $h$ 左侧的部分,$y$ 是 $u_i$ 中出现在 $h$ 右侧的部分。图示如下:
图 2.44
$xhy \rightarrow xTy$ 的扩展视图
我们称 $h$ 及其规约规则 $T \rightarrow h$ 为 $u_i$ 的句柄 (handle)。换句话说,出现在 $w \in L(G)$ 的最左归约中的字符串 $u_i$ 的句柄是 $u_i$ 中规约字符串的出现,以及此归约中 $u_i$ 的规约规则。偶尔我们只将句柄与其规约字符串关联,当我们不关心规约规则时。出现在 $L(G)$ 中某些字符串的最左归约中的字符串称为有效字符串 (valid string)。我们只为有效字符串定义句柄。
这段内容引入了自底向上解析理论中一个极其核心的术语——句柄 (handle)。
引入术语的目的
作者明确表示,引入术语是为了更精确地讨论上一节提出的“仅凭前缀确定归约步骤”的思想。句柄这个词,就是用来指代在最左归约的某一步中,那个“应该被归约”的子串。
句柄的定义
- 上下文: 我们考虑的是一个合法字符串 $w$ 的最左归约过程。$u_i$ 是这个过程中的一个中间字符串(句型)。
- 归约步骤: 在 $u_i \succ u_{i+1}$ 这一步,我们应用了某条规则 $T \rightarrow h$ 的“逆过程”。这意味着我们在 $u_i$ 中找到了一个子串 $h$,并把它替换成了变量 $T$,从而得到了 $u_{i+1}$。
- 分解字符串: 我们可以把 $u_i$ 分解成三部分:$u_i = xhy$。
- $h$: 就是那个被替换的规约字符串。
- $x$: 是 $h$ 左边的所有符号。
- $y$: 是 $h$ 右边的所有符号。
- 正式定义: 句柄是一个二元组,包含了规约字符串 $h$ 的这次出现,以及所使用的规约规则 $T \rightarrow h$。
- 例子: 在归约 a(ab)b 为 a(S)b 时,如果使用的是规则 $S \rightarrow ab$,那么句柄就是 (ab, S \rightarrow ab)。
- 简化称呼: 有时为了方便,我们直接把规约字符串 $h$ 称为句柄,但这只是一个简称,完整的句柄还包括所用的规则。
图示的解释
图2.44非常直观地展示了这个过程。
- 左边是 $u_i$,被明确地分成了 $x, h, y$ 三段。$x$ 由 $j$ 个符号组成,$h$ 由 $k$ 个符号组成,$y$ 由 $l$ 个符号组成。
- 右边是 $u_{i+1}$。可以看到,$x$ 和 $y$ 部分原封不动,只有中间的 $h$ 被替换成了单个变量 $T$。
- 箭头 $\succ$ 表示这是一次归约操作。
相关术语:有效字符串
- 定义: 一个字符串如果出现在某个合法语言成员的最左归约序列中,它就被称为有效字符串 (valid string) 或可行前缀 (viable prefix,在更严格的LR理论中)。
- 意义: 我们只为这些“有意义”的、在合法归约路径上出现的字符串定义句柄。对于一个随机的、不合法的字符串,讨论它的句柄是没有意义的。
把所有概念串起来
一个DCFG的核心要求可以这样重新表述:对于任何一个有效字符串,它的句柄必须是唯一的,并且我们仅凭扫描到句柄的末尾就能确定它就是句柄,而无需查看句柄右侧的任何内容。
- $\overbrace{...}^{...}$: 这是一种标记方法,用花括号和上标来解释下面内容的含义。
- $x = x_1 \dots x_j$: 字符串 $x$ 由 $j$ 个符号 $x_1, \dots, x_j$ 组成。
- $h = h_1 \dots h_k$: 规约字符串 $h$ 由 $k$ 个符号组成。
- $y = y_1 \dots y_l$: 字符串 $y$ 由 $l$ 个符号组成。
- $u_i = xhy$: 归约前的字符串。
- $u_{i+1} = xTy$: 归约后的字符串。
- $T$: 规则 $T \rightarrow h$ 左侧的单个变量。
- 这个公式是对归约操作 $u_i \succ u_{i+1}$ 的一个具象化、可视化的分解,清晰地展示了哪部分被替换,哪部分保持不变。
继续使用算术文法 $E \rightarrow E+T \mid T$, $T \rightarrow F$, $F \rightarrow \mathbf{id}$。
- 字符串: id + id
- 最右推导: $E \Rightarrow E+T \Rightarrow E+F \Rightarrow E+\mathbf{id} \Rightarrow T+\mathbf{id} \Rightarrow F+\mathbf{id} \Rightarrow \mathbf{id}+\mathbf{id}$
- 最左归约 (逆过程):
- 有效字符串 $u_1 = \mathbf{id} + \mathbf{id}$
- 我们归约最左边的 id。
- $h = \mathbf{id}$, 规则是 $F \rightarrow \mathbf{id}$。
- 所以 id+id 的句柄是 (id, F \rightarrow id)。
- $x = \varepsilon$ (空串), $y = + id。
- $u_2 = F + \mathbf{id}$。
- 有效字符串 $u_2 = F + \mathbf{id}$
- 我们归约 F。
- $h = F$, 规则是 $T \rightarrow F$。
- 所以 F+id 的句柄是 (F, T \rightarrow F)。
- $x = \varepsilon$, $y = + id。
- $u_3 = T + \mathbf{id}$。
- ... 以此类推。在 E + F 这一步,句柄是 (F, T \rightarrow F)。在 E + T 这一步,句柄是 (E+T, E \rightarrow E+T)。
- 句柄是唯一的吗?: 在一个无歧义文法中,对于一个给定的有效字符串,它的句柄是唯一的。因为唯一的分析树决定了唯一的逆最右推导顺序,也就决定了每一步归约的是谁。如果文法有歧义,一个有效字符串就可能因为对应不同的分析树而有多个句柄。
- 句柄的位置: 句柄不一定在字符串的开头或结尾,它可以出现在任何位置。
- 句柄与最左归约: 句柄这个概念是和最左归约(即逆最右推导)紧密绑定的。在其他任意的归约顺序中讨论句柄是没有意义的。
本段为自底向上归约过程中的关键元素——句柄 (handle)——给出了形式化的定义。在一个有效字符串(即出现在某个最左归约路径上的字符串)中,句柄指的是在下一步将被归约的那个子串,以及用于归约它的那条规则。这个定义是精确讨论DCFG确定性要求的基石,它将“下一步该怎么走”这个模糊的问题,聚焦到了“如何唯一地、仅凭前缀就找到句柄”这个具体问题上。
本段的目的是引入一个核心技术术语“句柄”,它是后续所有关于DCFG和LR解析理论的基石。没有“句柄”这个精确的词汇,就无法清晰地描述“在归约的某一步中应该被操作的对象”。通过定义句柄,我们将确定性问题从一个宏观的路径选择问题,转化为了一个微观的、在每一步中识别唯一句柄的问题。
你是一个侦探,正在分析一段由罪犯留下的加密信息(有效字符串)。
- 句柄: 你知道罪犯在加密时,最后一步是把某个词(比如 "VICTORY")替换成了一个符号(比如 "$%")。在解密时,你的任务就是找到这个 "$%"$ 符号,并把它还原成 "VICTORY"。这个 "$%"$ 符号及其还原规则,就是你当前要处理的句柄。
- DCFG的确定性: 你有一种特殊能力,只要从左到右读这段加密信息,一旦你读到了那个 "$%"$ 符号,你就能立刻确定它就是最后一步加密操作留下的痕迹,而不需要看它后面的内容。你不会把它和信息中其他看起来也像 "$%"$ 的普通符号搞混。
你正在做一道化学合成题,目标是合成物质 S。
- 最左归约: 实验步骤是倒着写的,从最终产物(一堆终结符)开始,一步步还原回起始原料 S。
- 有效字符串: 实验过程中的任何一个中间产物混合物。
- 句柄: 在当前的混合物中,有两个或多个物质(规约字符串 $h$)可以在当前条件下反应,生成一个新的、更接近起始原料的中间产物(变量 $T$)。这一对(或一组)即将反应的物质 $h$,以及它们的反应方程式 $T \rightarrow h$,就是当前混合物的句柄。
- 确定性: 在一个“确定性”的实验流程中,在任何一步,混合物里都只有唯一一组物质能够发生反应。你永远不会面临“是让A和B反应呢,还是让C和D反应呢?”的选择。
1919. 最左归约的补充说明
📜 [原文19]
请注意,$y$,即句柄后面的 $u_i$ 部分,总是终结符串,因为归约是最左的。否则,$y$ 将包含一个变量符号,而这只能来自一个规约字符串完全在 $h$ 右侧的先前的规约步骤。但那样的话,最左归约应该在更早的步骤归约句柄。
这是一个非常重要和精妙的补充说明,它揭示了最左归约过程的一个关键结构特性。
核心论点
在最左归约的任何一步 $u_i = xhy$ 中,句柄 $h$ 右边的部分 $y$ 必然只包含终结符 (terminals),不可能包含任何变量 (variables)。
证明思路 (反证法)
作者给出了一个简洁的反证法思路:
- 假设不成立: 假设在某个最左归约步骤中,句柄 $h$ 右边的 $y$ 部分包含了一个变量,我们称之为 $V$。
- 追溯变量的来源: 这个变量 $V$ 是怎么来的呢?它不可能是原始输入字符串的一部分(因为原始输入全是终结符)。所以,$V$ 必然是在之前的某个归约步骤中,由一个子串被归约而成的。
- 定位归约步骤: 既然 $V$ 在 $y$ 中,也就是在 $h$ 的右边,那么生成 $V$ 的那个归约步骤,其整个规约字符串也必然完全位于当前句柄 $h$ 的右侧。
- 与“最左归约”定义矛盾:
- 我们回顾一下最左归约的定义:它是最右推导的逆过程。
- 在一个最右推导中,我们总是先处理(展开)最右边的变量。
- 这意味着,在逆向的最左归约中,我们应该先处理(归约)那些由最右边的变量生成的部分。
- 在我们的假设中,有一个归约(生成 $V$ 的那次)发生在当前句柄 $h$ 的右边。这意味着在原始的最右推导中,生成 $h$ 的那次变量展开,比生成 $V$ 的那次变量展开要更靠左。
- 根据最右推导的规则,我们应该先展开更右边的(生成 $V$ 的那部分),再展开更左边的(生成 $h$ 的那部分)。
- 那么,在反向的归约中,我们就应该先归约生成 $V$ 的那部分,再归约 $h$。
- 但是,我们当前的步骤是要归约 $h$,而 $V$ 还在它的右边没有被归约。这与“应该先归约更右边的部分”相矛盾。
- 结论: 因此,最初的假设“$y$ 中包含变量”是错误的。$y$ 必须只包含终结符。
这个性质的意义
这个性质非常重要,因为它完美地匹配了DPDA的行为。一个DPDA从左到右扫描输入。当它决定要进行一次归约时(即它在栈顶找到了一个句柄),它已经扫描过的部分对应于 $x$ 和 $h$,而尚未扫描的输入部分则对应于 $y$。因为尚未扫描的输入必然全是终结符,所以这个性质与DPDA的物理模型完全吻合。解析器在决定归约句柄 $h$ 时,它“未来的输入”($y$)里没有任何已经归约好的“高级结构”(变量),只有原始的、待处理的终结符。
让我们再次审视 id + id * id 的最左归约(逆最右推导)过程:
id + id id $\succ$ id + id F $\succ$ id + T * F $\succ$ id + T $\succ$ F + T $\succ$ T + T $\succ$ E + T $\succ$ E
- 步骤: 考察从 id + T * F 归约为 id + T 这一步。
- 句型 $u_i = \text{id} + T * F$。
- 句柄 $h = T * F$ (来自规则 $T \rightarrow T \times F$)
- 分解: $x = \text{id} +$, $h = T*F$, $y = \varepsilon$ (空串)
- 检查: $y$ 是空串,只包含终结符(或者说不包含变量)。性质成立。
- 步骤: 考察从 id + id id 归约为 id + id F 这一步。
- 句型 $u_i = \text{id} + \text{id} * \text{id}$。
- 句柄 $h = \text{id}$ (最右边的那个) (来自规则 $F \rightarrow \mathbf{id}$)
- 分解: $x = \text{id} + \text{id} *$, $h = \text{id}$, $y = \varepsilon$
- 检查: $y$ 是空串。性质成立。
- 一个假想的错误归约:
假设在 E + T * F 这一步,我们错误地选择归约 E。比如有个规则 $S \rightarrow E$。
- 错误选择: $h=E$, $x=\varepsilon$, $y= + T * F。
- 问题: 这里的 $y$ 包含了变量 $T$ 和 $F$。这违反了我们刚讨论的性质。
- 原因: 这之所以是错误的,是因为 TF 在 E 的右边,并且它本身也是一个可以被归约的结构(可以归约为T)。根据最左归约的原则,我们应该先处理更右边的句柄。在这个例子中,TF 才是真正的句柄。
- 对最左归约的误解: 这个性质是最左归约(逆最右推导)所特有的。如果采用其他任意的归约顺序(比如逆最左推导),这个性质就不一定成立了。
- $y$ 可以为空: $y$ 部分是空串 $\varepsilon$ 是完全可能的,而且很常见,特别是在归约的后期阶段。空串当然只包含终结符。
本段对最左归约过程给出了一个关键的洞察:在任何一步归约 $u_i = xhy$ 中,句柄 $h$ 右边的部分 $y$ 必然是一个纯粹的终结符串。作者通过反证法,说明了如果 $y$ 中存在变量,那将与最左归约(作为最右推导的逆过程)的定义相矛盾,因为更右边的结构应该被更早地归约。这个性质加强了自底向上归约与DPDA这种从左到右扫描模型的内在联系。
本段的目的是深化对最左归约结构特性的理解,并为后续将DCFG与DPDA进行等价性关联提供一个重要的理论支撑。它解释了为什么自底向上解析(特别是LR解析)可以高效地工作:解析器在任何时候都不需要担心它还没看到的输入中会隐藏着已经完成的、复杂的语法结构(变量),未来全是“原材料”(终结符)。
这就像一个遵守“先完成右边任务”原则的项目经理在做项目复盘。
- 项目计划 (最右推导): 经理的计划总是优先完成最右边的子任务。
- 项目复盘 (最左归约): 复盘时,是倒着看计划的执行过程。
- 你看到经理正在复盘“核心模块A”(句柄 $h$)的完成情况。
- 本段的结论: 此时,你发现所有在“核心模块A”之后才开始的任务($y$部分),都还处于最原始的“需求分析”阶段(终结符状态),没有任何一个已经变成了“设计完成”或“编码完成”的“半成品”(变量状态)。
- 为什么?: 因为如果右边有任何一个任务已经成了“半成品”,根据经理“先完成右边任务”的原则,他应该先去复盘那个右边的半成品,而不是现在正在复盘的“核心模块A”。
你正在逆向工程一个复杂的机械装置,你采用的策略是“先拆最外层、最后安装的零件”。
- 安装过程 (最右推导): 工人安装时,总是先把最里面的核心装好,然后一层层往外装,最后装上最右边的外壳。
- 你的拆解 (最左归约): 你倒着来。
- 你首先拆下最右边的外壳(归约一个句柄)。
- 本段的结论: 当你正在拆解某个内部零件(句柄 $h$)时,你往它的右边看,发现所有右边的东西都还是最原始的、未经拆解的“外壳”或“螺丝钉”(终结符),没有任何东西已经是被拆解下来的“内部组件”(变量)。
- 原因: 如果右边有任何一个“内部组件”已经被你拆下来了,根据你“先拆最外层”的策略,你当初就应该先去继续拆解那个更靠外的组件,而不是跑来拆现在这个更靠里的零件。
2020. 句柄的歧义性与示例
📜 [原文20]
示例 2.45
考虑文法 $G_1$:
其语言是 $B \cup C$,其中 $B=\left\{\mathrm{a}^{m} \mathrm{~b}^{m} \mid m \geq 1\right\}$ 和 $C=\left\{\mathrm{a}^{m} \mathrm{~b}^{2 m} \mid m \geq 1\right\}$。在字符串 aaaabbb $\in L\left(G_{1}\right)$ 的此最左归约中,我们在每一步都下划线标记了句柄:
同样,这是字符串 aaabbbbbb 的最左归约:
在这两种情况下,所示的最左归约恰好是唯一可能的归约;但在其他可能发生几次归约的文法中,我们必须使用最左归约来定义句柄。请注意,aaabbb 和 aaabbbbbb 的句柄不相等,即使这些字符串的初始部分相同。我们将在定义 DCFG 时更详细地讨论这一点。
这个示例通过一个精心设计的文法 $G_1$,非常清晰地展示了“无歧义”和“确定性(DCFG)”之间的关键差异。
文法 $G_1$ 的分析
- 规则:
- $R \rightarrow S \mid T$: 开始符号 $R$ 可以是 $S$ 类型或 $T$ 类型。
- $S \rightarrow aSb \mid ab$: $S$ 生成语言 $\{a^m b^m \mid m \ge 1\}$。
- $T \rightarrow aTbb \mid abb$: $T$ 生成语言 $\{a^m b^{2m} \mid m \ge 1\}$。
- 语言: $L(G_1)$ 是上述两个语言的并集,即 $\{a^m b^m \mid m \ge 1\} \cup \{a^m b^{2m} \mid m \ge 1\}$。
- 无歧义性: 这个文法是无歧义的。因为任何一个字符串,要么符合 $a^m b^m$ 的形式,要么符合 $a^m b^{2m}$ 的形式(当 $m \ge 1$ 时,这两种形式不可能同时满足),所以任何合法的字符串都只有一棵唯一的分析树,从而有唯一的最左归约路径。
归约过程的展示
作者展示了两个字符串的最左归约过程,并用下划线标出了每一步的句柄。
- 归约 aaabbb:
- aaabbb $\succ$ aa(S)bb: 句柄是 ab,规则是 $S \rightarrow ab$。
- aaSbb $\succ$ a(S)b: 句柄是 aSb,规则是 $S \rightarrow aSb$。
- aSb $\succ$ S: 句柄是 aSb,规则是 $S \rightarrow aSb$。
- S $\succ$ R: 句柄是 S,规则是 $R \rightarrow S$。
- 勘误: 原文的归约序列 aaaabbb 可能是笔误,根据上下文和逻辑,应为 aaabbb 归约为 aSb,再归约为 S。或者原文的 a 和 b 个数有误。我们以逻辑为准,分析 aaabbb 的归约为 aa(ab)b -> a(aSb)b -> S。让我们严格按照逆最右推导来:
- 最右推导 aaabbb: $R \Rightarrow S \Rightarrow aSb \Rightarrow aaSbb \Rightarrow aa(ab)bb$。这也是错的。正确的推导是: $R \Rightarrow S \Rightarrow aSb \Rightarrow a(ab)b = aabb$。
- 让我们以一个明确的例子 aabb 来分析:最右推导 $R \Rightarrow S \Rightarrow aSb \Rightarrow a(ab)b = aabb$。其逆过程(最左归约)是:aabb $\succ$ aSb $\succ$ S $\succ$ R。第一步的句柄是 ab。
- 归约 aabbbb:
- 最右推导: $R \Rightarrow T \Rightarrow aTbb \Rightarrow a(abb)bb = aabbbb$。
- 最左归约: aabbbb $\succ$ aTbb $\succ$ T $\succ$ R。第一步的句柄是 abb。
核心观察与问题
- 观察: 作者指出:“aaabbb 和 aaabbbbbb 的句柄不相等,即使这些字符串的初始部分相同。”
- 更精确地说,对于字符串 aabb,解析器读到 aab 时,真正的句柄是 ab。
- 对于字符串 aabbbb,解析器读到 aab 时,真正的句柄是 abb。
- 问题所在: 想象一个从左到右读取输入的DPDA(或解析器)。
- 当它读取了前缀 aab 之后,它面临一个决策:当前的句柄是否已经形成?
