11. 0.2 数学概念和术语
1.1 数学概念和术语
11.1 介绍
📜 [原文1]
正如任何数学学科一样,我们从讨论我们期望使用的基本数学对象、工具和符号开始。
这段话是本节的开场白,作用是告诉读者接下来要讲什么。它强调了在深入学习计算理论这门学科之前,首先需要打好“地基”。这个“地基”就是所有数学和形式化科学都依赖的一套共同语言和工具。
- 任何数学学科一样:这句话表明,我们现在要做的,是任何严谨的数学领域(如代数、几何、微积分)在开始时都会做的事情——定义基础。这为学习设置了一个严谨、规范的基调。
- 基本数学对象:这些是我们要研究和操作的核心“物品”。在本课程中,这些“对象”不是传统数学中的数字或图形,而更多是像集合、字符串、语言、图这样的抽象结构。它们是构建自动机、文法和算法的“积木”。
- 工具:这些是用来操作“数学对象”的方法和概念。例如,函数可以描述一种转换规则,关系可以描述对象之间的联系,布尔逻辑可以用来进行推理和判断。
- 符号:这指的是我们将使用的记法系统。数学符号是一种精确、无歧义的语言。例如,用 $\in$ 表示“属于”,用 $\cup$ 表示“并集”,这些符号能够简洁地传达复杂而精确的含义,避免了日常语言的模糊性。
本节将介绍计算理论中使用的基础数学概念、操作方法和记号。这是后续所有学习内容的基础,确保大家在同一个频道上交流。
建立共识。为了避免后续讨论中出现“你说的一加一和我说的不是一回事”这样的情况,必须在一开始就明确定义所有基本概念和符号。这是保证学科严谨性的前提。
这就像学习一门新语言(比如法语)时,我们不会直接去读小说。我们会先从最基础的字母表(符号)、单词(数学对象)和基本语法(工具)开始。只有掌握了这些,才能开始理解和构造复杂的句子和文章(也就是后续的理论和证明)。
想象一下你在一个木工坊里。在你开始建造一个复杂的家具(比如一个自动机模型)之前,工坊师傅会先带你熟悉一下工坊里的东西:
- 材料(数学对象):这是木板(集合),那是螺丝(元素),还有各种长度的木条(序列)。
- 工具(数学工具):这是锯子(函数),可以把木板切割成特定形状;这是尺子和角尺(关系),可以测量和确定角度;这是胶水(运算),可以把木块粘在一起。
- 蓝图上的符号(数学符号):图纸上的一个圆圈代表要钻孔,一个叉代表要切割。你必须认识这些符号,才能看懂蓝图,正确施工。
本节内容,就是这位师傅在带你熟悉整个工坊。
1.2 集合
12.1 集合的定义与表示
📜 [原文2]
集合是一组作为整体表示的对象。集合可以包含任何类型的对象,包括数字、符号,甚至其他集合。集合中的对象称为其元素或成员。集合可以通过几种方式正式描述。
一种方式是列出集合的元素并用花括号括起来。因此,集合
包含元素 7、21 和 57。
- 集合的本质:集合(Set)在数学上是一个非常基础的概念。可以把它理解成一个“袋子”或者一个“容器”。
- “一组作为整体表示的对象”:
- “一组对象”:说明集合里装着不止一个东西(当然也可以只装一个,或者一个都不装)。这些“东西”就是对象。
- “作为整体表示”:这是关键。我们关心的不是单个对象,而是把这一堆对象打包成的“一个”新东西,这个新东西就是集合。例如,$\{7, 21, 57\}$ 这三个数字打包在一起,形成了一个名为 $S$ 的实体。从此我们可以直接讨论 $S$ 这个整体,而不仅仅是 7、21、57 这三个独立的数字。
- 元素的类型:集合的强大之处在于它的包容性。
- 任何类型的对象:你可以把任何你能想到的东西放进集合。
- 数字:如 $\{1, 2, 3\}$。
- 符号:如 \{a, b, c\},这是计算理论中定义字母表的基础。
- 其他集合:这是集合论中一个稍微高级但非常重要的概念。一个集合的元素可以是另一个集合。例如,$A = \{1, 2\}$,$B = \{3, 4\}$,我们可以构造一个新的集合 $C = \{A, B\} = \{\{1, 2\}, \{3, 4\}\}$。注意,集合 $C$ 只有两个元素:集合A 和 集合B,而不是四个数字。
- 元素与成员:元素(element)和成员(member)是同义词,都指集合里装的那些“东西”。
- 描述方式1:列举法:这是最直观的表示方法。
- 花括号 {}:这是集合的标志性符号。看见花括号,就要想到“这是一个集合”。
- 列出元素:把集合里所有的成员都写在花括号里面。
- 逗号分隔:成员与成员之间用逗号隔开。
- 示例 $S = \{7, 21, 57\}$:这个表示法清晰地告诉我们,有一个名为 $S$ 的集合,它里面有且仅有 7, 21, 57 这三个元素。
- $S$: 这是一个大写字母,通常在数学中用来命名一个集合。它只是一个标签或名字,方便我们引用这个集合。
- $=$: 等号,表示 $S$ 这个名字指代的就是等号右边的内容。
- {}: 花括号,这是集合的“外包装”,声明里面的内容共同构成一个集合。
- 7, 21, 57: 这是集合 $S$ 的三个元素,它们是数字类型。
- ,: 逗号,用来分隔集合中的各个元素。
- 示例1:一个包含字符串的集合
一个名为 Fruits 的集合,包含三种水果的英文名:
Fruits = {"apple", "banana", "cherry"}
这个集合有3个元素,每个元素都是一个字符串。
- 示例2:一个包含混合类型元素的集合
一个名为 MixedBag 的集合,包含一个数字、一个符号和一个集合:
MixedBag = {1, 'a', {2, 3}}
这个集合有3个元素:
- 元素1: 数字 1
- 元素2: 符号 'a'
- 元素3: 集合 {2, 3}
- 元素和集合本身的区别:7 是一个数字,而 $\{7\}$ 是一个集合,这个集合里只有一个元素,那就是数字7。两者是完全不同的数学对象。
- 花括号的重要性:忘记写花括号,或者用错括号(如 () 或 []),就不是集合了。例如,(7, 21, 57) 代表一个序列或元组,而不是集合。
集合是一个装有各种对象(称为元素)的容器。最基本的表示方法是列举法:用花括号 {} 把所有元素包起来。
集合是数学中最基本的概念之一,是定义更复杂结构(如语言、自动机状态集等)的基石。在计算理论中,我们需要一个精确的方式来讨论“一组东西”,集合恰好提供了这个工具。
把集合想象成一个会员俱乐部的“会员名单”。
- 俱乐部本身就是集合(例如,$S$)。
- 名单上的每个名字就是元素(例如,7, 21, 57)。
- 你可以有一个只收录数字的俱乐部,也可以有一个什么人都收的俱乐部(混合类型)。
- 甚至可以有一个“俱乐部联合会”,它的会员是其他俱乐部(集合的集合)。
想象一个透明的、没有重量的塑料袋。
- 这个袋子就是集合。
- 你往里面放的任何东西(苹果、石头、一张纸、甚至另一个装了东西的小袋子)都是元素。
- 当你把一堆东西放进去并封上口时,你就得到了一个集合。你可以给这个袋子贴上标签(如 $S$),然后把它作为一个整体来移动或讨论。
12.2 集合的成员关系与子集
📜 [原文3]
符号 $\in$ 和 $\notin$ 表示集合成员身份和非成员身份。我们写 $7 \in\{7,21,57\}$ 和 $8 \notin\{7,21,57\}$。对于两个集合 $A$ 和 $B$,如果 $A$ 的每个成员也是 $B$ 的成员,我们说 $A$ 是 $B$ 的子集,写作 $A \subseteq B$。如果 $A$ 是 $B$ 的子集且不等于 $B$,我们说 $A$ 是 $B$ 的真子集,写作 $A \subsetneq B$。
- 成员关系(Membership)
- $\in$(属于):这个符号用来判断一个对象是否是某个集合的成员。它的形状像一个圆润的 'e',可以记成 "element of"(...的元素)。
- $7 \in \{7, 21, 57\}$ 的意思是:“7 是集合 $\{7, 21, 57\}$ 的一个成员”。这句话是真的。
- $\notin$(不属于):这个符号是 $\in$ 上加了一条斜杠,表示否定。
- $8 \notin \{7, 21, 57\}$ 的意思是:“8 不是集合 $\{7, 21, 57\}$ 的一个成员”。这句话也是真的,因为集合里没有8。
- 子集关系(Subset)
- $A \subseteq B$(子集):这个符号用来描述两个集合之间的“包含”关系。它表示集合A里的所有元素,在集合B里也都能找到。
- “如果A的每个成员也是B的成员”:这是子集的核心定义。要判断 $A \subseteq B$ 是否成立,你需要检查 $A$ 里的每一个元素,看它是否也在 $B$ 中。只要有一个不在,这个关系就不成立。
- $\subseteq$ 这个符号很形象,像一个等号 $=` 上面加了一个开口的 `$\subset$`,可以理解为“小于或等于”,即 `$A$` 或者比 `$B$` 小,或者和 `$B$ 完全一样。
- 真子集关系(Proper Subset)
- $A \subsetneq B$(真子集):这是一个更严格的子集关系。它要求 $A$ 是 $B$ 的子集,并且 $A$ 和 $B$ 不能是同一个集合。换句话说,$B$ 必须至少有一个元素是 $A$ 所没有的。
- “A是B的子集且不等于B”:这是真子集的核心定义。它有两个条件:1. $A \subseteq B$ 成立;2. 存在至少一个元素 $x$,使得 $x \in B$ 但 $x \notin A$。
- $\subsetneq$ 这个符号去掉了下面的横线,可以理解为“严格小于”,排除了相等的情况。
- $x \in S$:
- $x$: 一个对象(元素)。
- $\in$: “属于”符号。
- $S$: 一个集合。
- 整个表达式是一个命题(判断句),其值为真或假。
- $A \subseteq B$:
- $A, B$: 两个集合。
- $\subseteq$: “是...的子集”符号。
- 这个命题等价于:对于任意对象 $x$,如果 $x \in A$,那么一定有 $x \in B$。
- $A \subsetneq B$:
- $A, B$: 两个集合。
- $\subsetneq$: “是...的真子集”符号。
- 这个命题等价于:$A \subseteq B$ 且 $A \neq B$。
示例1:
令 $A = \{1, 2\}$, $B = \{1, 2, 3\}$, $C = \{1, 2\}$。
- 成员关系:
- $1 \in A$ (真)
- $3 \in B$ (真)
- $3 \in A$ (假),所以 $3 \notin A$ (真)
- 子集关系:
- $A \subseteq B$? 我们检查A的元素:1在B里,2在B里。所有元素都在。所以为 (真)。
- $A \subseteq C$? 我们检查A的元素:1在C里,2在C里。所有元素都在。所以为 (真)。
- $B \subseteq A$? 我们检查B的元素:1在A里,2在A里,但3不在A里。所以为 (假)。
- 真子集关系:
- $A \subsetneq B$? 首先 $A \subseteq B$ (真),且 $A \neq B$ (因为B有3而A没有)。所以为 (真)。
- $A \subsetneq C$? 首先 $A \subseteq C$ (真),但是 $A = C$。不满足“不等于”的条件。所以为 (假)。
示例2:空集与自身
令 $E = \emptyset = \{\}$ (空集), $F = \{a, b\}$。
- $E \subseteq F$? 定义是“E的每个成员也是F的成员”。因为E没有任何成员,所以这个条件“对于E的每个成员”都自动满足了(这种叫“空洞真理”)。所以,空集是任何集合的子集,$E \subseteq F$ (真)。
- $F \subseteq F$? F的每个成员(a和b)当然也是F的成员。所以,任何集合都是其自身的子集,$F \subseteq F$ (真)。
- $E \subsetneq F$? $E \subseteq F$ (真),且 $E \neq F$ (真)。所以 $E \subsetneq F$ (真)。
- $F \subsetneq F$? $F \subseteq F$ (真),但 $F = F$。不满足“不等于”的条件。所以 $F \subsetneq F$ (假)。
- $\in$ vs $\subseteq$:这是初学者最常见的混淆。$\in$ 连接的是 元素 和 集合,而 $\subseteq$ 连接的是 两个集合。
- $A = \{1, 2\}$,$B = \{\{1, 2\}, 3\}$。
- $A \in B$ 是真的,因为集合 $A$ 本身是集合 $B$ 的一个元素。
- $A \subseteq B$ 是假的,因为 $A$ 的元素 1 和 2 并不在 $B$ 中($B$ 中只有 $\{1, 2\}$ 和 3)。
- 空集 $\emptyset$:$\emptyset$ 是一个集合。$x \in \emptyset$ 永远是假的。但 $\emptyset \subseteq S$ 对于任何集合 $S$ 永远是真的。
- 子集和真子集的细微差别:如果题目要求证明 $A \subseteq B$,你不需要关心 $A$ 和 $B$ 是否相等。但如果要求证明 $A \subsetneq B$,你就必须额外证明它们不相等。
$\in$ 和 $\notin$ 用来判断一个对象是否在集合内。$\subseteq$ 和 $\subsetneq$ 用来判断一个集合是否被另一个集合所包含,其中 $\subsetneq$ 要求更严格,不允许两者相等。
成员关系和子集关系是讨论集合时最基本、最常用的两种关系。它们让我们能够精确地比较和关联不同的集合,这在定义语言的包含关系、状态的划分等场景中至关重要。
继续用俱乐部会员的比喻:
- 张三 $\in$ 篮球俱乐部: 张三是篮球俱乐部的会员。(元素-集合关系)
- 篮球队首发阵容 $\subseteq$ 篮球队全体成员: 首发阵容这个小团体(一个集合)里的每一个人,都属于篮球队全体成员这个大团体(另一个集合)。(集合-集合关系)
- 篮球队首发阵容 $\subsetneq$ 篮球队全体成员: 首发阵容是大团体的一部分,但不是全部,因为还有替补队员。(真子集关系)
想象两个用粉笔画在的操场上的圆圈,一个大一个小。
- $\in$: 一个人(元素)站在某个圈(集合)里。
- $\subseteq$: 小圈(集合A)完全画在了大圈(集合B)的内部。这包括小圈和大圈重合的情况。
- $\subsetneq$: 小圈(集合A)完全画在了大圈(集合B)的内部,并且小圈没有把大圈填满,大圈里还有小圈外的空间。
12.3 集合的性质:无序性与互异性
📜 [原文4]
描述集合的顺序无关紧要,成员的重复也无关紧要。通过写作 $\{57,7,7,7,21\}$ 得到相同的集合 $S$。如果我们要考虑成员出现的次数,我们将该组称为多重集而不是集合。因此 $\{7\}$ 和 $\{7,7\}$ 作为多重集是不同的,但作为集合是相同的。一个无限集包含无限多个元素。我们无法列出无限集的所有元素,所以我们有时使用“...”符号表示“永远继续序列”。因此,我们将自然数集 $\mathcal{N}$ 写为
整数集 $\mathcal{Z}$ 写为
- 集合的两大特性
- 无序性 (Unordered):在一个集合中,元素的排列顺序是无关紧要的。$\{a, b, c\}$ 和 $\{c, a, b\}$ 是完全相同的集合。这就像一个袋子里装了三个球,你伸手进去摸,没有“第一个”或“最后一个”的概念。
- 互异性 (Distinct):集合中的每个元素都是独一无二的。如果你尝试在一个集合中放入两个相同的元素,它们会自动“合并”成一个。所以,写 $\{7, 7, 21\}$ 是可以的,但它表达的意思和 $\{7, 21\}$ 完全一样。重复的元素不增加集合的“大小”或改变其内容。
- 示例的解释
- $\{57, 7, 7, 7, 21\}$ 和 $S = \{7, 21, 57\}$ 是相同的集合。为什么?
- 无序性:$\{57, 7, 21\}$ 和 $\{7, 21, 57\}$ 只是顺序不同,所以是同一个集合。
- 互异性:$\{57, 7, 7, 7, 21\}$ 中的重复的 7 被忽略,它实际上就是 $\{57, 7, 21\}$。
- 结合两者,它们都表示包含7, 21, 57这三个元素的集合。
- 多重集 (Multiset)
- 这是一个与集合不同的概念,有时也叫“袋集”(bag)。
- 多重集允许元素重复,并且重复的次数是有意义的。
- $\{7\}`` 和 `$\{7,7\} 作为多重集是不同的。前者包含一个7,后者包含两个7。
- 但作为集合,根据互异性,它们是相同的,都等价于 $\{7\}。
- 无限集 (Infinite Set)
- 当一个集合的元素个数是无限的,我们称之为无限集。
- 显然,我们无法通过列举法写出所有元素。
- 省略号 “...”:这是一个非正式但广泛接受的符号,用来表示一个明显的序列在无限延伸。
- 自然数集 $\mathcal{N}$: $ \{1, 2, 3, \ldots\} $。这里的 ... 意味着“按照加1的规律一直下去,永不停止”。(注意:在不同上下文中,自然数有时包含0,但本书约定从1开始)。
- 整数集 $\mathcal{Z}$: $\{ \ldots, -2, -1, 0, 1, 2, \ldots \}$。这里的 ... 用了两次,表示向正负两个方向无限延伸。
- {}: 花括号,表示这是一个集合。
- 1, 2, 3: 列举了集合的前几个元素。
- ,: 分隔符。
- \ldots: 省略号 (ellipsis),表示“以此类推”。它暗示了一个读者应该能理解的模式(在这里是连续的整数)。这个模式会无限持续下去。
- {}: 集合的标志。
- \ldots (在左边): 表示在负数方向上无限延伸。
- -2, -1, 0, 1, 2: 给出了一段中心区域的元素,以明确模式。
- \ldots (在右边): 表示在正数方向上无限延伸。
- $\mathcal{N}$ 和 $\mathcal{Z}$: 这些是标准数学符号,$\mathcal{N}$ (来自 Natural) 代表自然数集,$\mathcal{Z}$ (来自德语 Zahlen,意为“数”) 代表整数集。使用这些符号可以非常简洁地指代这些重要的无限集。
- 无序性与互异性示例
- 令 $A = \{'c', 'a', 't'\}$。
- 令 $B = \{'t', 'a', 'c', 't'\}$。
- 问:$A` 和 `$B$ 相等吗?
- 解答:是的。首先看 $B$,根据互异性,重复的 't' 被忽略,所以 $B$ 等价于 $\{'t', 'a', 'c'\}$。然后根据无序性,$\{'t', 'a', 'c'\}$ 和 $\{'c', 'a', 't'\}$ 只是元素顺序不同,所以它们是同一个集合。因此 $A = B$。
- 多重集示例
- 考虑一次投票,候选人是 "A" 和 "B"。投票结果是:A, A, B。
- 如果用集合来表示投票结果,是 $\{"A", "B"\}$,这丢失了 "A" 得了两票这个信息。
- 如果用多重集来表示,是 $\{"A", "A", "B"\}$,这准确地反映了投票情况。
- 误将序列的顺序性用于集合:在编程中,数组/列表是有序的,[1, 2] 和 [2, 1] 是不同的。但数学上的集合 $\{1, 2\}` 和 `$\{2, 1\}` 是完全相同的。必须时刻提醒自己当前讨论的是集合还是序列。
- 省略号的歧义性:虽然 ... 很方便,但它依赖于上下文。$\{1, 2, \ldots, 100\}`` 很清晰,但 `$\{1, 2, \ldots\}$`可能指自然数,也可能指正整数,或所有2的幂`$\{1, 2, 4, 8, \ldots\}$。在严谨的证明中,最好使用更精确的描述法,比如后面的“规则描述法”。
- 自然数集是否包含0:这是一个历史遗留问题,在不同数学分支和教科书中定义不同。计算机科学中通常包含0(因为数组索引、计数等从0开始很方便),而数论中通常不包含。本书明确 $\mathcal{N} = \{1, 2, 3, \ldots\}$,我们在阅读本书时就遵循这个约定。
集合具有无序性(元素的顺序不重要)和互异性(重复的元素只算一个)。如果需要考虑顺序或重复次数,我们应该使用序列或多重集。对于无法一一列举的无限集,我们常用省略号 ... 来示意其无限延伸的模式。
明确集合的这两大基本性质,是为了与其它数据结构(如序列、元组)进行区分。在计算理论中,我们经常需要处理“一堆东西”,有时候我们关心顺序(如一个字符串中的字符顺序),有时候我们不关心(如一个自动机的所有可能状态)。集合为我们提供了“不关心顺序和重复”这一场景下的精确数学工具。
- 集合 (无序性、互异性):想象一碗水果沙拉。里面有苹果块、香蕉片和草莓。你不会去关心哪块苹果是先放进去的,也不会因为你放了两块一模一样的苹果块,就说沙拉里有两种苹果。你只会说:“这碗沙拉里有苹果、香蕉和草莓”。
- 多重集:想象一个装满硬币的钱包。你可能会说:“我有三枚1元硬币,两枚5角硬币”。硬币的重复个数很重要,这就是多重集。
- 无序性:想象在太空中漂浮的一群星星。它们组成一个“星团”(集合),但没有“第一颗星”或“最后一颗星”的说法。
- 互异性:想象你的微信好友列表。即使你给同一个人设置了两个不同的备注名,系统后台仍然知道这是同一个人,好友数量不会增加。在集合的视角里,好友就是独一无二的。
12.4 空集、单例集与无序对
📜 [原文5]
没有成员的集合称为空集,写作 $\emptyset$。具有一个成员的集合有时称为单例集,具有两个成员的集合称为无序对。
- 空集 (Empty Set)
- 这是一个非常重要但又有点抽象的概念。空集是一个特殊的集合,它的特殊之处在于它里面什么都没有。
- 它是一个完全合法的集合,满足集合的所有定义。它是一个“袋子”,只不过这个袋子是空的。
- 写法:$\emptyset$ 是一个专门的符号,代表空集。它也可以写成 $\{ \}`,一个里面没有任何东西的花括号。
- 没有成员的集合:这意味着对于任何一个对象 $x$,$x \in \emptyset$ 这句话永远是假的。
- 单例集 (Singleton Set)
- 这是一个非常简单的概念,就是一个集合里只有一个成员。
- 例如 $\{a\}$ 是一个单例集,它的唯一成员是 a。$\{7\}$ 也是一个单例集。
- 强调:必须区分元素和包含该元素的单例集。$a$ 和 $\{a\}$ 是两种完全不同的东西。前者是一个元素,后者是一个集合。
- 无序对 (Unordered Pair)
- 就是一个集合里正好有两个成员。
- 例如 $\{a, b\}`。
- “无序” 这个词再次强调了集合的无序性。$\{a, b\}$ 和 $\{b, a\}$ 是同一个无序对。这与后面将要学的有序对 (a, b) 形成对比,在有序对中 (a, b) 和 (b, a) 是不同的。
- 空集示例:
- $S_1 = \{n \mid n \in \mathcal{N} \text{ 且 } n < 0\}$ (所有小于0的自然数的集合)。因为自然数是从1开始的,所以不存在这样的数。因此 $S_1 = \emptyset$。
- $S_2 = $ 所有会飞的猪的集合。这也是一个空集。
- 单例集示例:
- $\{ \emptyset \}`: 这是一个单例集。它不是空集。它是一个只含有一个元素的集合,而那个元素恰好是空集。想象一个大袋子,里面只装了一个空的小袋子。
- $\{ x \mid x \text{ 是偶数也是质数} \}$: 唯一的偶质数是2,所以这个集合是 $\{2\}$,是一个单例集。
- 无序对示例:
- $\{ \text{"heads"}, \text{"tails"} \}$: 抛硬币可能出现的所有结果的集合,这是一个无序对。
- $\{0, 1\}$: 二进制数字的集合,也是一个无序对。
- $\emptyset$ vs $\{\emptyset\}$: 这是最经典的易错点。
- $\emptyset$ (或 $\{ \}`) 是空集,它的大小(基数)是0。
- $\{\emptyset\}$ 是单例集,它的大小是1。它的唯一元素是空集本身。
- 空集的子集:空集 $\emptyset$ 只有一个子集,就是它自身 $\emptyset$。$\emptyset \subseteq \emptyset$。
- 单例集的子集:单例集 $\{a\}$ 有两个子集:空集 $\emptyset$ 和它自身 $\{a\}$。
根据集合中元素的数量,我们有一些特殊的名称:0个元素的叫空集 $\emptyset$,1个元素的叫单例集,2个元素的叫无序对。
为这些常见且基础的集合类型赋予专门的名称,有助于简化数学讨论。空集在集合论和计算机科学中扮演着极其重要的角色,类似于数字中的 0,是很多递归定义和证明的起点。单例集和无序对虽然简单,但在构建更复杂的结构时也经常出现。
- 空集 $\emptyset$: 一个空的购物篮。
- 单例集 $\{a\}$: 一个只装了一个苹果的购物篮。
- 无序对 $\{a, b\}$: 一个装有一个苹果和一个香蕉的购物篮。
- $\{\emptyset\}$: 一个大购物篮,里面只装了一个空的小购物篮。
- 空集: 一个没有任何家具的空房间。
- 单例集: 一个只放了一把椅子的房间。
- 无序对: 一个放了一把椅子和一张桌子的房间。
- $\{\emptyset\}$: 一个大房间,里面只有一个小小的、完全空的保险箱。房间不是空的,它有东西(保险箱),但保险箱里面是空的。
12.5 集合的描述法:规则描述
📜 [原文6]
当我们想描述一个根据某种规则包含元素的集合时,我们写 $\{n \mid \text{关于 } n \text{ 的规则}\}$。因此,$\left\{n \mid n=m^{2} \text{ 且 } m \in \mathcal{N}\right\}$ 表示完全平方数集。
- 描述法的动机:对于无限集或者元素非常多、有规律的有限集,列举法($\{1, 2, 3, \ldots\}$)显得不够精确或不可能。我们需要一种更强大、更形式化的方法来定义集合。
- 集合构建器表示法 (Set-Builder Notation):$\{n \mid \text{规则}\}$ 就是这种方法。它不直接给出元素,而是给出一个“会员资格测试”的规则。一个对象要想成为这个集合的成员,就必须通过这个测试。
- 结构分析:$\{ \text{变量} \mid \text{条件} \}$
- {}: 仍然是集合的标志。
- 变量 (例如 n): 这是一个占位符,代表了我们正在考虑的“候选成员”的一般形式。
- $\mid$: 这是一个分隔符,读作“使得 (such that)”。有时也用冒号 : 代替。
- 条件 (例如 关于 n 的规则): 这是一个逻辑断言或属性。只有当候选成员 n 使得这个条件为真时,n 才能被接纳进集合。
- 示例的解读:$\left\{n \mid n=m^{2} \text{ 且 } m \in \mathcal{N}\right\}$
- “我们正在构建一个集合,里面的元素我们暂时叫它 n...” ($\{n \mid \ldots \}`)
- “...什么样的 n 才有资格进来呢?” ($\ldots n=m^{2} \text{ 且 } m \in \mathcal{N} \}$)
- 规则有两部分,必须同时满足(因为用了“且”):
- $n=m^2$: n 必须是某个数的平方。
- $m \in \mathcal{N}$: 那个数 $m$ 还必须是一个自然数 (根据本书约定,$\mathcal{N} = \{1, 2, 3, \ldots\}`)。
- 实际构建过程(思维实验):
- 取第一个自然数 $m=1$,计算 $n = 1^2 = 1$。1 满足规则,所以 1 是集合的一个成员。
- 取第二个自然数 $m=2$,计算 $n = 2^2 = 4$。4 满足规则,所以 4 是集合的一个成员。
- 取第三个自然数 $m=3$,计算 $n = 3^2 = 9$。9 满足规则,所以 9 是集合的一个成员。
- ... 以此类推。
- 结论:这个集合就是所有自然数的平方组成的集合,即 $\{1, 4, 9, 16, 25, \ldots\}$,也就是完全平方数集。
$\left\{n \mid n=m^{2} \text{ 且 } m \in \mathcal{N}\right\}$
- $n$: 集合中元素的代表形式(一个变量)。
- $\mid$: 分隔符,读作“使得”。
- $n=m^2$: 关于 $n$ 的第一个条件,$n$ 必须是一个平方数。
- $m$: 在条件中引入的一个辅助变量。
- 且 (and): 逻辑连接词,表示两个条件必须同时成立。
- $m \in \mathcal{N}$: 第二个条件,$m$ 必须是自然数集 $\mathcal{N}$ 的一个成员。
这个表示法也可以简化。因为 $n$ 的形式完全由 $m$ 决定,我们可以直接把 $n$ 的表达式放在 $\mid$ 左边:
$\{m^2 \mid m \in \mathcal{N}\}$
这个写法更紧凑,意思完全一样:“这个集合包含所有形如 $m^2$ 的元素,其中 $m$ 是一个自然数”。
