11. 4.2 不可判定性 (UNDECIDABILITY)
📜 [原文1]
在本节中,我们将证明计算理论中一个哲学上最重要的定理:存在一个特定的问题是算法不可解的。计算机看起来如此强大,你可能会认为所有问题最终都将迎刃而解。这里提出的定理表明计算机在根本上是受限制的。
这段话是本节的开篇,旨在引出“不可判定性”这一核心概念,并强调其在计算理论中的重要地位。
- “在本节中,我们将证明计算理论中一个哲学上最重要的定理”:
- 计算理论 (Computation Theory): 这是计算机科学的一个理论分支,研究计算的模型、算法的效率以及问题的可解性。它试图回答一些关于计算的根本问题,比如“什么问题是可以用计算机解决的?”
- 哲学上最重要: 这句话强调了该定理的深远影响。它不仅仅是一个技术性的结论,更改变了我们对计算、计算机乃至宇宙极限的认知。它告诉我们,并非所有清晰定义的问题都能被机械地解决,这触及了知识和能力的边界。
- 定理 (Theorem): 在数学和逻辑学中,定理是一个已被证明为真的陈述。这意味着我们将要看到一个严谨的、无懈可击的逻辑论证。
- “存在一个特定的问题是算法不可解的”:
- 问题 (Problem): 在计算理论中,一个问题通常被形式化地定义为一个关于输入和期望输出的关系。例如,“给定一个数,判断它是否是素数”就是一个问题。
- 算法 (Algorithm): 算法是一系列明确的、有限的指令,用于解决一个特定的问题或执行一个计算。你可以把它想象成一份精确的食谱,只要按部就班,总能得到结果。
- 不可解的 (Unsolvable) / 不可判定的 (Undecidable): 这两个词在这里基本是同义词。“算法不可解”意味着不存在任何一个算法,能够在有限时间内对该问题的所有可能输入都给出正确的“是”或“否”的答案。
- “计算机看起来如此强大,你可能会认为所有问题最终都将迎刃而解”:
- 这句话是在描述一种普遍存在的直觉或误解。随着科技的发展,计算机的处理能力越来越强,解决了无数复杂的问题,从天气预报到基因测序。这很容易让人产生一种信念,即只要有足够的时间和计算资源,任何问题都能被计算机解决。
- “这里提出的定理表明计算机在根本上是受限制的”:
- 这是本段的点睛之笔。它直接反驳了前一句话中的乐观想法。这种限制不是因为计算机不够快,或者内存不够大,而是一种根本性 (fundamental)的、逻辑上的限制。就像你无法画一个“圆的方块”一样,这种限制是内在于计算这个概念本身的。
- 示例1 (可解问题):
- 问题: 给定一个正整数 $n$,判断 $n$ 是否为偶数。
- 算法:
- 接收输入 $n$。
- 计算 $n$ 除以 2 的余数。
- 如果余数为 0,输出“是”。
- 如果余数为 1,输出“否”。
- 这个算法对任何输入的正整数都能在有限步骤内给出正确答案,所以“判断一个数是否为偶数”是可解的 (solvable)。
- 示例2 (即将要讨论的不可解问题):
- 问题: 给定任意一个计算机程序 $P$ 和它的一个输入 $I$,判断程序 $P$ 在输入 $I$ 上是否会最终停止运行(而不是无限循环)。这就是著名的“停机问题”。
- 本节将证明: 不存在一个通用的算法能够解决所有情况下的停机问题。你无法写一个程序,它能分析任何其他的程序和输入,并总是正确地告诉你那个程序会不会死循环。这就是一个“算法不可解”的例子。
- 易错点: “不可解”不等于“目前还没解决”。“目前还没解决”可能只是因为问题太难,或者我们还没找到巧妙的算法(比如曾经的“费马大定理”)。而“不可解”是已经通过数学证明,永远不可能存在解决它的通用算法。
- 边界情况: 这里的“计算机”指的是图灵机或任何与之等价的计算模型。这个结论适用于我们今天使用的所有计算机,也包括未来可能发明的任何遵循同样计算原理的机器。它不排除某些特定类型的、非图灵完备的计算设备能解决某些特定问题。
本段作为引言,宣告了一个颠覆性的结论:计算机的能力是有限的。它通过对比“计算机无所不能”的普遍印象,引出了即将被证明的“存在算法不可解问题”的定理,并强调了这一定理在哲学和计算理论上的核心重要性。
本段的目的是设置舞台,激发读者的好奇心,并建立对“不可判定性”概念重要性的初步认识。它通过制造一种认知上的冲突(计算机很强大 vs 计算机有根本限制),为后续的严格证明铺平了道路,让读者明白我们不是在讨论一个无关紧要的理论细节,而是一个关于计算本质的核心事实。
想象一个万能的“问题回答机”。你给它任何一个形式清晰的问题,它都能给你一个明确的“是”或“否”的答案。本段告诉我们,这样的机器在逻辑上是不可能存在的。必然有一些问题,它无法回答。
想象你有一把“万能钥匙”,你认为它可以打开世界上所有的锁。你试了很多很多锁,它都成功打开了,这让你更加相信它是万能的。但突然,有人拿来一篇严谨的数学证明,告诉你:“从逻辑上可以证明,必然存在至少一把锁,是你的这把‘万能钥匙’永远打不开的。” 这个证明本身并没有指出是哪一把锁,但它确定无疑地告诉你,你的钥匙的能力是有边界的。本节要做的,就是展示这篇“数学证明”。
📜 [原文2]
什么样的问题是计算机不可解的?它们是深奥的,只存在于理论家的思想中吗?不是!即使是一些人们想要解决的普通问题,也被证明是计算上不可解的。
这一段通过自问自答的方式,进一步阐述了“不可解问题”的现实意义,消除读者可能产生的“这只是纯理论,与我无关”的想法。
- “什么样的问题是计算机不可解的?”:
- 这是一个承上启下的设问。前一段告诉我们存在这样的问题,现在自然要问:它们到底长什么样?
- “它们是深奥的,只存在于理论家的思想中吗?”:
- 深奥的 (esoteric): 指的是那些非常专业、只有少数专家才能理解的概念。
- 理论家的思想中: 暗示这些问题可能只是数学家或逻辑学家为了理论构建而发明的抽象游戏,与现实世界没有联系。
- 这个问题是在主动回应读者的潜在疑虑。很多人会觉得,既然日常生活中计算机什么都能做,那么所谓的“不可解问题”肯定是一些非常奇怪、非常不切实际的“脑筋急转弯”。
- “不是!”:
- 一个斩钉截铁的否定。直接打破了前面的猜测。
- “即使是一些人们想要解决的普通问题,也被证明是计算上不可解的。”:
- 普通问题 (ordinary problems): 这里的“普通”是相对于“深奥”而言的。它指的是那些在软件工程、编程、人工智能等领域中实际出现,并且工程师们非常希望能够解决的问题。
- 被证明是计算上不可解的: 再次强调,“不可解”是一个经过严格数学证明的确定性结论。
- 这句话的重点是,不可解性并非阳春白雪,而是下里巴人。它就在我们日常的编程和软件开发工作中潜伏着。
- 示例1 (软件验证问题 - 本节即将提到):
- 问题: 给定一个C++程序和一个功能规格说明文档(比如,"这个函数应该对任意输入的整数数组进行升序排序")。写一个“验证程序”,能自动判断这个C++程序是否完全符合规格说明。
- 现实意义: 这是软件测试和质量保证领域梦寐以求的工具。如果存在,就可以彻底消灭软件Bug。
- 结论: 这个问题是不可解的。不存在一个通用的程序可以验证所有程序的正确性。
- 示例2 (病毒检测问题):
- 问题: 给定一段可执行代码,判断它是否是一个计算机病毒(即,它是否会修改其他程序文件)。
- 现实意义: 这是杀毒软件的核心功能。
- 结论: 在其最通用的形式下,这个问题是不可解的。这是因为判断一段代码是否有“恶意”行为,本质上是在预测它的行为,这与停机问题紧密相关。任何杀毒软件都必然存在“漏报”(无法识别新病毒)或“误报”(将正常程序判断为病毒)的可能性,不可能做到100%完美。
- 误解: “杀毒软件不是存在吗?为什么说病毒检测不可解?”
- 澄清: 现实中的杀毒软件并没有解决这个问题的“通用形式”。它们使用的是“启发式”方法和“特征码”匹配。
- 特征码匹配: 杀毒软件有一个已知病毒的“黑名单”。它检查你的文件是否与名单上的某个病毒的片段(特征码)匹配。这种方法无法检测到任何新病毒。
- 启发式方法: 杀毒软件会分析程序的行为模式,比如“它是否试图修改系统文件?”“它是否在网络上发送奇怪的数据?”。如果行为可疑,就报警。这是一种基于经验的猜测,可能会误判,也可能被聪明的病毒绕过。
- 因此,杀毒软件是对“不可解问题”的一个不完美的、实用主义的解决方案,它永远无法做到绝对的精确。
本段的核心作用是“接地气”。它通过设问和坚决的否定,将“不可判定性”这个抽象的理论概念与软件验证、病毒检测等实际的、人们迫切希望解决的“普通问题”联系起来,强调了学习和理解这一概念的现实必要性。
本段旨在消除理论与实践之间的隔阂。通过指出不可解问题的普遍性和实用性,它激励读者认真对待接下来的理论证明,因为这些证明的结论将直接影响我们对软件工程、网络安全等实际领域能力边界的理解。
想象医生看病。有些病,比如普通感冒,医生有一套明确的诊断和治疗流程(算法),几乎总能治好(可解)。但有些问题,比如预测一个人在未来十年内是否会患上某种罕见的遗传病,可能不存在一个100%准确的预测方法(不可解)。医生能做的,是基于现有的知识进行风险评估(启发式方法),但这不等于解决了这个根本性的预测问题。
你是一名城市规划师,你想设计一个完美的交通系统,保证在任何时间、任何路况下(比如突然的事故、节假日的人潮),整个城市的交通都绝对不会发生任何拥堵。本段告诉你:对不起,这样的“完美交通系统设计算法”是不存在的。交通系统过于复杂,其行为在根本上是不可完全预测和控制的,你总会遇到意料之外的情况导致堵车。你只能设计出“比较好”的系统,但无法设计出“绝对完美”的系统。
📜 [原文3]
在一种不可解的问题中,你得到一个计算机程序和一个关于该程序应该做什么的精确规范(例如,对数字列表进行排序)。你需要验证程序是否按规范执行(即,它是正确的)。由于程序和规范都是数学上精确的对象,你希望通过将这些对象输入到一台经过适当编程的计算机中来自动化验证过程。然而,你会感到失望。软件验证的通用问题是计算机不可解的。
这一段详细阐述了前文提到的“普通问题”之一——软件验证 (Software Verification),并明确指出它的通用形式是不可解的。
- “在一种不可解的问题中,你得到一个计算机程序和一个关于该程序应该做什么的精确规范”:
- 这里开始描述一个具体场景。
- 计算机程序 (Computer Program): 一段用某种编程语言(如Python, Java, C++)写成的代码。
- 精确规范 (Precise Specification): 对程序预期行为的无歧义描述。这不仅仅是“这个程序要好用”这样的模糊描述,而是数学或逻辑上严格的定义。
- “(例如,对数字列表进行排序)”: 这是一个规范的具体例子。更精确的规范可能是:“对于任意一个输入的整数列表L,程序必须输出一个列表L',使得L'中的元素与L中的元素完全相同,并且对于L'中任意的两个相邻元素a, b,都有 a ≤ b”。
- “你需要验证程序是否按规范执行(即,它是正确的)”:
- 验证 (Verify): 检查或证明某物是否为真或准确。
- 正确的 (Correct): 程序的实际行为完全符合其规范。
- 这个任务就是软件工程中的“正确性验证”。
- “由于程序和规范都是数学上精确的对象,你希望通过将这些对象输入到一台经过适当编程的计算机中来自动化验证过程。”:
- 数学上精确的对象: 一个程序本质上是一串有限的符号序列,其语法和语义由编程语言严格定义。一个精确的规范也可以用形式化语言(如逻辑公式)来表示。因此,它们都可以被看作是数学对象。
- 自动化验证过程: 既然程序和规范都是数学对象,我们自然会想,能不能写一个“超级分析程序”(我们称之为“验证器”),把待验证的“程序”和它的“规范”作为输入,然后这个“验证器”就能自动分析,并输出“是,此程序正确”或“否,此程序有误”。
- “然而,你会感到失望。”:
- 一个转折,预示着希望的破灭。
- “软件验证的通用问题是计算机不可解的。”:
- 这是本段的核心结论。
- 通用问题 (General Problem): 这里的“通用”是关键。它指的是能够处理任意程序和任意规范的验证问题。
- 不可解: 再次强调,不存在这样一个万能的、可以自动验证所有程序的“验证器”。
- 示例1 (一个可验证的特定情况):
- 程序 P1: def sort_list(L): return sorted(L) (Python代码)
- 规范 S1: “对输入列表进行升序排序”。
- 验证: 对于这个特定的程序P1和规范S1,我们(人类)可以很容易地验证它是正确的,因为sorted()函数就是按规范工作的。甚至可以写一个特定的测试程序,生成各种列表来测试它。但这不叫“通用验证”。
- 示例2 (一个难以验证的程序,接近不可解问题的本质):
