10.4 构造量子编码
我们已经有了一个研究量子编码的理论框架,但是还没有多少具体的量子编码。为了弥补这个缺憾,我们首先在 10.4.1 节简单介绍一下经典线性码,然后在 10.4.2 节介绍如何根据经典线性码构造叫作 Calderbank-Shor-Steane(CSS)编码的一大类量子编码。作为最后一步,我们在 10.5 节发展出稳定子编码,这是一类比 CSS 更广泛的量子编码,提供了一个能构造各种量子编码的强大方法。
10.4.1 经典线性编码
经典纠错码有各种各样的重要工程应用,因此很自然地人们已经针对它们发展出非常强大的理论。我们对经典纠错码感兴趣的根源是这些理论和技术对量子纠错码也有意义,特别是经典线性码理论,它能被用来构造一大类性能良好的量子纠错码。在本节中我们将回顾一下经典线性码,并着重强调那些对量子纠错码有价值的想法。
一个将 $k$ 比特信息编码到 $n$ 比特编码空间上的线性码 $C$ 由一个 $n \times k$ 的产生矩阵 $G$ 确定,这些矩阵的元素是 $Z_{2}$ 的元素,也就是 1 和 0 。矩阵 $G$ 将信息映射到对应的编码上来,因此,$k$ 比特的信息 $x$ 被编码后就成为 $G x$ ,这里,信息 $x$ 可以被看成一个列向量。值得注意的是,本节中矩阵乘法运算,以及其他代数运算,都是取模为 2 的结果。作为一个简单例子,将一个比特映到三个比特的重复性编码,可以由产生矩阵
$$
G=\left[\begin{array}{l}
1 \tag{10.53}\\
1 \\
1
\end{array}\right]
$$
确定,这里 $G$ 将可能的信息, 0 或者 1 ,映射到它们对应的编码形式,$G[0]=(0,0,0)$ 及 $G[1]=$ $(1,1,1)$ 。(注意 $(a, b, \cdots, z)$ 是列向量的标准记号)。如果一个编码用 $n$ 个比特来编码 $k$ 个比特的信息,我们称之为一个 $[n, k]$ 编码;上面的例子即为一个 $[3,1]$ 编码。一个稍微复杂一些的例子是
量子计算与量子信息: 10 周年版
将一个两比特信息中的每一个比特用重复性编码来处理,这样将得到一个 $[6,2]$ 编码。这里对应的产生矩阵是
$$
G=\left[\begin{array}{ll}
1 & 0 \tag{10.54}\\
1 & 0 \\
1 & 0 \\
0 & 1 \\
0 & 1 \\
0 & 1
\end{array}\right]
$$
同时,如同预期的一样,我们可以看到,
$$
\begin{array}{ll}
G(0,0)=(0,0,0,0,0,0) ; & G(0,1)=(0,0,0,1,1,1) \\
G(1,0)=(1,1,1,0,0,0) ; & G(1,1)=(1,1,1,1,1,1) \tag{10.56}
\end{array}
$$
不难看出,所有可能的码字都是 $G$ 的列所张成的空间中的向量。因此,为了让所有的信息编码方式唯一,我们需要 $G$ 的列向量线性无关,除此之外对 $G$ 没有任何约束。
习题10.14 对于将 $k$ 比特数据中的每个比特以复制 $r$ 次的方式编码的重复性编码,写出其产生矩阵。这是一个 $[r k, k]$ 线性编码,应该有大小为 $r k \times k$ 的产生矩阵。
习题 10.15 证明将 $G$ 的一列加到另一列上所得到的产生矩阵,会产生完全一样的编码。
相对于一般纠错码,线性码的一个巨大优势是其紧凑的描述。将 $k$ 个比特编码到 $n$ 个比特上的一般性编码,需要有 $2^{k}$ 个码字,每个的描述长度为 $n$ ,因此总共需要 $n 2^{k}$ 个比特来描述整个纠错码。但是,同样规格的线性码只需要 $k n$ 个比特来描述,因而节省了指数数量的存储空间。紧凑的描述也体现在高效的编码和解码的能力上,这是一个经典线性码和它的量子近亲——稳定子编码所拥有的重要共同特征。我们已经看到了如何对线性码进行有效编码,只要将 $k$ 比特的信息乘以大小为 $n \times k$ 的产生矩阵 $G$ ,就会得到 $n$ 比特的编码后信息,整个过程的代价是 $O(n k)$ 。
关于线性码的产生矩阵定义方式,一个吸引人的特征是我们希望编码的信息和如何编码之间显而易见的联系。然而,如何实施纠错其实不是十分容易能看出来。理解线性码的纠错,一个最容易的方式是为线性码引入一个叫作奇偶校验的等价替代形式。在这种定义方式中,一个 $[n, k]$编码被定义为 $\mathbf{Z}_{2}$ 上的所有 $n$ 元向量 $x$ ,并且同时满足
$$
\begin{equation*}
H x=0 \tag{10.57}
\end{equation*}
$$
这里,$H$ 是一个 $(n-k) \times k$ 矩阵,被称为奇偶校验矩阵,它所有的元素都是 0 或者 1 。一个相等但更简洁的方式,是将编码空间定义为 $H$ 的核空间。编码 $k$ 个比特需要 $2^{k}$ 个码字,因此 $H$ 的核空间必须至少是 $k$ 维,因此我们要求 $H$ 的行向量线性无关。
习题10.16 证明将奇偶校验矩阵的一行加到另一行不改变编码本身。因此,使用高斯消去法和比特交换可以假设奇偶校验矩阵具有标准形式 $\left[A \mid I_{n-k}\right]$ ,这里 $A$ 是一个 $(n-k) \times k$ 矩阵。
为了联系线性码的奇偶校验图景和它的产生矩阵图景,我们需要开发一个允许我们在奇偶校
验矩阵 $H$ 和产生矩阵 $G$ 之间来回转换的程序。为了从奇偶校验矩阵到产生矩阵,选取张成 $H$ 核空间的 $k$ 个线性无关列向量 $y_{1}, \cdots, y_{k}$ ,然后将 $G$ 的列向量设成 $y_{1}, \cdots, y_{k}$ 。为了从产生矩阵到奇偶校验矩阵,选取与 $G$ 的列向量都正交的 $n-k$ 个线性无关向量 $y_{1}, \cdots, y_{n-k}$ ,然后将 $H$ 的行设置为 $y_{1}^{T}, \cdots, y_{n-k^{\circ}}^{T}$(这里,正交是指内积对 2 取模结果为 0 )。例如,考虑指标为 $[3,1]$ ,由式(10.53)中的产生矩阵定义的重复性编码。为了构造 $H$ ,我们取正交于 $G$ 的列的两个线性无关向量,例如 $(1,1,0)$ 和 $(0,1,1)$ ,定义奇偶校验矩阵为
$$
H \equiv\left[\begin{array}{lll}
1 & 1 & 0 \tag{10.58}\\
0 & 1 & 1
\end{array}\right]
$$
不难验证,只有码字 $x=(0,0,0)$ 和 $x=(1,1,1)$ 才满足 $H x=0$ 。
习题 10.17 对式( 10.54 )中产生矩阵定义的[6,2]重复性编码,给出一个奇偶校验矩阵。
习题10.18 证明对同一个线性码来说,奇偶校验矩阵 $H$ 和产生矩阵 $G$ 满足 $H G=0$ 。
习题 10.19 假设 $[n, k]$ 线性码有形如 $H=\left[A \mid I_{n-k}\right]$ 的奇偶校验矩阵,这里 $A$ 是 $(n-k) \times k$ 矩阵。证明对应的产生矩阵是
$$
\begin{equation*}
G=\left[\frac{I_{k}}{-A}\right] \tag{10.59}
\end{equation*}
$$
(注意 $-A=A$ ,因为我们的运算都是对 2 取模。但是,对比 $\mathbf{Z}_{2}$ 更一般的域上的线性编码来说,这个等式也成立。)
奇偶校验矩阵使得错误探测和信息恢复的过程非常清晰。假设我们将信息 $x$ 编码成 $y=G x$ ,但是因为噪声,码字 $y$ 产生了错误 $e$ ,使得被影响后的码字成为 $y^{\prime}=y+e_{\circ}$(注意,这里的加法是对 2 取模。)因为对所有码字有 $H y=0$ ,我们得到 $H y^{\prime}=H e$ ,我们将 $H y^{\prime}$ 称为错误征状,它扮演了类似量子纠错中错误征状的角色。 $H y^{\prime}$ 是被噪声干扰后的状态 $y^{\prime}$ 的函数,与量子计算中的征状由测量被噪声干扰后的量子态所确定类似。并且,由于 $H y^{\prime}=H e$ ,错误征状包含错误发生状况的信息,因此有希望据此恢复出原本的信息 $y$ 。为了证实这一点,我们假设没有错误或只有一个错误发生。如果没有错误,则对应的错误征状是 $H y^{\prime}=0$ ;如果在第 $j$ 个比特发生了一个错误,则错误征状是 $H e_{j}$ ,这里 $e_{j}$ 是第 $j$ 个元素为 1 的单位向量。因此,如果假设错误发生在至多一个比特上,则可以通过计算错误征状 $H y^{\prime}$ ,再与不同可能的 $H e_{j}$ 对比,来确定需要修正的比特的位置并最终恢复原有信息。
上述线性码中实现纠错的思路,可以用距离的概念更一般性地推广开来。假设 $x$ 和 $y$ 都是 $n$比特长的码字,$x$ 和 $y$ 之间的(汉明)距离 $d(x, y)$ 定义为 $x$ 和 $y$ 取值不同的位置的总数。比如, $d((1,1,0,0),(0,1,0,1))=2$ 。一个码字 $x$ 的(汉明)权重,则定义为它和全零字符串之间的距离, $\mathrm{wt}(x) \equiv d(x, 0)$ ,也就是这个码字中非零位置的总数。因此,我们有 $d(x, y)=\mathrm{wt}(x+y)$ 。为了理解与纠错的联系,假设我们用线性码将 $x$ 编码成 $y=G x$ 。因为噪声的干扰,编码后的码字变成 $y^{\prime}=y+e$ 。假设比特翻转错误发生的概率小于 $1 / 2$ ,则在已知 $y^{\prime}$ 的情况下,最有可能的正确码字 $y$ 是从 $y$ 到 $y^{\prime}$ 所需要的翻转次数最少的那一个,即最小化 $w t(e)=d\left(y, y^{\prime}\right)$ 的那个 $y$ 。原则上,基于线性码的纠错,可以用将 $y^{\prime}$ 用这样的 $y$ 替代的过程来实现,但实际上这种过程效率很低,因为每次计算最小距离 $d\left(y, y^{\prime}\right)$ 需要搜索 $2^{k}$ 个不同可能的码字。所以,在经典纠错码中,很
大一部分精力花在如何为纠错码构造特殊的结构,使得纠错能以更高效的方式实现。注意,这些构造方法并不是本书讨论的话题。
纠错码的全局特点也可以使用汉明距离来理解。我们将一个编码的距离定义为任意两个码字之间的最小距离,即
$$
\begin{equation*}
d(C) \equiv \min _{x, y \in C, x \neq y} d(x, y) \tag{10.60}
\end{equation*}
$$
注意,我们有 $d(x, y)=\operatorname{wt}(x+y)$ 。因为编码是线性的,如果 $x$ 和 $y$ 是码字,则 $x+y$ 也是,于是
$$
\begin{equation*}
d(C)=\min _{x \in C, x \neq 0} \operatorname{wt}(x) \tag{10.61}
\end{equation*}
$$
记 $d \equiv d(C)$ ,我们说 $C$ 是一个 $[n, k, d]$ 编码。距离这个概念的重要性在于,一个距离为 $2 t+1$ 的编码,最多可以纠正 $t$ 个比特上的错误。如果错误少于 $t$ 个,则我们可以将噪声干扰后的编码信息 $y^{\prime}$ 解码为满足 $d\left(y, y^{\prime}\right) \leqslant t$ 的唯一码字 $y$ 。
习题 $10.20 H$ 是一个奇偶校验矩阵,而且任意的 $d-1$ 列都线性无关,但存在 $d$ 列线性相关。证明 $H$ 定义的编码距离为 $d$ 。
习题 10.21 (辛格顿界限)证明一个 $[n, k, d]$ 编码一定满足 $n-k \geqslant d-1$ 。
一个线性纠错码的好典范是汉明码。假设 $r \geqslant 2$ 是一个整数,$H$ 是一个矩阵,并且 $H$ 的列是所有 $2^{r}-1$ 个可能的非零比特串。则奇偶校验矩阵 $H$ 定义了一个指标为 $\left[2^{r}-1,2^{r}-r-1\right]$ 的线性码,我们称之为汉明码。对于量子纠错码来说,一个重要的例子是 $r=3$ 的情况,即这是一个 $[7,4]$ 编码,它的奇偶校验矩阵是
$$
H=\left[\begin{array}{lllllll}
0 & 0 & 0 & 1 & 1 & 1 & 1 \tag{10.62}\\
0 & 1 & 1 & 0 & 0 & 1 & 1 \\
1 & 0 & 1 & 0 & 1 & 0 & 1
\end{array}\right]
$$
$H$ 的任意两列都是不同的,因而也线性无关;前三列是线性相关的,因此根据习题 10.20 这个编码的距离是 3 。因此,这个编码能够纠正任何一个单独比特上的一个噪声。实际上,对应的纠错方案非常简单。假设错误发生在第 $j$ 个比特上,则观察式(10.62)可知 $H e_{j}$ 就是 $j$ 的一个二进制表示,因而指出了需要翻转的比特的位置。
习题10.22 证明所有的汉明码距离为 3 ,因此能纠正单个比特上的错误。因此,汉明码是 $\left[2^{r}-1\right.$ , $\left.2^{r}-r-1,3\right]$ 编码。
关于线性编码,是否还有更一般性的规律?特别是,我们希望有这么一种条件,能告诉我们符合某个参数要求的编码是否存在。实际上,一个并不意外的事实是,许多技术都能给出这种条件。其中,一个类似的叫作 Gilbert-Varshamov 界限的结果指出,对于大的整数 $n$ ,存在一个能纠正 $t$ 个错误的 $[n, k]$ 纠错码的条件是
$$
\begin{equation*}
\frac{k}{n} \geqslant 1-H\left(\frac{2 t}{n}\right) \tag{10.63}
\end{equation*}
$$
这里,$H(x) \equiv-x \log (x)-(1-x) \log (1-x)$ 是第 11 章会详细介绍的二元香农摘。Gilbert-Varshamov界限的重要性在于保证了,只要不用过少的比特数 $(n)$ 去编码过多比特 $(k)$ 的信息,具有不错性能的纠错码是一定存在的。Gilbert-Varshamov 界的证明并不困难,留作习题。
习题 10.23 证明 Gilbert-Varshamov 界限。
作为对回顾经典纠错码的一个总结,我们介绍对偶构造的想法,这是一个重要的纠错码构造方法。假设 $C$ 是一个 $[n, k]$ 编码,产生矩阵是 $G$ ,奇偶校验矩阵是 $H_{\circ}$ 。那么,我们可以用产生矩阵 $G^{T}$ 和奇偶校验矩阵 $H^{T}$ 构造另一个编码 $C^{\perp}$ ,称为 $C$ 的对偶。等价地,$C$ 的对偶由那些与 $C$的所有码字都正交的码字 $y$ 构成。一个编码如果满足 $C \subseteq C^{\perp}$ ,则称它是弱自对偶的;如果满足 $C=C^{\perp}$ ,则称它是严格对偶的。一个非常值得注意的事实是,经典线性码的对偶构造方法,在量子纠错码中也会自然出现,而且是一类称为 CSS 编码的重要纠错码的关键所在。
习题 10.24 证明一个产生矩阵为 $G$ 的编码是弱自对偶的,当且仅当 $G^{T} G=0$ 。
习题 $10.25 C$ 为一个线性码,证明如果 $x \in C^{\perp}$ ,则 $\sum_{y \in C}(-1)^{x \cdot y}=|C|$ ,而如果 $x \notin C^{\perp}$ ,则有 $\sum_{y \in C}(-1)^{x \cdot y}=0$ 。