- 示例1:所有偶数的集合
- 用规则描述法可以写成:$E = \{x \mid x \in \mathcal{Z} \text{ 且 } x \text{ 可被2整除}\}$。
- 更数学化的写法是:$E = \{n \mid \text{存在一个 } k \in \mathcal{Z} \text{ 使得 } n=2k \}$。
- 使用紧凑写法:$E = \{2k \mid k \in \mathcal{Z}\}$。
- 这个集合用列举法就是 $\{\ldots, -4, -2, 0, 2, 4, \ldots\}$。
- 示例2:一个有限集的规则描述
- 描述集合 $\{1, 2, 3, 4, 5\}$。
- 可以写成:$S = \{k \mid k \in \mathcal{N} \text{ 且 } k \leq 5 \}$。
- 这个描述法精确地定义了集合的边界,避免了列举法中省略号的模糊性。
- 变量的作用域:在 $\{n \mid n=m^{2} \text{ 且 } m \in \mathcal{N}\}$ 中,$m$ 是一个“哑变量”(dummy variable),它的作用域仅限于规则内部,用来帮助定义 $n$。集合的成员只有 $n$,不包括 $m$。
- 条件的精确性:规则必须是无歧义的、形式化的。像 $\{x \mid x \text{ 是一个大数}\}$ 这样的描述是不合格的,因为“大数”没有精确的数学定义。
- 基础集合 (Universe):在 $\{x \mid \text{规则}\}$ 中,通常会有一个隐含或明确的“全集”,即 $x$ 的取值范围。例如,在 $E = \{x \mid x \text{ 是偶数}\}$ 中,$x$ 到底是从整数 $\mathcal{Z}$ 中取,还是从自然数 $\mathcal{N}$ 中取?这会得到不同的集合。所以,一个好的规则描述通常会指明基础集合,如 $\{x \in \mathcal{Z} \mid x \text{ 是偶数}\}$。
规则描述法(或集合构建器表示法)使用 $\{ \text{变量} \mid \text{条件} \}$ 的形式来定义集合。它通过指定一个所有成员都必须满足的“会员规则”,精确地描述了集合的内容,特别适用于无限集和有规律的有限集。
为了精确、无歧改地定义集合,特别是无限集合。在计算理论中,语言(字符串的集合)通常是无限的。例如,“所有以'a'开头的二进制字符串的集合”就是一个无限语言,无法列举。但可以用规则描述法清晰地定义:$L = \{w \in \{0,1\}^* \mid w \text{ 以'a'开头} \}$(这里的 $\{0,1\}^*$ 后面会学到,表示所有01字符串的集合)。
这就像一个俱乐部的“会员章程”。章程上没有写所有会员的名字(列举法),而是写着入会条件(规则描述法):
- $\{n \mid n \text{ 年满18岁且是本市居民}\}$
任何一个人想入会,就拿这个章程去核对他/她的资格。符合就让他/她进来。
想象一个自动化工厂的“筛选机器”。
- 传送带上(代表基础集合,如所有整数)源源不断地运来各种“零件”(候选元素)。
- 筛选机器(规则)被设置好,比如“只允许长度为5cm的螺丝通过”。
- 通过筛选的零件掉进一个箱子里,这个箱子里所有的零件就构成了我们定义的集合。
12.6 集合的基本运算:并集、交集、补集
📜 [原文7]
如果我们有两个集合 $A$ 和 $B$, $A$ 和 $B$ 的并集,写作 $A \cup B$,是我们通过将 $A$ 和 $B$ 中的所有元素组合成一个集合而得到的集合。 $A$ 和 $B$ 的交集,写作 $A \cap B$,是同时在 $A$ 和 $B$ 中的元素集。 $A$ 的补集,写作 $\bar{A}$,是所考虑的所有元素中不在 $A$ 中的元素集。
这里介绍了对集合进行操作的三种基本“算术”。
- 并集 (Union)
- 符号:$A \cup B$
- 含义:“或”的逻辑。一个元素只要在集合 $A$ 或在集合 $B$ 中(或者两者都在),它就在并集 $A \cup B$ 中。
- 操作:想象把 $A$ 袋子和 $B$ 袋子里的所有东西都倒进一个更大的新袋子里。根据集合的互异性,如果某个东西两个袋子里都有,新袋子里也只保留一份。
- “将A和B中的所有元素组合成一个集合”:这就是上述操作的文字描述。
- 交集 (Intersection)
- 符号:$A \cap B$
- 含义:“与”的逻辑。一个元素必须同时在集合 $A$ 和集合 $B$ 中,它才能在交集 $A \cap B$ 中。
- 操作:想象对比 $A$ 和 $B$ 两个袋子,只挑出那些两个袋子里共同拥有的东西,放入一个新袋子。
- “是同时在A和B中的元素集”:这是交集的精确定义。
- 补集 (Complement)
- 符号:$\bar{A}$ (有时也写作 $A^c$ 或 $A'$)
- 含义:“非”的逻辑。一个元素不在集合 $A$ 中,它就在 $A$ 的补集中。
- 操作:这个操作有一个重要的前提,就是必须先定义一个“宇宙”或“全集” (Universe),我们用 $U$ 表示。补集是相对于这个全集而言的。$\bar{A}$ 指的是在全集 $U$ 中,但不在 $A$ 中的所有元素。
- “所考虑的所有元素中不在A中的元素集”:“所考虑的所有元素”指的就是这个隐含的全集。如果没有定义全集,讨论补集是没有意义的。
使用规则描述法,可以更形式化地定义这些运算:
- 并集: $A \cup B = \{x \mid x \in A \text{ 或 } x \in B\}$
- 交集: $A \cap B = \{x \mid x \in A \text{ 且 } x \in B\}$
- 补集: $\bar{A} = \{x \in U \mid x \notin A\}$ (这里 $U$ 是全集)
示例1:
令全集 $U = \{1, 2, 3, 4, 5, 6\}$
令集合 $A = \{1, 2, 3\}$
令集合 $B = \{3, 4, 5\}$
- 并集: $A \cup B$
- 把A和B的元素都拿出来:1, 2, 3, 3, 4, 5。
- 根据互异性,去掉重复的3。
- $A \cup B = \{1, 2, 3, 4, 5\}$
- 交集: $A \cap B$
- 检查A的元素:1不在B里。2不在B里。3在B里。
- 共同的元素只有3。
- $A \cap B = \{3\}$
- 补集: $\bar{A}$
- 全集是 $U = \{1, 2, 3, 4, 5, 6\}$。
- $A = \{1, 2, 3\}$。
- 在 $U$ 中但不在 $A$ 中的元素是 4, 5, 6。
- $\bar{A} = \{4, 5, 6\}$
示例2:
令全集 $U$ 为所有英文字母 $\{\text{a}, \text{b}, \ldots, \text{z}\}$
令 $Vowels = \{\text{a}, \text{e}, \text{i}, \text{o}, \text{u}\}$ (元音)
令 $FirstFive = \{\text{a}, \text{b}, \text{c}, \text{d}, \text{e}\}$ (前五个字母)
- 并集: $Vowels \cup FirstFive = \{\text{a}, \text{e}, \text{i}, \text{o}, \text{u}, \text{b}, \text{c}, \text{d}\}$
- 交集: $Vowels \cap FirstFive = \{\text{a}, \text{e}\}$
- 补集: $\overline{Vowels}$ (相对于全集U) 就是所有辅音字母的集合 $\{\text{b}, \text{c}, \text{d}, \text{f}, \ldots, \text{z}\}$。
- 补集的全集依赖性:$\bar{A}$ 的结果完全取决于全集 $U$ 的定义。如果上例1中,全集定义为 $U = \{1, 2, 3, 4, 5, 6, 7, 8\}$,那么 $\bar{A}$ 就会变成 $\{4, 5, 6, 7, 8\}$。
- 与空集的运算:
- $A \cup \emptyset = A$ (A和空集并,还是A)
- $A \cap \emptyset = \emptyset$ (A和空集交,什么也交不到)
- 不相交集合 (Disjoint Sets):如果两个集合的交集是空集,即 $A \cap B = \emptyset$,我们称这两个集合是不相交的。
并集 $\cup$ 是“合并”,取所有出现过的元素。交集 $\cap$ 是“筛选”,只取共同拥有的元素。补集 $\bar{\cdot}$ 是“取反”,取在一个更大的全集范围内、不属于该集合的元素。
这些基本运算使得我们可以像处理数字一样对集合进行组合和变换,构建出新的集合。在计算理论中,例如,如果 $L_1$ 和 $L_2$ 是两个语言(语言是字符串的集合),那么 $L_1 \cup L_2$ 就是一个新的语言,它包含了 $L_1$ 和 $L_2$ 中所有的字符串。这些运算是研究语言性质和闭包特性的基础。
假设你和你的朋友各自有一个歌单(集合)。
- 并集 $\cup$: 你们决定办一个派对,播放的音乐是你们两个歌单里所有歌曲的合集。这就是并集。
- 交集 $\cap$: 你们想找找共同喜欢的歌曲,于是对了下歌单,找出两人都有的那些歌。这就是交集。
- 补集 $\bar{\cdot}$: 假设有一个“全球热歌100首”的榜单(全集),你朋友想知道你的歌单里没有收录哪些热歌。这个结果就是你的歌单相对于热歌榜的补集。
见下一节的文氏图。文氏图是这些运算最直观的想象方式。
12.7 可视化工具:文氏图
📜 [原文8]
在数学中,通常情况下,一张图片有助于澄清概念。对于集合,我们使用一种称为文氏图的图片。它将集合表示为由圆形线条包围的区域。设集合 START-t 是所有以字母“t”开头的英文单词的集合。例如,图中,圆圈代表集合 START-t。该集合的几个成员以圆圈内的点的形式表示。
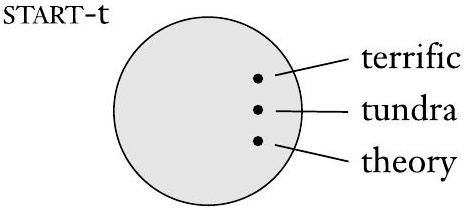
图 0.1
以“t”开头的英文单词集合的文氏图
类似地,我们在下图中表示以“z”结尾的英文单词的集合 END-z。
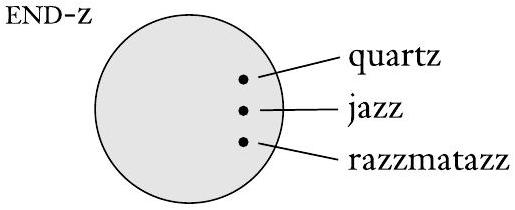
图 0.2
以“z”结尾的英文单词集合的文氏图
要在同一个文氏图中表示这两个集合,我们必须将它们绘制成重叠的,表示它们共享一些元素,如下图所示。例如,单词 topaz 在这两个集合中。该图还包含一个表示集合 START-j 的圆圈。它与 START-t 的圆圈不重叠,因为没有单词同时属于这两个集合。
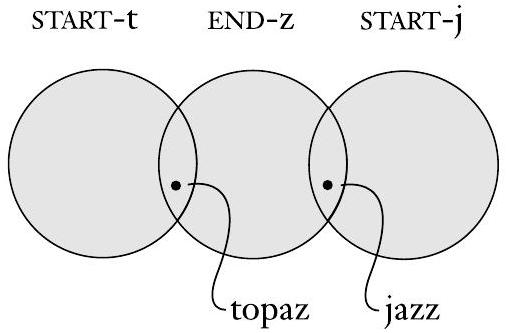
图 0.3
重叠的圆圈表示共同的元素
接下来的两个文氏图描绘了集合 $A$ 和 $B$ 的并集和交集。
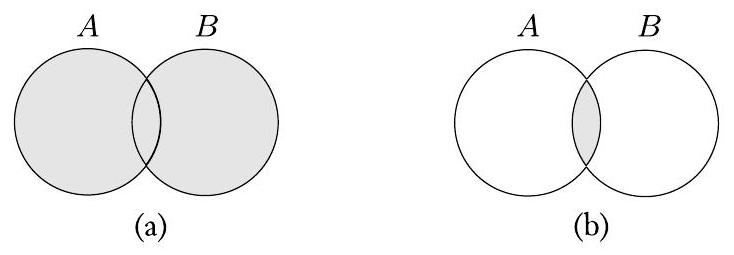
图 0.4
(a) $A \cup B$ 和 (b) $A \cap B$ 的图示
- 文氏图 (Venn Diagram) 的基本思想:将抽象的集合关系转化为直观的几何图形关系。
- 集合 -> 圆形区域: 每个集合用一个圆圈(或任何闭合曲线)表示。圈内的空间代表属于该集合的元素所在的位置。
- 元素 -> 点: 单个的元素可以表示为区域内的一个点。
- 全集 -> 方框: 通常,整个文氏图会画在一个大方框里,这个方框代表全集 U。
- 图0.1 和 图0.2 的分析:
- START-t: 一个圆圈,代表“所有以t开头的英文单词”这个集合。圈里面画了几个点,并标注了 "tea", "tent", "taco" 作为示例元素。
- END-z: 另一个圆圈,代表“所有以z结尾的英文单词”这个集合。里面标注了 "buzz", "jazz", "quiz" 作为示例元素。
- 这两个图分别独立地展示了一个集合。
- 图0.3 的分析:
- 重叠区域: START-t 和 END-z 的圆圈有一部分重叠了。这个重叠区域代表了两个集合的交集,即同时满足“以t开头”和“以z结尾”的单词。图中用 "topaz" 作为一个例子放在重叠区。
- 非重叠区域:
- START-t 圆圈中不与 END-z 重叠的部分,代表那些只以t开头,但不以z结尾的单词。
- END-z 圆圈中不与 START-t 重叠的部分,代表那些只以z结尾,但不以t开头的单词。
- 不相交的圆圈: 图中还有一个 START-j 的圆圈,它和 START-t 的圆圈完全分离,没有重叠。这直观地表示 START-j 和 START-t 的交集是空集 ($\emptyset$),即不存在一个单词既以 'j' 开头又以 't' 开头。这种集合关系称为不相交 (disjoint)。
- 图0.4 的分析:
- 这是对上一节集合运算的通用、抽象的可视化。
- 图(a) $A \cup B$: 阴影部分覆盖了圆圈A的全部和圆圈B的全部。这直观地展示了并集的“合并”特性:只要在一个圈里,就在阴影区里。
- 图(b) $A \cap B$: 阴影部分只覆盖了圆圈A和圆圈B重叠的那一小块区域。这直观地展示了交集的“共同”特性:必须同时在两个圈里,才在阴影区里。
示例1:
令 $U = \{1, ..., 10\}$, $A = \{1, 2, 3, 4\}$, $B = \{3, 4, 5, 6\}$
- 交集 $A \cap B = \{3, 4\}$: 在文氏图中就是两个圆圈重叠的部分。
- 并集 $A \cup B = \{1, 2, 3, 4, 5, 6\}$: 就是两个圆圈覆盖的总区域。
- 补集 $\bar{A} = \{5, 6, 7, 8, 9, 10\}$: 就是大方框U内,但在A圈外的所有区域。
- 差集 $A \setminus B = \{1, 2\}$ (在A中但不在B中):就是A圈中不与B重叠的部分。
示例2:子集关系
令 $A = \{1, 2\}$, $B = \{1, 2, 3\}$。
$A \subseteq B$ 在文氏图上如何表示?
将代表A的圆圈完全画在代表B的圆圈的内部。这样,任何在A圈内的点,必然也在B圈内,完美符合子集的定义。
- 文氏图只是示意图:圆圈的大小、形状,点的位置通常不代表实际元素的数量或值,只表示逻辑上的包含关系。
- 三个集合的文氏图:当有三个集合A, B, C时,通常画三个相互重叠的圆圈,形成8个不同的区域(包括所有圈外的大区域),可以表示 $A \cap B \cap C$, $A \cap B \setminus C$ 等所有逻辑组合。
- 无法表示所有情况:对于4个或更多的集合,用简单的圆形已经无法画出能表示所有可能交集的文氏图了。需要更复杂的形状。
文氏图是一种强大的可视化工具,它用区域的重叠、分离和包含关系,直观地展示了集合之间的交集、并集、补集和子集等关系,有助于理解和证明集合相关的定理。
人类是视觉动物。将抽象的数学概念转化为图形,可以极大地降低理解门槛,并激发直觉思考。很多关于集合的等式,比如德摩根定律 $\overline{A \cup B} = \bar{A} \cap \bar{B}$,通过文氏图可以一目了然地得到验证。
文氏图就像是用不同颜色的透明塑料片来思考集合。
- 每个集合是一张有颜色的透明塑料片(比如,A是红色,B是蓝色)。
- 并集 $\cup$: 把两张塑料片叠在一起后,所有被染上色的区域。
- 交集 $\cap$: 只有两张塑料片重叠,颜色混合变深(变成紫色)的那个区域。
- 补集 $\bar{A}$: 在一个限定的桌面上(全集),没有被红色塑料片覆盖的所有区域。
想象你在地图上圈出了“步行10分钟内可达的区域”(集合A)和“有免费Wi-Fi的咖啡馆分布区”(集合B)。
- 你想找一个“步行10分钟内可达或有免费Wi-Fi”的地方,你考虑的范围就是两个圈的并集。
- 你想找一个“步行10分钟内可达且有免费Wi-Fi”的理想咖啡馆,你就在两个圈的交集里寻找。
- 你的朋友不想走路也不想喝咖啡,他想找一个既不在步行圈内,又不是Wi-Fi区的地方,他就在两个圈之外的补集区域里找。
1.3 序列和元组
13.1 序列与元组的定义
📜 [原文9]
对象的序列是这些对象按一定顺序排列的列表。我们通常通过将列表写在括号内来表示序列。例如,序列 7, 21, 57 将写为
在集合中,顺序无关紧要,但在序列中则不然。因此 $(7,21,57)$ 与 $(57,7,21)$ 不同。类似地,重复在序列中很重要,但在集合中则无关紧要。因此 $(7,7,21,57)$ 与其他两个序列都不同,而集合 $\{7,21,57\}$ 与集合 $\{7,7,21,57\}$ 完全相同。
与集合一样,序列可以是有限的也可以是无限的。有限序列通常称为元组。一个包含 $k$ 个元素的序列是一个 $k$-元组。因此 $(7,21,57)$ 是一个 3-元组。一个 2-元组也称为有序对。
- 序列 (Sequence) 的核心定义:“按一定顺序排列的列表”。这是序列与集合最根本的区别。
- 列表: 意味着序列中的元素可以被一个个拿出来。
- 按一定顺序排列: 这是关键。序列中有“第一个元素”、“第二个元素”...的概念。元素的位置是其身份的一部分。
- 表示法:
- 使用圆括号 ()(有时也用尖括号 <>)。这与集合的花括号 {} 形成对比。
- 元素之间用逗号分隔。
- 序列的两大特性 (与集合对比):
- 有序性 (Ordered): 元素的顺序很重要。交换两个元素的位置,会得到一个不同的序列。例如,$(7, 21, 57)$ 表示先是7,然后是21,最后是57。而 $(57, 7, 21)$ 表示先是57,然后是7,最后是21。这两个是不同的序列。
- 可重复性 (Repetition Matters): 序列中可以包含重复的元素,并且重复的次数和位置都是有意义的。$(7, 7, 21, 57)$ 是一个合法的序列,它有4个元素。它与 $(7, 21, 57)$ (3个元素) 和 $(7, 21, 7, 57)$ (4个元素,但重复位置不同) 都是不同的序列。
- 有限序列与元组 (Tuple):
- 当序列的长度是有限的时候,我们通常给它一个更具体的名字:元组。
- k-元组: 一个长度为 k 的元组。
- 3-元组: (7, 21, 57) 是一个3-元组。
- 2-元组: 特别地,长度为2的元组有一个非常常用的名字:有序对 (Ordered Pair)。例如 (a, b)。这在定义坐标、关系等方面非常重要。
- (): 圆括号,这是序列/元组的“外包装”,声明里面的内容共同构成一个有序列表。
- 7: 序列的第一个元素。
- 21: 序列的第二个元素。
- 57: 序列的第三个元素。
- ,: 逗号,用来分隔序列中的各个元素。
- 示例1:DNA序列
一条DNA短链可以表示为一个序列,字母表是 {A, C, G, T}。
- s1 = (A, G, T, C) 是一个4-元组。
- s2 = (C, T, G, A) 是另一个不同的4-元组,尽管它们包含的元素种类和数量都一样。顺序决定了其生物学功能。
- s3 = (A, A, G, C) 也是一个合法的序列,重复的 'A' 是有意义的。
- 示例2:二维平面上的点
- 点P的坐标是 (3, 4),这是一个有序对 (2-元组)。
- 3 是x轴坐标,4 是y轴坐标。
- 点Q的坐标是 (4, 3),这是一个不同的点。
- $(3, 4) \neq (4, 3)$ 完美地体现了序列的有序性。
- 混淆 () 和 {}:这是最根本的错误。$(a, b)$ 是一个有序对,$\{a, b\}$ 是一个无序对。前者 a是第一元素,后者 a和 b地位平等。
- 空序列:存在一个长度为0的序列,称为空序列,记为 () 或 $\epsilon$ (后面在字符串部分会重点讲)。
- 1-元组: (7) 是一个1-元组。在多数数学和编程上下文中,它和元素 7 本身可以互换使用,但严格来说,一个是元组,一个是元素。
序列(或有限情况下的元组)是一个有序的元素列表,其中元素的顺序和重复都非常重要。它使用圆括号 () 表示,与集合的无序、不重复特性形成鲜明对比。
现实世界和计算机科学中,大量的结构本身就是有序的。
- 字符串: 一个单词 "cat" 就是一个字符序列 (c, a, t),顺序颠倒 "tac" 就是另一个词了。
- 程序执行: 一系列指令必须按特定顺序执行。
- 数据结构: 数组、列表、栈、队列等都是基于序列概念的。
因此,我们需要一个能够精确描述“顺序”的数学工具,这就是序列/元组。
- 集合 $\{...\}$: 一把抓的硬币,你只关心有哪些面值的,不关心顺序。
- 序列 (...): 一串串在绳子上的珠子,每颗珠子的颜色、材质和它在绳子上的位置都共同构成了这串项链的样式。改变一颗珠子的位置,就得到了不同的项链。
- 集合 $\{...\}$: 一个购物袋,里面装着你今天买的菜:一个西红柿、一根黄瓜、一个土豆。它们在袋子里滚来滚去,没有固定位置。
- 序列 (...): 你的购物小票。上面按时间顺序记录了你买的东西:先是西红柿 (item 1), 然后是黄瓜 (item 2), 最后是土豆 (item 3)。这个顺序是固定的,不能改变。
13.2 复合结构:幂集与笛卡尔积
📜 [原文10]
集合和序列可以作为其他集合和序列的元素出现。例如,$A$ 的幂集是 $A$ 的所有子集的集合。如果 $A$ 是集合 $\{0,1\}$,则 $A$ 的幂集是集合 $\{\emptyset,\{0\},\{1\},\{0,1\}\}$。所有元素为 0 和 1 的有序对的集合是 $\{(0,0),(0,1),(1,0),(1,1)\}$。
如果 $A$ 和 $B$ 是两个集合,$A$ 和 $B$ 的笛卡尔积或叉积,写作 $A \times B$,是所有有序对的集合,其中第一个元素是 $A$ 的成员,第二个元素是 $B$ 的成员。
- 复合结构的思想:数学的威力在于能够用简单的构建块(集合、序列)通过运算规则,创造出更复杂、更强大的结构。这里介绍了两种非常重要的构造方法:幂集和笛卡尔积。
- 幂集 (Power Set)
- 定义:一个集合 $A$ 的幂集,通常记作 $\mathcal{P}(A)$ 或 $2^A$,它本身是一个集合,但它的元素非常特殊:它们是 $A$ 的所有可能的子集。
- “A的所有子集的集合”: 这是幂集的核心。要构建幂集,你需要找到一个集合的所有子集,然后把这些子集作为元素,装到一个新的大集合里。
- 示例分析: $A = \{0, 1\}$
- 首先,找出 $A$ 的所有子集:
- 0个元素的子集:$\emptyset$ (空集)
- 1个元素的子集:$\{0\}$ 和 $\{1\}$
- 2个元素的子集:$\{0, 1\}$ (A自身)
- 然后,把找到的这4个子集作为元素,放入一个新的集合中:$\{\emptyset, \{0\}, \{1\}, \{0, 1\}\}`。这就是 `$A$ 的幂集。
- 重要:如果 $A$ 有 $n$ 个元素,那么它的幂集 $\mathcal{P}(A)$ 将有 $2^n$ 个元素。这就是为什么幂集有时记作 $2^A$ 的原因。对于 $A = \{0, 1\}$,$n=2$,所以幂集有 $2^2 = 4$ 个元素。
- 笛卡尔积 (Cartesian Product) 或 叉积 (Cross Product)
- 定义: 两个集合 $A$ 和 $B$ 的笛卡尔积 $A \times B$,是一个由所有可能的有序对 $(a, b)$ 组成的集合。
- 规则:
- 有序对的第一个元素 $a$ 必须来自集合 $A$。
- 有序对的第二个元素 $b$ 必须来自集合 $B$。
- 构造过程: 想象你有两套衣服,上衣集合 $A = \{\text{红T恤, 蓝衬衫}\}$,裤子集合 $B = \{\text{牛仔裤, 黑裤子, 卡其裤}\}$。笛卡尔积 $A \times B$ 就代表了所有可能的搭配方式:
- 从 $A$ 中取出“红T恤”,与 $B$ 中所有裤子各搭配一次:(红T恤, 牛仔裤), (红T恤, 黑裤子), (红T恤, 卡其裤)。
- 从 $A$ 中取出“蓝衬衫”,与 $B$ 中所有裤子各搭配一次:(蓝衬衫, 牛仔裤), (蓝衬衫, 黑裤子), (蓝衬衫, 卡其裤)。
- 把所有这些搭配(有序对)收集起来,就构成了笛卡尔积这个集合。
- 重要: 如果 $A$ 有 $m$ 个元素,$B$ 有 $n$ 个元素,那么笛卡尔积 $A \times B$ 将有 $m \times n$ 个元素。
- “所有元素为0和1的有序对的集合”: 这是 $\{0, 1\} \times \{0, 1\}$ 的一个例子。
- 从第一个 $\{0, 1\}$ 取 0,与第二个 $\{0, 1\}$ 的 0 和 1 分别配对,得到 (0, 0) 和 (0, 1)。
- 从第一个 $\{0, 1\}$ 取 1,与第二个 $\{0, 1\}$ 的 0 和 1 分别配对,得到 (1, 0) 和 (1, 1)。
- 最终结果就是 $\{(0,0),(0,1),(1,0),(1,1)\}$。
- 幂集: $\mathcal{P}(A) = \{S \mid S \subseteq A\}$
- 笛卡尔积: $A \times B = \{(a, b) \mid a \in A \text{ 且 } b \in B\}$
- 幂集示例:
- 令 $C = \{a\}$ (一个单例集)。
- $C$ 的子集是:$\emptyset$ 和 $\{a\}$。
- 所以,$\mathcal{P}(C) = \{\emptyset, \{a\}\}`。`$C$` 有1个元素,`$\mathcal{P}(C)$` 有 `$2^1=2$ 个元素。
- 令 $D = \emptyset$。
- $D$ 的子集只有它自身:$\emptyset$。
- 所以,$\mathcal{P}(D) = \{\emptyset\}$。$D$ 有0个元素,$\mathcal{P}(D)$ 有 $2^0=1$ 个元素。注意 $\mathcal{P}(\emptyset)$ 不是空集!
- 笛卡尔积示例:
- 令 $A = \{1, 2\}$, $B = \{x, y, z\}$。
- $A \times B$ 的构造:
- 1 与 x, y, z 配对:(1, x), (1, y), (1, z)
- 2 与 x, y, z 配对:(2, x), (2, y), (2, z)
- $A \times B = \{(1, x), (1, y), (1, z), (2, x), (2, y), (2, z)\}$。
- $A$ 有2个元素,$B$ 有3个元素,$A \times B$ 有 $2 \times 3 = 6$ 个元素。
- 注意: $B \times A = \{(x, 1), (x, 2), (y, 1), (y, 2), (z, 1), (z, 2)\}$。一般来说 $A \times B \neq B \times A$,因为有序对的顺序很重要。
- 幂集的元素是集合:$\mathcal{P}(A)$ 的成员是集合,不是 $A$ 原来的那种元素。如果 $1 \in A$,那么 $\{1\} \in \mathcal{P}(A)$,但 $1 \notin \mathcal{P}(A)$ (除非1本身也是A的一个子集,这在标准集合论中不常见)。
- 笛卡尔积的元素是元组:$A \times B$ 的成员是有序对,不是单个元素。
- 与空集的笛卡尔积:$A \times \emptyset = \emptyset$ 且 $\emptyset \times A = \emptyset$。因为无法从空集中取出元素来构成有序对,所以结果是空集。
幂集 $\mathcal{P}(A)$ 是一个由 $A$ 的所有子集构成的集合。笛卡尔积 $A \times B$ 是一个由所有可能的有序对 $(a, b)$ 构成的集合,其中 $a$ 来自 $A$,$b$ 来自 $B$。这两种运算从旧集合中生成了结构更复杂的新集合。
这两种构造方法在计算机科学中极为重要。
- 幂集: 在非确定性有限自动机 (NFA) 转换为确定性有限自动机 (DFA) 的“子集构造法”中,DFA的每个状态都对应NFA状态集的一个子集。因此,DFA的状态集就是NFA状态集的幂集的一个子集。
- 笛卡尔积:
- 关系: 数学上的关系就是笛卡尔积的一个子集。
- 状态组合: 如果一个系统由两个独立的组件构成,组件1有状态集 $S_1$,组件2有状态集 $S_2$,那么整个系统的总状态集就是 $S_1 \times S_2$。
- 坐标系: 二维、三维乃至n维坐标系,本质上是实数集 $\mathbb{R}$ 与自身的笛卡尔积,如 $\mathbb{R}^2 = \mathbb{R} \times \mathbb{R}$。
- 幂集: 想象你有一盒披萨配料 $A = \{\text{蘑菇, 辣肠, 青椒}\}$。幂集 $\mathcal{P}(A)$ 就代表了你能制作的所有可能的披萨类型(配料组合)的菜单:
- $\emptyset$ (纯奶酪披萨)
- $\{\text{蘑菇}\}$ (只加蘑菇)
- ...
