12.4 确定性上下文无关语言
回想一下,确定性有限自动机和非确定性有限自动机在语言识别能力上是等价的。相比之下,非确定性下推自动机比它们的确定性对应物更强大。我们将证明某些上下文无关语言不能被确定性下推自动机 (DPDA) 识别——这些语言需要非确定性下推自动机。能够被确定性下推自动机 (DPDA) 识别的语言称为确定性上下文无关语言 (DCFL)。这个上下文无关语言的子类与实际应用相关,例如编程语言编译器中解析器的设计,因为对于 DCFL 而言,解析问题通常比对于 CFL 而言更容易。本节简要概述了这个重要而优美的主题。
在定义 DPDA 时,我们遵循确定性的基本原则:在计算的每一步,DPDA 根据其转移函数最多只有一种方式可以进行。定义 DPDA 比定义 DFA 更复杂,因为 DPDA 可以在不弹出栈符号的情况下读取输入符号,反之亦然。因此,我们允许 DPDA 的转移函数中包含 $\varepsilon$ 移动,尽管 DFA 中禁止 $\varepsilon$ 移动。这些 $\varepsilon$ 移动有两种形式:对应于 $\delta(q, \boldsymbol{\varepsilon}, x)$ 的 $\boldsymbol{\varepsilon}$ 输入移动,以及对应于 $\delta(q, a, \boldsymbol{\varepsilon})$ 的 $\boldsymbol{\varepsilon}$ 栈移动。一个移动可能结合这两种形式,对应于 $\delta(q, \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon})$。如果一个 DPDA 在特定情况下可以进行 $\varepsilon$ 移动,则它被禁止在该相同情况下进行涉及处理符号而不是 $\varepsilon$ 的移动。否则可能会出现多个有效的计算分支,导致非确定性行为。形式化定义如下。
定义 2.39
一个确定性下推自动机是一个 6 元组 ( $Q, \Sigma, \Gamma, \delta, q_{0}, F$ ),其中 $Q, \Sigma, \Gamma$ 和 $F$ 都是有限集,且
- $Q$ 是状态集,
- $\Sigma$ 是输入字母表,
- $\Gamma$ 是栈字母表,
- $\delta: Q \times \Sigma_{\varepsilon} \times \Gamma_{\varepsilon} \longrightarrow\left(Q \times \Gamma_{\varepsilon}\right) \cup\{\emptyset\}$ 是转移函数,
- $q_{0} \in Q$ 是开始状态,且
- $F \subseteq Q$ 是接受状态集。
转移函数 $\delta$ 必须满足以下条件。对于每个 $q \in Q, a \in \Sigma$, 和 $x \in \Gamma$, 以下值中只有一个不为 $\emptyset$:
转移函数可以输出形式为 $(r, y)$ 的单个移动,也可以通过输出 $\emptyset$ 表示没有动作。为了说明这些可能性,让我们考虑一个例子。假设一个 DPDA $M$ 带有转移函数 $\delta$,处于状态 $q$,其下一个输入符号是 $a$,并且其栈顶是符号 $x$。如果 $\delta(q, a, x)=(r, y)$,那么 $M$ 读取 $a$,将 $x$ 从栈中弹出,进入状态 $r$,并将 $y$ 压入栈中。或者,如果 $\delta(q, a, x)=\emptyset$,那么当 $M$ 处于状态 $q$ 时,它没有读取 $a$ 并弹出 $x$ 的移动。在这种情况下,$\delta$ 的条件要求 $\delta(q, \varepsilon, x), \delta(q, a, \varepsilon)$, 或 $\delta(q, \varepsilon, \varepsilon)$ 中的一个非空,然后 $M$ 相应地移动。该条件通过阻止 DPDA 在相同情况下采取两种不同的动作来强制确定性行为,例如如果 $\delta(q, a, x) \neq \emptyset$ 和 $\delta(q, a, \varepsilon) \neq \emptyset$ 都成立。当栈非空时,DPDA 在每种情况下都只有一个合法的移动。如果栈为空,DPDA 只有当转移函数指定一个弹出 $\varepsilon$ 的移动时才能移动。否则 DPDA 没有合法的移动,它会在不读取剩余输入的情况下拒绝。
DPDA 的接受方式与 PDA 相同。如果 DPDA 在读取完输入字符串的最后一个输入符号后进入一个接受状态,它就接受该字符串。在所有其他情况下,它拒绝该字符串。拒绝发生的情况是 DPDA 读取了整个输入,但在结束时没有进入接受状态,或者 DPDA 未能读取整个输入字符串。后一种情况可能出现,如果 DPDA 试图弹出空栈,或者如果 DPDA 进行了一系列无休止的 $\varepsilon$ 输入移动,而没有读取输入超过某一点。
DPDA 的语言称为确定性上下文无关语言。
示例 2.40
示例 2.14 中的语言 $\left\{0^{n} 1^{n} \mid n \geq 0\right\}$ 是一个 DCFL。我们可以通过为任何缺失的状态、输入符号和栈符号组合添加转移到一个不可能接受的“死”状态来轻松修改其 PDA $M_{1}$,使其成为一个 DPDA。
示例 2.16 和 2.18 给出了 CFLs $\left\{\mathrm{a}^{i} \mathrm{~b}^{j} \mathrm{c}^{k} \mid i, j, k \geq 0 \text{ 且 } i=j \text{ 或 } i=k\right\}$ 和 $\left\{w w^{\mathcal{R}} \mid w \in\{0,1\}^{*}\right\}$,它们不是 DCFLs。问题 2.27 和 2.28 表明识别这些语言需要非确定性。