10.4.2 Calderbank-Shor-Steane 编码
作为范例,我们要介绍的第一大类量子纠错码是 Calderbank-Shor-Steane,基于发明人的首字母缩写一般称为 CSS 编码。CSS 编码是更广泛的稳定子编码的一类重要子集。
假设 $C_{1}$ 和 $C_{2}$ 分别是 $\left[n, k_{1}\right]$ 和 $\left[n, k_{2}\right]$ 的经典线性码,并且 $C_{2} \subset C_{1}, C_{1}$ 和 $C_{2}^{\perp}$ 都纠正 $t$ 个错误。我们现在来定义一个指标为 $\left[n, k_{1}-k_{2}\right]$ 的量子编码 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ ,称为 $C_{1}$ 在 $C_{2}$ 上的 $\operatorname{CSS}$编码,它能纠正 $t$ 个量子比特上的错误。假设 $x \in C_{1}$ 是 $C_{1}$ 编码中的任意码字,那么定义量子态 $\left|x+C_{2}\right\rangle$ 如下:
$$
\begin{equation*}
\left|x+C_{2}\right\rangle \equiv \frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}|x+y\rangle \tag{10.64}
\end{equation*}
$$
这里+是模 2 的逐位加法。假设 $x^{\prime}$ 是 $C_{1}$ 的元素,而且 $x-x^{\prime} \in C_{2}$ ,则容易得知 $\left|x+C_{2}\right\rangle=$ $\left|x^{\prime}+C_{2}\right\rangle$ 。因此,$\left|x+C_{2}\right\rangle$ 只依赖于 $x$ 所在的 $C_{1} / C_{2}$ 的陪集,这解释了为何我们使用陪集符号
 此,$\left|x+C_{2}\right\rangle$ 和 $\left|x^{\prime}+C_{2}\right\rangle$ 是正交态。量子编码 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 就定义为对所有状态 $\left|x+C_{2}\right\rangle$ 所张成的向量空间,这里 $x$ 取遍 $C_{1}$ 所有值,$C_{2}$ 在 $C_{1}$ 中所有陪集的数量为 $\left|C_{1}\right| /\left|C_{2}\right|$ ,因此 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$的维数为 $\left|C_{1}\right| /\left|C_{2}\right|=2^{k_{1}-k_{2}}$ ,所以 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 是一个 $\left[n, k_{1}-k_{2}\right]$ 量子编码。
此,$\left|x+C_{2}\right\rangle$ 和 $\left|x^{\prime}+C_{2}\right\rangle$ 是正交态。量子编码 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 就定义为对所有状态 $\left|x+C_{2}\right\rangle$ 所张成的向量空间,这里 $x$ 取遍 $C_{1}$ 所有值,$C_{2}$ 在 $C_{1}$ 中所有陪集的数量为 $\left|C_{1}\right| /\left|C_{2}\right|$ ,因此 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$的维数为 $\left|C_{1}\right| /\left|C_{2}\right|=2^{k_{1}-k_{2}}$ ,所以 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 是一个 $\left[n, k_{1}-k_{2}\right]$ 量子编码。
我们现在利用经典纠错码 $C_{1}$ 和 $C_{2}^{\perp}$ 的特征来探测和纠正量子错误!事实上,基于 $C_{1}$ 和 $C_{2}^{\perp}$的纠错特征,我们可以纠正最多 $t$ 个 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 上的相位翻转错误和比特翻转错误。假设比特翻转错误由 $n$ 比特的向量 $e_{1}$ 描述,其中取值 1 的位置就是错误发生的位置,否则取值为 0 ;相位翻转错误发生的情况由 $n$ 比特向量 $e_{2}$ 描述,类似错误发生的位置上取值为 1 ,否则为 0 。如果原
来的量子态是 $\left|x+C_{2}\right\rangle$ ,则错误干扰后的状态为
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}(-1)^{(x+y) \cdot e_{2}}\left|x+y+e_{1}\right\rangle \tag{10.65}
\end{equation*}
$$
为了探测哪些比特发生了翻转,一个方便的方式是引人足够的初态为 $|0\rangle$ 的辅助量子比特,它们的用处是储存编码 $C_{1}$ 的征状。我们利用可逆计算将奇偶校验矩阵 $H_{1}$ 作用在 $C_{1}$ 编码上,将 $\left|x+y+e_{1}\right\rangle|0\rangle$ 变为 $\left|x+y+e_{1}\right\rangle\left|H_{1}\left(x+y+e_{1}\right)\right\rangle=\left|x+y+e_{1}\right\rangle\left|H_{1} e_{1}\right\rangle$ 。由于 $(x+y) \in C_{1}$ 将被奇偶校验矩阵消掉,所以这个操作的效果是产生了状态
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}(-1)^{(x+y) \cdot e_{2}}\left|x+y+e_{1}\right\rangle\left|H_{1} e_{1}\right\rangle \tag{10.66}
\end{equation*}
$$
习题10.26 $H$ 是一个奇偶校验矩阵,解释如何用一个只由受控非门构成的电路来计算变换 $|x\rangle|0\rangle \rightarrow|x\rangle|H x\rangle_{\circ}$
比特翻转错误的探测由测量这些辅助量子比特完成,测量得到结果 $H_{1} e_{1}$ ,再扔掉辅助量子比特后得到量子态
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}(-1)^{(x+y) \cdot e_{2}}\left|x+y+e_{1}\right\rangle \tag{10.67}
\end{equation*}
$$
在知道错误征状 $H_{1} e_{1}$ 之后,我们就可以反推出错误 $e_{1}$ ,因为 $C_{1}$ 可以纠正最多 $t$ 个错误。而纠正这些错误很自然地就是在错误发生的位置均作用一个非门,这将产生状态
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}(-1)^{(x+y) \cdot e_{2}}|x+y\rangle \tag{10.68}
\end{equation*}
$$
为了探测相位翻转错误,我们在每个量子比特上作用一个阿达玛门,系统的状态将成为
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right| 2^{n}}} \sum_{z} \sum_{y \in C_{2}}(-1)^{(x+y) \cdot\left(e_{2}+z\right)}|z\rangle \tag{10.69}
\end{equation*}
$$
这里求和是对 $n$ 比特变量 $z$ 的所有可能值进行。令 $z^{\prime} \equiv z+e_{2}$ ,上述量子态也可以写作
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right| 2^{n}}} \sum_{z^{\prime}} \sum_{y \in C_{2}}(-1)^{(x+y) \cdot z^{\prime}}\left|z^{\prime}+e_{2}\right\rangle \tag{10.70}
\end{equation*}
$$
(下一步出现于习题 10.25 。)假设 $z^{\prime} \in C_{2}^{\perp}$ ,则不难看出 $\sum_{y \in C_{2}}(-1)^{y \cdot z^{\prime}}=\left|C_{2}\right|$ ,而如果 $z^{\prime} \equiv z+e_{2}$ ,则 $\sum_{y \in C_{2}}(-1)^{y \cdot z^{\prime}}=0$ 。因此,我们可以将上述量子态再写成
$$
\begin{equation*}
\frac{1}{\sqrt{2^{n} /\left|C_{2}\right|}} \sum_{z^{\prime} \in C_{2}^{\frac{1}{2}}}(-1)^{x \cdot z^{\prime}}\left|z^{\prime}+e_{2}\right\rangle \tag{10.71}
\end{equation*}
$$
上式正好就是 $e_{2}$ 描述的比特翻转错误!于是,就如同探测比特翻转错误一样,我们引入辅助量
子态,可逆地在编码 $C_{2}^{\perp}$ 上作用奇偶校验矩阵 $H_{2}$ 以得到 $H_{2} e_{2}$ ,然后就可以纠正"比特翻转错误"$e_{2}$ ,最终得到量子态
$$
\begin{equation*}
\frac{1}{\sqrt{2^{n} /\left|C_{2}\right|}} \sum_{z^{\prime} \in C_{2}^{\perp}}(-1)^{x \cdot z^{\prime}}\left|z^{\prime}\right\rangle \tag{10.72}
\end{equation*}
$$
再对每个量子比特作用一个阿达玛门,量子纠错就完成了。为此,我们既可以直接计算这些逻辑门作用的结果,也可以用下面的替代方法:注意结果其实就是将这些阿达玛门作用在式(10.71)上,然后令 $e_{2}=0$ 。由于 $H$ 是自逆的,这相当于将量子态变为式(10.68)的状态,再令 $e_{2}=0$ ,
$$
\begin{equation*}
\frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}|x+y\rangle \tag{10.73}
\end{equation*}
$$
这正是原本的量子态!
CSS 编码的一个重要应用是证明 Gilbert-Varshamov 界限的量子版本,因此保证了高性能量子编码的存在性。这个重要的结论指出,在 $n$ 变大的极限情况下,存在某个能纠正至多 $k$ 个量子比特上任意错误的 $[n, k]$ 量子编码,使得
$$
\begin{equation*}
\frac{k}{n} \geqslant 1-2 H\left(\frac{2 t}{n}\right) \tag{10.74}
\end{equation*}
$$
成立。因此,只要我们不希望用 $n$ 个量子比特编码过多的 $k$ 个量子比特,高性能的量子编码是确实存在的。因为经典编码 $C_{1}$ 和 $C_{2}$ 受到的限制,证明 CSS 编码的 Gilbert-Varshamov 界限比证明经典 Gilbert-Varshamov 界限复杂得多,见本章最后的遗留问题。
总结一下,假设 $C_{1}$ 和 $C_{2}$ 分别是 $\left[n, k_{1}\right]$ 和 $\left[n, k_{2}\right]$ 的经典线性编码,$C_{2} \subset C_{1}$ ,而且 $C_{1}$ 和 $C_{2}^{\perp}$ 都能纠正至多 $t$ 个错误,那么 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 是一个能纠正最多 $t$ 个量子比特上任意错误的 $\left[n, k_{1}-k_{2}\right]$ 量子纠错码。并且,对应的错误探测和纠正步骤,只需要应用数量是编码大小的常数倍数的阿达玛门和受控非门。其实编码和解码也可以用编码大小常数倍数的操作完成,但我们暂时不再详述,而是在 10.5.8 节以更广泛的视角回到这个问题上。
习题10.27 证明在拥有同样纠错特征的意义下,由
$$
\begin{equation*}
\left|x+C_{2}\right\rangle \equiv \frac{1}{\sqrt{\left|C_{2}\right|}} \sum_{y \in C_{2}}(-1)^{u \cdot y}|x+y+v\rangle \tag{10.75}
\end{equation*}
$$
定义的编码与 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 等价,这里 $u$ 和 $v$ 是参数。这些编码被记作 $\operatorname{CSS}_{u, v}\left(C_{1}, C_{2}\right)$ ,将在后面的 12.6.5 节中用来学习量子密钥分配。
Steane 编码
之前我们讨论过 $[7,4,3]$ 汉明码,它的奇偶校验矩阵是
$$
H=\left[\begin{array}{lllllll}
0 & 0 & 0 & 1 & 1 & 1 & 1 \tag{10.76}\\
0 & 1 & 1 & 0 & 0 & 1 & 1 \\
1 & 0 & 1 & 0 & 1 & 0 & 1
\end{array}\right]
$$
基于它,一个重要的 $\operatorname{CSS}$ 量子编码可以被构造出来。我们将汉明码标记为 $C$ ,定义 $C_{1} \equiv C$ 和 $C_{2} \equiv C^{\perp}$ 。为了定义 $\operatorname{CSS}$ 编码,我们需要验证 $C_{2} \subset C_{1}$ 。根据定义,$C_{2}$ 的奇偶校验矩阵是 $C_{1}$ 产生矩阵的转置,即
$$
H\left[C_{2}\right]=G\left[C_{1}\right]^{T}=\left[\begin{array}{lllllll}
1 & 0 & 0 & 0 & 0 & 1 & 1 \tag{10.77}\\
0 & 1 & 0 & 0 & 1 & 0 & 1 \\
0 & 0 & 1 & 0 & 1 & 1 & 0 \\
0 & 0 & 0 & 1 & 1 & 1 & 1
\end{array}\right]
$$
习题 10.28 验证式(10.77)中矩阵的转置是 $[7,4,3]$ 汉明码的产生矩阵。
