1Handout 8A
Anum Ahmad 和 Zachary Thayer
COMS 3261 Fall 2024
📜 [原文1]
Anum Ahmad 和 Zachary Thayer
COMS 3261 Fall 2024
这部分是讲义的标题信息。
- Anum Ahmad 和 Zachary Thayer:这是讲义的作者。在学术材料中,通常会在开头标明作者,以明确内容的来源和责任人。
- COMS 3261 Fall 2024:这部分信息指明了该讲义所属的课程和学期。
- COMS 3261:是课程代码,通常代表“Computer Science”(计算机科学)的某个特定课程。这里的课程很可能是关于计算理论、自动机理论或形式语言的。
- Fall 2024:代表2024年秋季学期。这有助于将讲义置于特定的时间背景下,方便学生和老师按学期整理和查找资料。
- 示例1:如果现在是2025年春季学期,一位选修了COMS 3261的学生在复习时看到了这份资料,他能立刻知道这是去年秋季学期的内容,可能会与当前学期的教学内容有些许差异,从而提醒自己注意核对。
- 示例2:一位助教在准备新学期的教学材料时,可以根据这个标识快速找到往年的讲义作为参考,了解课程的大致结构和重点内容。
- 易错点:学生可能会忽略这些信息,认为它们不重要。但实际上,课程内容、重点甚至评分标准都可能随学期和教授的变化而调整。直接使用旧学期的资料而不加核对,可能会导致学习上的偏差。
- 边界情况:如果一份讲义没有标注作者和课程信息,它的可信度和适用范围就会大打折扣。读者无法确定这份材料是否权威,也无法判断它是否适用于自己的学习需求。
这部分是讲义的元数据,提供了作者、课程和学期信息。它为讲义提供了上下文,并帮助读者定位其来源和适用范围。
该部分的目的是为了标准化和归档学术材料。通过明确作者、课程和时间,可以确保内容的来源清晰、可追溯,并方便教学管理和学生学习。
这就像一本书的封面,上面印着书名、作者和出版社。它告诉你这本书是谁写的,关于什么主题,属于哪个系列。
想象一下你收到一份文件,文件的页眉上清晰地写着:“机密文件 | 2024年项目A | 负责人:张三”。你立刻就能明白这份文件的重要性和背景。讲义的标题信息起着类似的作用。
1 图灵机
11 概览/直觉
📜 [原文2]
图灵机(Turing Machine)是如此强大,以至于它可以模拟任何其他“合理的”计算模型。以下是与我们之前较弱的模型相比,一些值得记住的关键变化。
- 无限纸带:在标准模型中,我们将输入写在纸带上,随后是无限数量的空格符。这给了我们无限内存!当直观地考虑一个图灵机是否可以解决某个问题时,记住我们可以访问内存可以使问题变得简单(例如,检查一个字符串是否包含恰好 67 个 1 的问题:直觉上我们知道这可以通过在每次处理一个 1 时递增计数,然后检查该计数是否等于 67 来完成)。
- 读/写能力:除了读取,我们现在还可以写入。写入的能力解锁了执行计算和存储中间结果的能力。(另一种直观考虑一种语言是否可以由图灵机 判定的方法是询问 Python 程序是否可以解决它)。
- 不受限制的移动:带头可以向左和向右移动,允许图灵机多次访问纸带上的任何位置。
这部分内容介绍了图灵机的核心概念和它相较于之前学习的计算模型(如有限自动机DFA/NFA、下推自动机PDA)的强大之处。
- 核心论点:图灵机是一种极其强大的计算模型,它可以模拟任何其他“合理的”计算模型。这被称为邱奇-图灵论题(Church-Turing Thesis)的通俗说法。这个论题指出,任何能被算法解决的计算问题,都能被图灵机解决。换句话说,图灵机定义了“可计算”的上限。
- 关键变化(与弱模型的对比):
- 无限纸带 (Infinite Tape):这是图灵机最核心的特征之一。
- 之前的模型:有限自动机(DFA/NFA)几乎没有内存(只有当前状态),下推自动机(PDA)有一个栈(stack),但访问方式受限(只能访问栈顶)。
- 图灵机:拥有一个纸带(tape),这个纸带在概念上是向右无限延伸的。纸带被划分为一个个的格子,每个格子可以存储一个符号。输入字符串被放置在纸带的起始部分,后面跟着无限个空白符号(blank symbol, 通常记为 _ 或 ⊔)。
- 意义:无限纸带等同于无限内存。这使得图灵机可以存储和处理任意数量的信息,不再像DFA那样受限于有限的状态,也不像PDA那样受限于栈的后进先出结构。
- 直觉应用:因为有了无限内存,很多看似复杂的问题变得直观上可解。例如,要检查字符串w中是否恰好有67个'1'。对于DFA来说,如果状态数量少于67,是无法完成这个任务的(需要68个状态来计数0到67)。但对于图灵机,我们可以简单地在纸带的某个地方开辟一个“计数区”,每当读写头在输入区读到一个'1',就去计数区将一个二进制数加一。最后,我们只需检查计数区的值是否为67。
- 读/写能力 (Read/Write Capability):
- 之前的模型:DFA/NFA和PDA的读头只能读取输入,不能修改。
- 图灵机:它的带头(tape head)不仅可以读取当前格子上的符号,还可以写入一个新的符号来覆盖它。
- 意义:写入能力是实现“计算”的关键。它允许图灵机在纸带上进行草稿运算、标记已处理过的部分、存储中间结果。例如,在做加法 a+b 时,可以把 a 和 b 写在纸带上,然后通过一系列的擦除和写入操作,最终将结果 a+b 呈现在纸带上。
- 类比:将图灵机看作一个Python程序。Python程序可以读取变量的值,也可以修改变量的值(x = x + 1)。这种读写能力是所有现代计算机的基础。因此,一个判断问题能否被图灵机判定的直观方法是:你能不能写一个Python程序来解决它?如果能(并且保证程序对任何输入都会停止),那么这个问题就是图灵机可判定的。
- 不受限制的移动 (Unrestricted Movement):
- 之前的模型:DFA/NFA/PDA的读头通常只能单向移动(从左到右)。
- 图灵机:带头在每一步操作后,可以选择向左(L)或向右(R)移动一个格子。
- 意义:双向移动意味着图灵机可以反复扫描输入、回顾之前处理过的内容。这对于需要多次访问数据的算法至关重要。例如,在判断一个字符串是否是回文 ww^R 时,图灵机可以先读取第一个字符,移动到字符串末尾,检查最后一个字符是否匹配,然后回到第二个字符,再移动到倒数第二个字符,如此反复,直到检查完整个字符串。
- 无限纸带示例:假设我们要判断一个数是否是质数。输入是这个数的二进制表示,比如111(代表7)。
- 图灵机可以将111复制到纸带的另一部分。
- 然后在旁边开始写下10(2),尝试用111除以10。它可以反复从111中减去10,看余数是否为0。
- 如果余数不为0,它就擦掉10,写上11(3),再重复除法过程。
- 这个过程需要大量的存储空间来记录当前的除数、被减数、商和余数,无限纸带保证了无论输入的数有多大,总有足够的空间进行这些计算。
- 读/写能力示例:我们要计算2+3,输入在纸带上是11_111(用1的数量表示数字)。
- 图灵机的带头从左到右扫描,找到第一个_。
- 它将这个_写入一个1。纸带变为111_11。
- 然后向右移动,找到最后一个1。
- 将这个1写入一个_(即擦除它)。纸带变为111_1_。
- 现在纸带的开头是11111_,也就是5。通过读写操作,我们完成了加法。
- 不受限制的移动示例:判断字符串0110是否是回文。
- 带头在最左边的0,读取并将其写入一个特殊符号X,记住读的是0。纸带: X110。
- 带头一直向右(R)移动,直到遇到第一个空白符号_。
- 然后向左(L)移动一格,到达最右边的0。
- 检查这个符号是否与第一步记住的0匹配。匹配。
- 将这个0也写入X。纸带: X11X。
- 带头一直向左(L)移动,直到遇到第一个X。
- 然后向右(R)移动一格,到达1。读取并将其写入Y,记住读的是1。纸带: XY1X。
- 重复上述过程,向右找到X,再向左一格到达1,匹配成功,写入Y。纸带: XYYX。
- 当图灵机发现所有符号都被标记过,且每次都匹配成功,它就知道这是个回文。这个过程需要带头在纸带上反复来回移动。
- 无限不等于瞬时:无限纸带不意味着图灵机可以一步访问到无穷远的位置。带头每次只能移动一格,访问遥远的位置需要相应的时间。
- “合理的计算模型”:这个词组比较模糊,邱奇-图灵论题本身是一个未经数学证明的论题(因为它试图形式化“算法”这个直觉概念),但至今未发现反例,被计算机科学界广泛接受。
- Python程序类比的局限:虽然Python程序是很形象的类比,但一个真实的Python程序运行在有限内存的计算机上。图灵机是一个理论模型,拥有真正的无限内存。此外,不是所有Python程序都会停机,这对应了图灵机的停机问题。一个能保证在所有输入上都终止的程序才对应一个判定器(Decider)。
本节介绍了图灵机作为一种计算模型,其强大之处在于三个核心特性:无限纸带(无限内存)、读/写能力(执行计算和存储中间结果)和不受限制的移动(反复访问数据)。这三者结合,使得图灵机能够模拟所有已知的计算过程,成为定义“可计算性”的理论基石。
本节的目的是从宏观和直觉的层面,建立学生对图灵机基本概念和能力的理解。通过与之前学过的较弱模型(如DFA)进行对比,突出其在内存、操作和移动上的革命性提升,为后续学习图灵机的形式化定义和具体应用打下基础。
想象一个工人(带头)站在一条无限长的传送带(纸带)前。传送带上有一个个格子,放着写有符号的卡片。工人有一个小本子(内部状态),上面记录着当前要做的事情。他每次可以:
- 看一眼面前格子里的卡片上写的什么符号(读)。
- 根据小本子上的指令和卡片上的符号,拿出笔,擦掉卡片上的符号,写上一个新的(写)。
- 同样根据指令,让传送带向左或向右移动一格(移动)。
- 翻到小本子的下一页,更新要做的事情(状态转移)。
这个工人可以完成任何你写在小本子上的明确指令集(算法)。
想象你在用一支铅笔和一块橡皮在一张无限长的方格纸上做数学题。你可以读取任何格子里的数字,用橡皮擦掉,再用铅笔写上新的数字。你可以随意移动你的视线到纸上的任何地方。这张纸就是纸带,你的眼睛和手就是带头,你的大脑就是有限状态控制器。拥有这样的工具,你可以执行任何你知道步骤的计算过程,比如长除法、开方等等,无论数字有多大。
12 示例
📜 [原文3]
我们从图灵机的形式化定义开始。我们说 M 是一个图灵机,如果它可以被写为一个 7-元组
- Q= 有限状态集
- $\Sigma=$ 有限字母表
- $\Gamma=$ 纸带字母表($\Sigma$ 连同空白符号以及可能出现的其他特殊符号)
- $\delta: Q \times \Gamma \rightarrow Q \times \Gamma \times\{L, R\}$ 转移函数
- $q_{0}=$ 起始状态
- $q_{a c c}=$ 接受状态
- $q_{\text {rej }}=$ 拒绝状态
为了看一个形式化给出的图灵机示例,令 $L=\left\{w \in\{0,1\}^{*}\right.$ : w 包含 1$\}$。我们构造一个识别此语言的图灵机 M 如下:
- $\mathrm{Q}=\left\{q_{0}, q_{a c c}, q_{r e j}\right\}$
- $\Sigma=\{0,1\}$
- $\Gamma=\left\{\Sigma \cup \_\right\}$
- $q_{0}, q_{a c c}, q_{r e j}$ 已给出
- $\delta\left(q_{0}, 0\right)=\left(q_{0}, 0, R\right), \delta\left(q_{0}, 1\right)=\left(q_{a c c}, 1, L\right), \delta\left(q_{0}, \iota\right)=\left(q_{r e j}, \iota, R\right)$
你看明白这个图灵机是如何工作的吗?本质上,一旦我们在输入上看到一个 1 并达到接受状态,我们就能使图灵机“停机”。
我们现在给出一个更复杂的示例:令 $A=\left\{0^{2^{n}}: n \geq 0\right\}$。我们构造一个判定 A 的图灵机 M 如下:$\left\{Q, \Sigma, \Gamma, \delta, q_{1}, q_{a c c}, q_{r e j}\right\}$
- $\mathrm{Q}=\left\{q_{1}, q_{2}, q_{3}, q_{4}, q_{5}, q_{a c c}, q_{r e j}\right\}$
- $\Sigma=\{0\}$
- $\Gamma=\{0, X, \_\}$
- 起始状态是 $q_{1}$,
- $q_{a c c}$ 如前所述给出
- $q_{\text {rej }}$ 如前所述给出
- 我们用状态图给出转移函数:
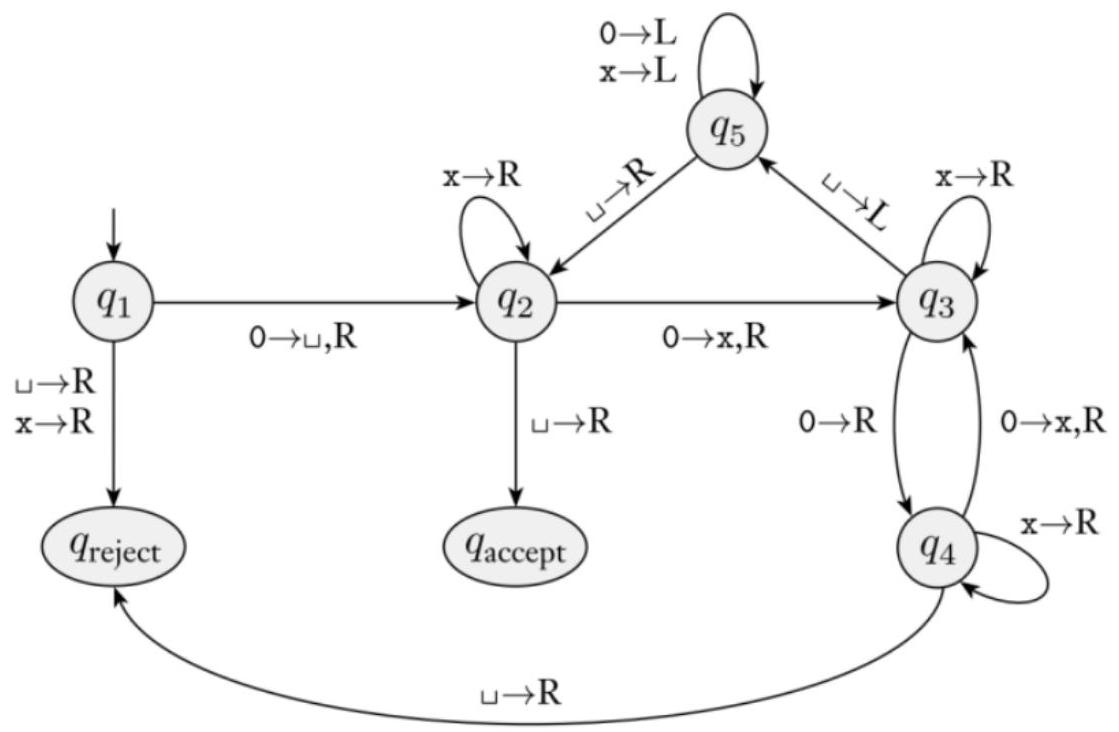
我们可以按以下方式解释这个形式化的转移图:如果字符串为空,$q_{1}$ 拒绝它。否则,在第一个零处放置一个空格并移动到状态 $q_{2}$。从那里开始,当它横跨字符串时,状态在勾销 0 和保留它们为空白之间切换。如果 0 的个数是偶数,它最终会到达 $q_{3}$ 并通过 $q_{5}$ 向左穿行到 $q_{2}$,在那里重复该过程。另一方面,如果个数是奇数(除了 1 之外),它将最终到达 $q_{4}$ 并拒绝。
那么 M 识别(实际上是判定!)L。
正如我们所见,这种构造图灵机的方法非常繁琐,所以我们通常只给出实现级或高层描述。实现级描述是一种更高程度的形式化,我们仍然解释我们希望读/写头在输入纸带上做什么,但我们不给出显式的 7-元组,并且使用更多的英语句子。这里有一个这样的例子:
令 A 定义如上;我们给出判定 A 的图灵机 M 的实现级描述如下——在输入 w 上:
- 在纸带上从左到右扫过,勾销每隔一个 0
- 如果在第 1 阶段我们发现纸带上只有一个 0,接受。
- 如果在第 1 阶段纸带包含奇数个零,且数量大于 1,拒绝。
- 将带头返回到纸带左端。
- 回到步骤 1。