涉及 DPDA 的论证往往在技术上有些复杂,尽管我们努力强调构造背后的主要思想,但读者可能会发现本节比前几章的其他节更具挑战性。本书后面的材料不依赖本节,因此如果需要可以跳过。
我们将从一个技术性引理开始,它将简化后面的讨论。如前所述,DPDA 可能会因为未能读取整个输入而拒绝输入,但这样的 DPDA 会引入混乱的情况。幸运的是,下一个引理表明我们可以将 DPDA 转换为一个避免这种不便行为的 DPDA。
引理 2.41
每个 DPDA 都有一个等价的 DPDA,它总是读取整个输入字符串。
证明思路 如果 DPDA 尝试弹出一个空栈,或者因为它进行了一系列无休止的 $\varepsilon$ 输入移动,它可能无法读取整个输入。我们将第一种情况称为挂起 (hanging),第二种情况称为循环 (looping)。我们通过用一个特殊符号初始化栈来解决挂起问题。如果该符号在输入结束前从栈中弹出,DPDA 会读取到输入末尾并拒绝。我们通过识别循环情况,即那些永远不再读取输入符号的情况,并重新编程 DPDA,使其读取并拒绝输入而不是循环来解决循环问题。我们必须调整这些修改以适应在输入最后一个符号处发生挂起或循环的情况。如果 DPDA 在读取完最后一个符号后进入接受状态,则修改后的 DPDA 接受而不是拒绝。
证明 令 $P=\left(Q, \Sigma, \Gamma, \delta, q_{0}, F\right)$ 为一个 DPDA。首先,添加一个新开始状态 $q_{\text {start}}$、一个额外的接受状态 $q_{\text {accept}}$、一个新状态 $q_{\text {reject}}$,以及其他如所述的新状态。对每个 $r \in Q, a \in \Sigma_{\varepsilon}$, 和 $x, y \in \Gamma_{\varepsilon}$ 执行以下更改。
首先修改 $P$,使其一旦进入接受状态,就保持在接受状态直到读取下一个输入符号。对于每个 $q \in Q$,添加一个新接受状态 $q_{\mathrm{a}}$。对于每个 $q \in Q$,如果 $\delta(q, \boldsymbol{\varepsilon}, x)=(r, y)$,则设置 $\delta\left(q_{\mathrm{a}}, \boldsymbol{\varepsilon}, x\right)=\left(r_{\mathrm{a}}, y\right)$,然后如果 $q \in F$,也将 $\delta$ 更改为 $\delta(q, \varepsilon, x)=\left(r_{\mathrm{a}}, y\right)$。对于每个 $q \in Q$ 和 $a \in \Gamma$,如果 $\delta(q, a, x)=(r, y)$,则设置 $\delta\left(q_{\mathrm{a}}, a, x\right)=(r, y)$。令 $F^{\prime}$ 为新旧接受状态的集合。
接下来,修改 $P$,使其在尝试弹出空栈时拒绝,通过用一个特殊的栈符号 $\%%MATH_BLOCK_75%%,它会进入 $q_{\text {reject}}$ 并扫描输入直到结束。如果 $P$ 在接受状态检测到 $\$$,它会进入 $q_{\text {accept}}$。然后,如果仍有未读取的输入,它会进入 $q_{\text {reject}}$ 并扫描输入直到结束。形式上,设置 $\delta\left(q_{\text {start}}, \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon}\right)=\left(q_{0}, \$\right)$。对于 $x \in \Gamma$ 和 $\delta(q, a, x) \neq \emptyset$,如果 $q \notin F^{\prime}$,则设置 $\delta(q, a, \$)=\left(q_{\text {reject}}, \varepsilon\right)$,如果 $q \in F^{\prime}$,则设置 $\delta(q, a, \$)=\left(q_{\text {accept}}, \boldsymbol{\varepsilon}\right)$。对于 $a \in \Sigma$,设置 $\delta\left(q_{\text {reject}}, a, \boldsymbol{\varepsilon}\right)=\left(q_{\text {reject}}, \boldsymbol{\varepsilon}\right)$ 和 $\delta\left(q_{\text {accept}}, a, \boldsymbol{\varepsilon}\right)=\left(q_{\text {reject}}, \boldsymbol{\varepsilon}\right)$。
最后,修改 $P$,使其拒绝而不是在输入结束前进行一系列无休止的 $\varepsilon$ 输入移动。对于每个 $q \in Q$ 和 $x \in \Gamma$,如果当 $P$ 在状态 $q$ 启动且栈顶为 $x \in \Gamma$ 时,它从不弹出 $x$ 下方的任何内容,也从不读取输入符号,则称 $(q, x)$ 为循环情况 (looping situation)。如果 $P$ 在其随后的移动中进入接受状态,则称该循环情况为接受的,否则为拒绝的。如果 $(q, x)$ 是一个接受的循环情况,设置 $\delta(q, \boldsymbol{\varepsilon}, x)=\left(q_{\text {accept}}, \boldsymbol{\varepsilon}\right)$,而如果 $(q, x)$ 是一个拒绝的循环情况,设置 $\delta(q, \boldsymbol{\varepsilon}, x)=\left(q_{\text {reject}}, \boldsymbol{\varepsilon}\right)$。