与式(10.76)相比,我们可以看到 $H\left[C_{2}\right]$ 的行张成比 $H\left[C_{1}\right]$ 的行所张成空间严格大的空间,由于对应的编码就是 $H\left[C_{2}\right]$ 和 $H\left[C_{1}\right]$ 的核空间,于是我们有 $C_{2} \subset C_{1}$ 。并且,$C_{2}^{\perp}=\left(C^{\perp}\right)^{\perp}=C$ ,所以 $C_{1}$ 和 $C_{2}^{\perp}$ 都是能纠正一个错误的距离为 3 的编码。 $C_{1}$ 和 $C_{2}$ 分别是 $[7,4]$ 和 $[7,3]$ 编码,所以 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 是一个 $[7,1]$ 量子编码,它能纠正一个量子比特上的任意错误。
这个 $[7,1]$ 量子编码因为它的发明者被称作 Steane 编码,它有一些很好的特性,非常好用,因此在本章后面我们将反复将其作为例子讨论。 $C_{2}$ 的码字由式(10.77)和习题 10.28 很容易确定。在此我们不打算将其逐项写出来,其实它们隐含在 Steane 编码逻辑 $\left|0_{L}\right\rangle$ ,即 $\left|0+C_{2}\right\rangle$ 的各项中:
$$
\begin{align*}
\left|0_{L}\right\rangle= & \frac{1}{\sqrt{8}}[|0000000\rangle+|1010101\rangle+|0110011\rangle+|1100110\rangle \tag{10.78}\\
& +|0001111\rangle+|1011010\rangle+|0111100\rangle+|1101001\rangle]
\end{align*}
$$
为了确定另一个逻辑码字,我们需要找到一个不在 $C_{2}$ 中的 $C_{1}$ 的元素,一个这样的例子是 $(1,1,1$ , $1,1,1,1)$ 。因此,我们有
$$
\begin{array}{r}
\left|1_{L}\right\rangle=\frac{1}{\sqrt{8}}[|1111111\rangle+|0101010\rangle+|1001100\rangle+|0011001\rangle \tag{10.79}\\
+|111000\rangle+|0100101\rangle+|1000011\rangle+|0010110\rangle]
\end{array}
$$
10.5 稳定子编码
我们不能勉为其难地去尝试克隆;相应地,我们通过拆分
量子相千来保护
我们宝贵的量子信息免受噪音的困扰,虽然这样做会让计算花费很长时间。
校正一个翻转和一个相位已足够。如果在我们的代码中出现另一个错误,我们简单地测量它,然后上帝掊骰子,让其嬗变为 $X, Y$ 或 $Z$ 。我们开始于带噪声的七,九或五
并以完美的一结尾。为了更好地发现
我们必须避免的那些缺陷,我们首先必须努力
搞明白哪些对易,哪些不对易。
通过群和本征态,我们学会了
用我们的量子技巧修复您的量子错误。
——"量子错误校正十四行诗",丹尼尔•格特斯曼(Daniel Gottesman)
稳定子编码,有时候也称作可加性量子编码,是一类重要的量子编码,它与经典线性编码有类似的构造方法。为了介绍稳定子编码,我们需要先发展出一种名为稳定子形式的强大方法,它可以让我们理解量子力学的一大类操作。实际上,稳定子形式的应用可以远远超出量子纠错的范围,但是在本书中我们将精力主要集中在这一块。我们首先定义稳定子形式,接着介绍酉变换逻辑门和测量如何用它描述,同时也给出一个定量描述稳定子操作极限的定理。最后,我们将介绍以下内容:稳定子编码的稳定子构造方法,一些具体的例子,一个有用的标准形式,以及编码,解码和纠错的电路构造。
10.5.1 稳定子形式
稳定子形式的核心想法可以用一个例子来描述。考虑两个量子比特的 EPR 对
$$
\begin{equation*}
|\psi\rangle=\frac{|00\rangle+|11\rangle}{\sqrt{2}} \tag{10.80}
\end{equation*}
$$
不难验证,这个量子态满足 $X_{1} X_{2}|\psi\rangle=|\psi\rangle$ 和 $Z_{1} Z_{2}|\psi\rangle=|\psi\rangle$ ,因此我们说,状态 $|\psi\rangle$ 被 $X_{1} X_{2}$和 $Z_{1} Z_{2}$ 稳定。实际上一个不太明显的事实是,状态 $|\psi\rangle$ 是被这两个算子稳定的唯一量子态(不考虑全局变量带来的差别)。稳定子形式的基本思想就是,对于许多量子态,用稳定它们的算子来描述经常比直接描述状态本身更加方便。这个论断乍看之下非常让人意外,但却是真实的。实际上,许多量子编码(包括 CSS 编码和 Shor 编码),用稳定子来描述比直接用状态向量来描述要方便简洁许多。更重要的是,量子比特和量子操作上的噪声,例如 $\mathrm{H} 门$ ,相位门,甚至受控非门和计算基下的测量,都可以很容易地用稳定子形式来描述。
稳定子形式具有如此威力的关键,是对群论的巧妙运用,关于群论的介绍请见附录 B 。我们关心的群主要是 $n$ 量子比特上的泡利群。对单量子比特而言,泡利群由连同系数 $\pm 1, \pm \mathrm{i}$ 在内的所有泡利矩阵组成:
$$
\begin{equation*}
G_{1} \equiv{ \pm I, \pm \mathrm{i} I, \pm X, \pm \mathrm{i} X, \pm Y, \pm \mathrm{i} Y, \pm Z, \pm \mathrm{i} Z} \tag{10.81}
\end{equation*}
$$
上述集合在矩阵乘法运算下构成一个群。读者可能会问,为什么我们不去掉系数 $\pm 1, \pm \mathrm{i}$ ?我们将它们包括进来是为了让 $G_{1}$ 在乘法运算下封闭,因而构成一个合法的群。对于一般情况,即 $n$ 量子比特上的泡利群,由所有泡利矩阵的 $n$ 次张量乘积构成,并且同样包含所有可能的系数 $\pm 1, \pm \mathrm{i}_{\circ}$
我们现在给出稳定子更精确的定义。假设 $S$ 是 $G_{n}$ 的一个子群,将 $V_{S}$ 定义为被 $S$ 所有元素稳定的 $n$ 量子比特状态的集合。于是,由于 $V_{S}$ 的每个元素在 $S$ 中元素的作用下保持稳定,$V_{S}$ 是
被 $S$ 稳定的向量空间,$S$ 则被称作空间 $V_{S}$ 的稳定子。为了帮助大家确信这一点,可以完成下面的习题。
习题10.29 证明 $V_{S}$ 中任意两个元素的线性组合也在 $V_{S}$ 中。因此,$V_{S}$ 是 $n$ 量子比特状态空间的子空间。证明 $V_{S}$ 是 $S$ 中每个算子所稳定的子空间的交集(也就是,$S$ 中元素特征值为 1 的特征空间。)
我们现在来看一个稳定子形式的简单例子,这个例子涉及三个量子比特,$S \equiv\left\{I, Z_{1} Z_{2}, Z_{2} Z_{3}\right.$ , $\left.Z_{1} Z_{3}\right\}_{\circ}$ 在 $Z_{1} Z_{2}$ 作用下稳定的子空间由 $|000\rangle,|001\rangle,|110\rangle,|111\rangle$ 张成,而在 $Z_{2} Z_{3}$ 作用下稳定的子空间由 $|000\rangle,|100\rangle,|011\rangle,|111\rangle$ 张成。注意在这两个列表中共同的元素是 $|000\rangle,|111\rangle$ ,由此可知,在这个例子上 $V_{S}$ 就是 $|000\rangle$ 和 $|111\rangle$ 张成的子空间。
这里,$V_{S}$ 可以仅仅通过观察 $S$ 中两个元素所稳定的子空间来确定,这展示了一个重要的一般性现象———个群可以用它对应的生成元来描述。正如附录 B 中介绍的,如果一个群 $G$ 的每一个元素都可以写成 $g_{1}, \cdots, g_{l}$ 中元素组成的乘积形式,则称 $G$ 可以由它的一组元素 $g_{1}, \cdots, g_{l}$生成,记作 $G=\left\langle g_{1}, \cdots, g_{l}\right\rangle$ 。在上面的例子中,$S=\left\langle Z_{1} Z_{2}, Z_{2} Z_{3}\right\rangle$ ,因为 $Z_{1} Z_{3}=\left(Z_{1} Z_{2}\right)\left(Z_{2} Z_{3}\right)$ , $I=\left(Z_{1} Z_{2}\right)^{2}$ 。使用生成元的一个巨大好处是它提供了一个非常简洁的方式来描述群。实际上,在附录 B 中我们可以看到,一个大小为 $|G|$ 的群,可以由一组至多包含 $\log (|G|)$ 个生成子组成的集合生成。并且,为了验证一个特定的向量被一个群 $S$ 稳定,我们只需要验证它被生成元稳定,因为如果这是正确的,生成元的乘积自然也会稳定这个向量,因而这是一种极端方便的群表示方法。(我们用来表示群生成子的符号 $\langle\cdots\rangle$ 可能会跟 2.2 .5 节中表示可观测量平均值的符号混淆,但实际上根据上下文应该不难区分具体的含义。)
不只是泡利群的子群 $S$ 可以被用作非平凡向量空间的稳定子。例如,考虑由 ${ \pm I, \pm X}$ 构成的 $G_{1}$ 的子群。明显地,$(-I)|\psi\rangle=|\psi\rangle$ 的唯一解是 $|\psi\rangle=0$ ,因此 ${ \pm I, \pm X}$ 只稳定一个平凡的子空间。为了让被稳定的子空间 $V_{S}$ 是非平凡的,$S$ 必须满足什么条件呢?两个容易被看出的必要条件是:(a)$S$ 的元素彼此对易,(b)$-I$ 不在 $S$ 中。我们现在还没有足够的工具证明,但实际上后面会看到,这两个条件对 $V_{S}$ 非平凡来说也是充分的。
习题 10.30 证明由 $-I \notin S$ 可以推导出 $\pm \mathrm{i} I \notin S$ 。
为了说明上述两个条件是必要的,假设 $V_{S}$ 是非平凡的,于是它包含一个非零向量 $|\psi\rangle$ 。假设 $M$ 和 $N$ 是 $S$ 的两个元素,则 $M$ 和 $N$ 是泡利矩阵的张量积,再加上一个可能的全局系数。由于泡利矩阵彼此之间都是反对易的,于是 $M$ 和 $N$ 要么对易,要么反对易。为了得到条件(a),即它们都对易,我们假设它们反对易,然后指出这将导致一个矛盾。实际上,根据假设有 $-N M=M N$ ,因此 $-|\psi\rangle=-N M|\psi\rangle=M N|\psi\rangle=|\psi\rangle$ ,这里第一个和最后一个等式来自 $M$ 和 $N$ 稳定 $|\psi\rangle$ 的事实。所以,我们有 $-|\psi\rangle=|\psi\rangle$ ,这意味着 $|\psi\rangle$ 必须是零向量,这是一个矛盾。为了得到条件(b),即 $-I \notin S$ ,注意 $-I$ 是 $S$ 的元素意味着 $-I|\psi\rangle=|\psi\rangle$ ,这又导致一个矛盾。
习题10.31 假设 $S$ 是元素 $g_{1}, \cdots, g_{l}$ 生成的 $G_{n}$ 的子群。证明 $S$ 中所有元素对易,当且仅当对每对 $i$ 和 $j$ ,有 $g_{i}$ 和 $g_{j}$ 对易。
七量子比特 Steane 编码提供了一个稳定子形式的漂亮例子。
事实上,图 10-6 展示的六个生成子 $g_{1}, \cdots, g_{6}$ 可以产生一个 Steane 编码空间的稳定子。我
们可以感受一下,与式(10.78)和式(10.79)中基于状态向量的复杂描述相比,新的描述方法是多么简洁而干净。当我们用新视角来考察量子纠错时,我们会看到进一步的优势。同时,我们也可以注意到图 10-6 中生成子的结构,与之前构造 Steane 编码时用到的经典线性编码 $C_{1}$ 和 $C_{2}^{\perp}$ 的奇偶校验矩阵之间(如前所述,对 Steane 编码来说,$C_{1}=C_{2}^{\perp}$ 是 $[7,4,3]$ 汉明码,对应的奇偶校验矩阵由式(10.76)给出)有相似之处。稳定子的头三个生成子有 $X$ 的出现,并且它们的位置对应着 $C_{1}$ 的奇偶校验矩阵中 1 的位置;类似地,后三个生成子 $g_{4}$ 到 $g_{6}$ ,有 $Z$ 的出现,它们的位置对应着 $C_{2}^{\perp}$ 的奇偶校验矩阵中 1 的位置。观察到这些事实,解答下面的习题就不再困难。
| 名称 |
算子 |
|
|
|
|
|
|
|
| $g_{1}$ |
$I$ |
$I$ |
$I$ |
$X$ |
$X$ |
$X$ |
$X$ |
|
| $g_{2}$ |
$I$ |
$X$ |
$X$ |
$I$ |
$I$ |
$X$ |
$X$ |
|
| $g_{3}$ |
$X$ |
$I$ |
$X$ |
$I$ |
$X$ |
$I$ |
$X$ |
|
| $g_{4}$ |
$I$ |
$I$ |
$I$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
|
| $g_{5}$ |
$I$ |
$Z$ |
$Z$ |
$I$ |
$I$ |
$Z$ |
$Z$ |
|
| $g_{6}$ |
$Z$ |
$I$ |
$Z$ |
$I$ |
$Z$ |
$I$ |
$Z$ |
|
图 10-6 七量子比特 Steane 编码的稳定子生成元。每项代表一个相应量子比特上的张量积;例如 $Z I Z I Z I Z=Z \otimes I \otimes Z \otimes I \otimes Z \otimes I \otimes Z=Z_{1} Z_{3} Z_{5} Z_{7}$
习题10.32 验证图 10-6 中的生成子稳定 10.4.2 节所述 Steane 编码的码字。
上面我们使用稳定子形式描述一个量子编码,其实预示着我们在后面也会用这个方法描述一大类量子编码。但就目前来说,重要的是要体会到,作为一个量子编码,Steane 编码并无特别之处,它只是向量空间的一个可以用稳定子描述的子空间。
实际上,我们需要这些生成子 $g_{1}, \cdots, g_{l}$ 都是互相独立的,这意味着去掉任何一个生成子,剩下的生成子能生成的群是严格小的,即
$$
\begin{equation*}
\left\langle g_{1}, \cdots, g_{i-1}, g_{i+1}, \cdots, g_{l}\right\rangle \neq\left\langle g_{1}, \cdots, g_{l}\right\rangle \tag{10.82}
\end{equation*}
$$
就我们目前的理解来说,决定一组生成子是否独立是一个非常耗费时间的过程。幸运的是,用被称为校验矩阵的想法,有一个很简单的办法完成这个任务。如此称呼这个方法的原因是,它在稳定子编码中起到的作用,与奇偶校验矩阵在经典线性编码中起到的作用类似。
假设 $S=\left\langle g_{1}, \cdots, g_{l}\right\rangle$ ,有一个极有用的用校验矩阵来描述生成子的方法。这是一个 $l \times 2 n$ 的矩阵,它的行对应着生成元 $g_{1}, \cdots, g_{l}$ ,矩阵左手边的 1 意味着生成子包含 $X$ 操作,右手边的 1意味着生成子包含 $Z$ 操作,而两边都有 1 则表示生成子中有 $Y$ 操作。更具体地,第 $i$ 行是如下构造出来的。如果 $g_{i}$ 的第 $j$ 个量子比特上是 $I$ ,则第 $j$ 和第 $n+j$ 列元素是 0 ;如果第 $j$ 个量子比特上是 $X$ ,则第 $j$ 和第 $n+j$ 列元素分别是 1 和 0 ;如果第 $j$ 个量子比特上是 $Z$ ,则第 $j$ 和第 $n+j$ 列元素分别是 0 和 1 ;如果第 $j$ 个量子比特上是 $Y$ ,则第 $j$ 和第 $n+j$ 列元素都是 1 。于是,