备注。应当注意,对于实现级描述,人们也可以使用非确定性图灵机或多带图灵机。我们在第 2 节中展开讨论这些模型。
最后,对图灵机最不正式的描述是“高层描述”,其中我们使用算法呈现我们希望图灵机如何行动,并且我们不考虑读/写头应该如何在输入纸带上行动。以下是此类示例:
回到我们上面定义的相同语言 A,判定器 M 的高层描述将是——在输入 $w$ 上:
- 检查 w 是否具有 $0^{2^{n}}$ 的形式(对于某个 n)。
- 如果检查暗示 w 具有正确的形式,接受。否则,拒绝。
这部分通过三个层次的描述(形式化定义、实现级描述、高层描述)来举例说明如何构造和理解图灵机。
1.2.1 形式化定义
首先,文章给出了图灵机的7-元组形式化定义。这是描述一个图灵机最精确、最底层的方式。
- $Q$ (有限状态集):图灵机的“大脑”可以处于的有限个状态之一。
- $\Sigma$ (有限字母表):输入字符串允许使用的符号集合。它不包含空白符号。
- $\Gamma$ (纸带字母表):纸带上允许出现的所有符号的集合。它必须包含输入字母表$\Sigma$和空白符号_。它还可以包含其他用于计算的辅助符号(例如标记'X')。所以 $\Sigma \subseteq \Gamma$ 且 _ $\in \Gamma$。
- $\delta$ (转移函数):这是图灵机的“程序”或“指令集”。它告诉图灵机在某个特定状态(来自$Q$)下,读取到纸带上的某个特定符号(来自$\Gamma$)时,应该做什么。其输出是一个三元组:
1. 要转移到的新状态(来自$Q$)。
2. 要写入纸带的新符号(来自$\Gamma$)。
3. 带头的移动方向(L代表向左,R代表向右)。
- $q_0$ (起始状态):图灵机开始运行时所处的初始状态。
- $q_{acc}$ (接受状态):一个特殊的状态。一旦进入此状态,图灵机立即停机并接受输入字符串。
- $q_{rej}$ (拒绝状态):另一个特殊的状态。一旦进入此状态,图灵机立即停机并拒绝输入字符串。
1.2.2 示例1:识别包含'1'的字符串
- 语言 $L = \{w \in \{0,1\}^* \mid w \text{ 包含 } 1\}$
- 目标:构造一个图灵机 M,只要输入字符串中有一个'1',就接受;如果扫描完整个字符串都没有'1',就拒绝。
- M 的构造:
- $Q = \{q_0, q_{acc}, q_{rej}\}$:只有三个状态:起始、接受、拒绝。
- $\Sigma = \{0,1\}$:输入只能是0和1。
- $\Gamma = \{0, 1, \_\}$:纸带上可以有0, 1或空白符号。
- $q_0$ 是起始状态。
- 转移函数 $\delta$ 的解释:
- $\delta(q_0, 0) = (q_0, 0, R)$:在起始状态$q_0$读到'0',保持在$q_0$状态,把'0'写回(相当于没变),然后带头向右移动,继续寻找'1'。
- $\delta(q_0, 1) = (q_{acc}, 1, L)$:在起始状态$q_0$读到'1',任务完成!立即转移到接受状态$q_{acc}$,把'1'写回,带头向左移动(向左或向右都行,因为已经要停机了)。
- $\delta(q_0, \_) = (q_{rej}, \_, R)$:在起始状态$q_0$读到空白符号_,这说明已经扫描完了整个输入字符串,但一个'1'都没找到。所以转移到拒绝状态$q_{rej}$。
- 工作流程:图灵机从左到右扫描字符串。遇到'0'就继续向右。一旦遇到'1',就立刻进入接受状态并停机。如果直到字符串末尾(读到_)都没遇到'1',就进入拒绝状态并停机。
- “停机”的意义:进入 $q_{acc}$ 或 $q_{rej}$ 意味着计算结束。对于这个例子,机器总是在有限步内停机,所以它是一个判定器(Decider)。
1.2.3 示例2:识别语言 $A = \{0^{2^n} \mid n \ge 0\}$
这个语言包含的字符串是长度为1, 2, 4, 8, 16, ... (即2的幂)的'0'串。
这是一个更复杂的例子,展示了图灵机如何进行实际的计算。
- 形式化描述(状态图):这个状态图非常复杂,但其核心思想是反复“减半”字符串的长度,检查每次减半是否都能整除。
- $q_1$:起始状态。
- 如果输入是空(读到_),拒绝。这不是2的幂。($n \ge 0$, $2^0=1$)。
- 如果读到'0',它会将其替换为_(原文描述为“放置一个空格”,但通常用一个特殊符号如'X'更好,这里可能为了简化)。然后移动到$q_2$。这处理了$n=0$的情况(输入"0",长度为1),但图似乎指向一个更复杂的逻辑。让我们遵循下一个更高层次的描述来理解。
- 实现级描述 (Implementation-Level Description):这是一种用自然语言和算法步骤来描述图灵机行为的方式,比形式化定义更易读。
- 算法思想:一个数是2的幂,当且仅当它可以被2反复整除,直到结果为1。在这个过程中,每一步的被除数都必须是偶数(除了最后得到1)。对于字符串来说,“长度除以2”就对应于“勾销掉一半的0”。
- 步骤分解:
1. “在纸带上从左到右扫过,勾销每隔一个 0”: 这一步是在检查'0'的数量是否是偶数。它会标记第一个'0',跳过第二个,标记第三个,以此类推。
- 比如输入0000 (长度4):
- 第一次扫描:勾销第1个和第3个0,变成X0X0。
2. “如果在第 1 阶段我们发现纸带上只有一个 0,接受。”: 这是算法的终止条件。如果经过若干次“减半”后,只剩下一个'0',说明原始长度是2的幂。
- 比如输入0000:第一轮后剩下2个0(未被勾销的)。第二轮扫描X0X0,勾销掉第一个未勾销的0,只剩下1个0。此时再进行下一轮扫描时,会发现只剩一个0,于是接受。
3. “如果在第 1 阶段纸带包含奇数个零,且数量大于 1,拒绝。”: 如果'0'的个数是奇数(且不为1),那么它肯定不是2的幂。例如,输入000(长度3),第一次扫描就会发现有奇数个0,直接拒绝。
4. “将带头返回到纸带左端。”: 准备进行下一轮“减半”。
5. “回到步骤 1。”: 重复这个过程。
- 这个算法为什么能工作:
- $w = 0^8$:
- Round 1: 扫描8个0,勾销4个,剩下4个。
- Round 2: 在剩下的4个0里,勾销2个,剩下2个。
- Round 3: 在剩下的2个0里,勾销1个,剩下1个。
- Round 4: 扫描发现只剩下1个0,接受。
- $w = 0^6$:
- Round 1: 扫描6个0,勾销3个,剩下3个。
- Round 2: 扫描剩下的3个0,发现是奇数个,拒绝。
1.2.4 高层描述 (High-Level Description)
这是最抽象的描述,基本上就是用一句话来描述算法的目标,完全不关心图灵机的具体实现细节。
- 描述: “在输入 $w$ 上:1. 检查 w 是否具有 $0^{2^{n}}$ 的形式。2. 如果是,接受。否则,拒绝。”
- 意义: 这种描述在讨论可计算性理论(computability theory)时非常有用,因为它让我们专注于问题本身是否可计算,而不是陷入实现的泥潭。当我们说一个问题是可判定的,我们通常指的是存在一个这样高层描述的算法,并且我们相信它可以被一个图灵机实现。
- $$ M=\left(Q, \Sigma, \Gamma, \delta, q_{0}, q_{a c c}, q_{r e j}\right) $$
- M: 代表一个图灵机。
- Q: (Finite set of states) 这是一个集合,包含了图灵机所有可能的状态,例如 $\{q_0, q_1, q_{scan}, q_{rewind}, q_{acc}, q_{rej}\}$。集合是有限的,这是“有限状态控制”部分的体现。
- $\Sigma$: (Input alphabet) 输入字母表,一个符号的有限集合。例如,对于二进制字符串,$\Sigma = \{0, 1\}$。
- $\Gamma$: (Tape alphabet) 纸带字母表,一个符号的有限集合。它包含输入字母表中的所有符号,以及空白符号_,可能还有其他用于计算的辅助符号。例如,$\Gamma = \{0, 1, X, Y, \_\}$。
- $\delta$: (Transition function) 转移函数。它的定义域是 $Q \times \Gamma$,值域是 $Q \times \Gamma \times \{L, R\}$。
- $Q \times \Gamma$: 表示一个“状态-符号”对。例如,(当前状态, 当前带头下读取的符号)。
- $Q \times \Gamma \times \{L, R\}$: 表示一个“状态-符号-方向”三元组。例如,(下一个状态, 要写入的符号, 带头移动方向)。
- 整个函数 $\delta(q, a) = (q', b, D)$ 的意思是:当图灵机处于状态 $q$ 并且带头读取到符号 $a$ 时,它应该将状态变为 $q'$,在当前纸带位置写入符号 $b$,然后将带头向方向 $D$(L或R)移动一格。
- $q_0 \in Q$: (Start state) 起始状态,是 $Q$ 中的一个特定状态。
- $q_{acc} \in Q$: (Accept state) 接受状态,是 $Q$ 中的一个特定状态。
- $q_{rej} \in Q$: (Reject state) 拒绝状态,是 $Q$ 中的一个特定状态。$q_{acc}$ 和 $q_{rej}$ 是不同的状态。
- 示例1的数值示例 (语言 L):
- 输入 w = 00:
- 初始格局: (q0)00_ (带头在第一个0上)
- $\delta(q_0, 0) = (q_0, 0, R)$. 纸带不变, 带头右移。格局: 0(q0)0_
- $\delta(q_0, 0) = (q_0, 0, R)$. 纸带不变, 带头右移。格局: 00(q0)_
- $\delta(q_0, \_) = (q_{rej}, \_, R)$. 遇到空白, 转移到拒绝状态。格局: 00_(q_rej) -> 停机并拒绝。
- 输入 w = 010:
- 初始格局: (q0)010_
- $\delta(q_0, 0) = (q_0, 0, R)$. 右移。格局: 0(q0)10_
- $\delta(q_0, 1) = (q_{acc}, 1, L)$. 遇到'1', 转移到接受状态。格局: (q_acc)010_ -> 停机并接受。
- 示例2的数值示例 (语言 A) (使用实现级描述):
- 输入 w = 0000 (长度4, $2^2$):
- 第1轮:
- 从左到右扫描,勾销每隔一个0。纸带变为 X0X0。剩下2个有效'0'。
- 2不等于1,也不是奇数>1。
- 带头返回左端。
- 第2轮:
- 从左到右扫描剩下的'0'。勾销第一个遇到的有效'0' (即原来第二个0)。纸带变为 XXY0 (假设用Y表示第二轮的勾销)。现在只剩下1个有效'0'。
- 带头返回左端。
- 第3轮:
- 从左到右扫描,发现只剩下1个'0'。根据规则2,接受。
- 输入 w = 000 (长度3, 非2的幂):
- 第1轮:
- 从左到右扫描,发现有3个'0'。根据规则3(奇数个零且数量大于1),拒绝。
- 形式化定义的繁琐性:正如文中所说,为哪怕是中等复杂的语言写出完整的7-元组定义都非常困难且容易出错。这就是为什么我们更常用实现级或高层描述。
- 识别(Recognize) vs 判定(Decide):
- 一个图灵机 M 识别一个语言 L,如果对于任何在 L 中的字符串 $w$,M 都会接受。对于不在 L 中的字符串 $w$,M要么拒绝,要么永不停机(无限循环)。
- 一个图灵机 M 判定一个语言 L,如果它识别 L,并且对于所有输入字符串(无论在不在 L 中),M 最终都会停机(即进入接受或拒绝状态)。
- 判定器是一种行为更好的识别器。示例1和示例2中的图灵机都是判定器。
- 空白符号的处理:输入字符串的右边是无限的空白符号。图灵机需要正确处理何时停止扫描。同时,带头也可以向左移动到输入串的左边,那里也是无限的空白符号(在某些定义中是这样,在另一些定义中,向左移出左边界会导致停机或保持原地不动)。
- 高层描述的风险:高层描述非常方便,但也可能隐藏了实现的复杂性。一个看似简单的步骤(如“检查w是否是质数”)可能需要一个非常复杂的图灵机子程序。在证明可判定性时,必须确保高层描述中的每一步都是一个可判定的过程。
本节通过三个不同抽象层次的例子,展示了如何描述和理解图灵机。
- 形式化定义(7-元组)是最精确但最繁琐的。
- 实现级描述(算法步骤+纸带操作)在可读性和精确性之间取得了很好的平衡,是设计和交流图灵机算法的常用方式。
- 高层描述(纯算法思想)最简洁,适用于理论探讨,但需要确保其背后的操作是可计算的。
这些例子说明了图灵机不仅能做简单的模式匹配,还能执行复杂的算术和逻辑运算。
本节旨在将上一节介绍的图灵机抽象概念具体化。通过具体的例子,学生可以:
- 学会如何阅读和解释图灵机的形式化定义和状态图。
- 理解不同抽象层次(形式化、实现级、高层)描述图灵机的优缺点和适用场景。
- 初步掌握设计简单图灵机算法的思路,特别是利用纸带进行读写操作来实现计数和变换等功能。
描述一个图灵机就像写菜谱:
- 高层描述:“做一道番茄炒蛋。”(只说目标)
- 实现级描述:“1. 准备两个鸡蛋和三个番茄。2. 将鸡蛋打散,番茄切块。3. 热锅倒油,先炒鸡蛋,盛出。4. 再倒油,炒番茄,加入鸡蛋翻炒,加盐调味。”(给出步骤,但省略细节)
- 形式化定义:“1. 左手拿起鸡蛋,与碗边呈90度角,以每秒0.5米的初速度撞击,重复两次。2. 右手持筷子,以每分钟120圈的角速度搅拌碗中液体,持续30秒...”(给出每一步极其精确、无歧义的指令)
在图灵机的语境下,我们大部分时间使用“实现级描述”就足够了。
想象一下,语言 $A = \{0^{2^n}\}$ 的判定过程就像一个严格的工匠在检查一堆木棍。
- 输入:一捆长度为 $k$ 的木棍($k$个0)。
- 工匠的规则 (算法):
