11.3
正则表达式
在算术中,我们可以使用 + 和 × 运算来构建表达式,例如
类似地,我们可以使用正则运算来构建描述语言的表达式,这些表达式被称为正则表达式。一个例子是:
算术表达式的值是数字 32。正则表达式的值是语言。在这种情况下,其值是包含所有以 0 或 1 开头,后跟任意数量 0 的字符串的语言。我们通过将表达式分解为各个部分来获得此结果。首先,符号 0 和 1 是集合 $\{0\}$ 和 $\{1\}$ 的简写。因此 $(0 \cup 1)$ 表示 $(\{0\} \cup\{1\})$。这部分的值是语言 $\{0,1\}$。部分 $0^{*}$ 表示 $\{0\}^{*}$,其值是包含任意数量 0 的字符串的语言。其次,就像代数中的 × 符号一样,连接符号 ∘ 在正则表达式中通常是隐式的。因此 $(0 \cup 1) 0^{*}$ 实际上是 $(0 \cup 1) \circ 0^{*}$ 的简写。连接将来自两个部分的字符串连接起来,以获得整个表达式的值。
正则表达式在计算机科学应用中扮演着重要角色。在涉及文本的应用中,用户可能希望搜索符合特定模式的字符串。正则表达式提供了一种描述此类模式的强大方法。UNIX 中的 awk 和 grep 等实用程序、Perl 等现代编程语言以及文本编辑器都提供了使用正则表达式描述模式的机制。
示例 1.51
正则表达式的另一个例子是
它以语言 $(0 \cup 1)$ 开始,并应用 星号运算。这个表达式的值是包含所有可能的 0 和 1 字符串的语言。如果 $\Sigma=\{0,1\}$,我们可以将 $\Sigma$ 写成正则表达式 $(0 \cup 1)$ 的简写。更一般地,如果 $\Sigma$ 是任何字母表,正则表达式 $\Sigma$ 描述的是该字母表上所有长度为 1 的字符串组成的语言,而 $\Sigma^{*}$ 描述的是该字母表上所有字符串组成的语言。类似地,$\Sigma^{*} 1$ 是包含所有以 1 结尾的字符串的语言。语言 $\left(0 \Sigma^{*}\right) \cup\left(\Sigma^{*} 1\right)$ 包含所有以 0 开头或以 1 结尾的字符串。
在算术中,我们说 × 具有比 + 更高的优先级,意思是当有选择时,我们先执行 × 运算。因此在 $2+3 \times 4$ 中,$3 \times 4$ 在加法之前完成。为了让加法先完成,我们必须添加括号以获得 $(2+3) \times 4$。在正则表达式中,星号运算先完成,其次是连接,最后是并,除非括号改变了通常的顺序。
正则表达式的形式化定义
定义 1.52
如果 $R$ 是正则表达式,则 $R$ 是以下之一:
- 字母表 $\Sigma$ 中某个 $a$。
- $\varepsilon$。
- $\emptyset$。
- ( $R_{1} \cup R_{2}$ ),其中 $R_{1}$ 和 $R_{2}$ 是正则表达式。
- $\left(R_{1} \circ R_{2}\right)$,其中 $R_{1}$ 和 $R_{2}$ 是正则表达式。
- $\left(R_{1}^{*}\right)$,其中 $R_{1}$ 是正则表达式。
在项目 1 和 2 中,正则表达式 $a$ 和 $\varepsilon$ 分别表示语言 $\{a\}$ 和 $\{\varepsilon\}$。在项目 3 中,正则表达式 $\emptyset$ 表示空语言。在项目 4、5 和 6 中,表达式表示通过对语言 $R_{1}$ 和 $R_{2}$ 执行并或连接,或对语言 $R_{1}$ 执行星号运算所获得的语言。