- 程序 P2 (伪代码):
```
function find_special_number():
n = 1
while True:
if n is a perfect number and n > 10000: // 完美数是指其所有真因数之和等于自身的数
return n
n = n + 1
```
- 规范 S2: “这个程序最终会停止并返回一个大于10000的完美数”。
- 验证: 要验证P2是否符合S2,你需要知道是否存在一个大于10000的完美数。目前数学上已经知道存在,但如果这个问题是未解的呢?更进一步,如果程序里的判断条件是某个未解的数学猜想(如“是否存在奇完美数”),那么要验证这个程序是否会停机(即是否符合规范),就等价于解决那个数学猜想。
- 通用验证的困难: 一个通用的验证器需要能解决所有类似的问题,包括那些内嵌了未解数学猜想的程序。这显然是不可能的。停机问题正是这种困难的根源。
- 误解: “不可解”意味着我们不能做任何软件测试或验证。
- 澄清: 不是。它只是意味着完全自动化的、100%精确的、通用的验证是不可能的。
- 单元测试 (Unit Testing): 我们可以对程序的特定输入验证其输出,但这不能保证对所有输入都正确。
- 形式化方法 (Formal Methods): 对于一些特定类型的、规模较小的关键程序(如芯片设计、航空航天软件),专家们可以使用数学工具进行手动或半自动的验证。但这需要高昂的成本,且不能应用于所有软件。
- 静态分析工具 (Static Analysis Tools): 比如代码中的linter或bug finder,它们可以找到一些常见模式的错误,但不能保证找到所有错误。它们是“通用软件验证”这个不可解问题的实用主义近似解。
本段通过一个具体的、在软件工程中至关重要的例子——软件正确性验证——来阐明“不可解问题”的现实性。它清晰地描述了程序员们梦想拥有的“自动验证器”,然后揭示了这个梦想在最普适的意义上是无法实现的,因为“通用软件验证问题”本身是计算上不可解的。
本段的目的是将之前宽泛的讨论聚焦到一个具体、深刻且影响深远的实例上。通过解构软件验证问题,它让读者能够更具体地感受到“不可判定性”理论的力量和它对计算机科学实践的直接限制。
想象一个文学评论机器人。你给它任何一本小说(程序)和任何一个主题(规范),比如“这本小说是否表达了对工业化的批判?”。你希望这个机器人能读完小说后,给出一个绝对正确的“是”或“否”。本段是说,这样的机器人不存在。因为理解小说的内涵涉及到无穷的复杂性、歧义和上下文,无法被一个固定的算法完全捕捉。软件验证也是如此,程序的行为空间巨大,无法用一个通用算法完全探索。
你是一家制药公司的CEO,你希望开发一种“万能药物疗效预测器”。你把任何一种新药的化学分子式(程序)和任何一种疾病的定义(规范)输入这个机器,它就能告诉你这种药能否治愈这种病。本段的结论相当于证明了:这种万能预测器是不可能被制造出来的。药物和疾病的相互作用太复杂了,充满了未知。你只能通过大量的临床试验(测试)来近似地评估疗效,但永远无法事先获得一个绝对肯定的、对所有药物和疾病都适用的答案。
📜 [原文4]
在本节和第5章中,你将遇到几个计算上不可解的问题。我们的目标是帮助你对不可解的问题类型形成一种感觉,并学习证明不可解性的技术。
这段话是一个学习导航,为读者设定了本节及后续章节的学习目标。
- “在本节和第5章中,你将遇到几个计算上不可解的问题”:
- 这是一个内容预告。它告诉读者,我们将要学习的不是孤立的一个例子,而是一系列相关的不可解问题。这暗示了不可解性是一个普遍现象,并且这些问题之间可能存在关联。
- 第5章通常会讨论“可归约性”(Reducibility),这是一种证明其他问题不可解的核心技术。
- “我们的目标是帮助你对不可解的问题类型形成一种感觉”:
- 目标一:形成感觉 (Form a feeling)。这是一种高级的学习目标,超越了单纯的记忆和背诵。
- “感觉”或直觉,意味着当读者将来遇到一个新问题时,能够凭经验和理解,敏锐地判断出“这个问题闻起来有点像个不可解问题”。
- 不可解问题的类型: 这些问题通常具有一些共性,比如涉及到对任意计算过程行为的预测(如程序会不会停机、会不会访问某个内存地址)、涉及到无穷集合的性质判断、或者涉及到自我指涉(self-reference)的悖论。学习多个例子有助于归纳出这些共同特征。
- “并学习证明不可解性的技术”:
- 目标二:学习证明技术 (Learn proof techniques)。这是一个技能目标。
- 不仅仅是知道“什么”是不可解的,更要掌握“如何证明”一个问题是不可解的。
- 本节将介绍最根本的证明技术之一:对角化 (Diagonalization)。第5章将介绍归约 (Reduction),即将一个已知不可解问题“转化”为新问题,从而证明新问题也是不可解的。
- 示例1 (即将学习的技术:对角化):
- 我们将用它来证明第一个不可解问题——停机问题的一个变种 ($A_{\mathrm{TM}}$)。这个技术的核心思想是,构造一个“捣蛋鬼”对象,这个对象通过与一个假设存在的列表中的所有对象都至少有一个特征不同,来证明它自己不在这个列表里,从而戳穿“列表是完整的”这个假设。
- 示例2 (将在第5章学习的技术:归约):
- 问题A: 停机问题(已知不可解)。
- 问题B: “给定一个程序,判断它是否会打印出数字‘42’”。
- 归约技术: 我们可以证明,如果存在一个能解决问题B的算法 SolveB,我们就能利用它来构造一个解决问题A的算法 SolveA。具体做法是:
- 要解决停机问题 A(P, I)(程序P在输入I上是否停机),我们构造一个新的程序 P'。
- P' 的逻辑是:首先,运行 P(I);然后,如果 P(I) 停机了,就打印 '42'。
- 现在,我们把 P' 交给假设存在的 SolveB。如果 SolveB(P') 回答“是”(会打印42),那就意味着 P(I) 停机了。如果 SolveB(P') 回答“否”,那就意味着 P(I) 无限循环了。
- 这样,我们就用 SolveB 解决了停机问题A。但我们已经知道问题A是不可解的,这是一个矛盾。
- 因此,我们最初的假设“存在解决问题B的算法 SolveB”必定是错误的。结论:问题B也是不可解的。
- 这就是归约。我们把一个已知难的问题的“难”度,“传递”给了另一个问题。
- 易错点: 认为所有证明都像第一个证明那么复杂。实际上,在掌握了归约技术后,证明新的不可解问题会变得模式化和相对简单,关键在于巧妙地构造归约过程。
- 学习建议: 在学习第一个对角化证明时,不必苛求一次性完全理解所有细节,可以先接受其结论。重点是理解其“自我指涉”和“反证”的核心思想。在学习归约时,重点是理解“如果B可解,则A也可解”这个逻辑链条是如何建立的。
本段是学习路线图,明确了本节及后续章节的两大核心目标:一是通过接触多个实例,培养对不可解问题共性的直觉性认识;二是掌握证明问题不可解的两种关键技术——对角化和归约。
本段的目的是管理读者的学习预期,让读者知道接下来内容的结构和重点。通过预告将要学习“一系列”问题和“证明技术”,它鼓励读者从更高的视角来学习,不仅仅是看懂单个证明,而是要提炼出方法论。
学习不可解性就像学习如何识别“伪科学”。
- 形成感觉: 看多了占星术、永动机的例子,你就会对那些声称“违反基本物理定律”或“能预测一切”的理论产生一种天然的警惕感。
- 学习技术: 学习物理学定律(如能量守恒)和逻辑学,你就能从根本上论证为什么永动机是不可能的,而不仅仅是说“感觉它不靠谱”。
想象你在学习当一名侦探。
- 目标一 (形成感觉): 通过分析多个不同的悬案(不可解问题),你逐渐对那些“完美犯罪”的共同特征有了感觉,比如不在场证明的逻辑漏洞、利用了人性的普遍弱点等。
- 目标二 (学习技术): 你学习具体的侦查技术,比如指纹分析、弹道分析、逻辑推理(证明技术)。一开始你可能要学最基本的现场勘查(对角化),后来你学会了通过一个案子的线索去破解另一个关联的案子(归约)。
22. $A_{\text {TM }}$ 的定义与识别
📜 [原文5]
现在我们转向第一个确立特定语言不可判定性的定理:判定图灵机是否接受给定输入字符串的问题。我们将其称为 $A_{\text {TM }}$,类似于 $A_{\text {DFA }}$ 和 $A_{\text {CFG }}$。但是,虽然 $A_{\text {DFA }}$ 和 $A_{\text {CFG }}$ 是可判定的, $A_{\text {TM }}$ 却不是。设
这一段正式引入了本节要证明其不可判定性的核心主角:语言 $A_{\mathrm{TM}}$。
- “现在我们转向第一个确立特定语言不可判定性的定理”:
- 这是一个清晰的过渡句,表明前面的引言结束,正式的理论内容开始。我们将要学习的是计算理论历史上的一个里程碑式的定理。
- “判定图灵机是否接受给定输入字符串的问题”:
- 这是对 $A_{\mathrm{TM}}$ 所代表的问题的非形式化描述。
- 图灵机 (Turing Machine, TM): 计算的理论模型,可以看作是所有现代计算机的数学抽象。它有一个读写头、一条无限长的磁带和一个有限的状态控制器。
- 接受 (accepts): 当一个图灵机在处理一个输入字符串后,最终进入一个预先指定的“接受状态”并停机,我们就说这个图灵机“接受”了这个字符串。
- 问题核心: 给定任何一个图灵机 $M$ 的设计图和一个输入字符串 $w$,判断 $M$ 在输入 $w$ 上运行后,最终会不会停在接受状态。
- “我们将其称为 $A_{\text {TM }}$,类似于 $A_{\text {DFA }}$ 和 $A_{\text {CFG }}$”:
- 命名: $A_{\mathrm{TM}}$ 是这个问题的形式化语言名称。下标 TM 代表 图灵机,A 代表接受 (Acceptance)。
- 类比:
- $A_{\text{DFA}} = \{\langle B, w \rangle \mid B \text{ is a DFA and } B \text{ accepts } w\}$ 是判断一个确定性有限自动机(DFA)是否接受字符串 $w$ 的问题。
- $A_{\text{CFG}} = \{\langle G, w \rangle \mid G \text{ is a CFG and } G \text{ generates } w\}$ 是判断一个上下文无关文法(CFG)是否能生成字符串 $w$ 的问题。
- 这个类比很重要,因为它把新问题置于我们已知的知识体系中。
- “但是,虽然 $A_{\text {DFA }}$ 和 $A_{\text {CFG }}$ 是可判定的, $A_{\text {TM }}$ 却不是”:
- 这是一个关键的对比,突出了图灵机与 DFA、CFG 这类较弱计算模型之间的本质区别。
- 可判定的 (Decidable): 意味着存在一个算法(本身也是一个图灵机),对于 $A_{\text{DFA}}$ 或 $A_{\text{CFG}}$ 的任何输入 $\langle \text{模型}, w \rangle$,都能在有限时间内停机,并给出正确的“是”或“否”的答案。我们可以写一个程序来模拟任何DFA或CFG,并且由于它们的能力受限(DFA没有无限内存,CFG的派生有特定结构),我们可以保证模拟过程或检查过程总会结束。
- $A_{\text {TM }}$ 却不是: 这是本节要证明的核心论点。图灵机的能力太强大了(可以模拟任何计算机程序),以至于它可能会在某些输入上无限循环(永不停机)。正是这种“无限循环”的可能性,导致了我们无法创造一个万能的算法来判定它最终是否会接受。
- “设 ...”:
- 这是对 $A_{\mathrm{TM}}$ 的形式化定义。
- $A_{\mathrm{TM}}$: 这是一个语言 (Language) 的名称。在计算理论中,语言是一个字符串的集合。
- $\{$ ... $\}$: 这是集合的标准表示法。
- $\langle M, w\rangle$: 这代表一个字符串。它是由图灵机 $M$ 的描述(编码)和输入字符串 $w$ 的描述(编码)拼接而成的。
- $\langle \cdot \rangle$: 这个尖括号表示“编码 (encoding)”。因为图灵机本身是一个数学构造,为了让它能成为另一个图灵机的输入,我们必须先把它用一个标准的格式描述成一个字符串。比如,我们可以把 $M$ 的状态集、转移函数等所有信息,按照一个预先约定好的规则,写成一长串的0和1。
- $M$: 一个图灵机对象。
- $w$: 一个字符串,作为图灵机 $M$ 的输入。