- 如果是 ab,那么它应该立即执行归约 $S \rightarrow ab$。
- 如果是 abb,那么它还需要再多读一个 b 才能形成句柄。
- 为了做出这个决定,解析器必须“向右看”,看看 aab 后面的符号是什么。如果后面没 b 了或者是别的符号,句柄可能是 ab。如果后面还有 b,句柄可能是 abb。
- 结论: 因为确定句柄需要依赖于句柄右侧的上下文信息,所以这个文法不是DCFG,尽管它是无歧义的。
- $R \rightarrow S \mid T$: $R$ 推导出 $S$ 或 $T$。
- $S \rightarrow \mathrm{a} S \mathrm{~b} \mid \mathrm{ab}$: $S$ 推导出 $aSb$ 或 $ab$。这是递归定义,用于生成配对的a和b。
- $T \rightarrow \mathrm{a} T \mathrm{bb} \mid \mathrm{abb}$: $T$ 推导出 $aTbb$ 或 $abb$。这也是递归定义,用于生成1:2配对的a和b。
- $B=\left\{\mathrm{a}^{m} \mathrm{~b}^{m} \mid m \geq 1\right\}$: 语言B,由相等数量的a和b组成。
- $C=\left\{\mathrm{a}^{m} \mathrm{~b}^{2 m} \mid m \geq 1\right\}$: 语言C,b的数量是a的两倍。
- 归约序列:
- aaabbb $\succ$ aaSbb $\succ$ aSb $\succ$ S $\succ$ R
- 这里可能存在笔误,但它想表达的是一个逐步归约的过程。例如 aa(ab)b $\succ$ a(S)b $\succ$ S。每一步,一个子串(句柄)被其对应的变量替换。
- 输入: aab...
- 解析器状态: 已经读取了 aab。
- 困境:
- 可能性1: 完整输入是 aabb。那么解析器应该识别出 ab 是句柄,并执行归约 $S \rightarrow ab$,得到 aSb。
- 可能性2: 完整输入是 aabbbb。那么解析器应该继续读取,识别出 abb 是句柄,并执行归约 $T \rightarrow abb$,得到 aTb。
- 决策依据: 要在可能性1和2之间做出选择,解析器必须知道 aab 后面的符号。如果后面是 b,它仍然无法确定,因为两种可能性都还存在。它需要看得更远。这种需要“向右看”(lookahead)的行为,正是非确定性的体现。一个理想的DCFG解析器在读完句柄后就应该能立刻做出决定。
- 无歧义陷阱: 这个例子是理解“无歧义”与“确定性(LR)”区别的最佳教材。不要因为一个文法无歧义就认为它一定是DCFG。
- 句柄的识别: 句柄的识别是自底向上解析的关键。DCFG要求句柄的识别过程是“确定”的,即不需要lookahead。
示例2.45通过文法 $G_1$ (生成 $\{a^m b^m\} \cup \{a^m b^{2m}\}$) 展示了一个无歧义但非确定性的上下文无关文法。通过分析两个相似前缀的字符串(如aabb和aabbbb)的归约过程,我们发现,为了确定当前应该归约的句柄(是ab还是abb),解析器必须检查句柄右侧的符号。这种对“未来”输入的依赖性,违反了DCFG的核心要求——仅凭已扫描的前缀做出唯一的归约决策。因此,$G_1$ 不是一个DCFG。
本示例的目的是提供一个具体的反例,以巩固上一节建立的理论概念。它让“确定性不仅是无歧义,还需要不依赖右侧上下文”这一抽象思想变得具体可见。通过这个例子,读者可以亲身体会到一个DPDA在解析此类语言时会遇到的“选择困境”,从而深刻理解DCFG的限制为何如此设定。
你是一个只看当下、从不向右看的决策者。
- 当前情况: 你已经看到了序列 a, a, b。
- 决策点: 你需要决定,是把 a,b 这两个元素打包成一个“S组件”,还是再等一个 b 来了之后,把 a,b,b 打包成一个“T组件”。
- 你的困境: 作为一个从不“向右看”的决策者,你不知道下一个元素是什么。你被卡住了,无法做出唯一的、确定的决策。
- 结论: 设计这个决策流程的“文法”,不是一个“确定性”的文法。
你正在做英语的完形填空,但有一个奇特的限制:你必须在读到一个词的瞬间,就决定它和前面的词组成什么短语,不能看它后面的词。
- 句子片段: "I can..."
- 你的困境: 你读到 "can" 时,你不知道它是一个情态动词(后面跟动词原形,如 "I can do it."),还是一个名词(后面跟别的,如 "I can see a tin can.")。为了做出判断,你需要看后面的词。
- 限制下的失败: 由于你被禁止“向右看”,你无法在读到 "can" 的瞬间确定它的用法和它组成的短语(句柄)。
- 类比: 这种需要依赖右侧上下文来消除歧义的语法结构,就不符合DCFG的严格要求。示例2.45中的文法 $G_1$ 就创造了类似的困境。
2121. 对比DCFG与非DCFG文法
📜 [原文21]
PDA 可以通过利用其非确定性猜测其输入是在 $B$ 中还是在 $C$ 中来识别 $L\left(G_{1}\right)$。然后,在它将 a 压入栈后,它弹出 a 并根据 b 或 bb 进行匹配。问题 2.25 要求您证明 $L\left(G_{1}\right)$ 不是 DCFL。如果您尝试制作一个识别此语言的 DPDA,您会发现机器无法事先知道输入是在 $B$ 中还是在 $C$ 中,因此它不知道如何将 a 与 b 匹配。将此文法与文法 $G_2$ 进行对比:
其中输入的第一个符号提供了此信息。我们对 DCFG 的定义必须包含 $G_2$ 但排除 $G_1$。
这段内容通过对比两个文法 $G_1$ 和 $G_2$,进一步强化了“确定性”的来源——明确的、无歧义的决策信息。
回顾 $G_1$ 的问题
- 语言: $L(G_1) = \{a^m b^m\} \cup \{a^m b^{2m}\}$。
- NPDA 的解法: 一个非确定性下推自动机 (NPDA) 可以轻松识别这个语言。它在开始读输入时,就进行一次“猜测”:
- 分支1: 猜测输入属于 $\{a^m b^m\}$。于是它进入一个模式,读一个 'a' 压栈,读一个 'b' 弹栈。
- 分支2: 猜测输入属于 $\{a^m b^{2m}\}$。于是它进入另一个模式,读一个 'a' 压栈,读两个 'b' 弹栈。
- 只要输入字符串能在其中任何一个分支被成功匹配,NPDA就接受该字符串。这里的“猜测”是非确定性的核心体现。
- DPDA 的困境: 一个确定性下推自动机 (DPDA) 没有“猜测”的能力。当它读入一连串 'a' 并压栈后,开始遇到 'b'。此时,它必须做出一个唯一的决定:是按照 1:1 的比例销账,还是按照 1:2 的比例销账?由于它无法“预知”整个字符串的结构,它没有足够的信息来做出这个唯一的、正确的决定。这就是为什么 $L(G_1)$ 不是一个DCFL。
引入文法 $G_2$ 作为对比
- 文法 $G_2$:
- $R \rightarrow 1S \mid 2T$
- $S \rightarrow aSb \mid ab$
- $T \rightarrow aTbb \mid abb$
- 语言 $L(G_2)$: 这个文法生成的语言是 $\{1w \mid w \in \{a^m b^m\}\} \cup \{2w \mid w \in \{a^m b^{2m}\}\}$。
- $G_2$ 的优越性: 这个新文法的巧妙之处在于,它在每个字符串的开头用一个明确的标记('1' 或 '2')来消除了歧义。
- 如果字符串以 '1' 开头,解析器(或DPDA)就确定地知道,接下来的部分必须符合 $S$ 的规则,即 $a^m b^m$ 的形式。
- 如果字符串以 '2' 开头,解析器就确定地知道,接下来的部分必须符合 $T$ 的规则,即 $a^m b^{2m}$ 的形式。
- $G_2$ 是一个 DCFG: 因为开头的符号提供了做出正确决策所需的所有信息,所以在解析(归约)过程的每一步,选择都是唯一的。当解析器看到 '1' 时,它就进入了“S模式”;看到 '2' 就进入“T模式”。后续的归约,比如在看到 ab 时,如果在“S模式”下,就可以确定地归约为 $S$。因此,$G_2$ 是一个DCFG。
最终目标
作者总结道:“我们对DCFG的定义必须包含 $G_2$ 但排除 $G_1$。” 这为即将到来的形式化定义设定了一个明确的检验标准。任何一个好的DCFG定义,都必须能够精准地将 $G_2$ 这样的“好”文法纳为成员,同时将 $G_1$ 这样的“坏”(非确定性)文法排除在外。
**[公式与符号逐项
- 文法 $G_2$:
- $R \rightarrow 1S \mid 2T$: 这是文法的开始规则。它表明一个合法的字符串必须以终结符 '1' 或 '2' 开头。
- 如果以 '1' 开头,那么后面的部分必须遵循变量 $S$ 的规则。
- 如果以 '2' 开头,那么后面的部分必须遵循变量 $T$ 的规则。
- $S \rightarrow \mathrm{a} S \mathrm{~b} \mid \mathrm{ab}$: 这和 $G_1$ 中的 $S$ 完全一样,生成 $\{a^m b^m \mid m \ge 1\}$。
- $T \rightarrow \mathrm{a} T \mathrm{bb} \mid \mathrm{abb}$: 这和 $G_1$ 中的 $T$ 完全一样,生成 $\{a^m b^{2m} \mid m \ge 1\}$。
- 对于文法 $G_2$ 和 DPDA:
- 输入: 1aabb
- DPDA 读到 '1'。它立刻知道了“现在是S模式,必须匹配 $a^m b^m$”。
- 它进入一个专门处理 $S$ 的状态集。
- 读 'a', 压栈。
- 读 'a', 压栈。
- 读 'b', 弹栈。
- 读 'b', 弹栈。
- 输入结束,栈空。接受。
- 整个过程没有任何歧义。
- 输入: 2aabbbb
- DPDA 读到 '2'。它立刻知道了“现在是T模式,必须匹配 $a^m b^{2m}$”。
- 它进入一个专门处理 $T$ 的状态集。
- 读 'a', 压栈。
- 读 'a', 压栈。
- 读 'b', 此时它知道应该按照1:2的比例销账,可能它会弹出一个栈符号,并进入一个“等待第二个b”的状态。
- 读第二个 'b',完成一次销账。
- 重复此过程,直到输入结束,栈空。接受。
- 对比: 如果给这个为 $G_2$ 设计的DPDA输入一个 1aabbbb,它会在读到 '1' 后进入“S模式”,然后当它发现 'b' 的数量是 'a' 的两倍时,匹配就会失败,从而正确地拒绝该字符串。
- 标记的作用: 标记 ('1' 和 '2') 的作用是“预告”。它们在解析的早期阶段就为后续的决策提供了关键信息,从而消除了不确定性。这在解析理论中被称为 LL(1) 性质,即向前看一个符号就足以做出唯一的推导选择。
- DCFG的范围: 并非所有DCFL都能被这种简单的加“起始标记”的方式改造。$G_2$ 是一个特例,用来说明“提供决策信息”是实现确定性的关键。
本段通过将非DCFG文法 $G_1$ 与一个改造后的DCFG文法 $G_2$ 进行对比,生动地阐释了确定性的来源。$G_1$ 的问题在于,解析器需要根据不确定的未来做出选择。而 $G_2$ 通过在字符串开头添加一个明确的标记('1'或'2'),提前告知了解析器应该采用哪种解析策略,从而消除了所有不确定性。这个对比清晰地表明,一个好的DCFG定义,必须能够将 $G_2$ 这样的“信息明确”的文法识别为确定性的,而将 $G_1$ 这样需要“猜测”的文法排除在外。
本段的目的是通过一个正反对比的实例,为读者建立一个关于“什么是确定性文法”的更强的直觉。它不仅仅满足于说明 $G_1$ 的问题,更是通过构造一个“好”的文法 $G_2$ 来展示解决问题的方向。这为后续更加形式化、更加普适的DCFG定义(如LR(k)文法和DK检验)提供了动机和现实基础。
这就像去一家餐厅点餐。
- 餐厅 $G_1$ (非DCFG): 菜单上有一道菜叫“主厨惊喜”。你点了之后,不知道上来的是牛排还是鱼排,只有等菜上齐了才知道。你的用餐体验是“非确定性”的。
- 餐厅 $G_2$ (DCFG): 菜单上是“1号套餐(牛排)”和“2号套餐(鱼排)”。你在点餐时(读取第一个符号),就已经确定了你接下来会吃到什么。你的用餐体验是“确定性”的。
- 类比: G_2的文法,就像是给不确定的选项加上了明确的“编号”,让选择变得容易和确定。
你是一个分拣中心的机器人。
- 包裹来自 $G_1$: 包裹上只写着“易碎品”。你不知道应该把它送到“玻璃器皿区”还是“电子产品区”。你需要拆开包裹(向右看)才能决定。你的工作流程是“非确定性”的。
- 包裹来自 $G_2$: 包裹上贴着一个巨大的标签:“1-玻璃”或“2-电子”。你一看到标签(第一个符号),就能立刻把它送到正确的传送带上。你的工作流程是“确定性”的。
- DCFG的本质: DCFG就像是要求所有的“包裹”(字符串)都必须有这样清晰、明确的“分拣标签”,让处理过程的每一步都没有歧义。
2222. 句柄在DCFG定义中的作用
📜 [原文22]
示例 2.46
令 $G_3$ 为以下文法:
这个文法说明了几点。首先,它生成带结束标记的语言。我们稍后将重点关注带结束标记的语言,届时我们将证明 DPDA 和 DCFG 之间的等价性。其次,$\boldsymbol{\varepsilon}$ 句柄可能出现在归约中,如在字符串 ()()- 的最左归约中用短下划线表示:
句柄在定义 DCFG 中扮演重要角色,因为句柄决定归约。一旦我们知道一个字符串的句柄,我们就知道下一个规约步骤。为了理解即将到来的定义,请记住我们的目标:我们旨在定义 DCFG 以使其与 DPDA 对应。我们将通过展示如何将 DCFG 转换为等价的 DPDA,反之亦然来建立这种对应关系。为了使这种转换有效,DPDA 需要找到句柄以便它可以找到归约。但找到句柄可能很棘手。似乎我们需要知道一个字符串的下一个规约步骤来识别其句柄,但 DPDA 不会提前知道归约。我们将通过限制 DCFG 中的句柄来解决这个问题,以便 DPDA 可以更容易地找到它们。
这个示例和随后的讨论是定义DCFG之前最后也是最关键的铺垫。它通过一个新的例子,引出了定义DCFG所面临的核心挑战以及解决该挑战的总体思路。
示例 $G_3$ 的要点
- 文法 $G_3$: 生成平衡的括号对序列,并带有结束标记。例如 (), ()(), (()) 都会匹配(并带上结束标记)。
- 要点1:带结束标记: 这个文法生成的所有字符串都以 $\dashv$ 结尾。这再次强调了之前提到的,DCFG和DPDA的等价性证明将建立在带结束标记的语言之上。
- 要点2:$\varepsilon$句柄: 归约过程中可能出现句柄是空串 $\varepsilon$ 的情况。
- 归约序列分析: ()()\dashv (原文的 \dashv () () \dashv 可能是笔误,我们分析 ()()\dashv)。
- 最右推导:$S \Rightarrow T\dashv \Rightarrow T(T)\dashv \Rightarrow T()\dashv \Rightarrow T(T)()\dashv \Rightarrow T(\varepsilon)()\dashv \Rightarrow \varepsilon(\varepsilon)()\dashv = ()()\dashv$。这个推导很复杂。
- 我们直接看原文给的归约序列:()()\dashv (假设这是初始串)。
- ()()\dashv $\succ$ T()\dashv (这里应该是 (ε)归约为 (T),再 T 归约为 T(T))。原文的序列有些跳跃,但它想表达的核心点在 T(ε) () \dashv 这一步。
- 在 T( ) ( ) \dashv 这个中间句型中,括号内是空的。解析器需要识别出这个“空”是一个句柄,对应于规则 $T \rightarrow \varepsilon$。然后将这个“空”归约为 $T$,得到 T(T) () \dashv。
- 这个 $\varepsilon$ 句柄的存在,为句柄识别增加了一层复杂性。
定义DCFG的核心挑战
这段论述的逻辑链非常清晰:
- 目标: 定义DCFG,使其能与DPDA一一对应。
- 对应关系的基础: DPDA做的是“识别”,DCFG做的是“生成”。要让它们对应,我们需要找到一个共同的“计算模型”。这个模型就是“自底向上归约”。一个DPDA在识别字符串时,其内部操作可以被看作是在执行一次最左归约。
- DPDA的能力: DPDA从左到右读取输入,并利用其栈来“记住”已经看到的前缀的结构。当栈顶形成一个句柄时,DPDA就执行一次归约操作(即用规则左侧的变量替换栈顶的句柄)。
- 核心矛盾:
- 从文法角度看,句柄是由“下一步要归约什么”所定义的。
- 从DPDA角度看,它必须先找到句柄,才能知道下一步要归约什么。
- 这看起来像一个“先有鸡还是先有蛋”的问题:要知道归约步骤,似乎得先知道句柄;但要找到句柄,似乎又得先知道归约步骤。
- 解决方案: 作者指明了出路——我们不能指望DPDA去解决这个难题。相反,我们要对文法本身施加限制。我们只允许那些“句柄很容易被找到”的文法成为DCFG。
- “容易找到”是什么意思? 这意味着DPDA仅凭从左到右扫描到的前缀,就能够唯一、无歧义地确定句柄已经形成,而不需要“向右看”或者进行任何猜测。
- 文法 $G_3$:
- $S \rightarrow T \dashv$: 开始规则,确保整个字符串以 $T$ 的形式出现,并以 $\dashv$ 结尾。
- $T \rightarrow T(T) \mid \varepsilon$: 这是一个递归规则,用来生成嵌套和连续的括号对。
- $T \rightarrow T(T)$ 生成了结构。例如 $T \Rightarrow T(T) \Rightarrow \varepsilon (T) \Rightarrow (T) \Rightarrow () $。
- $T \rightarrow \varepsilon$ 是基础情况,允许递归结束,或生成空括号对 ()。
- 归约序列:
- 这个序列旨在展示归约过程,特别是 ε 句柄的出现。虽然步骤有些跳跃和可能的笔误(如开头的 \dashv),但其核心信息是,在 T( ) ( ) \dashv 这样的句型中,那个空的 就是句柄。
- 句柄识别的挑战: 再次使用 $G_1$ 的例子,字符串前缀 aab。
- DPDA的状态: 栈里可能存着代表 aa 的信息。现在读入了 b。
- DPDA的困惑: 栈顶现在代表了 aab 的某种结构。这是句柄吗?