不要混淆正则表达式 $\varepsilon$ 和 $\emptyset$。表达式 $\varepsilon$ 表示包含一个单一字符串(即空字符串)的语言,而 $\emptyset$ 表示不包含任何字符串的语言。
表面上,我们似乎有陷入用自身来定义正则表达式概念的危险。如果属实,我们将有一个循环定义,这是无效的。然而,$R_{1}$ 和 $R_{2}$ 总是小于 $R$。因此,我们实际上是根据较小的正则表达式来定义正则表达式,从而避免了循环性。这种类型的定义被称为归纳定义。
表达式中的括号可以省略。如果省略,求值将按照优先级顺序进行:星号运算,然后是连接,最后是并。
为方便起见,我们将 $R^{+}$简写为 $R R^{*}$。换句话说,尽管 $R^{*}$ 包含来自 $R$ 的 0 次或更多次连接字符串的所有字符串,但语言 $R^{+}$包含来自 $R$ 的 1 次或更多次连接字符串的所有字符串。因此 $R^{+} \cup \varepsilon=R^{*}$。此外,我们将 $R^{k}$ 简写为 $k$ 个 $R$ 相互连接。
当我们想区分正则表达式 $R$ 和它所描述的语言时,我们用 $L(R)$ 来表示 $R$ 的语言。
示例 1.53
在以下实例中,我们假设字母表 $\Sigma$ 为 $\{0,1\}$。
- $0^{*} 10^{*}=\{w \mid w$ 包含一个 1$\}$。
- $\Sigma^{*} 1 \Sigma^{*}=\{w \mid w$ 至少包含一个 1$\}$。
- $\Sigma^{*} 001 \Sigma^{*}=\{w \mid w$ 包含字符串 001 作为子串$\}$。
- $1^{*}\left(01^{+}\right)^{*}=\{w \mid w$ 中的每个 0 后都至少跟一个 1$\}$。
- $(\Sigma \Sigma)^{*}=\{w \mid w$ 是偶数长度的字符串$\} .^{5}$
- $(\Sigma \Sigma \Sigma)^{*}=\{w \mid w$ 的长度是 3 的倍数$\}$。
- $01 \cup 10=\{01,10\}$。
- $0 \Sigma^{*} 0 \cup 1 \Sigma^{*} 1 \cup 0 \cup 1=\{w \mid w$ 以相同符号开始和结束$\}$。
- $(0 \cup \varepsilon) 1^{*}=01^{*} \cup 1^{*}$。
表达式 $0 \cup \varepsilon$ 描述的是语言 $\{0, \varepsilon\}$,因此连接运算在 $1^{*}$ 中的每个字符串之前添加 0 或 $\varepsilon$。
- $(0 \cup \varepsilon)(1 \cup \varepsilon)=\{\varepsilon, 0,1,01\}$。
- $1^{*} \emptyset=\emptyset$。
将空集与任何集合连接都会产生空集。
- $\emptyset^{*}=\{\varepsilon\}$。
星号运算将语言中的任意数量的字符串组合起来,得到结果中的一个字符串。如果语言是空的,星号运算可以组合 0 个字符串,只产生空字符串。
[^3]如果我们让 $R$ 是任意正则表达式,我们有以下恒等式。它们是检验你是否理解定义的好方法。
$R \cup \emptyset=R$。