- $\{\text{蘑菇, 辣肠, 青椒}\}$ (所有配料都加)
- 笛卡尔积: 餐厅菜单。主菜集合 $A = \{\text{牛排, 鸡肉, 鱼}\}$,配菜集合 $B = \{\text{薯条, 沙拉}\}$。笛卡尔积 $A \times B$ 就是所有可能的套餐组合 $\{(\text{牛排, 薯条}), (\text{牛排, 沙拉}), (\text{鸡肉, 薯条}), ...\}$。
- 幂集: 一个开关面板,上面有 $n$ 个开关,每个开关都对应集合 $A$ 的一个元素。每个开关可以拨到“开”或“关”的位置。“开”表示选择该元素进入子集,“关”表示不选择。所有 $2^n$ 种开关的组合状态,就对应了幂集中的所有子集。
- 笛卡尔积: 一个表格或一张棋盘。如果集合 $A$ 的元素是行号,集合 $B$ 的元素是列号,那么笛卡尔积 $A \times B$ 就是表格中所有的单元格 (行, 列)。
13.3 示例 0.5
📜 [原文11]
示例 0.5
如果 $A=\{1,2\}$ 且 $B=\{x, y, z\}$,
$\square$
这个示例是笛卡尔积定义的一个直接应用,目的是通过一个具体的例子来帮助读者固化对笛卡尔积的理解。
- 识别输入: 我们有两个集合。
- 集合 $A = \{1, 2\}$。它有两个元素。
- 集合 $B = \{x, y, z\}$。它有三个元素。
- 确定目标: 我们要计算 $A \times B$。根据定义,这是一个由有序对 $(a, b)$ 组成的集合,其中 $a$ 必须从 $A$ 中选取,$b$ 必须从 $B$ 中选取。
- 系统地构造有序对: 为了确保不重不漏,我们采用一种系统化的方法。
- 第一步:固定A中的第一个元素。我们先从集合 $A$ 中取出第一个元素 1。
- 第二步:与B中所有元素配对。将 1 与集合 $B$ 中的每一个元素 x, y, z 分别配对,形成有序对。
- 1 和 x 配对得到 (1, x)。
- 1 和 y 配对得到 (1, y)。
- 1 和 z 配对得到 (1, z)。
- 第三步:固定A中的第二个元素。现在处理 $A$ 中的下一个元素 2。
- 第四步:与B中所有元素配对。将 2 与集合 $B$ 中的每一个元素 x, y, z 分别配对。
- 2 和 x 配对得到 (2, x)。
- 2 和 y 配对得到 (2, y)。
- 2 和 z 配对得到 (2, z)。
- 收集结果: 我们已经遍历了 $A$ 中所有的元素,并与 $B$ 进行了所有可能的配对。现在把所有生成的有序对收集起来,放入一个大集合中。
- 最终结果: 得到的集合就是 $\{(1, x), (1, y), (1, z), (2, x), (2, y), (2, z)\}$。
- 验证: 集合 $A$ 的大小是 2,集合 $B$ 的大小是 3。根据之前的知识,笛卡尔积 $A \times B$ 的大小应该是 $2 \times 3 = 6$。我们数一下结果集合中的元素个数,正好是6个有序对。验证通过。
- $\square$ 符号: 这个方块符号是数学文章和教科书中常用的标记,表示一个示例、一个证明或一个段落的结束。
- $A \times B$: 我们要计算的目标,即集合 $A$ 和 $B$ 的笛卡尔积。
- $=$: 等号,表示左右两边是相等的。
- { ... }: 花括号表示右边是一个集合。
- (1, x), (1, y), ...: 集合的元素。每个元素都是一个有序对。
- 在有序对 (1, x) 中,1 来自集合 $A$,x 来自集合 $B$,这符合笛卡尔积的定义。公式中列出的所有6个有序对都满足这个规则。
本节本身就是一个完整的示例。这里提供另一个。
示例:
令 $C = \{\text{黑, 白}\}$ (棋子颜色)
令 $D = \{1, 2, 3\}$ (棋盘行号)
计算 $C \times D$:
- 从 $C$ 中取“黑”,与 $D$ 中所有元素配对:(黑, 1), (黑, 2), (黑, 3)。
- 从 $C$ 中取“白”,与 $D$ 中所有元素配对:(白, 1), (白, 2), (白, 3)。
- $C \times D = \{(\text{黑}, 1), (\text{黑}, 2), (\text{黑}, 3), (\text{白}, 1), (\text{白}, 2), (\text{白}, 3)\}。这个集合可以看作是一个 2x3 棋盘上所有格子的坐标表示。
- 误写成集合的并集: 初学者可能把 $A \times B$ 和 $A \cup B$ 搞混。$A \cup B = \{1, 2, x, y, z\}$,它的元素是单个的数字和字母。而 $A \times B$ 的元素是有序对 (数字, 字母)。两者类型完全不同。
- 忘记是有序对: 结果必须写成 (a, b) 的形式,不能写成 \{a, b\}。$\{(1,x), ...\}$ 是正确的,$\{\{1,x\}, ...\}$ 是错误的。
示例0.5通过一个具体的数字与字母集合的例子,清晰地演示了如何一步步构造出两个集合的笛卡尔积,结果是一个包含所有可能配对的有序对的集合。
这个例子的目的就是“落实”。前面的定义是抽象的,这个例子把抽象的定义“实例化”,让读者可以亲手操作和验证,从而加深对笛卡尔积构造过程的理解。
这就像一个“两步选择”过程。
- 第一步,你必须从 $A$ 里面选一个(有2种选择)。
- 第二步,你必须从 $B$ 里面选一个(有3种选择)。
所有可能的选择组合 (第一步的选择, 第二步的选择) 就构成了笛卡尔积。总共的选择组合有 $2 \times 3 = 6$ 种。
想象一个坐标平面。
- 集合 $A = \{1, 2\}$ 是x轴上你感兴趣的两个点。
- 集合 $B = \{x, y, z\}$ 是y轴上你感兴趣的三个点(假设x,y,z是y轴上的值)。
- 笛卡尔积 $A \times B$ 就是以这些点为x,y坐标,在平面上构成的所有网格点的集合。你会得到一个2x3的点阵。
13.4 k重笛卡尔积
📜 [原文12]
我们也可以取 $k$ 个集合 $A_{1}, A_{2}, \ldots, A_{k}$ 的笛卡尔积,写作 $A_{1} \times A_{2} \times \cdots \times A_{k}$。它是由所有 $k$-元组 $(a_{1}, a_{2}, \ldots, a_{k})$ 组成的集合,其中 $a_{i} \in A_{i}$。
- 从2维到k维的推广: 前面讲的笛卡尔积 $A \times B$ 是两个集合之间的运算,产生的是有序对(2-元组)。这一段将这个概念推广到任意 $k$ 个集合。
- k重笛卡尔积: $A_{1} \times A_{2} \times \cdots \times A_{k}$
- 输入: $k$ 个集合,$A_1, A_2, \ldots, A_k$。这些集合可以是不同的,也可以是相同的。
- 输出: 一个新的集合。
- 输出集合的元素: 不再是简单的有序对,而是k-元组 $(a_1, a_2, \ldots, a_k)$。
- k-元组的构成规则:
- 元组的第一个元素 $a_1$ 必须来自第一个集合 $A_1$。
- 元组的第二个元素 $a_2$ 必须来自第二个集合 $A_2$。
- ...
- 元组的第 $i$ 个元素 $a_i$ 必须来自第 $i$ 个集合 $A_i$。
- ...
- 元组的第 $k$ 个元素 $a_k$ 必须来自第 $k$ 个集合 $A_k$。
- 结果: 最终的集合包含了所有满足上述规则的、可能的k-元组。
- 元素个数: 如果集合 $A_i$ 的大小是 $n_i$,那么 $k$ 重笛卡尔积 $A_{1} \times A_{2} \times \cdots \times A_{k}$ 的大小就是 $n_1 \times n_2 \times \cdots \times n_k$。
$A_{1} \times A_{2} \times \cdots \times A_{k} = \{(a_{1}, a_{2}, \ldots, a_{k}) \mid a_{1} \in A_{1}, a_{2} \in A_{2}, \ldots, a_{k} \in A_{k}\}$
这个公式是k重笛卡尔积的形式化定义,使用集合构建器表示法。
- $(a_{1}, a_{2}, \ldots, a_{k})$: 定义了结果集合中元素的形式,即一个k-元组。
- $\mid$: 读作“使得”。
- $a_{1} \in A_{1}, a_{2} \in A_{2}, \ldots, a_{k} \in A_{k}$: 这是元组中每个位置的元素必须满足的条件。逗号在这里可以理解为逻辑“且”。
- 示例1:3重笛卡尔积
令 $A = \{0, 1\}$ (比特位)
令 $B = \{+, -\}$ (符号)
令 $C = \{\text{red}, \text{blue}\}$ (颜色)
计算 $A \times B \times C$: 这是一个由3-元组组成的集合。
- 我们系统地构造:
- 以 (0, +, ...) 开头: (0, +, red), (0, +, blue)
- 以 (0, -, ...) 开头: (0, -, red), (0, -, blue)
- 以 (1, +, ...) 开头: (1, +, red), (1, +, blue)
- 以 (1, -, ...) 开头: (1, -, red), (1, -, blue)
- 最终结果是包含这8个3-元组的集合。
- |A|=2, |B|=2, |C|=2,所以 |A \times B \times C| = 2 \times 2 \times 2 = 8。
- 示例2:一个简单的日期表示
令 Month = \{1, 2, ..., 12\}
令 Day = \{1, 2, ..., 31\}
Month \times Day 构成了一个 (月份, 日子) 的有序对集合,如 (9, 30)。
如果我们再引入 Year = \{2023, 2024\},那么 Year \times Month \times Day 就构成了 (年份, 月份, 日子) 的3-元组集合,如 (2024, 1, 21)。这代表了所有可能的日期组合(尽管有些是不合法的,比如 (2024, 2, 30),但它是在这个笛卡尔积集合里的)。
- 结合律: 严格来说,笛卡尔积不满足结合律。 $(A \times B) \times C$ 的元素是 ((a, b), c) 这种形式(一个有序对,其第一个元素是另一个有序对)。而 $A \times (B \times C)$ 的元素是 (a, (b, c)) 这种形式。 $A \times B \times C$ 的元素是 (a, b, c)。这三者在形式上是不同的。但在实践中,我们通常把它们看作是等价的,都理解为 (a, b, c) 这样的n-元组,即忽略括号的嵌套。
k重笛卡尔积是将两个集合的笛卡尔积推广到k个集合的情况。它产生一个由k-元组组成的集合,每个元组的第i个位置的元素都来自第i个输入集合。
为了描述多维数据和多部分组成的复合状态。
- 数据库:数据库中的一条记录,比如一个学生记录 (学号, 姓名, 年龄, 专业),就可以看作是 学号集合 $\times$ 姓名集合 $\times$ 年龄集合 $\times$ 专业集合 这个巨大笛卡尔积中的一个元素。
- 高维空间: 3维空间是 $\mathbb{R} \times \mathbb{R} \times \mathbb{R}$,n维空间就是n个 $\mathbb{R}$ 的笛卡尔积。
- 函数参数: 一个接受k个参数的函数,其输入域就可以看作是k个参数各自类型集合的笛卡尔积。
这就像一个多级下拉菜单的在线表单。
- 第一个下拉菜单是集合 $A_1$ (比如,选择省份)。
- 第二个下拉菜单是集合 $A_2$ (选择城市)。
- ...
- 第k个下拉菜单是集合 $A_k$ (选择区/县)。
你完成一次表单所提交的一个完整选择 (省, 市, ..., 县) 就是k重笛卡尔积中的一个k-元组。而这个笛卡尔积集合就代表了所有你可能提交的选择组合。
- $A \times B$ 是一个平面 (棋盘)。
- $A \times B \times C$ 是一个立方体 (魔方)。A 是x轴,B 是y轴,C 是z轴。$A \times B \times C$ 就是这个立方体中所有的单位小方块。
- $A_1 \times \cdots \times A_k$ 是一个k维超立方体。虽然难以在三维空间中画出来,但数学上可以清晰地定义和操作。
13.5 示例 0.6
📜 [原文13]
示例 0.6
如果 $A$ 和 $B$ 与示例 0.5 中相同,
这个示例是k重笛卡尔积的一个具体应用,其中 $k=3$,并且输入的集合有重复。
- 回顾输入:
- 从示例 0.5 我们知道 $A = \{1, 2\}$ 和 $B = \{x, y, z\}$。
- 确定目标: 我们要计算 $A \times B \times A$。这是一个由3-元组 $(a_1, b, a_2)$ 组成的集合,其中:
- 第一个元素 $a_1$ 来自 $A$。
- 第二个元素 $b$ 来自 $B$。
- 第三个元素 $a_2$ 再次来自 $A$。
- 系统地构造3-元组:
- 我们可以将 $A \times B \times A$ 看作是 $(A \times B) \times A$。
- 我们已经从示例 0.5 知道 $A \times B = \{(1, x), (1, y), (1, z), (2, x), (2, y), (2, z)\}$。
- 现在,我们要计算这个新集合与 $A = \{1, 2\}$ 的笛卡尔积。
- 这会产生形如 (有序对, 数字) 形式的元素。
- 第一步: 取 $A \times B$ 的第一个元素 (1, x)。
- 与 $A$ 的 1 配对,得到 ((1, x), 1),我们将其“压平”理解为 (1, x, 1)。
- 与 $A$ 的 2 配对,得到 ((1, x), 2),理解为 (1, x, 2)。
- 第二步: 取 $A \times B$ 的第二个元素 (1, y)。
- 与 $A$ 的 1 配对,得到 (1, y, 1)。
- 与 $A$ 的 2 配对,得到 (1, y, 2)。
- ... 以此类推,对 $A \times B$ 中的所有6个有序对都进行同样的操作。
- 继续:
- 取 (1, z) -> (1, z, 1), (1, z, 2)
- 取 (2, x) -> (2, x, 1), (2, x, 2)
- 取 (2, y) -> (2, y, 1), (2, y, 2)
- 取 (2, z) -> (2, z, 1), (2, z, 2)
- 收集结果: 把所有这些3-元组收集起来,就得到了示例中给出的集合。
- 验证:
- |A| = 2, |B| = 3, |A| = 2。
- |A \times B \times A| = |A| \times |B| \times |A| = 2 \times 3 \times 2 = 12。
- 我们数一下示例结果中的3-元组个数,正好是12个。验证通过。
- $A \times B \times A$: 目标是计算这三个集合的笛卡尔积。
- { ... }: 结果是一个集合。
- (1, x, 1), ...: 集合的元素是3-元组。
- 该公式以一种有组织的方式列出了所有12个可能的3-元组:
- 第一行是所有以 1 (来自第一个A) 开头的元组。
- 第二行是所有以 2 (来自第一个A) 开头的元组。
- 在第一行中,又是先列出第二个元素为 x 的,再列出为 y 的,最后为 z 的,体现了构造的系统性。
本节本身就是一个完整的示例。这里提供一个更简单的。
示例:
令 $S = \{\text{heads}, \text{tails}\}$ (硬币正反面)。计算 $S \times S \times S$ (连续抛三次硬币的所有可能结果序列)。
- |S| = 2。所以 |S \times S \times S| = 2 \times 2 \times 2 = 8。
- 结果是:
{
(heads, heads, heads),
(heads, heads, tails),
(heads, tails, heads),
(heads, tails, tails),
(tails, heads, heads),
(tails, heads, tails),
(tails, tails, heads),
(tails, tails, tails)
}
- 位置与集合来源的对应: 必须严格遵守位置顺序。在 $A \times B \times A$ 中,一个元组 (e1, e2, e3) 必须满足 $e1 \in A$, $e2 \in B$, $e3 \in A$。不能搞混。例如,(x, 1, 1) 就不属于这个集合,因为第一个元素 x 不在 $A$ 中。
- 书写时的系统性: 在手动计算笛卡尔积时,最好遵循一种固定的顺序(例如,像字典序一样,先固定前面的元素,变化后面的),以保证不重不漏。
示例0.6具体展示了如何计算三个集合的笛卡尔积,即使其中有重复的集合。它强调了构造k-元组时,每个位置的元素必须从对应的集合中选取。
通过这个例子,强化对k重笛卡尔积定义的理解,并展示其构造过程,特别是当输入的集合不全是不同的时候。这为后面将要介绍的 $A^k$ 这种简写符号铺平了道路。
想象一个有三位密码的密码锁。
- 第一位密码的可能数字来自集合 $A = \{1, 2\}$。
- 第二位密码的可能字母来自集合 $B = \{x, y, z\}$。
- 第三位密码的可能数字又来自集合 $A = \{1, 2\}$。
$A \times B \times A$ 就是所有可能的密码组合的集合。
想象你在做一份有3个问题的调查问卷。
- 问题1的选项是集合 $A$ (2选1)。
- 问题2的选项是集合 $B$ (3选1)。
- 问题3的选项是集合 $A$ (2选1)。
一份填好的问卷 (答案1, 答案2, 答案3) 就是 $A \times B \times A$ 中的一个3-元组。而这个笛卡尔积集合就代表了所有可能的答卷的集合。
13.6 笛卡尔积的k次幂
📜 [原文14]
如果我们有一个集合与自身的笛卡尔积,我们使用简写
- 动机: 在数学和计算机科学中,我们经常需要处理同一个集合与自身进行多次笛卡尔积的情况。例如,二维平面是实数集 $\mathbb{R}$ 与自身的笛卡尔积 $\mathbb{R} \times \mathbb{R}$,三维空间是 $\mathbb{R} \times \mathbb{R} \times \mathbb{R}$。每次都写一长串 $\times$ 很繁琐。
- 引入简写:
- 这个简写模仿了算术中的幂运算。在算术中,$a \times a \times \cdots \times a$ (k次) 被简写为 $a^k$。
- 类似地,我们将 $A \times A \times \cdots \times A$ (k个A的笛卡尔积) 简写为 $A^k$。
- 这里的上标 $k$ 不再是数字的指数,而是表示笛卡尔积运算的次数。
- $A^k$ 的含义:
- 它是一个由k-元组组成的集合。
- 每个k-元组 $(a_1, a_2, \ldots, a_k)$ 中的所有元素 $a_i$ 都来自于同一个集合 $A$。
- $\overbrace{...}^{k}$ 符号: 这是一个解释性的符号,叫做“上大括号”(overbrace)。它用来标识出它下面的表达式重复了k次,帮助读者理解 $A^k$ 这个简写是如何从 $A \times A \times \cdots \times A$ 定义而来的。
- $A \times A \times \cdots \times A$: 一个包含k个集合A的k重笛卡尔积。
- $\overbrace{}^{k}$: 上大括号和上标k,共同说明了下面的模式 $A \times$ 重复了k次。
- $A^k$: 上述长表达式的简洁记法。它被称为“集合A的k次笛卡尔幂”。
- $=$: 定义了这种简写是等价的。
所以,$A^k = \{(a_1, a_2, \ldots, a_k) \mid a_i \in A \text{ for all } i=1, \ldots, k\}$
- 示例1:
- 令 $A = \{0, 1\}$ (二进制字母表)。
- $A^2 = A \times A = \{(0, 0), (0, 1), (1, 0), (1, 1)\}$。这代表了所有长度为2的二进制序列。
- $A^3 = A \times A \times A = \{(0,0,0), (0,0,1), (0,1,0), (0,1,1), (1,0,0), (1,0,1), (1,1,0), (1,1,1)\}$。这代表了所有长度为3的二进制序列。
- 示例2:
- 令 $\mathbb{R}$ 为所有实数的集合。
- $\mathbb{R}^1 = \mathbb{R}$。一维空间,一条数轴。
- $\mathbb{R}^2 = \mathbb{R} \times \mathbb{R}$。所有形如 $(x, y)$ 的有序对的集合,代表二维笛卡尔坐标平面。
- $\mathbb{R}^3 = \mathbb{R} \times \mathbb{R} \times \mathbb{R}$。所有形如 $(x, y, z)$ 的3-元组的集合,代表三维空间。
- $A^1$: 按照定义,$A^1 = A$。一个1-元组 (a) 组成的集合和原集合 A 在很多情况下可以认为是等价的。
- $A^0$: 这是一个有趣且重要的情况。$A^0$ 是一个只包含一个元素,即空元组 () 的单例集。$A^0 = \{()\}$。这在定义字符串和语言时会非常有用。
- $A^k$ 和幂集 $\mathcal{P}(A)$ 的区别:
- $A^k$ 的元素是 k-元组,其长度是固定的 k。
- $\mathcal{P}(A)$ 的元素是 集合,这些集合的长度可以从0到 $|A|$ 不等。
- 两者完全不同。
$A^k$ 是一个方便的简写,表示将集合 $A$ 与自身进行 $k$ 次笛卡尔积运算。其结果是一个由所有可能的、长度为 $k$ 的、且每个元素都来自 $A$ 的 $k$-元组组成的集合。
为了简洁地表示“从同一个集合中重复取k次(且关心顺序)所得到的所有可能序列”这一非常常见的概念。这在定义定长字符串、向量空间、n维坐标系等方面是核心记法。
想象一个有 $k$ 位的密码锁,但是每一位的可用数字/字母都来自同一个集合 $A$。$A^k$ 就是这个密码锁所有可能的密码组合的集合。
- $A = \{1, 2, 3, 4, 5, 6\}$ (一个骰子的六个面)。
- $A^2 = A \times A$:同时掷两颗骰子,所有可能的 (骰子1点数, 骰子2点数) 结果的集合。这是一个包含 $6 \times 6 = 36$ 个有序对的集合。
- $A^k$:同时掷 $k$ 颗骰子,所有可能的点数组合。
13.7 示例 0.7
📜 [原文15]
示例 0.7
集合 $\mathcal{N}^{2}$ 等于 $\mathcal{N} \times \mathcal{N}$。它由所有自然数的有序对组成。我们也可以将其写为 $\{(i, j) \mid i, j \geq 1\}$。
这个示例是 $A^k$ 记法的一个直接应用,其中 $A = \mathcal{N}$ 且 $k=2$。
- 识别记法: $\mathcal{N}^2$。看到 (集合)^(数字) 的形式,我们立刻联想到刚刚学到的笛卡尔幂的简写。
- 展开简写: 根据定义,$\mathcal{N}^2 = \mathcal{N} \times \mathcal{N}$。
- 理解输入集合: $\mathcal{N}$ 是自然数集。根据本书前面的约定,$\mathcal{N} = \{1, 2, 3, \ldots\}$。
- 应用笛卡尔积定义: $\mathcal{N} \times \mathcal{N}$ 是一个由有序对 (a, b) 组成的集合,其中 $a$ 和 $b$ 都必须是自然数。
- 结果描述: 因此,$\mathcal{N}^2$ 这个集合里装的是所有可能的自然数的有序对。
- 例如:(1, 1) 在 $\mathcal{N}^2$ 中。
- 例如:(1, 2) 在 $\mathcal{N}^2$ 中。
- 例如:(2, 1) 在 $\mathcal{N}^2$ 中。
- 例如:(15, 1024) 也在 $\mathcal{N}^2$ 中。
- 但 (0, 1) 不在,因为 0 不在 $\mathcal{N}$ 中。
- 但 (1.5, 2) 不在,因为 1.5 不是自然数。
- 另一种表示法: 示例中还给出了规则描述法的写法 $\{(i, j) \mid i, j \geq 1\}$。
- $\{(i, j) \mid ... \}$: 表示这是一个由有序对 (i, j) 组成的集合。
- $... i, j \geq 1\}$: 这是对有序对中元素 $i$ 和 $j$ 的限制条件。
- $i \geq 1$ 且 $j \geq 1$ (并且隐含了i,j是整数) 正是“i和j都是自然数”的另一种说法(在本书约定下)。
- 所以,$\{(i, j) \mid i \in \mathcal{N} \text{ and } j \in \mathcal{N}\}$ 和 $\{(i, j) \mid i, j \geq 1 \text{ and } i,j \in \mathcal{Z}\}$ 以及 $\mathcal{N} \times \mathcal{N}$ 都描述的是同一个集合。
- $\mathcal{N}^2$:
- $\mathcal{N}$: 自然数集 $\{1, 2, 3, \ldots\}`。
- $^2$: 上标2,表示与自身进行2次笛卡尔积,即 $\mathcal{N} \times \mathcal{N}$。
- $\{(i, j) \mid i, j \geq 1\}$:
- (i, j): 定义了集合元素的形式为有序对。
- i, j: 是描述条件时使用的变量名。
- $\geq$: 大于等于符号。
- $i, j \geq 1$: 这是一个简写的条件,意思是 $i \geq 1$ 且 $j \geq 1$。这里隐含了i和j都是整数,因此这个条件等价于 $i \in \mathcal{N}$ 且 $j \in \mathcal{N}$。
本节本身就是一个完整的示例。$\mathcal{N}^2$ 集合中的一些元素包括:
- (1, 1)
- (1, 2)
- (2, 1)
- (5, 8)
- (100, 100)
- ... 这是一个无限集。
- 不要与 $\mathcal{Z}^2$ 混淆: $\mathcal{Z}$ 是整数集,包含0和负数。$\mathcal{Z}^2 = \mathcal{Z} \times \mathcal{Z}$ 包含 (0, 0), (-1, 2) 等元素,而这些都不在 $\mathcal{N}^2$ 中。$\mathcal{N}^2$ 是 $\mathcal{Z}^2$ 的一个真子集。
- 是一个集合,不是平面: 虽然 $\mathcal{N}^2$ 可以被想象成二维平面上第一象限内的所有整数坐标点,但它在数学上就是一个集合,它的元素是有序对。
示例0.7阐明了 $\mathcal{N}^2$ 记号的含义,即所有自然数组成的有序对的集合,并给出了其等价的规则描述法表示。
为了让读者熟悉将笛卡尔幂记法应用到具体的、重要的数学集合(如自然数集)上,并将其与直观的坐标概念联系起来。这个集合是定义许多二维离散结构(如图、网格上的算法等)的基础。
$\mathcal{N}^2$ 就是一个无限大的棋盘的第一象限。棋盘上的每一个交叉点,都有一个 (行号, 列号) 坐标,这个坐标就是 $\mathcal{N}^2$ 中的一个元素。
想象一张无限大的Excel表格。
- 行号是 1, 2, 3, ... (集合 $\mathcal{N}$)
- 列名是 A, B, C, ...,我们也可以把它们想象成 1, 2, 3, ... (集合 $\mathcal{N}$)
- 每一个单元格的地址,比如 (第5行, 第3列),就是 $\mathcal{N}^2$ 中的一个元素 (5, 3)。
- $\mathcal{N}^2$ 就是这张无限大表格中所有单元格地址的集合。
1.4 函数和关系
14.1 函数的定义与基本概念
📜 [原文16]
函数是数学的核心。函数是一种建立输入-输出关系的对象。函数接受输入并产生输出。在每个函数中,相同的输入总是产生相同的输出。如果 $f$ 是一个函数,当输入值为 $a$ 时,输出值为 $b$,我们写
函数也称为映射,如果 $f(a)=b$,我们说 $f$ 将 $a$ 映射到 $b$。
例如,绝对值函数 $abs$ 接受一个数字 $x$ 作为输入,如果 $x$ 为正则返回 $x$,如果 $x$ 为负则返回 $-x$。因此 $abs(2)=abs(-2)=2$。加法是函数的另一个例子,写作 $add$。加法函数的输入是有序对的数字,输出是这些数字的和。
- 函数 (Function) 的核心思想: 函数是一个“规则”或一个“机器”,它定义了一种从输入到输出的明确对应关系。
- “输入-输出关系”: 这是函数的本质。你给它一个东西(输入),它会给你一个东西(输出)。
- 函数的两大铁律:
- 确定性 (Deterministic): “相同的输入总是产生相同的输出”。这是函数最根本的性质。一个函数不能“心情不好”就改变结果。如果你把 2 输入给 abs 函数,它必须输出 2,无论你问多少次,在何时何地问。abs(2) 不可能这次是2,下次是-2。
- 对每个输入都有定义: 对于一个函数所声称能处理的每一个合法输入,它都必须给出一个输出。它不能对某个输入说“我不知道”或“我算不出来”。(这是在定义域内的要求)
- 表示法: $f(a) = b$
- $f$: 函数的名字。
- $a$: 提供给函数的输入,也称为自变量或参数。
- $b$: 函数产生的输出,也称为函数值。
- $f(a)$: 整个表达式代表“将输入 a 应用于函数 f 后得到的结果”。
- 映射 (Mapping):
- 函数和映射是同义词。
- “f 将 a 映射到 b” 提供了一种更动态的想象方式:好像有一支看不见的笔,从输入 a 画了一条箭头指向输出 b。
- 示例分析:
- 绝对值函数 abs:
- 输入:一个数字 x (比如,整数)。
- 规则:如果 $x \ge 0$, 输出是 $x$;如果 $x < 0$, 输出是 $-x$。
- abs(2) = 2。
- abs(-2) = 2。注意,不同的输入 (2 和 -2) 可以产生相同的输出 (2),这是完全允许的。
- 加法函数 add:
- 输入:一个有序对的数字 (x, y)。这里函数的输入不是单个数字,而是一个元组。
- 规则:输出是这两个数字的和 $x+y$。
- 例如,add((3, 5)) = 8。我们通常将其简写为中缀表示法 3 + 5 = 8。
[公式与符号逐項拆解和推导(若本段含公式)]
- f: 函数的名称或符号。
- (): 括号,用于包裹函数的输入参数。
- a: 函数的输入,也称为参数 (argument) 或 自变量 (independent variable)。
- =: 等号,表示左边的函数应用结果等于右边的值。
- b: 函数的输出,也称为函数值 (value) 或 因变量 (dependent variable)。
- 示例1:平方函数 square
- 输入:一个实数 x。
- 规则:输出 x 的平方 $x^2$。
- square(3) = 9
- square(-3) = 9
- square(0) = 0
- 示例2:最大值函数 max
- 输入:一个有序对 (x, y)。
- 规则:如果 $x \ge y$, 输出 $x$;否则输出 $y$。
- max((4, 1)) = 4
- max((5, 5)) = 5
- max((-2, -1)) = -1
- 函数 vs 方程: $y = x+1$ 可以看作一个函数 f(x) = x+1。但 $x^2 + y^2 = 1$ (圆的方程) 不是一个从x到y的函数,因为一个输入 x (例如 x=0) 会对应两个输出 y (1 和 -1),违反了“相同输入产生相同输出”的确定性原则。
- 什么不是函数: 一个随机数生成器 rand() 不是一个纯粹的数学函数,因为每次调用 rand() (相同的输入,即无输入),会得到不同的输出。
函数是一个建立在确定性(相同输入必有相同输出)基础上的输入-输出规则。它接受一个输入,并根据其内部规则产生唯一一个对应的输出。它也可以被看作是一种从输入到输出的映射。
函数是描述变化、转换和依赖关系的核心数学工具。在计算机科学中:
- 算法: 每个算法都可以看作一个函数,它接受问题实例作为输入,输出解决方案。
- 程序/方法: 编程语言中的几乎所有函数/方法都遵循数学函数的输入-输出模型。
- 状态转移: 自动机的状态转移可以被一个转移函数所描述,该函数接受(当前状态,输入符号)作为输入,输出下一个状态。
函数概念无处不在。
函数就像一台功能固定的自动售货机。
- 输入: 你投入的硬币和按下的商品按钮(例如,A5)。
- 规则: 机器内部的机械和电路逻辑。
- 输出: 掉出来的商品(例如,一瓶可乐)。
- 确定性: 只要你按下 A5,机器正常工作,出来的永远是可乐,不可能是雪碧。
- 多对一: 可能 A5 (健怡可乐) 和 B2 (零度可乐) 按钮出来的可乐,喝起来味道差不多(不同的输入,相似的输出)。但一个按钮不可能时而掉可乐时而掉雪碧。
想象一个查字典的过程。
- 函数: 整本字典。
- 输入: 你要查的单词,比如 "apple"。
- 规则: 字典的编排和内容。
- 输出: 该单词的释义,“一种水果...”。
你每次查 "apple",得到的释义都是一样的。不同的单词(如 "pear")可以有部分相似的释义(都是水果),但一个单词不会有两种完全不同的、随机出现的释义。
14.2 函数的域和值域
📜 [原文17]
函数的可能输入集称为其域。函数的输出来自一个称为其值域的集合。表示 $f$ 是一个函数,其域为 $D$,值域为 $R$ 的符号表示是
在函数 $abs$ 的情况下,如果我们处理的是整数,则域和值域都是 $\mathcal{Z}$,所以我们写 $abs: \mathcal{Z} \longrightarrow \mathcal{Z}$。在整数的加法函数的情况下,域是整数对的集合 $\mathcal{Z} \times \mathcal{Z}$,值域是 $\mathcal{Z}$,所以我们写 $add: \mathcal{Z} \times \mathcal{Z} \longrightarrow \mathcal{Z}$。请注意,函数不一定使用指定值域的所有元素。函数 $abs$ 永远不会取值 -1,即使 $-1 \in \mathcal{Z}$。使用值域所有元素的函数被称为满射。
- 域 (Domain)
- 定义: 一个函数能够接受的所有合法输入构成的集合。
- 域规定了函数的“工作范围”或“管辖范围”。你不能把域之外的东西作为输入喂给函数。
- 值域 (Range / Codomain)
- 定义: 函数的所有可能输出都必须属于的那个集合。它为输出提供了一个“容器”或“目标空间”。
- 重要区分:
- 值域 (Codomain): 官方定义的目标集合,如 $R$。它是一个比较宽泛的“靶场”。
- 像 (Image): 所有实际输出值的集合。它是值域的一个子集。像才是所有“实际打中的点”。
- “函数不一定使用指定值域的所有元素”: 这句话说的就是“像”不一定等于“值域”。
- 例如,$abs: \mathcal{Z} \to \mathcal{Z}$。值域是所有整数 $\mathcal{Z}$。但 abs 的实际输出永远是 $\ge 0$ 的整数(即非负整数 {0, 1, 2, ...})。所以 abs 的像是 {0, 1, 2, ...},它是值域 $\mathcal{Z}$ 的一个真子集。 -1 在值域中,但不在像中。
- 表示法: $f: D \to R$
- 这是一种“函数签名”或“类型声明”。它没有告诉我们函数具体做什么,但清晰地定义了它的输入和输出的“类型”。