- 不是。如果完整字符串是 aabbbb,句柄是 abb,还没形成完。
- 栈顶代表了 aa,下一个输入是 b,再下一个是 b。这时栈顶形成了代表 aabb 的结构。这是句柄吗?
- 不一定。如果完整字符串是 aabb,句柄是 ab,不是 aabb。
- 这个例子生动地说明了“找到句柄可能很棘手”。
- 句柄容易找到的例子 (来自 $G_2$) : 字符串前缀 1ab。
- DPDA的状态: 读了 1,进入“S模式”。读了 a,压栈。读了 b,弹栈。
- DPDA的决策: 在读完 1ab 后,DPDA的栈可能是空的。它看到 ab 组成了一个完整的 $S \rightarrow ab$ 归约单元。因为'1'已经锁定了上下文,所以DPDA可以确定地知道,ab 就是一个句柄。它不需要担心这个 ab 会不会是 abb 的一部分,因为“S模式”下不存在 abb 规则。
- 不要陷入鸡生蛋的悖论: 理解作者的解决方案是跳出这个悖论,不是去增强DPDA的能力,而是去筛选文法,只接受那些本身“行为良好”的文法。
- $\varepsilon$ 产生式: 带有 $\varepsilon$ 规则的文法给句柄识别带来了额外的挑战。解析器需要在“什么都没看到”的地方识别出一个句柄。
本节通过示例 $G_3$ 强调了带结束标记的语言和 $\varepsilon$句柄在讨论DCFG时的重要性。接着,它深刻地揭示了定义DCFG所面临的核心困境:DPDA的归约行为依赖于找到句柄,但句柄的定义本身又依赖于归约步骤,这构成了一个看似循环的难题。最终,文章指明了解决方向:我们不解决这个难题,而是绕过它——通过对文法本身施加足够强的限制,来保证其句柄总是“容易被找到的”,从而使得DPDA能够确定性地执行归约。
本段是DCFG形式化定义之前最后一次、也是最重要的一次概念澄清。它将之前所有关于确定性、归约、句柄的讨论,全部聚焦到了“如何让句柄易于识别”这一个核心问题上。这为下一节引入“强制句柄”(Forced Handle)这一关键概念,并最终给出DCFG的形式化定义,做好了最充分的铺垫。它把“为什么DCFG的定义是这样的?”这个问题,提前进行了解答。
你是一个机器人,任务是根据一本食谱做菜。
- 食谱: 文法。
- 做菜步骤: 归约过程。
- “混合A和B,放入烤箱”: 一个归约步骤,句柄是“A和B”。
- 机器人(DPDA)的困境: 你看着一堆食材(中间句型),食谱上说“找到现在应该混合的食材(句柄),然后混合它们”。你问:“我怎么知道哪些是现在应该混合的?” 食谱回答:“就是我下一步要你混合的那些啊!” —— 这就是循环困境。
- 解决方案(DCFG): 你换了一本“傻瓜食谱”。这本食谱的特点是,所有应该在某一步混合的食材,都会被预先用一个红色的托盘装好。你作为机器人,任务变得极其简单:你不需要理解菜谱的逻辑,你只要从左到右扫描食材台,一旦看到一个红色托盘,就把它里面的东西全倒进锅里。这个“红色托盘”,就是被“限制”过的、容易找到的句柄。
你正在编辑一个非常长的视频,你的任务是找到所有的“转场”特效并替换它们。
- 句柄: 一个“转场”片段。
- 困境: 有些转场特效(比如淡入淡出)边界很模糊,你可能要看完转场之后的好几秒,才能确定前面那段确实是一个完整的淡入淡出特效,而不是一个普通的亮度变化。这使得找到句柄很困难。
- DCFG的解决方案: 你要求所有的视频剪辑师在制作视频时,必须遵守一个新规定:每一个转场特效的前后,都必须加上一个持续1帧的“绿色标记帧”。
- 你的新工作流程(DPDA): 现在你的工作变得异常简单。你从头到尾扫描视频,完全不需要理解内容,只要一看到“绿色标记帧”,你就知道它和你刚刚看过的片段共同构成了一个“转场”(句柄),然后执行替换操作。这个“绿色标记帧”就是让句柄变得“容易找到”的限制。
2323. 强制句柄与DCFG定义
📜 [原文23]
为了激发定义,考虑有歧义的文法,其中某些字符串有几个句柄。选择特定的句柄可能需要事先知道哪棵分析树推导出该字符串,而 DPDA 肯定无法获得此信息。我们将看到 DCFG 是无歧义的,因此句柄是唯一的。然而,仅凭唯一性对于定义 DCFG 来说是不够的,如示例 2.45 中的文法 $G_1$ 所示。
为什么唯一的句柄不意味着我们有一个 DCFG 呢?答案通过检查 $G_1$ 中的句柄可以清楚地看到。如果 $w \in B$,句柄是 ab;而如果 $w \in C$,句柄是 abb。尽管 $w$ 决定了哪种情况适用,但发现 ab 或 abb 哪个是句柄可能需要检查整个 $w$,而 DPDA 在需要选择句柄时还没有读取整个输入。
为了定义与 DPDA 对应的 DCFG,我们对句柄施加更强的要求。有效字符串的初始部分,包括其句柄,必须足以确定句柄。因此,如果我们从左到右读取一个有效字符串,一旦我们读取到句柄,我们就知道我们已经找到了它。我们不需要读取句柄之外的内容来识别句柄。回想一下,有效字符串中未读取的部分只包含终结符,因为有效字符串是通过初始终结符串的最左归约获得的,并且未读取的部分尚未处理。因此,我们说有效字符串 $v=xhy$ 的句柄 $h$ 是强制句柄 (forced handle),如果 $h$ 是每个有效字符串 $x h \hat{y}$ 中唯一的句柄,其中 $\hat{y} \in \Sigma^{*}$。
定义 2.47
确定性上下文无关文法是一种上下文无关文法,其中每个有效字符串都有一个强制句柄。
这段内容是本章的高潮,它给出了DCFG的形式化定义,其核心是引入了“强制句柄 (forced handle)”这一关键概念。
从“唯一句柄”到“强制句柄”
文章的论证层层递进:
- 排除有歧义文法: 首先,有歧义的文法肯定不行。因为一个有歧义的字符串有多棵分析树,也对应多个最左归约路径,因此在某一步它可能有多个句柄。DPDA无法选择,所以有歧义文法肯定不是DCFG。因此,DCFG必须是无歧义的,这意味着每个有效字符串的句柄是唯一的。
- 唯一句柄还不够: 接着,文章提出了一个更深刻的问题:为什么句柄唯一还不够?这里再次请出了反例 $G_1$ (来自示例2.45)。
- 文法 $G_1$: 是无歧义的,所以对于任何给定的字符串,其句柄是唯一的。
- 问题: 对于字符串 aabb(属于B类),其(第一个)句柄是 ab。对于字符串 aabbbb(属于C类),其(第一个)句柄是 abb。
- DPDA的视角: DPDA从左到右处理输入。当它处理完 aab 时,它需要决定下一步怎么办。但此时它并不知道完整的字符串是什么。如果它能“看到”整个字符串,它当然知道句柄是唯一的。但它不能。它只能根据已经看到的前缀 aab 来决策。而仅凭 aab,无法判断句柄是 ab 还是 abb。这个决定需要依赖于句柄右侧的上下文。
- 结论: “全局唯一”的句柄对DPDA没有帮助,DPDA需要的是一种“局部可判断”的唯一性。
- 引入“强制句柄”: 为了满足DPDA的需求,我们必须对句柄施加更强的约束。
- 核心要求: “有效字符串的初始部分,包括其句柄,必须足以确定句柄。”
- 直白解释: 当你从左到右读一个字符串时,只要你一读完句柄的最后一个符号,你就应该能立刻、百分之百地确定“好了,句柄就是它了!”,而完全不需要再往右多看哪怕一个符号。
- 形式化定义“强制句柄”: 一个句柄 $h$ (在有效字符串 $v=xhy$ 中) 是强制句柄,需要满足一个非常强的条件:对于任何以 $xh$ 开头的有效字符串(无论它后面跟的是什么 $\hat{y}$),它的句柄都必须是这个 $h$。
- 这意味着,一旦前缀 $xh$ 形成,后面跟什么都无法改变“$h$是句柄”这个事实。$h$ 的“句柄地位”是被前缀 $xh$ “强制”锁定的。
定义 2.47: DCFG 的正式定义
有了“强制句柄”这个完美的工具,DCFG的定义就水到渠成了:
“确定性上下文无关文法是一种上下文无关文法,其中每个有效字符串都有一个强制句柄。”
这个定义精准地抓住了“确定性”的本质:不仅每一步的正确选择是唯一的,而且做出这个选择所需的信息是受限的(仅限前缀),这恰好与DPDA的工作模式相匹配。
本段是概念性的,没有复杂的计算公式,但“强制句柄”的定义是关键。
- 设 $v = xhy$ 是一个有效字符串,其句柄是 $h$。
- $h$ 是 强制句柄 (forced handle) $\iff$ 对于任意的 $\hat{y} \in \Sigma^*$,只要 $xh\hat{y}$ 也是一个有效字符串,那么 $xh\hat{y}$ 的句柄也必须是 $h$。
- 强制句柄的例子 (来自文法 $S \rightarrow aSb \mid ab$):
- 有效字符串: aabb。它的句柄是 ab。这里 $x=`a`, $h=ab, $y=b。
- 检查强制性: 前缀是 $xh = aab。是否存在另一个以 aab 开头的有效字符串,其句柄不是 ab?
- 以 aab 开头的有效字符串只有 aabb 自己(在最左归约的这个阶段)。所以,句柄 ab 在这里是强制的。更普遍地,对于这个文法,只要一个 ab 出现在可以被归约的位置,它就一定是句柄,后面跟什么都改变不了。
- 非强制句柄的例子 (来自文法 $G_1$):
- 有效字符串: aabbbb。它的句柄是 abb。这里 $x=`a`, $h=abb, $y=b。
- 检查强制性: 前缀是 $xh = aabb。句柄是 abb。
- 我们问:是否存在另一个以 aab 开头的有效字符串,其句柄不是 abb?