将空语言添加到任何其他语言都不会改变它。
$R \circ \varepsilon=R$。
将空字符串连接到任何字符串都不会改变它。
然而,在前面的恒等式中交换 $\emptyset$ 和 $\varepsilon$ 可能会导致等式失效。
$R \cup \varepsilon$ 可能不等于 $R$。
例如,如果 $R=0$,则 $L(R)=\{0\}$ 但 $L(R \cup \varepsilon)=\{0, \varepsilon\}$。
$R \circ \emptyset$ 可能不等于 $R$。
例如,如果 $R=0$,则 $L(R)=\{0\}$ 但 $L(R \circ \emptyset)=\emptyset$。
正则表达式是编程语言编译器设计中的有用工具。编程语言中的基本对象,称为词法单元 (tokens),例如变量名和常量,可以用正则表达式描述。例如,一个可能包含小数部分和/或符号的数值常量可以用语言
的成员来描述,其中 $D=\{0,1,2,3,4,5,6,7,8,9\}$ 是十进制数字的字母表。生成的字符串示例有:$72,3.14159,+7$. 和 $-.01$。
一旦用正则表达式根据其词法单元描述了编程语言的语法,自动化系统就可以生成词法分析器 (lexical analyzer),它是编译器中初步处理输入程序的组成部分。
与有限自动机的等价性
正则表达式和有限自动机在描述能力上是等价的。这一事实令人惊讶,因为有限自动机和正则表达式表面上看起来截然不同。然而,任何正则表达式都可以转换为识别其所描述语言的有限自动机,反之亦然。回想一下,正则语言是指被某个有限自动机识别的语言。
定理 1.54
一个语言是正则语言当且仅当某个正则表达式描述它。
这个定理有两个方向。我们分别将每个方向陈述并证明为一个独立的引理。
引理 1.55
如果一个语言被正则表达式描述,那么它是正则语言。
证明思路 假设我们有一个描述某个语言 $A$ 的正则表达式 $R$。我们展示如何将 $R$ 转换为一个识别 $A$ 的 NFA (非确定型有限自动机)。根据推论 1.40,如果一个 NFA 识别 $A$,那么 $A$ 是正则语言。
证明 让我们将 $R$ 转换为一个 NFA $N$。我们考虑正则表达式形式化定义中的六种情况。
- $R=a$,对于字母表 $\Sigma$ 中的某个 $a$。那么 $L(R)=\{a\}$,以下 NFA 识别 $L(R)$。
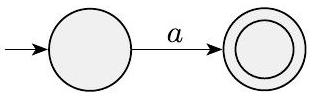
请注意,这台机器符合 NFA 的定义,但不符合 DFA (确定型有限自动机) 的定义,因为它对于每个可能的输入符号,有些状态没有离开的箭头。当然,我们可以在这里展示一个等价的 DFA;但我们现在只需要 NFA,而且它更容易描述。
形式上,$N=\left(\left\{q_{1}, q_{2}\right\}, \Sigma, \delta, q_{1},\left\{q_{2}\right\}\right)$,其中我们通过说明 $\delta\left(q_{1}, a\right)=\left\{q_{2}\right\}$ 以及对于 $r \neq q_{1}$ 或 $b \neq a$ 时 $\delta(r, b)=\emptyset$ 来描述 $\delta$。
- $R=\varepsilon$。那么 $L(R)=\{\varepsilon\}$,以下 NFA 识别 $L(R)$。