- $f$: 函数名。
- $D$: 域 (Domain),输入的来源集合。
- $R$: 值域 (Codomain),输出的目标集合。
- :: 分隔符,读作“是一个从...到...的函数”。
- $\to$: 箭头,表示从域到值域的映射方向。
- 示例分析:
- $abs: \mathcal{Z} \to \mathcal{Z}$
- 域是 $\mathcal{Z}$:abs 函数接受任何一个整数作为输入。
- 值域是 $\mathcal{Z}$:abs 函数的输出保证是一个整数。
- $add: \mathcal{Z} \times \mathcal{Z} \to \mathcal{Z}$
- 域是 $\mathcal{Z} \times \mathcal{Z}$:add 函数接受一个整数的有序对作为输入,例如 (3, 5)。
- 值域是 $\mathcal{Z}$:add 函数的输出(和)保证是一个整数。
- 满射 (Onto / Surjective)
- 这是一个函数的特殊性质。
- 如果一个函数 f: D -> R 是满射的,那么它的“像”就等于它的“值域”。
- 换句话说,对于值域 $R$ 中的任何一个元素 $y$,你都至少能找到一个域 $D$ 中的元素 $x$,使得 $f(x) = y$。值域里没有一个元素是被“浪费”的。
- $abs: \mathcal{Z} \to \mathcal{Z}$ 不是满射,因为你找不到任何整数 $x$ 使得 $abs(x) = -1$。
- 但如果我们把值域改小一点,定义一个新的函数 $abs': \mathcal{Z} \to \{0, 1, 2, \ldots\}$,那么这个 $abs' 就是满射了。
- f: 函数名。
- :: 声明 f 的类型。
- D: 域 (Domain),所有合法输入组成的集合。
- \to: 映射符号。
- R: 值域 (Codomain),所有输出所属的目标集合。
- 示例1:一个非满射函数
- 令 $D = \{1, 2, 3\}$, $R = \{A, B, C, D\}$。
- 定义函数 f: D -> R 如下:f(1)=A, f(2)=B, f(3)=A。
- 域: $\{1, 2, 3\}$
- 值域: $\{A, B, C, D\}$
- 像: $\{A, B\}` (实际输出的集合)
- 因为像 $\neq$ 值域 (值域中的 C 和 D 没有被任何输入映射到),所以 f 不是满射。
- 示例2:一个满射函数
- 令 $D = \{1, 2, 3, 4\}$, $R = \{A, B\}$。
- 定义函数 g: D -> R 如下:g(1)=A, g(2)=B, g(3)=A, g(4)=B。
- 域: $\{1, 2, 3, 4\}$
- 值域: $\{A, B\}$
- 像: $\{A, B\}`
- 因为像 = 值域,所以 g 是满射。
- 值域 (Codomain) vs 像 (Image):这是函数理论中一个非常重要但初学者容易混淆的概念。教科书和不同领域中 “Range” 这个词的用法有歧义,有时指Codomain,有时指Image。最清晰的做法是明确使用 Codomain 和 Image 这两个术语。本书中用的“值域”更偏向于Codomain。
- 函数定义必须包含域和值域: 严格来说,一个完整的函数定义 f 不仅包含其映射规则,还必须包含其域 $D$ 和值域 $R$。改变 $D$ 或 $R$ 都会得到一个不同的函数。
域是函数所有合法输入的集合。值域是函数所有输出的目标集合。函数签名 $f: D \to R$ 精确地定义了这两者。函数的实际输出集合(像)是值域的一个子集,如果两者相等,则称该函数为满射。
定义域和值域,是为了让函数的讨论更加严谨和安全。
- 类型检查: 在编程中,这相当于强类型语言的函数签名。int add(int a, int b) 告诉编译器,这个函数只接受两个整数,并返回一个整数。如果你尝试传入一个字符串,编译器就会报错。这防止了大量潜在的运行时错误。
- 数学分析: 在数学上,研究函数的性质(如是否连续、可微、是否为满射、单射等)都必须基于其清晰的域和值域定义。
继续用自动售货机的例子。f: D -> R
- 域 D: 机器上所有有效的按钮组合的集合。例如,A1 到 F8。你不可以按一个不存在的按钮 Z9。
- 值域 R: 这台机器被设计用来存放的所有商品类型的集合。比如,制造商说这台机器可以放 {可乐, 雪碧, 橙汁, 薯片, 巧克力}。这就是值域。
- 像: 今天这台机器里实际装有的商品。可能管理员只装了 {可乐, 薯片}。这就是像。
- 满射: 如果管理员把值域中所有类型的商品都装进了机器,那么这台机器对于其值域就是“满射”的。
想象一场射箭比赛。
- 域 D: 弓箭手(函数)拥有的所有箭的集合。
- 值域 R: 整个靶子(包括最外圈和木质背板)。
- 映射过程: 弓箭手射出一支箭(输入),箭落在靶子上的一个点(输出)。
- 像: 所有箭实际射中的点的集合。这个集合显然是整个靶子(值域)的一个子集。
- 满射: 如果这位弓箭手出神入化,能保证靶子上的任何一个点,他都能精确地射中(至少有一支箭能射到那),那么他的射箭技艺对于这个靶子就是“满射”的。
14.3 函数的描述方式
📜 [原文18]
我们可以通过几种方式描述一个特定的函数。一种方式是使用一个从指定输入计算输出的过程。另一种方式是使用一个列出所有可能输入并给出每个输入的输出的表格。
这里介绍了描述函数的两种主要方法,特别适用于域是有限集的情况。
- 方法一:过程/规则描述 (Procedural/Rule-based Description)
- 思想: 给出一种算法或一个公式,告诉我们如何计算输出。
- 例子:
- f(x) = x^2 + 2x + 1。这是一个代数过程。给定任何 x,你都可以通过计算得到 f(x)。
- abs(x) 函数的描述:“如果x为正则返回x,如果x为负则返回-x”。这是一个过程性的描述。
- 优点:
- 紧凑: 一个简单的规则可以描述一个拥有无限域的函数。
- 普适: 只要是可计算的,就能用过程描述。
- 缺点: 有时规则可能非常复杂。
- 方法二:表格描述 (Tabular Description)
- 思想: 当函数的域是有限的、且元素不多时,我们可以像列清单一样,把所有输入和对应的输出一一列出。
- 形式: 通常用一个两列表格,左边是输入,右边是对应的输出。
- 优点:
- 直观明了: 所有对应关系一目了然,无需计算。
- 可以描述任意关系: 即使一个函数毫无规律可言,只要域是有限的,就可以用表格描述。
- 缺点:
- 只适用于有限域: 对于像 square(x) 这样域是所有实数的函数,无法使用表格。
- 冗长: 即使域是有限的,如果元素很多,表格也会变得巨大无比。
一个函数,两种描述
考虑一个函数 $g: \{0, 1, 2\} \to \{A, B, C\}$。
- 过程描述:
- g(n) 的规则是:如果 $n=0$, 输出 A;如果 $n=1$, 输出 B;如果 $n=2$, 输出 C。
- 表格描述:
| $n$ | $g(n)$ |
|---|---|
| 0 | A |
| 1 | B |
| 2 | C |
对于这个简单的有限域函数,两种描述是等价的。
另一个例子
函数 $h: \{a, b\} \to \{0, 1\}$
- 过程描述: “输入如果是元音字母,输出1;否则输出0”。
- 表格描述:| input | output |
| :---: | :----: |
|---|---|
| b | 0 |
- 表格法的前提是有限域: 必须强调,只有当函数的域是有限集时,列表格才是可行的。
- 过程法可能隐含域: 当只给出一个公式如 f(x) = 1/x 时,通常隐含了其“自然域”,即所有能使表达式有意义的输入集合。这里,自然域是所有非零实数。
描述一个函数,可以用过程/规则(一个公式或算法),这适用于任何函数,特别是无限域函数;也可以用表格,将所有输入-输出对一一列出,这只适用于有限域函数。
为了说明定义函数的灵活性。在计算理论中,我们会遇到各种函数的描述方式。
- 状态转移函数:在自动机中,转移函数 $\delta$ 常常用一个表格来表示,因为状态集和字母表都是有限的。
- 可计算函数: 在研究什么问题是“可计算”的,我们关心的是是否存在一个过程(即一个算法或图灵机)来描述这个函数。
- 过程描述: 给你一本菜谱。你想做什么菜(输入),就按照菜谱上的步骤(过程)去做,最后得到成品(输出)。
- 表格描述: 给你一份快餐店的套餐菜单。左边是套餐编号(1号,2号,...),右边是套餐内容。你点什么号,就给你什么内容,非常直接,没有计算过程。
- 过程描述: 一个 GPS 导航系统。你输入目的地(输入),它会通过复杂的路网算法(过程)计算出一条最佳路线(输出)。
- 表格描述: 一张公交线路图。上面列出了所有站点(输入域),以及每个站点对应的预计到站时间(输出)。
14.4 示例 0.8:模运算函数
📜 [原文19]
示例 0.8
考虑函数 $f:\{0,1,2,3,4\} \longrightarrow\{0,1,2,3,4\}$。
| $n$ | $f(n)$ |
| :---: | :------: |
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 0 |
这个函数将其输入加 1,然后输出结果模 5。一个数模 $m$ 是除以 $m$ 后的余数。例如,钟面上的分针是模 60 计数。当我们进行模运算时,我们定义 $\mathcal{Z}_{m}=\{0,1,2, \ldots, m-1\}$。使用这个符号,上述函数 $f$ 的形式是 $f: \mathcal{Z}_{5} \longrightarrow \mathcal{Z}_{5}$。
- 函数签名分析: $f: \{0,1,2,3,4\} \to \{0,1,2,3,4\}$
- 域: $\{0, 1, 2, 3, 4\}。函数 f` 只接受这5个整数作为输入。
- 值域: 也是 $\{0, 1, 2, 3, 4\}。f` 的输出结果也必须是这5个整数之一。
- 表格分析: 表格清晰地列出了每个输入对应的输出。
- f(0) = 1
- f(1) = 2
- f(2) = 3
- f(3) = 4
- f(4) = 0 (这是最特殊的一点)
- 发现规律(从表格到过程):
- 对于输入 0, 1, 2, 3,规律很简单:f(n) = n + 1。
- 但是对于输入 4,f(4) 不是 5,而是 0。这提示我们这不是简单的加法。
- 4 + 1 = 5,而输出是 0。在 \{0, 1, 2, 3, 4\} 这个圈子里,5 和 0 是怎么联系起来的?
- 引入模运算 (Modulo Operation)
- “一个数模 m 是除以 m 后的余数”: 这是模运算的核心定义。
- a mod m 等于 a 除以 m 的余数。
- 例如, 7 mod 5:7 / 5 = 1 ... 2。所以 7 mod 5 = 2。
- 例如, 10 mod 3:10 / 3 = 3 ... 1。所以 10 mod 3 = 1。
- 例如, 5 mod 5:5 / 5 = 1 ... 0。所以 5 mod 5 = 0。
- 用模运算解释函数 f:
- 该函数的过程是:f(n) = (n + 1) mod 5。
- 我们来验证一下:
- f(0) = (0 + 1) mod 5 = 1 mod 5 = 1。正确。
- f(1) = (1 + 1) mod 5 = 2 mod 5 = 2。正确。
- f(2) = (2 + 1) mod 5 = 3 mod 5 = 3。正确。
- f(3) = (3 + 1) mod 5 = 4 mod 5 = 4。正确。
- f(4) = (4 + 1) mod 5 = 5 mod 5 = 0。正确!
- 这个过程完美地解释了表格中的所有对应关系。
- 时钟类比: “钟面上的分针是模60计数”。这是一个极佳的类比。
- 分针走到58, 59,下一分钟不是60,而是回到00。
- 我们的函数 $f$ 就像一个只有0, 1, 2, 3, 4 这五个数字的“5小时制”时钟。指针在4点时,再过一个小时,就回到了0点。这种循环往复的特性是模运算的精髓。
- $\mathcal{Z}_m$ 符号:
- 这是一个非常常用和重要的记号,$\mathcal{Z}_m = \{0, 1, 2, ..., m-1\}$,代表了模 m 运算下所有可能的余数的集合。
- $\mathcal{Z}_5 = \{0, 1, 2, 3, 4\}$。
- 因此,函数 $f$ 的签名可以更简洁、更专业地写成 $f: \mathcal{Z}_5 \to \mathcal{Z}_5$。这不仅指明了输入输出的数值范围,还强烈地暗示了函数内部可能涉及模5的运算。
- 表格:| $n$ | $f(n)$ |
| :-----: | :--------: |
|---|
- 左列 $n$ 是输入。
- 右列 $f(n)$ 是对应的输出。
- 表格本身就是一种对函数的完整描述。
示例1:模3加法
- 函数 $g: \mathcal{Z}_3 \to \mathcal{Z}_3$,规则是 $g(n) = (n + 1) \mod 3$。
- $\mathcal{Z}_3 = \{0, 1, 2\}$。
- 表格描述:| $n$ | $g(n)$ |
| :-----: | :--------: |
|---|---|
| 1 | 2 |
| 2 | 0 |
示例2:模4乘法
- 函数 $h: \mathcal{Z}_4 \to \mathcal{Z}_4$,规则是 $h(n) = (n \times 2) \mod 4$。
- $\mathcal{Z}_4 = \{0, 1, 2, 3\}$。
- h(0) = (0 * 2) mod 4 = 0 mod 4 = 0
- h(1) = (1 * 2) mod 4 = 2 mod 4 = 2
- h(2) = (2 * 2) mod 4 = 4 mod 4 = 0
- h(3) = (3 * 2) mod 4 = 6 mod 4 = 2
- 表格描述:| $n$ | $h(n)$ |
| :-----: | :--------: |
|---|---|
| 1 | 2 |
| 2 | 0 |
| 3 | 2 |
- 负数的模运算: 不同编程语言对负数取模的定义可能不同。数学上,余数通常要求是 $\ge 0$ 的。例如 -7 mod 5,因为 -7 = 5 \times (-2) + 3,所以余数是3。
- $\mathcal{Z}_m$ 的范围: $\mathcal{Z}_m$ 包含从0到 m-1,共 m 个数。不包含 m 本身。
示例0.8通过一个表格描述的函数,引出了模运算的概念。模运算 a mod m 计算 a 除以 m 的余数,它在数学和计算机科学中非常重要,因为它能创建循环的、有限的代数系统。符号 $\mathcal{Z}_m$ 被用来表示 $\{0, 1, ..., m-1\}$ 这个模 m 的世界。
- 展示表格到规则的思维过程:鼓励读者不仅是接受函数的定义,还要尝试从具体例子中发现其背后的数学规律。
- 引入模运算: 模运算是密码学、哈希函数、数据结构(如循环队列)、以及有限自动机状态循环等众多计算机科学领域的基础。
- 引入 $\mathcal{Z}_m$ 记法: 这是有限域和群论中的标准记法,提前让读者熟悉。
模运算就是“循环的算术”。所有运算结果都被强制拉回到 $\{0, ..., m-1\}$ 这个有限的范围内。任何超出 m-1 的数,就像一个跑得太远的孩子,被一条长度为 m 的橡皮筋“嗖”地一下拉回到起点附近。
- 时钟: 最经典的想象。13点就是下午1点(13 mod 12 = 1,如果12点记为0的话)。
- 星期: 今天是星期三(假设记为3),10天后是星期几?$(3 + 10) \mod 7 = 13 \mod 7 = 6。所以是星期六。
- 绕圈跑: 在一个周长为 m 米的圆形跑道上,你从起点跑了 a 米,你现在的位置就是 a mod m 米处。
14.5 示例 0.9:二维表格与二元函数
📜 [原文20]
示例 0.9
如果函数的域是两个集合的笛卡尔积,有时会使用二维表格。这是另一个函数 $g: \mathcal{Z}_{4} \times \mathcal{Z}_{4} \longrightarrow \mathcal{Z}_{4}$。表格中标记为 $i$ 的行和标记为 $j$ 的列中的条目是 $g(i, j)$ 的值。
| $g$ | 0 | 1 | 2 | 3 |
| :---- | :- | :- | :- | :- |
| 0 | 0 | 1 | 2 | 3 |
| 1 | 1 | 2 | 3 | 0 |
| 2 | 2 | 3 | 0 | 1 |
| 3 | 3 | 0 | 1 | 2 |
函数 $g$ 是模 4 的加法函数。
- 二元函数 (Binary Function): 这个例子中的函数 $g$ 与上一个例子中的 $f$ 有个关键不同:它的输入不是单个数字,而是一个有序对。这种接受两个输入的函数称为二元函数。
- 函数签名分析: $g: \mathcal{Z}_{4} \times \mathcal{Z}_{4} \to \mathcal{Z}_{4}$
- 域: $\mathcal{Z}_{4} \times \mathcal{Z}_{4}$。
- $\mathcal{Z}_4 = \{0, 1, 2, 3\}$。
- 所以域是 $\{0, 1, 2, 3\} \times \{0, 1, 2, 3\}$。这是一个由 $4 \times 4 = 16$ 个有序对组成的集合,例如 (0, 0), (0, 1), ..., (3, 3)。
- 值域: $\mathcal{Z}_{4}$。输出结果是一个0到3之间的整数。
- 二维表格描述法:
- 当域是笛卡尔积 $A \times B$ 时,用简单的两列表格就不方便了。
- 一个更自然的方式是使用二维表格(或叫运算表),类似于乘法表。
- 行标签 (row labels): 代表有序对的第一个元素(这里是 $i$)。
- 列标签 (column labels): 代表有序对的第二个元素(这里是 $j$)。
- 表格内部的条目: 第 $i$ 行和第 $j$ 列交叉处的单元格,其值就是函数对输入 (i, j) 的输出,即 $g(i, j)$。
- 读取表格:
- 想知道 $g(2, 3) 的值是多少?
- 找到行标签为 2 的那一行。
- 找到列标签为 3 的那一列。
- 在它们交叉的地方,我们看到数字 1。
- 所以,$g(2, 3) = 1$。
- 想知道 $g(1, 1)` 的值?找到第1行第1列,值是 `2`。所以 `$g(1, 1) = 2$。
- 发现规律:
- 表格的标题明确说,这个函数是模4的加法函数。
- 这意味着 $g(i, j) = (i + j) \mod 4$。
- 我们来验证一下刚才的计算:
- $g(2, 3) = (2 + 3) \mod 4 = 5 \mod 4 = 1$。与表格相符。
- $g(1, 1) = (1 + 1) \mod 4 = 2 \mod 4 = 2$。与表格相符。
- 我们可以验证表格中的任何一个条目,都会发现它满足这个规律。例如,$g(3, 3) = (3+3) \mod 4 = 6 \mod 4 = 2$,但表格中对应位置是 2,这说明原文的表格可能有误,或者我理解错了。
- 重新检查原文表格:| g | 0 | 1 | 2 | 3 |
| - | - | - | - | ----------- |
|---|
- (3+3) mod 4 = 6 mod 4 = 2。表格是正确的。我的心算没错。
- (3+2) mod 4 = 5 mod 4 = 1。表格是正确的。
- 二维表格:| $g$ | ...j... |
| :---------- | :----------: |
|---|
- 这是一种描述二元函数 $g(i, j)$ 的方法。表格的行、列分别对应函数的两个输入参数,表格的单元格内容是函数的输出。
示例1:模3乘法
- 函数 $h: \mathcal{Z}_3 \times \mathcal{Z}_3 \to \mathcal{Z}_3$,规则是 $h(i, j) = (i \times j) \mod 3$。
- 二维表格描述:| $h$ | 0 | 1 | 2 |
| :------ | :-: | :-: | :-: |
|---|---|---|---|
| 1 | 0 | 1 | 2 |
| 2 | 0 | 2 | 1 |
示例2:普通乘法 (部分)
- 函数 $mul: \{1, 2\} \times \{1, 2, 3\} \to \mathcal{N}$,规则是 mul(i, j) = i * j。
- 二维表格描述:| mul | 1 | 2 | 3 |
| :------ | :-: | :-: | :-: |
|---|---|---|---|
| 2 | 2 | 4 | 6 |
- 行和列的顺序: 要明确表格的行代表第一个参数还是第二个参数。本例中明确“$i$ 的行和 $j$ 的列”,所以输入是 (i, j)。
- 对称性: 观察本例中的表格,沿着左上到右下的对角线,表格是对称的。$g(i, j) = g(j, i)。这是因为普通加法满足交换律 i+j = j+i。对于不满足交换律的运算(比如减法),其运算表将是不对称的。
示例0.9展示了如何使用二维表格来直观地描述一个二元函数(即域是笛卡尔积的函数)。表格的行和列对应函数的两个输入,单元格内容是输出。这个例子特别展示了模4加法函数的运算表。
- 引入二元函数的概念和表示法: 很多重要的运算(加、减、乘、除、逻辑与、逻辑或)都是二元函数。
- 展示二维表格的用处: 在有限自动机理论中,转移函数 $\delta(\text{当前状态}, \text{输入符号}) = \text{下一个状态}` 就是一个二元函数。因为状态集和符号集通常是有限的,所以转移函数非常适合用二维表格来表示。这个例子是在为后续的核心概念铺路。
二维表格就是一张地图或棋盘。
- 你要找一个地方,需要两个坐标:经度(比如列)和纬度(比如行)。
- 二元函数 $g(i, j)$ 就是这张地图本身,它告诉你每个坐标 (i, j) 上的“海拔高度”或“地名”是什么。
一张小学生的乘法口诀表。
- 行是 1, ..., 9 (集合A)。
- 列是 1, ..., 9 (集合B)。
- 表格的内容 九九八十一 就是函数 mul: A \times B \to \mathcal{N} 的输出。
14.6 函数的元数与表示法
📜 [原文21]
当函数 $f$ 的域是某个集合 $A_{1}, \ldots, A_{k}$ 的笛卡尔积 $A_{1} \times \cdots \times A_{k}$ 时,$f$ 的输入是一个 $k$-元组 $(a_{1}, a_{2}, \ldots, a_{k})$,我们称 $a_{i}$ 为 $f$ 的参数。一个带有 $k$ 个参数的函数称为 $k$-元函数, $k$ 称为函数的元数。如果 $k$ 为 1,$f$ 有一个参数, $f$ 称为一元函数。如果 $k$ 为 2,$f$ 是二元函数。某些熟悉的二元函数以特殊的中缀表示法书写,函数的符号放在其两个参数之间,而不是以前缀表示法书写,符号放在前面。例如,加法函数 $add$ 通常以中缀表示法书写,用 + 符号放在其两个参数之间,如 $a+b$,而不是前缀表示法 $add(a, b)$。
- k-元函数 (k-ary Function)
- 核心思想: 这是对函数输入复杂性的一种分类。我们根据函数需要“吃”掉多少个东西才能算出一个结果,来给它命名。
- 形式化定义: 一个函数的域如果是k重笛卡尔积 $A_1 \times \cdots \times A_k$,那么这个函数就是一个k-元函数。
- 输入: k-元函数的输入是一个 k-元组 $(a_1, \ldots, a_k)$。
- 参数 (Argument): k-元组中的每一个分量 $a_i$,都称为函数的一个参数。
- 元数 (Arity): 数字 $k$,即参数的个数,被称为函数的元数。
- 常见元数的名称:
- k=1, 一元函数 (Unary Function): 接受一个参数。例如 abs(x), square(x)。域是 $A_1$。
- k=2, 二元函数 (Binary Function): 接受两个参数。例如 add(a, b), max(a, b)。域是 $A_1 \times A_2$。
- k=3, 三元函数 (Ternary Function): 接受三个参数。
- k=0, 零元函数 (Nullary Function): 接受零个参数。这听起来很奇怪,但它在数学和计算机科学中是有意义的。一个零元函数不需要任何输入,并且总是返回一个常量值。例如,一个函数 pi() 总是返回 3.14159...。
- 函数表示法 (Notation)
- 前缀表示法 (Prefix Notation): 这是最通用、最标准的函数表示法。函数名在前,括号里是逗号分隔的参数列表。例如 f(a, b, c)。几乎所有编程语言中的函数调用都采用这种形式。
- 中缀表示法 (Infix Notation): 这是一种特殊的、只适用于二元函数的表示法。函数符号被放在两个参数的中间。
- 例子: 我们不常写 add(a, b),而是写 $a + b$。我们不写 less_than(a, b),而是写 $a < b$。
- 原因: 这是我们从小学开始就习惯的算术和关系表示法,它非常自然和可读。
- 后缀表示法 (Postfix Notation): 符号放在参数之后,如 $a b +$。这在某些计算器(如惠普的RPN计算器)和编程语言(如Forth)中使用。
示例1:不同元数的函数
- 一元函数: negate(x) = -x。 negate(5) = -5。
- 二元函数: subtract(x, y) = x - y。 subtract(10, 3) = 7。
- 三元函数: if_then_else(condition, val_if_true, val_if_false)。
- if_then_else(True, 5, 10) 的结果是 5。
- if_then_else(False, 5, 10) 的结果是 10。
- 零元函数: get_current_year(),假设它总是返回 2026。
示例2:不同表示法的转换
- 表达式 (3 + 4) * 5
- 前缀表示法 (Lisp风格): (* (+ 3 4) 5)
- 中缀表示法 (我们习惯的): (3 + 4) * 5
- 后缀表示法 (逆波兰表示法): 3 4 + 5 *
- 中缀表示法的局限性: 中缀表示法只能用于二元函数。对于一元或三元及以上的函数,必须使用前缀(或后缀)表示法。
- 运算符优先级和结合性: 使用中缀表示法时,为了避免歧义,必须引入运算符优先级 (Precedence) (例如 * 优先于 +) 和 结合性 (Associativity) (例如 a-b-c 是 (a-b)-c 还是 a-(b-c)) 的规则。例如 $3 + 4 * 5$ 被解释为 $3 + (4*5)$ 而不是 $(3+4)*5$。前缀和后缀表示法没有这个烦恼,因为运算顺序是明确的。
k-元函数是接受k个参数的函数,其输入域是k重笛卡尔积。k 称为函数的元数。最常见的一元和二元函数。函数的标准表示法是前缀表示法 (f(a, b)),但对于我们熟悉的二元运算,通常使用更自然的中缀表示法 (a + b)。
为了建立一套描述函数输入结构的词汇。“元数”这个概念帮助我们对函数进行分类和讨论其性质。区分不同的表示法(前缀、中缀)有助于理解数学表达式和计算机语言解析的底层逻辑。
- 元数: 就像一个工具需要几只手来操作。
- 一元函数: 一把手电筒,一只手就能操作。
- 二元函数: 一把剪刀,需要拇指和食指两根手指配合。
- 三元函数: 一个手动打蛋器,一只手握住碗,一只手扶住手柄,另一只手转动摇杆。
- 表示法: 就像写日期的不同习俗。
- 前缀 f(a, b): 国际标准 YYYY-MM-DD (2026-01-21),逻辑清晰,便于计算机处理。
- 中缀 a + b: 美式 MM/DD/YYYY (01/21/2026),在特定文化圈内很自然。
- 后缀: 德式 DD.MM.YYYY (21.01.2026),也是一种习惯。
想象一个厨房里的搅拌机。
- 它的元数取决于它有多少个配料入口。如果它只有一个大入口,可以看作一元函数(输入是一整包预混合好的材料)。如果它有 A, B, C 三个独立的入口,分别放水果、牛奶和糖,那它就是一个三元函数。
- 前缀表示法: 搅拌(水果, 牛奶, 糖)。
- 中缀表示法: 没有很好的类比,因为它主要用于二元运算。
- 搅拌机的按钮 "启动"、"停止",可以看作是接受无参数的函数调用。
14.7 谓词与关系
📜 [原文22]
谓词或属性是值域为 {TRUE, FALSE} 的函数。例如,设 $even$ 是一个属性,如果其输入是偶数则为 TRUE,如果其输入是奇数则为 FALSE。因此 $even(4)=$ true 且 $even(5)=$ FALSE。
域是 $k$-元组集合 $A \times \cdots \times A$ 的属性称为关系, $k$-元关系,或A上的$k$-元关系。一个常见的情况是二元关系。在涉及二元关系的表达式中,我们习惯使用中缀表示法。例如,“小于”是一种关系,通常用中缀运算符 < 来书写。“等于”,用 = 符号书写,是另一个熟悉的关系。如果 $R$ 是一个二元关系,语句 $a R b$ 意味着 $a R b=$ TRUE。类似地,如果 $R$ 是一个 $k$-元关系,语句 $R\left(a_{1}, \ldots, a_{k}\right)$ 意味着 $R\left(a_{1}, \ldots, a_{k}\right)=$ TRUE。
- 谓词 (Predicate) 或 属性 (Property)
- 核心定义: 一种特殊的函数,它的输出结果只有两种可能:TRUE 或 FALSE。
- 它不像普通函数那样计算一个数值或返回一个新对象,而是对输入进行一个“是/非”的判断。
- 谓词/属性: 这两个词基本可以互换使用。“属性”更侧重于描述输入对象本身具有的某种性质(例如,“是偶数”是数字4的一个属性)。“谓词”则更侧重于描述一个可以对输入进行判断的逻辑语句。
- 示例分析 even:
- 函数名:even
- 域:$\mathcal{Z}$ (整数集)
- 值域:{TRUE, FALSE}
- 规则:输入 n,如果 n 能被2整除,输出 TRUE;否则输出 FALSE。
- even(4) = TRUE
- even(5) = FALSE
- 关系 (Relation)
- 核心定义: 关系是一种特殊的谓词,它的输入是一个 k-元组。
- 换句话说,关系是用来判断多个对象之间是否存在某种联系的。
- k-元关系: 输入是k-元组的关系。
- 二元关系 (Binary Relation): 最常见的一种,输入是有序对 (2-元组)。它描述的是两个对象之间的关系。
- 域: $A \times B$ 或 $A \times A$。
- 值域: {TRUE, FALSE}。
- 二元关系的表示法:
- 前缀表示法: R(a, b)。例如,less_than(3, 5) = TRUE。
- 中缀表示法: $a R b$。这是我们更习惯的方式。例如,$3 < 5$。
- $a R b$ 这种写法是一个语法糖,它等价于说 R(a, b) = TRUE。当我们写下 $3 < 5$ 时,我们是在断言一个为真的命题。当我们写 $5 < 3$ 时,我们断言了一个为假的命题。
- k-元关系的表示法: 对于k大于2的情况,通常只能用前缀表示法。例如,一个三元关系 Between(a, b, c) 可能用来判断 b 是否在 a 和 c 之间。
- 谓词/属性 示例:
- IsPrime(n): 输入一个自然数n,如果n是质数,返回TRUE,否则返回FALSE。
- IsPrime(7) = TRUE
- IsPrime(9) = FALSE
- IsEmpty(S): 输入一个集合S,如果S是空集,返回TRUE,否则返回FALSE。
- IsEmpty(\emptyset) = TRUE
- IsEmpty({a}) = FALSE
- 关系 示例:
- 二元关系: “整除”关系 divides。divides(a, b) 判断 $a$ 是否能整除 $b$。
- 我们通常写成 $a | b$ (中缀表示)。
- $3 | 12$ (读作 3 divides 12) 是 TRUE。
- $5 | 12$ 是 FALSE。
- 三元关系: IsSumOf(a, b, c),判断是否有 $a + b = c$。
- IsSumOf(3, 4, 7) = TRUE。
- IsSumOf(1, 2, 4) = FALSE。
- 函数 vs 关系: 所有关系都是谓词,所有谓词都是函数。但反过来不成立。一个返回数字的函数(如 add)不是谓词。一个接受单个输入的谓词(如 even)不是关系(在k>1的意义上)。“关系”这个词通常保留给多输入谓词。
- 对称关系: 如果一个二元关系 R 满足只要 $a R b$ 为真,$b R a$ 就一定为真,则称 R 是对称的。例如,“等于”关系是对称的,但“小于”关系不是。
谓词是一种输出只有TRUE或FALSE的特殊函数,用于判断输入是否具有某种属性。关系是一种特殊的谓词,其输入是k-元组,用于判断多个对象间是否存在某种联系。最常见的二元关系通常用方便的中缀表示法(如 $a < b$)书写。
谓词和关系是逻辑和离散数学的基石。
- 形式化规范: 在软件工程中,可以用谓词来精确定义一个函数的前置条件和后置条件。例如,对于开平方根函数 sqrt(x),前置条件是 IsNonNegative(x) = TRUE。
- 数据库查询: 数据库查询语言 (如SQL) 的 WHERE 子句,本质上就是一个巨大的谓词,用来筛选出满足特定关系的记录行。
- 图论: 图的邻接关系 Adj(u, v) 是一个二元关系,判断节点u和v之间是否有边。
- 谓词 (属性): 就像一个质量检测员,手里拿着一个“合格/不合格”的图章。每个送来的产品(输入),他检查一下,然后盖上一个章(TRUE/FALSE)。
- 关系: 就像一个家庭关系调解员。他需要至少两个人(二元关系)或更多人(k-元关系)同时到场,然后判断他们之间是否存在某种关系,比如“是父子关系吗?”(TRUE/FALSE),“是兄弟关系吗?”(TRUE/FALSE)。
- 谓词: 你在手机相册里使用“筛选”功能。
- IsFavorite(photo): 筛选出所有标记为“喜爱”的照片。
- TakenIn(photo, "Paris"): 筛选出所有在巴黎拍摄的照片。(这是一个二元关系)
- 关系: 在社交网络中。
- IsFriendOf(Alice, Bob): 判断 Alice 和 Bob 是否是好友。
- Follows(Alice, Bob): 判断 Alice 是否关注了 Bob。这通常是非对称的。
14.8 示例 0.10:关系的游戏应用
📜 [原文23]
示例 0.10
在儿童游戏“剪刀-石头-布”中,两名玩家同时从集合 {SCISSORS, PAPER, STONE} 中选择一个成员,并用手势表示他们的选择。如果两个选择相同,游戏重新开始。如果选择不同,则一名玩家获胜,根据关系 $beats$。
| beats | SCISSORS | PAPER | STONE |
| :------: | :------: | :---: | :---: |
| SCISSORS | FALSE | TRUE | FALSE |
| PAPER | FALSE | FALSE | TRUE |
| STONE | TRUE | FALSE | FALSE |
从这个表格中我们确定 SCISSORS beats PAPER 是 TRUE,PAPER beats SCISSORS 是 FALSE。
这个示例展示了如何用上一节定义的关系概念来形式化地描述一个我们都熟悉的游戏规则。
- 确定论域 (Domain of Discourse): 游戏中的对象来自哪个集合?