为简化起见,我们此后假设 DPDA 读取其输入直到结束。
DCFLs 的性质
我们将探讨 DCFL 类的闭包和非闭包性质,并利用这些性质展示一个不是 DCFL 的 CFL。
定理 2.42
DCFL 类在补运算下是闭合的。
证明思路 交换 DFA 的接受状态和非接受状态会产生一个识别补语言的新 DFA,从而证明正则语言类在补运算下是闭合的。同样的方法也适用于 DPDA,只是有一个问题。DPDA 可能会通过在输入字符串末尾的一系列移动中同时进入接受和非接受状态来接受其输入。在这种情况下,交换接受和非接受状态仍然会接受。
我们通过修改 DPDA 来限制接受发生的时间来解决这个问题。对于输入的每个符号,修改后的 DPDA 只有在即将读取下一个符号时才能进入接受状态。换句话说,只有读取状态——总是读取输入符号的状态——可以是接受状态。然后,通过仅在这些读取状态之间交换接受和非接受,我们反转了 DPDA 的输出。
证明 首先按照引理 2.41 的证明中所述修改 $P$,并令 $\left(Q, \Sigma, \Gamma, \delta, q_{0}, F\right)$ 为所得的机器。该机器总是读取整个输入字符串。此外,一旦进入接受状态,它会保持在接受状态直到读取下一个输入符号。
为了实现证明思路,我们需要识别读取状态。如果 DPDA 在状态 $q$ 读取输入符号 $a \in \Sigma$ 而不弹出栈,即 $\delta(q, a, \varepsilon) \neq \emptyset$,则将 $q$ 指定为读取状态。但是,如果它既读取又弹出,读取的决定可能取决于弹出的符号,因此将该步骤分为两步:先弹出然后读取。因此,如果对于 $a \in \Sigma$ 和 $x \in \Gamma$,$\delta(q, a, x)=(r, y)$,则添加一个新状态 $q_x$ 并修改 $\delta$,使 $\delta(q, \boldsymbol{\varepsilon}, x)=\left(q_{x}, \boldsymbol{\varepsilon}\right)$ 和 $\delta\left(q_{x}, a, \boldsymbol{\varepsilon}\right)=(r, y)$。将 $q_x$ 指定为读取状态。状态 $q_x$ 从不弹出栈,因此它们的动作与栈内容无关。如果 $q \in F$,则将 $q_x$ 指定为接受状态。最后,从任何不是读取状态的状态中移除接受状态的指定。修改后的 DPDA 等价于 $P$,但它在每个输入符号最多进入一次接受状态,即在即将读取下一个符号时。
现在,反转哪些读取状态被归类为接受状态。所得的 DPDA 识别补语言。
这个定理意味着一些 CFLs 不是 DCFLs。任何其补集不是 CFL 的 CFL 都不是 DCFL。因此,$\underline{A}=\left\{\mathrm{a}^{i} \mathrm{~b}^{j} \mathrm{c}^{k} \mid i \neq j \text{ 或 } j \neq k \text{ 其中 } i, j, k \geq 0\right\}$ 是一个 CFL 但不是 DCFL。否则 $\bar{A}$ 将是一个 CFL,那么问题 2.30 的结果将错误地暗示 $\bar{A} \cap \mathrm{a}^{*} \mathrm{~b}^{*} \mathrm{c}^{*}=\left\{\mathrm{a}^{n} \mathrm{~b}^{n} \mathrm{c}^{n} \mid n \geq 0\right\}$ 是上下文无关的。
问题 2.23 要求您证明 DCFL 类不封闭于其他熟悉的运算,例如并集、交集、星运算和逆运算。
为了简化论证,我们偶尔会考虑带结束标记的输入,其中特殊结束标记符号 $\dashv$ 附加到输入字符串的末尾。在这里,我们将 $\dashv$ 添加到 DPDA 的输入字母表中。正如我们在下一个定理中所示,添加结束标记不会改变 DPDA 的能力。然而,设计带结束标记输入的 DPDA 通常更容易,因为我们可以利用知道输入字符串何时结束的优势。对于任何语言 $A$,我们用带结束标记语言 $A \dashv$ 表示字符串 $w \dashv$ 的集合,其中 $w \in A$。
定理 2.43
$A$ 是一个 DCFL 当且仅当 $A \dashv$ 是一个 DCFL。
证明思路 证明这个定理的正向是常规的。假设 DPDA $P$ 识别 $A$。那么 DPDA $P^{\prime}$ 识别 $A \dashv$,通过模拟 $P$ 直到 $P^{\prime}$ 读取 $\dashv$。此时,$P^{\prime}$ 接受,如果 $P$ 在前一个符号期间进入了接受状态。$P^{\prime}$ 在 $\dashv$ 之后不读取任何符号。
为了证明反向,让 DPDA $P$ 识别 $A \dashv$,并构造一个 DPDA $P^{\prime}$ 来识别 $A$。当 $P^{\prime}$ 读取其输入时,它模拟 $P$。在读取每个输入符号之前,$P^{\prime}$ 确定如果该符号是 $\dashv$, $P$ 是否会接受。如果是, $P^{\prime}$ 进入接受状态。请注意,$P$ 在读取 $\dashv$ 后可能会操作栈,因此确定它在读取 $\dashv$ 后是否接受可能取决于栈内容。当然,$P^{\prime}$ 不能在每个输入符号处弹出整个栈,因此它必须确定 $P$ 在读取 $\dashv$ 后会做什么,但不能弹出栈。相反,$P^{\prime}$ 在栈上存储额外的信息,允许 $P^{\prime}$ 立即确定 $P$ 是否会接受。这些信息表明 $P$ 会从哪些状态最终接受,同时(可能)操纵栈,但不再读取更多的输入。