- 是的,存在! 字符串 aabb 就是一个以 aab 开头的有效字符串,但它的句柄是 ab,而不是 abb。
- 结论: 因为句柄依赖于它后面的内容(是b还是bb),所以 abb 在这里不是一个强制句柄。因此,文法 $G_1$ 不是DCFG。
- 有效字符串的范围: 强制句柄的定义是针对所有有效字符串的。这意味着在归约的每一步,句柄都必须是强制的。
- 与LR(k)的关系: 强制句柄的概念非常接近于 LR(0) 文法的定义。一个文法是LR(0)的,如果仅凭栈内容(对应前缀 $xh$)就能唯一确定何时归约以及使用哪个规则。我们这里讨论的DCFG,其核心就是LR(k)文法,特别是LR(0)或LR(1)文法。
本段通过层层递进的思辨,最终给出了确定性上下文无关文法 (DCFG) 的形式化定义。它首先排除了有歧义文法,然后通过示例 $G_1$ 指出“句柄唯一”仍不足够,因为DPDA需要的是一种不依赖“未来”信息的局部决策能力。为此,它引入了核心概念“强制句柄”——一个其句柄地位仅由其左侧和自身前缀就能锁定的句柄。最后,DCFG被简洁地定义为:一个所有有效字符串都具有强制句柄的上下文无关文法。
本段的目的是为DCFG提供一个独立于DPDA的、纯粹基于文法自身属性的、严谨的数学定义。这个定义是后续所有理论探讨的逻辑起点。通过引入“强制句柄”,它成功地将DPDA的“从左到右、无未来视角”的工作模式,转化为了一条对文法产生式和结构本身的内在约束,从而在生成模型(文法)和识别模型(自动机)之间架起了一座坚实的桥梁。
这就像是在法律中定义“正当防卫”。
- 有歧义的定义: “在受到攻击时可以反击。”(这会导致“他是不是真的在攻击我?”“我能反击到什么程度?”等无数歧义)
- 无歧义但不够好的定义: “只有在事后被法庭裁定为正当防卫的情况下,你的反击才是合法的。”(这在现实中无法操作,你不能在反击前先去趟法庭)
- 强制句柄式的定义 (DCFG): “当你面临一个清晰可见、迫在眉睫、且无任何其他合理解决方案的致命威胁时(对应句柄的形成),你可以进行对等反击。”
- 强制性: 这个定义的关键在于,判断威胁是否“清晰可见、迫在眉睫”(即判断句柄是否形成)的标准,必须是当时当地的、任何一个普通人都能做出的判断,而不能依赖于“如果我当时不反击,他后来会不会杀了我”这种对未来的猜测(不能依赖句柄右侧的上下文)。
- DCFG的定义: 一个“确定性的法律体系”,就是它的每一条规则(如正当防卫)都是这样清晰、可立即判断、不依赖事后信息的。
你在玩一个节奏音乐游戏,比如吉他英雄。
- 音符 (有效字符串): 从屏幕上方掉落的音符序列。
- 按键 (归约): 当音符到达屏幕下方的判定线时,你按下对应的按钮。
- 句柄: 一个需要你按下的音符或和弦。
- 一个好的谱面 (DCFG):
- 无歧义: 不会出现两个音符重叠在一起让你不知道按哪个。
- 强制句柄: 当一个音符(句柄)到达判定线时,你就可以立刻按下它。你完全不需要根据后面将要掉下来的音符来决定你现在这个音符应该怎么按。例如,不会有这样的规则:“如果这个红色音符后面紧跟着一个蓝色音符,你就按红色;如果后面跟着一个黄色音符,你刚才那个红色就别按,等它们俩一起下来再按。” 这样的谱面是没法玩的。
- DCFG的定义: 就是一个“可以正常玩的”、“没有反人类设计的”节奏游戏谱面。它的每一个按键决策(归约决策)都只依赖于当前到达判定线的音符,而与未来的音符无关。
2424. DCFG定义的补充说明与DK检验介绍
📜 [原文24]
为了简化起见,在本节关于确定性上下文无关语言的讨论中,我们将始终假设 CFG 的开始变量不出现在任何规则的右侧,并且文法中的每个变量都出现在文法语言中某个字符串的归约中,即文法不包含无用变量。
尽管我们对 DCFG 的定义在数学上是精确的,但它并没有给出任何明显的方法来确定一个 CFG 是否是确定性的。接下来,我们将介绍一个精确地做到这一点的过程,称为 DK 检验。我们还将利用 DK 检验背后的构造,在展示如何将 DCFG 转换为 DPDA 时,使 DPDA 能够找到句柄。
这部分内容包含两个方面:一是对后续讨论的文法进行简化假设,二是引出用于实际判断一个文法是否为DCFG的工具——DK检验。
简化假设
作者提出了两条假设,以清理掉文法中一些不影响核心问题但会使讨论变繁琐的“枝节”。
- 开始变量不出现在规则右侧:
- 假设: 文法的开始变量 $S$ 不会是任何产生式 $A \rightarrow \dots S \dots$ 的一部分。
- 为什么: 如果开始变量可以被其他东西推导出来,那么在归约时,当归约到 $S$ 后,可能还可以继续归约。这会使“归约到开始变量即为成功”这一结束条件变得模糊。
- 如何做到: 这个假设很容易满足。对于任何一个不满足此条件的文法,我们都可以轻易地改造它。只需引入一个新的开始变量 $S'$,并增加一条唯一的规则 $S' \rightarrow S$。现在 $S'$ 是新的开始变量,它不出现在任何规则的右侧。这个改造不改变文法生成的语言。
- 不包含无用变量:
- 假设: 文法中的每个变量都是“有用的”。一个有用的变量必须满足两个条件:a) 它能从开始变量推导出来;b) 它最终能推导出一串终结符。
- 在归约视角下: 这个假设等价于说,每个变量都确实会出现在“某个合法字符串的归约过程”中。
- 为什么: 如果一个变量是无用的(例如,它无法从开始变量到达,或者它会陷入无限推导而无法产生终结符),那么包含它的规则也是无用的。讨论这些无用之物会增加复杂性,但对语言本身毫无影响。
- 如何做到: 存在标准算法可以从任何CFG中移除所有的无用变量和规则,而不改变其语言。
引入DK检验
- 定义虽好,但难用: 作者指出了刚刚给出的DCFG定义(基于强制句柄)的一个重大实践缺陷:它是一个“描述性”定义,而不是一个“操作性”定义。也就是说,它告诉你一个DCFG应该“长什么样”,但没有告诉你一个具体的方法去“检查”一个给定的文法是不是DCFG。直接去验证“每个有效字符串都有强制句柄”是非常困难的,因为有效字符串有无限多个。
- DK检验的角色: 为了解决这个问题,作者引入了一个名为DK检验 (DK-test) 的过程。(这里的DK代表Donald Knuth,LR理论的创立者)。
- 目的: DK检验是一个具体的、算法化的过程,可以对任何一个CFG进行测试,并明确地回答“是”或“否”——该文法是否是一个DCFG。
- 一石二鸟: 作者还预告了这个检验的另一个重要作用。DK检验的核心构造过程(后面会讲到,是构造一个DFA)不仅仅是一个“检验器”,它本身就包含了识别句柄所需的所有信息。这个构造将被直接用于“将DCFG转换为等价的DPDA”的证明中。换句话说,DK检验的副产品,恰好就是DPDA的大脑或控制单元。
- 简化假设1的例子:
- 原始文法: $S \rightarrow aS \mid \varepsilon$
- 问题: 开始变量 $S$ 出现在了规则 $S \rightarrow aS$ 的右侧。
- 改造:
- 引入新开始变量 $S'$。
- 增加规则 $S' \rightarrow S$。
- 新文法为: $S' \rightarrow S$, $S \rightarrow aS \mid \varepsilon$。
- 这个新文法生成与原来完全相同的语言,但满足了假设。
- DK检验的预告:
- 想象一个“文法健康扫描仪”(DK检验)。
- 输入: 文法 $G_1$ (来自示例2.45,非DCFG)。
- 扫描仪工作: 它内部会构建一个复杂的图(DFA)。
- 输出: 扫描仪亮起红灯,并报告“错误:在状态X发现‘移入/归约冲突’”。这意味着在某个解析状态,机器不知道是该继续读下一个符号(移入),还是应该执行一次归约。这对应于“句柄不是强制的”。
- 输入: 文法 $G_2$ (来自示例2.45对比,是DCFG)。
- 输出: 扫描仪亮起绿灯,报告“文法健康,是一个DCFG”。同时,它还会打印出那张复杂的图,并说:“把这张图安装到你的DPDA里,它就能完美地解析这个文法了。”
- 假设的适用范围: 作者明确了这些简化假设仅为“本节关于DCFL的讨论”。在其他上下文中,可能需要处理更一般形式的文法。
- DK检验的名称: 这里的“DK”是为了向Donald Knuth致敬。在标准的编译器教材中,这个过程通常被称为构造LR(0)或LR(1)项目集和分析表的过程。DK检验是本书作者对这个过程的一个称呼。
本段首先通过两条简化假设(开始变量不出现在右侧、无无用变量)来“净化”后续讨论的文法,使问题聚焦于核心。然后,它指出了“强制句柄”定义在实践上的困难,并为此引入了一个终极解决方案——DK检验。DK检验被描述为一个可以明确判断任意CFG是否为DCFG的算法过程。更重要的是,这个检验过程的构造物,将直接被用作将DCFG转换为等价DPDA的核心部件,起到了承上启下的关键作用。
本段的目的是从“理论定义”过渡到“实践方法”。它回答了读者心中必然会产生的下一个问题:“好了,我知道什么是DCFG了,但我怎么知道我手里的这个文法是不是DCFG呢?”通过引入DK检验,作者为这个问题提供了路线图。同时,将DK检验与DCFG到DPDA的转换联系起来,展示了理论的统一性和构造的复用性,让读者对后续内容有了更清晰的预期。
你是一位天才医生,你刚刚对一种疑难杂症“确定性缺乏症”给出了一个完美的理论定义。
- 定义 (强制句柄): “如果一个病人(文法)的每一个生理反应(有效字符串)都满足X性质(有强制句柄),那么他就是健康的(DCFG)。”
- 实践困境: 这个定义虽然精确,但在临床上没法用。你总不能把病人所有可能的生理反应都测试一遍。
- 你的发明 (DK检验): 你发明了一台“健康扫描仪”。病人只要躺进去扫描5分钟,机器就能通过分析其内部的“生理状态转换图”,直接给出一个“健康”或“不健康”的诊断。
- 发明的附加价值: 更神奇的是,如果诊断结果是“健康”,扫描仪还会打印出一份详细的“个性化健康指南”(DK检验的构造),告诉这位病人以后应该如何行动(DPDA如何工作)才能保持健康。
你是一个汽车工程师,正在为一款新车设计自动驾驶系统。
- DCFG的定义: 你对“可安全自动驾驶的道路”下了一个定义:“一条路是安全的,如果在这条路上的任何一个位置,车辆仅凭已行驶过的路况就能唯一确定下一步是该转弯还是直行,无需观察远方的路况。”
- 实践困境: 你不能真的派车去把全世界所有的路都跑一遍来验证这个定义。
- 你的新工具 (DK检验): 你利用高精度卫星图像和GIS数据,开发了一个软件。这个软件可以分析任何一条道路的地图数据(文法),并构建出一个“决策点网络图”(DFA)。通过检查这个图是否存在“决策冲突点”,软件就可以直接判断这条路是否“可安全自动驾驶”。
- 工具的复用: 如果软件判断一条路是安全的,它输出的那个“决策点网络图”,可以直接被下载到汽车的自动驾驶电脑(DPDA)里,作为其导航和决策的核心逻辑。
2525. DK检验的构造基础
📜 [原文25]
DK 检验依赖于一个简单但令人惊讶的事实。对于任何 CFG $G$,我们可以构造一个相关的 DFA $DK$,它可以识别句柄。具体来说,$DK$ 接受其输入 $z$ 当且仅当
- $z$ 是某个有效字符串 $v=zy$ 的前缀,且
- $z$ 以 $v$ 的句柄结束。
此外,$DK$ 的每个接受状态都指示相关的规约规则。在一般的 CFG 中,可能适用多个规约规则,这取决于 $z$ 扩展到的有效 $v$。但在 DCFG 中,正如我们将看到的,每个接受状态都对应于恰好一个规约规则。
这段内容揭示了DK检验背后的核心魔法:构造一个能够识别“句柄前缀”的确定性有限自动机 (DFA)。
一个惊人的事实
- 核心思想: 对于任何一个CFG(无论它是不是DCFG),我们都能造出一个DFA。这个DFA不是用来识别CFG生成的语言的(因为CFG生成的语言通常不是正则的),而是用来识别该CFG在自底向上归约过程中出现的所有可能的“句柄前缀”。
- 句柄前缀是什么: 再次回顾,一个有效字符串 $v$ 可以被写成 $xhy$,其中 $h$ 是句柄。那么,$z=xh$ 就是这个有效字符串的一个前缀,并且这个前缀恰好以句柄 $h$ 结尾。我们称这样的 $z$ 为一个“句柄前缀”。
- DFA $DK$ 的能力:
- 接受条件: DFA $DK$ 被设计成,当且仅当它读取的字符串 $z$ 是一个“句柄前缀”时,它才会进入一个接受状态。
- 信息附加: 不仅如此,$DK$ 的每个接受状态还“知道”这个句柄对应的是哪条归约规则。例如,如果 $h$ 来自规则 $A \rightarrow h$,那么 $DK$ 进入的那个接受状态就会“标记”着规则 $A \rightarrow h$。
$DK$ 在不同文法中的表现
- 在普通CFG中: 如果文法不是DCFG(比如有歧义,或者像 $G_1$ 那样),那么一个句柄前缀 $z$ 后面可能跟着不同的 $y_1, y_2, \dots$,形成不同的有效字符串 $v_1, v_2, \dots$。这些不同的 $v$ 可能有不同的句柄或不同的归约规则。
- 结果: 这将导致 $DK$ 的某个接受状态可能关联着多条归约规则。或者,从这个接受状态出发,可能还有后续的路径,这意味着机器不确定在读完 $z$ 时是否真的完成了句柄的识别。
- 在DCFG中 (预告): 如果文法是一个DCFG,那么根据“强制句柄”的定义,一旦前缀 $xh$ 形成,句柄就必须是 $h$,并且归约规则也随之确定。
- 结果: 这将完美地反映在DFA $DK$ 的结构上。对于一个DCFG,它的 $DK$ 的每个接受状态将只对应唯一的一条归约规则。并且,一旦进入接受状态,就不会有因为读入更多终结符而通往另一个接受状态的路径(这呼应了“无需向右看”的特性)。
把这个事实和DK检验联系起来
虽然这里还没说DK检验具体怎么做,但蓝图已经非常清晰了:
- 构造: 拿到一个CFG $G$。
- 运行算法: 通过一个特定的算法(后面会讲),为 $G$ 构造出对应的DFA $DK$。
- 检验: 检查这个造出来的 $DK$ 是否“行为良好”。“行为良好”就意味着:
- 每个接受状态是否只关联一条归约规则?
- 进入接受状态后,是否还存在不确定性?
- 结论: 如果 $DK$ “行为良好”,那么原始文法 $G$ 就是一个DCFG。否则,就不是。
- 文法: $S \rightarrow aSb \mid ab$
- 有效字符串: aSb。它的句柄是 ab(假设来自 aabb 的归约)。
- $v = aSb$, $x=a$, $h=S$, $y=b$。
- 句柄前缀: 让我们考虑 aabb 的归约。第一步句柄是 ab。
- $v = aabb$。归约的第一步是 ab $\rightarrow$ S。所以句柄是 ab。
- $v$ 本身就可以看作 $xhy$ 的形式,其中 $x=aa$, $h=bb$ 这不对。
- 应该是 aabb 的句柄是 ab (最右推导的逆)。最右推导: $S \Rightarrow aSb \Rightarrow a(ab)b = aabb$。逆过程是: aabb $\succ$ aSb。句柄是 ab,句柄前缀是 aab。
- DFA $DK$ 的行为: 当 $DK$ 读取字符串 aab 时,它会进入一个接受状态。这个接受状态会标记着规则 "S $\rightarrow$ ab"。
- 文法 $G_1$: $S \rightarrow ab$, $T \rightarrow abb$ 等。
- 句柄前缀: aab
- DFA $DK$ 的行为: 当 $DK$ 读取 aab 时,它会发现:
- 如果这个 aab 是 aabb 的前缀,那么 ab 是句柄,应该按 $S \rightarrow ab$ 归约。
- 如果这个 aab 是 aabbbb 的前缀,那么 abb 是句柄,还没读完呢。
- 这会导致 $DK$ 在读完 aab 时,处于一个“不确定”的状态。这个状态可能既包含一个指示“可以按 $S \rightarrow ab$ 归约”的信息,又包含一个指示“如果下一个是b,请继续前进”的信息。这种冲突,就是DK检验要找出的“毛病”。
- DFA识别的对象: 一定要牢记,这个DFA $DK$ 识别的不是CFG生成的语言 $L(G)$,而是 $L(G)$ 的所有句柄前缀的集合。这是一个正则语言,所以可以用DFA识别,这正是这个方法的精妙之处。
- 有效字符串: $DK$ 只关心来自有效字符串的句柄前缀。构造 $DK$ 的算法必须有办法只考虑这些“有意义”的前缀。
本段揭示了DK检验的理论基础:对于任何CFG,都存在一个对应的DFA(称为$DK$),这个DFA能够识别出该文法所有可能的“句柄前缀”(即以句柄结尾的、某个有效字符串的前缀)。$DK$的接受状态不仅能识别出句柄前缀,还能指明对应的归约规则。一个文法是否是DCFG,将直接体现在这个$DK$自动机的结构特性上:对于DCFG,其$DK$的接受状态是“确定”的(每个接受状态只对应一条规则且无后续冲突);而对于非DCFG,其$DK$的接受状态会体现出“不确定性”(一个状态对应多条规则,或存在“归约/移入”冲突)。
本段的目的是将DK检验从一个空洞的名字,变成一个具体的、可操作的目标。它清晰地定义了检验所依赖的核心构造物——DFA $DK$,以及这个DFA应该具备的功能。这为下一节具体介绍如何构造这个DFA做好了铺垫。通过“识别句柄前缀”这个概念,它在抽象的文法性质和具体的自动机模型之间建立了一座坚固的桥梁。
你是一位语言学家,正在研究一门古老语言的语法。
- 语法规则 (CFG): 你整理出的语法规则。
- 你的新发现 (惊人的事实): 你发现了一个规律。虽然这门语言的句子结构很复杂,但所有句子的“核心短语”(句柄)的“前导部分”(句柄前缀),都遵循一个非常简单的、可以用流程图(DFA)描述的模式。
- 流程图 ($DK$): 你画出了这个流程图。图中的每个“终点”(接受状态)都标注着“这是一个‘名词短语’”或“这是一个‘动词短语’”(归约规则)。
- 诊断语法 (DK检验): 你发现,对于有些“确定性”很好的古语言,这个流程图非常清晰,每个终点都只有一个标注。而对于一些有歧义的、混乱的古语言,流程图的某些终点上贴了好几个相互矛盾的标注。你意识到,你可以通过检查这个流程图的“清晰度”,来判断这门古语言的语法是否是“确定性的”。
你是一家公司的CEO,正在分析公司的项目审批流程。
- 项目流程 (CFG): 一个项目从提出到完成的各种可能路径。
- 审批节点 (句柄): 项目进行到某个阶段,需要一个部门经理签字批准(归约)。
- DFA $DK$: 你设计了一个自动化的邮件监控系统。系统会阅读所有关于项目的往来邮件(字符串前缀)。
- 系统的能力: 这个系统非常智能。每当一封邮件内容(前缀)恰好满足了某个“审批节点”的所有前置条件时(形成了句柄前缀),系统就会自动给对应的部门经理发送一封“请签字”的邮件(进入接受状态)。这封邮件的主题会写明是“关于A项目的B审批节点”(指示归约规则)。
- 流程诊断 (DK检验): 你通过分析系统的日志发现:
- 在设计良好的流程中,系统发出的每封“请签字”邮件都目的明确,收件人唯一。
- 在混乱的流程中,系统有时会“困惑”,比如一封邮件同时满足了A项目和B项目的审批条件,系统不知道该发给哪个经理(一个状态对应多个规则)。或者,它发了邮件给A经理,但如果它再多等一天,这事就该B经理批了(移入/归约冲突)。
- 结论: 你可以通过分析这个自动化系统的“困惑日志”,来诊断你的公司项目流程是否“确定”和高效。
2626. DK检验的构造细节:NFA J 和 K
📜 [原文26]