- 他把木棍排成一排,拿出粉笔,给每隔一根木棍画上标记。
- 画完后,他数一下没画标记的木棍。
- 如果数量是奇数(而且不止一根),他立刻把整捆木棍扔掉(拒绝)。
- 如果只剩下一根没画标记的木棍,他满意地点点头,收下这捆木棍(接受)。
- 如果剩下偶数根,他把所有画了标记的木棍扔掉,对剩下的木棍重复第一步。
这个过程不断地将木棍数量减半,只有最初数量是2的幂的木棍才能通过所有轮次的筛选,最终剩下一根。
2 图灵机的两种变体
📜 [原文4]
虽然标准图灵机是一个强大的模型,但存在几种变体,它们提供了替代视角,但在计算能力上是等价的。即以下几种:
这部分引出了图灵机的变体模型。核心思想是,我们可以对标准图灵机(单纸带,确定性)的结构进行一些修改,例如增加更多的纸带或引入非确定性。然而,一个惊人的结论是,这些变体虽然在设计算法时可能更方便、更直观,但它们在“能解决什么问题”这个根本层面上,其计算能力与最基础的标准图灵机是等价的。这意味着,任何一个多带图灵机能解决的问题,我们总能构造一个单带图灵机来解决它(尽管可能慢得多);反之亦然。这进一步加强了邱奇-图灵论题的地位,表明“可计算性”这个概念是相当稳健的,不依赖于模型的具体细节。
本段作为引言,指出即将讨论的图灵机变体(如多带图灵机、非确定性图灵机)在计算能力上与标准图灵机等价,它们的主要价值在于提供了更灵活和方便的算法设计工具。
为了引入多带图灵机和非确定性图灵机这两个重要的变体模型。预先声明它们与标准模型计算能力等价,可以帮助学生将注意力集中在这些变体如何简化问题求解上,而不是担心它们是否定义了一种新的、更强的计算类型。
这就像比较不同型号的计算器。一个基础款计算器只有加减乘除。一个科学计算器多了三角函数和对数功能。一个编程计算器还能处理进制转换。虽然科学计算器和编程计算器在按键上更方便,但理论上,只要有足够的时间和纸张,你可以用最基础的加减乘除来模拟出三角函数和对数运算。它们在根本的“数学计算能力”上是等价的,方便性不同而已。图灵机的变体也是如此。
想象一个厨师(标准图灵机)只有一个灶台和一口锅。他当然可以做出复杂的宴席,但可能需要频繁地洗锅、腾出灶台,过程很繁琐。现在给他配备一个拥有多个灶台和多口锅的豪华厨房(多带图灵机)。他可以同时炖汤、炒菜、蒸饭,效率大大提高,做菜的思路也更清晰。但是,他能做的菜品种类(能解决的问题),和只有一个灶台时是一样的,只是过程更顺畅了。
21 多带图灵机
📜 [原文5]
这是图灵机的一种变体,其中我们固定了一定数量的纸带和相应的带头。在每一步中,机器从所有纸带读取符号,写入符号,并独立移动每个带头。这个模型在许多情况下都很有用,例如在不同的计算之间切换、比较字符串、复制字符串以供以后保存、组织、并行执行固定数量的事情等。
示例 我们有兴趣证明可识别语言在 AtLeastOne 运算下是封闭的,该运算定义如下。令 $L$ 为某种图灵机可识别语言。那么 AtLeastOne $(\mathrm{L})=\{\langle x \# y\rangle \mid x, y$ 中至少有一个在 $L$ 中\}。也就是说,AtLeastOne(L) 的元素是由 \# 分隔的两个字符串,且两个字符串中至少有一个在原语言中。注意 $L$ 的字母表为 $\Sigma$,其中 $\# \notin \Sigma$,而 AtLeastOne(L) 的字母表为 $\Sigma \cup\{\#\}$(我们正将 $\#$ 添加到新语言的字母表中,用作输入的分隔符)。
令 $M$ 为识别 $L$ 的图灵机,这是我们用于 AtLeastOne(L) 的 2 带的多带图灵机 $M^{\prime}$:
在输入 $w=x \# y$ 上,执行以下操作:
- 将 $\#$ 之前的所有内容写在一条纸带上(这就是 $x$),并将之后的所有内容写在另一条上(这就是 $y$)。
- 在纸带 1 ($x$) 上模拟 $M$(识别 $L$ 的机器)的 1 个步骤,如果机器接受,接受 $w$。
- 在纸带 2 ($y$) 上模拟 $M$ 的 1 个步骤,如果机器接受,那么接受 $w$
- 返回步骤 2。
这就是为什么这行得通:
如果 $w$ 在 AtLeastOne $(\mathrm{L})$ 中,这意味着 $x$ 或 $y$ 在 $L$ 中。由于 $M$ 识别 $L$,它最终会在其中一条纸带上接受,因此 $M^{\prime}$ 将接受 $w$。
如果 $w$ 不在 AtLeastOne $(\mathrm{L})$ 中,那么 $x$ 或 $y$ 都不在 $L$ 中。所以,$M$ 永远不会在任何一条纸带上接受,我们会无限期运行,因此 $M^{\prime}$ 不接受 $w$。
注意我们可以添加拒绝标准,例如如果两条纸带都处于拒绝状态则输出拒绝,但当输入不在语言中时,永远运行也是可以的。为了澄清,正如我们所写的那样,如果两条纸带都表示拒绝,步骤 2 和 3 将无限期交替且没有任何变化。
另请注意:如果说“在 $x$ 上模拟 $M$,然后在 $y$ 上模拟 $M$。如果 $M$ 接受 $x$ 我们就接受,否则转到 $y$,如果它在那里接受我们就接受”是不正确的。关键问题是 $M$ 可能会在 $x$ 上永远运行,所以我们永远无法尝试 $y$。这就是为什么我们很聪明地每次一步地交替模拟 $M$ 在 $x$ 和 $y$ 上的运行。
如果我们试图证明可判定语言类在此运算下是封闭的,那么上述较简单的算法将起作用,因为如果 $M$ 是一个判定器,它保证在每个输入上都会停机,所以上述也将是一个判定器(尽管顺便提一下,请注意我们没有办法确定一个给定的机器是否是判定器,正如我们将看到的)。
非确定性图灵机的替代方案。注意非确定性图灵机的简述见下文 2.2。我们的非确定性图リング机 $N$ 操作如下:
在输入 $w=x \# y$ 上,执行以下操作:
- 非确定性地选择 $x$ 或 $y$,并在所选内容上模拟 $M$,然后输出 $M$ 的结果。
我们看到,如果 $w \in \operatorname{AtLeastOne}(\mathrm{L})$,那么 $x$ 或 $y$ 必有一个在 $L$ 中,所以如果我们幸运地选择了在 $L$ 中的字符串,$M$ 将接受, $N$ 也会接受。
如果 $w \notin$ AtLeastOne $(\mathrm{L})$,那么不存在能让 $N$ 接受的猜测/选择。
这部分详细介绍多带图灵机并通过一个例子展示其应用。
2.1.1 多带图灵机定义和用途
- 定义:一个多带图灵机拥有 $k$ 条纸带,每条纸带都有自己独立的读写头。
- 转移函数:其转移函数的形式变为 $\delta: Q \times \Gamma^k \rightarrow Q \times \Gamma^k \times \{L, R, S\}^k$ (S代表Stay,保持不动)。这意味着,图灵机根据当前状态和所有 $k$ 个带头下读取到的符号,来决定下一个状态、要在每条纸带上写入什么新符号,以及每个带头各自如何移动。
- 用途:
- 比较字符串:可以把两个字符串分别放在两条纸带上,两个带头同步移动进行比较。
- 复制字符串:可以把一条纸带的内容复制到另一条纸带上,而不用在单条纸带上来回奔波。
- 并行计算:可以“同时”在不同的纸带上执行不同的计算任务,如此处的例子所示。这极大地简化了需要管理多个并行进程的算法设计。
2.1.2 示例:证明可识别语言对 AtLeastOne 运算封闭
- 问题:我们要证明,如果语言 $L$ 是图灵机可识别的,那么由 $L$ 构造出的新语言 $AtLeastOne(L)$ 也是图灵机可识别的。
- 语言定义:
- $L$ 是一个可识别语言,意味着存在一个图灵机 $M$ 识别它。
- $AtLeastOne(L) = \{ w \mid w = x\#y, \text{并且 } x \in L \text{ 或 } y \in L \}$。
- 证明思路:我们需要构造一个新的图灵机 $M'$,使其能够识别 $AtLeastOne(L)$。这里使用2带图灵机会让构造变得非常直观。
- $M'$ 的构造(使用2带图灵机):
1. 输入处理:输入 $w=x\#y$ 写在第一条纸带上。$M'$ 首先扫描第一条纸带,将#之前的部分(即 $x$)复制到第一条纸带的开头,并将#之后的部分(即 $y$)复制到第二条纸带上。
2. 交替模拟:这是算法的核心。$M'$ 开始模拟 $M$ 在 $x$ 和 $y$ 上的运行。但它不是先完整地模拟完 $M(x)$ 再去模拟 $M(y)$,而是:
- 在纸带1上模拟 $M$ 对 $x$ 运行一步。
- 检查 $M$ 是否接受。如果接受,则 $M'$ 立刻接受整个输入 $w$ 并停机。
- 在纸带2上模拟 $M$ 对 $y$ 运行一步。
- 检查 $M$ 是否接受。如果接受,则 $M'$ 立刻接受整个输入 $w$ 并停机。
- 重复这个“一步 $x$,一步 $y$”的循环。
- 正确性分析:
- 如果 $w \in AtLeastOne(L)$:这意味着 $x \in L$ 或 $y \in L$。因为 $M$ 识别 $L$,所以对属于 $L$ 的输入,$M$ 一定会在有限步后接受。假设 $M$ 在 $k$ 步后接受 $x$。那么 $M'$ 的交替模拟过程在进行到第 $k$ 轮对 $x$ 的模拟时,就会发现 $M$ 接受了,于是 $M'$ 也接受 $w$。同理,如果 $y \in L$,$M'$ 也会在有限步后接受。
- 如果 $w \notin AtLeastOne(L)$:这意味着 $x \notin L$ 并且 $y \notin L$。因为 $M$ 是一个识别器,对于不属于 $L$ 的输入,它可能拒绝,也可能永不停机。
- 如果 $M$ 在 $x$ 和 $y$ 上都拒绝,那么 $M'$ 的模拟永远不会进入接受状态,它会无限循环下去(或者可以设计一个拒绝逻辑,比如两个都拒绝时 $M'$ 也拒绝)。
- 如果 $M$ 在 $x$ 上永不停机,同时 $M$ 在 $y$ 上也永不停机(或拒绝),$M'$ 的交替模拟也会永不停机。
- 在所有情况下,只要 $w \notin AtLeastOne(L)$,$M'$ 就永不接受。
- 结论:$M'$ 接受所有属于 $AtLeastOne(L)$ 的字符串,且不接受任何不属于 $AtLeastOne(L)$ 的字符串。因此,$M'$ 识别 $AtLeastOne(L)$,证明了可识别语言在该运算下是封闭的。
2.1.3 关键点:为什么必须交替模拟?
- “陷阱”:一个看似更简单的算法是:“1. 在 $x$ 上运行 $M$。2. 如果 $M$ 接受,就接受。3. 否则,在 $y$ 上运行 $M$。4. 如果 $M$ 接受,就接受。”
- 问题所在:这个简单算法的致命缺陷在于,$M$ 只是一个识别器,不是判定器。如果 $x \notin L$,M 可能会在 $x$ 上永不停机。这样一来,我们的算法就会卡在第一步,永远没有机会去检查 $y$,即使 $y$ 可能属于 $L$。
- 交替模拟(Dovetailing):这种“一步 $x$,一步 $y$”的技巧被称为“燕尾榫”或“交织”。它确保了即使其中一个计算过程是无限的,另一个计算过程也能获得执行机会。这是一个在可计算性理论中非常重要的技巧,用于处理多个可能无限的计算。
2.1.4 可判定语言 vs. 可识别语言
- 如果 $L$ 是可判定的,那么识别 $L$ 的图灵机 $M$ 就是一个判定器,它对任何输入都保证停机。
- 在这种情况下,上面那个“错误的”简单算法(先运行完 $x$,再运行 $y$)就变成正确的了。因为在 $x$ 上的模拟保证会在有限步内结束(无论是接受还是拒绝),所以我们总有机会去处理 $y$。
- 这个例子深刻地揭示了识别和判定之间的关键区别:是否保证停机。
2.1.5 非确定性图灵机的替代方案
- 思路:非确定性允许图灵机进行“猜测”。
- 构造:一个新的非确定性图灵机 $N$:
1. 在输入 $w=x\#y$ 上,非确定性地选择 $x$ 或 $y$。
2. 在选择的那个字符串上完整地模拟 $M$。
3. $N$ 的输出就是 $M$ 的输出。
- 正确性分析:
- 如果 $w \in AtLeastOne(L)$:那么至少存在一个正确的选择(比如选了属于 $L$ 的 $x$)。沿着这条“幸运的”计算路径, $M$ 会接受,因此 $N$ 也存在一条接受路径。根据非确定性图灵机的定义,只要存在一条接受路径,它就接受整个输入。
- 如果 $w \notin AtLeastOne(L)$:那么无论 $N$ 猜 $x$ 还是 $y$,$M$ 都不会接受。因此,$N$ 没有任何一条计算路径可以达到接受状态,所以 $N$ 不接受 $w$。
- 这个例子也展示了非确定性在简化算法设计上的威力。
- 设 $L = \{w \mid w \text{ 是合数}\}$。$L$ 是可识别的(甚至可判定的)。$M$ 是一个识别 $L$ 的图灵机。
- 输入 $w = 4\#7$ (4是合数, 7是质数)。$w \in AtLeastOne(L)$。
- $M'$ 的运行:
- 纸带1: 4 ; 纸带2: 7
- 模拟 $M(4)$ 一步。
- 模拟 $M(7)$ 一步。
- ...
- 因为4是合数,$M$ 会在有限步(比如在检查到因子2时)后接受4。
- 在 $M'$ 的某个循环中,它模拟到了 $M$ 接受4的那一步。$M'$ 立刻停机并接受 $w=4\#7$。它甚至不需要知道 $M(7)$ 的结果。
- 输入 $w = HALT_{TM}\#ACCEPT_{DFA}$。假设 $x = HALT_{TM}$(停机问题,不可判定但可识别)并且 $x \notin L_{HALT}$(即某图灵机在某输入上不停机),而 $y = ACCEPT_{DFA}$ 且 $y \in L_{ACCEPT}$ (DFA的接受问题,可判定)。
- 错误算法:“先模拟 $x$”。算法会永远模拟 $M(x)$,永远不会停机,也就永远不会去检查 $y$。
- 正确算法(交替模拟):
- 模拟 $M(x)$ 一步。
- 模拟 $M(y)$ 一步。
- 模拟 $M(x)$ 第二步。
- 模拟 $M(y)$ 第二步。
- ...