- $\mid$: 读作“使得 (such that)”。它分开了集合中元素的形式和这些元素必须满足的条件。
- $M \text { is a TM and } M \text { accepts } w$: 这是元素 $\langle M, w\rangle$ 属于集合 $A_{\mathrm{TM}}$ 所必须满足的条件。
- $M \text { is a TM}$: 确保编码的第一部分 $\langle M \rangle$ 确实能被解码成一个合法的图灵机。
- $M \text { accepts } w$: 核心条件。当把字符串 $w$ 作为输入提供给图灵机 $M$ 时,$M$ 经过一系列计算步骤后,最终停机并处于“接受状态”。
- 示例1 (属于 $A_{\mathrm{TM}}$ 的元素):
- 设图灵机 $M_1$ 的功能是:检查输入字符串中是否包含子串 "00"。如果包含,就进入接受状态;否则进入拒绝状态。
- 设输入字符串 $w_1 = "101001"$。
- 当 $M_1$ 运行在 $w_1$ 上时,它会找到 "00",进入接受状态并停机。
- 因此,$M_1$ accepts $w_1$。
- 所以,字符串 $\langle M_1, w_1 \rangle$ 是语言 $A_{\mathrm{TM}}$ 中的一个元素。
- 示例2 (不属于 $A_{\mathrm{TM}}$ 的元素):
- 使用上面同一个图灵机 $M_1$。
- 设输入字符串 $w_2 = "101010"$。
- 当 $M_1$ 运行在 $w_2$ 上时,它从头到尾都找不到 "00",最终会进入拒绝状态并停机。
- 因此,$M_1$ does not accept $w_2$。
- 所以,字符串 $\langle M_1, w_2 \rangle$ 不在语言 $A_{\mathrm{TM}}$ 中。
- 示例3 (一个更微妙的不属于 $A_{\mathrm{TM}}$ 的元素):
- 设图灵机 $M_2$ 的功能是:寻找一个奇完美数。它在磁带上不停地测试数字 1, 3, 5, 7, ... 看它们是不是完美数。如果找到了,就进入接受状态。
- 设输入字符串 $w$ 是任意字符串($M_2$ 的设计是忽略输入 $w$)。
- 由于至今为止人类尚未发现任何奇完美数,并且普遍猜测不存在奇完美数,$M_2$ 在任何输入 $w$ 上都会无限循环下去,永远不会停机,自然也永远不会进入接受状态。
- 因此,$M_2$ does not accept $w$。
- 所以,字符串 $\langle M_2, w \rangle$ 不在语言 $A_{\mathrm{TM}}$ 中。这个例子揭示了不可判定性的根源:我们无法通过有限时间的观察来断定 $M_2$ 是“正在算”还是“永远算不完”。
- 易错点: 混淆 $A_{\mathrm{TM}}$ 本身是一个语言(字符串的集合)和它所代表的“问题”。语言是问题的形式化表达。当我们说“判定 $A_{\mathrm{TM}}$”时,我们的意思是“解决那个判断图灵机是否接受输入的问题”。
- 关键区别: $A_{\text{DFA}}$ 可判定是因为任何DFA在任何输入上都必然停机。它的计算路径长度等于输入字符串的长度,所以模拟它肯定会结束。而 $A_{\text{TM}}$ 不可判定的根源在于图灵机可以不停机(循环)。
本段正式定义了核心研究对象——语言 $A_{\mathrm{TM}}$。它是一个集合,包含了所有“能被图灵机 $M$ 接受的输入 $w$”的编码对 $\langle M, w\rangle$。通过与已知的可判定语言 $A_{\text{DFA}}$ 和 $A_{\text{CFG}}$ 进行对比,本段明确提出了核心论点:与这些较弱的模型不同,$A_{\mathrm{TM}}$ 是不可判定的,其根本原因在于图灵机具有无限循环的潜在行为。
本段的目的是为接下来的证明建立一个清晰、明确、形式化的目标。通过给出 $A_{\mathrm{TM}}$ 的数学定义,它将一个模糊的哲学问题(计算机能力的极限)转化为了一个可以进行严格逻辑论证的数学问题:证明语言 $A_{\mathrm{TM}}$ 不是一个可判定语言。
想象一个巨大的图书馆,书架上放满了各种各样的“操作手册”(图灵机 $M$)和“零件”(输入 $w$)。$A_{\mathrm{TM}}$ 就是这个图书馆里的一个特殊的“荣誉名册”。如果一本操作手册 $M$ 能够成功地利用零件 $w$ 组装出一个“获奖作品”(进入接受状态),那么这对组合的名字 $\langle M, w \rangle$ 就会被记录在荣誉名册上。本节要证明的是:你不可能雇一个图书管理员(算法),他能对你给他的任意一本手册和零件,都准确地告诉你这对组合的名字最终会不会被写上荣誉名册。
你有一个神奇的“命运水晶球”(判定器)。你把任何一个人的照片(图灵机 $M$)和这个人的一个人生目标(输入 $w$),比如“在40岁前成为百万富翁”,放进水晶球。水晶球总能告诉你这个人最终能否实现这个目标。
- 对于“在40岁前成为百万富翁”这个目标,实现与否是明确的,40岁生日那天就知道结果了。这类似于 DFA,总有明确的终点。
- 现在换一个目标:“找到人生的真正意义”。这个人可能会一生都在追寻,可能到死也没找到,也可能某天顿悟。你无法预知他会在哪一天“停机并接受”。$A_{\mathrm{TM}}$ 就类似于这个问题。本节的结论是,能预测任何人能否实现“找到人生真谛”这种无限可能目标的“命运水晶球”是不存在的。
33. 定理 (THEOREM) 4.11
📜 [原文6]
$A_{\text {TM }}$ 是不可判定的。
在进行证明之前,我们首先观察到 $A_{\text {TM }}$ 是图灵可识别的。因此,这个定理表明识别器比判定器更强大。要求图灵机在所有输入上都停机限制了它能识别的语言种类。以下图灵机 $U$ 识别 $A_{\text {TM }}$。
$U=$ “在输入 $\langle M, w\rangle$ 上,其中 $M$ 是一个图灵机,$w$ 是一个字符串:
- 模拟 $M$ 在输入 $w$ 上的运行。
- 如果 $M$ 进入其接受状态,则接受;如果 $M$ 进入其拒绝状态,则拒绝。”
请注意,如果 $M$ 在 $w$ 上循环,这台机器在输入 $\langle M, w\rangle$ 上也会循环,这就是为什么这台机器不判定 $A_{\mathrm{TM}}$ 的原因。如果算法有某种方法来判定 $M$ 在 $w$ 上没有停机,它就可以在这种情况下拒绝。然而,算法没有办法做出这个判定,正如我们将看到的。
这段话在正式开始证明 $A_{\mathrm{TM}}$ 不可判定之前,先退一步,证明了一个较弱但同样重要的性质:$A_{\mathrm{TM}}$ 是图灵可识别的。这个区分对于理解计算复杂性的层次至关重要。
- “$A_{\text {TM }}$ 是不可判定的。”:
- 这是定理4.11的内容,一个断言。我们即将要证明它。
- “在进行证明之前,我们首先观察到 $A_{\text {TM }}$ 是图灵可识别的。”:
- 这是一个重要的铺垫。
- 图灵可识别的 (Turing-recognizable): 一个语言 L 被称为图灵可识别的,如果存在一个图灵机 $M_{rec}$,对于任何属于 L 的字符串 $s$, $M_{rec}$ 在输入 $s$ 上会停机并接受。对于任何不属于 L 的字符串, $M_{rec}$ 或者停机并拒绝,或者永不停机(无限循环)。
- 可判定 (Decidable) vs 可识别 (Recognizable) 的关键区别:
- 判定器 (Decider): 对所有输入都必须停机,并给出明确的“接受”或“拒绝”。
- 识别器 (Recognizer): 只需对它应该接受的输入保证停机并接受。对于它不接受的输入,它可以拒绝,也可以“用无限循环来表达拒绝”。
- “因此,这个定理表明识别器比判定器更强大。”:
- 这里的“更强大”指的是能处理的语言范围更广。
- 所有可判定的语言都是图灵可识别的(因为判定器本身就是一个满足识别器定义的、更严格的图灵机)。
- 而这个定理将证明,存在像 $A_{\mathrm{TM}}$ 这样图灵可识别但不可判定的语言。
- 这就在可识别语言的集合和可判定语言的集合之间划出了一道鸿沟,证明了前者是一个比后者更大的集合。
- “要求图灵机在所有输入上都停机限制了它能识别的语言种类。”:
- 这句话从另一个角度解释了上面的观点。如果你对一个图灵机施加“必须在所有输入上停机”的约束(即要求它成为一个判定器),那么它能处理的语言集合就变小了。放松这个约束,允许它在某些输入上循环(成为一个识别器),它就能处理更多的语言。
- “以下图灵机 $U$ 识别 $A_{\text {TM }}$。”:
- 这里开始构造一个具体的图灵机 $U$,来证明 $A_{\mathrm{TM}}$ 确实是图灵可识别的。
- “$U=$ ‘在输入 $\langle M, w\rangle$ 上...’”:
- 这是对识别器 $U$ 的算法描述。$U$ 的工作是接收一个图灵机 $M$ 的编码和字符串 $w$。
- 步骤1: “模拟 $M$ 在输入 $w$ 上的运行。” 这是核心操作。$U$ 就像一个虚拟机或解释器。它读取 $\langle M \rangle$ 的编码,然后在自己的磁带上建立起 $M$ 的状态、转移函数以及输入 $w$ 的初始布局,然后一步一步地按照 $M$ 的规则来更新磁带和状态。
- 步骤2: “如果 $M$ 进入其接受状态,则接受;如果 $M$ 进入其拒绝状态,则拒绝。” $U$ 持续模拟,并监控被模拟的 $M$ 的状态。
- 如果 $M$ 停机并接受,$U$ 也停机并接受。
- 如果 $M$ 停机并拒绝,$U$ 也停机并拒绝。
- “请注意,如果 $M$ 在 $w$ 上循环,这台机器...也会循环”:
- 这是关键点。$U$ 的模拟是忠实的。如果 $M$ 陷入无限循环,$U$ 的模拟过程也永远不会结束,$U$ 自身也就陷入了无限循环。
- 正因为存在这种“一起循环”的可能性,$U$ 才不是一个判定器。判定器被要求在所有输入上停机,但 $U$ 在输入是 $\langle M, w \rangle$ 且 $M$ 在 $w$ 上循环时,无法停机。
- “这就是为什么这台机器不判定 $A_{\mathrm{TM}}$ 的原因。”:
- 明确指出了 $U$ 只是一个识别器而非判定器。
- “如果算法有某种方法来判定 $M$ 在 $w$ 上没有停机,它就可以在这种情况下拒绝。”:
- 这里点明了从识别器升级到判定器所缺失的关键环节:需要一个“循环检测器”。
- 一个假设的判定器 $H$ 的逻辑会是:先模拟 $M$ 在 $w$ 上的运行,同时运行一个“循环检测器”。如果 $M$ 接受了,就接受。如果 $M$ 拒绝了,就拒绝。如果“循环检测器”响了,报告说 $M$ 已经陷入无限循环,那么 $H$ 就可以自信地停机并拒绝。
- “然而,算法没有办法做出这个判定,正如我们将看到的。”:
- 预告了接下来的证明核心:我们将证明,这样一个通用的“循环检测器”(即解决停机问题的算法)是不可能存在的。
- 输入1 (U会停机并接受):
- $M_1$: 检查输入是否包含 "00"。
- $w_1$: "101001"。
- $U$ 的行为: 输入为 $\langle M_1, w_1 \rangle$。
- $U$ 模拟 $M_1$ 处理 "101001"。
- $U$ 发现 $M_1$ 在第五步后进入了接受状态。
- $U$ 停机并接受。
- 这符合识别器的定义,因为 $\langle M_1, w_1 \rangle \in A_{\mathrm{TM}}$。
- 输入2 (U会停机并拒绝):
- $M_1$: 检查输入是否包含 "00"。
- $w_2$: "101010"。
- $U$ 的行为: 输入为 $\langle M_1, w_2 \rangle$。
- $U$ 模拟 $M_1$ 处理 "101010"。
- $U$ 发现 $M_1$ 在读完整个字符串后进入了拒绝状态。
- $U$ 停机并拒绝。
- 这也符合识别器的行为,因为 $\langle M_1, w_2 \rangle \notin A_{\mathrm{TM}}$。
- 输入3 (U会无限循环):
- $M_2$: 寻找奇完美数,忽略输入。
- $w$: 任意字符串。
- $U$ 的行为: 输入为 $\langle M_2, w \rangle$。
- $U$ 模拟 $M_2$ 的运行。
- $U$ 忠实地模拟 $M_2$ 一个接一个地测试奇数 1, 3, 5, ...