我们将在正式介绍 $DK$ 并建立其性质之后描述 DK 检验,但计划如下。在 DCFG 中,所有句柄都是强制的。因此,如果 $zy$ 是一个有效字符串,其前缀 $z$ 以 $zy$ 的句柄结束,那么该句柄是唯一的,并且它也是所有有效字符串 $z \hat{y}$ 的句柄。为了使这些性质成立,$DK$ 的每个接受状态都必须与单个句柄相关联,从而与单个适用的规约规则相关联。此外,接受状态不能有导致通过读取 $\Sigma^{*}$ 中的字符串而到达接受状态的出边。否则,$zy$ 的句柄将不唯一,或者它将依赖于 $y$。在 DK 检验中,我们构造 $DK$,然后得出结论,如果其所有接受状态都具有这些性质,则 $G$ 是确定性的。
为了构造 DFA $DK$,我们将构造一个等价的 NFA $K$,并通过定理 1.39 中介绍的子集构造将 $K$ 转换为 $DK^{1}$。为了理解 $K$,首先考虑一个执行更简单任务的 NFA $J$。它接受以任何规则的右侧结尾的每个输入字符串。构造 $J$ 很容易。它猜测使用哪个规则,并且还猜测何时开始将输入与该规则的右侧匹配。在匹配输入时,$J$ 跟踪所选右侧的进度。我们通过在规则中的相应位置放置一个点来表示此进度,从而产生一个带点规则 (dotted rule),在其他材料中也称为项 (item)。因此,对于每个右侧有 $k$ 个符号的规则 $B \rightarrow u_{1} u_{2} \cdots u_{k}$,我们得到 $k+1$ 个带点规则:
每个带点规则对应于 $J$ 的一个状态。我们用方框 $B \rightarrow u . v$ 表示与带点规则 $B \rightarrow u . v$ 关联的状态。接受状态 $B \rightarrow u.$ 对应于末尾有点的已完成规则。我们添加一个单独的开始状态,该状态对所有符号具有自环,并对每个规则 $B \rightarrow u$ 具有到 $B \rightarrow . u$ 的 $\varepsilon$ 移动。因此,如果匹配在输入结束时成功完成,$J$ 则接受。如果发生不匹配,或者匹配的结束与输入的结束不一致,则 $J$ 的此计算分支拒绝。
这段内容详细阐述了构造DFA $DK$ 的具体策略,并引入了构造过程中的两个关键概念:带点规则 (item) 和一个简化的NFA $J$。
DK检验的计划重述
首先,作者再次明确了DK检验的逻辑:
- 前提: DCFG的句柄是强制的。
- 推论: 这意味着,如果一个前缀 $z$ 是一个句柄前缀,那么它所关联的归约规则必须是唯一的,并且这个事实不能被 $z$ 后面的任何符号所改变。
- 对DFA $DK$的要求: 为了反映这一特性,我们最终构造的DFA $DK$ 必须满足:
- 要求A (归约/归约冲突): 每个接受状态只能关联一个归约规则。
- 要求B (移入/归约冲突): 接受状态不能有“出边”连接到另一个接受状态(通过读取终结符)。这对应于“不能向右看”。
- 检验步骤: 构造 $DK$,然后检查它是否满足要求A和B。如果满足,文法就是DCFG。
构造 $DK$ 的策略:NFA $\rightarrow$ DFA
作者指出,直接构造DFA $DK$ 很复杂,所以采用一个标准的两步策略:
- 先构造一个更容易理解的非确定性有限自动机 (NFA),我们称之为 $K$。这个 $K$ 能够识别所有的句柄前缀,但它是非确定性的。
- 然后,使用我们在第一章学过的子集构造法 (subset construction),将这个NFA $K$ 确定化,得到等价的DFA $DK$。
理解构造过程的垫脚石:NFA $J$
为了让读者能理解更复杂的 $K$ 是如何工作的,作者先引入了一个超级简化的版本,NFA $J$。
- $J$ 的任务: 识别所有以“任意产生式右部”结尾的字符串。例如,如果文法有规则 $A \rightarrow bc$,那么 $J$ 会接受 "abc", "xbc", "cbc" 等等。
- $J$ 的工作方式 (非确定性):
- 猜测起点: $J$ 从一个特殊的开始状态出发,这个状态有一个自环,可以读取任意符号。这意味着 $J$ 可以“忽略”任意长的前缀。
- 猜测规则: 在任何时刻,$J$ 都可以通过一个 $\varepsilon$ 移动,“猜测”它要开始匹配某条规则 $B \rightarrow u$ 的右侧了。
- 跟踪进度: 为了跟踪匹配进度,引入了带点规则 (Dotted Rule / Item) 的概念。
- 什么是带点规则: 它就是一个在产生式右部的某个位置加了一个“点”.的规则。
- 点的含义: 点.左边的部分,是我们已经成功匹配的;点右边的部分,是我们期望接下来要匹配的。
- 例子: 对于规则 $B \rightarrow u_1 u_2 u_3$:
- $B \rightarrow \cdot u_1 u_2 u_3$: 表示我们刚决定要匹配这条规则,还没匹配任何东西。
- $B \rightarrow u_1 \cdot u_2 u_3$: 表示我们已经成功匹配了 $u_1$,接下来期望匹配 $u_2$。
- $B \rightarrow u_1 u_2 u_3 \cdot$: 表示我们已经成功匹配了整个右侧。这是一个“完成项”。
- $J$ 的结构:
- 状态: $J$ 的每一个状态都对应一个带点规则。例如,状态 [B -> u . v]。
- 转移: 如果当前在状态 [B -> u . a v],读入符号 a,就转移到状态 [B -> ua . v]。
- 开始状态: 一个特殊的开始状态,有到所有 [B -> . u] 形式状态的 $\varepsilon$ 边。
- 接受状态: 所有对应“完成项”的状态,即形如 [B -> u .] 的状态。
- $J$ 的问题: $J$ 太“宽泛”了。它会尝试匹配任何规则的右侧,而不管这个右侧是不是一个合法的“句柄”。
从 $J$ 到 $K$
这里的讨论为下一节更复杂的NFA $K$ 做了铺垫。我们可以预见,$K$ 的构造会和 $J$ 类似,也会使用“带点规则”作为状态。但 $K$ 必须比 $J$ 更“聪明”,它不能随便猜测规则,它只能猜测那些“可能成为句柄”的规则。这个“聪明”的机制将是下一节的重点。
- 这组公式展示了由一条产生式 $B \rightarrow u_{1} u_{2} \cdots u_{k}$ 生成的所有可能的带点规则 (items)。
- 点的数量是 $k+1$ 个,代表了匹配该规则右侧的 $k+1$ 种不同进度阶段(从“还没开始”到“全部完成”)。
- $B \rightarrow \cdot u_{1} u_{2} \cdots u_{k}$: 初始项。
- $B \rightarrow u_{1} u_{2} \cdots u_{k} .$: 完成项或可归约项。
- 文法规则: $T \rightarrow T \times F$
- 生成的带点规则 (Items):
- $T \rightarrow \cdot T \times F$
- $T \rightarrow T \cdot \times F$
- $T \rightarrow T \times \cdot F$
- $T \rightarrow T \times F \cdot$
- NFA $J$ 中对应的状态和转移 (部分):
- 存在状态 [T -> . T F], [T -> T . F], [T -> T . F], [T -> T F .]。
- 从 [T -> T . F] 状态,如果读入符号 ,就会转移到 [T -> T * . F] 状态。
- 状态 [T -> T * F .] 是一个接受状态。
- 子集构造的复杂性: 将NFA转换为DFA的子集构造法可能会导致状态数量的指数级增长。虽然理论上总是可行的,但在实践中,得到的DFA $DK$ 可能会非常庞大。
- Item的另一个名字: 作者提到,带点规则在其他文献中也叫项 (item)。在学习编译器理论时,“LR(0)项”或“LR(1)项”是更标准的说法。
本段详细规划了DK检验的实施蓝图。它首先重申了检验的逻辑——通过检查一个特殊构造的DFA $DK$ 的结构特性来判断文法是否为DCFG。然后,它阐述了构造 $DK$ 的方法:先构造一个非确定性的版本 $K$,再通过子集构造法将其确定化。为了让读者理解 $K$ 的构造,又引入了一个更简单的模型 $J$,并借此机会定义了核心的数据结构——带点规则 (item),它被用来在自动机状态中跟踪产生式右侧的匹配进度。
本段的目的是将抽象的“构造一个DFA”这一任务,分解为更具体、更易于理解的步骤。通过引入NFA $J$ 作为教学工具,它为读者理解带点规则和基于它的状态转移机制提供了一个简单的入口。这是一种“分而治之”的教学策略,为下一节介绍更复杂的NFA $K$ 的构造规则(特别是处理变量和 $\varepsilon$ 移动的规则)做好了充分的概念准备。
这就像学习一项复杂的烹饪技术。
- 目标: 制作一道分子料理“确定性泡沫”。
- DK检验: 分子料理设备(光谱仪)的说明书,告诉你最后如何检测泡沫是否合格。
- DFA $DK$: 那台精密的光谱仪。
- NFA $K$: 光谱仪的设计蓝图,很复杂。
- NFA $J$ (本节内容): 为了让你看懂蓝图,工程师先给你看一个“简易手电筒”的电路图。这个手电筒和光谱仪用了类似的基本元件(比如电池、开关、灯泡)。
- 带点规则 (Item): 就是电路图里的基本元件符号,比如 -[ ]- 代表电阻,--|(-- 代表电池。你通过学习手电筒的电路图,认识了这些基本元件和它们的连接方式。
- 下一步: 学会了看手-电筒电路图,你就能更好地理解光谱仪那张复杂得多的设计蓝图 $K$ 了。
你正在学习如何追踪动物。
- DFA $DK$: 一个能识别“猎豹足迹链”的AI识别器。
- NFA $K$: AI识别器的核心算法,基于概率和不确定性。
- NFA $J$: 为了教你这个算法,老师先让你学习一个简单的任务:识别“任何动物的脚印”。
- 带点规则: 你有一本《动物脚印识别手册》。
- 手册里的一页: “猎豹的步态模式:左前掌 -> 右后掌 -> 右前掌 -> 左后掌”。
- 带点规则: 就是你在追踪时,用一个标记来记录你识别到哪一步了。
- 猎豹 -> . 左前掌 ...: "我正在找猎豹的脚印,期望看到的第一个是左前掌印。"
- 猎豹 -> 左前掌 . 右后掌 ...: "我找到了左前掌印,现在正在找右后掌印。"
- 猎豹 -> ... 左后掌 .: "我完成了对一个完整步态模式的识别!"
- NFA $J$ 的工作: 你在森林里随便走,看到一个脚印,就猜测“这会不会是猎豹的?”,然后开始按手册匹配。这种方法很低效,因为你可能会把兔子的脚印也当成猎豹的开始追踪。
- NFA $K$ 的改进: 下一步要学的 $K$ 会更聪明,它会根据地形、环境等信息,只在“猎豹可能出现”的地方启动追踪,从而大大提高效率。
2727. NFA K 的构造与引理
📜 [原文27]
NFA $K$ 类似地操作,但它更谨慎地选择匹配规则。只允许潜在的规约规则。像 $J$ 一样,它的状态对应于所有带点规则。它有一个特殊的开始状态,该状态对每个涉及开始变量 $S_1$ 的规则都有一个到 $S_1 \rightarrow .u$ 的 $\varepsilon$ 移动。在其计算的每个分支上,$K$ 将潜在的规约规则与输入的子字符串匹配。如果该规则的右侧包含一个变量,$K$ 可以非确定性地切换到扩展该变量的某个规则。引理 2.48 将这个想法形式化。我们首先详细描述 $K$。
转移有两种:移进移动 (shift-moves) 和 $\epsilon$ 移动 ($\epsilon$-moves)。移进移动出现在每个是终结符或变量的 $a$,以及每个规则 $B \rightarrow uav$:
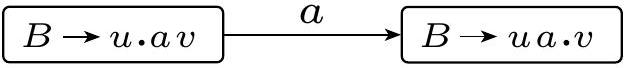
$\epsilon$ 移动出现在所有规则 $B \rightarrow uCv$ 和 $C \rightarrow r$:
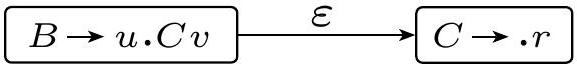
接受状态是所有 $B \rightarrow u.$,对应于已完成的规则。接受状态没有出边,并用双框表示。
下一个引理及其推论证明了 $K$ 接受所有以某个 $z$ 的有效扩展的句柄结尾的字符串 $z$。因为 $K$ 是非确定性的,我们说它“可能”进入一个状态意味着 $K$ 在其非确定性的某个分支上确实进入该状态。
引理 2.48
当读取输入 $z$ 时,$K$ 可能进入状态 $T \rightarrow u . v$ 当且仅当 $z=xu$ 且 $xuvy$ 是有效字符串,其句柄为 $uv$,规约规则为 $T \rightarrow uv$,对于某个 $y \in \Sigma^{*}$。
这部分内容正式地、详细地定义了NFA $K$ 的构造,它是通往最终DFA $DK$ 的关键一步。
NFA $K$ vs NFA $J$
- 相似之处:
- 状态都是带点规则 (items)。
- 都是NFA。
- 关键区别: $K$ 比 $J$ “更谨慎”或“更智能”。
- $J$ 会尝试匹配任何规则的右侧。
- $K$ 只会尝试匹配那些“潜在的规约规则”,即那些可能成为句柄的规则。这个“潜在”是通过一个更精巧的转移机制实现的。
NFA $K$ 的构造规则
- 状态: 集合是所有可能的带点规则。
- 开始状态: 一个特殊的开始状态(我们称之为 $q_{start}$)。从 $q_{start}$,有 $\varepsilon$ 移动连接到所有以开始变量 $S$(原文用 $S_1$)为左侧的规则的初始项。例如,如果 $S \rightarrow ab$ 和 $S \rightarrow c$ 是开始规则,那么就有从 $q_{start}$ 到 [S -> .ab] 和 [S -> .c] 的 $\varepsilon$ 移动。
- 意义: 这确保了 $K$ 的所有计算都从一个合法的、可以从开始变量推导出的结构开始。
- 转移规则: 分为两种。
- 移进移动 (Shift-moves):
- 形式: [B -> u . a v] $\xrightarrow{a}$ [B -> ua . v]
- 含义: 如果 $K$ 当前处于一个期望看到符号 a 的状态(点在 a 前面),并且此时输入流中恰好是 a,那么 $K$ 就消耗掉这个 a,并转移到一个新的状态,这个新状态表示 a 已经被成功匹配(点移动到 a 后面)。这里的 a 可以是终结符或变量。
- 作用: 这是自动机沿着输入字符串向前“吃”的过程。
- $\varepsilon$ 移动 ($\epsilon$-moves):
- 形式: [B -> u . C v] $\xrightarrow{\varepsilon}$ [C -> . r] (对于所有以C为左侧的规则 $C \rightarrow r$)
- 含义: 如果 $K$ 当前处于一个期望看到一个变量 C 的状态(点在 C 前面),它不能直接从输入流中消耗 C(因为输入流里只有终结符)。所以,$K$ 进行一次非确定性的 $\varepsilon$ 移动。它“猜测”这个 C 将由哪条规则 $C \rightarrow r$ 推导而来,并跳转到对应规则的初始项 [C -> . r],准备开始匹配 r。
- 作用: 这是实现“上下文无关”的关键。它允许自动机在一个大的语法结构的匹配过程中,“潜入”到一个小的、嵌套的语法结构的匹配中去。这就是 $K$ 比 $J$ 聪明的地方,$K$ 的 $\varepsilon$ 移动是有目的的、上下文驱动的。
- 接受状态:
- 定义: 所有“完成项”,即形如 [B -> u .] 的状态。
- 特点: 接受状态没有出边,并用双框表示。一旦进入,就意味着一个潜在的句柄已经被完整识别。
引理 2.48 的陈述与意义
这个引理是理解 $K$ 的功能的关键。它精确地描述了 $K$ 的状态和文法的归约过程之间的深刻联系。
- 引理内容: $K$ 在读取字符串 $z$ 后,能够到达状态 [T -> u . v] $\iff$(当且仅当)存在一个分解 $z=xu$,使得 $xuvy$ 是一个有效字符串,并且其(在最左归约中的)句柄恰好是 $uv$。
- 解读 ($\Rightarrow$): 如果 $K$ 经过一系列移动,读了 $z$ 并到达了 [T -> u . v],那么这个计算路径本身就编码了一棵部分分析树。这棵树证明了 $z$(也就是 $xu$)是某个以 $uv$ 为句柄的有效字符串的前缀。
- 解读 ($\Leftarrow$): 如果存在一个以 $uv$ 为句柄的有效字符串 $xuvy$,那么在最右推导中,必然存在一个从 $T$ 推导出 $uv$ 的过程,并且这个过程镶嵌在从开始变量推导出 $xuvy$ 的更大过程中。$K$ 的 $\varepsilon$ 移动和移进移动的设计,恰好能完美地模拟这个推导的逆过程,从而在读取 $xu$ 后到达状态 [T -> u . v]。
- 核心价值: 这个引理告诉我们,NFA $K$ 的运行过程,完全复刻了(所有可能的)最左归约过程。$K$ 的每一个状态都对应着归约过程中的一个确切的中间步骤。
- 移进移动图示:
- 它展示了当点.的右边是一个符号a时,自动机如何通过消耗输入a来把点向前推进一格。这是LR解析中的“移进 (Shift)”操作的自动机表示。
- $\varepsilon$移动图示:
- 它展示了当点.的右边是一个变量C时,自动机如何通过一个不消耗输入的 $\varepsilon$ 移动,非确定性地跳转到所有以C为左侧的规则的初始项。这对应于LR解析中,在构建项目集时进行的“闭包 (Closure)”操作。
- 文法: $S \rightarrow (S) \mid \varepsilon$
- NFA $K$ 的部分构造:
- 开始: 从 $q_{start}$ 有 $\varepsilon$ 移动到 [S -> . (S)] 和 [S -> .]。
- 状态 [S -> . (S)]:
- 这是一个期望看到 ( 的状态。
- 移进: $\xrightarrow{(}$ 到达 [S -> ( . S)]。
- 状态 [S -> ( . S)]:
- 这是一个期望看到变量 S 的状态。
- $\varepsilon$移动: 触发到 $S$ 规则初始项的 $\varepsilon$ 移动。
- $\xrightarrow{\varepsilon}$ 到达 [S -> . (S)] (回到自身)。
- $\xrightarrow{\varepsilon}$ 到达 [S -> .]。
- 状态 [S -> .]:
- 这是一个完成项,因此它是一个接受状态。
- 追踪输入 ():
- $q_{start}$ $\xrightarrow{\varepsilon}$ [S -> . (S)]
- 读入 (: [S -> . (S)] $\xrightarrow{(}$ [S -> ( . S)]
- 在 [S -> ( . S)] 中,进行 $\varepsilon$ 移动: $\xrightarrow{\varepsilon}$ 到 [S -> .]。
- 在 [S -> .] 中,这是一个完成项,对应规则 $S \rightarrow \varepsilon$。这识别出了一个句柄 ε。在 () 的归约 (ε) 中,ε 是句柄。这与引理相符。
- (继续追踪) 假设归约发生,回到 [S -> ( S . )] 状态。
- 读入 ): [S -> ( S . )] $\xrightarrow{)}$ [S -> (S) .]。
- 到达 [S -> (S) .],这是另一个接受状态,识别出句柄 (S)。
- 变量与终结符: 在移进移动中,点后面的符号 a 可以是终结符或变量。但在 DFA 中,转移边上只能是终结符。这个区别在子集构造时会体现出来,对变量的移进实际上是在DFA状态内部完成的。
- $\varepsilon$移动的递归性: $\varepsilon$ 移动可以形成一个链条。如果 A -> . B ..., B -> . C ..., 那么从 A 的项会有一个 $\varepsilon$ 闭包,包含 B 和 C 的初始项。这个闭包计算是构造LR自动机的核心算法。