- 由于 $y$ 的问题是可判定的,对 $y$ 的模拟会在有限步 $k$ 后停机并接受。因此,交替模拟的算法在第 $k$ 次模拟 $M(y)$ 时就会发现 $y$ 被接受,从而接受整个输入。这个例子完美地展示了交替模拟的必要性。
- 混淆识别和判定:这是本节的核心易错点。在为可识别语言设计图灵机时,必须时刻警惕永不停机的情况,并使用交替模拟等技巧来处理并行的计算。
- 多带图灵机的实现细节:虽然概念上很简单,但将一个k带图灵机转换为单带图灵机的过程很复杂。它通常涉及在单条纸带上划分出k个“轨道”,并用特殊符号标记每个虚拟带头的位置,模拟一次k带操作需要在单带上来回移动多次,效率较低。
- 忘记复制步骤:在使用多带图灵机时,第一步通常是将输入适当地分配到各个纸带上。这个预处理步骤是必要的,不能省略。
本节介绍了多带图灵机作为标准图灵机的一个方便的变体。通过证明可识别语言对 AtLeastOne 运算封闭的例子,清晰地展示了多带图灵机在处理并行计算任务时的优势。更重要的是,这个例子深刻地揭示了识别器和判定器的关键区别,并引入了“交替模拟”(Dovetailing)这一处理多个可能无限计算过程的重要技巧。
- 引入多带图灵机:介绍一种更灵活、更接近实际编程直觉的图灵机模型。
- 强化对“可识别”的理解:通过一个具体的例子,让学生深入理解“可识别”意味着可能永不停机,以及由此带来的算法设计上的挑战。
- 教授重要技巧:介绍“交替模拟”,这是一个在可计算性理论和算法设计中反复出现的通用且强大的技巧。
- 展示封闭性证明:演示如何使用构造法来证明一个语言类在某个运算下是封闭的。
多带图灵机就像一个拥有多块黑板的数学家。他可以在一块黑板上演算问题A,在另一块黑板上演算问题B。如果他想知道A或B是否有一个有解,他可以:
- 在黑板A上算一步。
- 然后走到黑板B前算一步。
- 再回到黑板A算下一步...
这样,即使问题A的演算过程是无限的,他也能保证问题B的演算在向前推进。只要其中任何一个问题得出了答案,他就可以立刻宣布找到了一个解。
想象一下你在同时下载两个文件,一个可能特别大或者源不好(可能永远下不完),另一个是普通的小文件。你的下载管理器(图灵机)不会傻傻地等第一个文件下完再开始下第二个。它会给两个文件都分配一些带宽(交替模拟),轮流下载。这样,当那个小文件下载完成时(一个计算过程接受),你就可以立即使用它了,而不必等到那个可能永远也下不完的大文件有结果。
22 非确定性图灵机
📜 [原文6]
非确定性图灵机(Non-Deterministic Turing Machines)从给定的格局出发可以有多个可能的移动。当且仅当存在一条通向接受状态的序列时,它们才接受输入。非确定性是一个非常强大(有时也是违反直觉的)概念。即便如此,它可以使设计算法变得更简单,因为你可以(在非确定性步骤中)进行“猜测”,然后只需在事后验证:当且仅当在正确/幸运的猜测下非确定性图灵机接受,输入才在语言中。
示例 我们给出一个非确定性图灵机来判定以下语言:
REACHABILITY $=\{\langle G, s, t\rangle \mid G$ 是一个图, $s, t$ 是顶点, G 中存在一条从 $s$ 到 $t$ 的路径 \}
我们的非确定性图灵机 $N$ 操作如下:
在输入 $w=\langle G, s, t\rangle$ 上,其中 $G$ 是一个图, $s, t$ 是 $G$ 中的顶点,执行以下操作:
- 将当前顶点设置为 $s$。
- 将当前顶点标记为已访问。
- 如果通过一条边与当前顶点相连的顶点集都被标记了,拒绝。否则,非确定性地将当前顶点设置为该集合中的一个未标记顶点。
如果当前顶点是 $t$,接受 $w$。否则返回步骤 2。
为什么这行得通:假设 $w \in$ REACHABILITY:那么根据 REACHABILITY 的定义,存在一条路径,或从 $s$ 到 $t$ 的由边连接的顶点序列。因此,存在一个 $N$ 可以做出的幸运选择序列以从 $s$ 到达 $t$,所以 $N$ 接受 $w$。
假设 $w \notin$ REACHABILITY:那么不存在这样可猜测的从 $s$ 到 $t$ 的路径,所以所有可能的猜测都会使 $N$ 拒绝 $w$。
这部分介绍了非确定性图灵机(NTM),并用图的可达性问题作为例子说明其工作原理和设计优势。
2.2.1 非确定性图灵机定义
- 核心区别:与确定性图灵机(DTM)的主要区别在于转移函数。
- DTM的转移函数 $\delta(q, a)$ 输出一个确定的 (状态, 符号, 方向) 三元组。
- NTM的转移函数 $\delta(q, a)$ 输出一个包含多个可能三元组的集合。例如,$\delta(q_0, a) = \{ (q_1, b, R), (q_2, c, L) \}$,表示在 $q_0$ 读到 $a$ 时,机器可以走向 $q_1$,也可以走向 $q_2$。
- 计算模式:NTM的计算不是一条线性的路径,而是一棵“计算树”。树的根是初始格局,每个节点的子节点代表了它在下一步所有可能的格局。
- 接受条件:如果这棵计算树中,至少有一条从根节点到某个包含接受状态$q_{acc}$的叶节点的路径,那么NTM就接受该输入。如果所有路径都导向拒绝或无限循环,则NTM不接受。
2.2.2 “猜测与验证”模型
- 非确定性最强大的直觉模型是“猜测与验证”(Guess and Check)。
- 猜测:在算法的非确定性步骤,机器可以“猜测”一个解决方案或一个正确的路径。这相当于在计算树中探索一条特定的分支。
- 验证:在猜测之后,机器的其余部分以确定性的方式来验证这个猜测是否正确。
- 接受:当且仅当存在一个“幸运的”猜测,能让后续的验证部分成功,整个NTM才接受输入。这简化了许多搜索问题的算法设计:我们不必编写搜索算法,只需编写一个验证算法,然后用非确定性来“神奇地”提供一个待验证的候选解。
2.2.3 示例:图的可达性问题 (REACHABILITY)
- 语言定义:REACHABILITY 包含所有编码为 $\langle G, s, t \rangle$ 的字符串,其中 $G$ 是一个图,$s$ 和 $t$ 是图中的两个顶点,并且在 $G$ 中存在一条从 $s$ 到 $t$ 的路径。
- NTM 算法设计:
1. 初始化:将一个“当前位置”指针放在起始顶点 $s$ 上。为了防止在环里无限循环,我们需要一个方法来记录访问过的顶点。算法将当前顶点标记为“已访问”。
2. 循环/猜测步骤:
- 查看与“当前位置”顶点相连的所有邻居。
- 非确定性地选择一个尚未被标记为“已访问”的邻居。
- 将“当前位置”指针移动到这个新选择的邻居上。
- 将新位置标记为“已访问”。
- 检查:如果当前位置就是目标顶点 $t$,则接受。
- 否则,回到循环的开始,从新位置继续探索。
3. 拒绝条件:如果在某一步,当前顶点的所有邻居都已经被标记过了(而当前位置还不是 $t$),说明走进了死胡同,这条计算路径拒绝。
- 正确性分析:
- 如果 $\langle G, s, t \rangle \in$ REACHABILITY:这意味着图中真实存在一条从 $s$ 到 $t$ 的路径,比如 $s \rightarrow v_1 \rightarrow v_2 \rightarrow \dots \rightarrow t$。那么,NTM就存在一个“幸运的”猜测序列:在 $s$ 时猜到 $v_1$,在 $v_1$ 时猜到 $v_2$,...,最终到达 $t$。沿着这条由幸运猜测构成的计算路径,NTM最终会接受。
- 如果 $\langle G, s, t \rangle \notin$ REACHABILITY:这意味着从 $s$ 出发,无论走哪条路都无法到达 $t$。因此,NTM的任何一个猜测序列(任何一条计算路径)最终都会因为无路可走(所有邻居都被访问过)而进入拒绝状态。不存在任何一条路径能让NTM接受。
- 与DTM的对比:一个确定性的图灵机来解决这个问题,需要实现一个系统的搜索算法,比如广度优先搜索(BFS)或深度优先搜索(DFS)。这需要明确地管理一个队列或栈来存储待访问的顶点,过程要复杂得多。NTM则把“搜索”这个过程隐藏在了非确定性的“猜测”中。
- 图 G: 顶点 {s, a, b, t}, 边 {(s,a), (s,b), (a,t), (b,a)}
- 输入: $\langle G, s, t \rangle$
- NTM的计算树:
- Level 0: (q_start, current_vertex=s, visited={s})
- Level 1 (从s出发的猜测):
- 分支1: 猜邻居 'a' -> (q_loop, current_vertex=a, visited={s,a})
- 分支2: 猜邻居 'b' -> (q_loop, current_vertex=b, visited={s,b})
- Level 2 (从各分支继续猜测):
- 从分支1 (在a处): a的邻居是s, t, b。s已被访问。
- 分支1.1: 猜邻居 't' -> (q_loop, current_vertex=t, visited={s,a,t}) -> 当前是t,接受!
- 分支1.2: 猜邻居 'b' -> (q_loop, current_vertex=b, visited={s,a,b})
- 从分支2 (在b处): b的邻居是s, a。s已被访问。
- 分支2.1: 猜邻居 'a' -> (q_loop, current_vertex=a, visited={s,b,a})
- 结论: 因为存在一条路径(分支1.1)导向了接受状态,所以NTM接受输入 $\langle G, s, t \rangle$。
- 如果输入是 $\langle G, t, s \rangle$ (从t到s是否有路径?)
- Level 0: (q_start, current_vertex=t, visited={t})
- Level 1: t没有任何出边。它的邻居集合为空。根据规则3,所有(零个)邻居都被“访问”过了。所以这条路径拒绝。
- 结论: 计算树只有一条路径,且该路径拒绝。所以NTM不接受输入 $\langle G, t, s \rangle$。
- 非确定性不是随机性:NTM不是掷骰子。它会神奇地探索所有可能性。接受的条件是存在一条成功路径,而不是有很高概率找到一条。
- 非确定性不等于并行计算:虽然NTM的计算可以想象成一棵树,但它仍然是一个单一的机器模型。它和多带图灵机是不同的概念。多带图灵机是确定性地、一步一步地并行处理多个任务。NTM是“一次性”探索所有分支,只要有一个成功就算成功。
- NTM的计算能力:一个非常重要的(也是违反直觉的)结论是,非确定性图灵机和确定性图灵机在计算能力上是等价的。任何一个NTM都可以被一个DTM模拟。模拟的方法通常是DTM系统地、逐层地(类似BFS)模拟NTM的整个计算树。这会导致DTM的运行时间指数级地慢于NTM,但这不影响“可计算性”的结论。这个问题(DTM模拟NTM的效率)正是计算复杂性理论中著名的 P vs NP 问题的核心。
- 算法中的“标记”:在实现这个NTM时,“标记为已访问”的操作需要在纸带上完成。例如,图的表示可以是邻接表,标记一个顶点就可以是在纸带上找到该顶点的表示,并在旁边写一个'X'。
本节介绍了非确定性图灵机 (NTM),它通过允许在一步中有多种可能的转移,极大地简化了某些问题的算法设计,特别是搜索类问题。其核心思想可以理解为“猜测并验证”。通过图的可达性问题 (REACHABILITY) 的例子,我们看到NTM可以将复杂的搜索逻辑(如BFS/DFS)简化为简单的“猜测下一个节点”的步骤。尽管NTM看起来比DTM强大,但它们的计算能力是等价的。
- 引入非确定性模型:介绍计算理论中“非确定性”这一核心概念,并将其应用到最强的计算模型——图灵机上。
- 展示算法设计优势:通过REACHABILITY这个经典例子,让学生体会到非确定性在简化算法设计方面的威力,为后续学习NP完全性等复杂性理论概念打下基础。
- 对比DTM与NTM:隐式地引导学生思考确定性计算和非确定性计算之间的关系,这是计算复杂性理论的中心议题。
非确定性图灵机就像一个拥有无穷分身的侦探,在调查一个迷宫般的案件。
- 每当遇到一个岔路口(多种选择),侦探就会分裂成多个分身,每个分身探索一条路。
- 这些分身继续前进,遇到新的岔路口会继续分裂。
- 只要有任何一个分身最终找到了出口(接受状态),整个侦探(NTM)就立刻宣告成功。
- 如果所有分身都走进了死胡同或永远在迷宫里转圈(拒绝或循环),那么侦探就宣告失败。
这个模型的美妙之处在于,我们作为“侦探的设计者”,只需要告诉每个分身如何走一步以及如何判断是否到达出口,而无需操心如何系统地搜索整个迷宫。
想象你在玩一个电子游戏,想知道能否从起点走到终点。你不需要自己一点点试路。你只需要按下一个“神力”按钮(非确定性)。游戏瞬间计算了所有可能的路径,如果存在一条能通向终点的路,屏幕上就直接显示“胜利!”(接受)。如果没有任何路能走通,屏幕就显示“失败”(不接受)。非确定性图灵机就像是拥有这种“神力”按钮的计算机。
3 练习题
31 练习题1
📜 [原文7]
- 考虑输入-输出图灵机 $M=\left(Q, \Sigma, \Gamma, \delta, q_{0}, q_{\text {halt }}\right)$,其中 $Q= \left\{q_{0}, q_{1}, q_{\text {halt }}\right\}, \Sigma=\{0,1\}, \Gamma=\{0,1,\llcorner \}$, 且 $\delta$ 由以下给出:
$\left.\left.\delta\left(q_{0}, 0\right)=\left(q_{0}, 0, R\right), \delta\left(q_{0}, 1\right)=\left(q_{0}, 1, R\right), \delta\left(q_{0},\right\lrcorner\right)=\left(q_{1},\right\lrcorner L\right)$
$\left.\delta\left(q_{1}, 0\right)=\left(q_{\text {halt }}, 1, R\right), \delta\left(q_{1}, 1\right)=\left(q_{1}, 0, L\right), \delta\left(q_{1}, \iota\right)=\left(q_{\text {halt }},\right\lrcorner, L\right)$
(a) 提供 $M$ 在输入 100 上运行时的完整格局序列。
$M$ 在此输入上的输出是什么?
(b) $M$ 在 10011 上的输出是什么?在输入 11 上呢?
(c) $M$ 计算的是什么函数?
这道题要求我们追踪一个给定的输入-输出图灵机的运行过程,并推断它所计算的函数。输入-输出图灵机与我们之前看到的判定器或识别器略有不同,它的目标不是接受或拒绝,而是在停机时,将纸带上的内容作为输出。它通常只有一个停机状态 $q_{halt}$,而不是 $q_{acc}$ 和 $q_{rej}$。
首先,我们来分析这个图灵机的转移函数 $\delta$:
- 状态 $q_0$ 的行为:
- $\delta(q_0, 0) = (q_0, 0, R)$: 读到0,不变,向右移动。
- $\delta(q_0, 1) = (q_0, 1, R)$: 读到1,不变,向右移动。
- $\delta(q_0, \_) = (q_1, \_, L)$: 读到空白符,不变,状态变为 $q_1$,并向左移动。
- 总结 $q_0$: 这个状态的作用就是从左到右扫描整个输入字符串,直到找到字符串末尾的空白符。然后它切换到状态 $q_1$ 并把带头移动到输入串的最后一个字符上。
- 状态 $q_1$ 的行为:
- $\delta(q_1, 0) = (q_{halt}, 1, R)$: 读到0,将其翻转为1,然后进入停机状态 $q_{halt}$。
- $\delta(q_1, 1) = (q_1, 0, L)$: 读到1,将其翻转为0,保持在 $q_1$ 状态,并继续向左移动。
- $\delta(q_1, \_) = (q_{halt}, \_, L)$: 读到空白符(这意味着已经移动到了输入串的左边),进入停机状态 $q_{halt}$。
- 总结 $q_1$: 这个状态从右到左扫描字符串。如果遇到1,就翻转成0,继续向左。一旦遇到第一个0(从右边算起),就将其翻转成1,然后立即停机。如果在找到0之前就走到了字符串的开头(读到空白符),也停机。
- 整体行为分析:
- 机器首先移动到输入二进制数的末尾。
- 然后从右向左,将所有的 '1' 变为 '0'。
- 当遇到第一个 '0' 时,将其变为 '1' 并停机。
- 如果一路都是 '1',直到字符串开头,那么所有的 '1' 都会变成 '0',然后机器在字符串左边的空白处停机。
这正是二进制加一的操作!