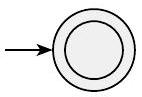
形式上,$N=\left(\left\{q_{1}\right\}, \Sigma, \delta, q_{1},\left\{q_{1}\right\}\right)$,其中对于任何 $r$ 和 $b$,$\delta(r, b)=\emptyset$。
- $R=\emptyset$。那么 $L(R)=\emptyset$,以下 NFA 识别 $L(R)$。
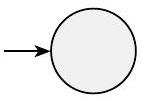
形式上,$N=(\{q\}, \Sigma, \delta, q, \emptyset)$,其中对于任何 $r$ 和 $b$,$\delta(r, b)=\emptyset$。
- $R=R_{1} \cup R_{2}$。
- $R=R_{1} \circ R_{2}$。
- $R=R_{1}^{*}$。
对于最后三种情况,我们使用正则语言类在正则运算下封闭的证明中给出的构造。换句话说,我们从 $R_{1}$ 和 $R_{2}$(或在情况 6 中仅 $R_{1}$)的 NFA 以及适当的封闭构造来构建 $R$ 的 NFA。
这结束了定理 1.54 证明的第一部分,给出了“当且仅当”条件的较容易方向。在继续讨论另一个方向之前,我们先通过一些示例来了解如何使用此过程将正则表达式转换为 NFA。
示例 1.56
我们分阶段将正则表达式 $(\mathrm{ab} \cup \mathrm{a})^{*}$ 转换为 NFA。我们从最小的子表达式开始构建,逐步到较大的子表达式,直到我们拥有原始表达式的 NFA,如下图所示。请注意,此过程通常不会给出状态最少的 NFA。在此示例中,该过程给出了一个有八个状态的 NFA,但最小的等价 NFA 只有两个状态。你能找到它吗?
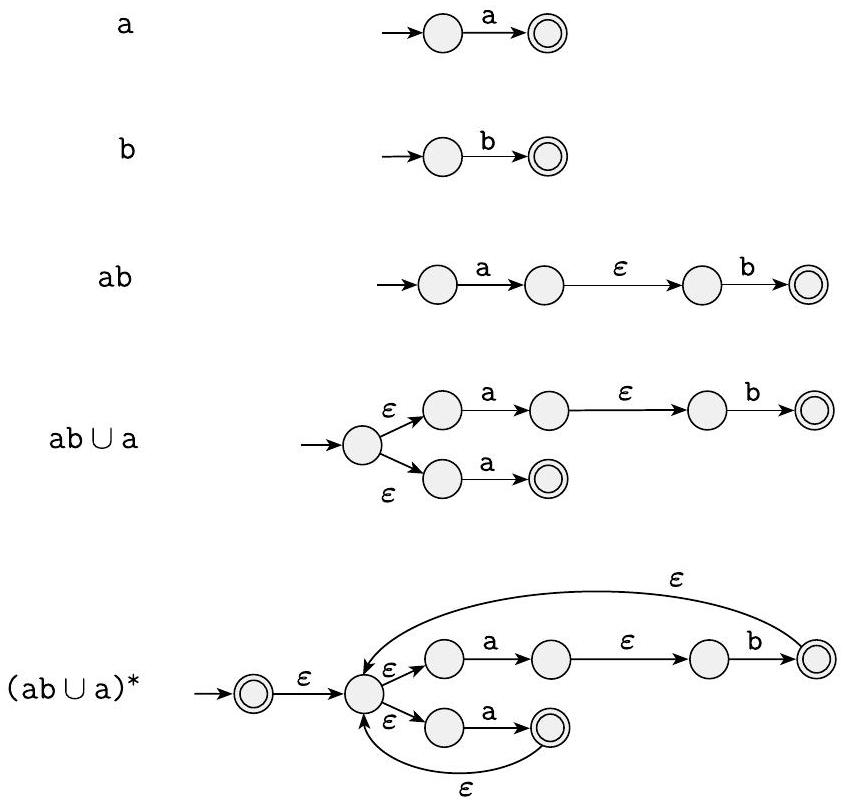
图 1.57
从正则表达式 $(\mathrm{ab} \cup \mathrm{a})^{*}$ 构建 NFA
示例 1.58
在图 1.59 中,我们将正则表达式 $(\mathrm{a} \cup \mathrm{b})^{*} \mathrm{aba}$ 转换为 NFA。其中一些次要步骤未显示。
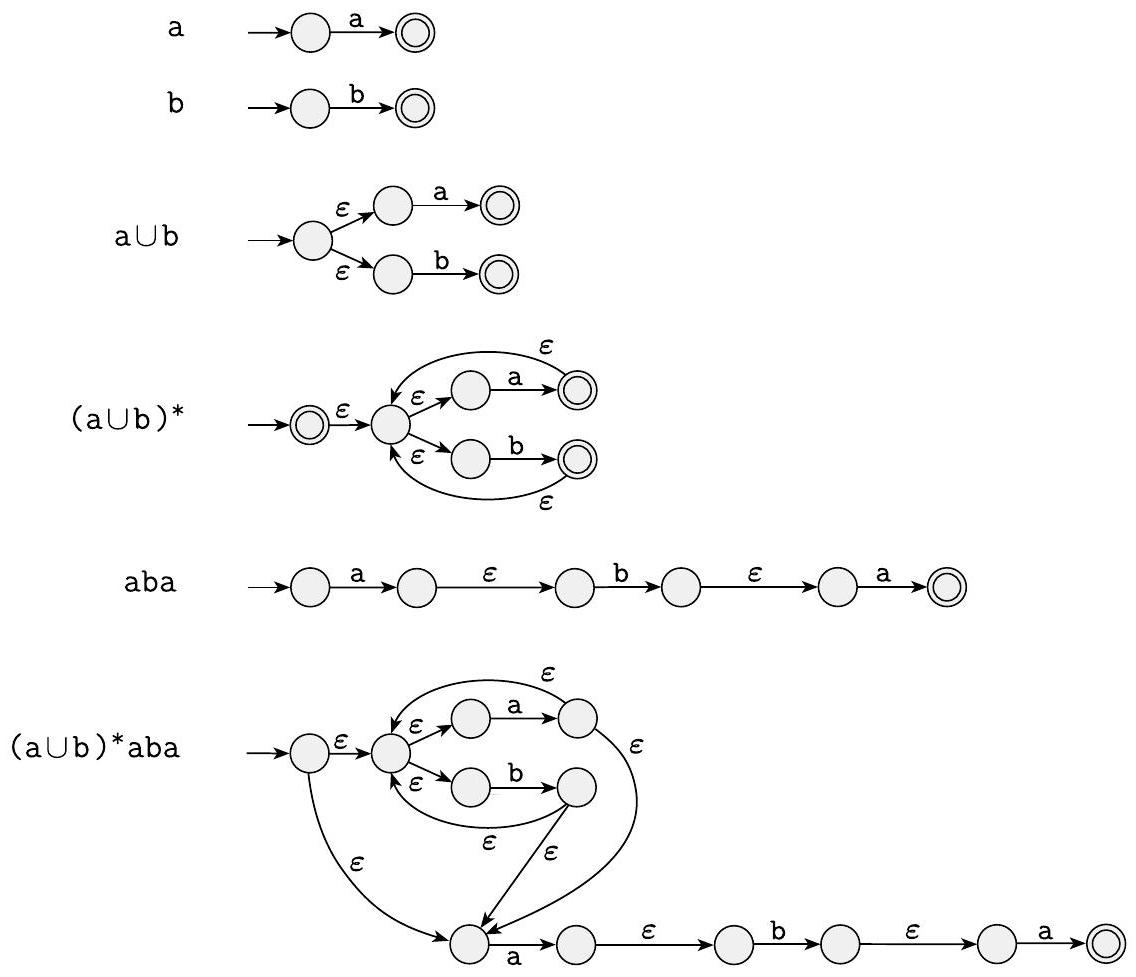
图 1.59
从正则表达式 $(\mathrm{a} \cup \mathrm{b})^{*} \mathrm{aba}$ 构建 NFA $\square$
现在让我们转向定理 1.54 证明的另一个方向。
引理 1.60
如果一个语言是正则语言,那么它被正则表达式描述。
证明思路 我们需要证明如果一个语言 $A$ 是正则语言,那么一个正则表达式描述它。因为 $A$ 是正则语言,它被一个 DFA 接受。我们描述一个将 DFA 转换为等价正则表达式的过程。
我们将此过程分为两部分,使用一种新型的有限自动机,称为广义非确定型有限自动机 (GNFA)。首先,我们展示如何将 DFA 转换为 GNFA,然后将 GNFA 转换为正则表达式。
广义非确定型有限自动机只是非确定型有限自动机,其中转移箭头可以有任何正则表达式作为标签,而不是仅仅是字母表的成员或 $\varepsilon$。GNFA 从输入中读取符号块,不一定像普通 NFA 那样一次只读取一个符号。GNFA 通过读取输入中的符号块,沿着连接两个状态的转移箭头移动,这些符号块本身构成了一个由该箭头上的正则表达式描述的字符串。GNFA 是非确定型的,因此可能有几种不同的方法来处理相同的输入字符串。如果其处理能够使 GNFA 在输入结束时处于接受状态,则它接受其输入。下图展示了一个 GNFA 的示例。