证明 我们只给出反向的证明细节。如我们在证明思路中所述,令 DPDA $P=\left(Q, \Sigma \cup\{\dashv\}, \Gamma, \delta, q_{0}, F\right)$ 识别 $A \dashv$,并构造一个 DPDA $P^{\prime}=\left(Q^{\prime}, \Sigma, \Gamma^{\prime}, \delta^{\prime}, q_{0}{ }^{\prime}, F^{\prime}\right)$ 来识别 $A$。首先,修改 $P$,使其每个移动都只执行以下操作之一:读取一个输入符号;将一个符号压入栈;或将一个符号从栈中弹出。通过引入新状态,进行此修改是直接的。
$P^{\prime}$ 模拟 $P$,同时在栈上维护其栈内容的副本,并交错有附加信息。每当 $P^{\prime}$ 压入 $P$ 的一个栈符号时,$P^{\prime}$ 都会紧接着压入一个表示 $P$ 状态子集的符号。因此,我们设置 $\Gamma^{\prime}=\Gamma \cup \mathcal{P}(Q)$。 $P^{\prime}$ 中的栈交错包含 $\Gamma$ 的成员和 $\mathcal{P}(Q)$ 的成员。如果 $R \in \mathcal{P}(Q)$ 是栈顶符号,那么通过在 $P$ 的任何一个状态中启动 $P$, $P$ 最终将在不读取任何更多输入的情况下接受。
最初,$P^{\prime}$ 将集合 $R_0$ 压入栈中,$R_0$ 包含每个状态 $q$,使得当 $P$ 在空栈的状态 $q$ 启动时,它最终会在不读取任何输入符号的情况下接受。然后 $P^{\prime}$ 开始模拟 $P$。为了模拟弹出移动,$P^{\prime}$ 首先弹出并丢弃作为栈顶符号出现的状态集合,然后再次弹出以获得 $P$ 在此时会弹出的符号,并使用它来确定 $P$ 的下一个移动。模拟压入移动 $\delta(q, \boldsymbol{\varepsilon}, \boldsymbol{\varepsilon})=(r, x)$,其中 $P$ 在从状态 $q$ 到状态 $r$ 的过程中压入 $x$,如下进行。首先 $P^{\prime}$ 检查栈顶的状态集合 $R$,然后它压入 $x$,之后压入集合 $S$,其中 $q \in S$ 如果 $q \in F$ 或者如果 $\delta(q, \varepsilon, x)=(r, \varepsilon)$ 并且 $r \in R$。换句话说,$S$ 是那些要么立即接受,要么在弹出 $x$ 后会导致状态 $R$ 的状态集合。最后,$P^{\prime}$ 模拟读取移动 $\delta(q, a, \varepsilon)=(r, \varepsilon)$,通过检查栈顶的集合 $R$ 并在 $r \in R$ 时进入接受状态。如果 $P^{\prime}$ 在进入此状态时处于输入字符串的末尾,它将接受输入。如果它不在输入字符串的末尾,它将继续模拟 $P$,因此此接受状态还必须记录 $P$ 的状态。因此,我们将此状态创建为 $P$ 原始状态的第二个副本,并将其标记为 $P^{\prime}$ 中的接受状态。
确定性上下文无关文法
本节定义确定性上下文无关文法,它是确定性下推自动机的对应物。我们将证明这两个模型在能力上是等价的,前提是我们只关注带结束标记的语言,其中所有字符串都以 $\dashv$ 终止。因此,这种对应关系不如我们在正则表达式和有限自动机,或在 CFG 和 PDA 中看到的那样强,后者中的生成模型和识别模型在不需要结束标记的情况下描述了完全相同的语言类。然而,在 DPDA 和 DCFG 的情况下,结束标记是必要的,因为如果没有这个限制,等价性就不成立。
在确定性自动机中,计算的每一步都决定了下一步。自动机不能对如何进行做出选择,因为在每一点上只有一个可能性。为了在文法中定义确定性,我们观察到自动机中的计算对应于文法中的推导。在确定性文法中,推导是受约束的,正如您将看到的。
CFG 中的推导从开始变量开始,通过一系列根据文法规则的替换“自上而下”进行,直到推导得到一个终结符串。为了定义 DCFG,我们采取“自下而上”的方法,从一个终结符串开始,然后反向处理推导,采用一系列规约步骤,直到达到开始变量。每个规约步骤都是一个反向替换,其中规则右侧的终结符和变量字符串被相应左侧的变量替换。被替换的字符串称为规约字符串。我们将整个反向推导称为归约 (reduction)。确定性上下文无关文法是根据具有特定属性的归约定义的。
更形式化地,如果 $u$ 和 $v$ 是变量和终结符字符串,写 $u \succ v$ 表示 $v$ 可以通过一个规约步骤从 $u$ 获得。换句话说,$u \succ v$ 的含义与 $v \Rightarrow u$ 相同。从 $u$ 到 $v$ 的归约是一个序列
我们说 $u$ 可以归约为 $v$,写作 $u \stackrel{*}{\rightarrow} v$。因此 $u \stackrel{*}{\rightarrow} v$ 只要 $v \xrightarrow{*} u$。从 $u$ 的归约是从 $u$ 到开始变量的归约。在最左归约中,每个规约字符串仅在其左侧的所有其他规约字符串都已被归约后才被归约。稍加思考,我们可以看到最左归约是反向的最右推导。