(a) 输入 100
- 格局(Configuration)的表示方法:我们将纸带内容写出,并将当前状态写在带头指向的符号的左边。例如 1(q0)00_ 表示状态是 $q_0$,带头在第二个字符'0'上。
1. 初始: (q0)100_
2. $\delta(q_0, 1) = (q_0, 1, R)$: 1(q0)00_
3. $\delta(q_0, 0) = (q_0, 0, R)$: 10(q0)0_
4. $\delta(q_0, 0) = (q_0, 0, R)$: 100(q0)_
5. $\delta(q_0, \_) = (q_1, \_, L)$: 10(q1)0_
6. $\delta(q_1, 0) = (q_{halt}, 1, R)$: 101(q_halt)_ -> 停机
- 格局序列:
(q0)100_ -> 1(q0)00_ -> 10(q0)0_ -> 100(q0)_ -> 10(q1)0_ -> 101(q_halt)_
- 输出: 停机时,纸带上的内容是 101。
(b) 输入 10011 和 11
- 输入 10011:
1. $q_0$阶段: 带头移动到最右边。格局变为 1001(q1)1_。
2. $q_1$阶段:
- $\delta(q_1, 1) = (q_1, 0, L)$: 100(q1)10_
- $\delta(q_1, 1) = (q_1, 0, L)$: 10(q1)000_
- $\delta(q_1, 0) = (q_{halt}, 1, R)$: 10100(q_halt)_ -> 停机
- 输出: 10100。 (二进制的 10011 是19,加一得20,即二进制的 10100。正确。)
- 输入 11:
1. $q_0$阶段: 带头移动到最右边。格局变为 1(q1)1_。
2. $q_1$阶段:
- $\delta(q_1, 1) = (q_1, 0, L)$: (q1)10_
- $\delta(q_1, 1) = (q_1, 0, L)$: (q1)_00_
- $\delta(q_1, \_) = (q_{halt}, \_, L)$: 停机
- 输出: 00。 (二进制的11是3,加一得4,即二进制的100。这里输出00是因为图灵机没有在最左边添加一位的逻辑。它只是在原有的位数上操作。这是一个边界情况,说明这个图灵机对于会产生进位的加法,不能正确处理最高位。)
(c) M 计算的是什么函数?
- 函数: 该图灵机计算函数 $f(w) = w+1$,其中 $w$ 被解释为一个二进制数。
- 限制/缺陷: 正如在(b)中看到的,如果加法导致需要增加二进制数的位数(例如,从11到100),这个图灵机无法正确处理。它会把11变成00,然后停机。一个更完善的二进制加法器在遇到这种情况时,应该在最左边添加一个'1'。
- 输入 w = 101 (5):
- $q_0$ 扫描到末尾: 10(q1)1_
- $\delta(q_1, 1) = (q_1, 0, L)$: 1(q1)00_
- $\delta(q_1, 0) = (q_{halt}, 1, R)$: 110(q_halt)_ -> 停机。
- 输出: 110 (6)。正确。
- 格局表示法: 务必清晰地表示出当前状态和带头位置,这是追踪图灵机运行的关键。
- 进位问题: 正如上面分析的,当输入是全1串时(如1, 11, 111...),该图灵机的计算结果是错误的。它会将111(7)计算为000(0),而不是1000(8)。
- 输入-输出图灵机: 注意它和判定器的区别。它的目的是计算并留下输出,而不是简单地回答“是”或“否”。
这道题通过一个具体的例子,让我们手动模拟图灵机的运行。
- (a)和(b)考察了对格局和转移函数的理解和追踪能力。
- (c)考察了从具体操作中归纳出图灵机所实现的抽象功能的能力。
- 该图灵机实现了一个(有缺陷的)二进制加一计算器。
这道题旨在巩固学生对图灵机形式化定义和运行机制的理解。通过手工模拟,学生能更深刻地体会到图灵机是如何通过简单的、局部的读/写/移动规则来完成复杂计算的。同时,它也引导学生思考算法的边界情况和潜在缺陷。
这个图灵机就像一个笨拙但守规矩的会计,在算盘上加一。
- 他先把目光移到算盘的最右边一列($q_0$状态)。
- 然后开始从右往左拨珠子($q_1$状态)。
- 如果珠子在上面(代表'1'),他就把它拨下去(变成'0'),然后看左边一列。
- 如果珠子在下面(代表'0'),他就把它拨上来(变成'1'),然后就停下来下班了($q_{halt}$)。
这个过程和我们手动做二进制加法时的“逢一进位,遇零置一”的过程一模一样。
想象一条由0和1组成的灯带。
- 你先走到灯带的最右端。
- 然后你从右向左走。
- 每遇到一盏亮着的灯('1'),你就把它关掉('0'),然后继续向左走。
- 当你遇到第一盏灭着的灯('0'),你把它打开('1'),然后你就停下不动了。
这就是这个图灵机在做的事情。
32 练习题2
📜 [原文8]
- 令 $\Sigma=\{\#, 0,1\}$。提供一个计算以下函数的输入-输出图灵机的实现级描述:
其中 $\langle x\rangle$ 代表数字 $x$ 的二进制表示。
(例如,如果图灵机在纸带上以 \#100 开始,它应该以 纸带上的 \#10 停机;如果它以 \#11 开始,它应该以 \#1010 停机。)
你可以使用具有多于一条纸带的图灵机——在这种情况下,输出应写在第一条纸带上。
这道题要求我们设计一个图灵机来实现著名的考拉兹猜想(Collatz conjecture)中的一步操作。我们需要给出实现级描述,这意味着我们不需要写出完整的7-元组,但需要清晰地描述纸带和带头的操作。使用多带图灵机可以大大简化设计。
我们将使用一个3带图灵机来解决这个问题。
- 纸带1: 输入/输出带。初始时包含#<x>,最终将包含计算结果。
- 纸带2: 计算带。用于执行算术运算的草稿空间。
- 纸带3: 辅助带。用于存储中间值,如 $x$ 的副本。
算法的实现级描述:
在输入 $w = \#\langle x \rangle$ 上:
- 预处理和分支
a. 将带头1移动到字符串的末尾,检查 $\langle x \rangle$ 的最后一位。
b. 如果最后一位是 '0' ( $x$ 是偶数),则进入偶数处理流程。
c. 如果最后一位是 '1' ( $x$ 是奇数),则进入奇数处理流程。
- 偶数处理流程 (计算 $x/2$)
a. 识别: $x$ 是偶数,其二进制表示以 '0' 结尾。
b. 计算: 二进制数除以2,相当于右移一位,即去掉末尾的'0'。
c. 操作:
i. 将带头1移动到 $\langle x \rangle$ 的最后一个字符 '0' 上。
ii. 将这个 '0' 擦除(替换为空白符 _)。
iii. 停机。纸带1上现在是 #<x/2>。
- 奇数处理流程 (计算 $3x+1$)
a. 识别: $x$ 是奇数。计算 $3x+1$。我们知道 $3x+1 = (2x+x)+1$。在二进制中,$2x$ 就是 $x$ 左移一位(在末尾加一个'0')。
b. 准备计算:
i. 将纸带1上 '#' 之后的内容 $\langle x \rangle$ 复制到纸带2和纸带3上。纸带2和纸带3现在都包含 $\langle x \rangle$。
c. 计算 $2x$:
i. 在纸带2的 $\langle x \rangle$ 末尾添加一个 '0'。现在纸带2上是 $\langle 2x \rangle$。
d. 计算 $2x+x$ (即 $3x$):
i. 现在我们需要执行二进制加法:(纸带2) + (纸带3)。这是一个标准的图灵机子程序。
ii. 使用纸带1作为输出区域(先清空原有内容)。
iii. 从右到左对齐纸带2和纸带3。
iv. 模拟手动的二进制加法,处理好进位,将结果逐位写在纸带1上。完成后,纸带1上是 $\langle 3x \rangle$。
e. 计算 $(3x)+1$:
i. 我们刚刚在纸带1上得到了 $\langle 3x \rangle$。现在需要对其加一。
ii. 调用练习题1中描述的二进制加一子程序(或者一个更完善的版本)。
iii. 在纸带1上,从右到左扫描 $\langle 3x \rangle$,将遇到的'1'翻转为'0',直到遇到'0'或空白,将其翻转为'1'。
f. 格式化输出:
i. 确保纸带1的内容是 #<3x+1> 的形式。这可能需要移动纸带内容,在前面插入 '#'。一个更简单的做法是在步骤 d-i 中清空纸带1时,先在开头写好 '#'。
ii. 停机。
- 示例1:输入 #100 ($x=4$,偶数)
- 带头1移动到末尾,看到 '0'。进入偶数流程。
- 将最后一个 '0' 替换为 _。纸带1变为 #10_。
- 停机。输出为 #10(代表 $x=2$),正确。
- 示例2:输入 #11 ($x=3$,奇数)
- 带头1移动到末尾,看到 '1'。进入奇数流程。
- 复制:
- 纸带1: #11
- 纸带2: 11
- 纸带3: 11
- 计算 $2x$:
- 纸带2末尾加'0',变为 110 (代表6)。
- 计算 $3x = 2x+x$:
- 执行二进制加法 110 + 11。
- 将纸带1清空并在开头写'#',然后将加法结果写入。纸带1变为 #1001。
- 计算 $3x+1$:
- 对纸带1上的 1001 执行加一操作。
- 从右到左,'1'变'0',产生进位。下一个'0'变'1',进位消失。
- 1001 + 1 = 1010。
- 纸带1内容更新为 #1010。
- 停机。输出为 #1010(代表 $x=10$),因为 $3*3+1=10$,正确。
- 多带图灵机的使用: 明确每条纸带的用途是关键。如果不使用多带,在单条纸带上完成这些操作会非常复杂,需要在纸带上来回移动、标记、复制和删除,极易出错。
- 二进制算术子程序: 像“二进制加法”和“二进制加一”这样的操作,在这里被当作一个已知的子程序来调用。在真正的底层设计中,这些子程序本身也需要被详细实现。
- 空间管理: 在奇数情况下,计算 $3x+1$ 的结果通常比 $x$ 更长。必须确保图灵机有能力将纸带上的内容“推后”以腾出空间,或者使用多条纸带来避免这个问题。我们使用多带图灵机的方法,通过在一条干净的纸带上写结果,很好地解决了空间问题。
- 输入格式: 题目规定输入格式为 #<x>。我们的算法需要正确地处理'#'符号,只对后面的二进制部分进行计算,并在最终输出时保留'#'。
这道题要求我们设计一个图灵机,根据输入 $x$ 的奇偶性执行不同的算术运算。
- 对于偶数 $x$,计算 $x/2$,这在二进制中对应于简单的右移操作(删除末尾的'0')。
- 对于奇数 $x$,计算 $3x+1$,这需要更复杂的算术运算,包括左移(乘以2)、加法和加一。
通过使用多带图灵机,我们可以将复杂的计算分解到不同的“草稿纸”上,大大简化了算法的设计,使其更清晰、更易于管理。
- 练习图灵机算法设计: 让学生练习如何将一个数学函数转换为图灵机的实现级描述。
- 展示多带图灵机的实用性: 这个问题是一个绝佳的例子,说明了为什么多带图灵机虽然在计算能力上与单带等价,但在实践中是一个非常有用的工具。
- 应用算术运算: 考察学生是否理解基本的二进制算术运算(左移/右移代表乘/除2,二进制加法)以及如何将这些运算思想转化为图灵机的步骤。
这个图灵机就像一个遵循特定流程的办公室文员。
- 拿到一份文件(输入 #
)。 - 他首先看文件编号的最后一位,判断是奇是偶。
- 如果是偶数:他直接撕掉编号的最后一位数字,工作完成。
- 如果是奇数:
a. 他拿出两张草稿纸。在两张纸上都抄下文件编号。
b. 在第一张草稿纸上的编号末尾添个0。
c. 然后他拿出计算器,把两张草稿纸上的数字加起来,把结果写在一张新的正式文件上。
d. 最后,他给新文件上的编号加一。工作完成。
整个流程清晰、分步,多张草稿纸(多条纸带)让复杂的计算任务变得井井有条。
想象你在一个巨大的沙盘上用石子表示二进制数。
- 输入: #符号后面跟着一排石子(代表 $\langle x \rangle$)。
- 偶数情况: 如果最右边没有石子(代表'0'),你直接把那个空格抹掉,让沙盘变短一点。
- 奇数情况: 如果最右边有石子(代表'1'),你进入一个复杂模式:
- 你在旁边复制两份一模一样的石子排列。
- 在第一份复制品的末尾再加一堆代表'0'的空地。
- 你开始费力地(但有条不紊地)将两份复制品的石子合并,执行二进制加法规则,在最开始的沙盘区域摆出新的结果。
- 最后,你再对这个新结果执行“加一”操作(从右边开始,把石子拿走,直到遇到空地,放一个石子)。
33 练习题3
📜 [原文9]
- 令 $L=\{\langle M, k\rangle \mid M \text{ 是一个图灵机}, k \text{ 是一个正整数, 且存在一个使 } M \text{ 运行至少 } k \text{ 步的输入}\}$
证明 $L$ 是可判定的。
这道题要求我们证明语言 $L$ 是可判定的。这意味着我们需要构造一个图灵机 $D$ (一个判定器),它能在有限时间内对任何输入 $\langle M, k \rangle$ 给出“接受”或“拒绝”的答案。
- 语言 L 的定义:
- 输入是一个二元组 $\langle M, k \rangle$,其中 $M$ 是一个图灵机的编码, $k$ 是一个正整数。
- 语言 $L$ 中的元素满足条件:存在一个输入字符串 $w$,使得图灵机 $M$ 在 $w$ 上运行时,其计算步数至少为 $k$。
- 证明思路:
我们要构建一个判定器 $D$ 来判定 $L$。$D$ 的输入是 $\langle M, k \rangle$。$D$ 的任务是回答:“是否存在一个输入 $w$ 能让 $M$ 跑上至少 $k$ 步?”
这里的关键词是“存在”。我们似乎需要搜索所有可能的输入字符串 $w$。但所有可能的输入字符串是无限多的,直接搜索是行不通的。我们需要找到一个界限。
让我们思考一下,什么情况下 $M$ 的运行步数会少于 $k$ 步?如果 $M$ 在所有输入 $w$ 上,都在 $k-1$ 步之内停机了(接受或拒绝),那么就不存在能让它运行至少 $k$ 步的输入。
关键洞见在于,一个图灵机在 $k$ 步内能做什么?