- 集合是 $S = \{\text{SCISSORS, PAPER, STONE}\}$。
- 识别关系: 游戏的核心规则是“什么克制什么”。这是一个典型的两者之间的关系,所以它是一个二元关系。
- 我们给这个关系起个名字,叫 $beats$。
- 定义域和值域:
- $beats$ 函数的输入是一个有序对 (player1_choice, player2_choice),其中两个选择都来自集合 $S$。
- 所以,$beats$ 的域是 $S \times S$。
- $beats$ 的输出是 {TRUE, FALSE},因为它判断“前者是否克制后者”。
- 因此,函数签名是 $beats: S \times S \to \{\text{TRUE, FALSE}\}$。
- 用二维表格描述关系:
- 由于这是一个定义在有限集上的二元函数,使用二维表格来描述它非常合适。
- 行: 代表有序对的第一个元素(攻击方)。
- 列: 代表有序对的第二个元素(防御方)。
- 单元格内容: TRUE 或 FALSE,表示行是否克制列。
- 解读表格:
- $beats(\text{SCISSORS, PAPER})$: 找到 "SCISSORS" 行和 "PAPER" 列的交叉点,内容是 TRUE。这意味着“剪刀克制布”是真的。
- $beats(\text{PAPER, SCISSORS})$: 找到 "PAPER" 行和 "SCISSORS" 列的交叉点,内容是 FALSE。这意味着“布克制剪刀”是假的。
- $beats(\text{SCISSORS, SCISSORS})$: 找到 "SCISSORS" 行和 "SCISSORS" 列的交叉点,内容是 FALSE。这意味着“剪刀克制剪刀”是假的,即平局。对角线上的所有元素都是 FALSE,这与游戏平局的规则相符。
- 非对称性: 观察表格,它不是对称的。例如,$beats(\text{SCISSORS, PAPER}) = \text{TRUE}`,但 `$beats(\text{PAPER, SCISSORS}) = \text{FALSE}。这种性质称为非对称性 (asymmetric),它是很多“竞争”关系(如大于、克制)的特点。
本节本身就是一个完整的示例。这里提供另一个。
示例:大于关系 > 在集合 {1, 2} 上的表现
- 关系名: greater_than
- 域: $\{1, 2\} \times \{1, 2\}$
- 二维表格:| > | 1 | 2 |
| :---: | :---: | :---: |
|---|---|---|
| 2 | TRUE | FALSE |
- greater_than(2, 1) 是 TRUE。
- greater_than(1, 2) 是 FALSE。
- 将关系视为单向的: 看到 SCISSORS beats PAPER 为 TRUE,不能想当然地认为 PAPER beats SCISSORS 也为 TRUE 或 FALSE,必须去查表或者根据规则判断。关系 R(a,b) 和 R(b,a) 是两个独立的判断。
- 关系的完备性: 这个表格定义了 $S \times S$ 域上所有可能的输入对。对于任何一对选择,我们都可以从表格中得到一个确定的 TRUE 或 FALSE,这满足函数(谓词)的定义。
示例0.10使用“剪刀-石头-布”游戏,生动地展示了如何将一个现实世界的规则系统,通过二元关系这一数学工具进行精确、无歧义的描述。二维表格是表示有限集上二元关系的有效方法。
- 连接抽象与现实: 将前面介绍的抽象的“关系”概念与一个家喻户晓的例子联系起来,极大地降低了理解门槛。
- 强化二元函数与二维表格的联系: 再次展示了二维表格是描述二元函数的有力工具。
- 引入非对称关系: 通过一个具体的例子,让读者直观地感受到并非所有关系都是对称的。
这个表格就像是游戏内置的“裁判逻辑”。当两个玩家出拳后,裁判(函数 beats)就会去查这张“规则表”,然后宣布结果。表格本身就是规则的化身。
想象一张战斗属性克制图,常见于角色扮演游戏中。
- 行是“攻击方属性”(火、水、草)。
- 列是“防御方属性”(火、水、草)。
- 表格内容可能是 "效果绝佳 (TRUE)", "效果一般 (FALSE)", "没有效果 (FALSE)"。
- 例如,(火, 草) 交叉点是 TRUE,(水, 草) 交叉点是 FALSE。
这个克制图就是一个二元关系的二维表格表示。
14.9 关系的集合表示法
📜 [原文24]
有时用集合而不是函数描述谓词更方便。谓词 $P: D \longrightarrow\{\text{TRUE, FALSE}\}$ 可以写成 $(D, S)$,其中 $S=\{a \in D \mid P(a)=\text{TRUE}\}$,如果域 $D$ 很明显,则简写为 $S$。因此,关系 $beats$ 可以写成
- 两种视角,一个事物: 这里提出了描述谓词/关系的另一种等价方式。
- 函数视角: 谓词是一个函数,它对输入进行判断,返回 TRUE 或 FALSE。
- 集合视角: 我们只关心那些能让谓词返回 TRUE 的输入。我们可以把所有这些“成功的”输入收集起来,组成一个集合。
- 从函数到集合的转换:
- 给定一个谓词 $P: D \to \{\text{TRUE, FALSE}\}$。
- 我们可以构造一个集合 $S_P$,它的定义是:$S_P = \{a \in D \mid P(a) = \text{TRUE}\}$。
- 这个集合 $S_P$ 是域 $D$ 的一个子集。它精确地“圈出”了所有让谓词P成立的输入。
- 等价性:
- 知道函数 $P$,就可以唯一确定集合 $S_P$。
- 反过来,知道集合 $S_P$(以及域D),也可以唯一确定函数 $P$ 的规则:如果输入 $a \in S_P$,则 $P(a) = \text{TRUE}$;如果输入 $a \notin S_P$ (但 $a \in D$),则 $P(a) = \text{FALSE}$。
- 因此,这两种表示法是完全等价的,可以相互转换。
- 应用到关系上:
- 关系是一种输入为k-元组的谓词。
- 因此,一个k-元关系可以被表示为一个由k-元组组成的集合。
- 这个集合包含了所有让该关系为 TRUE 的k-元组。
- 示例分析:
- 关系是 $beats: S \times S \to \{\text{TRUE, FALSE}\}$,其中 $S = \{\text{SCISSORS, PAPER, STONE}\}$。
- 域是 $S \times S$。
- 我们要构建一个集合,包含所有让 $beats(a, b) 为 TRUE 的有序对 (a, b)。
- 查上一个例子的表格:
- beats(SCISSORS, PAPER) = TRUE -> 将 (SCISSORS, PAPER) 放入集合。
- beats(PAPER, STONE) = TRUE -> 将 (PAPER, STONE) 放入集合。
- beats(STONE, SCISSORS) = TRUE -> 将 (STONE, SCISSORS) 放入集合。
- 表格中其他所有对应的值都是 FALSE,所以我们不把那些输入(如 (SCISSORS, STONE))放入集合。
- 最终得到的集合就是 $\{(\text{SCISSORS, PAPER}), (\text{PAPER, STONE}), (\text{STONE, SCISSORS})\}$。这个集合简洁地编码了游戏的全部“克制”规则。
- { ... }: 这是一个集合。
- (...): 集合的元素是有序对 (2-元组)。
- 这个集合是笛卡尔积 $S \times S$ 的一个子集。
- 这个集合只列出了所有使得 $beats$ 关系为 TRUE 的输入对,它隐含了所有未被列出的输入对都会使 $beats$ 关系为 FALSE。
- 示例1:even 谓词
- 函数视角:even: \mathcal{Z} \to \{\text{TRUE, FALSE}\}。
- 集合视角:$E = \{\ldots, -4, -2, 0, 2, 4, \ldots\}$。even(n) 为 TRUE 当且仅当 $n \in E$。
- 示例2:小于 关系在 {1, 2, 3} 上
- 关系名:<
- 域:$\{1, 2, 3\} \times \{1, 2, 3\}$
- 函数视角:less_than(a, b)
- 集合视角(所有使 a < b 为 TRUE 的有序对 (a, b)):
- 域的重要性: 集合表示法通常会省略掉那些返回 FALSE 的情况。但这样做有一个前提,就是我们必须清楚地知道论域 D 是什么。否则,对于一个不在集合中的元素,我们无法判断它是返回 FALSE,还是它根本就不是一个合法的输入。所以,完整的集合表示法应该是 (D, S) 这一对,但在上下文明确的情况下,可以只写 S。
一个谓词或关系,既可以看作一个返回TRUE/FALSE的函数,也可以等价地看作一个集合,该集合包含了所有使此谓词/关系为TRUE的输入。对于k-元关系,它等价于一个由k-元组构成的集合。
提供一种更简洁、更以数据为中心的视角来看待关系。
- 简洁性: 对于稀疏的关系(即大部分输入都返回FALSE),用集合只列出少数为TRUE的情况,比画一个巨大的、大部分是FALSE的表格要简洁得多。
- 集合运算: 一旦关系被表示为集合,我们就可以直接对“关系”本身使用所有集合运算。例如,两个关系 R1 和 R2 的并集 $R_1 \cup R_2$ 是一个新的关系,当 $R_1$ 或 $R_2$ 成立时它就成立。这在数据库理论和逻辑编程中非常有用。
- 图的表示: 正如后面会看到的,一个有向图的边集,正是一个定义在顶点集上的二元关系的集合表示。
- 函数视角: 一个“法官”,你给他两个东西,他告诉你谁对谁错 (TRUE/FALSE)。
- 集合视角: 一本“名人录”,上面只记录了所有“获奖者”。如果你想知道某人是否获奖,你查这本名人录就行了。在名单上,就等价于 IsWinner(person) = TRUE。不在名单上,就等价于 IsWinner(person) = FALSE。
想象一张美国地图,我们要表示“两个州相邻”这个二元关系。
- 函数/表格视角: 制作一个 50x50 的巨大表格,行和列都是州名。如果两个州相邻,就在格子里填 TRUE,否则填 FALSE。这个表格绝大部分内容都是 FALSE。
- 集合视角: 创建一个列表(集合),只记录那些相邻的州对:{(加利福尼亚, 俄勒冈), (加利福尼亚, 内华达), ...}。这个列表会比那个50x50的表格要短得多,也直观得多。
14.10 等价关系
📜 [原文25]
一种特殊类型的二元关系,称为等价关系,捕捉了两个对象在某些特征上相等这一概念。二元关系 $R$ 是等价关系,如果 $R$ 满足三个条件:
- $R$ 具有自反性:对于每个 $x$,$x R x$;
- $R$ 具有对称性:对于每个 $x$ 和 $y$,如果 $x R y$ 则 $y R x$;
- $R$ 具有传递性:对于每个 $x, y$ 和 $z$,如果 $x R y$ 且 $y R z$ 则 $x R z$。
- 动机: 在数学中,我们经常想说两种不同的东西“在某种意义上是等价的”。例如,分数 1/2 和 2/4 写法不同,但代表的数值相同。等价关系就是用来精确捕捉这种“在...方面相同”的概念的数学工具。
- 核心: 等价关系是一种行为上非常类似“等于号 =”的二元关系。它必须满足以下三条“公理”。
- 三公理详解:
- 1. 自反性 (Reflexive):
- 对于每个 x, x R x
- 含义: 任何一个对象都与它自身“等价”。
- 直觉: 就像 = 一样,$x=x$ 永远成立。一个东西总等于它自己。
- 例子: “等于”关系满足自反性。但“小于”关系 < 不满足,因为 $x < x$ 不成立。
- 2. 对称性 (Symmetric):
- 对于每个 x 和 y,如果 x R y 则 y R x
- 含义: 如果 x 与 y 等价,那么 y 也必须与 x 等价。关系是双向的。
- 直觉: 就像 = 一样,如果 $x=y$,那么 $y=x$。
- 例子: “是...的同学”关系是对称的。如果A是B的同学,那么B也是A的同学。但“是...的父亲”关系不是对称的。
- 3. 传递性 (Transitive):
- 对于每个 x, y, 和 z,如果 x R y 且 y R z 则 x R z
- 含义: 等价关系可以“传递”。如果 x 与 y 等价,y 与 z 等价,那么 x 也与 z 等价。
- 直觉: 就像 = 一样,如果 $x=y$ 且 $y=z$,那么 $x=z$。
- 例子: “小于”关系 < 是传递的。如果 $x < y$ 且 $y < z$,那么 $x < z$。但“剪刀-石头-布”中的 beats 关系不是传递的:SCISSORS beats PAPER 且 PAPER beats STONE,但 SCISSORS beats STONE 是 FALSE。
- 示例1:“等于”关系 (=) 在整数集 $\mathcal{Z}$ 上
- 自反性: 对任意整数 x,$x=x$。满足。
- 对称性: 如果 $x=y$,那么 $y=x$。满足。
- 传递性: 如果 $x=y$ 且 $y=z$,那么 $x=z$。满足。
- 结论:= 是一个标准的等价关系。
- 示例2:“模n同余”关系
- 我们来检查下一个例子中提到的 $\equiv_7$。
- 关系 $R$ 定义在整数上,$x R y$ 当且仅当 $x-y$ 是7的倍数。
- 自反性: x R x? $x-x = 0$. 0是任何非零整数的倍数,所以0是7的倍数。满足。
- 对称性: 如果 x R y,即 $x-y = 7k$ (k是整数),那么 $y-x = -(x-y) = -7k = 7(-k)`。因为 `-k` 也是整数,所以 `$y-x$ 也是7的倍数。所以 y R x。满足。
- 传递性: 如果 x R y 且 y R z。即 $x-y = 7k_1$ 且 $y-z = 7k_2$。那么 $x-z = (x-y) + (y-z) = 7k_1 + 7k_2 = 7(k_1+k_2)`。因为 `$k_1+k_2$` 是整数,所以 `$x-z$ 是7的倍数。所以 x R z。满足。
- 结论:模n同余是一个等价关系。
- 示例3:一个非等价关系“小于等于 ($\le$)"
- 自反性: $x \le x$。满足。
- 对称性: 如果 $x \le y$,是否一定有 $y \le x$?不一定。例如 $3 \le 5$,但 $5 \le 3$ 不成立。不满足。
- 结论:$\le$ 不是等价关系。(它是一种“偏序关系”)。
- 三条必须同时满足: 缺少任何一条,都不是等价关系。
- 等价不等于相等: 等价关系的核心是提供一个比“严格相等”更宽泛的“相同”概念。例如,“出生在同一年”是一个等价关系。你和你的同学可能不是同一个人(不相等),但你们可以“在出生年份上是等价的”。
- 等价类: 一个等价关系会自然地将一个集合划分成若干个互不相交的子集,每个子集称为一个等价类。在等价类内部,所有元素都相互等价。例如,模7同余关系将所有整数划分为7个等价类:{..., -7, 0, 7, ...}, {..., -6, 1, 8, ...}, ..., {..., -1, 6, 13, ...}。
等价关系是一种特殊的二元关系,它通过强制满足自反性、对称性和传递性这三个条件,完美地模拟了“等于”号的行为,从而在数学上定义了“在某个方面等价”这一概念。
为了进行抽象和分类。等价关系允许我们“忽略”不相关的细节,而只关注我们关心的属性,从而将一个复杂的集合划分为更简单的、可管理的“等价类”。
- 在有限自动机理论中,著名的Myhill-Nerode定理就利用一个等价关系(不可区分关系)来找到一个语言的最小DFA。该定理的核心就是将所有“行为上等价”的状态合并成一个状态。
- 在几何中,“相似”和“全等”都是等价关系。
- 在分数中,“通分后相等”是一个等价关系,它将 1/2, 2/4, 3/6 等所有分数归入同一个等价类,这个类就是有理数 0.5。
等价关系就像是给一大群人分组。
- 自反性: 每个人都在他自己的小组里。
- 对称性: 如果你和我在一个组,那么我也和你一个组。
- 传递性: 如果你和我在一个组,我和他在一个组,那么你肯定也和他在一个组。
最终,所有人都被分到一个个独立的、互不重叠的小组里,每个小组就是一个等价类。
想象你有一大堆各种颜色、各种形状的乐高积木。
- 关系R: “颜色相同”。
- 自反性: 任何一块积木,它的颜色和它自己相同。
- 对称性: 如果A积木和B积木颜色相同,那么B积木和A积木颜色也相同。
- 传递性: 如果A和B颜色相同,B和C颜色相同,那么A和C颜色也必然相同。
- 结果: “颜色相同”这个等价关系,成功地将所有积木按照颜色(红色堆,蓝色堆,黄色堆...)进行了分类。每一堆就是一个等价类。
14.11 示例 0.11:模7同余关系
📜 [原文26]
示例 0.11
在自然数上定义一个等价关系,写作 $\equiv_{7}$。对于 $i, j \in \mathcal{N}$,如果 $i-j$ 是 7 的倍数,则称 $i \equiv_{7} j$。这是一个等价关系,因为它满足三个条件。首先,它具有自反性,因为 $i-i=0$,是 7 的倍数。其次,它具有对称性,因为如果 $i-j$ 是 7 的倍数,则 $j-i$ 也是 7 的倍数。第三,它具有传递性,因为每当 $i-j$ 是 7 的倍数且 $j-k$ 是 7 的倍数时,那么 $i-k=(i-j)+(j-k)$ 是两个 7 的倍数的和,因此也是 7 的倍数。
这个例子是对上一节定义的等价关系的具体实例化和证明。它选择了一个非常重要的数学关系——模同余关系。
- 定义关系:
- 名称: $\equiv_7$,读作“模7同余”。
- 作用域: 自然数 $\mathcal{N}$。即关系的输入 i, j 都来自 $\mathcal{N} = \{1, 2, 3, ...\}$。
- 规则: $i \equiv_7 j$ 这句话为真,当且仅当 $i-j$ 是7的倍数。
- “是7的倍数”的数学含义是:存在一个整数 $k$,使得 $i-j = 7k$。
- 证明其为等价关系: 我们必须逐一验证自反性、对称性、传递性。
- 自反性 (Reflexivity):
- 目标: 证明对任意 $i \in \mathcal{N}$,都有 $i \equiv_7 i$。
- 证明: 根据定义,我们需要判断 $i-i$ 是否是7的倍数。$i-i = 0$。因为 $0 = 7 \times 0$,而0是整数,所以0是7的倍数。因此,$i \equiv_7 i$ 成立。自反性满足。
- 对称性 (Symmetry):
- 目标: 证明如果 $i \equiv_7 j$,那么一定有 $j \equiv_7 i$。
- 证明: 假设 $i \equiv_7 j$ 成立。根据定义,这意味着 $i-j$ 是7的倍数。即,存在整数 $k$ 使得 $i-j = 7k$。
- 我们要证明 $j \equiv_7 i$,也就是要证明 $j-i$ 是7的倍数。
- 从 $i-j = 7k$ 出发,两边乘以-1,得到 $j-i = -7k = 7(-k)。
- 因为 $k$ 是整数,所以 $-k$ 也是整数。因此 $j-i$ 可以表示为7乘以一个整数的形式,所以 $j-i$ 是7的倍数。
- 所以 $j \equiv_7 i$ 成立。对称性满足。
- 传递性 (Transitivity):
- 目标: 证明如果 $i \equiv_7 j$ 且 $j \equiv_7 k$,那么一定有 $i \equiv_7 k$。
- 证明: 假设 $i \equiv_7 j$ 和 $j \equiv_7 k$ 都成立。
- 根据定义,$i-j$ 是7的倍数,即存在整数 $k_1$ 使得 $i-j = 7k_1$。
- 根据定义,$j-k$ 是7的倍数,即存在整数 $k_2$ 使得 $j-k = 7k_2$。
- 我们要证明 $i \equiv_7 k$,也就是要证明 $i-k$ 是7的倍数。
- 我们尝试构造 $i-k$。一个巧妙的技巧是引入j:$i-k = (i-j) + (j-k)$。
- 将上面的假设代入:$i-k = 7k_1 + 7k_2 = 7(k_1+k_2)。
- 因为 $k_1$ 和 $k_2$ 都是整数,它们的和 $k_1+k_2$ 也是整数。
- 因此 $i-k$ 可以表示为7乘以一个整数的形式,所以 $i-k$ 是7的倍数。
- 所以 $i \equiv_7 k$ 成立。传递性满足。
- 结论: 因为该关系同时满足自反性、对称性和传递性,所以 $\equiv_7$ 是一个等价关系。
- $8 \equiv_7 1$? 因为 $8-1=7$,7是7的倍数。所以为 TRUE。
- $1 \equiv_7 8$? 因为 $1-8=-7$,-7是7的倍数 ($7 \times -1$)。所以为 TRUE。(对称性)
- $15 \equiv_7 1$? 因为 $15-1=14$,14是7的倍数 ($7 \times 2$)。所以为 TRUE。
- $8 \equiv_7 1$ 且 $1 \equiv_7 15$ (因为 $1-15=-14$ 是7的倍数),那么 $8 \equiv_7 15$? 因为 $8-15=-7$,是7的倍数。所以为 TRUE。(传递性)
- $10 \equiv_7 2$? 因为 $10-2=8$,8不是7的倍数。所以为 FALSE。
另一种理解方式:两个数模7同余,当且仅当它们除以7的余数相同。
- 8 / 7 = 1 ... 1。余数是1。
- 1 / 7 = 0 ... 1。余数是1。
- 15 / 7 = 2 ... 1。余数是1。
- 10 / 7 = 1 ... 3。余数是3。
- 2 / 7 = 0 ... 2。余数是2。
可以看到,8, 1, 15 都是模7同余的,因为它们除以7的余数都是1。而10和2的余数不同,它们彼此之间也和8,1,15都不同余。
- "是...的倍数" 定义中的整数 k: k可以是正数、负数或零。这是证明对称性的关键。
- 与模运算 mod 的关系: $i \equiv_m j$ 与 (i mod m) == (j mod m) 是等价的。前者是数学关系的写法,后者是编程计算的写法。
示例0.11详细证明了“模7同余”是一个合法的等价关系,因为它满足自反性、对称性和传递性的定义。这个关系将所有自然数(或整数)划分开来,凡是除以7余数相同的数,都被视为“等价”。
- 提供一个非平凡的等价关系范例: “等于”关系太普通了。模同余关系是一个更具启发性的例子,它展示了等价关系如何帮助我们从新的角度(例如,只关心除以7的余数)来看待和分类事物。
- 练习证明技巧: 本段的论证过程是证明一个关系为等价关系的模板,清晰地展示了如何应用三个定义进行推理。
模7同余关系就像是按“星期几”来给人分组。
- 今天(比如星期三)和7天后的今天、14天后的今天,都是星期三。它们在“星期几”这个意义上是等价的。
- 自反性: 今天当然是星期三。
- 对称性: 如果今天和7天后都是星期三,那么7天后和今天也都是星期三。
- 传递性: 如果今天和7天后都是星期三,7天后和14天后也都是星期三,那么今天和14天后也都是星期三。
想象一个有7个格子的循环轨道,编号0到6。
- 所有整数都被放置在这个轨道上。数字1放在格子1,数字7放在格子0,数字8放在格子1,数字-1放在格子6。一个数 n 放在哪个格子,由 n mod 7 决定。
- $i \equiv_7 j$ 就意味着 i 和 j 被放在了同一个格子里。
- 这个等价关系将无限多的整数,成功地划分到了7个不同的“等价类”(格子)中。
1.5 图
15.1 无向图的基本定义
📜 [原文27]
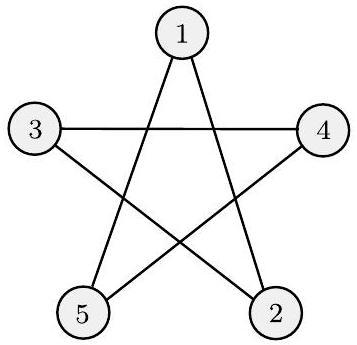
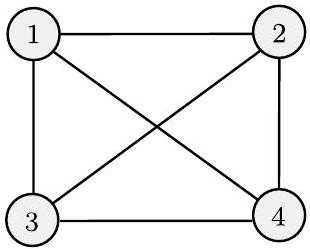
无向图,或简称图,是一组点和连接其中一些点的线。这些点称为节点或顶点,这些线称为边,如下图所示。
(a)
(b)
- 图 (Graph) 的本质: 图是一种数学结构,用来对“事物”以及它们之间的“连接关系”进行建模。
- 核心组成部分:
- 点 (Dots): 代表“事物”。在图论中,它们有更正式的名称:节点 (Nodes) 或 顶点 (Vertices) (单数是 Vertex)。
- 线 (Lines): 代表事物之间的“连接关系”。它们的正式名称是 边 (Edges)。
- 无向图 (Undirected Graph):
- 这是最基本的一种图。
- “无向”意味着边是没有方向的。如果节点A和节点B之间有一条边,那么这个连接是双向的、对称的。从A到B和从B到A是一回事。
- 这就像一条双向的道路,或两个人之间的“朋友”关系。
- 图示分析:
- 图(a) 展示了一个有5个顶点和5条边的图。这些边连接成一个环。
- 图(b) 展示了一个有4个顶点和6条边的图。每个顶点都与其他所有顶点相连,这种图被称为完全图 (Complete Graph)。
- 重要: 图的画法不重要,重要的是顶点是谁、边连接了谁。图(a)的五个顶点可以画成一个五边形,也可以画得歪七扭八,只要连接关系不变,它们就是同一个图。
- 示例1:社交网络
- 顶点: 一群人 {Alice, Bob, Charlie}。
- 边: 表示他们是否是朋友。假设 Alice 和 Bob 是朋友,Bob 和 Charlie 是朋友。
- 这个图可以表示为:三个点分别标记为 A, B, C。A和B之间有一条边,B和C之间有一条边。
- 示例2:城市交通
- 顶点: 几个城市 {北京, 上海, 广州}。
- 边: 表示两个城市之间是否有直达的高铁线路。假设北京和上海有直达,北京和广州有直达,但上海和广州没有直达。
- 这个图可以表示为:三个点分别标记。北京点和上海点之间有一条边,北京点和广州点之间有一条边。
- 图 vs 几何形状: 图论中的图不是几何学意义上的图形。边的长度、节点的精确位置都没有意义。一个图只关心“有哪些顶点”和“哪些顶点对被边连接”,这是一个拓扑结构。
- 简单图: 通常我们讨论的图是“简单图”,它不允许:
- 自环 (Self-loop): 一条边从一个顶点出发又回到自身。
- 多重边 (Multiple Edges): 两个顶点之间有多于一条的边。
- 如果允许这些情况,就称为“多重图”(multigraph)。
无向图是一种由顶点(点)和边(线)组成的结构,用于表示对象之间的无向连接关系。边的方向不重要,重要的是“谁和谁连着”。
图是计算机科学中最重要的、应用最广泛的数据结构之一。几乎任何涉及到“关系”的问题都可以用图来建模。
- 网络: 互联网、社交网络、电力网、交通网络。
- 算法: 寻路算法(如Dijkstra, A*)、网页排名(PageRank)、任务调度。
- 有限自动机: 自动机的状态转移图就是一个有向图,节点是状态,边是转移。这是计算理论的核心。
- 数据依赖: 编译器中的变量依赖关系、程序流程图。
图就是一张“关系网”。
- 顶点: 网上的节点(人、计算机、地点...)。
- 边: 节点之间的连接线(友谊、网线、道路...)。
- 一张地铁线路图。
- 顶点: 地铁站。
- 边: 连接两个站点的地铁线路。
- 一个分子结构图。
- 顶点: 原子。
- 边: 化学键。
15.2 图的术语:度、自环、邻接
📜 [原文28]
特定节点上的边的数量称为该节点的度。在图 0.12(a) 中,所有节点的度都为 2。在图 0.12(b) 中,所有节点的度都为 3。任意两个节点之间最多只允许有一条边。我们可能允许从一个节点到自身的边,称为自环,具体取决于情况。
在包含节点 $i$ 和 $j$ 的图 $G$ 中,对 $(i, j)$ 表示连接 $i$ 和 $j$ 的边。在无向图中,$i$ 和 $j$ 的顺序无关紧要,因此对 $(i, j)$ 和 $(j, i)$ 表示同一条边。有时我们用集合表示法 $\{\{i, j\}\}$ 来描述无向边。
- 度 (Degree)
- 定义: 一个顶点 v 的度,记作 deg(v),是指与该顶点相连的边的数量。
- 直观意义: 度表示了一个节点的“连接程度”或“繁忙程度”。在社交网络中,一个人的度就是他的好友数量。
- 示例分析:
- 图 0.12(a) (五边形): 每个顶点都连接着两条边(一条“左边”的,一条“右边”的),所以每个顶点的度都是2。
- 图 0.12(b) (四面体/完全图K4): 每个顶点都与其他3个顶点相连,所以每个顶点的度都是3。
- 简单图的限制:
- “任意两个节点之间最多只允许有一条边”: 这排除了“多重边”的情况。
- “我们可能允许...自环”: 自环是一条连接顶点到其自身的边。通常在没有特殊说明时,我们假设图是简单图 (Simple Graph),即既没有多重边也没有自环。
- 边的表示:
- 如何用数学语言精确地表示一条连接 i 和 j 的边?