这是 CFG 中确定性背后的思想。在一个带有开始变量 $S$ 且字符串 $w$ 属于其语言的 CFG 中,假设 $w$ 的最左归约是
首先,我们规定每个 $u_i$ 决定了下一个规约步骤,从而决定了 $u_{i+1}$。因此 $w$ 决定了其完整的最左归约。这个要求只意味着文法是无歧义的。为了获得确定性,我们需要更进一步。在每个 $u_i$ 中,下一个规约步骤必须由 $u_i$ 的前缀(包括并直到该规约步骤的规约字符串 $h$)唯一确定。换句话说,$u_i$ 中的最左规约步骤不依赖于 $u_i$ 中在其规约字符串右侧的符号。
引入术语将帮助我们精确地阐述这个想法。设 $w$ 是 CFG $G$ 语言中的一个字符串,并设 $u_i$ 出现在 $w$ 的最左归约中。在规约步骤 $u_i \rightarrow u_{i+1}$ 中,假设规则 $T \rightarrow h$ 被反向应用。这意味着我们可以写 $u_i=xhy$ 和 $u_{i+1}=xTy$,其中 $h$ 是规约字符串,$x$ 是 $u_i$ 中出现在 $h$ 左侧的部分,$y$ 是 $u_i$ 中出现在 $h$ 右侧的部分。图示如下:
图 2.44
$xhy \rightarrow xTy$ 的扩展视图
我们称 $h$ 及其规约规则 $T \rightarrow h$ 为 $u_i$ 的句柄 (handle)。换句话说,出现在 $w \in L(G)$ 的最左归约中的字符串 $u_i$ 的句柄是 $u_i$ 中规约字符串的出现,以及此归约中 $u_i$ 的规约规则。偶尔我们只将句柄与其规约字符串关联,当我们不关心规约规则时。出现在 $L(G)$ 中某些字符串的最左归约中的字符串称为有效字符串 (valid string)。我们只为有效字符串定义句柄。
一个有效字符串可能有几个句柄,但这仅当文法有歧义时。无歧义文法只能通过一棵分析树生成字符串,因此最左归约,以及句柄,也是唯一的。在这种情况下,我们可以指代有效字符串的句柄。
请注意,$y$,即句柄后面的 $u_i$ 部分,总是终结符串,因为归约是最左的。否则,$y$ 将包含一个变量符号,而这只能来自一个规约字符串完全在 $h$ 右侧的先前的规约步骤。但那样的话,最左归约应该在更早的步骤归约句柄。
示例 2.45
考虑文法 $G_1$:
其语言是 $B \cup C$,其中 $B=\left\{\mathrm{a}^{m} \mathrm{~b}^{m} \mid m \geq 1\right\}$ 和 $C=\left\{\mathrm{a}^{m} \mathrm{~b}^{2 m} \mid m \geq 1\right\}$。在字符串 aaaabbb $\in L\left(G_{1}\right)$ 的此最左归约中,我们在每一步都下划线标记了句柄:
同样,这是字符串 aaabbbbbb 的最左归约:
在这两种情况下,所示的最左归约恰好是唯一可能的归约;但在其他可能发生几次归约的文法中,我们必须使用最左归约来定义句柄。请注意,aaabbb 和 aaabbbbbb 的句柄不相等,即使这些字符串的初始部分相同。我们将在定义 DCFG 时更详细地讨论这一点。
PDA 可以通过利用其非确定性猜测其输入是在 $B$ 中还是在 $C$ 中来识别 $L\left(G_{1}\right)$。然后,在它将 a 压入栈后,它弹出 a 并根据 b 或 bb 进行匹配。问题 2.25 要求您证明 $L\left(G_{1}\right)$ 不是 DCFL。如果您尝试制作一个识别此语言的 DPDA,您会发现机器无法事先知道输入是在 $B$ 中还是在 $C$ 中,因此它不知道如何将 a 与 b 匹配。将此文法与文法 $G_2$ 进行对比:
其中输入的第一个符号提供了此信息。我们对 DCFG 的定义必须包含 $G_2$ 但排除 $G_1$。
示例 2.46
令 $G_3$ 为以下文法:
这个文法说明了几点。首先,它生成带结束标记的语言。我们稍后将重点关注带结束标记的语言,届时我们将证明 DPDA 和 DCFG 之间的等价性。其次,$\boldsymbol{\varepsilon}$ 句柄可能出现在归约中,如在字符串 ()()- 的最左归约中用短下划线表示:
句柄在定义 DCFG 中扮演重要角色,因为句柄决定归约。一旦我们知道一个字符串的句柄,我们就知道下一个规约步骤。为了理解即将到来的定义,请记住我们的目标:我们旨在定义 DCFG 以使其与 DPDA 对应。我们将通过展示如何将 DCFG 转换为等价的 DPDA,反之亦然来建立这种对应关系。为了使这种转换有效,DPDA 需要找到句柄以便它可以找到归约。但找到句柄可能很棘手。似乎我们需要知道一个字符串的下一个规约步骤来识别其句柄,但 DPDA 不会提前知道归约。我们将通过限制 DCFG 中的句柄来解决这个问题,以便 DPDA 可以更容易地找到它们。
为了激发定义,考虑有歧义的文法,其中某些字符串有几个句柄。选择特定的句柄可能需要事先知道哪棵分析树推导出该字符串,而 DPDA 肯定无法获得此信息。我们将看到 DCFG 是无歧义的,因此句柄是唯一的。然而,仅凭唯一性对于定义 DCFG 来说是不够的,如示例 2.45 中的文法 $G_1$ 所示。
为什么唯一的句柄不意味着我们有一个 DCFG 呢?答案通过检查 $G_1$ 中的句柄可以清楚地看到。如果 $w \in B$,句柄是 ab;而如果 $w \in C$,句柄是 abb。尽管 $w$ 决定了哪种情况适用,但发现 ab 或 abb 哪个是句柄可能需要检查整个 $w$,而 DPDA 在需要选择句柄时还没有读取整个输入。