- 因为 $M_2$ 永远找不到奇完美数,所以 $M_2$ 永远不停机。
- 因此,$U$ 的模拟过程也永远不会结束,$U$ 无限循环。
- 这同样符合识别器的定义,因为 $\langle M_2, w \rangle \notin A_{\mathrm{TM}}$,识别器允许在这种情况下无限循环。
- 易错点: 认为 $U$ 这个机器很简单。实际上,$U$ 是一个极其复杂的程序。它是一个图灵机的模拟器,是现代编程语言解释器、虚拟机(JVM, Python VM)和操作系统概念的理论鼻祖。
- 边界情况: 如果输入的字符串 $\langle M, w \rangle$ 中的 $\langle M \rangle$ 部分不是一个合法的图灵机编码怎么办?一个设计完善的 $U$ 会首先检查编码的合法性。如果编码不合法,它会立即停机并拒绝。
本段在证明 $A_{\mathrm{TM}}$ 不可判定之前,先通过构造一个名为 $U$ 的通用图灵机,证明了 $A_{\mathrm{TM}}$ 是图灵可识别的。$U$ 的工作方式是直接模拟输入给定的图灵机 $M$ 在输入 $w$ 上的行为。$U$ 的局限性在于,当 $M$ 无限循环时,$U$ 也会无限循环,这使得它无法成为一个判定器。这一论证清晰地划分了可识别性和可判定性的界限,并揭示了不可判定性的核心困难在于无法通用地检测出无限循环。
本段的目的是建立一个更精细的分类体系。它告诉我们,问题并非只有“可解”和“不可解”两种,在“不可解”中还存在层次。$A_{\mathrm{TM}}$ 属于“半可解”(图灵可识别)的层次,即我们能验证“是”的答案,但不能总是验证“否”的答案。这为后续引入完全不可识别的语言(连“是”的答案都无法保证验证)埋下伏笔。
想象一个法官审案。
- 判定器就像一个“全知法官”。对于任何案件(输入),他总能在有限时间内做出“有罪”或“无罪”的最终判决。
- 识别器 $U$ 就像一个“耐心但非全知的调查员”。对于一个案件 $\langle M, w \rangle$,他的策略是:“让我们重现一下案情(模拟 $M$ on $w$)”。
- 如果案情重现显示 $M$ 明确“有罪”(接受),调查员就提交“有罪”报告。
- 如果案情重演显示 $M$ 明确“无罪”(拒绝),调查员就提交“无罪”报告。
- 但如果案情重演进入了一个无限的循环(比如嫌疑人一直在兜圈子,不说有罪也不说无罪),调查员也会跟着永远调查下去,无法给出最终报告。
- 定理4.11 要证明的是,“全知法官”是不存在的。
你是一名质检员,你的任务是检测一种新型的“永恒灯泡” $M$ 在特定电压 $w$ 下是否能“成功点亮”(接受)。
- 你的检测设备 $U$ 的工作方式是:把灯泡 $M$ 接上电压 $w$(模拟)。
- 如果灯泡亮了,设备 $U$ 的“成功”指示灯亮起($U$ 接受)。
- 如果灯泡烧了或者保险丝断了,设备 $U$ 的“失败”指示灯亮起($U$ 拒绝)。
- 但有一种特殊的“永恒灯泡”,它被设计为“寻找宇宙的终极真理”,它会一直运行、计算,永远不会停下来,也因此永远不会“成功点亮”。当你的设备 $U$ 检测这种灯泡时,它会一直等待下去,指示灯永远不亮,设备本身也“卡”住了($U$ 循环)。
- 因此,你的设备 $U$ 只能识别出那些能成功点亮的组合,但无法判定所有组合,因为它无法区分“正在通往成功的路上”和“陷入了永恒的思考”。
📜 [原文7]
图灵机 $U$ 本身也很有趣。它是艾伦·图灵在1936年首次提出的通用图灵机的一个例子。这台机器被称为通用的,因为它能够根据对机器的描述来模拟任何其他图灵机。通用图灵机在存储程序计算机的发展早期发挥了重要的作用。
这一段是对刚刚介绍的图灵机 $U$ 的一个历史和概念性的补充说明,强调了它的重要地位。
- “图灵机 $U$ 本身也很有趣。”:
- 引起读者的注意,暗示 $U$ 的意义超越了仅仅作为证明 $A_{\mathrm{TM}}$ 可识别的工具。
- “它是艾伦·图灵在1936年首次提出的通用图灵机的一个例子。”:
- 艾伦·图灵 (Alan Turing): 英国数学家、逻辑学家,被誉为“计算机科学之父”和“人工智能之父”。
- 1936年: 这是图灵发表奠基性论文《论可计算数及其在判定问题上的应用》的年份,这篇论文中首次提出了图灵机和通用图灵机的概念。
- 通用图灵机 (Universal Turing Machine, UTM): 正是这个 $U$。它的革命性在于,图灵证明了可以建造一台单一的、固定的机器 ($U$),它能模拟任何其他图灵机 ($M$)。
- “这台机器被称为通用的,因为它能够根据对机器的描述来模拟任何其他图灵机。”:
- 这里解释了“通用 (Universal)”的含义。
- 在通用图灵机出现之前,人们对“机器”的理解是“功能单一”。比如,一个加法器只能做加法,一个乘法器只能做乘法。如果你想做一个新的计算,你就需要造一台新的、专门的机器。
- 通用图灵机的突破在于,它把“做什么”(计算的逻辑,即程序 $M$)和“谁来做”(执行计算的物理设备 $U$)分开了。计算的逻辑 $M$ 被编码成数据(字符串 $\langle M \rangle$),作为“通用”机器 $U$ 的输入。
- “通用图灵机在存储程序计算机的发展早期发挥了重要的作用。”:
- 存储程序计算机 (Stored-program computer): 这是现代计算机体系结构的核心思想(也称为冯·诺依曼架构)。它的要点是,指令(程序)和数据都存储在同一个内存中,可以被CPU读取和执行。
- 关联: 通用图灵机 $U$ 就是存储程序思想的理论模型。
- $U$ 的控制器和磁带操作规则是固定的硬件(CPU)。
- 写在磁带上的 $\langle M, w \rangle$ 就是存储在内存中的程序和数据。$U$ 通过读取 $\langle M \rangle$ 来决定下一步该做什么,这正是CPU读取和执行内存中的指令。
- 这个理论概念为后来的工程师(如冯·诺依曼、莫奇利和埃克特)设计和建造第一代电子计算机(如ENIAC的后续机型EDVAC)提供了强大的理论基础和指导。
- 示例1 (现代计算机类比):
- 你的笔记本电脑就是一台通用图灵机的物理实现。
- 硬件 (CPU, 内存, 硬盘) 是固定的,这相当于 $U$。
- 当你运行 word.exe (文字处理软件) 时,word.exe 的二进制代码就是 $\langle M_1 \rangle$,你正在编辑的文档 .docx 就是 $w_1$。你的电脑($U$)通过执行 word.exe 的指令来处理你的文档。
- 当你关闭Word,运行 chrome.exe (浏览器) 时,chrome.exe 的代码就是 $\langle M_2 \rangle$,你访问的网址就是 $w_2$。你的电脑($U$)现在执行 chrome.exe 的指令。
- 你不需要为了运行不同软件而更换电脑硬件。这台“通用”的电脑可以模拟任何软件(程序)的行为。
- 示例2 (解释器类比):
- Python解释器本身是一个程序(通常用C语言编写),它就是 $U$ 的一个实例。
- 你写的一个Python脚本 my_script.py,就是 $\langle M \rangle$。
- 当你在命令行输入 python my_script.py input_data.txt 时,Python解释器($U$)读取并解析 my_script.py($\langle M \rangle$)的内容,然后根据这些指令来处理 input_data.txt($w$)。
- 历史误区: 有时人们会争论图灵和冯·诺依曼谁对存储程序计算机的贡献更大。最公允的看法是:图灵在1936年从纯数学和逻辑的角度提出了最根本的理论思想(通用图灵机),而冯·诺依曼等人在1945年左右,在具体的电子计算机工程实践中,明确并系统化了存储程序的体系结构。两者都是不可或缺的。
- 理论与实践: 理论上的通用图灵机有一条无限长的磁带。现实中的计算机内存是有限的。但在计算理论中,我们假设内存足够大,可以按需扩展,这种抽象使我们能专注于问题的可计算性,而不是资源限制。
本段是对图灵机 $U$ 的一个“旁注”,但内容极为重要。它揭示了 $U$ 不仅仅是证明过程中的一个辅助工具,它就是通用图灵机 (UTM) 的一个实例。这个由艾伦·图灵在1936年提出的革命性概念——即可以制造一台单一的、固定的机器来模拟任何其他机器——是现代存储程序计算机的理论基石,它将“程序”从固化的硬件中解放出来,使其成为可被处理的“数据”,从而开启了整个计算机和软件时代。
本段的目的是提升读者对理论的认识高度。它将一个抽象的证明工具 ($U$) 与计算机科学史上最核心的概念(通用计算、存储程序)联系起来,让读者明白我们正在讨论的不仅仅是某个定理的证明,而是整个计算机科学的理论基础。这增加了内容的深度和历史感。
通用图灵机就像一个“终极演员”。
- 普通演员: 可能只会演一种角色,比如喜剧演员只会演喜剧(专用机器)。
- 终极演员 (UTM): 你给他任何剧本($\langle M \rangle$),他都能完美地扮演其中的角色。他可以演哈姆雷特,也可以演小丑。他的表演能力(硬件)是固定的,但他能扮演的角色(软件)是无限的。剧本本身成了他表演的“输入数据”。
想象乐高积木。
- 专用机器: 你用乐高拼好的一辆“消防车模型”。它就只能是消防车。
- 通用图灵机 (UTM): 你手里有一大盒散装的乐高积木,和一本“乐高通用说明书”。这本通用说明书教你如何去读“任何”一个具体的乐高模型图纸。
- 你想拼消防车,就把“消防车图纸”($\langle M_1 \rangle$)拿来,按照“通用说明书”($U$ 的逻辑)的指导,一块一块地拼出消防车。
- 你想拼城堡,就把“城堡图纸”($\langle M_2 \rangle$)拿来,还是用同一本“通用说明书”的指导方法,拼出城堡。
- “通用说明书”+散装积木,就是通用图灵机。它把具体的“模型设计”变成了可以被读取和执行的“图纸数据”。
44. 对角化方法 (THE DIAGONALIZATION METHOD)
4.1 对角化方法的背景与目的
📜 [原文8]
$A_{\text {TM }}$ 不可判定性的证明使用了一种称为对角化的技术,该技术由数学家格奥尔格·康托尔于1873年发现。康托尔关注的是测量无限集大小的问题。如果我们有两个无限集,我们如何判断一个是否比另一个大,或者它们是否大小相同?对于有限集,当然,回答这些问题很容易。我们只需数数有限集中的元素,结果的数字就是它的大小。但是如果我们尝试数数无限集中的元素,我们将永远数不完!所以我们不能使用数数方法来判定无限集的相对大小。
这段话介绍了即将用于证明定理4.11的核心数学工具——对角化方法,并追溯了其历史来源和原始动机。
- “$A_{\text {TM }}$ 不可判定性的证明使用了一种称为对角化的技术”:
- 开门见山,点明了证明所依赖的关键武器。对角化 (Diagonalization) 是一种非常巧妙且强大的证明技巧。
- “该技术由数学家格奥尔格·康托尔于1873年发现”:
- 格奥尔格·康托尔 (Georg Cantor): 德国数学家,集合论的创始人。他的工作彻底改变了数学家对“无限”的理解。
- 1873年: 这是康托尔首次证明实数集不可数的年份,该证明中就使用了对角化。
- 这句交代了技术的发明者和历史,说明我们正在借用一个来自纯数学领域的经典工具。
- “康托尔关注的是测量无限集大小的问题”:
- 阐明了对角化最初被发明出来要解决的问题:比较不同无限集合的大小。
- 无限集 (Infinite Set): 包含无限多个元素的集合,例如自然数集 $\{1, 2, 3, \dots\}$。
- “如果我们有两个无限集,我们如何判断一个是否比另一个大,或者它们是否大小相同?”:
- 提出了比较无限集大小的挑战。这个问题的答案并不直观。例如,偶数集和整数集都是无限的,它们一样大吗?有理数集和实数集呢?