对七量子比特 Stenea 编码来说,可以由图 10-6 得到如下的校验矩阵
$$
\left[\begin{array}{lllllll|lllllll}
0 & 0 & 0 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \tag{10.83}\\
0 & 1 & 1 & 0 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 & 0 & 1 & 1 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 1 & 0 & 1 & 0 & 1
\end{array}\right]
$$
校验矩阵不包含任何关于生成子前系数的信息,但它包含许多其他的有用信息。为此,我们用 $r(g)$ 来代表泡利群中一个任意元素的 $2 n$ 维行向量描述。假设我们定义一个如下的 $2 n \times 2 n$ 矩阵 $\Lambda$ :
$$
\Lambda=\left[\begin{array}{ll}
0 & I \tag{10.84}\\
I & 0
\end{array}\right]
$$
这里对角线外 $I$ 是 $n \times n$ 的。那么,不难看出,泡利群的两个元素 $g$ 和 $g^{\prime}$ 对易当且仅当 $r(g) \Lambda r\left(g^{\prime}\right)^{T}=$ 0 。实际上,形式 $x \Lambda y^{T}$ 定义了 $x$ 和 $y$ 之间一种扭曲的内积,给出了 $x$ 和 $y$ 对应的泡利群元素是否对易的信息。
习题 10.33 证明 $g$ 和 $g^{\prime}$ 对易,当且仅当 $r(g) \Lambda r\left(g^{\prime}\right)^{T}=0$ 。(在校验矩阵表示中,代数运算都对 2 取模。)
习题10.34 令 $S=\left\langle g_{1}, \cdots, g_{l}\right\rangle$ ,证明 $-I$ 不是 $S$ 的元素,当且仅当对所有 $j$ 有 $g^{2}=I$ ,而且对所有 $j, g_{j} \neq-I$ 。
习题10.35 $S$ 是 $G_{n}$ 的子群,而且 $-I$ 不是 $S$ 的元素,证明对所有 $g \in S$ 有 $g^{2}=I$ 成立,因此 $g^{\dagger}=g$ 。
下面的命题建立了生成子的独立性和校验矩阵之间的一个紧密关系。
命题10.3 令 $S=\left\langle g_{1}, \cdots, g_{l}\right\rangle$ ,并且 $-I$ 不是 $S$ 的元素。生成元 $g_{1}$ 到 $g_{l}$ 是独立的,当且仅当对应校验矩阵的行线性独立。
证明
我们来证明对应的逆否命题。注意根据习题 10.35 ,对任意 $i$ 都有 $g_{i}^{2}=I$ 。由于 $r(g)+r\left(g^{\prime}\right)=$ $r\left(g g^{\prime}\right)$ ,行向量的相加对应着对应群元素的相乘。因此,校验矩阵的行线性相关,即 $\sum_{i} a_{i} r\left(g_{i}\right)=0$ ,而且对某个 $j$ 有 $a_{j} \neq 0$ ,当且仅当 $\prod_{i} g_{i}^{a_{i}}$ 等于单位阵,再加一个可能的全局系数。但是 $-I \notin S$ ,因此这个全局系数必须是 1 ,于是有 $g_{j}=g_{j}^{-1}=\prod_{i \neq j} g_{i}^{a_{i}}$ ,这意味着 $g_{1}, \cdots, g_{l}$ 不是独立的生成子。
下面这个看起来平凡的命题,被证明是非常有用的,从它出发可以立刻得出以下有用结论的一个证明,即如果 $S$ 由 $l=n-k$ 个独立且彼此对易的生成子所生成,同时 $g_{1}, \cdots, g_{l}$ ,则 $V_{S}$ 的维数为 $2^{k}$ 。在本章余下部分我们将反复使用本命题,它的证明也是基于校验矩阵的表示。
命题10.4 假设 $S=\left\langle g_{1}, \cdots, g_{l}\right\rangle$ 由 $l$ 个独立的生成子生成,而且 $-I \notin S$ 。在 $1, \cdots, l$ 中挑出一个固定的 $i$ ,则 $G_{n}$ 中存在一个元素 $g$ 使得对所有 $j \neq i$ 都有 $g g_{j} g^{\dagger}=g_{j}$ 和 $g g_{i} g^{\dagger}=-g_{i}$ 成立。证明
假设 $G$ 是与 $g_{1}, \cdots, g_{l}$ 相关的校验矩阵。根据命题 $10.3, G$ 的行线性无关,因此存在一个 $2 n$维的向量 $x$ 使得 $G \Lambda x=e_{i}$ 成立,这里 $e_{i}$ 是第 $i$ 个位置为 1 ,其他位置为 0 的 $l$ 维向量。令 $g$ 使得 $r(g)=x^{T}$ 成立,则根据 $x$ 的定义,我们有对 $j \neq i, r\left(g_{j}\right) \Lambda r(g)^{T}=0$ 成立,以及 $r\left(g_{i}\right) \Lambda r(g)^{T}=1$ 。因此,对 $j \neq i$ ,有 $g g_{j} g^{\dagger}=g_{j}$ 和 $g g_{i} g^{\dagger}=-g_{i}$ 。
在结束对稳定子形式基本特征的讨论之前,我们来确认之前提到的一个论断,即如果 $S$ 是被一组独立,互相对易的生成子生成,并且 $-I \notin S$ ,则 $V_{S}$ 是非平凡的。实际上,如果总共有 $l=n-k$ 个生成子,则一个合理的想法(稍后会证明)是 $V_{S}$ 是 $2^{k}$ 维的。因为直观上看,每多出一个生成子,则 $V_{S}$ 的维数就会被乘以 $1 / 2$ ,其根据是泡利矩阵乘积的特征值是 $+1,-1$ ,而它们将希尔伯特空间拆分成两个维度相同的子空间。
命题10.5 令 $S=\left\langle g_{1}, \cdots, g_{l}\right\rangle$ 是被 $n-k$ 个独立,互相对易的 $G_{n}$ 元素生成,而且 $-I \notin S$ 。则 $V_{S}$ 是 $2^{k}$ 维向量空间。
在后面关于稳定子形式的所有讨论中,我们总是假设稳定子由独立,相互对易的生成子描述,而且 $-I \notin S$ 。
证明
令 $x=\left(x_{1}, \cdots, x_{n-k}\right)$ 是一个向量,其 $n-k$ 个元素来自 $Z_{2}$ 。定义
$$
\begin{equation*}
P_{S}^{x} \equiv \frac{\prod_{j=1}^{n-k}\left(I+(-1)^{x_{j}} g_{j}\right)}{2^{n-k}} \tag{10.85}
\end{equation*}
$$
因为 $\left(I+g_{j}\right) / 2$ 是映到 $g_{j}$ 的 +1 特征空间的投影算子,容易看出 $P_{S}^{(0, \cdots, 0)}$ 是映射到 $V_{S}$ 上的投影算子。根据命题 10.4 ,对每个 $x$ 都存在一个 $G_{n}$ 的元素 $g_{x}$ 使得 $g_{x} P_{S}^{(0, \cdots, 0)}\left(g_{x}\right)^{\dagger}=P_{S}^{x}$ 成立,因此 $P_{S}^{x}$ 的维数跟 $V_{S}$ 的维数相同。并且不难看出,对于不同的 $x$ 来说,$P_{S}^{x}$ 之间是正交的。
同时,我们有下面的事实:
$$
\begin{equation*}
I=\sum_{x} P_{S}^{x} \tag{10.86}
\end{equation*}
$$
这里,左边是一个映射到 $2^{n}$ 维空间的投影算子,而右边是 $2^{n-k}$ 个正交投影算子的总和,并且它们的维数都跟 $V_{S}$ 相同。所以,$V_{S}$ 的维数一定是 $2^{k}$ 。
10.5.2 西逻辑门和稳定子形式
我们讨论了如何利用稳定子形式来描述向量空间,其实它也可以用来描述这些向量空间在更大空间中,由一系列有趣量子操作导致的动态过程。除了理解量子动态过程本身的兴趣,这种考虑的另一个目的是用稳定子形式来描述量子纠错码,特别是希望有一种简单的方式来理解噪声和其他一些动态过程在纠错码上的作用。假设我们在一个被群 $S$ 稳定的向量空间 $V_{S}$ 上作用一个西变换 $U$ ,则对 $S$ 的任意元素 $g$ ,都有
$$
\begin{equation*}
U|\psi\rangle=U g|\psi\rangle=U g U^{\dagger} U|\psi\rangle \tag{10.87}
\end{equation*}
$$
因此,状态 $U|\psi\rangle$ 被 $U g U^{\dagger}$ 稳定,于是我们可知向量空间 $U V_{S}$ 被群 $U S U^{\dagger} \equiv\left\{U g U^{\dagger} \mid g \in S\right\}$ 稳定。而且,如果 $g_{1}, \cdots, g_{l}$ 生成 $S$ ,则 $U g_{1} U^{\dagger}, \cdots, U g_{l} U^{\dagger}$ 生成 $U S U^{\dagger}$ 。所以,为了计算稳定子的变化,我们只需要计算对其生成子的影响。
这种方法描述动态过程的一个巨大优势就是,对于某些特别的西变换 $U$ ,生成子的变换呈现特别漂亮的形式。例如,假设我们对一个单量子比特作用一个阿达玛门。注意我们有
$$
\begin{equation*}
H X H^{\dagger}=Z ; \quad H Y H^{\dagger}=-Y ; \quad H Z H^{\dagger}=X \tag{10.88}
\end{equation*}
$$
于是,一个被 $Z$ 稳定的量子态 $|0\rangle$ ,在被作用一个阿达玛门之后,将被 $X$ 稳定 $(|+\rangle)$ 。
不太意外,如果我们有一个 $n$ 量子比特状态,它的稳定子是 $\left\langle Z_{1}, Z_{2}, \cdots, Z_{n}\right\rangle$ ,则不难看出这个状态一定是 $|0\rangle^{\otimes n}$ 。对这 $n$ 个量子比特各作用一个阿达玛门后,状态的稳定子为 $\left\langle X_{1}, X_{2}, \cdots, X_{n}\right\rangle$ ,而状态本身显然就是所有计算基下状态的均匀叠加态。这个例子中,最引人注意的一点就是,在基于向量的通常描述中我们需要给出 $2^{n}$ 个幅度的刻画,但在生成子提供的描述方案 $\left\langle X_{1}, \cdots, X_{n}\right\rangle$中,规模与 $n$ 是线性关系!也许你会认为,在对 $n$ 个量子比特中的每个作用阿达玛门后,量子计算机中完全没有纠缠,因此得到这种简洁的描述并不意外。但实际上,稳定子形式提供了多得多的可能,包括受控非门的有效刻画,它与 H 门一起可以生成纠缠。为了理解这一点,我们考虑算子 $X_{1}, X_{2}, Z_{1}, Z_{2}$ 如何在受控非门诱导的共轭操作下变化。假设 $U$ 是受控非门,其中量子比特 1负责控制,量子比特 2 是目标。我们有
$$
\begin{align*}
U X_{1} U^{\dagger} & =\left[\begin{array}{llll}
1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 \\
0 & 0 & 0 & 1 \\
0 & 0 & 1 & 0
\end{array}\right]\left[\begin{array}{llll}
0 & 0 & 1 & 0 \\
0 & 0 & 0 & 1 \\
1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0
\end{array}\right]\left[\begin{array}{llll}
1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 \\
0 & 0 & 0 & 1 \\
0 & 0 & 1 & 0
\end{array}\right] \\
& =\left[\begin{array}{llll}
0 & 0 & 0 & 1 \\
0 & 0 & 1 & 0 \\
0 & 1 & 0 & 0 \\
1 & 0 & 0 & 0
\end{array}\right] \\
& =X_{1} X_{2} \tag{10.89}
\end{align*}
$$
类似的计算可以得到,$U X_{2} U^{\dagger}=X_{2}, U Z_{1} U^{\dagger}=Z_{1}$ ,以及 $U Z_{2} U^{\dagger}=Z_{1} Z_{2}$ 。为了看出 $U$ 如何跟二量子比特泡利群中其他算子结合,我们只需要取已知结果的乘积。例如,为了计算 $U X_{1} X_{2} U^{\dagger}$ ,我们有 $U X_{1} X_{2} U^{\dagger}=U X_{1} U^{\dagger} U X_{2} U^{\dagger}=\left(X_{1} X_{2}\right) X_{2}=X_{1}$ 。泡利矩阵 $Y$ 可以类似地处理,比如 $U Y_{2} U^{\dagger}=\mathrm{i} U X_{2} Z_{2} U^{\dagger}=\mathrm{i} U X_{2} U^{\dagger} U Z_{2} U^{\dagger}=\mathrm{i} X_{2}\left(Z_{1} Z_{2}\right)=Z_{1} Y_{2}$ 。
习题 10.36 明确地验证 $U X_{1} U^{\dagger}=X_{1} X_{2}, U X_{2} U^{\dagger}=X_{2}, U Z_{1} U^{\dagger}=Z_{1}$ ,以及 $U Z_{2} U^{\dagger}=Z_{1} Z_{2}$ 。此外还有一些关于阿达玛门,相位门和泡利门的有用共轭关系,见图 10-7。
| 操作 |
输人 |
输出 |
| 受控非 |
$X_{1}$ |
$X_{1} X_{2}$ |
|
$Z_{1}$ |
$X_{2}$ |
|
$Z_{2}$ |
$Z_{1} Z_{2}$ |
|
$X$ |
$Z$ |
|
$Z$ |
$X$ |
| $S$ |
$X$ |
$Y$ |
|
$Z$ |
$Z$ |
|
$X$ |
$X$ |
|
$Z$ |
$-Z$ |
| $Y$ |
$X$ |
$-X$ |
|
$Z$ |
$-Z$ |
| $Z$ |
$X$ |
$-X$ |
|
$Z$ |
$Z$ |
图 10-7 共轭作用下一些常见操作对泡利群元素的变换。受控非门中量子比特 1 是控制,量子比特 2 是数据
习题 $10.37 U Y_{1} U^{\dagger}$ 是什么?