为了定义与 DPDA 对应的 DCFG,我们对句柄施加更强的要求。有效字符串的初始部分,包括其句柄,必须足以确定句柄。因此,如果我们从左到右读取一个有效字符串,一旦我们读取到句柄,我们就知道我们已经找到了它。我们不需要读取句柄之外的内容来识别句柄。回想一下,有效字符串中未读取的部分只包含终结符,因为有效字符串是通过初始终结符串的最左归约获得的,并且未读取的部分尚未处理。因此,我们说有效字符串 $v=xhy$ 的句柄 $h$ 是强制句柄 (forced handle),如果 $h$ 是每个有效字符串 $x h \hat{y}$ 中唯一的句柄,其中 $\hat{y} \in \Sigma^{*}$。
定义 2.47
确定性上下文无关文法是一种上下文无关文法,其中每个有效字符串都有一个强制句柄。
为了简化起见,在本节关于确定性上下文无关语言的讨论中,我们将始终假设 CFG 的开始变量不出现在任何规则的右侧,并且文法中的每个变量都出现在文法语言中某个字符串的归约中,即文法不包含无用变量。
尽管我们对 DCFG 的定义在数学上是精确的,但它并没有给出任何明显的方法来确定一个 CFG 是否是确定性的。接下来,我们将介绍一个精确地做到这一点的过程,称为 DK 检验。我们还将利用 DK 检验背后的构造,在展示如何将 DCFG 转换为 DPDA 时,使 DPDA 能够找到句柄。
DK 检验依赖于一个简单但令人惊讶的事实。对于任何 CFG $G$,我们可以构造一个相关的 DFA $DK$,它可以识别句柄。具体来说,$DK$ 接受其输入 $z$ 当且仅当
- $z$ 是某个有效字符串 $v=zy$ 的前缀,且
- $z$ 以 $v$ 的句柄结束。
此外,$DK$ 的每个接受状态都指示相关的规约规则。在一般的 CFG 中,可能适用多个规约规则,这取决于 $z$ 扩展到的有效 $v$。但在 DCFG 中,正如我们将看到的,每个接受状态都对应于恰好一个规约规则。
我们将在正式介绍 $DK$ 并建立其性质之后描述 DK 检验,但计划如下。在 DCFG 中,所有句柄都是强制的。因此,如果 $zy$ 是一个有效字符串,其前缀 $z$ 以 $zy$ 的句柄结束,那么该句柄是唯一的,并且它也是所有有效字符串 $z \hat{y}$ 的句柄。为了使这些性质成立,$DK$ 的每个接受状态都必须与单个句柄相关联,从而与单个适用的规约规则相关联。此外,接受状态不能有导致通过读取 $\Sigma^{*}$ 中的字符串而到达接受状态的出边。否则,$zy$ 的句柄将不唯一,或者它将依赖于 $y$。在 DK 检验中,我们构造 $DK$,然后得出结论,如果其所有接受状态都具有这些性质,则 $G$ 是确定性的。
为了构造 DFA $DK$,我们将构造一个等价的 NFA $K$,并通过定理 1.39 中介绍的子集构造将 $K$ 转换为 $DK^{1}$。为了理解 $K$,首先考虑一个执行更简单任务的 NFA $J$。它接受以任何规则的右侧结尾的每个输入字符串。构造 $J$ 很容易。它猜测使用哪个规则,并且还猜测何时开始将输入与该规则的右侧匹配。在匹配输入时,$J$ 跟踪
所选右侧的进度。我们通过在规则中的相应位置放置一个点来表示此进度,从而产生一个带点规则 (dotted rule),在其他材料中也称为项 (item)。因此,对于每个右侧有 $k$ 个符号的规则 $B \rightarrow u_{1} u_{2} \cdots u_{k}$,我们得到 $k+1$ 个带点规则:
每个带点规则对应于 $J$ 的一个状态。我们用方框 $B \rightarrow u . v$ 表示与带点规则 $B \rightarrow u . v$ 关联的状态。接受状态 $B \rightarrow u$. 对应于末尾有点的已完成规则。我们添加一个单独的开始状态,该状态对所有符号具有自环,并对每个规则 $B \rightarrow u$ 具有到 $B \rightarrow . u$ 的 $\varepsilon$ 移动。因此,如果匹配在输入结束时成功完成,$J$ 则接受。如果发生不匹配,或者匹配的结束与输入的结束不一致,则 $J$ 的此计算分支拒绝。
NFA $K$ 类似地操作,但它更谨慎地选择匹配规则。只允许潜在的规约规则。像 $J$ 一样,它的状态对应于所有带点规则。它有一个特殊的开始状态,该状态对每个涉及开始变量 $S_1$ 的规则都有一个到 $S_1 \rightarrow .u$ 的 $\varepsilon$ 移动。在其计算的每个分支上,$K$ 将潜在的规约规则与输入的子字符串匹配。如果该规则的右侧包含一个变量,$K$ 可以非确定性地切换到扩展该变量的某个规则。引理 2.48 将这个想法形式化。我们首先详细描述 $K$。
转移有两种:移进移动 (shift-moves) 和 $\epsilon$ 移动 ($\epsilon$-moves)。移进移动出现在每个是终结符或变量的 $a$,以及每个规则 $B \rightarrow uav$:
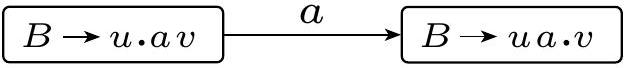
$\epsilon$ 移动出现在所有规则 $B \rightarrow uCv$ 和 $C \rightarrow r$:
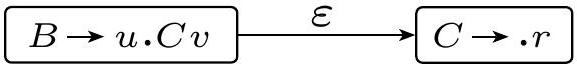
接受状态是所有 $B \rightarrow u.$,对应于已完成的规则。接受状态没有出边,并用双框表示。
下一个引理及其推论证明了 $K$ 接受所有以某个 $z$ 的有效扩展的句柄结尾的字符串 $z$。因为 $K$ 是非确定性的,我们说它“可能”进入一个状态意味着 $K$ 在其非确定性的某个分支上确实进入该状态。
引理 2.48
当读取输入 $z$ 时,$K$ 可能进入状态 $T \rightarrow u . v$ 当且仅当 $z=xu$ 且 $xuvy$ 是有效字符串,其句柄为 $uv$,规约规则为 $T \rightarrow uv$,对于某个 $y \in \Sigma^{*}$。