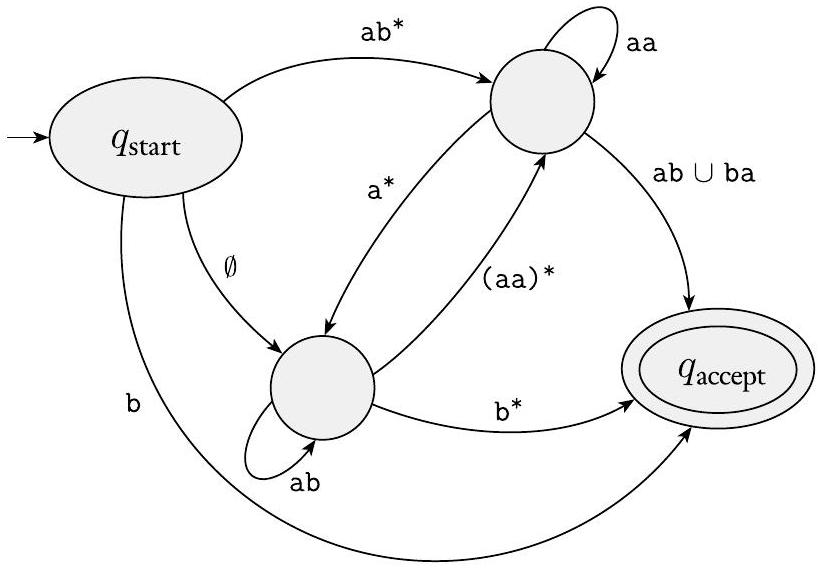
图 1.61
一个广义非确定型有限自动机
为方便起见,我们要求 GNFA 始终具有满足以下条件的特殊形式。
- 起始状态有指向所有其他状态的转移箭头,但没有从任何其他状态进入的箭头。
- 只有一个接受状态,它有从所有其他状态进入的箭头,但没有指向任何其他状态的箭头。此外,接受状态与起始状态不同。
- 除了起始状态和接受状态外,每个状态到每个其他状态以及每个状态到自身都有一条箭头。
我们可以很容易地将 DFA 转换为特殊形式的 GNFA。我们只需添加一个带 $\varepsilon$ 箭头的新起始状态到旧的起始状态,以及一个带 $\varepsilon$ 箭头的新接受状态从旧的接受状态。如果任何箭头有多个标签(或者在两个状态之间有多个指向同一方向的箭头),我们用一个标签是先前标签的并的单一箭头替换每个箭头。最后,我们在没有箭头的状态之间添加标记为 $\emptyset$ 的箭头。这最后一步不会改变所识别的语言,因为标记为 $\emptyset$ 的转移永远不会被使用。从现在开始,我们假设所有 GNFA 都处于特殊形式。
现在我们展示如何将 GNFA 转换为正则表达式。假设 GNFA 有 $k$ 个状态。那么,因为 GNFA 必须有一个起始状态和一个接受状态,并且它们必须彼此不同,我们知道 $k \geq 2$。如果 $k>2$,我们构造一个具有 $k-1$ 个状态的等价 GNFA。此步骤可以在新的 GNFA 上重复,直到它减少到两个状态。如果 $k=2$,GNFA 有一个从起始状态到接受状态的单一箭头。此箭头的标签就是等价的正则表达式。例如,将一个三状态 DFA 转换为等价正则表达式的阶段如下图所示。
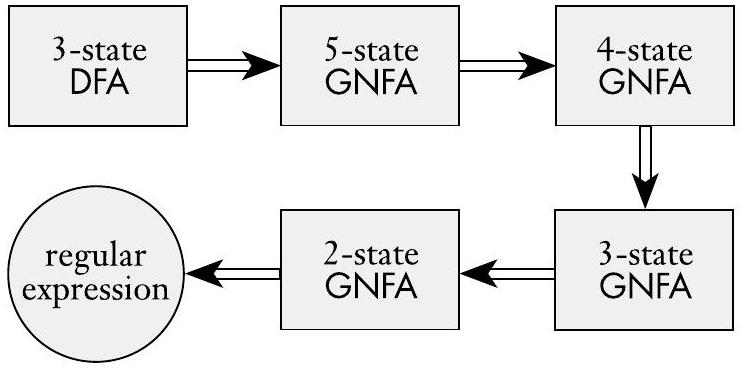
图 1.62
将 DFA 转换为正则表达式的典型阶段
关键步骤是当 $k>2$ 时,构造一个状态更少一个的等价 GNFA。我们通过选择一个状态,将其从机器中移除,并修复其余部分,以便仍然识别相同的语言来实现。任何状态都可以,只要它不是起始状态或接受状态。我们保证这样的状态将存在,因为 $k>2$。我们称被移除的状态为 $q_{\text {rip}}$。
移除 $q_{\text {rip}}$ 后,我们通过修改标记每个剩余箭头的正则表达式来修复机器。新的标签弥补了 $q_{\text {rip}}$ 的缺失,通过添加回丢失的计算。从状态 $q_{i}$ 到状态 $q_{j}$ 的新标签是一个正则表达式,它描述了所有可以直接或通过 $q_{\text {rip}}$ 将机器从 $q_{i}$ 带到 $q_{j}$ 的字符串。我们将在图 1.63 中说明这种方法。
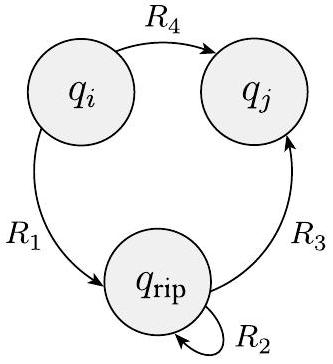
之前
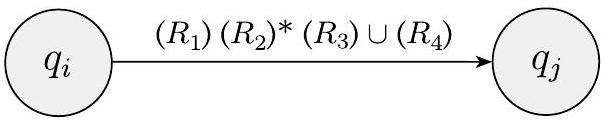
之后
图 1.63
构造一个状态更少一个的等价 GNFA
在旧机器中,如果
- $q_{i}$ 通过标记为 $R_{1}$ 的箭头到 $q_{\mathrm{rip}}$,
- $q_{\text {rip }}$ 通过标记为 $R_{2}$ 的箭头到自身,