作为利用稳定子形式理解酉变换的一个例子,我们现在考虑 1.3.4 节中介绍的交换电路。为了方便起见,这个电路如图 10-8 所示。考虑 $Z_{1}$ 和 $Z_{2}$ 操作在电路中逻辑门的联合作用下的变化, $Z_{1}$ 的变化路线为 $Z_{1} \rightarrow Z_{1} \rightarrow Z_{1} Z_{2} \rightarrow Z_{2}, Z_{2}$ 的变化路线为 $Z_{2} \rightarrow Z_{1} Z_{2} \rightarrow Z_{1} \rightarrow Z_{1}$ 。类似地,在这个电路下,$X_{1} \rightarrow X_{2}, X_{2} \rightarrow X_{1}$ 。很明显,如果我们取 $U$ 为交换操作,则有 $U Z_{1} U^{\dagger}=Z_{2}$ , $U Z_{2} U^{\dagger}=Z_{1}$ ,对 $X_{1}$ 和 $X_{2}$ 也有类似结果,如图 10-8 所示。证明这意味着此电路实现了 $U$ 则留作习题。
习题10.38 假设 $U$ 和 $V$ 是两量子比特上的西变换,而且它们对 $Z_{1}, Z_{2}, X_{1}, X_{2}$ 的共轭变换都有相同的结果,证明 $U=V$ 。

图 10-8 两量子比特的交换电路
交换电路的例子虽然有趣,但它并没有充分体现稳定子形式确实有用的真实特征,即描述某些类型量子纠缠的能力。前面我们已经看到,稳定子形式可以被用来描述 H门和受控非门,而这些门可以被用来制造纠缠(与 1.3.6节对比)。后面我们将会看到,稳定子形式可以被用来描述一大类纠缠态,包括许多的量子纠错码。
除了 H 门和受控非门,还有哪些逻辑门可以被稳定子形式描述呢?最重要的增补就是相位门,这是一个单量子比特 1 逻辑门,如前所述它的定义是
$$
S=\left[\begin{array}{ll}
1 & 0 \tag{10.90}\\
0 & \mathrm{i}
\end{array}\right]
$$
相位门以共轭形式在泡利矩阵上的作用很容易被计算如下:
$$
\begin{equation*}
S X S^{\dagger}=Y ; \quad S Z S^{\dagger}=Z \tag{10.91}
\end{equation*}
$$
习题 10.39 验证式(10.91)。
实际上,对于一个任意的西变换,如果它将 $G_{n}$ 中的元素变换到 $G_{n}$ 中另外一个元素,则这个西变换可以由阿达玛门,相位门和受控非门构成。根据定义,满足 $U G_{n} U^{\dagger}=G_{n}$ 的 $U$ 的集合被称为 $G_{n}$ 的规范子,记作 $N\left(G_{n}\right)$ 。所以,我们实际上是在说,$G_{n}$ 的规范子可以由阿达玛门,相位门和受控非门构成,因此,阿达玛门,相位门和受控非门经常也被称为规范子逻辑门。这个结果的证明虽然简单,但却很有指导意义,因此留作习题,见习题 10.40 。
定理10.6 假设 $U$ 是一个 $n$ 量子比特上的西变换,而且如果 $g \in G_{n}$ ,则有 $U g U^{\dagger} \in G_{n}$ 。那么 $U$可以由 $O\left(n^{2}\right)$ 个阿达玛门,相位门和受控非门,外加一个可能的全局相位构成。
习题 10.40 按照下面的思路,给出定理 10.6 的归纳证明。
1.证明阿达玛门和相位门可以被用来实现单量子比特上的任意规范子操作。
2.假设 $U$ 是 $N\left(G_{n+1}\right)$ 中的一个 $n+1$ 量子比特逻辑门,而且对 $G_{n}$ 中的元素 $g$ 和 $g^{\prime}$ ,有 $U Z_{1} U^{\dagger}=X_{1} \otimes g$ 和 $U X_{1} U^{\dagger}=Z_{1} \otimes g^{\prime}$ 。定义 $n$ 量子比特上的操作 $U^{\prime}$ 为 $U^{\prime}|\psi\rangle \equiv \sqrt{2}\langle 0| U(|0\rangle \otimes$ $|\psi\rangle)$ 。利用归纳假设,证明图 10-9 中 $U$ 的构造可以用 $O\left(n^{2}\right)$ 个阿达玛门,相位门和受控非门实现。
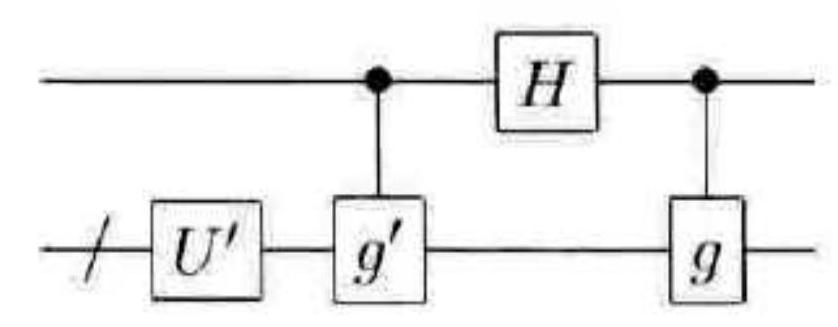
图 10-9 可以证明阿达玛门,相位门和受控非门能生成规范子 $N\left(G_{n}\right)$ 的一种构造
3.证明任意逻辑门 $U \in N\left(G_{n+1}\right)$ ,可以用 $O\left(n^{2}\right)$ 个阿达玛门,相位门和受控非门实现。
我们已经看到,许多有趣的量子逻辑门都在规范子 $N\left(G_{n}\right)$ 中,那么是否存在例外呢?实际上,绝大部分量子逻辑门不在规范子中,其中两个我们特别感兴趣的代表是 $\pi / 8$ 门和 Toffoli 门。假设 $U$ 代表 Toffoli 门,其中量子比特 1 和 2 负责控制,而量子比特 3 是目标;与之前相同,$T$ 依
然代表 $\pi / 8$ 门。不难计算,$\pi / 8$ 门和 Toffoli 门在泡利矩阵下的共轭运算为
$$
\begin{equation*}
T Z T^{\dagger}=Z \quad T X T^{\dagger}=\frac{X+Y}{\sqrt{2}} \tag{10.92}
\end{equation*}
$$
以及
$$
\begin{array}{ll}
U Z_{1} U^{\dagger}=Z_{1} & U X_{1} U^{\dagger}=X_{1} \otimes \frac{I+Z_{2}+X_{3}-Z_{2} X_{3}}{2} \\
U Z_{2} U^{\dagger}=Z_{2} & U X_{2} U^{\dagger}=X_{2} \otimes \frac{I+Z_{1}+X_{3}-Z_{1} X_{3}}{2} \\
U X_{3} U^{\dagger}=X_{3} & U Z_{3} U^{\dagger}=Z_{3} \otimes \frac{I+Z_{1}+Z_{2}-Z_{1} Z_{2}}{2} \tag{10.95}
\end{array}
$$
不幸的是,与只包含阿达玛门,相位门和受控非门的电路相比,使用稳定子形式来分析包含 $\pi / 8$门和 Toffoli 门的电路很不方便。但幸运的是,稳定子编码的编码,解码,错误探测和信息恢复操作,都可以用只属于规范子的逻辑门集合实现,因此对于这种编码的分析来说,稳定子形式是十分方便的。
习题 10.41 通过式(10.95)验证式(10.92)。
10.5.3 稳定子形式中的测量
我们已经看到,一小组西变换量子门可以很方便地用稳定子形式描述,但其实有更多的操作可以实现这一点。实际上,计算基下的测量也可以很容易地用稳定子形式表示。为了说明这一点,假设我们需要完成 $g \in G_{n}$ 描述的测量(如前所述,$g$ 是一个厄米算子,可以当作 2.2 .5 节描述的可观测量)。为了方便,我们可以不失一般性地假设 $g$ 是一个泡利矩阵的乘积,并且没有前置系数 -1 或 $\pm \mathrm{i}$ 。假设系统的状态是 $|\psi\rangle$ ,且有稳定子 $\left\langle g_{1}, \cdots, g_{n}\right\rangle_{\circ}$ 那么在测量的作用下,量子态的稳定子如何变化呢?总共有两个可能性:
1.$g$ 和稳定子的所有生成子对易。
2.$g$ 和稳定子的一个或多个生成元反对易。比如,假设稳定子有生成子 $g_{1}, \cdots, g_{n}, g$ 和 $g_{1}$ 反对易,那么不失一般性我们可以假设 $g$ 和 $g_{2}, \cdots, g_{n}$ 对易。这是因为,如果 $g$ 和这些元素中的某个不对易,比如 $g_{2}$ ,则可知 $g$ 和 $g_{1} g_{2}$ 对易,然后我们将生成子列表中的 $g_{2}$ 用 $g_{1} g_{2}$替代。
在上面第一种情形中,根据下面的论述,$g$ 或 $-g$ 是稳定子的一个元素。实际上,对于每一个稳定子的生成元,有 $g_{j} g|\psi\rangle=g g_{j}|\psi\rangle=g|\psi\rangle$ ,于是 $g|\psi\rangle$ 在 $V_{S}$ 中,即它是 $|\psi\rangle$ 乘以一个系数。因为 $g^{2}=I$ ,我们有 $g|\psi\rangle= \pm|\psi\rangle$ ,所以 $g$ 或 $-g$ 在稳定子中。假设 $g$ 是稳定子 $(-g$ 的情形可以类似讨论),则 $g|\psi\rangle=|\psi\rangle$ ,所以测量 $g$ 将以概率 1 获得测量结果 +1 ,而且并不影响量子态本身,所以稳定子保持不变。
在第二种情形中,当 $g$ 与 $g_{1}$ 反对易,跟其他生成子对易的时候会怎么样呢?注意到 $g$ 有特
征值 $\pm 1$ ,所以对应测量结果 $\pm 1$ 的投影算子分别为 $(I \pm g) / 2$ ,测量概率则为
$$
\begin{align*}
& p(+1)=\operatorname{tr}\left(\frac{I+g}{2}|\psi\rangle\langle\psi|\right) \tag{10.96}\\
& p(-1)=\operatorname{tr}\left(\frac{I-g}{2}|\psi\rangle\langle\psi|\right) \tag{10.97}
\end{align*}
$$
基于事实 $g_{1}|\psi\rangle=|\psi\rangle$ 和 $g g_{1}=-g_{1} g$ ,我们有
$$
\begin{align*}
p(+1) & =\operatorname{tr}\left(\frac{I+g}{2} g_{1}|\psi\rangle\langle\psi|\right) \tag{10.98}\\
& =\operatorname{tr}\left(g_{1} \frac{I-g}{2}|\psi\rangle\langle\psi|\right) \tag{10.99}
\end{align*}
$$
由求迹运算的循环特性,我们可以将 $g_{1}$ 放在求迹运算的右边并且根据 $g_{1}=g_{1}^{\dagger}$ 将它吸收进 $\langle\psi|$ (习题 10.35 ),得到
$$
\begin{equation*}
p(+1)=\operatorname{tr}\left(\frac{I-g}{2}|\psi\rangle\langle\psi|\right)=p(-1) \tag{10.100}
\end{equation*}
$$
因为 $p(+1)+p(-1)=1$ ,可知 $p(+1)=p(-1)=1 / 2$ 。假设测量所得结果为 +1 ,则系统的新状态为 $\left|\psi^{+}\right\rangle \equiv(I+g)|\psi\rangle / \sqrt{2}$ ,对应的稳定子为 $\left\langle g, g_{2}, \cdots, g_{n}\right\rangle$ 。类似地,如果测量结果为 -1 ,则对应的稳定子为 $\left\langle-g, g_{2}, \cdots, g_{n}\right\rangle$ 。
10.5.4 Gottesman-Knill 定理
可以用稳定子描述西操作和测量的事实,可以总结为著名的 Gottesman-Knill 定理。
定理10.7(Gottesman-Knill 定理)假设量子计算中只涉及以下操作:计算基下的状态制备,阿达玛门,相位门,受控非门,泡利门,与泡利群中可观测量对应的测量(计算基下测量是其中的特殊形式),以及基于量子测量结果的经典控制,则这种量子计算可以被经典计算机有效模拟。
实际上我们已经悄悄地证明了 Gottesman-Knill 定理。经典计算机模拟的方法就是对计算中所涉及的各种操作,记录其稳定子的生成子。例如,为了模拟一个阿达玛门,我们只需要更新描述量子态的 $n$ 个生成子。类似地,相位门,受控非门,泡利门和泡利矩阵可观测量对应的测量都可以在经典计算机上用 $O\left(n^{3}\right)$ 步实现模拟。因此,模拟一个包含 $m$ 个操作的量子计算过程,可以在经典计算机上用 $O\left(n^{3} m\right)$ 个操作完成模拟。
Gottesman-Knill 定理凸显了量子计算的微妙特性。它证实,某些量子计算,即使涉及了高度纠缠的量子态,也能被经典计算有效模拟。当然,并不是所有的量子计算(因此,并不是所有类型的量子纠缠)都能被稳定子形式有效描述,但可以描述的确实是很大一类。回顾一些有趣的量子信息处理方案,比如量子隐形传态(1.3.7节)和超密编码(2.3节),能被阿达玛门,受控非门和计算基下测量实现,因此根据 Gottesman-Knill 定理它们可以被经典计算机有效模拟。并且,我们将会看到,一大类量子纠错码也可以用稳定子形式描述。可见,量子纠缠赋予量子计算的,远远不止计算的能力。