证明思路 $K$ 通过将所选规则的右侧与输入的一部分匹配来操作。如果该匹配成功完成,它就接受。如果该右侧包含一个变量 $C$,则可能出现两种情况。如果 $C$ 是下一个输入符号,那么匹配所选规则就继续进行。如果 $C$ 已被展开,输入将包含从 $C$ 派生出的符号,因此 $K$ 非确定性地选择 $C$ 的替换规则并从该规则右侧的开头开始匹配。当当前所选规则的右侧已完全匹配时,它就接受。
证明 首先证明正向。假设 $K$ 在 $w$ 上进入 $T \rightarrow u . v$ 状态。检查 $K$ 从其开始状态到 $T \rightarrow u . v$ 的路径。将该路径视为由 $\boldsymbol{\varepsilon}$ 移动分隔的移进移动的运行。移进移动是共享同一规则的状态之间的转移,将点向右移动,越过从输入中读取的符号。在第 $i$ 次运行中,假设规则是 $S_i \rightarrow u_i S_{i+1} v_i$,其中 $S_{i+1}$ 是在下一次运行中展开的变量。倒数第二次运行是规则 $S_l \rightarrow u_l T v_l$,最后一次运行是规则 $T \rightarrow uv$。
输入 $z$ 必须等于 $u_1 u_2 \ldots u_l u = xu$,因为字符串 $u_i$ 和 $u$ 是从输入中读取的移进移动符号。令 $y^{\prime}=v_l \ldots v_2 v_1$,我们看到 $xuvy^{\prime}$ 在 $G$ 中是可推导的,因为上面的规则给出了如图 2.49 所示的推导分析树。
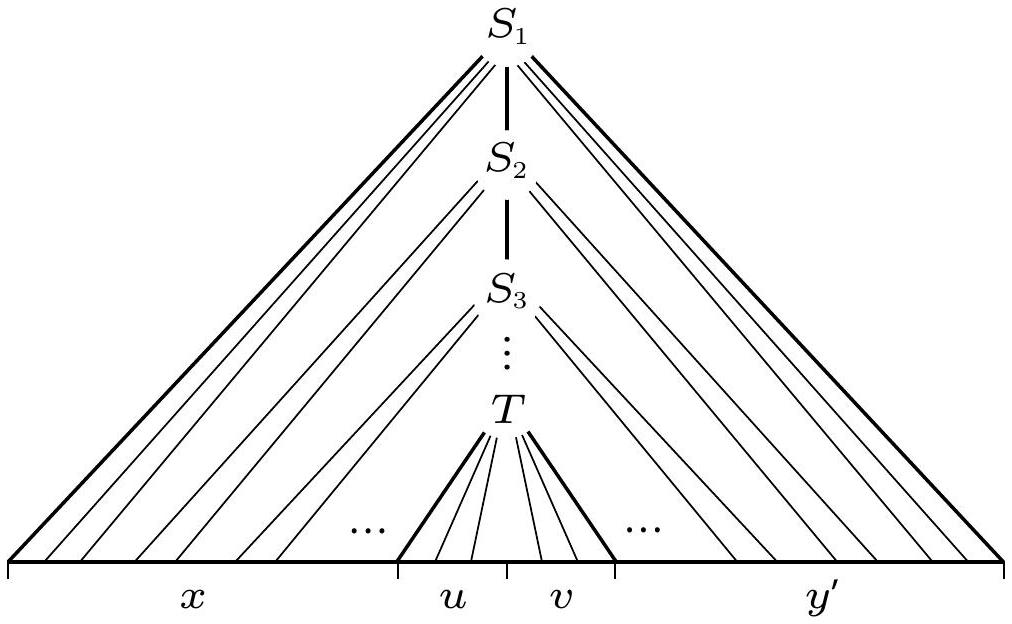
图 2.49
导致 $xuvy^{\prime}$ 的分析树
为了获得一个有效字符串,完全展开 $y^{\prime}$ 中出现的所有变量,直到每个变量都派生出一些终结符串,并将结果字符串称为 $y$。字符串 $xuvy$ 是有效的,因为它出现在 $w \in L(G)$ 的最左归约中, $w \in L(G)$ 是通过完全展开 $xuvy$ 中的所有变量而获得的终结符串。
如下图所示,$uv$ 是归约中的句柄,其规约规则是 $T \rightarrow uv$。
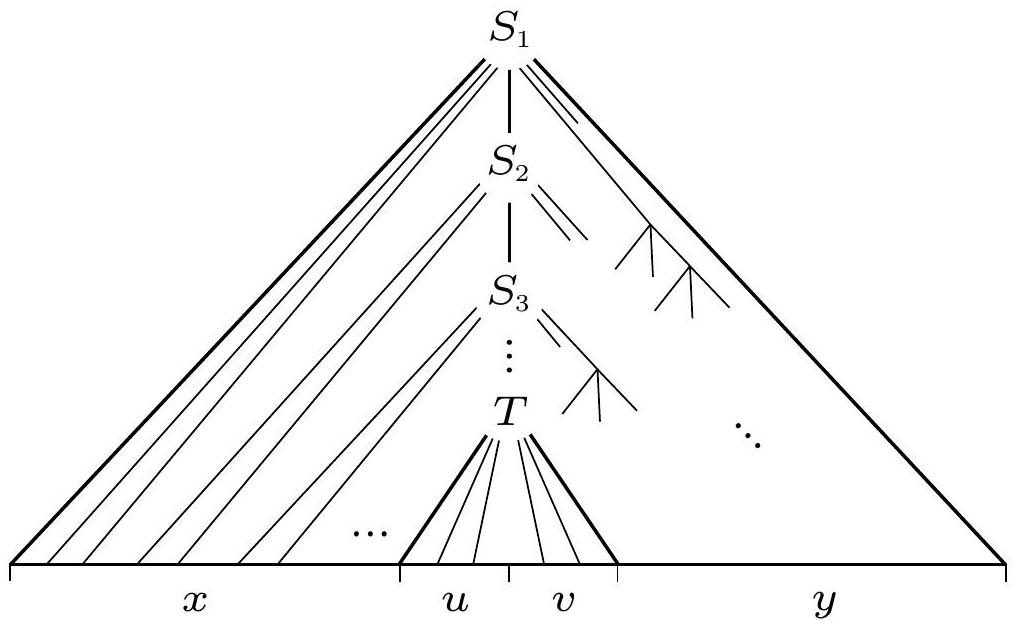
图 2.50
导致句柄为 $uv$ 的有效字符串 $xuvy$ 的分析树
现在我们证明引理的反向。假设字符串 $xuvy$ 是一个有效字符串,其句柄为 $uv$,规约规则为 $T \rightarrow uv$。证明 $K$ 在输入 $xu$ 上可能进入状态 $T \rightarrow u . v$。
$xuvy$ 的分析树显示在前面的图中。它以开始变量 $S_1$ 为根,并且必须包含变量 $T$,因为 $T \rightarrow uv$ 是 $xuvy$ 归约中的第一个规约步骤。令 $S_2, \ldots, S_l$ 为从 $S_1$ 到 $T$ 路径上的变量,如图所示。请注意,分析树中出现在此路径左侧的所有变量都必须未展开,否则 $uv$ 就不会是句柄。
在此分析树中,每个 $S_i$ 通过某个规则 $S_i \rightarrow u_i S_{i+1} v_i$ 引导至 $S_{i+1}$。因此,文法必须包含以下规则,用于某些字符串 $u_i$ 和 $v_i$。
$K$ 包含从其开始状态到状态 $T \rightarrow u . v$ 的以下路径,在读取输入 $z=xu$ 时。首先,$K$ 进行一个 $\epsilon$ 移动到 $S_1 \rightarrow . u_1 S_2 v_1$。然后,在读取 $u_1$ 的符号时,它执行相应的移进移动,直到在 $u_1$ 结束时进入 $S_1 \rightarrow u_1 . S_2 v_1$。然后它进行一个 $\varepsilon$ 移动到 $S_2 \rightarrow . u_2 S_3 v_2$ 并在读取 $u_2$ 时继续移进移动,直到它到达 $S_2 \rightarrow u_2 . S_3 v_2$,依此类推。读取 $u_l$ 后,它进入 $S_l \rightarrow u_l . T v_l$,这将通过一个 $\epsilon$ 移动导致 $T \rightarrow . uv$,最后在读取 $u$ 后,它处于 $T \rightarrow u . v$ 状态。
以下推论表明 $K$ 接受所有以某些有效扩展的句柄结尾的字符串 $z$。它通过令 $u=h$ 和 $v=\boldsymbol{\varepsilon}$ 从引理 2.48 得出。
推论 2.51
$K$ 可能在输入 $z$ 上进入接受状态 $T \rightarrow h.$ 当且仅当 $z=xh$ 且 $h$ 是某个有效字符串 $xhy$ 的句柄,规约规则为 $T \rightarrow h$。
最后,我们通过在第 55 页的定理 1.39 的证明中使用子集构造将 NFA $K$ 转换为 DFA $DK$,然后删除所有从开始状态无法到达的状态。因此,$DK$ 的每个状态都包含一个或多个带点规则。每个接受状态都包含至少一个已完成的规则。我们可以通过引用包含所示带点规则的状态来将引理 2.48 和推论 2.51 应用于 $DK$。
现在我们准备描述 DK 检验。
从 CFG $G$ 开始,构造相关的 DFA $DK$。通过检查 $DK$ 的接受状态来确定 $G$ 是否是确定性的。DK 检验规定每个接受状态包含
- 恰好一个已完成的规则,并且
- 没有点后立即跟着终结符号的带点规则,即没有形式为 $B \rightarrow u . av$ 的带点规则,其中 $a \in \Sigma$。
定理 2.52
$G$ 通过 DK 检验当且仅当 $G$ 是 DCFG。