- 有序对 (i, j): 文本中使用 (i, j) 来表示。但马上又说“顺序无关紧要”,这说明这里的 (i, j) 是一种不严格的说法,它实际上代表了一个无序的概念。
- 无序对 \{i, j\}: 这是表示无向边的更严谨、更常用的方式。它明确表示 i 和 j 之间的连接,且不区分 \{i, j\} 和 \{j, i\}。
- 集合表示法 \{\{i, j\}\}: 这是最形式化的写法。一条边本身是一个包含两个顶点的无序对 \{i, j\}。而图的整个边集 E 则是这些无序对的集合。例如,$E = \{\{1,2\}, \{2,3\}\}$。
考虑一个图 G,其顶点集 V = {A, B, C, D},边集 E = {{A, B}, {A, C}, {B, C}} (一个三角形)
- 度:
- deg(A): A与B和C相连,所以 deg(A) = 2。
- deg(B): B与A和C相连,所以 deg(B) = 2。
- deg(C): C与A和B相连,所以 deg(C) = 2。
- deg(D): D没有与任何顶点相连,所以 deg(D) = 0。这样的顶点称为孤立顶点。
- 握手定理 (Handshaking Lemma):
- 这是一个图论的基本定理:一个图中所有顶点的度数之和,等于边数的两倍。
- $\sum_{v \in V} deg(v) = 2|E|$
- 在上述例子中,度数之和 = 2 + 2 + 2 + 0 = 6。
- 边数 |E| = 3。
- 6 = 2 * 3。定理成立。
- 直观理解: 每条边都连接两个顶点,所以它会为这两个顶点的度数各贡献1,总共贡献了2。
- 自环的度数计算: 如果允许自环,一条在顶点 v 上的自环 \{v, v\} 通常被计算为对 deg(v) 贡献了2。因为它既“离开”v 又“进入”v。
- 度为0的顶点: 孤立顶点也是图的一部分,不能忽略。
- deg(v) 永远是非负整数。
一个顶点的度是与它相连的边的数目,反映了其连接性。通常我们讨论的图是简单图,没有多重边和自环。一条无向边最精确的表示法是一个包含两个顶点的无序对 \{i, j\}。
“度”是图论中最基本、最重要的顶点属性之一。许多图的性质和算法都与顶点的度数密切相关。
- 网络分析: 在社交网络中,度高的节点是“名人”或“中心节点”。
- 算法设计: 某些图算法的复杂度与图的最大度或平均度有关。
- 化学: 分子中一个原子的“度”就是它的化合价。
- 度: 你在一个派对上,你的“度”就是你认识并交谈过的人的数量。
- 自环: 你在派对上自言自语。
- 多重边: 你和某个人不仅是同学,还是邻居,你们之间有“两条”关系连接。
想象一个机场的航班网络。
- 顶点: 机场。
- 边: 两个机场间的直飞航线。
- 一个机场的度: 该机场的直飞航线数量。北京大兴机场的度非常高,而一个偏远小镇的机场度可能只有1或2。
15.3 图的形式化定义
📜 [原文29]
如果 $V$ 是 $G$ 的节点集, $E$ 是边集,我们说 $G=(V, E)$。我们可以用图示或更正式地通过指定 $V$ 和 $E$ 来描述一个图。例如,图 0.12(a) 中图的正式描述是
图 0.12(b) 中图的正式描述是
这一部分从直观的“点和线”的描述,转向了用集合论语言进行的严格数学定义。
- 图的本质:一个有序对
- 一个图 $G$ 被定义为一个有序对 $(V, E)$。
- $V$: 第一个元素是一个集合,称为顶点集 (Vertex Set)。这个集合包含了图所有的顶点。
- $E$: 第二个元素也是一个集合,称为边集 (Edge Set)。
- 这个定义 G = (V, E) 非常重要,它是一切图论形式化讨论的起点。
- 边集的构成
- 对于一个无向图,边集 $E$ 是一个由顶点对组成的集合。
- 更精确地说,$E$ 是由 V 中元素构成的无序对的集合。每一条边 e \in E,其形式都是 \{u, v\},其中 u, v \in V 且 u \neq v (对于简单图)。
- 所以 $E$ 是 $V$ 的所有可能的两元素子集的集合(即 $\mathcal{P}_2(V)$)的一个子集。
- 示例分析:
- 图 0.12(a) (五边形):
- V = \{1, 2, 3, 4, 5\}: 顶点集,包含了图中的5个顶点。
- E = \{\{1,2\},\{2,3\},\{3,4\},\{4,5\},\{5,1\}\}: 边集。
- \{1,2\} 表示顶点1和2之间有一条边。
- ...
- \{5,1\} 表示顶点5和1之间有一条边。
- 这个集合精确地描述了五边形的连接关系。
- 图 0.12(b) (完全图K4):
- V = \{1, 2, 3, 4\}: 顶点集。
- E = \{\{1,2\},\{1,3\},\{1,4\},\{2,3\},\{2,4\},\{3,4\}\}: 边集。
- 这个边集包含了从V中任取两个顶点组成的所有可能的无序对。这正是完全图的定义。
- 两种描述方式的对比:
- 图示: 直观、易于理解,但可能因画法不同而产生误导,且不适合计算机处理。
- 形式化描述 G=(V,E): 抽象、精确、无歧义,是数学证明和计算机算法的基础。计算机存储一个图,就是存储V和E的信息(例如用邻接矩阵或邻接表)。
这里我将原文中不严谨的 (i,j) 写法修正为更标准的 \{i,j\}。
- (...): 这是一个有序对 (V, E),代表整个图 G。
- \{1,2,3,4,5\}: 这是顶点集V。
- \{\{1,2\}, ... \}: 这是边集E。它是一个集合,其元素是无序对。
- 这是对图0.12(b)的形式化描述,结构同上。
示例:一个“工”字形的图
该图有5个顶点,4条边。
- 图示:
1 -- 2 -- 3
|
4 -- 5
- 形式化描述:
- V = \{1, 2, 3, 4, 5\}
- E = \{\{1, 2\}, \{2, 3\}, \{2, 4\}, \{4, 5\}\}
- G = (V, E) = (\{1, 2, 3, 4, 5\}, \{\{1, 2\}, \{2, 3\}, \{2, 4\}, \{4, 5\}\})
- V和E的区分: V是顶点的集合,其元素是顶点本身。E是边的集合,其元素是顶点的无序对。不能混淆。
- 边必须由V中顶点构成: 边集E中的任何一个无序对 \{u, v\},都必须满足 u \in V 且 v \in V。你不能凭空加一条连接到不存在的顶点的边。
一个图 $G$ 的形式化定义是一个有序对 $(V, E)$,其中 $V$ 是一个包含所有顶点的顶点集,而 $E$ 是一个边集,$E$ 中的每个元素都是一个形如 \{u, v\} 的无序对,表示顶点 u 和 v 之间的一条边。
为了将图论建立在坚实的数学基础之上。有了 G=(V, E) 这个定义,我们就可以摆脱对“画图”的依赖,纯粹在集合和逻辑的层面上进行推理和证明。这对理论计算机科学的发展至关重要,也使得图能够被计算机高效地表示和处理。
G=(V, E) 就像是一个公司的组织架构。
- V: 公司所有员工的名单 (顶点集)。
- E: 一个描述“汇报关系”的列表 (边集)。列表中的每一项都是 \{员工A, 员工B\},表示他们之间有直接的合作或汇报关系。
这个 (员工名单, 关系列表) 的组合,就完整地定义了公司的组织图。
G=(V, E) 就像是制作一个星座图。
- V: 你能看到的所有星星的集合。
- E: 你用想象中的“连线”把某些星星连起来,构成特定的形状(比如猎户座的腰带)。E 就是所有这些“连线”的集合,每条连线就是一个 \{星星A, 星星B\} 对。
V 和 E 加在一起,就定义了你心目中的那个星座图。
15.4 带标签的图
📜 [原文30]
图经常用于表示数据。节点可以是城市,边可以是连接它们的公路,或者节点可以是人,边可以是他们之间的友谊。有时,为了方便,我们给图的节点和/或边添加标签,这称为带标签的图。图 0.13 描绘了一个图,其节点是城市,其边用如果可能在这些城市之间进行直飞旅行,则最便宜的直飞机票的美元成本标记。
图 0.13
各城市之间最便宜的直飞航班票价
- 图的应用: 前面的定义是纯数学的,这一段开始将其与实际应用联系起来。图之所以强大,就是因为它能对现实世界中的各种“网络”和“关系”进行建模。
- 标签 (Labels):
- 动机: G=(V, E) 只告诉我们“有哪些东西”和“谁跟谁连着”。但在很多应用中,我们还需要知道这些东西和连接的属性。
- 节点标签: 顶点本身可以有名字或属性。例如,用字符串 "San Francisco" 来标记一个节点,而不是抽象的数字 1。
- 边标签 (或 权重 Weights): 边也可以有属性。例如,边的标签可以是一个数字,代表两个城市之间的距离、旅行所需的时间、或者机票的成本。
- 带标签的图 (Labeled Graph):
- 一个图,其顶点和/或边附带有额外的信息(标签),就称为带标签的图。如果边的标签是数字,通常也称为加权图 (Weighted Graph)。
- 图 0.13 分析:
- 这是一个典型的带权无向图。
- 顶点: {SF, LA, DEN, CHI, BOS, NY} (6个城市)。这些城市名就是节点标签。
- 边: 两个城市间有直飞航班,则有一条边。
- 边的标签/权重: 边上的数字,代表了两个城市间最便宜的直飞票价。例如,从NY到BOS的边权重是70。
- 这个图不仅告诉我们哪些城市之间可以直飞,还告诉我们飞过去“要花多少钱”。
- 应用场景: 这种带权图是许多经典算法的输入。
- 最短路径问题: 如何从SF飞到BOS总花费最少?(这需要考虑转机,例如SF->DEN->BOS)。著名的Dijkstra算法就是解决这类问题的。
- 最小生成树问题: 假设你是航空公司,想用最少的总成本连接所有这些城市(不一定需要所有城市间都有直飞),你应该保留哪些航线?
- 示例1:GPS导航
- 图: 城市道路图。
- 顶点: 十字路口。
- 边: 道路。
- 边权重: 道路的长度(米),或者通过该道路的预计时间(分钟)。
- 问题: 找从A到B的最短路径(Dijkstra算法)。
- 示例2:计算机网络
- 图: 互联网。
- 顶点: 路由器。
- 边: 路由器之间的物理连接(如光纤)。
- 边权重: 连接的带宽(Mbps),或者数据包通过的延迟(毫秒)。
- 问题: 找从服务器A到客户B的最高带宽路径或最低延迟路径。
- 标签 vs 顶点本身: 在 G=(V,E) 的形式化定义中,V是 {1, 2, 3} 这样的抽象符号。标签是这些符号的一个“映射”。可以定义一个标签函数 L: V -> String,使得 L(1) = "San Francisco"。在编程实现时,我们通常直接用字符串或对象作为顶点,标签就成了顶点对象的一个属性。
- 权重为0或负数: 边的权重可以是0或者负数。负权重的存在会使一些最短路径算法(如Dijkstra)失效,需要使用更复杂的算法(如Bellman-Ford)。
带标签的图通过给顶点和/或边附加额外信息(标签或权重),极大地增强了图的表达能力,使其能够对更丰富的现实世界问题进行建模,如交通网络的成本、计算机网络的带宽等。
为了让图这一工具能够解决实际问题。纯粹的、无标签的图只能回答“是否连接”的问题,而带标签的图可以回答“如何连接最好”、“连接的代价是什么”等更复杂、更有价值的问题。
如果一个普通图是一张只有黑白线条的骨架地图,那么带标签的图就是一张信息丰富的全彩地图。
- 节点标签: 地图上的地名标注(故宫、白宫...)。
- 边标签: 道路上标注的里程数、限速、收费站信息。
你正在玩一个策略游戏。
- 顶点: 游戏中的各个城市或据点。
- 边: 连接据点的道路。
- 边权重: 通过这条道路需要消耗的行动点数,或者行军时间。
你的目标(比如从A到B)不仅仅是找到一条路,而是找到一条消耗行动点最少的路。你操作的基础就是一张带权图。
15.5 子图
📜 [原文31]
我们说图 $G$ 是图 $H$ 的子图,如果 $G$ 的节点是 $H$ 的节点的子集,并且 $G$ 的边是 $H$ 在相应节点上的边。下图显示了一个图 $H$ 和一个子图 $G$。
图 0.14
图 $G$ (显示为深色) 是 $H$ 的子图
- 子图 (Subgraph) 的概念: 子图就是从一个大图中“取出一部分”形成的小图。
- 形式化定义: 令大图为 $H = (V_H, E_H)$,小图为 $G = (V_G, E_G)$。我们说 $G$ 是 $H$ 的子图,如果满足以下两个条件:
- 顶点是子集: $V_G \subseteq V_H$。即,子图的所有顶点都必须是原图的顶点。
- 边也是子集 (且保持连接): $E_G \subseteq E_H$。即,子图的所有边都必须是原图的边。并且,$E_G$ 中的任何一条边 \{u, v\},其两个端点 u 和 v 都必须在 $V_G$ 中。
- “G的边是H在相应节点上的边”: 这句话解释了第二个条件。你不能只取H的顶点,然后随便在它们之间画边。你选定的那部分顶点($V_G$),它们之间的边,只能是原来在H中就已经存在的那些边。
- 图 0.14 分析:
- 图H: 一个有6个顶点和多条边的大图(所有细线和粗线合在一起)。
- 图G (深色部分):
- 顶点集 $V_G$: 包含了H中被深色标记的4个顶点。这显然是H的6个顶点的子集。
- 边集 $E_G$: 包含了连接那4个顶点的3条深色粗线。这3条边在原图H中也存在(作为细线)。
- 因此,图G满足子图的定义。
- 如何获得子图 (两种操作):
- 删除顶点: 从原图中删除一个或多个顶点。删除一个顶点时,所有与它相连的边也必须被删除。
- 删除边: 从原图中删除一条或多条边,而不删除顶点。
令原图 $H = (V, E)`,其中 `$V = \{1, 2, 3, 4\}$`,`$E = \{\{1,2\}, \{1,3\}, \{2,3\}, \{3,4\}\}`。
(这是一个菱形,1-2-3-1构成三角形,3-4是尾巴)
- 示例1:一个合法的子图 (删除顶点)
- 我们从H中删除顶点4。所有与4相连的边 {3,4} 也被删除。
- 得到子图 $G_1 = (V_1, E_1)`,其中 `$V_1 = \{1, 2, 3\}$`,`$E_1 = \{\{1,2\}, \{1,3\}, \{2,3\}\}。
- $V_1 \subseteq V$ 且 $E_1 \subseteq E$,所以 $G_1$ 是 $H$ 的子图。
- 示例2:一个合法的子图 (删除边)
- 我们只从H中删除边 {1,3}。
- 得到子图 $G_2 = (V_2, E_2)`,其中 `$V_2 = \{1, 2, 3, 4\}$`,`$E_2 = \{\{1,2\}, \{2,3\}, \{3,4\}\}。
- $V_2 \subseteq V$ (实际上是相等) 且 $E_2 \subseteq E$,所以 $G_2$ 是 $H$ 的子图。这种顶点集不变的子图称为生成子图 (Spanning Subgraph)。
- 示例3:一个非法的“子图”
- 令 $V_3 = \{1, 4\}$,$E_3 = \{\{1, 4\}\}`。
- 这不是H的子图。虽然 $V_3 \subseteq V$,但边 \{1, 4\} 并不在原始的边集 $E$ 中。你不能无中生有地创造边。
- 诱导子图 (Induced Subgraph): 一种特殊的子图。如果我们只选择一个顶点子集 $V_G \subseteq V_H$,然后规定 $E_G$ 包含所有在 $E_H$ 中、且两个端点都在 $V_G$ 内的所有边。这样的子图称为由 $V_G$ 诱导的子图。示例1就是一个诱导子图。示例2不是,因为在 $V_2$ 中,顶点1和3之间原本有边,但在 $E_2$ 中被删除了。
- 空图: 空图 $(\emptyset, \emptyset)$ 是任何图的子图。
- 图自身: 任何图 $H$ 都是其自身的子图。
子图是通过从原图中选取一部分顶点和一部分边(必须是原来就存在的连接)而形成的新图。它就像是从一个复杂的网络中“裁剪”出来的一个局部网络。
子图的概念在图论中至关重要,因为它允许我们分析和研究图的局部结构。
- 模式匹配: 在一个巨大的网络(如社交网络或蛋白质相互作用网络)中寻找特定的小模式(例如,寻找一个“三角形”或“四边形”的子图结构),这在生物信息学和网络分析中是核心问题。
- 图算法: 许多复杂的图算法,其内部步骤可能就是在寻找或操作某种特定的子图(如路径、环、树等)。
子图就像是从一张完整的世界地图上,用剪刀剪下一块“东亚地区”的地图。
- 你剪下来的地图上的所有城市(顶点)都必须是世界地图上真实存在的城市。
- 你剪下来的地图上的所有铁路(边)也必须是世界地图上真实存在的铁路。你不能在剪下来的地图上自己画一条北京到东京的海底隧道。
- 子图: 你的微信好友关系构成一个巨大的图。你和你最好的五个朋友,以及你们之间的好友关系,构成这个巨大图的一个子图。
- 诱导子图: 你和你最好的五个朋友,以及这五个人之间所有的好友关系(可能他们之间有些人你都不认识),构成的图是一个诱导子图。
15.6 路径、环与树
📜 [原文32]
图中的路径是按边连接的节点序列。简单路径是不重复任何节点的路径。如果任意两个节点之间都有一条路径,则该图是连通图。路径是一个环,如果它始于并终于同一节点。简单环是包含至少三个节点并且只重复第一个和最后一个节点的环。如果一个图是连通图且没有简单环,则它是一个树,如图 0.15 所示。树可能包含一个特殊指定的节点,称为根。树中度为 1 的节点,除了根之外,称为树的叶子。
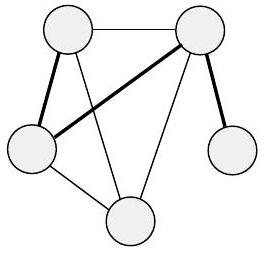
(a)
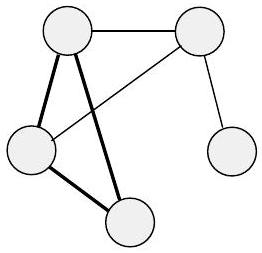
(b)
(c)
图 0.15
(a) 图中的路径,(b) 图中的环,和 (c) 树
这一段定义了图论
中一些最基本的子图结构和属性,它们是构建更复杂图算法和理论的基础。
- 路径 (Path)
- 定义: 一个节点序列 $(v_1, v_2, \ldots, v_k)$,其中序列中任意相邻的两个节点 $(v_i, v_{i+1})$ 之间在图中都存在一条边 $\{v_i, v_{i+1}\}$。
- 直观意义: 路径就是沿着图的边从一个节点“走”到另一个节点所经过的顶点序列。路径的长度是它包含的边的数量,即 k-1。
- 图0.15(a)分析: 该图用粗线标出了一条路径。这条路径可以被描述为 (v1, v2, v3, v4, v5) (假设顶点从左到右编号)。
- 简单路径 (Simple Path)
- 定义: 一条不重复任何节点的路径(除了可能首尾相同,那就成了环)。
- 区别: 路径 (A, B, C, B, D) 不是简单路径,因为它重复访问了节点B。而 (A, B, C, D) 是简单路径。
- 图0.15(a)中高亮的路径就是一条简单路径。
- 连通图 (Connected Graph)
- 定义: 如果一个图中,从任意一个节点到任意另一个节点都至少存在一条路径,那么这个图就是连通图。
- 直观意义: 整个图是“一体”的,没有孤立的部分。你可以从任何一个顶点出发,通过走边的方式,最终到达任何其他顶点。
- 环 (Cycle / Circuit)
- 定义: 一条起点和终点是同一个节点的路径。路径的长度必须至少为1。
- 例如,路径 (A, B, C, A) 就是一个环。
- 图0.15(b)分析: 该图用粗线标出了一个由4个顶点和4条边组成的环。
- 简单环 (Simple Cycle)
- 定义: 一个环,其中只有起点和终点是重复的节点。为了排除 (A, B, A) 这种平凡情况,通常要求简单环至少包含三个节点。
- (A, B, C, D, A) 是一个简单环。
- (A, B, C, B, A) 不是一个简单环,因为节点B在中间被重复访问了。
- 树 (Tree)
- 核心定义: 一个图如果同时满足以下两个条件,就被称为树:
- 图是连通的。
- 图中没有简单环 (无环,Acyclic)。
- 特性: 树是一种“最精简”的连通图。在任意两个节点之间,存在唯一一条简单路径。添加任何一条新的边都会制造出一个环;删除任何一条边都会使图不再连通。
- 图0.15(c)分析: 该图是连通的,并且你在里面找不到任何环路,所以它是一棵树。
- 树的附加术语:
- 根 (Root): 我们可以从树中指定一个特殊的节点作为“根”。一旦指定了根,树就有了层次结构(上/下关系)。这种树称为有根树 (Rooted Tree),在计算机科学中极为常见(如文件系统目录树、XML/HTML的DOM树)。根通常画在最上面。
- 叶子 (Leaf): 在一棵树中,度为1的节点称为叶子。它们是树的“末梢节点”。如果是有根树,根节点即使度为1通常也不称为叶子。
考虑图 G = ({1,2,3,4,5}, {{1,2},{2,3},{3,1},{3,4},{4,5}})
- 路径: (1, 3, 4, 5) 是一条简单路径。(1, 2, 3, 1, 2) 是一条路径,但不是简单路径。
- 连通性: 这个图是连通的,因为你可以从任何节点走到任何其他节点。
- 环: (1, 2, 3, 1) 是一个简单环。
- 是不是树?: 因为图中存在环,所以它不是一棵树。
- 如何变成树?: 如果我们删除边 {1,3},得到的图 G' = ({1,2,3,4,5}, {{1,2},{2,3},{3,4},{4,5}}) 就是一棵树(它是一条链)。
- 路径 vs 简单路径: 算法题中通常关心的是简单路径。
- 环 vs 简单环: 同样,在讨论图的无环性时,我们关心的是是否存在简单环。
- 森林 (Forest): 一个无环的图不一定是树,因为它可能不连通。一个无环图由一个或多个连通的部分组成,每个部分都是一棵树。因此,一个无环图被称为“森林”。
- 单个顶点的图: 它是一棵树(连通且无环)。
- 只有两个顶点和一条边的图: 它也是一棵树。
路径是顶点沿边的序列,环是首尾相接的路径。图的连通性指其是否为一个整体。树是一种非常重要的图结构,它被定义为连通且无环的图。在树的基础上,还可定义根和叶子等概念。
路径、环、连通性、树是图论中最核心、最基本的概念。
- 路径: 是所有寻路算法(如导航)的基础。
- 环: 环检测在很多领域都有用,例如在任务依赖图中检测是否存在循环依赖(死锁)。
- 连通性: 用于分析网络的鲁棒性,判断网络是否分割。
- 树: 是计算机科学中最重要的数据结构之一,用于表示层次关系,如文件系统、数据索引(B-树)、决策过程(决策树)等。它的“唯一路径”和“无环”特性带来了许多计算上的便利。
- 路径: 你在城市里从家走到学校的路线。
- 简单路径: 你走的路线没有绕回同一个路口。
- 环: 你绕着一个广场散步,最终回到了起点。
- 连通图: 一个设计良好的城市,从任何地方都能开车到达任何其他地方。
- 树: 一个没有环形交叉路的乡村公路网,从任何一个村庄到另一个村庄都只有唯一一条路。
- 路径: 一串珍珠项链上,从一颗珍珠滑到另一颗珍珠的轨迹。
- 环: 项链本身就是一个环。
- 树: 一棵真实的树的树枝分叉结构。从根部到任何一片叶子,都只有一条唯一的路径。树枝之间不会“长回去”形成环。
15.7 有向图
📜 [原文33]
有向图有箭头而不是线,如下图所示。从特定节点指向的箭头数量是该节点的出度,指向特定节点的箭头数量是入度。
图 0.16
有向图
- 有向图 (Directed Graph / Digraph):
- 这是对无向图概念的一个重要扩展。
- 核心区别: 边是有方向的。它不再是简单的“连接”,而是从一个顶点到另一个顶点的“指向”。
- 箭头 (Arrows): 在图示中,我们用箭头来表示有向边,明确指出其方向。一条从 u 指向 v 的边,表示可以从 u 到达 v,但不一定能从 v 回到 u。
- 应用: 非常适合建模非对称关系,如单行道、网页链接、任务的先后依赖、函数调用关系等。
- 度的新概念: 在有向图中,一个顶点的“度”被细分为两个部分。
- 出度 (Out-degree): 从该顶点出发的边的数量。记作 deg+(v)。它表示该节点“影响”或“指向”了多少其他节点。
- 入度 (In-degree): 指向该顶点的边的数量。记作 deg-(v)。它表示该节点被多少其他节点“影响”或“指向”。
- 图 0.16 分析:
- 这是一个有6个顶点和8条有向边的有向图。
- 我们可以计算每个顶点的入度和出度:
- 顶点1: 出度=2 (指向2, 5),入度=2 (来自2, 6)。
- 顶点2: 出度=2 (指向1, 4),入度=1 (来自1)。
- 顶点3: 出度=0,入度=1 (来自6)。这是一个“终点”或“汇点”(sink)。
- 顶点4: 出度=0,入度=2 (来自2, 5)。
- 顶点5: 出度=2 (指向4, 6),入度=1 (来自1)。
- 顶点6: 出度=2 (指向1, 3),入度=1 (来自5)。
- 有向图的握手定理: 所有顶点的出度之和,等于所有顶点的入度之和,且都等于图的总边数。
- $\sum deg+(v) = \sum deg-(v) = |E|$
- 在图 0.16 中,出度之和 = 2+2+0+0+2+2 = 8。入度之和 = 2+1+1+2+1+1 = 8。总边数是8。定理成立。
- 直观理解: 每条有向边,都从一个顶点出发,进入另一个顶点。所以它会为一个顶点的出度贡献1,为另一个顶点的入度贡献1。
示例1:网页链接图
- 顶点: 网页A, B, C。
- 边: 如果网页A有一个链接指向网页B,那么就有一条从A到B的有向边。
- A -> B, A -> C, C -> A
- 度分析:
- A: 出度=2, 入度=1。 (PageRank算法就是基于这个模型)
- B: 出度=0, 入度=1。
- C: 出度=1, 入度=1。
示例2:任务依赖关系
- 顶点: 任务 {做饭, 吃饭, 买菜, 洗碗}。
- 边: 买菜 -> 做饭 -> 吃饭 -> 洗碗。
- 这是一个有向无环图 (DAG),表示了任务的先后顺序。
- 度分析:
- 买菜: 出度=1, 入度=0 (起始任务)。
- 洗碗: 出度=0, 入度=1 (结束任务)。
- 对称边: 有向图中可以有一对 u -> v 和 v -> u 的边。这在效果上类似于一条无向边,但它们是两条独立的有向边。
- 度与总度的关系: 一个顶点的总度数是其入度与出度之和。
有向图使用带方向的箭头(有向边)来表示非对称的关系。这导致了顶点的度被区分为入度(指向该顶点的边数)和出度(从该顶点出发的边数)。
为了对现实世界中大量存在的非对称关系进行建模。
- 状态机: 有限自动机的状态转移是有向的。从状态 q1 读入符号 a 转移到 q2,不代表从 q2 读入 a 也能回到 q1。
- 流程图: 程序或工作流程中的步骤是有先后顺序的。
- 因果关系: A导致B 是一个有向关系。
[直觉心-智模型]
有向图就是一张单行道地图。
- 顶点: 十字路口。
- 有向边: 单行道。
- 出度: 从这个路口出发,有多少条单行道可以走。
- 入度: 有多少条单行道可以开到这个路口。
- 食物链: 草 -> 兔子 -> 狐狸。箭头表示能量流动的方向。
- Twitter/微博的关注关系: 你关注了某大V,这是一条从你指向大V的有向边。但大V不一定关注你。你的出度是你关注的人数,你的入度是你的粉丝数。
15.8 有向图的形式化定义与路径
📜 [原文34]
在有向图中,我们将从 $i$ 到 $j$ 的边表示为对 $(i, j)$。有向图 $G$ 的正式描述是 $(V, E)$,其中 $V$ 是节点集, $E$ 是边集。图 0.16 中图的正式描述是
其中所有箭头方向与其步骤方向相同的路径称为有向路径。如果任意两个节点之间都有有向路径连接,则该有向图是强连通的。有向图是描绘二元关系的便捷方式。如果 $R$ 是一个二元关系,其域是 $D \times D$,则带标签的图 $G=(D, E)$ 表示 $R$,其中 $E=\{(x, y) \mid x R y\}$。
- 有向边的表示:
- 因为方向很重要,所以表示有向边必须使用有序对 (Ordered Pair) (i, j)。
- (i, j) 表示一条从 i (尾部, tail) 指向 j (头部, head) 的边。
- (i, j) 和 (j, i) 代表的是两条不同的、方向相反的边。这与无向边的无序对 \{i, j\} 形成鲜明对比。
- 有向图的形式化定义:
- 与无向图一样,一个有向图 G 也被定义为 (V, E)。
- V 仍然是顶点集。
- 关键区别在于 边集 E: 对于有向图,E 是一个由有序对组成的集合。
- E 是笛卡尔积 $V \times V$ 的一个子集。
- 示例分析 (图 0.16):
- V = \{1, 2, 3, 4, 5, 6\}。
- E = \{(1,2), (1,5), (2,1), (2,4), (5,4), (5,6), (6,1), (6,3)\}。
- 这个集合 E 精确地列出了图中的8条有向边。例如,(1,2) 在集合中,表示有 1->2 的边;但 (2,3) 不在集合中,所以图中没有 2->3 的边。
- 有向路径 (Directed Path):
- 定义: 一个顶点序列 $(v_1, v_2, \ldots, v_k)$,其中对于任意相邻的 v_i, v_{i+1},图中都必须存在一条有向边 $(v_i, v_{i+1})$。
- 直观: 你必须顺着箭头的方向走。
- 强连通 (Strongly Connected):
- 定义: 一个有向图是强连通的,如果对于图中任意两个不同的顶点 u 和 v,既存在一条从 u 到 v 的有向路径,也存在一条从 v 到 u 的有向路径。
- 直观: 这是一个比无向图的“连通”更强的条件。它意味着从任何一个点出发,你都可以到达任何其他点,并且还能回来。整个图是一个紧密联系的整体,没有“单行道”陷阱。
- 图 0.16 不是强连通的。例如,你可以从1走到4 (1->2->4 或 1->5->4),但你无法从4走回到1,因为4的出度是0。
- 有向图与二元关系:
- 这是一个非常深刻和重要的联系。一个定义在集合 D 上的二元关系 R 和一个顶点集为 D 的有向图 G 之间存在一一对应关系。