- “对于有限集,当然,回答这些问题很容易。我们只需数数有限集中的元素,结果的数字就是它的大小。”:
- 用有限集的情况作对比。对于有限集,比如 A = {苹果, 香蕉, 橙子},B = {红, 绿},我们可以通过计数来比较大小。A的大小是3,B的大小是2,所以A比B大。
- “但是如果我们尝试数数无限集中的元素,我们将永远数不完!所以我们不能使用数数方法来判定无限集的相对大小。”:
- 指出了传统计数方法的局限性。对于无限集,计数过程没有终点,因此无法得到一个具体的“数量”来进行比较。我们需要一种新的、不依赖于“数完”这个过程的方法。
- 示例1 (有限集比较):
- 集合A: {a, b, c}
- 集合B: {1, 2, 3, 4}
- 方法: 数数。
- 结果: |A| = 3, |B| = 4。因为 3 < 4,所以集合A比集合B小。
- 示例2 (无限集比较的困境):
- 集合N (自然数): {1, 2, 3, 4, 5, ...}
- 集合E (偶数): {2, 4, 6, 8, 10, ...}
- 尝试数数:
- 数集合N: 1, 2, 3, ... 永远数不完。
- 数集合E: 2, 4, 6, ... 也永远数不完。
- 困境: 无法通过数数得到一个具体的数值来比较它们的大小。直觉上 E 是 N 的一部分,似乎应该更小,但康托尔的方法会给我们一个不同的答案。
- 易错点: 将日常生活中对“大小”的理解直接套用到无限集上。对于无限集,“一部分不一定比整体小”是可能成立的,这与我们的有限世界经验相悖。康托尔的理论需要我们更新对“大小”这个概念的定义。
- 核心思想的转变: 我们需要从“基数”(数出有多少个)的思维,转向“对应”(能否一一配对)的思维。
本段为引入对角化方法进行了铺垫。它指出,证明 $A_{\mathrm{TM}}$ 不可判定性所用的对角化技术,源于19世纪数学家康托尔为了解决“如何比较无限集大小”这一难题而进行的研究。它阐明了传统计数方法在面对无限集时的失效,从而引出了下文即将介绍的、康托尔提出的基于“配对”思想的新方法。
本段的目的是提供历史和思想背景。它告诉读者,对角化不是一个凭空出现的、只为计算机科学服务的技巧,而是源自于数学基础研究中一个非常深刻的问题。这有助于读者理解该方法的思想根源,并为接下来看似有些奇怪的“配对”和“一一对应”等概念做好心理准备。
想象你有两堆沙子,你想知道哪一堆更多。
- 有限集 (两小堆): 你可以一颗一颗地数每一堆有多少沙粒,然后比较两个数字。
- 无限集 (两个无限大的沙漠): 你不可能数完任何一个沙漠的沙粒。计数方法失效了。你需要新的方法。康托尔提出的方法是:你能不能从两个沙漠里同时一颗一颗地取出沙粒,让它们一一配对?如果你能一直配对下去,两个沙漠都没有剩余,那它们就“一样大”。如果一个沙漠取完了,另一个还有剩余,那剩下的那个就“更大”。
你是一家电影院的经理,今晚有两个厅(A厅和B厅)都在放电影,都坐满了人。你想知道哪个厅的观众更多,但又不方便进去一个一个地点人头。
- 康托尔的方法: 你可以在散场时,让A厅和B厅的观众两两配对,手拉手一起走出电影院。
- 如果最后所有人都找到了搭档,没有一个人落下,那么你就知道两个厅的观众人数一样多。
- 如果A厅的人都走光了,B厅还有人在等搭档,你就知道B厅的观众更多。
- 这个“配对”的方法,完全不需要知道每个厅具体有多少人,就能比较它们的大小。这就是康托尔思想的精髓,即将“计数”问题转化为“对应”问题。
📜 [原文9]
例如,取偶数集和所有二进制字符串集。这两个集都是无限的,因此都比任何有限集大,但其中一个是否比另一个大?我们如何比较它们的相对大小?
这一段通过两个具体的无限集合例子,让上一段提出的抽象问题变得更加具体。
- “例如,取偶数集和所有二进制字符串集”:
- 给出了两个需要比较大小的无限集合。
- 偶数集 (Set of even numbers): $\mathcal{E} = \{2, 4, 6, 8, \dots\}$。
- 所有二进制字符串集 (Set of all binary strings): $\Sigma^*$ where $\Sigma = \{0, 1\}$。这个集合包含:$\{\epsilon, 0, 1, 00, 01, 10, 11, 000, \dots\}$ (其中 $\epsilon$ 代表空字符串)。
- “这两个集都是无限的,因此都比任何有限集大”:
- 这是一个基本观察。无论你取一个多大的有限集,比如包含1万亿个元素的集,你总能在偶数集或二进制字符串集中找到更多的元素。
- “但其中一个是否比另一个大?”:
- 这是核心问题。两个都是无限的,它们的大小关系如何?
- 直觉上很难判断。偶数集看起来像是一条无限延伸的直线上的离散点。二进制字符串集似乎更“茂盛”,因为每个长度下都有多个字符串,而且长度可以无限增加。
- “我们如何比较它们的相对大小?”:
- 再次强调了比较方法的缺失,并引导读者思考解决方案。
- 偶数集 $\mathcal{E}$:
- 前几个元素: 2, 4, 6, 8, 10, 12, ...
- 它的元素是无限多的。
- 二进制字符串集 $\Sigma^*$:
- 长度为0的: $\epsilon$ (1个)
- 长度为1的: 0, 1 (2个)
- 长度为2的: 00, 01, 10, 11 (4个)
- 长度为3的: 000, 001, 010, 011, 100, 101, 110, 111 (8个)
- ...
- 它的元素也是无限多的。
- 比较的挑战:
- 我们能说二进制字符串集更大吗?因为它在每个“层级”(长度)上都在“扩张”,而偶数集只是线性增加。
- 康托尔的理论将给出一个精确的答案(剧透:它们其实一样大,因为它们都是“可数无限”的)。
- 不要依赖直觉: 在无限集合的世界里,视觉上的“密度”或“分支”并不能作为判断大小的可靠依据。必须依赖下文将要介绍的严格的“一一对应”定义。
- 元素的类型: 比较集合大小时,我们只关心元素的“个数”,不关心元素本身是什么。偶数是数字,二进制串是符号序列,但这不影响我们对它们所属集合的大小进行比较。
本段通过提出两个具体的无限集合——偶数集和二进制字符串集——的比较问题,将之前抽象的“如何比较无限集大小”的讨论实例化,使读者能够更清晰地感受到这个问题的挑战性,并为下文引入康托尔的“一一对应”方法做好了准备。
本段的目的是作为一个具体的思维实验,激发读者的思考。通过选择两个看起来结构很不一样的无限集,它强化了“计数”方法的无效性,并暗示需要一个更普适、更强大的工具来处理这类问题。
想象一个图书馆里有两种无限多的书。
- 第一种(偶数集): 《张三日记第2天》,《张三日记第4天》,《张三日记第6天》,... 无限延续下去。
- 第二种(二进制字符串集): 《密码书:空》,《密码书:0》,《密码书:1》,《密码书:00》,...
你作为图书管理员,想知道哪种书的总量更多。你无法数清任何一种。这个问题看似棘手。
你有两串无限长的珠子。
- 第一串(偶数集): 珠子上依次标着 2, 4, 6, 8, ...
- 第二串(二进制字符串集): 珠子上依次标着 $\epsilon, 0, 1, 00, 01, 10, 11, ...$ (按某种顺序列出所有二进制串)
哪串珠子更“长”?或者说,哪一串用的珠子更多?肉眼看不出来,需要一把特殊的“尺子”来测量。这把“尺子”就是康托尔的一一对应法。
4.2 一一对应与可数集
📜 [原文10]
康托尔提出了一个相当巧妙的解决方案来解决这个问题。他观察到,如果一个集的元素可以与另一个集的元素配对,那么这两个有限集的大小相同。这种方法在不数数的情况下比较大小。我们可以将这个想法扩展到无限集。更精确地说是这样的。
这段话正式引入了康托尔解决无限集比较问题的核心思想:从“计数”转向“配对”。
- “康托尔提出了一个相当巧妙的解决方案来解决这个问题”:
- 预示着答案的揭晓。
- “他观察到,如果一个集的元素可以与另一个集的元素配对,那么这两个有限集的大小相同。”:
- 这里从我们熟悉的有限集开始,建立一个直观的基础。
- 配对 (Paired off): 指的是建立一种一一对应关系。A集里的每一个元素都恰好对应B集里的一个元素,反之亦然,没有落下,也没有多余。
- 例子: 一场舞会,如果每个男士都恰好找到一位女士做舞伴,没有男士剩下,也没有女士剩下,那么我们就知道男士和女士的人数是相同的。我们根本不需要去数具体有多少人。
- “这种方法在不数数的情况下比较大小。”:
- 强调了这个新方法的本质。它绕过了“计数”这个在无限情况下不可行的操作。
- “我们可以将这个想法扩展到无限集。”:
- 这是关键的一步,将有限世界里的直觉推广到无限世界。康托尔的巨大贡献在于,他不仅提出了这个想法,还严格地证明了这个推广是合理且富有成果的。
- “更精确地说是这样的。”:
- 引出下文的严格数学定义。
- 示例1 (有限集配对):
- 集合A: {苹果, 橘子, 梨}
- 集合B: {盘子1, 盘子2, 盘子3}
- 配对:
- 苹果 -> 盘子1
- 橘子 -> 盘子2
- 梨 -> 盘子3
- 结论: 苹果和盘子可以完美地一一配对,所以它们的数量相同,都是3。我们不需要先数苹果有3个,再数盘子有3个,然后比较3和3。配对成功本身就证明了数量相等。
- 示例2 (有限集无法配对):
- 集合A: {笔A, 笔B}
- 集合C: {笔帽1, 笔帽2, 笔帽3}
- 尝试配对:
- 笔A -> 笔帽1
- 笔B -> 笔帽2
- 结果: 笔都用完了,但笔帽还剩下“笔帽3”。无法实现一一配对。
- 结论: 笔帽的集合比笔的集合大。
- 关键假设: 这个配对必须是“一对一”的。不能一个苹果对应两个盘子,也不能两个苹果对应同一个盘子。
- 推广的挑战: 对于无限集,我们无法像有限集那样“画出”所有的配对关系。我们需要找到一个“规则”或“函数”,这个函数能描述如何为集合A中的任何一个元素找到它在集合B中唯一的配对伙伴。
本段阐述了康托尔比较集合大小的革命性思想:用“能否完美配对”来代替“计数比较”。这个方法在有限集上是直观的,其真正的威力在于可以被严谨地推广到无限集,从而为我们提供了一把衡量“无限”的尺子。
本段的目的是完成从“旧方法行不通”到“新方法的思想核心”的过渡。它为下文即将出现的“一对一”、“满射”、“一一对应”等形式化定义提供了直观的、非数学的解释,降低了读者的理解门槛。
“座位”模型。
- 要判断一个房间里的人(集合A)和一个剧院里的座位(集合B)哪个多。
- 计数法: 分别数出人数和座位数,然后比较。
- 配对法: 让所有人都去坐到座位上。
- 如果每个人都坐下了,且没有一个空座,那么人和座位一样多。
- 如果有人没座位坐,那么人比座位多。
- 如果所有人都坐下了,还有空座位,那么座位比人多。
- 这个“坐座位”的过程就是建立一一对应的过程。它对于无限的人和无限的座位同样适用(在概念上)。
想象一条无限长的队伍A和另一条无限长的队伍B。你想知道哪条队伍更“长”。
你不能走到队尾去数,因为没有队尾。
康托尔的方法是:让两条队伍的排头兵并排站在一起,然后是第二名,第三名... 如果两条队伍能一直这样肩并肩地走下去,无穷无尽,那么这两条队伍就“一样长”。我们接下来要做的就是把这个“肩并肩”的过程数学化。
📜 [原文11]
定义 (DEFINITION) 4.12
假设我们有集合 $A$ 和 $B$ 以及一个从 $A$ 到 $B$ 的函数 $f$。如果 $f$ 从不将两个不同的元素映射到同一个位置——也就是说,如果当 $a \neq b$ 时 $f(a) \neq f(b)$,则称 $f$ 是一对一的。如果 $f$ 击中 $B$ 中的每个元素——也就是说,对于每个 $b \in B$,都存在一个 $a \in A$ 使得 $f(a)=b$,则称 $f$ 是满射的。如果存在一个一对一的、满射的函数 $f: A \longrightarrow B$,则称 $A$ 和 $B$ 大小相同。既是一对一又是满射的函数称为一一对应。在一一对应中, $A$ 的每个元素都映射到 $B$ 的一个唯一元素,并且 $B$ 的每个元素都有一个 $A$ 的唯一元素映射到它。一一对应仅仅是将 $A$ 的元素与 $B$ 的元素配对的一种方式。
这一段给出了上一段“配对”思想的严格数学定义,引入了三个核心概念:一对一(单射)、满射和一一对应(双射)。
- “假设我们有集合 $A$ 和 $B$ 以及一个从 $A$ 到 $B$ 的函数 $f$。”:
- 函数 (Function) $f$: 建立从集合 A (定义域) 到集合 B (到达域) 的映射规则。对于 A 中的每一个元素,f 都指定了 B 中的一个对应元素。
- “如果 $f$ 从不将两个不同的元素映射到同一个位置——也就是说,如果当 $a \neq b$ 时 $f(a) \neq f(b)$,则称 $f$ 是一对一的。”:
- 一对一 (One-to-one / Injective): 这是对“不重复”的定义。
- 直观解释: 从 A 出发的不同的“人”,必须到达 B 中不同的“座位”。不允许两个人抢同一个座位。
- 例子: $f(x) = x+1$ 是一对一的,因为如果 $x_1 \neq x_2$,那么 $x_1+1 \neq x_2+1$。而 $f(x) = x^2$ (定义域为全体整数)不是一对一的,因为 $f(2)=4$ 且 $f(-2)=4$,两个不同的输入 2 和 -2 映射到了同一个输出 4。
- “如果 $f$ 击中 $B$ 中的每个元素——也就是说,对于每个 $b \in B$,都存在一个 $a \in A$ 使得 $f(a)=b$,则称 $f$ 是满射的。”:
- 满射 (Onto / Surjective): 这是对“不遗漏”的定义。
- 直观解释: 集合 B 中的每一个“座位”都必须有来自 A 的“人”坐。不允许有空座。
- 例子: 考虑从整数集 $\mathbb{Z}$ 到整数集 $\mathbb{Z}$ 的函数。$f(x) = x+1$ 是满射的,因为对于任何一个整数 $y$,我们总能找到一个整数 $x = y-1$ 使得 $f(x)=y$。而 $f(x) = 2x$ 不是满射的,因为它只能“击中”偶数,所有的奇数座位都空着。
- “如果存在一个一对一的、满射的函数 $f: A \longrightarrow B$,则称 $A$ 和 $B$ 大小相同。”:
- 这是康托尔对“大小相同”的正式定义。它要求找到一个函数 $f$,这个函数既满足一对一(不重复),又满足满射(不遗漏)。
- “既是一对一又是满射的函数称为一一对应。”:
- 一一对应 (Correspondence / Bijection): 这是对“完美配对”的数学术语。双射是另一个常用名。
- 一一对应 = 单射 + 满射。
- “在一一对应中, $A$ 的每个元素都映射到 $B$ 的一个唯一元素,并且 $B$ 的每个元素都有一个 $A$ 的唯一元素映射到它。”:
- 用更通俗的语言重复了一遍一一对应的含义,强调了其“双向唯一性”。
- “一一对应仅仅是将 $A$ 的元素与 $B$ 的元素配对的一种方式。”:
- 回归到最初的直观思想,一个一一对应的函数 $f$ 就是一份描述了如何将 A 和 B 中元素进行完美配对的“配对清单”。
- 场景: $A = \{1, 2, 3\}, B = \{p, q, r\}$
- 示例1 (一一对应):
- $f_1(1)=p, f_1(2)=q, f_1(3)=r$
- 一对一?: 是。不同的输入1, 2, 3对应不同的输出p, q, r。
- 满射?: 是。B中的每个元素p, q, r都有一个A中的元素指向它。
- 结论: $f_1$ 是一个一一对应。因此,集合 A 和 B 大小相同。
- 示例2 (非一对一,非满射):
- $A = \{1, 2, 3\}, B = \{p, q, r\}$
- $f_2(1)=p, f_2(2)=p, f_2(3)=q$
- 一对一?: 否。因为 $f_2(1)=f_2(2)=p$,两个不同的输入映射到了同一个输出。
- 满射?: 否。因为B中的元素 $r$ 没有被任何A中的元素映射到。
- 结论: $f_2$ 不是一一对应。
- 示例3 (一对一,但非满射):
- $A = \{1, 2\}, B = \{p, q, r\}$
- $f_3(1)=p, f_3(2)=q$
- 一对一?: 是。
- 满射?: 否。$r$ 没有被击中。
- 结论: 不是一一对应。这意味着 |A| < |B|。
- 示例4 (满射,但非一对一):
- $A = \{1, 2, 3\}, B = \{p, q\}$
- $f_4(1)=p, f_4(2)=q, f_4(3)=q$
- 一对一?: 否。$f_4(2)=f_4(3)$。
- 满射?: 是。p和q都被击中了。
- 结论: 不是一一对应。这意味着 |A| > |B|。
- 函数方向: 函数 $f: A \longrightarrow B$ 的方向很重要。一个方向存在一一对应,反方向 $g: B \longrightarrow A$ 也必然存在一一对应(即 $f$ 的反函数 $f^{-1}$)。
- 存在性: 定义说的是“如果存在一个...函数”,意味着我们只需要找到一个满足条件的函数即可。可能存在很多不是一一对应的函数,但这不影响结论,只要我们能找到那怕一个是的就行。
本定义将“比较集合大小”这一直观概念,严格地形式化为寻找一个特定类型的函数——一一对应。一个函数是一一对应,当且仅当它同时是一对一(无冲突)和满射(无遗漏)。如果能在两个集合 A 和 B 之间建立一个一一对应,我们就称这两个集合大小相同。
本段的目的是为“比较无限集大小”提供一个坚实的、无歧义的数学基础。通过将问题转化为寻找一个具有特定属性(单射和满射)的函数,它使得我们可以使用数学工具来严谨地证明两个无限集合是否“大小相同”。这是整个对角化论证的逻辑基石。
[直觉心-智模型]
回到“座位”模型:$A$ 是人, $B$ 是座位,$f$ 是“安排座位”的规则。
- 一对一 (单射): 不允许两个人坐同一个座位。
- 满射 (满射): 不允许有空座位。
- 一一对应 (双射): 每个人都有座位,且每个座位都有人坐,不多不少,完美匹配。
想象你在给手套配对。左手手套是集合 A,右手手套是集合 B。
- 一一对应: 你把所有手套都配成了完整的一双。这意味着左手手套和右手手套的数量一样多。这个“配对”的过程就是建立一一对应 $f$。$f(\text{左手手套}_i) = \text{右手手套}_i$。
- 非一一对应:
- 剩下几只左手手套没配上对:函数不是满射的(对于B),A比B大。
- 剩下几只右手手套没配上对:函数不是一对一的(如果从B看A),B比A大。
📜 [原文12]
这些函数类型的另一种常用术语是单射 (injective) 代表一对一,满射 (surjective) 代表满射,以及双射 (bijective) 代表一对一和满射。
这一段是为一个概念提供多种常用术语,帮助读者在不同文献和语境中都能认出它们。
- “单射 (injective) 代表一对一”:
- 单射: 这是“one-to-one”在更形式化的数学语境中的标准术语。前缀 "in-" 可以理解为“注入”,每个源集合的元素被“注入”到目标集合的不同位置。
- 记忆技巧: “单” -> 单独的,不扎堆。每个输入都对应单独的输出。
- “满射 (surjective) 代表满射”:
- 满射: 这是“onto”在数学中的标准术语。前缀 "sur-" (源自法语,意为 "on" 或 "over"),可以理解为函数的像“覆盖”了整个目标集合。
- 记忆技巧: “满” -> 铺满了。输出覆盖了目标集合的每一个角落。
- “以及双射 (bijective) 代表一对一和满射”:
- 双射: 这是“correspondence” (一一对应) 在数学中的标准术语。前缀 "bi-" 意为“双”,表示它同时满足了单射和满射两个(“双”重)条件。
- 记忆技巧: “双” -> 双重满足:既单射又满射。
- 函数: $f: \mathbb{R} \to \mathbb{R}$, $f(x) = x^3$ (从实数集到实数集)
- 单射?: 是。如果 $x_1 \neq x_2$, 那么 $x_1^3 \neq x_2^3$。
- 满射?: 是。对于任何实数 $y$, 总能找到 $x = \sqrt[3]{y}$ 使得 $f(x) = y$。
- 结论: $f(x)=x^3$ 是一个双射函数。
- 函数: $g: \mathbb{R} \to \mathbb{R}$, $g(x) = x^2$
- 单射?: 否。例如 $g(2) = g(-2) = 4$。
- 满射?: 否。输出永远不会是负数,所以所有负实数都没有被“击中”。
- 结论: $g(x)=x^2$ 既不是单射也不是满射。
- 语境: 在计算机科学的教材中,"one-to-one", "onto" 更常见,因为它们更直观。在纯数学的教材中,"injective", "surjective", "bijective" 更为通用和标准。了解这两套术语有助于广泛阅读。
本段话是一个术语对应表,将直观的描述“一对一”和“满射”分别与它们在数学上更形式化的名称“单射”和“满射”联系起来,并指出同时满足这两者的函数被称为“双射”,也就是“一一对应”。
本段的目的是为了语言的严谨性和通用性。它确保读者在学习了直观概念后,也能掌握学术界标准的术语,以便于查阅其他资料或进行更深入的学习,避免因术语不同而产生困惑。
这就像给同一个东西起不同的名字。
- “一对一”是小名,听起来很亲切。
- “单射”是大名/学名,写在正式文书上。
- “满射”是另一个小名。
- “满射”是它的大名。
- “一一对应”是绰号。
- “双射”是它最正式的学名。
内容是同一个,只是在不同场合用不同的叫法。
想象你在填写一份国际表格。
- 表格上可能有一栏写着 Given Name(一对一),另一栏写着 First Name(单射),它们指的是同一个东西。
- 表格上可能写着 Family Name(满射),也可能写着 Surname(满射)。
- 本段的作用就是告诉你这些词是同义词,不要被搞糊涂了。
📜 [原文13]
示例 (EXAMPLE) 4.13
设 $\mathcal{N}$ 是自然数集 $\{1,2,3, \ldots\}$,设 $\mathcal{E}$ 是偶自然数集 $\{2,4,6, \ldots\}$。使用康托尔对大小的定义,我们可以看到 $\mathcal{N}$ 和 $\mathcal{E}$ 具有相同的大小。将 $\mathcal{N}$ 映射到 $\mathcal{E}$ 的一一对应 $f$ 简单地是 $f(n)=2 n$。我们可以借助表格更容易地可视化 $f$。
| $n$ | $f(n)$ |
| :--------: | :--------: |
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| $\vdots$ | $\vdots$ |
当然,这个例子看起来很奇怪。直观上, $\mathcal{E}$ 似乎比 $\mathcal{N}$ 小,因为 $\mathcal{E}$ 是 $\mathcal{N}$ 的一个真子集。但是,可以将 $\mathcal{N}$ 的每个成员与 $\mathcal{E}$ 的一个成员配对,所以我们声明这两个集的大小相同。
这个例子应用了刚刚定义的“一一对应”来证明一个反直觉的结论:自然数和偶数的数量一样多。
- “设 $\mathcal{N}$ 是自然数集 $\{1,2,3, \ldots\}$,设 $\mathcal{E}$ 是偶自然数集 $\{2,4,6, \ldots\}$。”:
- 定义了两个要比较的无限集合。$\mathcal{N}$ (Natural numbers) 和 $\mathcal{E}$ (Even numbers)。
- “使用康托尔对大小的定义,我们可以看到 $\mathcal{N}$ 和 $\mathcal{E}$ 具有相同的大小。”:
- 提出结论:根据定义4.12,这两个集合大小相同。
- “将 $\mathcal{N}$ 映射到 $\mathcal{E}$ 的一一对应 $f$ 简单地是 $f(n)=2 n$。”:
- 为了证明大小相同,我们必须给出一个具体的一一对应函数。这里给出的函数是 $f(n) = 2n$。
- 验证 $f(n)=2n$ 是否为一一对应 (双射):
- 定义域: $\mathcal{N} = \{1, 2, 3, \ldots\}$
- 到达域: $\mathcal{E} = \{2, 4, 6, \ldots\}$
- 验证单射 (一对一): 假设 $n_1, n_2 \in \mathcal{N}$ 且 $n_1 \neq n_2$。那么 $2n_1 \neq 2n_2$,即 $f(n_1) \neq f(n_2)$。所以函数是单射的。
- 验证满射 (满射): 对于到达域 $\mathcal{E}$ 中的任意一个偶数 $e$,我们总能在定义域 $\mathcal{N}$ 中找到一个数 $n = e/2$,使得 $f(n) = 2(e/2) = e$。因为 $e$ 是偶数,所以 $e/2$ 必然是一个自然数。所以函数是满射的。
- 结论: 因为 $f(n)=2n$ 既是单射又是满射,所以它是一个一一对应。
- “我们可以借助表格更容易地可视化 $f$。”:
- 表格直观地展示了这个配对关系:1对2,2对4,3对6,等等。对于任何一个自然数 $n$,它都唯一地对应一个偶数 $2n$;对于任何一个偶数 $e$,它都唯一地对应一个自然数 $e/2$。
- “当然,这个例子看起来很奇怪。”:
- 承认这个结论与我们的日常直觉相冲突。
- “直观上, $\mathcal{E}$ 似乎比 $\mathcal{N}$ 小,因为 $\mathcal{E}$ 是 $\mathcal{N}$ 的一个真子集。”:
- 点明了冲突的来源。真子集 (Proper Subset) 是指一个子集,它不等于母集(即母集中至少有一个元素不在该子集中)。例如,所有的偶数都属于自然数,但有些自然数(奇数)不是偶数,所以 $\mathcal{E}$ 是 $\mathcal{N}$ 的真子集。在有限集中,真子集总是比母集小。
- “但是,可以将 $\mathcal{N}$ 的每个成员与 $\mathcal{E}$ 的一个成员配对,所以我们声明这两个集的大小相同。”:
- 重申了康托尔的定义是最终的评判标准。尽管直觉上感觉很怪,但既然我们找到了一个完美的配对方案(一一对应),我们就必须根据定义得出结论:它们大小相同。这揭示了无限集的一个奇特性质:一个无限集可以和它的真子集大小相同。
- 配对示例1:
- 从 $\mathcal{N}$ 中取元素 100。根据函数 $f(n)=2n$,它对应到 $\mathcal{E}$ 中的元素 $f(100) = 200$。
- 反向配对示例2:
- 从 $\mathcal{E}$ 中取元素 998。要找到它在 $\mathcal{N}$ 中的配对伙伴,我们计算 $998 / 2 = 499$。所以 499 是它的配对伙伴,因为 $f(499) = 2 \times 499 = 998$。
- 定义域和到达域的重要性: 函数 $f(n)=2n$ 是否为一一对应,完全取决于我们如何定义它的定义域和到达域。
- 如果 $f: \mathcal{N} \to \mathcal{N}$ (从自然数到自然数),那么它就不是满射的,因为奇数没有被击中。
- 如果 $f: \mathcal{E} \to \mathcal{N}$ (从偶数到自然数),$f(n)=2n$ 甚至不是一个合法的函数,因为 $f(2)=4, f(4)=8$,输出不在到达域 $\mathcal{N}$ 的所有范围内。
- 只有当 $f: \mathcal{N} \to \mathcal{E}$,它才构成一个一一对应。
本例通过函数 $f(n)=2n$,成功地在自然数集 $\mathcal{N}$ 和偶自然数集 $\mathcal{E}$ 之间建立了一个一一对应。根据康托尔的定义,这证明了这两个集合大小相同。这个例子有力地展示了无限集合的一个核心特性:一个集合可以与其真子集大小相同,这与我们在有限集合上的经验截然不同。
本例的目的是让读者亲身体验一次应用康托尔定义的过程,并直面其带来的反直觉结果。通过这个简单但具有冲击力的例子,它迫使读者放弃基于有限世界的旧直觉,开始接纳和使用“一一对应”作为判断无限集大小的唯一标准。这是理解后续更复杂证明(如实数集不可数)的必要思想转变。
想象一个无限大的酒店,它有 1, 2, 3, ... 号房间,并且所有房间都住满了(自然数集 $\mathcal{N}$)。
现在又来了一批无限多的新客人,他们的编号是 2, 4, 6, ... (偶数集 $\mathcal{E}$)。酒店经理需要为所有新客人找到房间,但又不想赶走老客人。
经理通过广播通知:“请所有房间的客人,都搬到你现在房间号乘以2的新房间去。”
- 1号房客搬到2号房。
- 2号房客搬到4号房。
- 3号房客搬到6号房。
- ...