习题10.42 利用稳定子形式证明,图 1-13 中的电路如设计的那样,可以远程传输量子比特。注意稳定子形式限制了可以被远程传输的状态,所以在某种意义上这不是远程传输的完整描述,但它确实可以让我们理解远程传输的动态过程。
10.5.5 稳定子编码的构造
稳定子形式是量子纠错码的理想描述方法,本节我们来介绍具体的细节,并展示几类重要的量子编码,包括 Shor 的九量子比特编码,CSS 编码和一个五量子比特编码,后者也是能纠正单量子比特上任何错误的最小规模量子编码。其实,基本的想法非常简单:对于 $G_{n}$ 的一个子群 $S$ ,如果 $-I$ 不在 $S$ 中,并且 $S$ 有 $n-k$ 个独立,互相对易的生成子,$S=\left\langle g_{1}, \cdots, g_{n-k}\right\rangle$ ,则一个 $[n, k]$ 稳定子编码定义为被 $S$ 稳定的子空间 $V_{S}$ ,记作 $C(S)$ 。
编码 $C(S)$ 的逻辑基矢态是什么呢?原则上,给定稳定子 $S$ 的 $n-k$ 个生成子,我们可以选取 $C(S)$ 编码中任意一组规模为 $2^{k}$ 的标准正交基作为逻辑计算基矢态。但实际上,我们可以用一些更有意义的方式系统地选取,其中的一种如下所示。首先,我们选择算子 $\bar{Z}_{1}, \cdots, \bar{Z}_{k} \in G_{n}$使得 $g_{1}, \cdots, g_{n-k}, \bar{Z}_{1}, \cdots, \bar{Z}_{k}$ 形成一个独立,互相对易的集合(我们稍后介绍如何实现这一点),这里 $\bar{Z}_{j}$ 算子起到第 $j$ 个逻辑量子比特上的逻辑泡利算子 $Z$ 的作用。因此,逻辑计算基矢态 $\left|x_{1}, \cdots, x_{k}\right\rangle_{L}$ 被定义为稳定子为
$$
\begin{equation*}
\left\langle g_{1}, \cdots, g_{n-k},(-1)^{x_{1}} \bar{Z}_{1}, \cdots,(-1)^{x_{k}} \bar{Z}_{k}\right\rangle \tag{10.101}
\end{equation*}
$$
的量子态。类似地,我们将 $\bar{X}_{j}$ 定义为共轭操作下,将 $\bar{Z}_{j}$ 变成 $-\bar{Z}_{j}$ ,同时在其他 $\bar{Z}_{i}$ 和 $g_{i}$ 上保持不变的泡利算子的乘积。于是, $\bar{X}_{j}$ 类似于第 $j$ 个逻辑量子比特上的量子非门,而且算子 $\bar{X}_{j}$ 满足 $\bar{X}_{j} g_{k} \bar{X}_{j}^{\dagger}=g_{k}$ ,因此与稳定子的所有生成子对易。同时,不难验证, $\bar{X}_{j}$ 除了和 $\bar{Z}_{j}$ 反对易,还与剩下的所有 $\bar{Z}_{i}$ 对易。
稳定子编码的纠错特性,与它对应的生成子有何关联呢?假设我们用一个稳定子为 $S=$ $\left\langle g_{1}, \cdots, g_{n-k}\right\rangle$ 的 $[n, k]$ 纠错码 $C(S)$ 来编码一个量子态,然后发生了错误 $E_{\circ}$ 。在下面的三阶段分析中,我们将搞清楚,使用 $C(S)$ 可以探测出何种错误,以及何时能恢复。首先,为了获得与这些问题相关的直觉,我们考虑不同类型的错误在编码空间上的作用效果。因为这个阶段是为了获得直觉,所以我们并不提供证明。在第二阶段,根据量子纠错条件,我们提供一个陈述,给出何种错误能被稳定子编码探测和纠正,并且将证明这个陈述。在分析的第三阶段,我们将使用错误征状等概念,给出一个实际可操作的错误探测和信息纠正方案。
假设 $C(S)$ 是一个稳定子编码,并且被噪声 $E \in G_{n}$ 影响。当 $E$ 和所有的稳定子元素反对易时,会发生什么呢?在这种情况下,$E$ 将把编码空间变换到一个正交空间中来,所以这种错误可以通过合适的投影测量探测出来(可能也能纠正)。如果 $E$ 在 $S$ 中,则"错误"$E$ 根本不改变编码空间中任何态,因此不必担心它的影响。所以,真正的危险来自下面的情形,就是 $E$ 与 $S$ 的所有元素对易,但 $E$ 并不在 $S$ 中,也就是对所有 $g \in S$ 都有 $E g=g E$ 。满足对所有 $g \in S$ ,都有 $E g=g E$ 成立的 $E$ 的全体集合,被称为 $S$ 在 $G_{n}$ 里的中心子,记作 $Z(S)$ 。实际上,对于我们关
心的稳定子群 $S$ 来说,中心子实际上与一个我们更熟悉的群相同,即 $S$ 的规范子,记作 $N(S)$ 。 $S$ 的规范子是对所有 $g \in S$ 都有 $E g E^{\dagger} \in S$ 成立的所有 $E \in G_{n}$ 的全体集合。
习题 10.43 对 $G_{n}$ 的任意子群 $S$ ,证明 $E g E^{\dagger} \in S$ 。
习题 10.44 对 $G_{n}$ 的任意不包含 $-I$ 的子群,证明 $N(S)=Z(S)$ 。
基于这些对不同类型噪声算子 $E$ 所带来影响的观察,我们可以建立下面的定理,它实际上就是量子纠错条件(定理10.1)在稳定子编码中的重新表述。
定理10.8(稳定子编码的纠错条件)$S$ 是一个稳定子编码 $C(S)$ 的稳定子。假设 $\left\{E_{j}\right\}$ 是 $G_{n}$的一组算子,并且对所有的 $j$ 和 $k$ ,都有 $E_{j}^{\dagger} E_{k} \notin N(S)-S$ 。则 $\left\{E_{j}\right\}$ 对纠错码 $C(S)$ 来说是一组可纠正错误。
不失一般性,我们可以只考虑 $G_{n}$ 中且满足 $E_{j}^{\dagger}=E_{j}$ 的噪声 $E_{j}$ 。这个情形使得稳定子编码的纠错条件退化为,对所有 $j$ 和 $k, E_{j} E_{k} \notin N(S)-S$ 成立。
证明
假设 $P$ 是到编码空间 $C(S)$ 上的投影算子。对给定 $j$ 和 $k$ ,有两个可能:或者 $E_{j}^{\dagger} E_{k}$ 在 $S$ 中,或者 $E_{j}^{\dagger} E_{k}$ 在 $G_{n}-N(S)$ 中。先考虑第一种情况,因为在 $S$ 中元素的乘法作用下,$P$ 不变,因此有 $P E_{j}^{\dagger} E_{k} P=P$ 。而如果 $E_{j}^{\dagger} E_{k} \in G_{n}-N(S)$ ,则 $E_{j}^{\dagger} E_{k}$ 一定和 $S$ 的某个元素 $g_{1}$ 反对易。假设 $g_{1}, \cdots, g_{n-k}$ 是 $S$ 的一组生成子,则
$$
\begin{equation*}
P=\frac{\prod_{l=1}^{n-k}\left(I+g_{l}\right)}{2^{n-k}} \tag{10.102}
\end{equation*}
$$
根据反对易性,我们有
$$
\begin{equation*}
E_{j}^{\dagger} E_{k} P=\left(I-g_{1}\right) E_{j}^{\dagger} E_{k} \frac{\prod_{l=2}^{n-k}\left(I+g_{l}\right)}{2^{n-k}} \tag{10.103}
\end{equation*}
$$
但是因为 $\left(I+g_{1}\right)\left(I-g_{1}\right)=0$ ,有 $P\left(I-g_{1}\right)=0$ 。因此当 $E_{j}^{\dagger} E_{k} \in G_{n}-N(S)$ ,我们有 $P E_{j}^{\dagger} E_{k} P=$ 0 成立。所以错误集合 $\left\{E_{j}\right\}$ 满足量子纠错条件,是一组可纠正错误。
定理 10.8 的内容和证明是非常漂亮的理论结果,但即使在可行的情况下,它也没有明确告诉我们如何构造具体的纠错操作。为了理解如何做到这一点,假设 $g_{1}, \cdots, g_{n-k}$ 是一个 $[n, k]$ 稳定子编码对应的生成元,并且 $\left\{E_{j}\right\}$ 是一组可纠正错误。我们可以通过依次测量生成子 $g_{1}, \cdots, g_{n-k}$ ,并根据对应的测量结果 $\beta_{1}, \cdots, \beta_{n-k}$ 来获得错误征状,最终实现错误的探测。如果错误 $E_{j}$ 发生,则错误征状将由满足 $E_{j} g_{l} E_{j}^{\dagger}=\beta_{l} g_{l}$ 的 $\beta_{l}$ 给出。如果 $E_{j}$ 是唯一可能造成这种征状的错误算子,则信息纠正可以通过作用 $E_{j}^{\dagger}$ 来实现。当有两种不同的错误 $E_{j}$ 和 $E_{j^{\prime}}$ 对应相同的征状时,即 $E_{j} P E_{j}^{\dagger}=E_{j^{\prime}} P E_{j^{\prime}}^{\dagger}$ ,这里 $P$ 是到编码空间上的投影算子,则只要 $E_{j}^{\dagger} E_{j^{\prime}} \in S$ ,都有 $E_{j}^{\dagger} E_{j^{\prime}} P E_{j^{\prime}}^{\dagger} E_{j}=P$ ,因此在错误 $E_{j^{\prime}}$ 后作用 $E_{j}^{\dagger}$ 是一个纠正错误的方法。可见,对于每一种可能的错误征状,只需要找出对应该征状的任何一个错误 $E_{j}$ ,然后作用一个 $E_{j}^{\dagger}$ 算子即可纠正错误。
定理 10.8 使我们可以为量子编码引人类似经典编码中距离的概念。对一个错误 $E \in G_{n}$ ,我们将它的权重定义为张量积中非单位阵的项的数量。比如,$X_{1} Z_{4} Y_{8}$ 的权重为 $3_{\circ}$ 。一个稳定子编码 $C(S)$ 的距离定义为 $N(S)-S$ 中元素的最小权重。如果 $C(S)$ 是一个距离为 $d$ 的 $[n, k]$ 编码,我们说 $C(S)$ 是一个 $[n, k, d]$ 稳定子编码。根据定理 10.8 ,一个距离至少为 $2 t+1$ 的编码可以纠正 $t$ 个量子比特上的任意错误,这与经典情形相同。
习题 10.45 (纠正定位噪声)假设 $C(S)$ 是一个 $[n, k, d]$ 稳定子编码。使用这种编码,$n$ 个量子比特被用来编码 $k$ 个逻辑量子比特,然后噪声作用在编码数据上。但是,很幸运地,我们被告知只有 $d-1$ 个量子比特被噪声影响,而且被告知这 $d-1$ 个量子比特的精确位置。证明我们可以纠正这些定位噪声的影响。
10.5.6 例子
我们现在给出稳定子编码的一系列例子,这包括之前介绍过的九量子比特 Shor 编码和 CSS编码,但现在是以稳定子形式的角度来介绍。在每个例子中,将定理 10.8 的内容应用在对应的生成子上,我们可以很容易得出这些纠错码的一些特性。基于这些例子,我们还考虑对应的编码电路和解码电路。
三量子比特的比特翻转编码
考虑我们熟悉的三量子比特的比特翻转编码,它被量子态 $|000\rangle$ 和 $|111\rangle$ 张成,因此对应着 $Z_{1} Z_{2}$ 和 $Z_{2} Z_{3}$ 生成的稳定子。通过验证,可知错误集合 $\left\{I, X_{1}, X_{2}, X_{3}\right\}$ 中任何两项的乘积——即 $I, X_{1}, X_{2}, X_{3}, X_{1} X_{2}, X_{1} X_{3}, X_{2} X_{3}$ ——都跟稳定子对应生成子中的至少一项(除了 $I$ ,它在 $S$中)反对易,因此根据定理 $10.8,\left\{I, X_{1}, X_{2}, X_{3}\right\}$ 对具有稳定子描述 $\left\langle Z_{1} Z_{2}, Z_{2} Z_{3}\right\rangle$ 的三量子比特的比特翻转编码来说,是一组可纠正错误。
比特翻转编码的错误探测可以通过测量生成子 $Z_{1} Z_{2}$ 和 $Z_{2} Z_{3}$ 实现。例如,如果错误 $X_{1}$ 发生,则稳定子变成 $\left\langle-Z_{1} Z_{2}, Z_{2} Z_{3}\right\rangle$ ,因此征状测量将给出结果 +1 或者 -1 。类似地,错误 $X_{2}$ 将给出错误征状 -1 和 -1 ,错误 $X_{3}$ 将给出错误征状 +1 和 -1 ,平凡的错误 $I$ 将给出错误征状 +1和 +1 。在每种情形中,信息恢复都可以通过施加一个对应错误的逆操作来实现。对比特翻转编码相关纠错操作的总结,见图 10-10。