- 在 $k$ 步内,带头最多能从起始位置向左或向右移动 $k-1$ 格。
- 因此,在 $k$ 步之内,图灵机 $M$ 访问的纸带格子数量是有限的,最多是 $k$ 个格子(初始位置 + $k-1$ 次移动)。
- 这意味着,在 $k$ 步内,$M$ 的行为只受到纸带上它能访问到的那部分内容的影响。
考虑所有长度小于 $k$ 的输入字符串。为什么是这个界限?
- 如果 $M$ 在一个很长的输入 $w$ (长度 $\ge k$) 上运行,它在前 $k$ 步里,也只能看到 $w$ 的前 $k$ 个字符。
- 它的行为和在另一个输入 $w'$ ( $w$ 的前 $k-1$ 个字符) 上的前 $k$ 步是完全一样的。
- 更简单地,考虑空字符串 $\epsilon$ 作为输入。如果 $M$ 在 $\epsilon$ 上运行了至少 $k$ 步,那么我们就找到了一个满足条件的输入(即 $w=\epsilon$),于是 $\langle M, k \rangle \in L$。
- 如果 $M$ 在 $\epsilon$ 上运行了少于 $k$ 步就停机了,这还不够。我们还需要考虑别的输入。
让我们换个角度,从图灵机的格局(configuration)来想。一个格局包含了当前状态、纸带内容、带头位置。
- 如果一个图灵机运行了 $k$ 步,它会经历 $k+1$ 个不同的格局。
- 如果一个图灵机在某个点重复了一个格局,它就会进入无限循环。
- 但是,我们关心的是步数,而不是停机。
回到关键点:在前 $k$ 步内,机器的行为只取决于它能扫描到的纸带部分。
- 这部分纸带的长度最多为 $k$。
- 因此,我们只需要考虑那些长度小于 $k$ 的输入字符串就足够了。任何更长的字符串,在前 $k$ 步的行为上,都与一个长度小于 $k$ 的前缀等价。
- 甚至,我们可以只考虑一个输入:空字符串 $\epsilon$。
- 为什么?因为纸带上除了输入,还有无限的空白符号_。
- 如果 $M$ 需要读一些非空白的符号才能运行得更久,我们可以认为这些符号是 $M$ 自己写到纸带上的。
- 想象一下,任何在某个输入 $w$ 上运行 $k$ 步的计算过程,我们都可以构造一个在空输入 $\epsilon$ 上运行的图灵机 $M'$ 来模拟它($M'$ 先在纸带上写下 $w$,然后像 $M$ 一样运行)。
- 但题目给的是固定的 $M$。让我们重新思考。
一个更简单且正确的思路:
我们不需要搜索所有输入。我们只需要模拟 $M$ 在所有可能的短输入上的运行情况。但“多短”才够呢?
- 设 $M$ 的状态数为 $|Q|$,纸带字母表大小为 $|\Gamma|$。
- 在 $k$ 步内,图灵机可以产生的不同格局数量是巨大的,但我们不需要关心这个。
- 让我们回到最初的直觉:如果存在一个输入 $w$ 能让 $M$ 跑 $\ge k$ 步,那么 $M$ 在前 $k-1$ 步都没有停机。
- 我们可以尝试模拟 $M$ 在所有可能的输入上并行运行 $k$ 步。但这仍然是无限的。
最终的、正确的思路:有界模拟
- 我们不需要测试无限多的输入。我们只需要测试有限多个,并且模拟有限步。
- 判定器D的算法:
- $D$ 接收输入 $\langle M, k \rangle$。
- $D$ 系统地生成所有长度从 0 到 $k-1$ 的字符串。设 $M$ 的输入字母表为 $\Sigma$。这些字符串的数量是有限的。
- 对于其中的每一个字符串 $w$:
a. $D$ 模拟 $M$ 在输入 $w$ 上的运行。
b. $D$ 在模拟的同时进行计数,最多模拟 $k$ 步。
c. 如果在模拟的 $k$ 步内,$M$ 没有停机(即没有进入 $q_{acc}$ 或 $q_{rej}$),这意味着 $M$ 在 $w$ 上的运行步数至少是 $k$。$D$ 立即停机并接受 $\langle M, k \rangle$。
- 如果 $D$ 尝试了所有长度小于 $k$ 的字符串,并且在每个字符串上,$M$ 都在 $k$ 步内停机了,这意味着什么?这还不足以拒绝。因为可能存在一个长度为 $k$ 或更长的字符串能让 $M$ 运行更久。
让我们重新审视问题。我们需要证明的是可判定性。我们设计的判定器 $D$ 必须自己能停机。
关键在于:如果 $M$ 在所有长度小于 $k$ 的输入上都在 $k$ 步内停机,那么它在任何输入上都会在 $k$ 步内停机。
- 为什么这是真的? 假设 $M$ 在一个长度 $\ge k$ 的输入 $w$ 上运行了 $k$ 步或更多。在前 $k$ 步中,$M$ 的带头最多只能扫描到从起始位置开始的 $k$ 个格子。它的行为完全由 $w$ 的前 $k-1$ 个字符(长度为 $k$ 的前缀)决定。设这个前缀为 $w'$。那么 $M$ 在输入 $w'$ 上的前 $k$ 步行为与在 $w$ 上完全相同。因此,如果 $M$ 在 $w$ 上运行了 $\ge k$ 步,它在 $w'$ (一个长度小于 $k$ 的字符串)上也必然运行了 $\ge k$ 步。
- 这就形成了一个矛盾。所以我们的假设“$M$ 在一个长度 $\ge k$ 的输入上运行了 $\ge k$ 步”是错误的。
- 结论:我们只需要检查所有长度小于 $k$ 的字符串就足够了!
最终的判定器 D 的实现级描述:
在输入 $\langle M, k \rangle$ 上:
- 从 $M$ 的描述中提取其输入字母表 $\Sigma$。
- 构造一个所有长度从 0 到 $k-1$ 的 $\Sigma$ 上的字符串的列表。这个列表是有限的。
- 对于这个列表中的每一个字符串 $w$:
a. 模拟 $M$ 在输入 $w$ 上运行,最多 $k$ 步。
b. 如果在模拟过程中,$M$ 的步数达到了 $k$(即在 $k-1$ 步后仍未停机),那么我们找到了一个能让 $M$ 运行至少 $k$ 步的输入。因此,接受 $\langle M, k \rangle$ 并停机。
- 如果对于列表中的所有字符串 $w$,$M$ 都在 $k$ 步之内停机了,那么根据我们上面的论证,对于任何输入,$M$ 都会在 $k$ 步内停机。因此,不存在能让 $M$ 运行至少 $k$ 步的输入。所以,拒绝 $\langle M, k \rangle$ 并停机。
为什么 D 是一个判定器?
- 步骤1和2是有限的。
- 步骤3的循环次数是有限的。
- 循环体内的模拟(步骤3a)也是有界的,最多模拟 $k$ 步。
- 因此,无论在哪种情况下,判定器 $D$ 总会在有限时间内完成其计算并停机(接受或拒绝)。
- 所以,语言 $L$ 是可判定的。
- 设输入为 $\langle M, k=3 \rangle$。$M$ 的输入字母表 $\Sigma = \{a\}$。
- 判定器D的运行:
- $k=3$。需要检查所有长度小于3的字符串。
- 字符串列表为: ε (空串), a, aa。
- 循环开始:
- w = ε: 模拟 $M(\epsilon)$ 最多3步。
- 假设 $M(\epsilon)$ 在2步后停机了。继续下一个字符串。
- w = a: 模拟 $M(a)$ 最多3步。
- 假设 $M(a)$ 运行了1步,2步,但第3步时还未停机。
- 判定器 D 发现了一个满足条件的输入 'a'。
- D 立即接受 $\langle M, 3 \rangle$ 并停机。
- 另一个例子:
- 设输入为 $\langle M', k=5 \rangle$。$M'$ 的 $\Sigma = \{0, 1\}$。
- 判定器D的运行:
- $k=5$。需要检查所有长度 < 5 的字符串($\epsilon, 0, 1, 00, 01, ..., 1111$)。
- D 逐个模拟 $M'$ 在这些字符串上的运行,每种最多5步。
- 假设对于所有这些短字符串,$M'$ 都在5步内停机了(例如, $M'(\epsilon)$ 在2步停机, $M'(0)$ 在4步停机, $M'(1)$ 在4步停机, ...)。
- 当D检查完所有长度小于5的字符串后,发现没有一个能让 $M'$ 运行到第5步。
- D 拒绝 $\langle M', 5 \rangle$ 并停机。
- 误以为需要检查无限输入: 最大的易错点是认为需要检查所有可能的输入 $w$。关键的洞见是,一个 $k$ 步的计算过程只能被有限的信息影响,因此可以用有限的短字符串来代表所有可能的输入情况。
- 模拟步数的界限: 模拟必须有步数限制($k$ 步)。否则,如果 $M$ 在某个 $w$ 上永不停机,判定器 $D$ 也会陷入无限模拟。
- 字符串长度的界限: 为什么是长度小于 $k$?因为一个 $k$ 步的计算最多访问 $k$ 个格子,这 $k$ 个格子的内容可以由一个长度为 $k-1$ 的输入加上空白符来完全确定。所以检查到长度 $k-1$ 就足够了。
我们通过构造一个判定器 $D$ 证明了语言 $L$ 是可判定的。$D$ 的核心策略是有界模拟。它利用了图灵机在有限步数内只能访问有限空间的原理,将一个看似需要无限搜索的问题(“是否存在一个输入...”)转化为了一个在有限集合上进行的、有步数限制的模拟过程。因为模拟的字符串集合是有限的,且每次模拟的步数也是有限的,所以判定器 $D$ 保证在所有情况下都能停机,从而证明了 $L$ 的可判定性。
这道题是一个经典的关于可判定性的证明题。它的目的在于:
- 教授“有界模拟”的证明技巧: 这是一个非常重要的技巧,用于处理那些量词为“存在”但范围看似无限的语言。
- 加深对图灵机计算过程的理解: 强调计算的局部性原则——有限步的计算只能依赖于有限的信息。
- 区分可判定性与不可判定性: 这个问题是可判定的。它与之后会学到的停机问题($A_{TM}$)形成对比。停机问题没有步数限制 $k$,因此不能用有界模拟来判定。
这个问题就像在问:“我设计的这个机器人程序(M),有没有可能让它连续工作100个指令周期(k=100)而不死机?”
- 你的判定方法(判定器D):
- 你不需要把它放到所有可能的工作环境(无限输入)里去测试。
- 你意识到,在100个周期内,机器人最多只能和它周围100米内的东西فاعل。
- 所以,你只需要在一些小范围的、有代表性的测试环境里(长度小于k的字符串)测试它。
- 在每个测试环境里,你都只让它跑100个周期。
- 如果在某个测试环境里,它成功跑满了100个周期还没死机,你就回答:“是的,它有可能跑这么久。”(接受)
- 如果在所有你设置的小测试环境里,它都在100个周期内就早早死机了,你就得出结论:“不,它在任何环境下都撑不过100个周期。”(拒绝)
你的这个测试流程本身是保证能在有限时间内完成的。
想象一部电影的制作。问题是:“这部电影(M)的剧情有没有可能延续至少90分钟(k=90)?”
你要做的不是去构思所有可能的剧情(无限输入),而是去分析电影的“规则”(M的转移函数)。你发现,根据电影的规则,任何剧情线索,如果在前90分钟内没有导致“大结局”(停机),那么这条线索所依赖的角色和场景数量是有限的。你只需要检查有限个“开头发”(短字符串),看看有没有任何一个开头能在90分钟内不导向结局。
- 你拿出秒表,把每个“开头”都播放一遍,但最多只看90分钟。
- 如果你发现有一个“开头”真的演了90分钟还没完,你就回答“是”。
- 如果所有你试过的“开头”都在90分钟内就放完了“剧终”字幕,你就回答“否”。
这个检查过程本身是有限的,所以问题是可判定的。
34 练习题4
📜 [原文10]
- 令 $L$ 为一种可识别语言。
定义 $9 / 10(\mathrm{L})=\left\{<x_{1} \# x_{2} \# \ldots \# x_{10}>\mid x_{1}, \ldots, x_{10}\right.$ 中至少有 9 个在 $L$ 中\}。证明可识别语言在 9/10 运算下是封闭的。给出高层和实现级解决方案。
这道题要求我们证明,如果 $L$ 是一个可识别语言,那么经过 9/10 运算后得到的新语言 $9/10(L)$ 也是可识别的。我们需要从高层和实现级两个层面给出证明。
- 语言定义:
- $L$ 是可识别的,意味着存在一个图灵机 $M$ 识别它。
- $9/10(L)$ 的输入是10个用#分隔的字符串 $\langle x_1\#x_2\#...\#x_{10} \rangle$。
- 该输入属于 $9/10(L)$ 的条件是:这10个字符串中,至少有9个属于语言 $L$。
- 证明思路:
我们需要构造一个新的图灵机 $M'$ 来识别 $9/10(L)$。由于 $L$ 只是可识别的,这意味着 $M$ 在处理不属于 $L$ 的字符串时可能会永不停机。这就要求我们必须使用交替模拟(Dovetailing)的技巧。
3.4.1 高层描述
高层描述关注算法逻辑,不关心实现细节。
判定器 $M'$ 的高层描述:
在输入 $w = \langle x_1\#x_2\#...\#x_{10} \rangle$ 上:
1. 并行模拟: 并行地在所有10个子字符串 $x_1, x_2, \dots, x_{10}$ 上模拟图灵机 $M$。
2. 计数与接受: 维护一个计数器,初始为0。每当任何一个对 $x_i$ 的模拟进入接受状态时,就将计数器加一。
3. 检查条件: 如果计数器的值达到了9,立刻停机并接受输入 $w$。
为什么这个高层描述是正确的?
- 如果 $w \in 9/10(L)$: 这意味着至少有9个 $x_i$ 属于 $L$。由于 $M$ 识别 $L$,对于这9个(或更多)字符串, $M$ 的模拟最终都会进入接受状态。因此,我们的计数器最终会达到9,从而 $M'$ 会接受 $w$。
- 如果 $w \notin 9/10(L)$: 这意味着属于 $L$ 的字符串数量少于9个(最多8个)。因此,$M$ 最多只会在8个模拟中接受。计数器永远也达不到9。那些不属于 $L$ 的模拟可能会拒绝或永不停机,但这不影响计数器的值。因此,$M'$ 永远不会接受 $w$。
- 结论: $M'$ 识别 $9/10(L)$。
3.4.2 实现级描述
实现级描述需要说明如何用图灵机(特别是多带图灵机)来实现上述高层逻辑。
使用一个11带图灵机的实现级描述:
- 纸带1: 输入带,包含原始输入 $w$。
- 纸带2 - 纸带11: 10条工作带,分别用于模拟 $M$ 在 $x_1, x_2, \dots, x_{10}$ 上的运行。
判定器 $M'$ 的实现级描述:
在输入 $w = \langle x_1\#x_2\#...\#x_{10} \rangle$ 上:
1. 初始化:
a. 扫描纸带1,将子字符串 $x_1$ 复制到纸带2, $x_2$ 复制到纸带3,...,$x_{10}$ 复制到纸带11。
b. 在纸带1的某个空白区域设置一个计数器,例如写入一个'0'。
2. 交替模拟循环:
a. For i = 1 to 10:
i. 在纸带(i+1) 上,模拟 $M$ 对 $x_i$ 运行一步。
ii. 检查这次模拟是否使 $M$ 进入了接受状态。
iii. 如果是,并且这条纸带之前没有被标记为“已接受”,则:
- 在纸带1上找到计数器,将其加一。
- 检查计数器的值是否等于9。如果是,停机并接受 $w$。
- 为了防止重复计数,可以在纸带(i+1) 的开头做一个标记,表示这个子问题已经解决了。
b. 返回步骤 2a,开始新一轮的交替模拟。
为什么这个实现是正确的?