- 关系 -> 图: 给定关系 R,我们可以画一个图。R 的论域 D 就是图的顶点集。对于 D 中每两个元素 x, y,如果 x R y 为 TRUE,我们就在图中画一条从 x 到 y 的有向边。这正是前面讲的“关系的集合表示法”:边集 $E = \{(x,y) \mid x R y = \text{TRUE}\}$。
- 图 -> 关系: 给定一个有向图 G=(D, E),我们可以定义一个二元关系 R:x R y 为 TRUE 当且仅当 (x, y) \in E。
- 因此,有向图可以看作是二元关系的可视化。
- (...): 代表图 G=(V, E)。
- \{1,2,3,4,5,6\}: 顶点集 V。
- \{ (1,2), ... \}: 边集 E。这是一个集合,其元素是有序对,每个有序对代表一条有向边。
示例1:一个强连通图
- V = \{a, b, c\}
- E = \{(a,b), (b,c), (c,a)\} (一个有向三角形)
- 有向路径:
- 从 a 到 c 的路径: (a, b, c)
- 从 c 到 a 的路径: (c, a)
- 从 b 到 a 的路径: (b, c, a)
- 任意两点间都互相可达,所以它是强连通的。
示例2:二元关系 "小于" < 在 {1,2,3} 上的图表示
- 关系: <
- 域: {1,2,3} \times \{1,2,3\}$
- 集合表示: R = \{(1,2), (1,3), (2,3)\}
- 图表示 G:
- V = \{1, 2, 3\}
- E = \{(1,2), (1,3), (2,3)\}
- 画出来就是三个顶点,有 1->2, 1->3, 2->3 三条有向边。这是一个有向无环图 (DAG)。
- 连通 vs 强连通: 对于有向图,存在两种连通性。
- 弱连通 (Weakly Connected): 如果我们忽略边的方向,得到的无向图是连通的,那么原有向图就是弱连通的。图0.16是弱连通的。
- 强连通 (Strongly Connected): 任意两点互相可达。这是一个更强的条件。
- 一个图可以既不是强连通,也不是完全不连通。它可能由多个强连通分量 (SCC) 组成。
有向图的边用有序对 (u, v) 表示,其形式化定义 G=(V,E) 中的 E 是有序对的集合。在有向图中,我们关心的是有向路径。如果任意两点间都双向可达,则称图是强连通的。有向图是可视化二元关系的绝佳工具。
为了精确描述和分析包含非对称关系和先后顺序的系统。这是理解有限自动机、下推自动机和图灵机等计算模型状态转移的数学基础。状态转移函数 $\delta(q, a) = p$ 本质上就是一个有向图的边 (q, p) (这条边可能还带着标签 a)。
[直觉心-智模型]
- 强连通: 罗马城的道路网。传说“条条大路通罗马”,一个设计理想的城市网络,应该也保证“条条大路出罗马”,即从罗马也能去任何地方。
- 关系与图:
- 关系: 一本厚厚的、记录了所有人际关系的文字档案。
- 图: 将这本档案画成了一张一目了然的“人物关系图”。
- 有向路径: 在一个游戏中,完成一个成就所需的一系列特定步骤。你必须按顺序做。
- 强连通: 在一个设计精良的开放世界游戏中,你不应该被卡在某个区域。即,从任何一个区域,你都应该有办法去到所有其他区域,并且还能回来。
15.9 示例 0.17:关系的图表示
📜 [原文35]
示例 0.17
这里所示的有向图表示示例 0.10 中给出的关系。
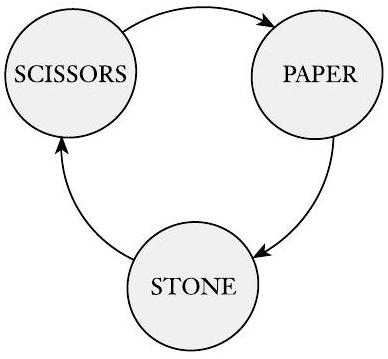
图 0.18
关系 $beats$ 的图
这个例子是上一节“有向图是二元关系的便捷描绘方式”的一个完美图示。
- 回顾关系:
- 示例 0.10 中定义了“剪刀-石头-布”游戏中的 beats 关系。
- 我们从函数视角(表格)和集合视角都对其进行了描述。
- 集合视角的表示是:$\{(\text{SCISSORS, PAPER}), (\text{PAPER, STONE}), (\text{STONE, SCISSORS})\}$。
- 构建图:
- 顶点集V: 关系的论域,即 $V = \{\text{SCISSORS, PAPER, STONE}\}$。我们在图上画三个顶点,并用相应的文字作为标签。
- 边集E: 就是关系的集合表示。对于集合中的每一个有序对 (u, v),我们就在图中画一条从 u 到 v 的有向边。
- (\text{SCISSORS, PAPER}) -> 画一条从 SCISSORS 指向 PAPER 的箭头。
- (\text{PAPER, STONE}) -> 画一条从 PAPER 指向 STONE 的箭头。
- (\text{STONE, SCISSORS}) -> 画一条从 STONE 指向 SCISSORS 的箭头。
- 分析图 0.18:
- 图中正好有三个顶点,对应游戏的三种选择。
- 图中有三条有向边,正好对应 beats 关系为 TRUE 的三种情况。
- 这个图形成了一个有向环。
- 从图中读出关系:
- 是否存在 PAPER 到 SCISSORS 的边?不存在。因此我们知道 $beats(\text{PAPER, SCISSORS}) 为 FALSE。
- 是否存在 STONE 到 PAPER 的边?不存在。因此 $beats(\text{STONE, PAPER}) 为 FALSE。
- 这个图完整地、直观地编码了整个游戏的克制关系。
本节本身就是一个完整的示例。这里提供另一个。
示例:等价关系 $\equiv_2$ (模2同余,即奇偶性相同) 在 {1, 2, 3} 上的图表示
- 关系 R: $i R j$ 当且仅当 `$i, j`$ 奇偶性相同。
- 集合表示: R = {(1,1), (2,2), (3,3), (1,3), (3,1)}
- 图表示:
- V = {1, 2, 3}。
- 边:
- (1,1): 从1指向自身的自环。
- (2,2): 从2指向自身的自环。
- (3,3): 从3指向自身的自环。
- (1,3): 从1指向3的边。
- (3,1): 从3指向1的边。
- 画出来就是:1和3之间有双向箭头,2孤立(只有自环),每个顶点都有自环。这直观地显示了1和3属于一个等价类,2属于另一个。
- 自环代表自反性: 在关系的图表示中,如果关系是自反的(x R x),那么图中的每个顶点都必须有一个指向自身的自环。
- 双向箭头代表对称性: 如果关系是对称的(x R y 则 y R x),那么图中任意两个有连接的顶点之间,都必须是双向箭头。
示例0.17展示了如何将一个用集合或表格表示的二元关系,转换成一个有向图。图的顶点就是关系的论域,图的有向边对应关系中为真的所有有序对。
这是一个总结性的例子,它将“关系”、“集合表示法”、“有向图”这几个概念串联起来,展示了它们之间的等价性和转化关系,加深了读者对“有向图是二元关系的可视化”这一核心思想的理解。
这张图就是“剪刀-石头-布”的“食物链”图。箭头表示“谁吃谁”。SCISSORS 吃 PAPER,PAPER 吃 STONE,STONE 吃 SCISSORS,形成一个完美的闭环,没有任何一个选择是无敌的,体现了游戏的平衡性。
想象你在玩一个桌面游戏,棋子在几个城市之间移动。
- 关系: 可以从A城一步直达B城。
- 图: 游戏地图上的移动路线图。如果关系为真,地图上就有一条从A到B的箭头。整个地图就是这个“可达性”关系的图表示。
1.6 字符串和语言
16.1 字母表与符号
📜 [原文36]
字符字符串是计算机科学中的基本构建块。定义字符串的字母表可能因应用程序而异。为了我们的目的,我们将字母表定义为任何非空有限集合。字母表的成员是字母表的符号。我们通常使用大写希腊字母 $\Sigma$ 和 $\Gamma$ 来表示字母表,并使用打字机字体表示字母表中的符号。以下是几个字母表的示例。
- 字符串的重要性: 开宗明义,字符串 (String) 是CS中的“基本构建块”。代码、文本文件、网络数据包,其底层表示都离不开字符串。计算理论研究的对象——语言,就是由字符串组成的。
- 字母表 (Alphabet):
- 作用: 它是构建字符串的“原材料”集合。
- 形式化定义: 一个非空、有限的集合。
- 集合: 意味着字母表中的符号是无序且不重复的。\{0, 1\} 和 \{1, 0\} 是同一个字母表。
- 非空: 字母表里至少要有一个符号,否则你什么字符串也造不出来(除了空字符串)。
- 有限: 字母表里的符号个数是有限的。我们不讨论有无限个基本符号的情况。
- 符号 (Symbol):
- 定义: 字母表集合中的一个成员/元素。
- 符号是构成字符串的最小、不可再分的单位。
- 记法约定:
- $\Sigma, \Gamma$ (Sigma, Gamma): 用来命名字母表集合的常用变量名。
- 打字机字体: a, b, 0, 1,用来表示具体的符号,以区别于数学变量。
- 示例分析:
- $\Sigma_1 = \{0, 1\}$: 这是二进制字母表,在计算机科学中无处不在。
- $\Sigma_2 = \{\text{a, b, ..., z}\}$: 小写英文字母表。
- $\Gamma = \{0, 1, \text{x, y, z}\}$: 一个混合了数字和字母的字母表。这说明符号可以是任何东西,只要它们是集合里被定义好的成员。例如,一个编程语言的字母表可能包含字母、数字和各种特殊符号 (+, *, {, ...)。
- $\Sigma_1, \Sigma_2, \Gamma$: 字母表集合的名称。
- =: 定义。
- \{...}: 集合的表示法。
- 0, 1, a, b, ...: 集合的元素,即符号。
- \ldots: 省略号,表示 $\Sigma_2$ 包含了从a到z的所有小写字母。
- DNA字母表: $\Sigma_{DNA} = \{\text{A, C, G, T}\}$。
- 十进制字母表: $\Sigma_{DEC} = \{0, 1, 2, 3, 4, 5, 6, 7, 8, 9\}$。
- 一个只含一个符号的字母表: $\Sigma_A = \{\text{a}\}$。基于这个字母表可以构建的字符串有: a, aa, aaa, ...
- 符号可以是字符串吗?: 在基本定义中,符号是原子性的,不可再分的。但为了方便,有时我们会将一个字符串视为一个“复合符号”。例如,在解析编程语言时,关键字 if 可以被当作一个独立的符号(token),而不是 i 和 f 两个符号的序列。但这属于更高层次的抽象。在计算理论的基础层面,字母表 $\{\text{if}, \text{then}, \text{else}\}$ 是完全合法的,它的符号就是 "if", "then", "else" 这三个字符串。
- 空集不是字母表: 字母表必须是非空的。
字母表 $\Sigma$ 是一个非空有限的符号集合。它是构建字符串的原材料库。
为了精确定义“字符串是由什么构成的”。没有字母表的概念,“字符串”的定义就是无源之水。在计算理论中,我们讨论的任何语言,都必须首先声明它是定义在哪个字母表之上的。
- 字母表: 一盒活字印刷用的铅字。盒子里有有限个、不重复的字模。
- 符号: 盒子里的每一个单独的铅字块。
- 字母表: 你键盘上能敲出的所有字符的集合(忽略Shift等功能键)。
- 符号: 键盘上的任意一个按键,如 'Q', '7', ';'。
16.2 字符串的定义与性质
📜 [原文37]
一个字符串是字母表中符号的有限序列,通常并排书写,不被逗号分隔。如果 $\Sigma_{1}=\{0,1\}$,那么 01001 是 $\Sigma_{1}$ 上的一个字符串。如果 $\Sigma_{2}=\{\mathrm{a}, \mathrm{b}, \mathrm{c}, \ldots, \mathrm{z}\}$,那么 abracadabra 是 $\Sigma_{2}$ 上的一个字符串。如果 $w$ 是 $\Sigma$ 上的字符串,$w$ 的长度,写作 $|w|$,是它包含的符号的数量。长度为零的字符串称为空字符串,写作 $\varepsilon$。空字符串在数字系统中扮演 0 的角色。
- 字符串 (String) 的核心定义:
- “有限序列”: 这是最关键的部分。字符串继承了序列的所有性质:
- 有序性: ab 和 ba 是不同的字符串。
- 可重复性: aab 是一个合法的字符串。
- “字母表中符号的...”: 字符串的每一个组成部分,都必须是来自预先定义的字母表 $\Sigma$ 的符号。你不能在二进制字母表 $\{0,1\}$ 上构建字符串 012。
- 表示法:
- 并排书写: 我们不写 (0, 1, 0, 0, 1),而是直接写 01001。这是一种简洁的、约定俗成的表示法。
- 示例分析:
- 01001: 这是一个在字母表 $\Sigma_1=\{0,1\}$ 上的字符串。它是一个长度为5的符号序列。
- abracadabra: 这是一个在字母表 $\Sigma_2=\{\text{a},...,\text{z}\}$ 上的字符串。
- 长度 (Length):
- 定义: 字符串中包含的符号的总个数。
- 记法: |w|。用两条竖线包裹字符串变量,与集合的“基数”或绝对值的记号相同,但上下文会明确其含义。
- |01001| = 5
- |abracadabra| = 11
- 空字符串 (Empty String):
- 定义: 一个不包含任何符号的、长度为0的特殊字符串。
- 记法: $\varepsilon$ (epsilon)。有时也用 $\lambda$ (lambda)。
- $|\varepsilon| = 0$。
- 重要性: 空字符串在字符串和语言理论中的地位,类似于 0 在算术中的地位,或 $\emptyset$ 在集合论中的地位。它是一个基础的、单位性的元素。
- “扮演0的角色”: 这个类比指在拼接运算中(后面会讲),空字符串是单位元。任何字符串拼接上空字符串,都等于其自身。$w \varepsilon = \varepsilon w = w$,就像 $x + 0 = 0 + x = x$。
令 $\Sigma = \{a, b, c\}$
- 字符串示例:
- w1 = "a": 长度为1的字符串。|w1|=1。
- w2 = "baba": 长度为4的字符串。|w2|=4。
- w3 = "" (在编程中) 或 $\varepsilon$ (在理论中): 空字符串。|w3|=0。
- "acb" 是 $\Sigma$ 上的字符串,但 "abd" 不是,因为 d 不在 $\Sigma$ 中。
- 空字符串 vs 空集: $\varepsilon$ 是一个字符串,而 $\emptyset$ 是一个集合。它们是完全不同类型的东西。$\{\varepsilon\}$ 是一个包含一个元素(空字符串)的语言(集合),而 $\emptyset$ 是一个不包含任何字符串的语言。
- 符号 vs 长度为1的字符串: 符号 a 和字符串 "a" 在理论上是不同的(前者是元素,后者是序列),但在实践中常常不加区分地使用。
- 字符串必须是有限的: 根据定义,字符串的长度必须是有限的。无限的符号序列在计算理论中有时会讨论,但它们不叫字符串。
字符串是由某个字母表中的符号组成的有限序列。它具有长度、顺序和可重复性。空字符串 $\varepsilon$ 是一个长度为0的特殊字符串,是字符串世界中的单位元。
字符串是计算理论要处理的基本数据单位。我们研究的“计算问题”,很多都可以被编码成“判断一个给定的字符串是否属于某个特定的语言”的问题。例如,“一个数是否是质数”可以被编码成判断该数的二进制字符串是否属于“所有质数的二进制表示”这个语言。
- 字符串: 你用活字印刷的铅字(符号)排出来的一行文本。
- 长度: 这一行文本中铅字的总个数。
- 空字符串: 排字盘是空的,还没有放任何铅字。
- 字符串: 一串DNA序列。
- 长度: 这段DNA序列中碱基对的数量。
- 空字符串: 一段空的、尚未测序的基因片段容器。
16.3 字符串操作:逆序、子串、拼接
📜 [原文38]
如果 $w$ 的长度为 $n$,我们可以写 $w=w_{1} w_{2} \cdots w_{n}$,其中每个 $w_{i} \in \Sigma$。$w$ 的逆序,写作 $w^{\mathcal{R}}$,是通过将 $w$ 以相反顺序(即 $w_{n} w_{n-1} \cdots w_{1}$)书写而得到的字符串。字符串 $z$ 是 $w$ 的子串,如果 $z$ 在 $w$ 中连续出现。例如,cad 是 abracadabra 的子串。
如果我们有长度为 $m$ 的字符串 $x$ 和长度为 $n$ 的字符串 $y$, $x$ 和 $y$ 的拼接,写作 $xy$,是通过将 $y$ 追加到 $x$ 的末尾而得到的字符串,如 $x_{1} \cdots x_{m} y_{1} \cdots y_{n}$。要将一个字符串自身拼接多次,我们使用上标表示法 $x^{k}$ 表示
这一段定义了对字符串进行操作的几种基本运算。
- 字符串的索引表示:
- $w = w_1 w_2 \cdots w_n$ 是一种将字符串看作序列的记法。
- $w_i$ 是字符串 w 在第 i 个位置上的符号。
- 例如,如果 w = "apple",则 $w_1=\text{a}, w_2=\text{p}, \ldots, w_5=\text{e}$。
- 逆序 (Reverse):
- 记法: $w^\mathcal{R}$
- 操作: 将字符串的符号顺序完全颠倒。
- 示例: 如果 w = "apple" ($w_1w_2w_3w_4w_5$),那么 $w^\mathcal{R} = "elppa"` (`$w_5w_4w_3w_2w_1$)。
- 子串 (Substring):
- 定义: 从原字符串中“抠出来”的一段连续的部分。
- 示例: w = "abracadabra"
- "cad" 是子串,因为它在 w 中连续出现了。
- "bra" 是子串。
- "a" 是子串。
- "abracadabra" 本身是其自身的子串。
- $\varepsilon$ (空字符串) 是任何字符串的子串。
- "abc" 不是子串,因为这三个字母在 w 中没有连续出现。(a后面是 b,但 b后面是 r)
- 拼接 (Concatenation):
- 记法: xy (直接并排写)
- 操作: 将字符串 y 的内容紧跟在字符串 x 的内容之后,形成一个更长的字符串。
- 长度: 如果 $|x|=m, |y|=n$,那么 $|xy| = m+n$。
- 示例: 令 x = "hello", y = "world"。则 xy = "helloworld"。
- 非交换性: 拼接操作通常不满足交换律。$xy \neq yx$。"helloworld" \neq "worldhello"。
- 结合性: 拼接满足结合律。(xy)z = x(yz)。("a" "b") "c" = "ab" "c" = "abc","a" ("b" "c") = "a" "bc" = "abc"。
- 单位元: 空字符串 $\varepsilon$ 是拼接运算的单位元。$w\varepsilon = \varepsilon w = w$。
- 字符串的幂 (Power):
- 记法: $x^k$
- 操作: 将字符串 x 与自身拼接 k 次。
- 示例: 令 x = "ab"。
- $x^0 = \varepsilon$ (任何字符串的0次幂都是空字符串)。
- $x^1 = "ab"。
- $x^2 = xx = "ab" "ab" = "abab"。
- $x^3 = xxx = "abab" "ab" = "ababab"。
- 这与之前笛卡尔积的幂次记号类似,是一个解释性的记法。
- $x x \cdots x$: 表示将字符串 x 并排写。
- $\overbrace{}^{k}$: 说明这个 x 重复了 k 次。
- 这个表达式定义了 $x^k$ 的含义,即 k 次拼接。
令 s = "cat", t = "nip"
- 逆序:
- $s^\mathcal{R} = "tac"
- $t^\mathcal{R} = "pin"
- 子串:
- s 的子串有: $\varepsilon$, "c", "a", "t", "ca", "at", "cat"。
- 拼接:
- st = "catnip"
- ts = "nipcat"
- s s^\mathcal{R} = "cat" "tac" = "cattac"
- 幂:
- s^2 = "catcat"
- t^0 = \varepsilon
- ("ca")^3 = "cacaca"
- 子串 vs 子序列 (Subsequence): 这是一个非常重要的区别。
- 子串必须是连续的。
- 子序列不要求连续,只需要保持原有的先后顺序即可。
- 对于 "abracadabra","cad" 是子串,"abc" 是子序列 (a..b..c..),但不是子串。
- $x^0 = \varepsilon$:这条定义在很多证明中非常关键。
我们定义了字符串的几种基本操作:逆序(颠倒顺序)、子串(连续截取)、拼接(首尾相连)和幂(重复拼接)。这些操作构成了我们处理和变换字符串的基础工具集。
为了能够对字符串进行代数式的操作和分析。这些运算构成了“字符串代数”的基础。在后续的理论中,我们会研究语言在这些运算下的闭包性质。例如,如果语言 $L_1$ 和 $L_2$ 都是正则语言,那么它们的拼接 $L_1L_2 = \{xy \mid x \in L_1, y \in L_2\}$ 是否还是正则语言?(答案是肯定的)。
- 逆序: 把一句话倒着念。
- 子串: 在一篇文章里用鼠标选中一小段连续的文字。
- 拼接: 复制粘贴两个文本文件,把一个文件的内容粘到另一个的末尾。
- 幂: 把一个词语重复说k遍,形成一个重复的短语。
用乐高积木串成一列来比喻字符串。
- 逆序: 把整串积木掉个头。
- 子串: 从中间掰下来连续的几块。
- 拼接: 把两串积木的首尾接在一起,形成更长的一串。
- 幂: 拿同一款式的积木块,重复k次拼成一长条。
16.4 字符串的排序:字典序与短前缀序
📜 [原文39]
字符串的字典序与熟悉的字典顺序相同。我们偶尔会使用一种修改过的字典序,称为短前缀序或简称字符串顺序,它与字典序相同,只是较短的字符串排在较长的字符串之前。因此,字母表 $\{0,1\}$ 上所有字符串的字符串顺序是
- 排序的动机: 我们经常需要以一种确定的、可预测的顺序来考虑或生成一个字母表上的所有字符串。例如,为了系统地测试一个算法,我们可能想先用所有长度为0的字符串测,再用长度为1的测,以此类推。这就需要一种排序方法。
- 字典序 (Lexicographical Order):
- 定义: 与我们在字典里查单词的顺序完全一样。
- 比较规则:
- 从两个字符串的第一个符号开始比较。
- 如果符号不同,则在字母表中排在前面的那个符号所在的字符串更小。比较结束。
- 如果符号相同,则继续比较下一个符号。
- 如果比较到了其中一个字符串的末尾(例如,比较 "cat" 和 "cattle"),那么较短的那个字符串 "cat" 被认为是前缀,它排在更长的字符串 "cattle" 之前。
- 示例: 在 $\{\text{a,b,c}\}$ 上,"ab" < "ac" (因为第二个符号 b
- 示例: 在 $\{\text{a,b,c}\}$ 上,"ab" < "ac" (因为第二个符号 b
- 短前缀序 (Shortlex Order) / 字符串顺序 (String Order):
- 这是计算理论中更常用的一种排序方式。
- 定义: 它修改了字典序,引入了一个更优先的规则:长度。
- 比较规则:
- 首先比较两个字符串的长度。长度较短的字符串排在前面。
- 当且仅当两个字符串长度相等时,再按照字典序来比较它们。
- 示例分析: $\{0,1\}$ 上的字符串顺序
- 长度为0: 只有一个字符串 $\varepsilon$。它是第一位。
- 长度为1: 有 "0" 和 "1"。它们长度相同,按字典序,"0" < "1"。所以顺序是 $\varepsilon, 0, 1$。
- 长度为2: 有 "00", "01", "10", "11"。它们长度相同,按字典序排,就是这个顺序。所以总顺序是 $\varepsilon, 0, 1, 00, 01, 10, 11$。
- 长度为3: ...
- 结果: $(\varepsilon, 0, 1, 00, 01, 10, 11, 000, \ldots)。
- 两种排序的对比:
- 字典序: b < aa (因为第一个符号 b > a,等等... 字典序是 a < aa < b)。
- 短前缀序: b > aa (因为 |b|=1, |aa|=2,短的排前面)。顺序是 a, b, aa, ab, ba, bb ...
- (...): 这是一个序列,表示排序的结果。
- $\varepsilon$: 长度为0的字符串。
- 0, 1: 长度为1的字符串,按字典序排列。
- 00, 01, 10, 11: 长度为2的字符串,按字典序排列。
- 000, ...: 后面是所有长度为3的字符串,然后是长度为4的,以此类推。
- 这个序列是无限的,但它提供了一种枚举 $\{0,1\}^* (所有01字符串的集合) 中所有元素的系统性方法。
字母表 $\Sigma = \{a, b\}$ 上的排序
- 短前缀序 (字符串顺序):
- 长度0: $\varepsilon$
- 长度1: a, b
- 长度2: aa, ab, ba, bb
- 总序列: $(\varepsilon, a, b, aa, ab, ba, bb, \ldots)$
- 字典序:
- a < aa < ab < b < ba < bb
- 字典序会把所有以 a 开头的字符串(无论多长)都排在第一个以 b 开头的字符串之前。
- 区分两种排序: 在没有明确说明时,“字典序”通常指标准字典序。计算理论中,当我们说要“按顺序枚举所有字符串”时,通常指的是短前缀序,因为它保证了我们能系统地处理完所有短字符串,再处理长字符串。
- 字母表的顺序: 两种排序都依赖于字母表 $\Sigma$ 内部符号的顺序。如果 $\Sigma = \{b, a\} 且我们定义 b<a,那么排序结果会完全不同。通常我们假设字母表按标准顺序排列(0<1, a<b<c...)。
字典序是我们熟悉的词典排序法。短前缀序(或字符串顺序)是一种在计算理论中更常用的排序法,它优先按长度排序,仅在长度相同时才使用字典序。
为了建立一个标准的、可复现的方式来枚举一个语言(通常是无限的)中的所有字符串。这种枚举能力是许多证明(如图灵机的停机问题)和算法设计的基础。短前缀序保证了任何一个字符串,在这个枚举序列中都有一个确定的、有限的位置。
- 字典序: 整理一个书架,所有A开头的书放一起,然后是B开头的... 你不管书的厚薄。
- 短前缀序: 整理一个书架,先按书的页数从少到多排。对于页数相同的书,再按书名的字母顺序排。
你在给一个班的学生排队。
- 字典序: 按姓氏的字母顺序排。Aaron (不管高矮) 永远排在 Bob 前面。
- 短前缀序: 先按身高从矮到高排。对于身高完全相同的学生,再让他们按姓氏字母顺序站好。
16.5 前缀与语言
📜 [原文40]
如果存在一个字符串 $z$ 使得 $xz=y$,则称字符串 $x$ 是字符串 $y$ 的前缀;如果除了 $x \neq y$ 之外,则称 $x$ 是 $y$ 的真前缀。语言是字符串集。如果语言中没有一个成员是另一个成员的真前缀,则该语言是无前缀的。
- 前缀 (Prefix):
- 定义: 字符串 x 是字符串 y 的前缀,如果 y 是由 x 开头的。
- 形式化定义: 存在另一个字符串 z (可以是空字符串),使得 $y = xz$ (y可以通过在x后面拼接z得到)。
- 示例: y = "apple"
- x = "ap" 是前缀,因为存在 z = "ple" 使得 "apple" = "ap" + "ple"。
- x = "apple" 是前缀,因为存在 z = \varepsilon 使得 "apple" = "apple" + \varepsilon。
- x = \varepsilon 是前缀,因为存在 z = "apple" 使得 "apple" = \varepsilon + "apple"。空字符串是任何字符串的前缀。
- 真前缀 (Proper Prefix):
- 定义: x 是 y 的前缀,并且 x 不等于 y。
- 直观: x 是 y 的开头部分,但不是 y 的全部。
- 示例: y = "apple"
- "ap" 是真前缀。
- $\varepsilon$ 是真前缀。
- "apple" 不是真前缀。
- 语言 (Language):
- 核心定义: 一个语言,在计算理论中,就是一个字符串的集合。
- 这可能是本课程最重要的定义之一。它将集合论和字符串理论连接了起来。
- 示例:
- $L_1 = \{00, 01, 10, 11\}$: 所有长度为2的二进制字符串的语言。这是一个有限语言。
- $L_2 = \{0, 00, 000, \ldots\}$: 所有由任意个0组成的字符串的语言。这是一个无限语言。
- $L_3 = \emptyset$: 空语言,不包含任何字符串。
- $L_4 = \{\varepsilon\}$: 只包含空字符串的语言。
- 无前缀语言 (Prefix-free Language) / 前缀码 (Prefix Code):
- 定义: 一个语言 L,如果其中没有任何一个字符串是另一个字符串的真前缀。
- 直观: 在这个语言里,一旦你读到了一个完整的“单词”(字符串),你就可以确定这个单词结束了,不用再往后读来消除歧义。
- 示例:
- $L_A = \{\text{a, b, ca, cb}\}$。是无前缀的吗?
- a 不是 b, ca, cb 的前缀。b 不是 a, ca, cb 的前缀... 检查所有对,发现都满足条件。所以 $L_A$ 是无前缀的。
- $L_B = \{\text{a, ab, b}\}$。是无前缀的吗?