本节形式化地定义了NFA $K$,它是识别文法所有句柄前缀的核心构造。与过于宽泛的NFA $J$ 不同,$K$ 的转移规则被设计得更为精巧:移进移动负责消耗输入并推进匹配,而$\varepsilon$移动则在需要匹配一个变量时,非确定性地跳转到该变量所有产生式的初始项,从而模拟了上下文无关的嵌套结构。最后,关键的引理2.48指出,$K$ 的计算过程与文法的最左归约过程存在一一对应关系,即 $K$ 能到达某个状态,当且仅当输入是对应的一个有效句柄前缀。这为通过分析 $K$(及其确定化版本 $DK$)的结构来判断文法性质奠定了理论基础。
本段的目的是提供构造DFA $DK$ 所需的“原材料”——NFA $K$。通过详细定义 $K$ 的两种转移(移进和$\varepsilon$移动),它实际上给出了编译器理论中著名的“构造LR(0)项目集规范族”的自动机化视角。引理2.48则是这个构造正确性的理论保证,它说明了为什么这个自动机真的能“识别句柄”。这是从文法理论走向自动机实践的关键一步。
你是一个侦探,在调查一个庞大的犯罪组织(文法)。
- NFA $K$: 你的整个调查网络。
- 带点规则 (状态): 每一个状态都是一个“案情假设”,比如“嫌疑人A(变量)参与了B计划(产生式),目前我们已经掌握了他第一步的证据(点左边),正在调查第二步(点右边)”。
- 移进移动: 你找到了一个物证(终结符),证实了你假设的第二步,于是你更新案情记录(进入新状态)。
- $\varepsilon$移动: 你的案情假设需要“嫌疑人C”的参与。但C是个神秘人物,他可能通过多种方式(C的产生式)参与。于是你的调查网络分叉了,派出多个小组($\varepsilon$移动),分别去调查C的每一种可能性。
- 引理2.48: 这个引理告诉你,你的调查网络是完备的。只要一个犯罪计划(有效字符串和句柄)真实存在,你的网络中就一定有一条调查路径能与之对应。
你正在用乐高拼一个极其复杂的千年隼号模型。
- 说明书 (CFG): 整个模型的说明书。
- NFA $K$: 你的一种拼装策略。
- 带点规则 (状态): 你脑子里的一个念头,比如“我现在要拼的是驾驶舱(一个大变量),说明书说驾驶舱由座椅和仪表盘组成,我已经拼好了座椅(点左边),现在要找仪表盘的零件了(点右边)”。
- 移进移动: 你找到了仪表盘零件,把它拼了上去。你的念头更新为“驾驶舱的座椅和仪表盘都拼好了”。
- $\varepsilon$移动: 你要开始拼驾驶舱了。你翻到说明书里讲驾驶舱的那一页,发现驾驶舱本身又由“座椅组件”和“仪表盘组件”构成。于是你脑子里冒出两个新的子任务($\varepsilon$移动):“开始拼座椅组件”和“开始拼仪表盘组件”。
- 引理2.48: 这个引理保证了,只要你按照说明书的所有可能性去尝试,你的拼装过程($K$的路径)总能覆盖所有正确的拼装步骤。
2828. 引理2.48的证明
📜 [原文28]
证明思路 $K$ 通过将所选规则的右侧与输入的一部分匹配来操作。如果该匹配成功完成,它就接受。如果该右侧包含一个变量 $C$,则可能出现两种情况。如果 $C$ 是下一个输入符号,那么匹配所选规则就继续进行。如果 $C$ 已被展开,输入将包含从 $C$ 派生出的符号,因此 $K$ 非确定性地选择 $C$ 的替换规则并从该规则右侧的开头开始匹配。当当前所选规则的右侧已完全匹配时,它就接受。
证明 首先证明正向。假设 $K$ 在 $w$ 上进入 $T \rightarrow u . v$ 状态。检查 $K$ 从其开始状态到 $T \rightarrow u . v$ 的路径。将该路径视为由 $\boldsymbol{\varepsilon}$ 移动分隔的移进移动的运行。移进移动是共享同一规则的状态之间的转移,将点向右移动,越过从输入中读取的符号。在第 $i$ 次运行中,假设规则是 $S_i \rightarrow u_i S_{i+1} v_i$,其中 $S_{i+1}$ 是在下一次运行中展开的变量。倒数第二次运行是规则 $S_l \rightarrow u_l T v_l$,最后一次运行是规则 $T \rightarrow uv$。
输入 $z$ 必须等于 $u_1 u_2 \ldots u_l u = xu$,因为字符串 $u_i$ 和 $u$ 是从输入中读取的移进移动符号。令 $y^{\prime}=v_l \ldots v_2 v_1$,我们看到 $xuvy^{\prime}$ 在 $G$ 中是可推导的,因为上面的规则给出了如图 2.49 所示的推导分析树。
图 2.49
导致 $xuvy^{\prime}$ 的分析树
为了获得一个有效字符串,完全展开 $y^{\prime}$ 中出现的所有变量,直到每个变量都派生出一些终结符串,并将结果字符串称为 $y$。字符串 $xuvy$ 是有效的,因为它出现在 $w \in L(G)$ 的最左归约中, $w \in L(G)$ 是通过完全展开 $xuvy$ 中的所有变量而获得的终结符串。
如下图所示,$uv$ 是归约中的句柄,其规约规则是 $T \rightarrow uv$。
图 2.50
导致句柄为 $uv$ 的有效字符串 $xuvy$ 的分析树
现在我们证明引理的反向。假设字符串 $xuvy$ 是一个有效字符串,其句柄为 $uv$,规约规则为 $T \rightarrow uv$。证明 $K$ 在输入 $xu$ 上可能进入状态 $T \rightarrow u . v$。
$xuvy$ 的分析树显示在前面的图中。它以开始变量 $S_1$ 为根,并且必须包含变量 $T$,因为 $T \rightarrow uv$ 是 $xuvy$ 归约中的第一个规约步骤。令 $S_2, \ldots, S_l$ 为从 $S_1$ 到 $T$ 路径上的变量,如图所示。请注意,分析树中出现在此路径左侧的所有变量都必须未展开,否则 $uv$ 就不会是句柄。
在此分析树中,每个 $S_i$ 通过某个规则 $S_i \rightarrow u_i S_{i+1} v_i$ 引导至 $S_{i+1}$。因此,文法必须包含以下规则,用于某些字符串 $u_i$ 和 $v_i$。
$K$ 包含从其开始状态到状态 $T \rightarrow u . v$ 的以下路径,在读取输入 $z=xu$ 时。首先,$K$ 进行一个 $\epsilon$ 移动到 $S_1 \rightarrow . u_1 S_2 v_1$。然后,在读取 $u_1$ 的符号时,它执行相应的移进移动,直到在 $u_1$ 结束时进入 $S_1 \rightarrow u_1 . S_2 v_1$。然后它进行一个 $\varepsilon$ 移动到 $S_2 \rightarrow . u_2 S_3 v_2$ 并在读取 $u_2$ 时继续移进移动,直到它到达 $S_2 \rightarrow u_2 . S_3 v_2$,依此类推。读取 $u_l$ 后,它进入 $S_l \rightarrow u_l . T v_l$,这将通过一个 $\epsilon$ 移动导致 $T \rightarrow . uv$,最后在读取 $u$ 后,它处于 $T \rightarrow u . v$ 状态。
这是对引理2.48的双向证明,旨在严格证明NFA $K$ 的计算路径与文法的最左归约过程是完美对应的。
证明思路的解释
- $K$ 的工作模式: $K$ 的核心是匹配规则右侧。它通过“移进”来消耗终结符,通过“$\varepsilon$移动”来展开非终结符(变量)。
- 变量处理: 当需要匹配变量 $C$ 时,它不能直接从输入中读取 $C$。相反,它非确定性地猜测一个 $C$ 的产生式(如 $C \rightarrow r$),然后转去匹配 $r$。
- 成功与接受: 当一条规则的右侧被完全匹配(点到达末尾),就意味着一个潜在的句柄被识别了,自动机进入接受状态。
正向证明 ($\Rightarrow$): 从 K 的路径到分析树
- 目标: 证明如果 $K$ 读了 $z$ 能到达状态 [T -> u . v],那么 $z=xu$ 并且 $xuvy$ 是一个以 $uv$ 为句柄的有效字符串。
- 证明步骤:
- 分析 $K$ 的路径: 从 $K$ 的开始状态到 [T -> u . v] 的任意一条成功路径,是由一系列“移进移动的片段”和连接它们的“$\varepsilon$移动”组成的。
- 移进与输入: 每一个“移进移动的片段”都对应于匹配某条规则右侧的一部分,并消耗了输入字符串的一部分。将所有这些被消耗的输入部分按顺序拼接起来,就得到了 $K$ 读取的总输入 $z$。
- $\varepsilon$移动与嵌套: 每一次 $\varepsilon$ 移动,都代表从一个规则的匹配(如 [S_i -> ... . S_{i+1} ...])跳转到了一个嵌套规则的开始(如 [S_{i+1} -> . ...])。
- 重建分析树: 我们可以根据这条路径逆向地构建出一棵分析树。最后一次移进运行对应于规则 $T \rightarrow uv$。倒数第二次运行对应于某个规则 $S_l \rightarrow u_l T v_l$,其中 $T$ 被展开。再往前,是 $S_{l-1} \rightarrow u_{l-1} S_l v_{l-1}$... 直到最初的开始变量 $S_1$。这个过程恰好能构造出如图2.49所示的分析树结构。
- 构造有效字符串: 这棵分析树的叶子节点组成了字符串 $xuvy'$,其中 $x=u_1...u_l, y'=v_l...v_1$。这个字符串是可推导的。为了得到一个有效字符串(最左归约路径上的句型),我们将 $y'$ 中所有可能存在的变量完全展开成终结符串,得到 $y$。最终的字符串 $xuvy$ 就是一个有效字符串。
- 确定句柄: 根据这棵分析树的结构(如图2.50),在最右推导中,变量 $T$ 是最后被展开的几个变量之一,它生成了 $uv$。因此,在逆向的归约过程中,$uv$ 是第一个被归约的几个部分之一,并且由于其结构,它就是 $xuvy$ 的句柄,规则是 $T \rightarrow uv$。
反向证明 ($\Leftarrow$): 从分析树到 K 的路径
- 目标: 证明如果 $xuvy$ 是一个以 $uv$ 为句柄的有效字符串,那么 $K$ 在读入 $xu$ 后一定能到达状态 [T -> u . v]。
- 证明步骤:
- 分析句柄和分析树: 因为 $xuvy$ 是一个以 $uv$ 为句柄的有效字符串(规则 $T \rightarrow uv$),那么它的分析树必然包含一个从开始变量 $S_1$ 到变量 $T$ 的路径,且 $T$ 下面挂着 $uv$。更重要的是,因为 $uv$ 是句柄(对应最右推导),所以在 $S_1$ 到 $T$ 这条主干路径左侧的所有子树都必须是单个变量,不能被展开成终结符。
- 提取文法规则: 这条从 $S_1$ 到 $T$ 的路径,必然是由一系列产生式规则构成的,形式为:
$S_1 \rightarrow u_1 S_2 v_1$
$S_2 \rightarrow u_2 S_3 v_2$
...
$S_l \rightarrow u_l T v_l$
$T \rightarrow uv$
- 在 $K$ 中构造路径: 现在,我们可以精确地构造出一条 $K$ 的计算路径来匹配这个结构:
a. 从 $K$ 的开始状态,通过 $\varepsilon$ 移动到 [S1 -> . u1 S2 v1]。
b. 移进 $u_1$:$K$ 消耗输入 $u_1$,状态变为 [S1 -> u1 . S2 v1]。
c. $\varepsilon$移动: 从上述状态,通过 $\varepsilon$ 移动到 [S2 -> . u2 S3 v2]。
d. 移进 $u_2$:消耗输入 $u_2$,状态变为 [S2 -> u2 . S3 v2]。
e. ... 这个过程一直持续 ...
f. 最后,在消耗完 $u_l$ 后,状态为 [Sl -> ul . T vl]。
g. $\varepsilon$移动: 从上述状态,通过 $\varepsilon$ 移动到 [T -> . uv]。
h. 移进 $u$:$K$ 消耗输入 $u$,最终状态变为 [T -> u . v]。
- 结论: 在整个过程中,$K$ 总共消耗了输入 $u_1 u_2 ... u_l u$,这正好等于 $xu$。因此,我们证明了 $K$ 在读取 $xu$ 后,确实可以到达状态 [T -> u . v]。
- 产生式链:
- 这个公式集合并不是文法的一部分,而是从一个给定的分析树中“提取”出来的、构成分析树主干的一系列规则。
- $S_1, S_2, \dots, S_l, T$ 是从根(开始变量)到产生句柄的那个变量 $T$ 的路径上的所有变量。
- $u_i, v_i$ 是这些规则中,出现在主干变量左侧和右侧的符号串。$u_i$ 最终构成了句柄前缀的一部分 $x$。
引理2.48的证明通过双向论证,严谨地建立了NFA $K$ 的计算状态与文法最左归约过程中的句柄和句型之间的等价关系。正向证明表明,$K$ 的任何一条计算路径都可以被翻译成一个合法的(部分)分析树,从而证明其识别的是一个有效句柄前缀。反向证明则表明,任何一个合法的句柄和句型,其分析树结构都可以被精确地映射为 $K$ 中的一条计算路径。这个证明是整个DK检验理论的基石,它保证了我们通过分析 $K$(及其确定化版本 $DK$)得到的结论,能够忠实地反映原始文法的内在结构属性。
本证明的目的是为引理2.48这一核心论断提供数学上的严谨性。没有这个证明,引理就只是一个“断言”或“猜想”。通过这个构造性的双向证明,我们确信了NFA $K$ 作为一个分析工具的正确性和完备性。它是连接抽象文法世界和具体自动机世界的桥梁,确保了我们在自动机上观察到的现象(如状态冲突)能够直接、可靠地翻译回文法世界的属性(如非确定性)。
2929. 推论2.51与DK检验的准备
📜 [原文29]
推论 2.51
$K$ 可能在输入 $z$ 上进入接受状态 $T \rightarrow h.$ 当且仅当 $z=xh$ 且 $h$ 是某个有效字符串 $xhy$ 的句柄,规约规则为 $T \rightarrow h$。
最后,我们通过在第 55 页的定理 1.39 的证明中使用子集构造将 NFA $K$ 转换为 DFA $DK$,然后删除所有从开始状态无法到达的状态。因此,$DK$ 的每个状态都包含一个或多个带点规则。每个接受状态都包含至少一个已完成的规则。我们可以通过引用包含所示带点规则的状态来将引理 2.48 和推论 2.51 应用于 $DK$。
现在我们准备描述 DK 检验。
从 CFG $G$ 开始,构造相关的 DFA $DK$。通过检查 $DK$ 的接受状态来确定 $G$ 是否是确定性的。DK 检验规定每个接受状态包含
- 恰好一个已完成的规则,并且
- 没有点后立即跟着终结符号的带点规则,即没有形式为 $B \rightarrow u . av$ 的带点规则,其中 $a \in \Sigma$。
这部分内容是DK检验的正式登场。它首先从引理2.48导出一个更直接的推论,然后描述了如何从NFA $K$ 得到最终的DFA $DK$,最后给出了DK检验的具体检测标准。
推论 2.51
- 内容: 这是引理2.48的一个特例,但却是最有用的特例。它关注的是NFA $K$ 的接受状态。
- 引理2.48说的是:$K$ 到达 [T -> u . v] 状态 $\iff$ 输入 $xu$ 是以 $uv$ 为句柄的有效字符串的前缀。
- 推论2.51将这个结论应用于 $v = \varepsilon$ 的情况。此时,状态是 [T -> u .] (一个完成项,即接受状态),句柄是 $u$。
- 所以推论是:$K$ 读了 $z$ 进入接受状态 [T -> h .] $\iff$ 输入 $z$ 本身就是一个句柄前缀($z=xh$),并且句柄就是 $h$。
- 意义: 这个推论直截了当地告诉我们,NFA $K$ 的接受状态恰好能识别出完整的句柄前缀。这正是我们设计它的初衷。
从 NFA $K$ 到 DFA $DK$
- 子集构造: 这是将任何NFA转换为等价DFA的标准算法。
- DFA的状态: $DK$ 的每个状态,都是 $K$ 的一个状态集合。
- DFA的开始状态: 是 $K$ 的开始状态以及所有可以从它通过 $\varepsilon$ 移动到达的状态的集合(即 $\varepsilon$-闭包)。
- DFA的转移: 如果 $DK$ 的一个状态(一个$K$的状态集)在读入符号 $a$ 后,可以转移到 $K$ 的另一组状态集,那么在 $DK$ 中就有一条标记为 $a$ 的边连接这两个状态。
- DFA的接受状态: $DK$ 的任何一个状态,只要它包含的 $K$ 的状态中至少有一个是 $K$ 的接受状态(即完成项),那么这个 $DK$ 的状态就是接受状态。
- 清理: 构造完后,删除所有从开始状态无法到达的死状态。
DK检验的正式描述
有了DFA $DK$,我们终于可以进行检验了。DK检验就是检查 $DK$ 的所有接受状态是否“干净”。一个“干净”的接受状态必须同时满足以下两个条件:
- 条件 1: 无 归约/归约 冲突 (Reduce/Reduce Conflict)
- 规定: “恰好一个已完成的规则”。
- 解释: 一个 $DK$ 的接受状态是一个带点规则的集合。因为它被标记为接受状态,所以这个集合里至少有一个完成项 [A -> u .]。这个条件要求,在整个集合里,不能有第二个完成项,比如 [B -> v .]。
- 为什么: 如果一个状态里有两个完成项,比如 [A -> u .] 和 [B -> v .],这意味着当DFA读到某个前缀并进入这个状态时,它识别出了两个可能的句柄,需要进行两种不同的归约。这就产生了“归约/归约”冲突,违反了确定性。
- 条件 2: 无 移入/归约 冲突 (Shift/Reduce Conflict)
- 规定: “没有点后立即跟着终结符号的带点规则”。
- 解释: 在一个 $DK$ 的接受状态里,除了那个唯一的完成项 [A -> u .] 之外,不能有任何形如 [B -> v . a w] 的项,其中 a 是一个终结符。
- 为什么:
- 完成项 [A -> u .] 的存在,意味着解析器此时有了一个选项:“我已经识别了一个完整的句柄,可以进行归约了。”
- 项 [B -> v . a w] 的存在,意味着解析器此时还有另一个选项:“如果我再多读一个输入符号 a(移入),我可能能匹配一个更长的句柄。”
- 这两个选项并存,解析器就不知道是该“归约”还是该“移入”。这就产生了“移入/归约”冲突,违反了确定性。这恰好对应了“不能向右看”的要求。如果需要向右看一个终结符 $a$ 才能决定是否归约,就说明句柄不是“强制”的。
- 归约/归约冲突的例子:
- 假设一个文法有规则 $A \rightarrow x$ 和 $B \rightarrow x$。
- 在构造 $DK$ 时,可能会出现一个接受状态,它包含 [A -> x .] 和 [B -> x .] 这两个完成项。
- 当DFA读入前缀并进入此状态时,它知道句柄是 $x$,但它不知道是该归约为 $A$ 还是 $B$。
- 结果: DK检验失败,该文法不是DCFG。
- 移入/归约冲突的例子 (来自文法 $G_1$):
- 文法有规则 $S \rightarrow ab$ 和 $T \rightarrow abb$。
- 在构造 $DK$ 的过程中,我们可能会得到一个状态,它包含:
- [S -> ab .] (一个完成项,建议“归约”)
- [T -> ab . b] (一个未完成项,点后面是终结符b,建议“移入b”)
- 当DFA读入前缀 ...ab 并进入此状态时,它就陷入了困境:
- 归约: 我应该宣布 ab 是句柄,并执行 $S \rightarrow ab$ 的归约吗?