这个操作完成后,所有老客人都有了新房间,并且他们占据了所有偶数号的房间(2, 4, 6, ...)。那么哪些房间空出来了呢?所有的奇数号房间(1, 3, 5, ...)都空出来了!
这个无限大的酒店,通过内部调整,凭空创造出了无限多的空房间。这个例子(希尔伯特旅馆悖论)生动地说明了无限集可以与其真子集(偶数房号)一一对应。
你有一根无限长的木棍(代表自然数集 $\mathcal{N}$),上面在 1, 2, 3, ... 的位置有标记。
你还有另一根无限长的橡皮筋(代表偶数集 $\mathcal{E}$),上面在 2, 4, 6, ... 的位置有标记。
现在,你把这根橡皮筋均匀地拉伸一倍。
- 原来在2位置的标记,现在到了1的位置。
- 原来在4位置的标记,现在到了2的位置。
- 原来在6位置的标记,现在到了3的位置。
- ...
通过拉伸(或压缩,这里是压缩),橡皮筋上的每一个标记都与木棍上的每一个标记完美地重合了。这根看起来“更稀疏”的橡皮筋,通过变形,可以和“更密集”的木棍完全对应。这个“变形”就是函数 $f(n)=2n$ 的逆操作。
📜 [原文14]
定义 (DEFINITION) 4.14
如果集合 $A$ 是有限的,或者它与 $\mathcal{N}$ 的大小相同,则称 $A$ 是可数的。
这个定义引入了一个非常重要的分类术语:可数集。
- “如果集合 $A$ 是有限的...”:
- 可数 (Countable) 的第一种情况是有限集。这很自然,任何有限的东西我们显然都是可以“数”的。例如,{a, b, c} 是可数的。
- “...或者它与 $\mathcal{N}$ 的大小相同...”:
- 可数的第二种情况,也是更核心的情况,是无限集中那些能与自然数集 $\mathcal{N} = \{1, 2, 3, \dots\}$ 建立一一对应的集合。
- 这种集合被称为“可数无限”(countably infinite) 或“可列”(denumerable)。
- “...则称 $A$ 是可数的。”:
- 总结:可数集 = 有限集 $\cup$ 可数无限集。
- “可数”的核心直觉是:一个集合是可数的,当且仅当你可以将它的所有元素排成一个列表(这个列表可以是有限的,也可以是无限的),不重不漏。
- 将元素排成列表的过程,就是在与自然数集(1号位,2号位,3号位...)建立一一对应。
- 列表中的第一个元素对应1,第二个元素对应2,以此类推。
- 示例1 (有限集,可数):
- $A = \{红, 黄, 蓝\}$ 是可数的,因为它是有限的。我们可以列出它:1. 红, 2. 黄, 3. 蓝。
- 示例2 (可数无限集):
- 偶数集 $\mathcal{E} = \{2, 4, 6, \dots\}$ 是可数的。
- 原因: 在示例4.13中,我们已经证明了它与 $\mathcal{N}$ 大小相同(即存在一一对应 $f(n)=2n$)。
- 列表: 我们可以把它排成一个无限列表:
- 2 (对应自然数1)
- 4 (对应自然数2)
- 6 (对应自然数3)
...
- 示例3 (全体整数集,可数):
- $\mathbb{Z} = \{\dots, -2, -1, 0, 1, 2, \dots\}$ 是可数的。
- 直觉: 看起来它比 $\mathcal{N}$ 大一倍还多一个0,但实际上它们大小相同。
- 列表证明: 我们可以把它排成一个不重不漏的无限列表:
- 0
- 1
- -1
- 2
- -2
- 3
- -3
...
- 这个列表包含了所有整数,并且每个整数都在列表的某个确定位置。这等价于建立了一个与 $\mathcal{N}$ 的一一对应。
- “可数” vs “可数无限”: “可数”是一个更宽泛的概念,它包括了有限的情况。而“可数无限”特指那些和 $\mathcal{N}$ 一样大的无限集。在很多上下文中,人们会省略“无限”而直接说“可数集”,暗指“可数无限集”,需要根据语境判断。
- 列表的顺序: 排列成列表的顺序可以有很多种,只要能保证不重不漏就行。比如全体整数也可以排成 0, 1, 2, 3, ..., -1, -2, -3, ...,但这种排法是错误的,因为它永远也排不到-1。正确的列表必须保证任何一个元素都能在有限的步数内被排到。
定义4.14 给出了“可数集”的正式定义。一个集合被称为可数的,如果它要么是有限的,要么可以和自然数集 $\mathcal{N}$ 建立一一对应。这个定义抓住了“能够被逐一列出”这一核心特征。
本定义的目的是建立一个重要的分类标准,将无限集合分为两大类:可数的和不可数的。自然数集 $\mathcal{N}$ 在这里扮演了“无限的单位1”的角色,作为衡量其他无限集大小的基准。接下来的论证将表明,图灵机的数量是可数的,而所有可能语言的数量是不可数的,这种数量上的巨大差异直接导致了不可判定语言的存在。
“排队”模型。一个集合是可数的,就意味着你能让这个集合里的所有元素到操场上排成一队(可能是有限长的队伍,也可能是无限长的队伍),并且你能给每个人都编上号:1号,2号,3号...
- 可数集: 可以成功排成一队。
- 不可数集 (后面会讲): 元素太多太“混乱”,你永远无法把它们排成一个有序的队伍,总会漏掉数不清的人。
想象你有许多多米诺骨牌。
- 如果一个集合是可数的,你就可以把代表它每个元素的骨牌,一个挨一个地排成一列。你可以从第一张骨牌开始,推倒它,然后它会依次推倒第二张、第三张... 直至无穷。你知道只要时间足够,这个连锁反应总会触及到代表任何一个元素的骨牌。
- 如果一个集合是不可数的,就好像这些骨牌散落在整个沙滩上,你无法把它们排成一条线。无论你怎么排,总有无穷无尽的骨牌被遗漏在旁边,无法被连锁反应触及。
📜 [原文15]
示例 (EXAMPLE) 4.15
现在我们来看一个更奇怪的例子。如果我们设 $\mathcal{Q}=\left\{\left.\frac{m}{n} \right\rvert\, m, n \in \mathcal{N}\right\}$ 为正有理数集, $\mathcal{Q}$ 看起来比 $\mathcal{N}$ 大得多。然而,根据我们的定义,这两个集的大小相同。我们给出一个与 $\mathcal{N}$ 的一一对应,以表明 $\mathcal{Q}$ 是可数的。一个简单的方法是列出 $\mathcal{Q}$ 的所有元素。然后我们将列表中的第一个元素与 $\mathcal{N}$ 中的数字1配对,将列表中的第二个元素与 $\mathcal{N}$ 中的数字2配对,依此类推。我们必须确保 $\mathcal{Q}$ 的每个成员在列表中只出现一次。
这一段提出了一个比“偶数集”更反直觉的例子:证明正有理数集 $\mathcal{Q}$ 是可数的,即和自然数集 $\mathcal{N}$ 一样大。
- “现在我们来看一个更奇怪的例子。”:
- 预示着接下来的结论会更加挑战直觉。
- “如果我们设 $\mathcal{Q}=\left\{\left.\frac{m}{n} \right\rvert\, m, n \in \mathcal{N}\right\}$ 为正有理数集, $\mathcal{Q}$ 看起来比 $\mathcal{N}$ 大得多。”:
- 正有理数集 $\mathcal{Q}$ (Set of positive rational numbers): 所有可以表示为两个正整数 $m, n$ 之比 $\frac{m}{n}$ 的数。
- 为什么看起来大得多?: 在数轴上,任意两个不相等的自然数之间(比如1和2)没有其他自然数。但任意两个不相等的有理数之间,都存在无限多个其他有理数(这称为稠密性)。例如,在 $1/3$ 和 $1/2$ 之间,有 $2/5, 3/7, ...$ 无数个有理数。这使得 $\mathcal{Q}$ 看起来比 $\mathcal{N}$ “密集”得多。
- “然而,根据我们的定义,这两个集的大小相同。”:
- 再次强调,必须以定义4.12(是否存在一一对应)为准绳,而不是直觉。
- “我们给出一个与 $\mathcal{N}$ 的一一对应,以表明 $\mathcal{Q}$ 是可数的。”:
- 点明了证明策略:只要能成功构造出一个一一对应,就证明了 $\mathcal{Q}$ 是可数无限的,从而与 $\mathcal{N}$ 大小相同。
- “一个简单的方法是列出 $\mathcal{Q}$ 的所有元素。”:
- 将构造一一对应的问题,转化为一个更具体的操作:能否将 $\mathcal{Q}$ 的所有元素不重不漏地排成一个无限列表。如果能,列表的第 $k$ 个元素就自然地与自然数 $k$ 构成了一一对应。
- “我们必须确保 $\mathcal{Q}$ 的每个成员在列表中只出现一次。”:
- 这是一个技术上的要点。因为同一个有理数可以有多种表示法,例如 $1/2 = 2/4 = 3/6$。在列表中,我们只能保留其中一个,比如最简形式 $1/2$,其他的重复项需要被跳过。
- 有理数的稠密性示例1:
- 取两个自然数 5 和 6。它们之间没有其他自然数。
- 取两个有理数 $1/2$ 和 $1/3$。我们可以找到它们之间的中点 $\frac{1/2 + 1/3}{2} = \frac{5/6}{2} = 5/12$。我们还可以在 $1/2$ 和 $5/12$ 之间再找中点... 这个过程可以无限进行下去。
- 有理数表示的重复性示例2:
- 有理数“零点五”可以被表示为:
- $1/2$
- $2/4$
- $3/6$
- $50/100$
- ...
- 在构造列表时,当我们第一次遇到 $1/2$ 并将其加入列表后,之后遇到的所有 $2/4, 3/6, ...$ 都必须被忽略。
- 错误的列表示例: 如果我们试图这样列出所有有理数:
- 先列出所有分母为1的:$1/1, 2/1, 3/1, \dots$
- 这个列表本身就是无限长的,我们永远也到不了“列出所有分母为2的”那一步。
- 这说明,构造一个不重不漏的列表需要一个巧妙的顺序,一个简单的、线性的排序方法是行不通的。
本段提出了一个惊人的论断:看起来比自然数“多得多”的正有理数集 $\mathcal{Q}$,实际上和自然数集 $\mathcal{N}$ 大小相同。它将证明这一论断的任务,转化为了一个具体的操作性问题:设计一种巧妙的方法,将所有正有理数不重不漏地排成一个无限长的列表。
本段的目的是通过一个更具挑战性的例子,来深化读者对“可数性”和“一一对应”概念的理解。它展示了康托尔的方法有多么强大,能够处理像有理数集这样结构复杂的集合,并得出完全出乎意料的结论。这为最终使用对角化证明实数集“不可数”做了重要的对比和铺垫。
想象一个二维的、无限大的棋盘。棋盘上每个格子 $(m, n)$ 代表一个分数 $m/n$。自然数集就像是这个棋盘的第一行,无限延伸。而有理数集是整个无限大的二维平面。直觉上,一个二维平面上的点肯定比一条直线上的点多得多。本段就是要告诉你:不,通过一种巧妙的“扫描”方法,你可以把二维棋盘上所有的点都一一收集起来,排成一条直线。
你是一个图书管理员,要整理一个图书馆里所有的书。书的编号是“第m排,第n架”,比如(第1排,第1架),(第3排,第5架)。这是一个二维的索引系统。你想把所有的书都贴上一个一维的、连续的条形码:1, 2, 3, ...