- $q_{\text {rip }}$ 通过标记为 $R_{3}$ 的箭头到 $q_{j}$,并且
- $q_{i}$ 通过标记为 $R_{4}$ 的箭头到 $q_{j}$,
那么在新机器中,从 $q_{i}$ 到 $q_{j}$ 的箭头将获得标签
我们为从任何状态 $q_{i}$ 到任何状态 $q_{j}$ 的每个箭头进行此更改,包括 $q_{i}=q_{j}$ 的情况。新机器识别原始语言。
证明 现在我们正式执行这个想法。首先,为了方便证明,我们正式定义引入的新型自动机。GNFA 类似于非确定型有限自动机,除了转移函数,其形式为
符号 $\mathcal{R}$ 是字母表 $\Sigma$ 上所有正则表达式的集合,$q_{\text {start }}$ 和 $q_{\text {accept }}$ 是起始状态和接受状态。如果 $\delta\left(q_{i}, q_{j}\right)=R$,则从状态 $q_{i}$ 到状态 $q_{j}$ 的箭头以正则表达式 $R$ 作为标签。转移函数的域是 $\left(Q-\left\{q_{\text {accept }}\right\}\right) \times\left(Q-\left\{q_{\text {start }}\right\}\right)$,因为除了没有从 $q_{\text {accept }}$ 出发或指向 $q_{\text {start }}$ 的箭头外,每个状态都连接到每个其他状态。
定义 1.64
广义非确定型有限自动机是一个 5 元组 $\left(Q, \Sigma, \delta, q_{\text {start }}, q_{\text {accept }}\right)$,其中
- $Q$ 是有限状态集,
- $\Sigma$ 是输入字母表,
- $\delta:\left(Q-\left\{q_{\text {accept }}\right\}\right) \times\left(Q-\left\{q_{\text {start }}\right\}\right) \longrightarrow \mathcal{R}$ 是转移函数,
- $q_{\text {start }}$ 是起始状态,
- $q_{\text {accept }}$ 是接受状态。
如果 $w=w_{1} w_{2} \cdots w_{k}$,其中每个 $w_{i}$ 都在 $\Sigma^{*}$ 中,并且存在状态序列 $q_{0}, q_{1}, \ldots, q_{k}$ 使得
- $q_{0}=q_{\text {start }}$ 是起始状态,
- $q_{k}=q_{\text {accept }}$ 是接受状态,并且
- 对于每个 $i$,我们有 $w_{i} \in L\left(R_{i}\right)$,其中 $R_{i}=\delta\left(q_{i-1}, q_{i}\right)$;换句话说,$R_{i}$ 是从 $q_{i-1}$ 到 $q_{i}$ 的箭头上的表达式,则 GNFA 接受 $\Sigma^{*}$ 中的字符串 $w$。
回到引理 1.60 的证明,我们设 $M$ 是语言 $A$ 的 DFA。然后我们通过添加新起始状态和新接受状态以及必要的额外转移箭头将 $M$ 转换为 GNFA $G$。我们使用过程 CONVERT( $G$ ),它接受一个 GNFA 并返回一个等价的正则表达式。此过程使用递归,这意味着它会调用自身。通过该过程仅在处理状态少一个的 GNFA 时调用自身来避免无限循环。GNFA 具有两个状态的情况无需递归处理。