- 移入: 还是我应该继续读取下一个符号 b,以期望匹配一个更长的句柄 abb?
- 结果: DK检验失败,该文法不是DCFG。
- 点后跟变量: 条件2只限制了点后跟终结符的情况。如果一个接受状态里,除了完成项,还有一个 [B -> v . C w] (C是变量)的项,这不构成移入/归约冲突。因为对变量的转移是在 $\varepsilon$-闭包中处理的,不直接消耗输入,不构成与“移入一个终结符”的直接冲突。
- LR(k)的区别: 这个DK检验描述的是 LR(0) 文法的检验。标准的 LR(1) 文法允许在有冲突时,向前“看一个”终结符来解决冲突。如果看了这一个终结符后能解决所有冲突,文法就是LR(1) 的。本书中的DCFG定义和DK检验更接近于最严格的LR(0)定义。
本节正式提出了DK检验的具体标准。它首先通过推论2.51确认了NFA $K$ 能够准确识别句柄前缀,然后描述了通过标准的子集构造法将 $K$ 转换为DFA $DK$ 的过程。最终的DK检验是一个对 $DK$ 所有接受状态的结构性检查,包含两个核心条件:1) 每个接受状态必须只包含一个完成项(防止“归约/归约”冲突);2) 接受状态中不能包含点后跟终结符的项(防止“移入/归约”冲突)。一个文法当且仅当其对应的 $DK$ 通过了这两个检验,才被判定为DCFG。
本段的目的是将之前所有的理论铺垫,最终汇聚成一个可执行、可操作的算法——DK检验。它用两条清晰、具体的规则,替代了“强制句柄”这个难以直接验证的抽象概念。这使得判断一个文法是否为DCFG从一个理论问题,变成了一个工程问题。这为编译器自动生成工具(如YACC、Bison)的存在提供了理论基础,这些工具内部就实现了类似DK检验的算法来判断用户提供的文法是否符合LR(k)要求。
你是一个公司的质检员,正在检查一份产品说明书(文法)的清晰度。
- DFA $DK$: 你根据说明书画出了一份“读者决策流程图”。
- 接受状态: 流程图中的某个节点,代表读者读到这里时,可能已经理解了一个完整的章节(句柄)。
- DK检验: 你检查流程图中的所有这些“章节完成”节点。
- 检查1 (无归约/归约冲突): 你检查一个节点,发现它上面写着“读到这里,你可能完成了第2章,也可能完成了第5章”。这个节点不合格,因为指令不唯一。
- 检查2 (无移入/归约冲突): 你检查另一个节点,它写着“读到这里,你完成了第3章。但是,如果你愿意再多读一句话,你就能完成一个更长的、关于3.1节的附录。” 这个节点也不合格,因为它让读者困惑:是该认为第3章已经结束了,还是该继续读下去?
- 结论: 只有当流程图中所有“章节完成”节点都没有这两种“指令不清”的问题时,这份说明书才是一份“确定性”的、清晰的好说明书。
你在一个十字路口指挥交通。这个路口是一个DK的接受状态。
- 归约/归约冲突: 你面前有两条路都亮起了绿灯。你无法指挥车辆,因为去哪边都“合法”。交通陷入混乱。
- 移入/归约冲突: 你面前的直行是绿灯(可以归约),但右转灯在闪黄灯,意思是“你可以右转,但也可以等等看”(可以移入)。你也无法做出唯一指令,司机们会困惑。
- 一个好的路口 (通过DK检验): 在任何时刻,都只有唯一一个方向是绿灯,其他方向都是红灯。指令清晰,交通顺畅。
3030. 定理2.52的证明
📜 [原文30]
定理 2.52
$G$ 通过 DK 检验当且仅当 $G$ 是 DCFG。
证明思路 我们将证明 DK 检验通过当且仅当所有句柄都是强制的。等价地,检验失败当且仅当某个句柄不是强制的。首先,假设某个有效字符串具有非强制句柄。如果我们对该字符串运行 $DK$,推论 2.51 说 $DK$ 在句柄结束时进入接受状态。DK 检验失败,因为该接受状态要么具有第二个已完成规则,要么具有导致接受状态的出边,其中出边以终结符号开头。在后一种情况下,接受状态将包含一个点后跟着终结符号的带点规则。
相反,如果 DK 检验失败,因为一个接受状态有两个已完成规则,则将相关字符串扩展为两个在该点具有不同句柄的有效字符串。类似地,如果它有一个已完成规则和一个点后跟着终结符号的带点规则,则使用引理 2.48 获得两个在该点具有不同句柄的有效扩展。构造与第二个规则对应的有效扩展有点微妙。
证明 从正向开始。假设 $G$ 不是确定性的,并证明它未能通过 DK 检验。取一个有效字符串 $xhy$,它有一个非强制句柄 $h$。因此,某个有效字符串 $xhy'$ 具有不同的句柄 $\hat{h} \neq h$,其中 $y'$ 是一个终结符串。我们因此可以将 $xhy'$ 写成 $\hat{x}\hat{h}\hat{y}$。
如果 $xh = \hat{x}\hat{h}$,则规约规则不同,因为 $h$ 和 $\hat{h}$ 不是同一个句柄。因此,输入 $xh$ 将 $DK$ 发送到一个包含两个已完成规则的状态,这违反了 DK 检验。
如果 $xh \neq \hat{x}\hat{h}$,则其中一个扩展了另一个。假设 $xh$ 是 $\hat{x}\hat{h}$ 的真前缀。如果 $\hat{x}\hat{h}$ 是较短的字符串,则将字符串互换并将 $y$ 代替 $y'$,论证相同。设 $q$ 是 $DK$ 在输入 $xh$ 上进入的状态。状态 $q$ 必须是接受状态,因为 $h$ 是 $xhy$ 的句柄。必须有一条从 $q$ 出发的转移箭头,因为 $\hat{x}\hat{h}$ 通过 $q$ 将 $DK$ 发送到接受状态。此外,该转移箭头标记为终结符号,因为 $y' \in \Sigma^{+}$。在这里 $y' \neq \varepsilon$,因为 $\hat{x}\hat{h}$ 扩展了 $xh$。因此 $q$ 包含一个点后立即跟着终结符号的带点规则,这违反了 DK 检验。
为了证明反向,假设 $G$ 在某个接受状态 $q$ 处未能通过 DK 检验,并通过展示一个非强制句柄来证明 $G$ 不是确定性的。因为 $q$ 是接受状态,它有一个已完成规则 $T \rightarrow h.$。设 $z$ 是导致 $DK$ 到 $q$ 的字符串。那么 $z=xh$,其中某个有效字符串 $xhy$ 的句柄为 $h$,规约规则为 $T \rightarrow h$,对于 $y \in \Sigma^{*}$。现在我们考虑两种情况,具体取决于 DK 检验如何失败。
首先,假设 $q$ 有另一个已完成规则 $B \rightarrow \hat{h}.$。那么某个有效字符串 $xhy'$ 必须有一个不同的句柄 $\hat{h}$,规约规则为 $B \rightarrow \hat{h}.$。因此,$h$ 不是强制句柄。
其次,假设 $q$ 包含一个规则 $B \rightarrow u . av$,其中 $a \in \Sigma$。因为 $xh$ 将 $DK$ 带到 $q$,我们有 $xh=\hat{x}u$,其中 $\hat{x}uav\hat{y}$ 是有效的,并且有一个句柄 $uav$,规约规则为 $B \rightarrow uav$,对于某个 $\hat{y} \in \Sigma^{*}$。为了证明 $h$ 是非强制的,完全展开 $v$ 中的所有变量以得到结果 $v' \in \Sigma^{*}$,然后令 $y'=av'\hat{y}$ 并注意到 $y' \in \Sigma^{*}$。以下最左归约表明 $xhy'$ 是一个有效字符串,$h$ 不是句柄。
其中 $S$ 是开始变量。我们知道 $\hat{x}uav\hat{y}$ 是有效的,我们可以通过使用最右推导从它获得 $\hat{x}uav'\hat{y}$,所以 $\hat{x}uav'\hat{y}$ 也是有效的。此外,$\hat{x}uav'\hat{y}$ 的句柄要么在 $v'$ 内部(如果 $v \neq v'$),要么是 $uav$(如果 $v=v'$)。在这两种情况下,句柄包含 $a$ 或跟随 $a$,因此不能是 $h$,因为 $h$ 完全在 $a$ 之前。因此,$h$ 不是强制句柄。
这是对DK检验正确性的双向证明,它要证明“文法G通过DK检验”与“G是DCFG”是完全等价的。
证明思路
- 等价转换: 证明的核心是把“G是DCFG”这个抽象定义,替换为它的等价命题“G的所有句柄都是强制的”。所以,证明变成了:G通过DK检验 $\iff$ G的所有句柄都是强制的。
- 正向思路 ($\Rightarrow$): 假设G的句柄不是强制的,我们要推出它不能通过DK检验。
- 如果存在一个非强制句柄,就意味着存在一个前缀,它后面可以跟不同的内容,从而导致不同的句柄。
- 这种情况在DFA $DK$ 上就会体现为“冲突”。要么是同一个前缀对应两个不同的归约规则(归约/归约冲突),要么是这个前缀本身可以归约,但如果再多读一个符号又能形成另一个更长的句柄(移入/归约冲突)。无论哪种,都导致DK检验失败。
- 反向思路 ($\Leftarrow$): 假设G不能通过DK检验,我们要推出它一定有非强制句柄。
- DK检验失败只有两种可能:归约/归约冲突,或移入/归约冲突。
- 归约/归约冲突: 这意味着存在一个前缀,可以对应两种不同的归约。我们从这个冲突出发,可以构造出两个具有相同前缀但句柄不同的有效字符串,从而证明存在非强制句柄。
- 移入/归约冲突: 这意味着一个前缀既可以被看作一个完整句柄的结束,也可以被看作另一个更长句柄的开始。同样,我们从这个冲突也能构造出两个具有相同前缀但句柄不同的有效字符串,证明存在非强制句柄。
形式化证明
正向证明:G不是DCFG $\Rightarrow$ G通不过DK检验
- 假设: G不是DCFG,即存在一个非强制句柄。
- 非强制句柄的定义: 存在一个有效字符串 $xhy$(句柄为$h$),以及另一个有效字符串 $xhy'$(句柄为 $\hat{h}$),其中 $\hat{h} \ne h$。
- 分情况讨论:
- 情况一:归约/归约冲突
- 当句柄前缀的长度相同时,即 $xh = \hat{x}\hat{h}$。这意味着同一个前缀 $xh$ 对应了两个不同的句柄(由于规则不同或串本身不同但此处长度相同,必然是规则不同)。
- 根据推论2.51,$DK$在读取前缀 $xh$ 后,会进入一个接受状态。因为这个前缀对应两个不同的归约规则 ($T \rightarrow h$ 和 $B \rightarrow \hat{h}$),所以这个接受状态会包含两个完成项 [T -> h .] 和 [B -> h .]。
- 这违反了DK检验的条件1。检验失败。
- 情况二:移入/归约冲突
- 当句柄前缀长度不同时,不失一般性,假设 $xh$ 是 $\hat{x}\hat{h}$ 的一个真前缀。
- 设 $DK$ 读完 $xh$ 后进入状态 $q$。因为 $h$ 是 $xhy$ 的句柄,所以 $q$ 必须是一个接受状态,包含完成项 [T -> h .]。
- 因为 $\hat{x}\hat{h}$ 比 $xh$ 长,所以 $DK$ 从状态 $q$ 出发,必须还有一条路径可以继续读取符号,最终到达识别 $\hat{h}$ 的另一个接受状态。这条路径的第一个转移边,必然是由一个终结符标记的(因为句柄右侧都是终结符)。
- 这意味着,状态 $q$ 中,除了完成项 [T -> h .],还必然存在一个形如 [... -> ... . a ...] 的项,它代表了那条出边的存在。
- 这违反了DK检验的条件2。检验失败。
反向证明:G通不过DK检验 $\Rightarrow$ G不是DCFG
- 假设: G通不过DK检验。这意味着存在一个接受状态 $q$,它不“干净”。
- 基础: 设 $z$ 是一个能让 $DK$ 到达状态 $q$ 的字符串。因为 $q$ 是接受状态,它必然包含一个完成项,我们称之为 [T -> h .]。根据推论2.51,我们知道 $z=xh$,并且存在一个有效字符串 $xhy$,其句柄是 $h$。
- 分情况讨论失败原因:
- 情况一:归约/归约冲突
- 假设 $q$ 中还有另一个完成项 [B -> h_hat .]。
- 同样根据推论2.51,这意味着存在一个有效字符串 $xhy'$,其句柄是 $\hat{h}$。
- 现在我们有了两个有效字符串 $xhy$ 和 $xhy'$,它们的前缀 $xh$ 是相同的,但句柄 $h$ 和 $\hat{h}$ 不同。
- 根据定义,这证明了 $h$ 是一个非强制句柄。所以G不是DCFG。
- 情况二:移入/归约冲突
- 假设 $q$ 中还有一个项 [B -> u . a v],其中 $a$ 是终结符。
- 根据引理2.48,这个项的存在意味着,存在一个有效字符串 $\hat{x}uav\hat{y}$,其句柄是 $uav$。并且, $DK$ 读入 $\hat{x}u$ 能到达一个包含 [B -> u . a v] 的状态。由于 $DK$ 是确定性的,并且它读入 $z=xh$ 到达了状态 $q$,那么必然有 $xh = \hat{x}u$。
- 现在我们来构造第二个有效字符串。我们知道 $\hat{x}uav\hat{y}$ 是有效的。我们可以把其中的变量 $v$ 展开成终结符串 $v'$,得到 $\hat{x}uav'\hat{y}$,它也是有效的。
- 令 $y' = av'\hat{y}$。我们来看字符串 $xhy' = xh(av'\hat{y}) = (\hat{x}u)av'\hat{y}$。这个字符串也是有效的。
- 但是,这个新字符串 $xhy'$ 的句柄是什么?它的句柄是 $uav$(或其一部分),肯定不是 $h$。因为句柄至少包含了符号 $a$,而 $h$ 在 $a$ 的左边。
- 我们找到了两个有效字符串 $xhy$ 和 $xhy'$,它们有共同的前缀 $xh$,但句柄不同 ($h$ vs. 包含$a$的某个串)。
- 这证明了 $h$ 是一个非强制句柄。所以G不是DCFG。
- 这是一个关键的构造步骤,用于证明移入/归约冲突会导致非强制句柄。
- $xhy' = xh a v' \hat{y}$: 我们构造的新的字符串。
- $= \hat{x} u a v' \hat{y}$: 因为我们知道 $xh = \hat{x}u$。
- $\xrightarrow{*} \hat{x} u a v \hat{y}$: 这一步是一个逆向的推导(即归约)。因为 $v'$ 是从 $v$ 推导出来的终结符串,所以 $v'$ 可以归约回 $v$。
- $\rightarrow \hat{x} B \hat{y}$: 这一步是关键的归约。因为我们知道 $\hat{x}uav\hat{y}$ 的句柄是 $uav$,所以 $uav$ 可以归约为 $B$。
- $\xrightarrow{*} S$: 从 $\hat{x}B\hat{y}$ 继续归约,最终可以归约到开始变量 $S$,因为我们知道 $\hat{x}uav\hat{y}$ 本身就是一个有效字符串(可以归约到S)。
- 结论: 整个序列证明了我们构造的 $xhy'$ 确实是一个可以归约到 $S$ 的有效字符串。
定理2.52的证明是严谨的双向论证。正向证明了如果一个文法不是DCFG(即存在非强制句柄),那么在DFA $DK$ 中必然会导致归约/归约或移入/归约冲突,从而无法通过DK检验。反向证明了如果一个文法无法通过DK检验,那么无论是哪种冲突,我们都可以利用冲突的信息,构造出具有相同前缀但句柄不同的两个有效字符串,从而证明该文法存在非强制句柄,因此不是DCFG。这个定理的证明,最终将“通过DK检验”和“是DCFG”这两个概念在数学上严格地等同了起来。
本证明的目的是为DK检验的正确性提供最终的、坚实的理论保障。它确保了DK检验这个算法工具不是一个“启发式”的、可能会出错的方法,而是与DCFG的形式化定义完全等价的、可靠的判定过程。这个证明是连接LR(k)文法理论与实际的解析器生成算法之间的核心桥梁。
3131. DK检验失败的示例
📜 [原文31]
示例 2.53
这里我们说明 DK 检验如何对以下文法失败。
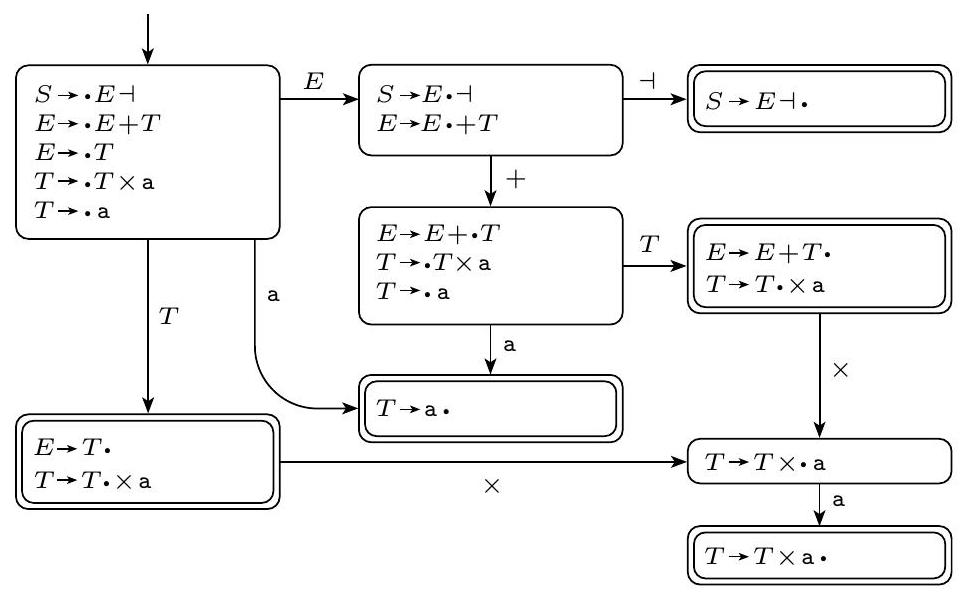
图 2.54
DK 检验失败示例
请注意左下方和右上方第二个有两个问题的状态,其中一个接受状态包含一个带点规则,其点后立即跟着终结符号。
这个示例通过一个具体的算术表达式文法,并展示其对应的DFA $DK$(的一部分),来直观地演示DK检验是如何失败的。
文法分析