| $Z_{1} Z_{2}$ |
$Z_{2} Z_{3}$ |
错误类型 |
操作 |
| +1 |
+1 |
无错误 |
无操作 |
| +1 |
-1 |
比特 3 3翻转 |
翻转比特 3 |
| -1 |
+1 |
比特 1 翻转 |
翻转比特 1 |
| -1 |
-1 |
比特 2 翻转 |
翻转比特 2 |
图 10-10 三量子比特的比特翻转编码的纠错,以稳定子语言描述
当然,关于三量子比特的比特翻转编码,上面简述的纠错程序实际上与早前的描述完全一致。这些因为引人稳定子形式而带来的基于群论的复杂分析是值得的,这在后面复杂的例子上将
变得更明显。
习题 10.46 证明三量子比特的相位翻转编码的稳定子,可以由 $X_{1} X_{2}$ 和 $X_{2} X_{3}$ 生成。
九量子比特 Shor 编码
如图 10-11 所示,Shor 编码的稳定子有八个生成子。对于包含 $I$ 和所有单量子比特错误的错误集,不难验证定理 10.8 的条件是成立的。例如,考虑单量子比特错误 $X_{1}$ 和 $Y_{4}$ ,它们的乘积 $X_{1} Y_{4}$ 与 $Z_{1} Z_{2}$ 反对易,因此不在 $N(S)$ 中。类似地,此错误集中任意两项的乘积或者在 $S$ 中,或者跟 $S$ 中至少一个元素反对易,因此不在 $N(S)$ 中,这显示 Shor 编码可以被用来纠正一个任意的单量子比特错误。
| 名称 |
算子 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| $g_{1}$ |
$Z$ |
$Z$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
|
|
|
|
|
| $g_{2}$ |
$I$ |
$Z$ |
$Z$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
|
|
|
|
|
| $g_{3}$ |
$I$ |
$I$ |
$I$ |
$Z$ |
$Z$ |
$I$ |
$I$ |
$I$ |
$I$ |
|
|
|
|
|
| $g_{4}$ |
$I$ |
$I$ |
$I$ |
$I$ |
$Z$ |
$Z$ |
$I$ |
$I$ |
$I$ |
|
|
|
|
|
| $g_{5}$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$Z$ |
$Z$ |
$I$ |
|
|
|
|
|
| $g_{6}$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$I$ |
$Z$ |
$Z$ |
|
|
|
|
|
| $g_{7}$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$I$ |
$I$ |
$I$ |
|
|
|
|
|
| $g_{8}$ |
$I$ |
$I$ |
$I$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
|
|
|
|
|
| $\bar{Z}$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
|
|
|
|
|
| $\bar{X}$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
|
|
|
|
|
图 10-11 九量子比特 Shor 编码的 8 个生成元,以及逻辑 $Z$ 操作和逻辑 $X$ 操作(是的,它们确实可能是期望的样子颠倒过来)
习题10.47 验证图 10-11 中的生成子可以生成式(10.13)中的两个码字。
习题 10.48 证明操作 $\bar{Z}=X_{1} X_{2} X_{3} X_{4} X_{5} X_{6} X_{7} X_{8} X_{9}$ 和 $\bar{X}=Z_{1} Z_{2} Z_{3} Z_{4} Z_{5} Z_{6} Z_{7} Z_{8} Z_{9}$ 可以充当 Shor 编码中逻辑量子比特上的逻辑 $Z$ 操作和 $X$ 操作。也就是,证明 $\bar{X}$ 和 $\bar{Z}$ 均独立于 Shor 编码的生成子,也都跟它们对易,并且 $\bar{X}$ 和 $\bar{Z}$ 之间反对易。
五量子比特编码
能编码一个量子比特,并且编码后量子态上任意一个单量子比特错误都能被探测和纠正的量子纠错码的大小最小是多少呢?实际上,这个问题的答案是 5 个量子比特(见12.4.3节)。
这种编码的稳定子形式的生成子见图 10-12 。因为此五量子比特编码是最小的能保护单量子比特错误的纠错码,因此可能有人认为这也是最有用的纠错码,但实际上在许多应用中使用 Steane 七量子比特编码更容易些。
习题 10.49 利用定理 10.8 验证五量子比特编码可以纠正任意单量子比特噪声。
| 名称 |
算子 |
|
|
|
|
|
|
|
|
|
| $g_{1}$ |
$X$ |
$Z$ |
$Z$ |
$X$ |
$I$ |
|
|
|
|
|
| $g_{2}$ |
$I$ |
$X$ |
$Z$ |
$Z$ |
$X$ |
|
|
|
|
|
| $g_{3}$ |
$X$ |
$I$ |
$X$ |
$Z$ |
$Z$ |
|
|
|
|
|
| $g_{4}$ |
$Z$ |
$X$ |
$I$ |
$X$ |
$Z$ |
|
|
|
|
|
| $\bar{Z}$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
$Z$ |
|
|
|
|
|
| $\bar{X}$ |
$X$ |
$X$ |
$X$ |
$X$ |
$X$ |
|
|
|
|
|
图 10-12 五量子比特编码的 4 个生成元,以及逻辑 $Z$ 操作和逻辑 $X$ 操作。注意后面 3 个生成元可以通过将第一个往右平移得到
五量子比特编码的逻辑码字为
$$
\begin{align*}
\left|0_{L}\right\rangle=\frac{1}{4} & {[|00000\rangle+|10010\rangle+|01001\rangle+|10100\rangle} \\
& +|01010\rangle-|11011\rangle-|00110\rangle-|11000\rangle \\
& -|111101\rangle-|00011\rangle-|111110\rangle-|01111\rangle \\
& -|10001\rangle-|01100\rangle-|10111\rangle+|00101\rangle] \tag{10.104}\\
\left|1_{L}\right\rangle=\frac{1}{4} & {[|11111\rangle+|01101\rangle+|10110\rangle+|01011\rangle} \\
& +|10101\rangle-|00100\rangle-|11001\rangle-|00111\rangle \\
& -|00010\rangle-|11100\rangle-|100001\rangle-|10000\rangle \\
& -|01110\rangle-|10011\rangle-|01000\rangle+|11010\rangle] \tag{10.105}
\end{align*}
$$
习题10.50 证明五量子比特编码以最大的程度满足量子汉明界,即它使不等式(10.51)的等号成立。
CSS 编码和七量子比特编码
$\operatorname{CSS}$ 编码是稳定子编码的一个极好例子,它清晰地展示了使用稳定子形式,理解量子纠错码的构造可以多么容易。假设 $C_{1}$ 和 $C_{2}$ 分别是指标为 $\left[n, k_{1}\right]$ 和 $\left[n, k_{2}\right]$ 的两个线性经典纠错码,并且 $C_{2} \subset C_{1}$ ,同时 $C_{1}$ 和 $C_{2}^{\perp}$ 都能纠正 $t$ 个错误。定义一个校验矩阵如下
$$
\left[\begin{array}{c|c}
H\left(C_{2}^{\perp}\right) & 0 \tag{10.106}\\
0 & H\left(C_{1}\right)
\end{array}\right]
$$
为了看出这确实定义了一个稳定子编码,我们需要此校验矩阵满足对易性条件 $H\left(C_{2}^{\perp}\right) H\left(C_{1}\right)^{T}=$ 0 ,但是由于假设 $C_{2} \subset C_{1}$ ,我们有 $H\left(C_{2}^{\perp}\right) H\left(C_{1}\right)^{T}=\left[H\left(C_{1}\right) G\left(C_{2}\right)\right]^{T}=0$ 。实际上,一个不难的练习就可以得到,此编码正是 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ ,并且能够纠正任意的 $t$ 量子比特错误。
七量子比特 Steane 编码是 CSS 编码的一个例子,在式(10.83)中我们已经看到它的校验矩阵。
对 Steane 编码来说,编码后的 $Z$ 和 $X$ 算子可以定义为
$$
\begin{equation*}
\bar{Z} \equiv Z_{1} Z_{2} Z_{3} Z_{4} Z_{5} Z_{6} Z_{7} ; \quad \bar{X} \equiv X_{1} X_{2} X_{3} X_{4} X_{5} X_{6} X_{7} \tag{10.107}
\end{equation*}
$$
习题10.51 验证式(10.106)定义的校验矩阵对应 $\operatorname{CSS}$ 编码 $\operatorname{CSS}\left(C_{1}, C_{2}\right)$ 的稳定子,并且利用定理 10.8 证明此编码可以纠正至多 $t$ 个量子比特上的任意错误。
习题 10.52 通过在码字上的直接作用,验证式(10.107)中的算子可以充当逻辑 $Z$ 和 $X$ 操作。
10.5.7 稳定子编码的标准形式
如果我们将编码以标准形式呈现,则对一个稳定子编码来说,逻辑 $Z$ 和 $X$ 算子的构造就容易多了。为了说明是什么标准形式,考虑一个 $[n, k]$ 稳定子编码 $C$ 的校验矩阵:
$$
\begin{equation*}
G=\left[G_{1} \mid G_{2}\right] \tag{10.108}
\end{equation*}
$$
这个矩阵有 $n-k$ 行,交换这个矩阵的行对应着重新标记其中一些生成子,在矩阵的两边交换对应的列则对应着重新标记量子比特,而将两行相加则对应着将生成子相乘。不难看出,当 $i \neq j$时,我们可能总是将生成子 $g_{i}$ 用 $g_{i} g_{j}$ 替代。因此,总是有一个生成元不同但实际上等价的纠错码,它的校验矩阵是 $G_{1}$ 被高斯消去法处理后的矩阵 $G$ ,注意必要时可做一些量子比特的交换:
$$
\begin{array}{c}
\\[-1em] % Adjust vertical space
\overbrace{\phantom{\begin{array}{c}I\\0\end{array}}}^{r} & \overbrace{\phantom{\begin{array}{c}A\\0\end{array}}}^{n-r} & \overbrace{\phantom{\begin{array}{c}B\\D\end{array}}}^{r} & \overbrace{\phantom{\begin{array}{c}C\\E\end{array}}}^{n-r} \\[0.5em] % Space between top labels and matrix
\begin{array}{c} r \\ n-k-r \end{array} \left\{ \right. &
\left[
\begin{array}{cc|cc}
I & A & B & C \\
0 & 0 & D & E
\end{array}
\right]
\end{array} \tag{10.109}
$$
这里,$r$ 是 $G_{1}$ 的秩。接着,通过必要时交换量子比特,对 $E$ 做一个高斯消去法我们得到
$$
\begin{array}{cl}
&
\begin{array}{cccccc}
\overbrace{\phantom{I}}^{r} & \overbrace{\phantom{A_1}}^{n-k-r-s} & \overbrace{\phantom{A_2}}^{k+s} &
\overbrace{\phantom{B}}^{r} & \overbrace{\phantom{C_1}}^{n-k-r-s} & \overbrace{\phantom{C_2}}^{k+s}