这个实现级描述就是高层描述中“并行模拟”的具体化。通过使用10条独立的纸带,并在它们之间轮流执行模拟步骤,我们实现了交替模拟。这确保了即使某个 $M(x_i)$ 的模拟陷入无限循环,其他9个模拟仍然可以继续进行。只要有9个模拟成功接受,我们的计数器就能达到9,从而整个机器 $M'$ 就能正确地接受输入。如果接受的模拟少于9个,$M'$ 就会一直在这个循环中运行下去(或直到所有非接受的模拟都拒绝),但绝不会接受。
- 设 $L = \{w \in \{a,b\}^* \mid w \text{ 包含 } aa \}$。这是一个正则语言,当然也是可识别的。
- 输入 $w = \langle aa\#ab\#bb\#aa\#...\#aa \rangle$,其中有9个aa和1个bb。
- $M'$ 的运行:
- 初始化: 10条工作带上分别放好了 aa, ab, bb, aa, ...
- 循环:
- 模拟 $M(aa)$ 一步。
- 模拟 $M(ab)$ 一步。
- 模拟 $M(bb)$ 一步。
- ...
- $M$ 在 aa 上的模拟会很快接受。$M$ 在 ab 和 bb 上的模拟会在扫描完字符串后拒绝(或停在非接受状态)。
- 随着交替模拟的进行,每当一个对 aa 的模拟完成时,计数器就会加一。
- 当第9个对 aa 的模拟完成并接受时,计数器从8变为9。
- 此时,$M'$ 立刻停机并接受整个输入 $w$,甚至不需要等待对 ab 和 bb 的模拟完成。
- 忘记交替模拟: 这是最严重的错误。如果采用顺序模拟(先完成 $M(x_1)$,再完成 $M(x_2)$ ...),一旦遇到一个不属于 $L$ 且导致 $M$ 永不停机的 $x_i$,整个 $M'$ 就会被卡住。
- 重复计数: 如果一个模拟接受了,需要有机制防止在后续的循环中重复为其增加计数。可以在对应纸带上做个标记,或者用一个额外的纸带记录哪些任务已经完成。
- 单带图灵机实现: 虽然题目允许使用多带图灵机,但值得思考如何用单带图灵机实现。这会复杂得多,需要在单条纸带上划分出10个“轨道”来存储10个子串和它们的模拟状态,并在这些轨道之间来回移动带头,手动实现交替。这能做到,但极其繁琐,也证明了多带图灵机在简化设计上的价值。
本题通过构造一个图灵机 $M'$ 证明了可识别语言类在 9/10 运算下是封闭的。
- 高层来看,算法并行模拟 $M$ 在10个子串上的运行,并对接受的个数进行计数。
- 实现级来看,这个并行过程可以通过一个多带图灵机进行交替模拟来具体实现,从而规避了某些模拟可能永不停机的问题。
- 核心技巧是交替模拟(Dovetailing),这是处理多个可能无限的计算任务的标准方法。
- 练习封闭性证明: 这是一种典型的封闭性证明题,要求学生掌握通过构造法证明语言类封闭性的套路。
- 应用交替模拟: 进一步强化在可识别语言场景下使用交替模拟的必要性和方法。
- 连接不同抽象层次: 要求学生同时给出高层和实现级描述,有助于他们理解理论算法如何转化为具体的机器操作。
你是一个项目经理,手下有10个程序员(10个模拟过程)。你的任务是,只要有9个或更多的程序员完成了他们的任务(进入接受状态),你就可以宣布整个项目成功。
- 错误的做法: 你挨个找程序员,死死地等着第一个程序员完成,再去找第二个... 如果第一个程序员遇到了一个无解的bug(永不停机),你就会永远等下去,项目永远无法成功。
- 正确的做法(交替模拟): 你在办公室里巡视,先花5分钟看看第一个程序员的进展,然后花5分钟看第二个,...,一轮过后,再从第一个开始。每当有程序员举手说“我完成了!”,你就在白板上画一个“正”字。当“正”字达到9个时,你立刻向老板汇报项目成功。
想象有10匹马在参加一场特殊的赛跑。终点线是“接受状态”。有些马可能跑得特别慢,甚至可能在路上迷路了再也回不来(永不停机)。你的任务是,一旦有9匹马冲过终点线,就立刻鸣枪庆祝。你不需要等最后一匹马,也不需要管那些迷路的马。交替模拟就像你的眼睛在10条赛道上来回扫视,而不是只盯着一条赛道看。
35 练习题5
📜 [原文11]
- 令 $L$ 为一种可识别语言。
定义 $\mathrm{m} / \mathrm{n}(\mathrm{L})=\left\{<\left(m, n, x_{1} \# x_{2} \# \ldots \# x_{n}\right)>\mid x_{1}, \ldots, x_{n}\right.$ 中至少有 m 个在 $L$ 中\}。证明可识别语言在 m/n 运算下是封闭的。给出一种高层实现。
这道题是上一题的泛化版本。不再是固定的9和10,而是任意给定的 $m$ 和 $n$。我们需要证明可识别语言对这个更通用的 m/n 运算也是封闭的。
- 语言定义:
- $L$ 是一个可识别语言,被图灵机 $M$ 识别。
- m/n(L) 的输入是一个元组 $\langle (m, n, x_1\#...\#x_n) \rangle$。
- 输入属于 m/n(L) 的条件是:在 $n$ 个子字符串 $x_1, \dots, x_n$ 中,至少有 $m$ 个属于语言 $L$。
- 证明思路:
我们同样需要构造一个新的图灵机 $M'$ 来识别 m/n(L)。由于 $m$ 和 $n$ 是输入的一部分,而不是固定的常数,$M'$ 必须能动态地处理任意数量的子串和任意的目标计数值。
高层描述:
判定器 $M'$ 的高层描述:
在输入 $w = \langle (m, n, x_1\#x_2\#...\#x_n) \rangle$ 上:
- 解析输入: 首先,解析输入 $w$,提取出数字 $m$ 和 $n$,并识别出 $n$ 个子字符串 $x_1, x_2, \dots, x_n$。
- 并行模拟: 并行地在所有 $n$ 个子字符串 $x_1, x_2, \dots, x_n$ 上模拟图灵机 $M$。
- 计数与接受: 维护一个接受计数器 accept_count,初始为0。每当任何一个对 $x_i$ 的模拟进入接受状态时,就将 accept_count 加一。
- 检查条件: 在每次计数器增加后,都检查 accept_count 的值是否等于 $m$。如果等于 $m$,立刻停机并接受输入 $w$。
为什么这个高层描述是正确的?
这个逻辑与练习题4完全相同,只是将固定的9和10换成了变量 $m$ 和 $n$。
- 如果 $w \in m/n(L)$: 至少有 $m$ 个 $x_i$ 属于 $L$。这些 $x_i$ 上的模拟最终都会被 $M$ 接受。因此,accept_count 最终会达到 $m$,$M'$ 会接受 $w$。
- 如果 $w \notin m/n(L)$: 属于 $L$ 的子字符串数量严格小于 $m$。因此 accept_count 永远无法达到 $m$。$M'$ 永远不会接受 $w$。
- 结论: $M'$ 识别 m/n(L)。
如何用图灵机实现这个高层描述?
虽然题目只要求高层描述,但我们可以思考一下其实现。
- 需要一个能处理任意 $n$ 个并行任务的图灵机。一个固定的 $k$ 带图灵机无法胜任,因为 $n$ 是变量。
- 我们需要一个能模拟无限带或动态数量带的图灵机。这可以通过在单条纸带上使用复杂的编码来实现。
- 单带实现思路:
- 纸带布局: 将单条纸带划分为多个部分。例如:
- #
# # # #...# #accept_count# 用来存储第 $i$ 个模拟的状态,包括 $x_i$ 的内容和 $M$ 在其上的模拟状态(如 $M$ 的当前状态、带头位置等)。
- #
- 解析输入: $M'$ 首先读取 $m$ 和 $n$,并将 $n$ 个子串 $x_i$ 设置到对应的
区域。 - 交替模拟循环:
a. $M'$ 的带头从左到右扫描整个纸带。
b. 当经过 <xi_config> 区域时,它读取该模拟的当前状态,并根据 $M$ 的转移函数模拟 $M$ 运行一步,然后更新 <xi_config> 区域。
c. 如果这次模拟使 $M$ 进入接受状态,并且该区域没有被标记过“已接受”,$M'$ 就移动到 accept_count 区域,将其加一。
d. 然后,$M'$ 检查 accept_count 是否等于 $m$。如果是,接受。
e. 完成对所有 $n$ 个配置的一步模拟后,将带头移回左端,开始新一轮的扫描。
这个单带实现是复杂但可行的,它证明了即使面对动态数量的并行任务,图灵机模型依然有能力处理。
- 设 $L = A_{DFA}$ (DFA的接受问题,可判定语言)。$M$ 是识别 $L$ 的图灵机。
- 输入 $w = \langle (m=2, n=3, \langle D_1, w_1 \rangle \# \langle D_2, w_2 \rangle \# \langle D_3, w_3 \rangle) \rangle$
- 其中 $D_1(w_1)$ 接受, $D_2(w_2)$ 拒绝, $D_3(w_3)$ 接受。
- 这个输入应该被接受,因为有2个(=m)子问题属于 $L$。
- $M'$ 的运行 (高层):
- 解析出 $m=2, n=3$ 和三个子问题。
- 并行模拟 $M(\langle D_1, w_1 \rangle)$, $M(\langle D_2, w_2 \rangle)$, $M(\langle D_3, w_3 \rangle)$。
- 交替进行:
- ... 经过一些步骤 ... $M(\langle D_1, w_1 \rangle)$ 模拟完成并接受。accept_count 变为1。
- 1不等于 $m=2$,继续模拟。
- ... 经过一些步骤 ... $M(\langle D_2, w_2 \rangle)$ 模拟完成并拒绝。accept_count 不变。
- ... 经过一些步骤 ... $M(\langle D_3, w_3 \rangle)$ 模拟完成并接受。accept_count 变为2。
- 检查: accept_count (2) 等于 $m$ (2)。
- $M'$ 立即停机并接受。
- $m, n$ 作为变量: 必须认识到 $m$ 和 $n$ 不是固定的,算法必须能处理任意的 $m, n$ 值。这意味着不能使用固定数量的纸带(除非证明一个2带或3带图灵机足以模拟这个过程,而这是可以做到的,但非常复杂)。
- $m > n$: 如果输入的 $m$ 大于 $n$,那么条件“至少有 $m$ 个”永远不可能满足。算法应该能正确处理这种情况,即永远不接受。我们的算法设计是正确的,因为 accept_count 最多只能达到 $n$,永远到不了 $m$。
- $m = 0$: 如果 $m=0$,那么条件“至少有0个”总是满足的。$M'$ 应该在解析输入后立即接受。我们的高层描述在 accept_count 初始化为0时,如果 $m=0$,第一次检查就会成功,所以也是正确的。
本题是练习题4的泛化,要求证明可识别语言对 m/n 运算封闭。
- 我们给出了一个高层的图灵机算法 $M'$,它能正确识别 m/n(L)。
- 该算法的核心思想依然是并行/交替模拟 $M$ 在所有 $n$ 个子串上的运行,并用一个计数器来追踪成功接受的模拟数量,一旦达到阈值 $m$ 就接受。
- 与上一题不同的是,$M'$ 必须能处理动态的 $m$ 和 $n$,这在实现层面提出了更高的要求,但从高层逻辑和可计算性的角度来看,问题本质是一样的。
- 考察泛化能力: 测试学生是否能将从具体例子(9/10)中学到的原理应用到更一般化的情况(m/n)。
- 加深对图灵机能力的理解: 引导学生思考图灵机如何处理变量参数(如 $m, n$),这触及了通用计算的概念。一个图灵机不仅能解决一个特定的问题,还能解决一类由参数定义的问题。
- 强调高层描述的重要性: 在问题变得更复杂(如需要处理动态数量的并行任务)时,高层描述让我们能够专注于问题的可计算性核心,而暂时搁置繁琐的实现细节。
你是一个质检员,面前有一条传送带,上面有 $n$ 箱产品。你的任务是,只要你发现其中有 $m$ 箱是合格的,就可以让整批货通过。
- 你有一个清单,上面写着今天的 $m$ 和 $n$ 是多少。
- 你不能只检查一箱,等它出结果,再查下一箱。因为有的箱子可能需要非常复杂的、耗时很久的检测(永不停机)。
- 你的策略: 你同时打开所有 $n$ 箱,给每箱都分配一个初级检测员。你自己在他们之间来回巡视,每个人都只让他做一小步检测。
- 每当有检测员向你报告“我这箱合格了!”,你就在你的计数板上加一笔。
- 你时刻盯着计数板,一旦上面的数字达到了 $m$,你就立刻按下“通过”按钮,整批货出库。
想象你在玩一个大型策略游戏,你需要完成一个“联盟胜利”。胜利条件是:在你的 $n$ 个盟友中,至少有 $m$ 个盟友建造了“奇迹”。
- 每个盟友建造“奇迹”的速度不一样,有的甚至可能因为资源不足而永远建不完(永不停机)。
- 你不会只盯着一个盟友,等他建完。
- 你的游戏界面(图灵机)可以让你同时看到所有盟友的进度条(并行模拟)。
- 每当一个盟友的“奇迹”进度条达到100%(进入接受状态),你的“胜利点数”(accept_count)就加一。
- 只要“胜利点数”达到了游戏设定的 $m$ 值,屏幕上就会立刻弹出“胜利!”的窗口。
36 练习题6
📜 [原文12]
- 令 CYCLE $=\{\langle G\rangle \mid G$ 是一个包含至少一个圈的图\}。回想一下,圈(cycle)是一个由边连接的顶点序列,其起点和终点在同一个顶点。证明 CYCLE 是可判定的。
这道题要求我们证明语言 CYCLE 是可判定的。这意味着我们需要设计一个算法(可以被一个图灵机实现),该算法对于任何输入的图 $G$,都能在有限时间内停机,并准确地回答 $G$ 中是否存在圈。
- 语言定义:
- CYCLE 是一系列图的编码 $\langle G \rangle$。
- 一个图 $G$ 的编码 $\langle G \rangle$ 属于 CYCLE,当且仅当 $G$ 中至少包含一个圈。
- 圈 (Cycle): 一个路径,其起点和终点是同一个顶点,并且路径中至少包含一条边。(对于简单图,通常要求圈的长度至少为3)。
- 证明思路:
我们需要给出一个判定器 $D$ 的算法。输入是图 $G$ 的编码,例如邻接矩阵或邻接表。既然要判定,算法必须保证对任何图都停机。图是有限的(有限的顶点和边),所以我们可以系统地搜索。
一个检测圈的经典算法是深度优先搜索 (DFS)。
使用深度优先搜索 (DFS) 的高层算法:
判定器 $D$ 的高层描述:
在输入 $\langle G \rangle$ 上,其中 $G=(V, E)$ 是一个图,V是顶点集,E是边集:
- 初始化一个空的“已访问”集合 visited,用于在单次DFS中记录路径上的顶点。
- 初始化一个空的“完全探索过”集合 fully_explored,用于记录已经完成DFS的顶点,避免重复工作。
- 对图中的每一个顶点 u in V:
a. 如果 u 在 fully_explored 中,跳过,处理下一个顶点。
b. 调用一个 DFS 辅助函数 DFS-Visit(u, parent=null)。DFS-Visit 的逻辑如下:
i. 将当前顶点 v 添加到 visited 集合中(表示 v 在当前搜索路径上)。
ii. 对于 v 的每一个邻居 w:
- 如果 w 在 visited 集合中,并且 w 不是 v 的父节点(对于无向图),那么我们找到了一个返祖边 (back edge),这意味着图中存在一个圈。立即停机并接受。
- 如果 w 不在 visited 集合中,递归调用 DFS-Visit(w, parent=v)。如果在任何递归调用中发现了圈(即返回“接受”),则将“接受”信号向上传递,最终停机并接受。
iii. 当一个顶点的所有邻居都探索完毕后,将它从 visited 集合中移除(回溯),并加入 fully_explored 集合。
- 如果遍历了所有顶点,并且所有DFS调用都正常结束而没有找到圈,那么图中不存在圈。停机并拒绝。
为什么这个算法是一个判定器?