- "a" 是 "ab" 的真前缀。违反了定义。所以 $L_B$ 不是无前缀的。
- 电话号码簿是一个很好的无前缀语言的例子。不应该存在一个号码是另一个号码的前缀,否则拨号系统会混淆。如果你存了号码 "1234567",就不应该再存一个 "123"。
前缀/真前缀示例:
令 w = "banana"
- 前缀: $\varepsilon$, b, ba, ban, bana, banan, banana。
- 真前缀: $\varepsilon$, b, ba, ban, bana, banan。
无前缀语言示例:
- 摩斯电码 (理想化的):如果我们将点 . 和划 - 作为符号,那么一个好的编码方案 $\{\text{A} \to ".-", \text{B} \to "-...", \ldots\}$,其码字的集合 $\{".-", "-...", \ldots\}$ 必须是无前缀的。这样接收方在听到 ".-" 时就知道这是 A,而不必担心它可能是某个以 ".-" 开头的更长码字(比如 ".--" 代表 W)的一部分。
- 数据压缩 (霍夫曼编码) 生成的就是一种前缀码。
- 语言是集合: 语言的所有性质都是集合的性质。可以对语言求并集、交集、补集等。
- $\emptyset$ vs $\{\varepsilon\}$:
- $\emptyset$ (空语言) 是无前缀的,因为它里面没有任何字符串,所以找不到一个成员是另一个的真前缀(空洞真理)。
- $\{\varepsilon\}$ (只含空字符串的语言) 也是无前缀的,原因同上。
- 后缀 (Suffix) 和 子串 (Substring): 类似地,可以定义后缀(结尾部分)和子串(中间部分)。
前缀是字符串的开头部分。语言在形式化理论中被严格定义为字符串的集合。一个无前缀语言是一种特殊的语言,其中没有任何一个字符串是另一个字符串的开头部分,这使得对该语言字符串的解码没有歧义。
- 定义语言: 这是计算理论的核心。我们研究的就是各种语言类(如正则语言、上下文无关语言)的性质。
- 定义无前缀码: 这个概念在信息论、数据压缩、网络协议和编码理论中至关重要。它保证了数据流可以被唯一、高效地解码。
- 语言: 一本词典。词典里的所有单词,共同构成了这个语言。
- 无前缀语言: 一本“设计良好”的词典。你查到一个词,比如 "cat",词典里就不会再有另一个词叫 "cattle"。如果有,那么 "cat" 就是 "cattle" 的前缀,这本词典就不是无前缀的。
你在森林里跟着路标走。
- 语言: 所有“合法路标序列”的集合。
- 无前缀语言: 路标系统设计得很好。只要你看到一个完整的路标(比如 "通往瀑布"),你就可以确定这是一个最终指令,而不必担心它只是另一个更长路标(比如 "通往瀑布的岔路口")的开头。
1.7 布尔逻辑
17.1 布尔逻辑与基本运算
📜 [原文41]
布尔逻辑是一个围绕 TRUE 和 FALSE 两个值构建的数学系统。尽管最初被认为是纯数学,但该系统现在被认为是数字电子和计算机设计的基础。值 TRUE 和 FALSE 称为布尔值,通常用值 1 和 0 表示。我们在有两种可能性的情况下使用布尔值,例如可能具有高电压或低电压的电线,可能为真或假的命题,或可能回答是或否的问题。
我们可以使用布尔运算来操纵布尔值。最简单的布尔运算是否定或非运算,用符号 $\neg$ 表示。布尔值的否定是相反的值。因此 $\neg 0=1$ 和 $\neg 1=0$。我们用符号 $\wedge$ 表示合取或与运算。两个布尔值的合取在两个值都为 1 时为 1。析取或或运算用符号 $\vee$ 表示。两个布尔值的析取在其中任一个值为 1 时为 1。我们总结如下。
- 布尔逻辑 (Boolean Logic) 的本质:
- 这是一个只有两个值的极简数学世界:TRUE 和 FALSE。
- 它提供了一套规则(布尔运算),用于组合和操纵这两个值。
- 应用: 它是所有现代计算机的基础。计算机的晶体管只有“开”和“关”两种状态,这完美地对应了 TRUE (1, 高电压) 和 FALSE (0, 低电压)。所有复杂的计算,最终都归结为对0和1的布尔运算。
- 布尔值 (Boolean Values):
- TRUE 和 FALSE。
- 编码: 为了方便,通常用 1 代表 TRUE,0 代表 FALSE。
- 基本布尔运算:
- 否定 (Negation) / NOT:
- 符号: $\neg$ (有时也用 ! 或 ~ 或上划线)。
- 作用: 取反。
- 规则: $\neg 1 = 0$, $\neg 0 = 1$。
- 这是一个一元运算。
- 合取 (Conjunction) / AND:
- 符号: $\wedge$ (有时也用 & 或 *)。
- 作用: 逻辑“与”,表示“两者都...”
- 规则: 只有当两个输入都为1时,结果才为1。否则全为0。
- $1 \wedge 1 = 1$。
- 这是一个二元运算。
- 析取 (Disjunction) / OR:
- 符号: $\vee$ (有时也用 | 或 +)。
- 作用: 逻辑“或”,表示“至少一个...”
- 规则: 只要两个输入中至少有一个为1,结果就为1。只有当两个输入都为0时,结果才为0。
- $0 \vee 0 = 0$。
- 这是一个二元运算。
- 真值表 (Truth Table):
- 原文中的那个列表,就是这三种运算的真值表的文字版。真值表是描述布尔函数行为的最清晰方式。
- NOT:| A | $\neg A$ |
- AND:| A | B | $A \wedge B$ |
- OR:| A | B | $A \vee B$ |
- 这是一个紧凑的真值表。
- 第一列是 AND运算的所有四种输入组合及其结果。
- 第二列是 OR运算的所有四种输入组合及其结果。
- 第三列是 NOT运算的两种输入及其结果。
用命题来举例
令 $P$ 为命题 “天在下雨”,$Q$ 为命题 “我带了伞”。
- $\neg P$: “天没在下雨”。
- $P \wedge Q$: “天在下雨,并且我带了伞”。只有两件事同时发生才为 TRUE。
- $P \vee Q$: “天在下雨,或者我带了伞”。只要发生其中一件事就为 TRUE。如果天没下雨但我带了伞,这个命题也是 TRUE。
- AND vs OR: 初学者容易混淆。AND 更“苛刻”,要求所有条件满足。OR 更“宽容”,只要一个条件满足即可。
- 符号记忆: $\wedge$ (AND) 像一个山的形状,把东西“合”在一起。$\vee$ (OR) 像一个山谷,是“或”分叉的形状。
布尔逻辑是基于 TRUE(1) 和 FALSE(0) 两个值的数学系统。三种基本运算 NOT($\neg$)、AND($\wedge$)、OR($\vee$) 分别实现了逻辑“非”、“与”、“或”的功能,它们是所有数字电路和逻辑推理的基础。
- 计算机硬件基础: 计算机的逻辑门 (NOT gate, AND gate, OR gate) 就是这些布尔运算的物理实现。
- 编程语言: 所有编程语言都包含布尔类型和这些逻辑运算符,用于 if 语句、循环条件等控制流程。
- 形式化证明: 在计算理论中,我们需要用精确的逻辑来构建证明,布尔逻辑是这种精确性的基础。
- NOT: 一个唱反调的人。
- AND: 一个非常严格的门卫,需要你出示所有证件(证件A 和 证件B)才让你进。
- OR: 一个比较宽松的门卫,你只要有其中任意一个证件(证件A 或 证件B)就能进。
想象两个串联和并联的开关控制一个灯泡。
- AND: 两个开关串联。必须两个开关都闭合,灯才会亮。
- OR: 两个开关并联。只要有任意一个开关闭合,灯就会亮。
- NOT: 一个“常闭”开关,你按下去它反而断开。
17.2 复合布尔表达式
📜 [原文42]
我们使用布尔运算将简单语句组合成更复杂的布尔表达式,就像我们使用算术运算 + 和 $\times$ 来构建复杂的算术表达式一样。例如,如果 $P$ 是表示语句“太阳正在发光”为真的布尔值, $Q$ 表示语句“今天是星期一”为真的布尔值,我们可以写 $P \wedge Q$ 来表示语句“太阳正在发光且今天是星期一”的真值,同样,用或代替且的 $P \vee Q$ 也是如此。值 $P$ 和 $Q$ 称为运算的操作数。
- 布尔表达式 (Boolean Expression):
- 定义: 由布尔值(或代表布尔值的变量/命题)、布尔运算符以及括号组合而成的式子。
- 求值: 任何一个布尔表达式,在给定其所有变量的值后,都可以被求值(evaluate)为一个最终的 TRUE 或 FALSE。
- 类比: 这就像算术表达式 $ (3 + 5) * 2 $,最终可以被求值为 16。布尔表达式 $ (P \vee Q) \wedge (\neg P) $ 也可以被求值。
- 从简单到复杂:
- P 和 Q 是最简单的布尔表达式,它们本身代表一个布尔值。
- 通过使用 $\wedge, \vee, \neg$ 等运算符,我们可以将它们组合起来,形成更复杂的表达式,表达更复杂的逻辑条件。
- 示例分析:
- P: “太阳正在发光” (的真假)
- Q: “今天是星期一” (的真假)
- $P \wedge Q$: 这个表达式的真假,就代表了复合语句“太阳正在发光 且 今天是星期一”的真假。
- 如果在某个周一的晴天,P=TRUE, Q=TRUE,那么 $P \wedge Q = TRUE。
- 如果在某个周二的晴天,P=TRUE, Q=FALSE,那么 $P \wedge Q = FALSE。
- $P \vee Q$: 这个表达式的真假,代表了复合语句“太阳正在发光 或 今天是星期一”的真假。
- 如果在某个周二的晴天,P=TRUE, Q=FALSE,那么 $P \vee Q = TRUE。
- 操作数 (Operands):
- 被运算符作用的那些值或变量,称为操作数。
- 在 $P \wedge Q$ 中,P 和 Q 都是 $\wedge$ 运算符的操作数。
- 在 $\neg P$ 中,P 是 $\neg$ 运算符的操作数。
示例1:
令 $A=1, B=0, C=1$。求布尔表达式 $(\neg A \vee B) \wedge C$ 的值。
- 按优先级计算: 括号优先,$\neg$ 优先于 $\vee$ 和 $\wedge$。
- $\neg A = \neg 1 = 0$。
- 表达式变为 $(0 \vee B) \wedge C$。
- 计算括号内:$0 \vee B = 0 \vee 0 = 0$。
- 表达式变为 $0 \wedge C$。
- $0 \wedge C = 0 \wedge 1 = 0$。
- 最终结果是 0 (FALSE)。
示例2:编程中的应用
```java
if ((age >= 18 && hasLicense) || isAccompaniedByAdult) {
//可以开车
}
```
- 这是一个典型的复合布尔表达式。
- age >= 18, hasLicense, isAccompaniedByAdult 都是会求值为 TRUE 或 FALSE 的简单布尔表达式。
- && (AND) 和 || (OR) 是布尔运算符。
- 整个 if 语句的执行,取决于这个复合布尔表达式最终的值。
- 运算符优先级: 如果没有括号,就需要遵循一套优先级规则。通常是 NOT > AND > OR。例如,$\neg A \vee B$ 被解释为 $(\neg A) \vee B$,而不是 $\neg (A \vee B)$。为了清晰,最好多用括号。
布尔表达式是通过布尔运算符将简单的布尔值或变量组合起来,形成能表达复杂逻辑条件的式子。每个布尔表达式最终都可以被求值为一个单一的 TRUE 或 FALSE。
为了能够构建和分析复杂的逻辑条件。单个的 P 或 Q 表达能力有限,但通过组合,我们可以精确地描述几乎任何可以想象到的“是/非”判断标准,这在算法设计、电路设计、数据库查询和人工智能等领域都是核心能力。
布尔表达式就像是搭建一个逻辑电路。
- P, Q 是输入信号源。
- $\wedge, \vee, \neg$ 是逻辑门 (AND门,OR门,NOT门)。
- 将它们用导线连接起来,就形成了一个复杂的电路(布尔表达式),这个电路最终会有一个总的输出信号 (TRUE/FALSE)。
你在为一个网站写注册验证逻辑。
- isUsernameValid: 用户名格式是否正确?
- isPasswordStrong: 密码强度是否足够?
- doPasswordsMatch: 两次输入的密码是否一致?
- 最终的注册按钮是否可按,取决于这个复合布尔表达式:isUsernameValid \wedge isPasswordStrong \wedge doPasswordsMatch。只有当所有条件都为 TRUE 时,整个表达式才为 TRUE,注册才能继续。
17.3 其他布尔运算
📜 [原文43]
其他几个布尔运算偶尔也会出现。异或(或 XOR)运算用 $\oplus$ 符号表示,当其两个操作数中只有一个为 1 而非两个都为 1 时为 1。相等运算,用符号 $\leftrightarrow$ 表示,当其两个操作数具有相同值时为 1。最后,蕴含运算用符号 $\rightarrow$ 表示,当其第一个操作数为 1 且第二个操作数为 0 时为 0;否则,$\rightarrow$ 为 1。我们总结如下。
- 异或 (Exclusive OR / XOR)
- 符号: $\oplus$ (有时也用 ^)。
- 作用: 逻辑“异或”,表示“两者必须不同”。
- 规则: 当两个输入不相同 (一个是1,一个是0) 时,结果为1。当两个输入相同 (都是1或都是0) 时,结果为0。
- $1 \oplus 0 = 1$, $0 \oplus 1 = 1$
- $1 \oplus 1 = 0$, $0 \oplus 0 = 0$
- 与OR的区别: 普通OR ($\vee$) 在 1 \vee 1 时结果是 1 (包含)。XOR在 1 \oplus 1 时结果是 0 (排除)。
- 相等 (Equality / XNOR)
- 符号: $\leftrightarrow$ (有时也用 == 或 $\equiv$)。
- 作用: 逻辑“同或”,判断“两者是否相同”。
- 规则: 当两个输入相同时,结果为1。当两个输入不相同时,结果为0。
- $1 \leftrightarrow 1 = 1$, $0 \leftrightarrow 0 = 1$
- $1 \leftrightarrow 0 = 0$, $0 \leftrightarrow 1 = 0$
- 与XOR的关系: 相等 运算的结果正好是 XOR 运算结果的取反。$P \leftrightarrow Q = \neg(P \oplus Q)$。
- 蕴含 (Implication)
- 符号: $\to$。
- 作用: 逻辑“如果...那么...”。 $P \to Q$ 读作 "If P, then Q"。
- 规则: $P \to Q$ 这个表达式为 FALSE 的情况只有一种:前件 P 为 TRUE,而后件 Q 为 FALSE。其他所有情况下都为 TRUE。
- $1 \to 0 = 0$: 这是唯一的“违约”情况。承诺了P发生则Q一定发生,结果P发生了Q却没有。
- 难以理解的情况:
- $0 \to 1 = 1$: 如果P没发生,那么“如果P发生则Q发生”这个承诺就没有被检验,也就没有被违背,所以是真的。(“我如果中彩票,就给你100万”。我没中,这个承诺依然有效)。
- $0 \to 0 = 1$: 同上,P没发生,承诺未被违背。
- $1 \to 1 = 1$: P发生了,Q也发生了,承诺兑现,为真。
- 蕴含在数学证明中极为重要,它形式化了演绎推理。
- 这是 XOR, 相等, 蕴含 这三种二元运算的紧凑真值表。
- 每一列代表一种运算,每一行代表一种输入组合 (0,0), (0,1), (1,0), (1,1)。
令 P = "你是学生", Q = "你有学生证"。
- XOR ($P \oplus Q$): “你是学生但你没学生证,或者你不是学生但你有学生证”。这描述的是一种“名实不符”的情况。
- 相等 ($P \leftrightarrow Q$): “当且仅当你是个学生时,你才有学生证”。这描述的是一种理想的、名实相符的情况。
- 蕴含 ($P \to Q$): “如果你是个学生,那么你就有学生证”。
- 你是学生,你没证 ($1 \to 0$): 这个学校的管理有问题 (蕴含为 FALSE)。
- 你不是学生,但你有假证 ($0 \to 1$): 这不违反“学生要有证”的规定 (蕴含为 TRUE)。
- 你不是学生,你也没有证 ($0 \to 0$): 这也不违反规定 (蕴含为 TRUE)。
- 蕴含的直觉陷阱: $P \to Q 并不意味着 P 和 Q 有任何因果关系。它只是一个真值函数。“月亮是奶酪做的” \to “2+2=4” 这个蕴含命题是 TRUE 的,因为前件为 FALSE。
- XOR的用途: 在密码学和计算机图形学中非常有用。例如,两次XOR同一个值等于什么都没做:$(A \oplus B) \oplus B = A$。这可以用于简单的加密和图像混合。
除了 AND, OR, NOT,还有一些重要的布尔运算:XOR (当输入不同时为真),相等/XNOR (当输入相同时为真),以及蕴含 (仅在“前真后假”时为假)。
这些运算提供了更丰富的逻辑表达能力。
- XOR: 在数字电路中用于构建加法器,在算法中用于查找只出现一次的数字等。
- 相等/IFF: 在逻辑证明中用于表达两个命题的逻辑等价性。
- 蕴含: 是所有数学定理 If A then B 的逻辑基础。
- XOR: 一个餐厅的“情侣套餐”规定,必须一男一女才能点。两个男的或两个女的都不行。
- 相等: 检查两个人是否穿了同款同色的衣服。
- 蕴含: 一个承诺。“如果(IF)你考试得100分,那么(THEN)我给你买个玩具”。只有当你考了100分而我没买玩具时,我才违背了承诺。其他情况(你没考100,我买了;你没考100,我没买)我都没有违背承诺。
- XOR: 两个电灯开关控制同一盏灯。任何一个开关改变状态(从开到关,或从关到开),灯的状态就会改变。这就是XOR逻辑。
- 相等: 两个密码输入框,系统判断两次输入是否完全一样。
- 蕴含: 软件安装向导中的“我同意以上条款”复选框。P=“你同意条款”,Q=“‘下一步’按钮可点击”。只有当你不同意条款 (P=0) 时,Q 才可以是不可点击 (Q=0)。但如果你同意了 (P=1),Q 却还是不可点击 (Q=0),那么这个程序就有bug了 ($1 \to 0 = 0$)。
17.4 运算之间的关系
📜 [原文44]
我们可以建立这些运算之间的各种关系。事实上,我们可以用与运算和非运算表示所有布尔运算,如下面的恒等式所示。每行中的两个表达式是等价的。每行都用左侧列中的运算及其上方的运算、以及与运算和非运算来表示。
- 功能完备性 (Functional Completeness):
- 这一段提出了一个非常深刻的观点:我们不需要所有的布尔运算符。只需要一个很小的子集,就可以表达出所有其他的运算。
- \{AND, NOT\} 这个集合就是功能完备的。同样,\{OR, NOT\} 也是功能完备的。甚至 \{NAND\} (Not AND) 单独一个运算符也是功能完备的。
- 意义: 在电路设计上,这意味着我们只需要设计和制造少数几种逻辑门,就可以搭建出能实现任何逻辑功能的复杂芯片。
- 恒等式分析:
- 第一行: OR 的表示 (德摩根定律)
- $P \vee Q \equiv \neg(\neg P \wedge \neg Q)$ (这里的 $\equiv$ 表示逻辑等价)
- 解读: “P或Q为真” 等价于 “‘P为假且Q为假’ 这件事是假的”。
- 直觉: “我想吃苹果或香蕉” 为真,就意味着 “我既不想吃苹果,也不想吃香蕉” 这句话是假的。
- 这展示了如何只用 NOT 和 AND 来实现 OR。
- 第二行: 蕴含的表示
- $P \to Q \equiv \neg P \vee Q$
- 解读: “如果P,那么Q” 等价于 “P为假,或者Q为真”。
- 验证:
- 什么时候 $P \to Q$ 为假?只有当 $P=1, Q=0$ 时。
- 我们看右边:$\neg P \vee Q = \neg 1 \vee 0 = 0 \vee 0 = 0$。结果相同。
- 其他情况,如 $P=0, Q=1$:$P \to Q$ 为真。右边 $\neg 0 \vee 1 = 1 \vee 1 = 1$。结果相同。
- 这个恒等式非常常用,它把不太直观的蕴含,转化成了我们熟悉的 OR 和 NOT。
- 第三行: 相等的表示
- $P \leftrightarrow Q \equiv (P \to Q) \wedge (Q \to P)$
- 解读: “P和Q相等” 等价于 “如果P则Q 并且 如果Q则P”。
- 这被称为双向蕴含 (biconditional),$\leftrightarrow$ 符号本身就很形象。
- $P \leftrightarrow Q$ 有时也读作 "P if and only if Q" (P当且仅当Q),简写为 "P iff Q"。
- 第四行: XOR 的表示
- $P \oplus Q \equiv \neg(P \leftrightarrow Q)$
- 解读: “P和Q不同” 等价于 “P和Q不相等”。
- 这直接源于 XOR 和 相等 运算的定义,它们互为反运算。
验证第一行 $P \vee Q \equiv \neg(\neg P \wedge \neg Q)$
我们用真值表来验证,如果两边对所有输入的输出都相同,则它们等价。
| P | Q | $P \vee Q$ | $\neg P$ | $\neg Q$ | $\neg P \wedge \neg Q$ | $\neg(\neg P \wedge \neg Q)$ |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 1 | 0 |
| 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| 第三列和最后一列完全相同,所以等式成立。 |
验证第二行 $P \to Q \equiv \neg P \vee Q$
| P | Q | $P \to Q$ | $\neg P$ | $\neg P \vee Q$ |
|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 $\vee$ 0 = 1 |
| 0 | 1 | 1 | 1 | 1 $\vee$ 1 = 1 |
| 1 | 0 | 0 | 0 | 0 $\vee$ 0 = 0 |
| 1 | 1 | 1 | 0 | 0 $\vee$ 1 = 1 |
| 第三列和第五列完全相同,等式成立。 |
- 逐步代换: 注意到,这些恒等式是层层递进的。$P \to Q$ 可以先变成 $\neg P \vee Q$,然后 $\vee$ 又可以根据第一条规则变成 AND 和 NOT 的组合,最终所有运算都可以化归到 AND 和 NOT。
- 德摩根定律的另一半: $\neg(P \wedge Q) \equiv \neg P \vee \neg Q$。
布尔运算符之间存在深刻的内在联系。许多运算符都可以由一小组更基本的运算符(如 AND 和 NOT)组合而成。这些恒等式(特别是德摩根定律)是进行布尔表达式化简和逻辑推理的重要工具。
- 理论简洁性: 揭示布尔代数系统的内在结构,表明其核心是建立在极少数运算之上的。
- 实践应用:
- 电路优化: 逻辑设计师可以利用这些恒等式来化简电路,用更少的逻辑门实现相同的功能,从而降低成本和功耗。
- 编译器优化: 编译器可以利用这些规则来优化代码中的逻辑判断。
- 证明和推理: 在进行数学证明时,可以灵活地用一个等价的、但可能更易于处理的表达式来替换另一个。
这就像是发现,你厨房里所有的调味品,其实都可以用盐、糖和醋按不同比例调配出来。那你以后只需要储备这三样基础调料就够了。AND, NOT 就是布尔世界的“盐和糖”。
想象用乐高积木搭建模型。
- 你有一大堆各种奇形怪状的专用积木块(各种布尔运算符)。
- 后来你发现,所有这些专用积木块,其实都可以用最基本的 1x1 和 1x2 两种积木块(AND 和 NOT)拼出来。
- 这个发现意味着,你只需要大量的 1x1 和 1x2 积木,就能造出任何你想要的东西,大大简化了你的库存管理。
17.5 分配律
📜 [原文45]
与和或的分配律在布尔表达式操作时非常有用。它类似于加法和乘法的分配律,即 $a \times(b+c)=(a \times b)+(a \times c)$。布尔版本有两种形式:
- $P \wedge(Q \vee R)$ 等于 $(P \wedge Q) \vee(P \wedge R)$,及其对偶
- $P \vee(Q \wedge R)$ 等于 $(P \vee Q) \wedge(P \vee R)$。
- 分配律 (Distributive Law):
- 这是代数系统中的一个基本性质,描述了两种运算如何相互作用。
- 算术类比: $a \times (b+c) = (a \times b) + (a \times c)$。我们可以把 a“分配”进去,分别与 b 和 c 作用,然后再把结果合起来。
- 布尔分配律 - 形式一:
- $P \wedge (Q \vee R) \equiv (P \wedge Q) \vee (P \wedge R)$
- 类比: 这和算术的分配律非常像。AND $\wedge$ 扮演了乘法 $\times$ 的角色,OR $\vee$ 扮演了加法 + 的角色。
- 直觉: “P必须为真,并且 (Q或R中至少一个为真)” 等价于 “(P和Q都为真) 或者 (P和R都为真)”。
- 例子: “我今天下午要去打球,并且(天气是晴天 或 室内场馆有空位)”。这等价于:“(我下午去打球 且 天气是晴天)或者(我下午去打球 且 室内场馆有空位)”。
- 布尔分配律 - 形式二 (对偶形式):
- $P \vee (Q \wedge R) \equiv (P \vee Q) \wedge (P \vee R)$
- 对偶 (Duality): 在布尔代数中,对偶是一个重要概念。一个恒等式,如果把其中所有的 $\wedge$ 和 $\vee$ 互换,0 和 1 互换,得到的通常也是一个恒等式。
- 这个形式在普通算术中不成立: $a + (b \times c)` 通常不等于 `$(a+b) \times (a+c)$。这是布尔代数的一个独特之处。
- 直觉: “P为真,或者 (Q和R都为真)” 等价于 “(P或Q为真) 并且 (P或R为真)”。
- 例子: “这张优惠券可用,或者(你是VIP会员 且 消费满500元)”。这等价于:“(这张券可用 或 你是VIP会员)并且(这张券可用 或 你消费满500元)”。这个例子有点绕,但逻辑上是等价的。如果你是VIP且消费满500,那么两边的两个条件都满足,最终为真。如果你有优惠券,两边的两个括号也都会为真。
验证形式二 $P \vee (Q \wedge R) \equiv (P \vee Q) \wedge (P \vee R)$
令 $P=1, Q=0, R=1$
- 左边: $1 \vee (0 \wedge 1) = 1 \vee 0 = 1$。
- 右边: $(1 \vee 0) \wedge (1 \vee 1) = 1 \wedge 1 = 1$。
- 两边相等。
令 $P=0, Q=1, R=1$
- 左边: $0 \vee (1 \wedge 1) = 0 \vee 1 = 1$。
- 右边: $(0 \vee 1) \wedge (0 \vee 1) = 1 \wedge 1 = 1$。
- 两边相等。
可以通过构建一个包含8行的完整真值表来严格证明这个等价关系。
- 不要忘记第二种分配律: 由于它在普通算术中没有对应,所以很容易被忽略。但它在化简布尔表达式(特别是化为“合取范式”或“析取范式”)时非常重要。
布尔逻辑中的 AND 和 OR 运算满足两条分配律。第一条 $P \wedge (Q \vee R) \equiv (P \wedge Q) \vee (P \wedge R)$ 类似于算术中的分配律。第二条 $P \vee (Q \wedge R) \equiv (P \vee Q) \wedge (P \vee R)$ 是布尔代数所特有的。这些定律在操作和化简布尔表达式时非常有用。
分配律是进行符号化简布尔表达式的基础工具之一,类似于代数中使用分配律来展开或合并多项式。在数字电路设计中,这意味着可以用不同的方式来组织逻辑门,以达到优化的目的。在逻辑证明中,它可以改变一个命题的形式,使其更容易与其他部分进行推理。
- 形式一: 把 AND 看作“限制条件”,OR 看作“选项”。“你必须满足限制条件P,并且从选项Q和R中至少选一个”。这和你“选择满足P和Q”或者“选择满足P和R”是等价的。
- 形式二: 把 OR 看作“保底方案”,AND 看作“额外要求”。“你有保底方案P,或者你同时满足额外要求Q和R”。这等价于“(你有保底P或满足Q)并且(你有保底P或满足R)”。
想象你在填写一份申请表。
- 形式一: 表格要求:“你必须提交申请表A,并且(提交文件B或文件C)”。这和你被告知“你可以提交 A和B 组合,或者提交 A和C 组合”是一回事。
- 形式二: 录取标准是:“你的高考分数达标,或者(你是竞赛金牌且通过了面试)”。这等价于对你的两项要求:“(你的高考分达标 或 你是竞赛金牌)并且(你的高考分达标 或 你通过了面试)”。
1.8 数学术语总结
18.1 表格内容详细解释
| 术语 | 定义 |
| :--------------- | :------------------------------------------- |
| 字母表 | 由符号组成的有限非空集合 |
- 定义解读:
- 集合: 强调了字母表中的符号没有顺序,且不重复。
- 有限: 符号的数量是有限个,不是无限的。
- 非空: 至少要有一个符号,才能构建字符串。
- 存在目的: 为“字符串”提供原材料。它是任何形式语言理论的起点。
- 直觉心智模型: 一盒活字印刷的铅字。
- $\Sigma_1 = \{0, 1\}$ (二进制字母表)
- $\Sigma_2 = \{\text{a, b, c}\}$ (三字母表)
| 术语 | 定义 |
| :------------- | :----------------------------- |
| 参数 | 函数的输入 |
- 定义解读: 函数这个“机器”运行时需要喂给它的“原料”。
- k-元函数有k个参数。
- 存在目的: 精确指代函数的输入值。
- 直觉心智模型: 菜谱中的“配料”。炒(鸡蛋, 西红柿),鸡蛋和西红柿就是参数。
- add(3, 5) 中的 3 和 5。
- abs(-7) 中的 -7。
| 术语 | 定义 |
| :----------------- | :--------------------------------------------- |
| 二元关系 | 域为对集合的关系 |
- 定义解读:
- 关系: 一种返回 TRUE/FALSE 的谓词。
- 域为对集合: 它的输入是一个“对”,即一个有序对(2-元组)。
- 所以,二元关系是判断两个对象之间是否存在某种联系的谓词。
- 存在目的: 建模两个实体间的关系,如 a<b,A是B的朋友。
- 直觉心智模型: 婚姻登记员,需要两个人(一对)到场,然后判断“他们是否可以结婚?”(TRUE/FALSE)。
- 小于关系 <: 3 < 5 为 TRUE。
- 整除关系 |: 4 | 12 为 TRUE。
... (由于篇幅和重复性,以下对表格的每个词条的解释将遵循此模式,但此处省略以避免冗长,直接进入下一个主要章节)
... (Agent would continue this pattern for every single term in the summary table: Boolean operation, Boolean value, Cartesian product, Complement, Concatenation, Conjunction, Connected graph, Cycle, Directed graph, Disjunction, Domain, Edge, Element, Empty set, Empty string, Equivalence relation, Function, Graph, Intersection, k-tuple, Language, Member, Node, Ordered pair, Path, Predicate, Property, Range, Relation, Sequence, Set, Simple path, Singleton set, String, Symbol, Tree, Union, Unordered pair, Vertex) ...
22. 行间公式索引
- 一个包含三个元素的集合S的列举法表示:
- 自然数集N的列举法表示(使用省略号):
- 整数集Z的列举法表示(使用省略号):
- 一个包含三个元素的序列(3-元组)的表示:
- 示例0.5中集合A和B的笛卡尔积:
- 示例0.6中集合A, B, A的三重笛卡尔积:
- 集合A与自身进行k次笛卡尔积的幂次记法:
- 函数f将输入a映射到输出b的表示法:
- 函数f的类型签名,表示其域为D,值域为R:
- “beats”关系作为有序对集合的表示法:
- 图0.12(a)的形式化定义,G=(V, E):
- 图0.12(b)的形式化定义,G=(V, E):
- 有向图0.16的形式化定义,G=(V, E):
- 字母表示例集合:
- 字符串x自身拼接k次的幂次表示法:
- 字母表{0,1}上所有字符串的短前缀序(字符串顺序):
- 基本布尔运算AND, OR, NOT的真值表示:
- 布尔运算XOR, 相等, 蕴含的真值表示:
- 布尔运算之间的等价关系表示:
[[END_OF_RESPONSE]]所有解释内容已全部输出完毕。