\end{array} \\
\begin{array}{r}
r \{ \\
n-k-r-s \{ \\
s \{
\end{array}
&
\left[
\begin{array}{ccc|ccc}
I & A_1 & A_2 & B & C_1 & C_2 \\
0 & 0 & 0 & D_1 & I & E_2 \\
0 & 0 & 0 & D_2 & 0 & 0
\end{array}
\right]
\end{array}
$$
这里最后的 $s$ 个生成子并不能跟最开始的 $r$ 个生成子对易,除非 $D_{2}=0$ ,因此我们可以假设 $s=0$ 。并且,通过行的线性组合,我们也可以设置 $C_{1}=0$ ,因此我们的校验矩阵有如下的形式:
$$
\begin{array}{cl}
&
\begin{array}{cccccc}
\overbrace{\phantom{I}}^{r} & \overbrace{\phantom{A_1}}^{n-k-r} & \overbrace{\phantom{A_2}}^{k} &
\overbrace{\phantom{B}}^{r} & \overbrace{\phantom{0}}^{n-k-r} & \overbrace{\phantom{C}}^{k}
\end{array} \\
\begin{array}{r}
r \{ \\
n-k-r \{
\end{array}
&
\left[
\begin{array}{ccc|ccc}
I & A_1 & A_2 & B & 0 & C \\
0 & 0 & 0 & D & I & E
\end{array}
\right]
\end{array}
$$
这里我们将 $E_{2}$ 和 $D_{1}$ 分别重新标记为 $E$ 和 $D$ 。不难看出,这种处理程序不是唯一的,但是,我们称任意校验矩阵形如式(10.111)的纠错码处于标准形式。
有了量子编码的标准形式,不难定义对应的编码 $Z$ 算子。具体来说,我们需要挑出 $k$ 个独立于生成子,彼此也互相独立的算子,同时这些算子与生成子对易,且彼此也对易。假设我们将这 $k$ 个编码 $Z$ 算子的校验矩阵写作 $G_{z}=\left[F_{1} F_{2} F_{3} \mid F_{4} F_{5} F_{6}\right]$ ,这里所有的矩阵都有 $k$ 行,而对应的列数为 $r, n-k-r, k, r, n-k-r$ 和 $k$ 。我们挑选这些矩阵使得 $G_{z}=\left[000 \mid A_{2}^{T} 0 I\right]$ ,则这些编码 $Z$ 算子稳定子元素之间的对易性,可由等式 $I \times\left(A_{2}^{T}\right)^{T}+A_{2}=0$ 得到。同时,由于这些编码 $Z$算子只包含 $Z$ 算子的乘积,则它们之间也是对易的。编码 $Z$ 算子同稳定子的头 $r$ 个生成子之间互相独立,来自编码 $Z$ 算子不包含 $X$ 项的事实;而与 $n-k-r$ 个生成元的集合之间互相独立,来自这些生成元的校验矩阵包含 $(n-k-r) \times(n-k-r)$ 个单位阵,而编码 $Z$ 算子的校验矩阵没有任何对应项。类似地,我们可以通过 $k \times 2 n$ 校验矩阵[ $0 E^{T} I \mid C^{T} 00$ ]来选出编码 $X$ 算子。
习题 10.53 证明编码 $Z$ 算子彼此独立。
习题10.54 利用上面定义的编码 $X$ 算子的校验矩阵,证明编码 $X$ 算子彼此独立,也独立于生成子;而且编码 $X$ 算子既彼此对易,也与稳定子的生成子对易。 $\bar{X}_{j}$ 与 $\bar{Z}_{j}$ 之外的 $\bar{Z}_{i}$ 也彼此对易,且与 $\bar{Z}_{j}$ 反对易。
作为一个例子,我们现在将 Steane 编码的校验矩阵(式(10.83))转化成标准形式。对这个编码,我们有 $n=7$ 和 $k=1$ ,观察校验矩阵可以看出 $\sigma_{x}$ 部分的秩为 $r=3$ 。通过交换量子比特 1 和 4,3 和 4,6 和 7 ,并且将行 6 加到行 4 ,行 6 加到行 5 ,以及行 4 和行 5 加到行 6 ,矩阵将成为如下的标准形式:
$$
\left[\begin{array}{lllllll|lllllll}
1 & 0 & 0 & 0 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \tag{10.112}\\
0 & 1 & 0 & 1 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 1 & 1 & 0 & 0 & 1 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 & 1 & 0 & 1 \\
0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 0 & 0 & 1 & 0
\end{array}\right]
$$
通过读取 $A_{2}=(1,1,0)$ ,可知编码 $Z$ 算子具有校验矩阵[0000000|1100001],这对应着 $\bar{Z}=$ $Z_{1} Z_{2} Z_{7}$ 。如前所述,量子比特 1 和 4,3 和 4 , 6 和 7 已经被交换,这对应着在原编码中编码 $Z$ 算子可以是 $\bar{Z}=Z_{2} Z_{4} Z_{6}$ 。考虑到式(10.107)显示编码 $Z$ 算子是 $\bar{Z}=Z_{1} Z_{2} Z_{3} Z_{4} Z_{5} Z_{6} Z_{7}$ ,这看来似乎有些费解。但是,注意到这两个"不同的"编码 $Z$ 算子只相差一个因子 $Z_{1} Z_{3} Z_{5} Z_{7}$ ,而这正是 Steane 编码的一个稳定子,因此这两个算子在 Steane 编码上具有同样的效果,前面让人疑惑的地方也就此化解。
习题 10.55 给出 Steane 编码标准形式的 $\bar{X}$ 算子。
习题 $10.56 ~ g$ 是稳定子的一个元素,证明将编码 $X$ 算子或编码 $Z$ 算子分别用它们和 $g$ 的乘积代替,不改变它们在编码上的作用效果。
习题 10.57 给出五量子比特和九量子比特编码标准形式下的校验矩阵。
10.5.8 编码,解码和纠错的量子电路
稳定子编码的一个特征就是它们的结构使得编码,解码和纠错程序的系统性构造成为可能。我们首先描述完成这些任务的一般性方法,然后作为例子给出一些具体的构造方案。考虑一个参数为 $[n, k]$ 的稳定子编码,它的生成元为 $g_{1}, \cdots, g_{n-k}$ ,逻辑 $Z$ 操作为 $Z_{1}, \cdots, \bar{Z}_{k}$ 。
作为量子计算的一个标准化起始态,制备编码后的量子态 $|0\rangle^{\otimes k}$ 并不困难。为此,我们从一个容易制备的量子态,例如 $|0\rangle^{\otimes k}$ 开始,然后依次测量可观测量 $g_{1}, \cdots, g_{n-k}, Z_{1}, \cdots, Z_{k}$ 。根据测量结果的不同,得到的量子态将被稳定子 $\left\langle \pm g_{1}, \cdots, \pm g_{n-k}, \pm Z_{1}, \cdots, \pm Z_{k}\right\rangle$ 稳定,这里符号可以根据测量结果来确定。正如在命题 10.4 的证明中那样,这些生成元和 $\bar{Z}_{j}$ 的符号,也可以通过作用一组泡利算子的乘积来修正,结果就是量子态的稳定子变为 $\left\langle g_{1}, \cdots, g_{n-k}, \bar{Z}_{1}, \cdots, \bar{Z}_{k}\right\rangle$ 。也就是说,量子态被调整为编码后的 $|0\rangle^{\otimes k}$ 。在这个状态被制备之后,我们可以通过在集合 $\bar{X}_{1}, \cdots, \bar{X}_{k}$中选择恰当的操作,再次将其变成任意的编码后计算基下量子态 $\left|x_{1}, \cdots, x_{k}\right\rangle_{\text {。 }}$ 当然,这种编码方案的一个缺点就是它不是西变换。为了得到酉性的编码方案,如同问题 10.3 中介绍的那样,我们可以采用另外一种基于校验矩阵标准形式的方法。如果我们想编码一个未知量子态,也可以如问题 9.4 中介绍的那样,从编码后的 $|0\rangle^{\otimes k}$ 出发系统性地完成。对我们目前的任务来说,制备 $|0\rangle^{\otimes k}$足够了。
对应的解码也是比较容易的。但是,有必要解释为什么对于很多目的,完全的解码是没有必要的。实际上,容错量子计算中的技术,可以直接被用来在编码后的量子态上实现逻辑操作,并不需要解码数据。并且,在这种方式下,计算的输出可以通过作用逻辑 $Z$ 操作直接读出,没有必要先做解码然后做计算基下测量。因此,对我们的目的来说,实现一个全西变换的解码步骤来保护编码后的量子信息并不那么重要。如果因为某种原因这种解码程序确实是我们想要的——比如也许有人正基于量子纠错通过一个有噪声量子信道传递量子信息——则只要再反向运行问题 10.3 中的西变换编码电路即可实现。
稳定子编码的纠错程序已在 10.5 .5 节描述过,它很像编码程序:即只需要依次测量稳定子 $g_{1}, \cdots, g_{n-k}$ ,得到错误征状 $\beta_{1}, \cdots, \beta_{n-k}$ ,接着基于 $\beta_{j}$ 通过经典计算得到所需要的纠错操作 $E_{j}^{\dagger}$ 。
上述搭建编码,解码和纠错电路的关键是要理解如何测量相应的算子。如前所述,这其实是我们已经广泛使用的普通投影测量的一个推广,之前我们的目标是将量子态投影到算子的特征向量上来,以便同时得到投影后的量子态和特征值本身。如果这让你回忆起第 5 章介绍的相位估计算法,那么它不是巧合!在那一章,根据习题 4.34 我们可知,如果有一个逻辑门能实现受控 $M$操作,图 10-13 所示的电路就可以用来实现单量子比特算子 $M$(特征值为 $\pm 1$ )对应的测量。此电路的两个有用版本,可见图 10-14 和图 10-15,它们完成 $X$ 和 $Z$ 测量。
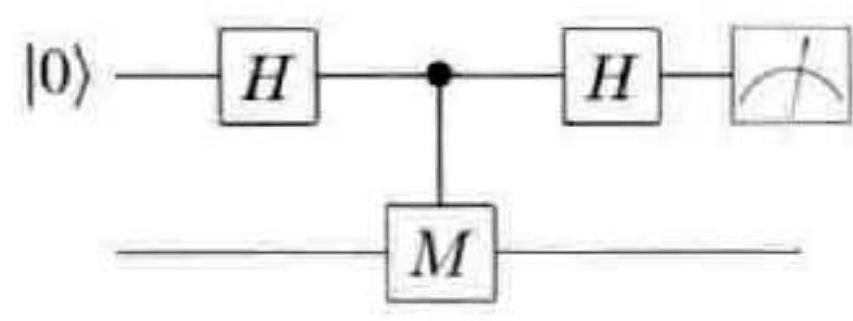
图 10-13 测量一个特征值为 $\pm 1$ 的单量子比特算子 $M$ 的量子电路。上面的量子比特是测量涉及的辅助态,下面的量子比特是被测量的数据

图 10-14 测量 $X$ 算子的量子电路。这里给出了两个等价的电路:左边是通常的构造(如图 10-13 所示),右边是一个有用的等价电路

图 10-15 测量 $Z$ 算子的量子电路。这里给出了两个等价的电路:左边是通常的构造(如图10-13 所示),右边是一个有用的简化电路
当然,这里 $M$ 是单量子比特操作的事实并没有任何特别之处:如果我们将图 10-13 中的第二个量子比特换成一系列量子比特,即 $M$ 变成特征值为 $\pm 1$ 的任意厄米算子,效果依然类似。例如,这样的算子包括一系列泡利算子的乘积,这是稳定子纠错码在编码,解码和纠错过程中经常需要测量的算子。
作为一个具体例子,我们考虑七量子比特 Steane 编码的征状测量和编码程序。为此,从此编码校验矩阵的标准形式出发是一个方便的做法,因为在这个矩阵上我们立刻可以看到需要直接测量的产生子。特别是,如前所述,左边的区块对应 $X$ 生成元,右边的区块对应 $Z$ 生成元,因此图 10-16 所示的电路立刻就是我们所需要的。注意 1 和 0 的分布,对应着左半边逻辑门(测量 $X$ ),以及右半边逻辑门(测量 $Z$ )作用的位置。因此,基于测量结果,通过作用适当的泡利算子乘积,此电路可以被用来实现纠错功能。或者,通过增加一个额外的测量 $\bar{Z}$ ,同时使用之前描述的方法修正产生子的正负号,此电路可以被用来制备编码后的逻辑量子态 $\left|0_{L}\right\rangle_{\circ}$
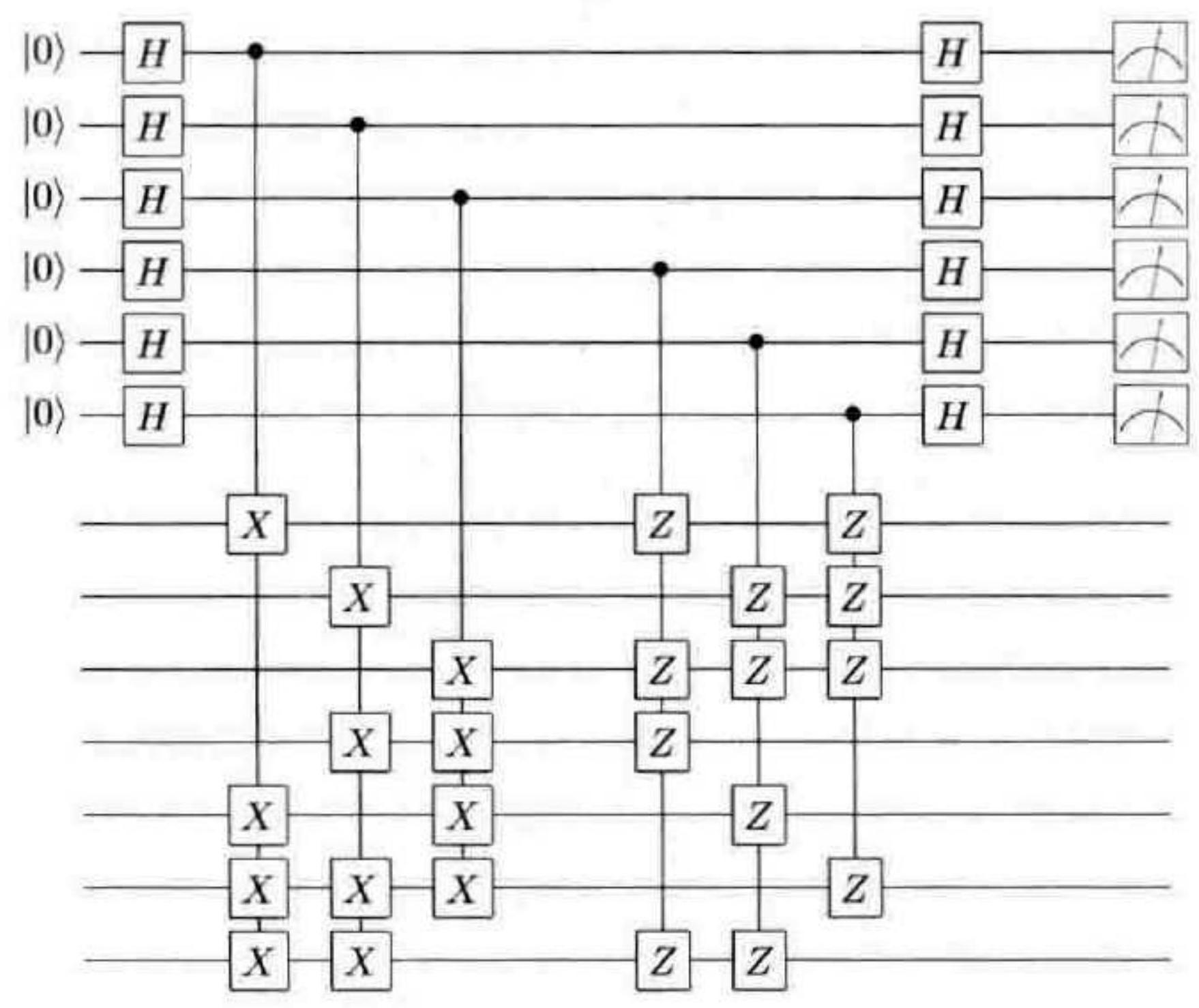
图 10-16 测量 Steane 编码生成元并给出错误征状的量子电路。上面 6 个量子比特是测量用到的辅助态,下面 7 个是编码量子比特
习题 10.58 验证图 10-13~图10-15 中的电路功能与描述的一致,同时验证提到的电路等价性。
习题 10.59 利用图 10-14 和图 10-15 中的电路等价性,证明图 10-16中的征状电路可以被图 10-17
中的电路替代。
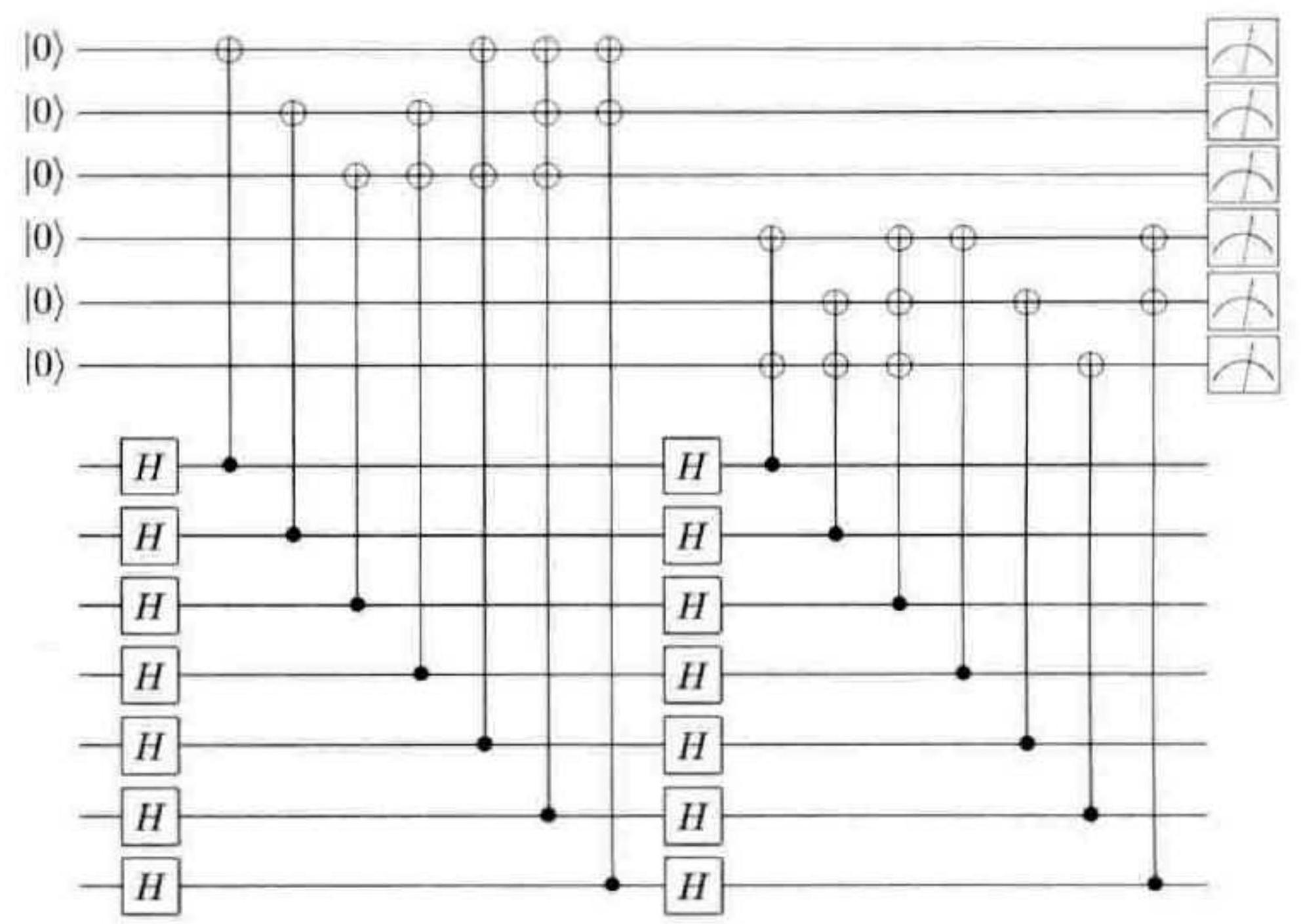
图 10-17 与图 10-16 等价的量子电路
习题10.60 为九量子比特和五量子比特编码构造与图 10-16 类似的征状测量电路。
习题10.61 如果用图 10-16 中电路来实现征状测量,为各种不同可能的错误征状明确描述出对应的信息恢复操作 $E_{j}^{\dagger}$ 。