这是一个典型的、用于算术表达式的文法,但它具有“左递归” ($E \rightarrow E+T$, $T \rightarrow T \times a$),这种文法对于自顶向下的LL解析器是有问题的,但对于自底向上的LR解析器(DK检验的基础)来说,通常是可以处理的。然而,这个特定的文法结构在这里会导致冲突。
DFA $DK$ 图的分析
图2.54展示了通过子集构造法(和$\varepsilon$-闭包)为该文法生成的DFA $DK$ 的一部分。图中的每个大方框都是DFA $DK$ 的一个状态,里面包含了它所代表的NFA $K$ 的状态集(即带点规则集/Item Set)。
失败点分析
作者指出了两个有问题的状态。我们重点分析其中一个,例如右上方第二个状态(由 E+T 移入 * 到达的那个状态的下游状态):
- 状态内容: 让我们推测这个状态的内容。假设我们有一个状态,在读取了像 a* 这样的前缀之后到达。这个状态可能包含:
- T -> T a . (完成项/可归约项): 这意味着,如果输入到此结束,Ta 就是一个句柄,可以被归约为 T。
- T -> T . a: 从 T 归约后,可能回到一个期望 的状态。
- E -> E . + T: 类似地。
- 让我们直接看图中标出的问题状态。例如,左下方那个状态,它在读取了 T 之后到达。这个状态包含:
- E -> T . (完成项)
- T -> T . * a (未完成项)
- 冲突分析 (移入/归约冲突):
- E -> T . 告诉解析器:“你刚刚识别了一个完整的句柄 T,你可以执行一次归约,用 E 替换 T。”
- T -> T . a 告诉解析器:“你先别急着归约。如果你再多读一个 符号(移入),你就有可能匹配一个更长的 T * a 规则。”
- 困境: 在这个状态,DFA面临一个选择:是“归约”还是“移入”?它不知道哪个选择是正确的,因为这取决于后续的输入。例如,如果输入是 a-,那么应该归约;如果输入是 aa-,那么应该移入。
- 结论: 由于存在这种“移入/归约”冲突,这个状态没有通过DK检验的第二条标准。因此,该文法不是一个DCFG。
右上方第二个状态的分析
类似的,我们可以分析另一个有问题的状态,比如在读取了 E+T 之后的状态。
- 状态内容: 这个状态会包含:
- E -> E + T . (完成项)
- T -> T . a (未完成项) (通过 E -> E+T 归约后,可能回到一个需要T的状态,T又可以扩展到 T.a)
- 冲突分析 (移入/归约冲突):
- E -> E + T . 建议执行归约。
- T -> T . a 建议移入一个 号。
- 同样,这是一个“移入/归约”冲突。
- 结论: 这个状态也未通过DK检验。
- 这是一个典型的表达式文法,定义了加法 + 和乘法 *。
- $S \rightarrow E \dashv$: 整个表达式后面必须跟一个结束标记。
- $E \rightarrow E+T \mid T$: 表达式(Expression)可以是一个表达式加一个项(Term),或者直接是一个项。这一定义了加法的左结合性。
- $T \rightarrow T \times \text{a} \mid \text{a}$: 项可以是一个项乘以一个因子a,或者直接是一个因子a。a在这里代表最基本的单元,如数字或变量。这一定义了乘法的左结合性。这个文法没有定义运算优先级,E+T*a 可能会有歧义,但这里冲突的来源是左递归和句柄识别。
- 输入前缀: a
- 解析器读取 a,可以将其归约为 T (使用 $T \rightarrow a$)。
- 归约后,句型为 T。此时,又可以归约为 E (使用 $E \rightarrow T$)。
- 解析器状态: 在读取 a 之后,DFA $DK$ 会到达一个状态,该状态同时包含 T -> a . 和 E -> T . (通过$\varepsilon$闭包)。
- 假设我们先归约 T -> a,得到 T。此时,我们面临选择:如果下一个符号是 ,我们应该移入 来匹配 T * a。如果下一个符号是 + 或者 $\dashv$,我们应该将 T 归约为 E。
- 这种不确定性,就体现在了DFA $DK$ 的状态冲突中。图中左下方的状态正是在读取 a 并归约为 T 之后到达的状态。
- 冲突的根源: 这个文法中的冲突,根源在于它没有显式地定义运算符的优先级。当解析器看到 T 时,它不知道这个 T 是准备参与一个更高优先级的乘法(因此要移入 *),还是应该结束作为一个加法表达式的一部分(因此要归约为 E)。
- 如何修复: 要修复这个文法,使其通过DK检验,通常需要重写文法来明确优先级,或者使用更强大的LALR(1)等解析技术,它允许通过向前看一个符号来解决这类冲突。
示例2.53提供了一个DK检验失败的具体案例。通过为给定的算术表达式文法构造其对应的DFA $DK$(图2.54),我们可以清晰地观察到,在某些状态下(例如读取了T之后的状态),同时存在一个“完成项”(建议归约)和一个“点后跟终结符的项”(建议移入)。这种“移入/归约冲突”违反了DK检验的规定,因此我们得出结论,该文法不是一个DCFG。这个例子直观地展示了DK检验是如何将文法中的结构性不确定性,转化为自动机状态中的具体冲突的。
本示例的目的是将抽象的DK检验规则,与一个具体、可视化的DFA图联系起来。它让读者不再只是理解检验的“规定”,而是能亲眼“看到”一个不符合规定的状态是什么样子的。通过分析图中状态的内容和其代表的冲突,读者可以更深刻地理解“移入/归约冲突”的实际含义,以及它为何会导致文法的非确定性。
这就像一个语法检查程序在分析你的句子。
- 句子: "The old man the boat."
- 程序分析: 当程序读到 "The old man" 时,它可能认为这是一个完整的名词短语(可以“归约”)。但是,它也知道 "man" 可以作动词(比如操纵船只),所以它还有一个选项是继续读下去,看 "man" 是否是句子的谓语(可以“移入”下一个词 "the")。
- 冲突: 程序陷入了“移入/归约”冲突。它不知道 "The old man" 在这里应该被看作一个结束的短语,还是一个未完成的句子的一部分。
- 类比: 示例2.53中的文法就造成了类似的困境,而DK检验就是那个能够检测出这种“语法病句”的程序。
你正在做一道菜,完全按照菜谱来。
- 菜谱: 文法。
- 你: 解析器/DFA。
- 冲突状态: 你做完了一道“番茄炒蛋”(一个完成项 T -> a .),菜谱上说,你可以把它盛盘了(归约)。但同一页的旁边还有一条小字写着:“或者,你也可以把它和旁边的豆腐混合,做成‘番茄炒蛋烧豆腐’”(一个未完成项 T -> T . * a)。
- 你的困境: 你不知道该不该盛盘。你需要看看旁边到底有没有豆腐(向右看)。
- DK检验失败: 这个菜谱写得不好,有“移入/归约”冲突,不是一个“确定性菜谱”。
3232. DK检验成功的示例
📜 [原文32]
示例 2.55
这是 DFA $DK$,显示以下文法是一个 DCFG。
图 2.56
通过 DK 检验的示例
请注意,所有接受状态都满足 DK 检验条件。$\square$
这个示例与上一个示例2.53形成鲜明对比,它展示了一个“行为良好”的文法,以及其如何顺利通过DK检验。
文法分析
- 文法: 这是之前在示例2.46中介绍过的、用于生成平衡括号序列的文法,并带有结束标记。
- 特点:
- $S \rightarrow T \dashv$: 保证了主结构由 $T$ 生成,并以 $\dashv$ 结尾。
- $T \rightarrow T(T) \mid \varepsilon$: 这是一个右递归的文法($T$ 出现在规则右侧的左边)。这种结构通常对LR解析器是友好的。它能生成如 ()\dashv, ()()\dashv, (())\dashv 等字符串。
DFA $DK$ 图的分析
图2.56展示了为这个文法生成的完整的DFA $DK$。我们来检查它的接受状态,看它们是否“干净”。
- 接受状态: 在图中,用双框表示的都是接受状态。我们可以看到有几个这样的状态。
- 左上角的接受状态:
- 内容: T -> ε .
- 检验:
- 条件1 (无R/R冲突): 这个状态里只有一个完成项 T -> ε .。通过。
- 条件2 (无S/R冲突): 这个状态里没有任何“点后跟终结符”的项。通过。
- 结论: 此状态干净。
- 中间的接受状态:
- 路径: 从开始,读入 ( ) 后可以到达。
- 内容: T -> T(T) .
- 检验:
- 条件1: 只有 T -> T(T) . 这一个完成项。通过。
- 条件2: 没有形如 ... . a ... 的项。通过。
- 结论: 此状态干净。
- 最右边的接受状态:
- 路径: 读入 T 和 \dashv 后到达。
- 内容: S -> T \dashv .
- 检验:
- 条件1: 只有 S -> T \dashv . 这一个完成项。通过。
- 条件2: 没有形如 ... . a ... 的项。通过。
- 结论: 此状态干净。
- 全局结论: 经过检查,图中所有的接受状态都完美地满足了DK检验的两条标准。没有任何归约/归约冲突或移入/归约冲突。
最终判定
因为该文法对应的DFA $DK$ 顺利通过了DK检验,所以我们得出结论:该文法是一个DCFG。
- $S \rightarrow T \dashv$: 开始规则。$S$ 是开始变量,它推导出一个由 $T$ 生成的结构,后面跟着一个终结符 $\dashv$(结束标记)。
- $T \rightarrow T(T)$: 递归规则。一个 $T$ 结构可以是一个 $T$ 结构后面跟着一个括号,括号里面又是一个 $T$ 结构。这可以生成 ()()() 这样的并列结构。
- $T \rightarrow \varepsilon$: 基础规则。$T$ 可以是空串。这允许递归终止,并生成最基本的 () 结构。
让我们追踪输入 ()\dashv 在这个DFA $DK$ 上的路径,来理解为什么没有冲突。
- 开始状态: 包含 [S -> . T \dashv], [T -> . T(T)], [T -> .]。注意这里就有个 T -> . 的完成项,但这不是接受状态,因为 \dashv 和 ( 都是可能的后随符号,这暗示文法是LR(1)而不是LR(0)。本书的DK检验简化了这一点,我们只检查最终的接受状态。
- 读入 (: 转移到一个新状态,其核心是 [T -> T( . T)]。经过$\varepsilon$-闭包,这个状态还会包含 [T -> . T(T)] 和 [T -> .]。
- 读入 ):
- 在 [T -> .] 这个项上,它建议进行归约 $T \rightarrow \varepsilon$。
- 归约后,状态会回到上一步,即核心为 [T -> T( . T)] 的状态,此时句型变为 (T。
- 现在,我们有了 T,可以从 [T -> T( . T)] 移进 T,到达核心为 [T -> T(T . )] 的状态。
- 在这个新状态 [T -> T(T . )] 中,我们期望读入 )。现在输入恰好是 ),于是我们移入 ),到达核心为 [T -> T(T) .] 的状态。
- 这个状态 [T -> T(T) .] 是一个接受状态。它里面只有一个完成项,没有其他冲突项。检验通过。
- 这个过程非常复杂,手动模拟很容易出错。关键在于理解图的含义:图的构造过程已经保证了在任何一个状态,面对任何一个输入,转移都是唯一的,并且在接受状态没有出现定义中的两种冲突。
- LR(0) vs LR(1): 这个文法实际上不是LR(0)的,但它是LR(1)的。例如,在初始状态,看到 ) 时,应该执行归约 $T \rightarrow \varepsilon$。但看到 ( 时,应该移入。这个决策需要向前看一个符号。本书的DK检验定义似乎简化了这一点,主要关注状态本身的内容,而不是解决冲突的lookahead集合。但其精神是一致的:通过构造一个DFA来检查文法的确定性。
- 图的完整性: 示例图可能不是由严格的LR(0)项目集构造的,而是一个更通用的、旨在说明问题的DFA。关键在于理解其最终结论:所有接受状态都是“干净”的。
示例2.55提供了一个DK检验成功的正面案例。它展示了文法 $S \rightarrow T\dashv, T \rightarrow T(T) \mid \varepsilon$ 所对应的DFA $DK$。通过逐一检查图中的所有接受状态(用双框标出),可以发现,每一个接受状态都满足DK检验的两条标准:既没有包含多个完成项(无R/R冲突),也没有在包含完成项的同时还包含“点后跟终结符”的项(无S/R冲突)。由于自动机的所有接受状态都是“干净的”,没有歧义,因此我们得出结论,这个文法是一个DCFG。
本示例的目的是与前一个失败的例子形成对比,完整地展示DK检验的双向判断能力。它告诉读者,DK检验不仅仅是一个“找茬”的工具,也是一个“发合格证”的工具。通过这个成功的例子,读者可以看到一个结构良好的DCFG在DFA $DK$ 中会呈现出一种清晰、无冲突的模式,从而对“确定性”在自动机层面的体现有一个更完整、更平衡的认识。
这回,你拿到了一本写得非常好的产品说明书(文法)。
- DFA $DK$: 你为这本说明书画出的“读者决策流程图”。
- 检查: 你检查流程图中所有代表“读完一章”的节点。
- 结果:
- 在每个这样的节点,都明确无误地写着“你刚刚读完了第X章”。绝不会出现“可能是第X章,也可能是第Y章”的情况。
- 在每个这样的节点,也都明确指示“本章已结束,请翻到下一章”,绝不会有“本章已结束,但如果你还想读一句话,可以翻到附录...”这样的令人困惑的附加选项。
- 结论: 这本说明书的结构是“确定性的”,每个部分的结束和开始都界定得清清楚楚。它通过了质检。
你正在一个设计得极好的十字路口指挥交通。
- 路口 (DK接受状态): 这个路口设计堪称完美。
- 你的体验:
- 在任何时刻,永远只有唯一一个方向的绿灯亮起。你从不担心会发出冲突的指令。
- 更重要的是,任何一条路的绿灯亮起时,其他所有方向的(无论是直行、左转还是右转)的信号灯都是明确的红灯。绝不会出现“直行绿灯,但右转黄灯闪烁”这种情况。
- 结论: 这个路口的信号系统设计是“确定性”的,它通过了交通安全检验。
33行间公式索引
- DPDA的确定性条件:
这句话描述了在任何给定的状态、输入符号和栈顶符号的组合下,最多只有一个转移规则可以被激活,从而保证了DPDA的确定性。
- 归约序列的通用表示:
这个序列表示一个字符串 $u$ 可以通过一系列的单步归约操作,最终转变为字符串 $v$。
- 句柄的图示化分解:
该图示详细地展示了一次归约操作,其中中间句型 $u_i$ 中的子串 $h$(句柄)被其对应的变量 $T$ 替换,从而得到新的句型 $u_{i+1}$。
- 示例2.45中的文法G1:
这个文法用于生成语言 $\{a^m b^m\} \cup \{a^m b^{2m}\}$,并被用作一个无歧义但非确定性的反例。
- 示例2.45中的第一个归约序列:
这个序列展示了对字符串 aaabbb(原文可能有误)进行最左归约的过程,并用下划线标出了每一步的句柄。
- 示例2.45中的第二个归约序列:
这个序列展示了对字符串 aaabbbbbb 进行最左归约的过程,突出了句柄识别对右侧上下文的依赖。
- 与G1对比的确定性文法G2:
这个文法通过在字符串开头添加'1'或'2'作为标记,消除了不确定性,使其成为一个DCFG。
- 示例2.46中的文法G3:
这个生成平衡括号序列的文法被用来引入“带结束标记的语言”和“ε句柄”的概念。
- 示例2.46中的归约序列:
此序列(尽管有笔误)旨在说明在归约过程中可能会出现空串ε作为句柄的情况。
- 带点规则(Item)的通用形式:
这组公式展示了由一条产生式可以生成的所有带点规则,它们代表了匹配该规则右侧的不同进度阶段。
- 从分析树中提取的产生式链:
这代表了从分析树的根到句柄对应变量的路径上的一系列产生式,是引理2.48证明中的关键构造。
- 移入/归约冲突的归约构造:
这个归约序列被用来证明,当DK检验因移入/归约冲突而失败时,我们可以构造出一个具有非强制句柄的有效字符串。
- 示例2.53中导致DK检验失败的文法:
这是一个左递归的算术表达式文法,其结构导致了在DK检验中出现移入/归约冲突。
- 示例2.55中通过DK检验的文法:
这个用于平衡括号的文法结构良好,其对应的DFA $DK$中没有冲突,因此它是一个DCFG。
[[END_OF_RESPONSE]]所有解释内容已全部输出完毕。