- 图 $G$ 的顶点数 $|V|$ 和边数 $|E|$ 都是有限的。
- 主循环(步骤3)最多执行 $|V|$ 次。
- DFS 算法(DFS-Visit)会访问每个顶点和每条边最多一到两次(取决于图的表示法和有向/无向)。visited 和 fully_explored 集合确保了没有无限循环。
- 总的计算步数是关于 $|V|$ 和 $|E|$ 的多项式级别,例如 $O(|V|+|E|)$。
- 因此,该算法对任何有限图输入,总是在有限时间内停机并给出正确的“接受”或“拒绝”答案。所以 CYCLE 是可判定的。
- 示例1:有圈的图
- $G = (V=\{1,2,3\}, E=\{(1,2), (2,3), (3,1)\})$ (一个三角形)
- 判定器D的运行:
- 从顶点1开始DFS。visited = {}, fully_explored = {}。
- DFS-Visit(1, null):
a. visited = {1}。
b. 看1的邻居,比如2。2不在visited中。
c. 递归调用 DFS-Visit(2, parent=1):
i. visited = {1, 2}。
ii. 看2的邻居,比如3。3不在visited中。
iii. 递归调用 DFS-Visit(3, parent=2):
- visited = {1, 2, 3}。
- 看3的邻居,有1和2。
- 邻居2是父节点,忽略。
- 邻居1在visited中,并且不是父节点。找到了返祖边 (3,1)! 这意味着路径 $1 \rightarrow 2 \rightarrow 3 \rightarrow 1$ 形成一个圈。
- 立即接受。
- 示例2:无圈的图(树)
- $G = (V=\{1,2,3\}, E=\{(1,2), (1,3)\})$
- 判定器D的运行:
- 从顶点1开始DFS。visited = {}, fully_explored = {}。
- DFS-Visit(1, null):
a. visited = {1}。
b. 看邻居2。2不在visited中。递归DFS-Visit(2, parent=1)。
i. visited = {1, 2}。2的邻居只有1,是父节点。探索完毕。
ii. 从visited移除2,将2加入fully_explored。visited={1}, fully_explored={2}。返回。
c. 看邻居3。3不在visited中。递归DFS-Visit(3, parent=1)。
i. visited = {1, 3}。3的邻居只有1,是父节点。探索完毕。
ii. 从visited移除3,将3加入fully_explored。visited={1}, fully_explored={2,3}。返回。
d. 1的所有邻居探索完毕。从visited移除1,将1加入fully_explored。
- 主循环检查下一个顶点,比如2。发现2在fully_explored中,跳过。
- 主循环检查顶点3,发现3在fully_explored中,跳过。
- 所有顶点都处理完毕,没有找到圈。拒绝。
- 有向图 vs 无向图:
- 在无向图中,当我们从 $v$ 访问邻居 $w$ 时,如果 $w$ 是 $v$ 的父节点(即我们刚刚从 $w$ 来到 $v$),这条边 $(v,w)$ 不算返祖边。必须判断 w != parent。
- 在有向图中,DFS的逻辑稍微不同。我们通常用三种颜色(白、灰、黑)来标记顶点状态(未访问、访问中、已完成)。如果DFS访问到一个灰色顶点,就说明有圈。
- 图不连通: 我们的算法通过遍历所有顶点来处理图不连通的情况。如果只从一个顶点开始DFS,可能会漏掉其他连通分量中的圈。
- 自环: 一个顶点到自身的边 $(v,v)$ 也是一个圈。DFS算法能检测到这种情况($v$的邻居包含$v$自身,而$v$已经在visited中)。
- 圈的定义: 题目中的定义“起点和终点在同一个顶点”比较宽松。在标准图论中,圈通常要求不重复顶点(除了起点终点)。DFS找到的返祖边保证了这一点。
我们证明了语言 CYCLE 是可判定的,因为存在一个总会停机的算法来解决它。
- 该算法基于深度优先搜索 (DFS),这是一种系统地遍历图的标准方法。
- 通过在DFS中记录当前路径上的顶点(visited集合),算法能够检测到“返祖边”,返祖边的存在等价于圈的存在。
- 由于图是有限的,DFS算法的运行时间是有限的,因此它构成了一个判定器。
- 练习可判定性证明: 这是另一个判定性证明的例子,但这次涉及的是一个常见的图论问题。
- 连接算法与可计算性理论: 这道题明确地展示了,一个在算法课上学到的具体算法(如DFS),可以直接作为证明一个语言可判定的依据。它强调了“可判定”等价于“存在一个能解决问题并保证停机的算法”。
- 巩固图论知识: 考察学生对图、圈、DFS等基本图论概念的理解。
检测图中的圈,就像在一个迷宫里寻找回路。
- 你是一个探险家,有一卷线(标记路径)和一本地图(记录去过的地方)。
- 你从一个路口出发,一边走一边放出你手中的线(将顶点加入visited)。
- 每到一个新的路口,你都先看看要走的路是不是通向一个你线上已经经过的地方。
- 如果你发现一条小路直接通向你身后线连着的某个旧路口(而不是你刚刚来的那个路口),你就知道你找到了一个环路!(返祖边)
- 如果你把一个路口的所有岔路都走完了(除了你来的路),发现都是死胡同或者已经彻底探索过的地方,你就会收回你的线,回到上一个路口,并在地图上把这个路口标记为“此路不通”(加入fully_explored)。
- 你把整个迷宫的所有路口都用这种方法探索一遍,如果始终没有发现环路,那就真的没有。这个过程虽然可能绕,但因为迷宫是有限的,你总能完成探索。
想象一个族谱。你要检查这个族谱里有没有“自己是自己的祖先”这种荒谬的情况(圈)。
- 你从某个人开始,往上追溯他的父亲、祖父、曾祖父...(DFS路径)。
- 你把追溯过的路径上的人名都记在一个小本子上(visited)。
- 如果在追溯过程中,你发现某个人的父亲竟然是你小本子上已经记下的某个人(不是他自己的儿子),那就出问题了,你找到了一个辈分上的圈。
- 这种系统性的追溯方法保证你能在有限时间内检查完整个有限的族谱。
4行间公式索引
1. 对图灵机M的7-元组形式化定义。
2. 对一个计算函数$f$的图灵机的描述,该函数根据输入$x$的奇偶性,分别计算$x/2$或$3x+1$。
54 讲义总结与核心概念回顾
本部分将对整个讲义的核心内容进行总结和回顾。讲义Handout 8A主要介绍了计算理论的基石——图灵机,并探讨了与之相关的可判定性和可识别性的概念。通过形式化定义、变体模型和一系列练习题,讲义旨在建立一个关于“什么是可计算的”以及“如何证明一个问题是可计算的”的坚实理解。
本部分是对整个讲义的概括,将分散在各个章节的知识点进行梳理和整合,帮助读者形成一个连贯的知识体系。
本总结部分的存在目的,是为了在详细解释了所有细节之后,提供一个宏观的视角,将关键概念串联起来,巩固学习效果,并揭示不同主题之间的内在联系。
这就像是读完一本厚书后,回顾一下书的目录和每一章的引言与结论。它帮助你整理思绪,将零散的情节和人物关系整合成一个完整的故事脉络,让你能清晰地向别人复述这本书讲了什么。
4.1 从有限到无限:图灵机的革命性
讲义的核心始于图灵机相较于旧模型(如DFA, PDA)的三个革命性突破:
- 无限纸带:提供了无限的内存,打破了有限自动机在存储能力上的根本限制。
- 读/写能力:允许机器在计算过程中修改其“内存”,这是执行真正意义上“计算”的基础,而不仅仅是识别模式。
- 双向移动:使得机器可以反复访问和处理数据,为需要来回参考信息的复杂算法提供了可能。
这三者共同构成了邱奇-图灵论题的基础,即任何直觉上可计算的函数都可以由一个图灵机来计算。
图灵机通过引入无限、可读写的内存和不受限制的数据访问方式,极大地扩展了计算模型的边界,定义了现代计算理论中“可计算”的范围。
本节总结的目的是提炼出图灵机模型最本质的强大之处,让读者牢记它与之前模型的根本区别,从而理解为何图灵机能成为计算理论的中心。
从DFA/PDA到图灵机,就像是从一个只能按顺序读一篇稿子并且记忆力有限的演讲者,升级成一个拥有无限长草稿纸、铅笔和橡皮的数学家。演讲者只能对稿子内容做简单的是非判断,而数学家则可以在草稿纸上进行任意复杂的推演和计算。
4.2 描述的三个层次:从形式到直觉
讲义通过三个层次来描述图灵机,展示了在不同场景下与图灵机打交道的方式:
- 形式化描述 (7-元组):最底层、最精确的定义,是理论的基石,但在实践中极其繁琐。
- 实现级描述:用自然语言描述带头的移动和纸带的操作,是在精确性和可读性之间的最佳平衡点,是设计算法时最常用的方式。
- 高层描述:用纯粹的算法思想来描述,完全忽略机器细节。这在讨论一个问题是否“可计算”时非常有用,让我们能专注于问题本身的核心逻辑。
根据任务的需要(理论证明、算法设计、可计算性分类),我们可以选择不同抽象层次的语言来描述图灵机,这体现了理论计算机科学中分层抽象的重要思想。
本节总结旨在让读者理解,与图灵机的“对话”可以是多层次的。不必拘泥于繁琐的形式化定义,而应根据目标灵活选用最合适的描述方式。
这如同描述如何开车:
- 高层描述:“从家开车去公司。”
- 实现级描述:“挂一档,踩油门,出小区右转,上主路后直行,在第三个红绿灯左转...”
- 形式化描述:“将右脚以20牛的力踩下右侧踏板,同时左手以...角度转动方向盘...”
我们通常使用实现级描述来教人开车,用高层描述来规划行程。
4.3 等价的变体:灵活性与计算能力
讲义介绍了两种重要的图灵机变体:
- 多带图灵机:拥有多条独立的纸带,极大地方便了需要并行处理、比较或存储多份数据的算法设计。它就像一个拥有多块草稿板的程序员。
- 非确定性图灵机 (NTM):允许一步有多种可能的走向,其“猜测并验证”的模型极大地简化了搜索类问题的算法设计。它就像一个能瞬间派出无数分身探索所有可能路径的侦探。
最关键的结论是:这些变体在计算能力上与最基础的单带确定性图灵机是等价的。它们能解决的问题集合完全相同,变体的优势在于提供更强大、更直观的算法设计工具,但并未突破“可计算”的边界。
图灵机的多种变体虽然在设计上更灵活、更强大,但它们并没有增加其根本的计算能力。这反过来证明了图灵机模型定义的“可计算性”是一个非常稳健和普适的概念。
本节总结的目的是强调计算能力等价性这一核心思想。读者应理解,使用多带或非确定性是为了“方便”,而不是为了解决“更难”的问题。这为后续P vs NP等复杂性问题的讨论埋下伏笔,那些问题关心的不是“能不能算”,而是“算得快不快”。
这就像高级编程语言(如Python)和汇编语言。用Python写程序远比用汇编简单方便(如同使用NTM),但计算机最终都要把Python代码翻译成底层的机器指令(如同模拟NTM的DTM)来执行。理论上,任何Python能做的事,只要有足够毅力,都可以用汇编完成。它们的“计算能力”是等价的。
4.4 可判定性与识别性:停机是关键
通过练习题,讲义深刻地揭示了两个核心概念的区别:
- 图灵可识别语言 (Turing-recognizable):存在一个图灵机,对于属于该语言的输入,它会接受;对于不属于的,它可能拒绝,也可能永不停机。
- 图灵可判定语言 (Turing-decidable):存在一个图灵机(称为判定器),对于任何输入,它总能在有限时间内停机,并给出明确的接受或拒绝。
关键区别:判定器必须对所有输入都保证停机。所有可判定语言都是可识别的,但反之不成立(例如,停机问题$A_{TM}$是可识别但不可判定的)。
“是否保证停机”是区分可判定性和可识别性的唯一标准。这个区别在设计处理可识别语言的算法时至关重要,并直接催生了“交替模拟”等技巧。
本节总结旨在巩固全讲义最重要的理论概念区分。理解这一区别是进入高级计算理论(如不可判定性、归约)的钥匙。
- 识别器就像一个只对好消息做出反应的科学家。如果实验成功(输入在语言中),他会立刻发表论文(接受)。如果实验失败(输入不在语言中),他可能会写一份失败报告(拒绝),也可能觉得还有希望而无休止地调整实验(永不停机)。
- 判定器则是一个严谨的审计员。对于任何账目(任何输入),他总能在规定时间内给出一个明确的“合规”(接受)或“不合规”(拒绝)的结论,绝不拖延。
4.5 证明技巧:构造、模拟与归约思想
讲义中的练习题集中展示了证明可判定性和封闭性的几种核心技巧:
- 直接构造 (Direct Construction):为问题设计一个具体的、保证停机的算法(如练习6用DFS检测圈)。这是证明可判定性最直接的方法。
- 交替模拟 (Dovetailing):在处理多个可能永不停机的计算时(如练习4、5),通过轮流模拟每一步来保证所有计算都有机会向前推进。这是证明可识别语言封闭性的关键技巧。
- 有界模拟 (Bounded Simulation):将一个看似无限的搜索问题(“是否存在一个输入...”)转化为一个在有限集合上的、有步数限制的有限过程(如练习3)。这是证明某些特定类型的语言可判定的巧妙方法。
计算理论中的证明很大程度上是构造性的。通过设计巧妙的图灵机算法,利用各种模拟技巧,我们可以形式化地证明一个问题的计算属性。
本节总结的目的是将练习题中隐含的通用证明方法论明确化。学生在未来遇到新的问题时,可以从这个“工具箱”中寻找合适的证明策略。
这些证明技巧就像是侦探的破案手法:
- 直接构造:现场证据确凿,直接推导出凶手。
- 交替模拟:有多个嫌疑人,但不能只盯一个。你需要同时调查所有人,一点点搜集线索,只要有一个人的证据链完整了,就可能破案。
- 有界模拟:推断凶手在作案的“黄金一小时”内,活动范围有限。你不需要搜查整个城市,只需要排查案发现场周围有限的区域和嫌疑人。
[[END_OF_RESPONSE]]所有解释内容已全部输出完毕。