Convert $(G)$:
- 设 $k$ 为 $G$ 的状态数。
- 如果 $k=2$,则 $G$ 必须由一个起始状态、一个接受状态和一个连接它们的单个箭头组成,该箭头标记为正则表达式 $R$。
返回表达式 $R$。
- 如果 $k>2$,我们选择任何一个不同于 $q_{\text {start }}$ 和 $q_{\text {accept }}$ 的状态 $q_{\text {rip }} \in Q$,并设 $G^{\prime}$ 为 GNFA ( $\left.Q^{\prime}, \Sigma, \delta^{\prime}, q_{\text {start }}, q_{\text {accept }}\right)$,其中
并且对于任何 $q_{i} \in Q^{\prime}-\left\{q_{\text {accept }}\right\}$ 和任何 $q_{j} \in Q^{\prime}-\left\{q_{\text {start }}\right\}$,设
其中 $R_{1}=\delta\left(q_{i}, q_{\text {rip }}\right)$,$R_{2}=\delta\left(q_{\text {rip }}, q_{\text {rip }}\right)$,$R_{3}=\delta\left(q_{\text {rip }}, q_{j}\right)$,和 $R_{4}=\delta\left(q_{i}, q_{j}\right)$。
- 计算 Convert $\left(G^{\prime}\right)$ 并返回此值。
接下来我们证明 CONVERT 返回一个正确的值。
断言 1.65
对于任何 GNFA $G$,Convert $(G)$ 等价于 $G$。
我们通过对 $k$(GNFA 的状态数)进行归纳来证明此断言。
基础情况:证明断言对于 $k=2$ 个状态成立。如果 $G$ 只有两个状态,它只能有一个从起始状态到接受状态的单个箭头。此箭头上的正则表达式标签描述了所有允许 $G$ 到达接受状态的字符串。因此,此表达式等价于 $G$。
归纳步骤:假设断言对于 $k-1$ 个状态成立,并使用此假设来证明断言对于 $k$ 个状态成立。首先我们证明 $G$ 和 $G^{\prime}$ 识别相同的语言。假设 $G$ 接受输入 $w$。那么在计算的接受分支中,$G$ 进入一个状态序列:
如果其中没有一个是移除的状态 $q_{\text {rip }}$,则显然 $G^{\prime}$ 也接受 $w$。原因是标记 $G^{\prime}$ 箭头的每个新正则表达式都包含旧正则表达式作为并的一部分。
如果 $q_{\text {rip }}$ 确实出现,则移除每个连续的 $q_{\text {rip }}$ 状态的运行会形成 $G^{\prime}$ 的接受计算。限定运行的状态 $q_{i}$ 和 $q_{j}$ 在它们之间的箭头上有一个新的正则表达式,它描述了所有通过 $G$ 上的 $q_{\text {rip }}$ 将 $q_{i}$ 带到 $q_{j}$ 的字符串。因此 $G^{\prime}$ 接受 $w$。