证明思路 我们将证明 DK 检验通过当且仅当所有句柄都是强制的。等价地,检验失败当且仅当某个句柄不是强制的。首先,假设某个有效字符串具有非强制句柄。如果我们对该字符串运行 $DK$,推论 2.51 说 $DK$ 在句柄结束时进入接受状态。DK 检验失败,因为该接受状态要么具有第二个已完成规则,要么具有导致接受状态的出边,其中出边以终结符号开头。在后一种情况下,接受状态将包含一个点后跟着终结符号的带点规则。
相反,如果 DK 检验失败,因为一个接受状态有两个已完成规则,则将相关字符串扩展为两个在该点具有不同句柄的有效字符串。类似地,如果它有一个已完成规则和一个点后跟着终结符号的带点规则,则使用引理 2.48 获得两个在该点具有不同句柄的有效扩展。构造与第二个规则对应的有效扩展有点微妙。
证明 从正向开始。假设 $G$ 不是确定性的,并证明它未能通过 DK 检验。取一个有效字符串 $xhy$,它有一个非强制句柄 $h$。因此,某个有效字符串 $xhy'$ 具有不同的句柄 $\hat{h} \neq h$,其中 $y'$ 是一个终结符串。我们因此可以将 $xhy'$ 写成 $xhy'=\hat{x}\hat{h}\hat{y}$。
如果 $xh = \hat{x}\hat{h}$,则规约规则不同,因为 $h$ 和 $\hat{h}$ 不是同一个句柄。因此,输入 $xh$ 将 $DK$ 发送到一个包含两个已完成规则的状态,这违反了 DK 检验。
如果 $xh \neq \hat{x}\hat{h}$,则其中一个扩展了另一个。假设 $xh$ 是 $\hat{x}\hat{h}$ 的真前缀。如果 $\hat{x}\hat{h}$ 是较短的字符串,则将字符串互换并将 $y$ 代替 $y'$,论证相同。设 $q$ 是 $DK$ 在输入 $xh$ 上进入的状态。状态 $q$ 必须是接受状态,因为 $h$ 是 $xhy$ 的句柄。必须有一条从 $q$ 出发的转移箭头,因为 $\hat{x}\hat{h}$ 通过 $q$ 将 $DK$ 发送到接受状态。此外,该转移箭头标记为终结符号,因为 $y' \in \Sigma^{+}$。在这里 $y' \neq \varepsilon$,因为 $\hat{x}\hat{h}$ 扩展了 $xh$。因此 $q$ 包含一个点后立即跟着终结符号的带点规则,这违反了 DK 检验。
为了证明反向,假设 $G$ 在某个接受状态 $q$ 处未能通过 DK 检验,并通过展示一个非强制句柄来证明 $G$ 不是确定性的。因为 $q$ 是接受状态,它有一个已完成规则 $T \rightarrow h.$。设 $z$ 是导致 $DK$ 到 $q$ 的字符串。那么 $z=xh$,其中某个有效字符串 $xhy$ 的句柄为 $h$,规约规则为 $T \rightarrow h$,对于 $y \in \Sigma^{*}$。现在我们考虑两种情况,具体取决于 DK 检验如何失败。
首先,假设 $q$ 有另一个已完成规则 $B \rightarrow \hat{h}.$。那么某个有效字符串 $xhy'$ 必须有一个不同的句柄 $\hat{h}$,规约规则为 $B \rightarrow \hat{h}.$。因此,$h$ 不是强制句柄。
其次,假设 $q$ 包含一个规则 $B \rightarrow u . av$,其中 $a \in \Sigma$。因为 $xh$ 将 $DK$ 带到 $q$,我们有 $xh=\hat{x}u$,其中 $\hat{x}uav\hat{y}$ 是有效的,并且有一个句柄 $uav$,规约规则为 $B \rightarrow uav$,对于某个 $\hat{y} \in \Sigma^{*}$。为了证明 $h$ 是非强制的,完全展开 $v$ 中的所有变量以得到结果 $v' \in \Sigma^{*}$,然后令 $y'=av'\hat{y}$ 并注意到 $y' \in \Sigma^{*}$。以下最左归约表明 $xhy'$ 是一个有效字符串,$h$ 不是句柄。
其中 $S$ 是开始变量。我们知道 $\hat{x}uav\hat{y}$ 是有效的,我们可以通过使用最右推导从它获得 $\hat{x}uav'\hat{y}$,所以 $\hat{x}uav'\hat{y}$ 也是有效的。此外,$\hat{x}uav'\hat{y}$ 的句柄要么在 $v'$ 内部(如果 $v \neq v'$),要么是 $uav$(如果 $v=v'$)。在这两种情况下,句柄包含 $a$ 或跟随 $a$,因此不能是 $h$,因为 $h$ 完全在 $a$ 之前。因此,$h$ 不是强制句柄。
在实际构建 DFA $DK$ 时,直接构造可能比首先构造 NFA $K$ 更快。首先在所有涉及开始变量的规则的起始位置添加一个点,并将这些现在带点规则放入 $DK$ 的开始状态。如果一个点在这些规则中的任何一个中在变量 $C$ 之前,则在所有左侧有 $C$ 的规则的起始位置添加点,并将这些规则添加到状态中,持续此过程直到没有新的带点规则。对于任何点后跟着的符号 $c$,添加一个标记为 $c$ 的出边到一个新状态,该状态包含通过在点前是 $c$ 的任何带点规则中将点移过 $c$ 而获得的带点规则,并添加对应于点前是变量的规则。
示例 2.53
这里我们说明 DK 检验如何对以下文法失败。
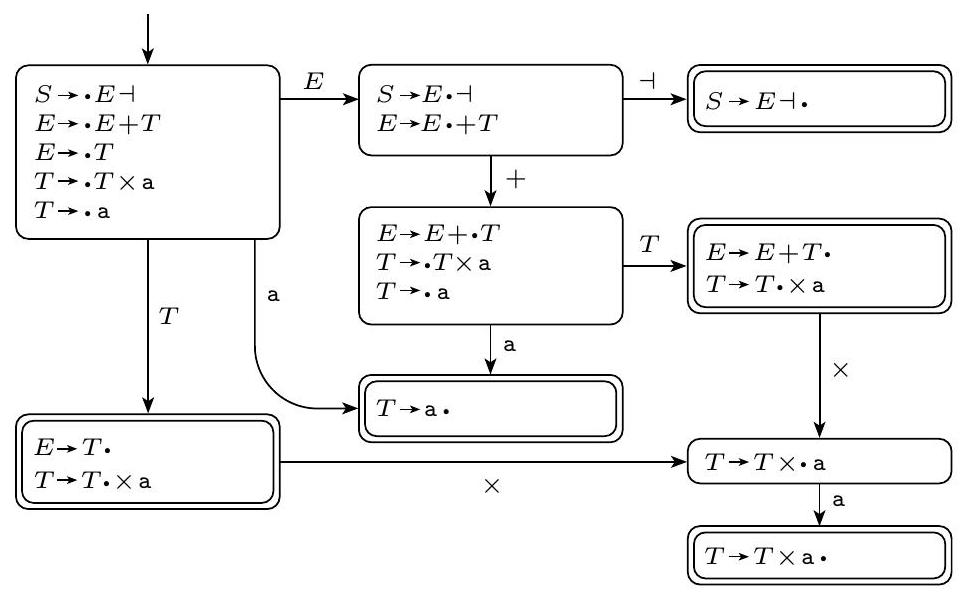
图 2.54
DK 检验失败示例
请注意左下方和右上方第二个有两个问题的状态,其中一个接受状态包含一个带点规则,其点后立即跟着终结符号。
示例 2.55
这是 DFA $DK$,显示以下文法是一个 DCFG。
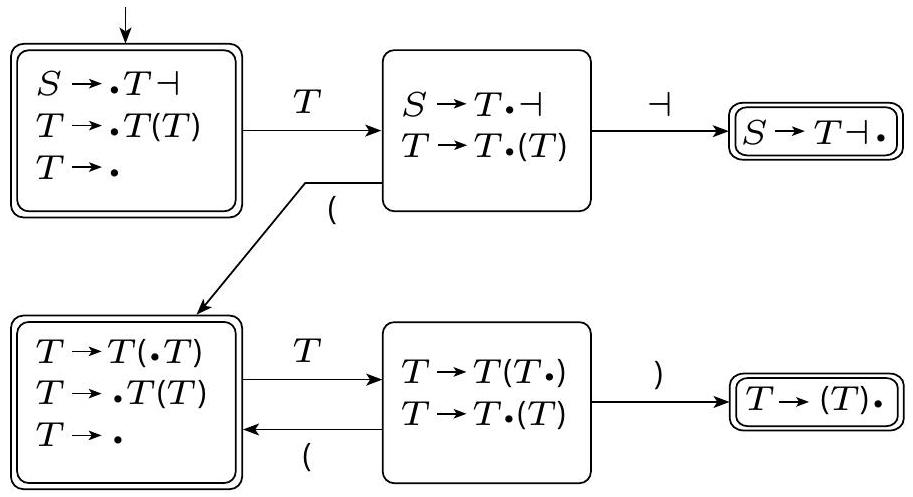
图 2.56
通过 DK 检验的示例
请注意,所有接受状态都满足 DK 检验条件。$\square$