反之,假设 $G^{\prime}$ 接受输入 $w$。由于 $G^{\prime}$ 中任何两个状态 $q_{i}$ 和 $q_{j}$ 之间的每个箭头都描述了在 $G$ 中直接或通过 $q_{\text {rip }}$ 将 $q_{i}$ 带到 $q_{j}$ 的字符串集合,因此 $G$ 也必须接受 $w$。因此 $G$ 和 $G^{\prime}$ 是等价的。
归纳假设表明,当算法递归调用自身处理输入 $G^{\prime}$ 时,结果是一个等价于 $G^{\prime}$ 的正则表达式,因为 $G^{\prime}$ 具有 $k-1$ 个状态。因此,此正则表达式也等价于 $G$,并且算法被证明是正确的。
这结束了断言 1.65、引理 1.60 和定理 1.54 的证明。
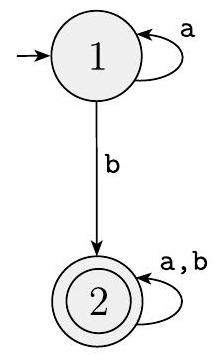
示例 1.66
在此示例中,我们使用上述算法将 DFA 转换为正则表达式。我们从图 1.67(a) 中的两状态 DFA 开始。
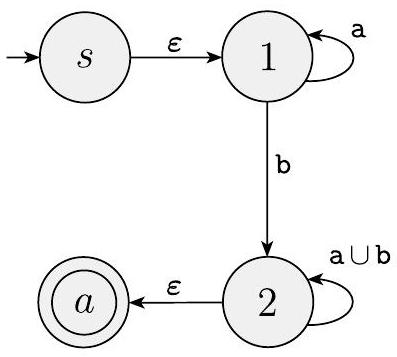
在图 1.67(b) 中,我们通过添加一个新起始状态和一个新接受状态(为了方便绘制,分别称为 $s$ 和 $a$,而不是 $q_{\text {start }}$ 和 $q_{\text {accept }}$)来制作一个四状态 GNFA。为了避免图形混乱,我们不绘制标记为 $\emptyset$ 的箭头,即使它们存在。请注意,我们将 DFA 上状态 2 的自循环上的标签 $\mathrm{a}, \mathrm{b}$ 替换为 GNFA 上相应位置的标签 $\mathrm{a} \cup \mathrm{b}$。我们这样做是因为 DFA 的标签表示两个转移,一个用于 a,另一个用于 b,而 GNFA 可能只有一个从 2 到自身的转移。
在图 1.67(c) 中,我们移除状态 2 并更新剩余的箭头标签。在这种情况下,唯一改变的标签是从 1 到 $a$ 的标签。在 (b) 部分中它是 $\emptyset$,但在 (c) 部分中它是 $\mathrm{b}(\mathrm{a} \cup \mathrm{b})^{*}$。我们通过遵循 CONVERT 过程的步骤 3 获得此结果。状态 $q_{i}$ 是状态 1,状态 $q_{j}$ 是 $a$,并且 $q_{\text {rip }}$ 是 2,因此 $R_{1}=\mathrm{b}$,$R_{2}=\mathrm{a} \cup \mathrm{b}$,$R_{3}=\varepsilon$,和 $R_{4}=\emptyset$。因此,从 1 到 $a$ 的箭头上的新标签是 $(\mathrm{b})(\mathrm{a} \cup \mathrm{b})^{*}(\varepsilon) \cup \emptyset$。我们将此正则表达式简化为 $\mathrm{b}(\mathrm{a} \cup \mathrm{b})^{*}$。
在图 1.67(d) 中,我们从 (c) 部分移除状态 1 并遵循相同的过程。由于只剩下起始状态和接受状态,连接它们的箭头上的标签就是等价于原始 DFA 的正则表达式。
(a)
(b)
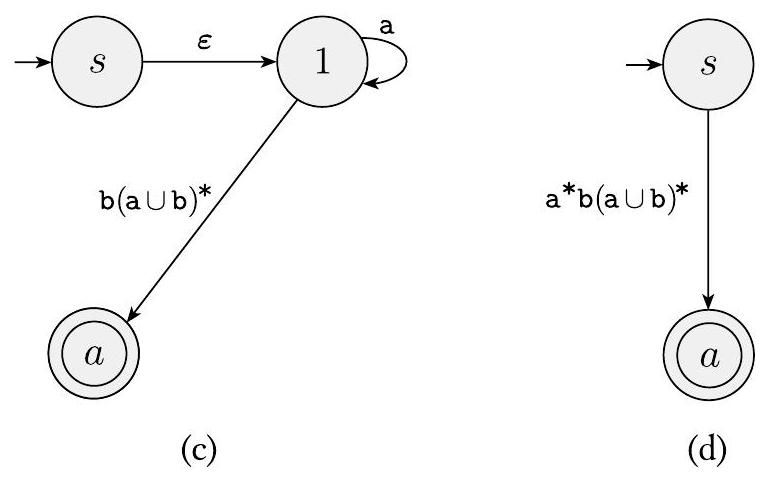
图 1.67
将两状态 DFA 转换为等价正则表达式 $\square$
示例 1.68
在此示例中,我们从一个三状态 DFA 开始。转换步骤如下图所示。
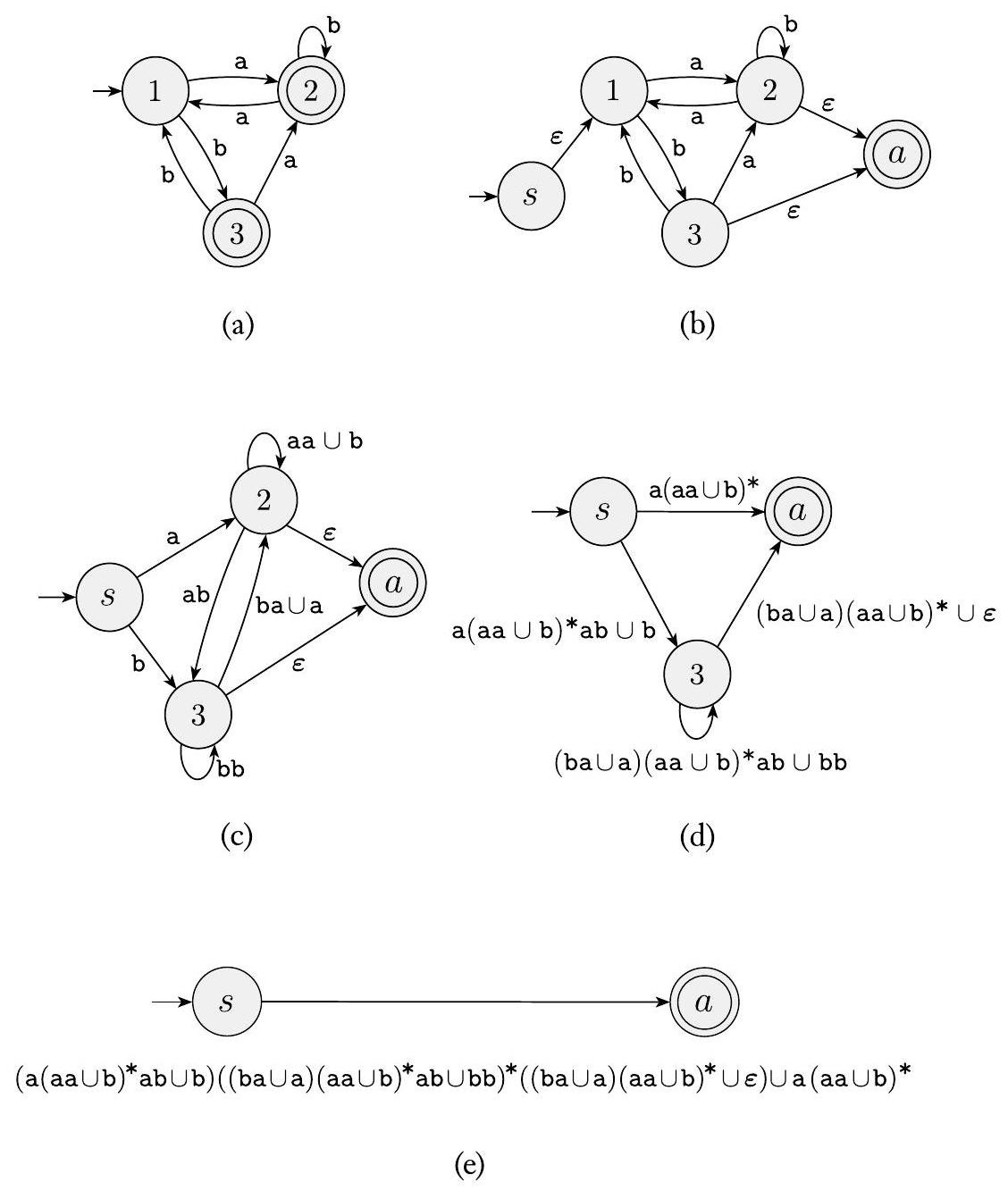
图 1.69
将三状态 DFA 转换为等价正则表达式 $\square$