- 错误方法: 先整理完第一排所有的书。因为第一排有无限多架,你永远也去不了第二排。
- 正确方法(即将介绍): 你需要一种“之”字形或者“螺旋形”的整理路线,确保你不会永远停留在一排或一列上,最终能访问到任何一本书。这个整理路线,就是构造一一对应的关键。
📜 [原文16]
为了得到这个列表,我们制作一个包含所有正有理数的无限矩阵,如图4.16所示。第 $i$ 行包含所有分子为 $i$ 的数字,第 $j$ 列包含所有分母为 $j$ 的数字。因此,数字 $\frac{i}{j}$ 出现在第 $i$ 行和第 $j$ 列中。
现在我们将这个矩阵变成一个列表。一个(不好的)尝试方法是,用第一行中的所有元素开始列表。这不是一个好方法,因为第一行是无限的,所以列表永远不会到达第二行。相反,我们列出对角线上的元素,这些元素叠加在图中,从角落开始。第一条对角线包含单个元素 $\frac{1}{1}$,第二条对角线包含两个元素 $\frac{2}{1}$ 和 $\frac{1}{2}$。因此,列表中的前三个元素是 $\frac{1}{1}, \frac{2}{1}$ 和 $\frac{1}{2}$。在第三条对角线中,出现了一个复杂情况。它包含 $\frac{3}{1}, \frac{2}{2}$ 和 $\frac{1}{3}$。如果我们简单地将这些添加到列表中,我们将重复 $\frac{1}{1}=\frac{2}{2}$。我们通过在出现重复时跳过一个元素来避免这种情况。所以我们只添加两个新元素 $\frac{3}{1}$ 和 $\frac{1}{3}$。以这种方式继续,我们得到 $\mathcal{Q}$ 的所有元素的列表。
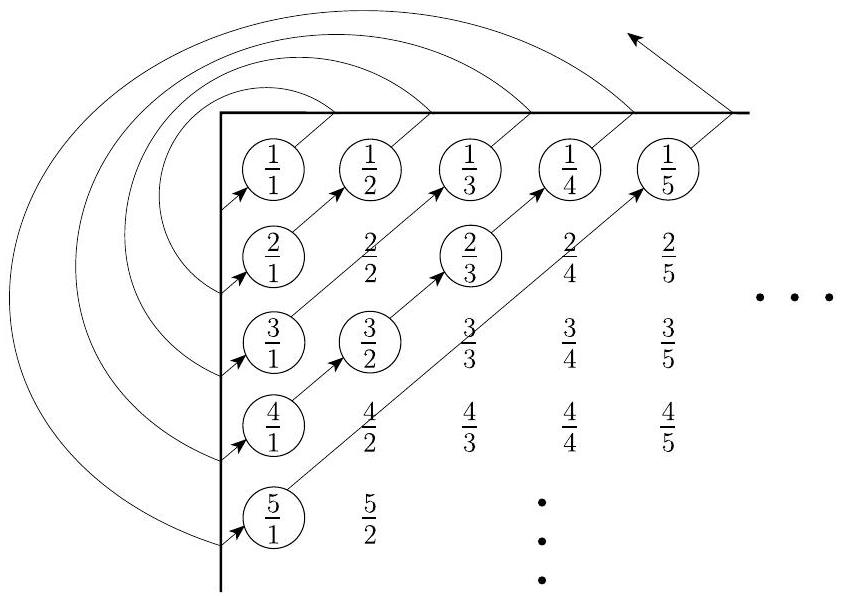
图 4.16
$\mathcal{N}$ 和 $\mathcal{Q}$ 的一一对应
这一段详细描述了如何通过“对角线”方法将二维的有理数矩阵转化为一维的列表,从而证明有理数集是可数的。
- “为了得到这个列表,我们制作一个包含所有正有理数的无限矩阵...”:
- 策略: 将所有正有理数 $\frac{m}{n}$ 安排在一个二维的网格(矩阵)中。
- 规则: 第 $i$ 行放所有分子为 $i$ 的数,第 $j$ 列放所有分母为 $j$ 的数。
- 结果: 格子 $(i, j)$ 里的数就是 $\frac{i}{j}$。这个矩阵覆盖了所有可能的正有理数(尽管有重复)。
- “现在我们将这个矩阵变成一个列表。”:
- 任务是从这个二维的、无限大的矩阵中,按照某个顺序把所有元素“捡”出来,排成一队。
- “一个(不好的)尝试方法是,用第一行中的所有元素开始列表...列表永远不会到达第二行。”:
- 再次排除了按行或按列的简单方法。因为每一行、每一列都是无限的,一旦开始就无法结束,导致遗漏掉其他所有行/列。
- “相反,我们列出对角线上的元素...从角落开始。”:
- 提出了巧妙的解决方案:沿着对角线方向遍历。
- 对角线定义: 这里的“对角线”指的是“左下到右上”方向的斜线。一条对角线上的所有元素 $(i, j)$ 的行号和列号之和 $i+j$ 是一个常数。
- 第一条对角线: $i+j=2$, 只有 $(1,1)$ -> $\frac{1}{1}$。
- 第二条对角线: $i+j=3$, 有 $(2,1), (1,2)$ -> $\frac{2}{1}, \frac{1}{2}$。
- 第三条对角线: $i+j=4$, 有 $(3,1), (2,2), (1,3)$ -> $\frac{3}{1}, \frac{2}{2}, \frac{1}{3}$。
- ...
- “第一条对角线...第二条对角线...第三条对角线...”:
- 逐步展示了遍历过程。关键在于,每一条对角线都是有限长的。第 $k$ 条对角线($i+j=k+1$)上有 $k$ 个元素。
- 因此,我们可以遍历完一条对角线,然后接着遍历下一条,保证我们总能前进到新的对角线。
- “在第三条对角线中,出现了一个复杂情况...我们通过在出现重复时跳过一个元素来避免这种情况。”:
- 处理了之前提到的重复表示问题。当遇到一个数,如 $\frac{2}{2}$,我们检查它化简后的形式 $\frac{1}{1}$ 是否已经在我们的列表中。
- $\frac{1}{1}$ 在第一条对角线时已经被加入列表了,所以我们跳过 $\frac{2}{2}$。
- 这个“检查并跳过”的步骤确保了最终的列表是“不重”的。
- “以这种方式继续,我们得到 $\mathcal{Q}$ 的所有元素的列表。”:
- 不重: 通过跳过重复项保证。
- 不漏: 任何一个正有理数 $\frac{m}{n}$ 都位于这个无限矩阵的第 $m$ 行、第 $n$ 列。它属于 $i+j=m+n$ 这条对角线。因为我们的遍历方法会依次访问所有的对角线,所以任何一个有理数终将在有限的步骤内被我们访问到。
- 结论: 既然我们能将 $\mathcal{Q}$ 的所有元素排成一个不重不漏的无限列表,那么 $\mathcal{Q}$ 就是可数的。
我们来手动生成这个列表的前几个元素:
- 对角线1 (i+j=2):
- 元素: $\frac{1}{1}$。
- 是否重复: 否。
- 列表: [$\frac{1}{1}$]
- 对角线2 (i+j=3):
- 元素: $\frac{2}{1}, \frac{1}{2}$。
- 是否重复: 否。
- 列表: [$\frac{1}{1}, \frac{2}{1}, \frac{1}{2}$]
- 对角线3 (i+j=4):
- 元素: $\frac{3}{1}, \frac{2}{2}, \frac{1}{3}$。
- 检查 $\frac{2}{2}$: 化简为 $\frac{1}{1}$,已在列表中。跳过。
- 列表: [$\frac{1}{1}, \frac{2}{1}, \frac{1}{2}, \frac{3}{1}, \frac{1}{3}$]
- 对角线4 (i+j=5):
- 元素: $\frac{4}{1}, \frac{3}{2}, \frac{2}{3}, \frac{1}{4}$。
- 是否重复: 否。
- 列表: [$\frac{1}{1}, \frac{2}{1}, \frac{1}{2}, \frac{3}{1}, \frac{1}{3}, \frac{4}{1}, \frac{3}{2}, \frac{2}{3}, \frac{1}{4}$]
- 对角线5 (i+j=6):
- 元素: $\frac{5}{1}, \frac{4}{2}, \frac{3}{3}, \frac{2}{4}, \frac{1}{5}$。
- 检查 $\frac{4}{2}$: 化简为 $\frac{2}{1}$,已在列表中。跳过。
- 检查 $\frac{3}{3}$: 化简为 $\frac{1}{1}$,已在列表中。跳过。
- 检查 $\frac{2}{4}$: 化简为 $\frac{1}{2}$,已在列表中。跳过。
- 列表: [$\frac{1}{1}, \frac{2}{1}, \frac{1}{2}, \frac{3}{1}, \frac{1}{3}, \frac{4}{1}, \frac{3}{2}, \frac{2}{3}, \frac{1}{4}, \frac{5}{1}, \frac{1}{5}$]
这个过程可以无限进行下去,最终将所有正有理数都囊括进来。
- 对角线方向: 这里的对角线是从左下到右上,也可以采用从左上到右下的“之”字形(Z-scan)等其他遍历方式,只要能保证遍历完所有有限的“块”并且总能前进到下一个“块”,都是有效的。
- 证明的完备性: 严格的证明需要两点:(1) 证明任何有理数都会在这个遍历中出现(不漏)。(2) 证明这个列表可以和自然数建立一一对应(可数)。我们已经通过构造过程直观地说明了这两点。
本段详细演示了证明正有理数集 $\mathcal{Q}$ 可数的具体方法。该方法首先将所有正有理数(包括重复表示)排列成一个无限大的二维矩阵,然后通过沿对角线方向的巧妙遍历,将这个二维矩阵中的元素转化成一个一维的无限列表。在遍历过程中,通过跳过重复出现的有理数,保证了列表中的元素是独一无二的。因为成功地将 $\mathcal{Q}$ 排成了一个列表,从而证明了 $\mathcal{Q}$ 是可数的,其大小与自然数集 $\mathcal{N}$ 相同。
本段的目的是提供一个构造性证明,展示如何处理一个看似比自然数集“更密集”的集合,并证明其可数性。这个“对角线遍历法”是集合论中一个经典的、强大的技巧,用于将二维的可数对象映射到一维上。它进一步强化了读者对“可数性”这一概念的理解,并为后续介绍“不可数”的对角化方法形成了鲜明对比。
回到二维棋盘的例子。对角线方法就像这样扫描棋盘:
- 先拿走 (1,1) 位置的棋子。
- 再拿走 (1,2) 和 (2,1) 位置的棋子。
- 再拿走 (1,3), (2,2), (3,1) 位置的棋子。
...
你不是一行一行地拿,而是一条斜线一条斜线地拿。因为每条斜线都是有限长的,你总能拿完,然后移动到下一条更长的斜线。这样可以保证,棋盘上任何一个位置 $(m, n)$ 的棋子,你最终都会拿到它。
想象你在一个巨大的玉米迷宫里收玉米。迷宫是无限大的,由无数行列的玉米组成。
- 笨方法: 沿着第一行一直走下去收。你会永远迷失在第一行,收不到其他行的玉米。
- 对角线方法: 你斜着走。先收第一条斜线上的玉米,然后是第二条、第三条... 每一条斜线都只有有限数量的玉米,你总能收完。然后你就可以进入下一条斜线。这种方法保证了迷宫里任何一株玉米最终都会被你收到。你把所有收到的玉米按顺序放进你的篮子,就形成了一个可数的列表。
4.3 不可数集与对角化论证
📜 [原文17]
在看到 $\mathcal{N}$ 和 $\mathcal{Q}$ 的一一对应之后,你可能会认为任何两个无限集都可以被证明具有相同的大小。毕竟,你只需要证明一个一一对应,这个例子表明确实存在令人惊讶的一一对应。然而,对于某些无限集,不存在与 $\mathcal{N}$ 的一一对应。这些集太大了。这样的集称为不可数。
这一段是过渡,从证明了多个集合是“可数的”,转向引入“不可数”的概念,预示着存在一个大小的“新层次”。
- “在看到 $\mathcal{N}$ 和 $\mathcal{Q}$ 的一一对应之后,你可能会认为任何两个无限集都可以被证明具有相同的大小。”:
- 描述了一种在学习了前几个例子后可能产生的自然推断。我们已经看到了反直觉的例子($\mathcal{N}$ 和 $\mathcal{E}$,$\mathcal{N}$ 和 $\mathcal{Q}$),它们都表明一些看起来“更大”的集合实际上和 $\mathcal{N}$ 一样大。这很容易让人觉得,也许所有无限集都一样大。
- “毕竟,你只需要证明一个一一对应,这个例子表明确实存在令人惊讶的一一对应。”:
- 解释了产生上述推断的原因。证明“一样大”只需要找到一个巧妙的一一对应即可。而证明有理数集可数的例子,展示了这种一一对应可以多么地“令人惊讶”和“反直觉”。如果连如此“稠密”的有理数集都能被“拉直”成一条线,那还有什么不能呢?
- “然而,对于某些无限集,不存在与 $\mathcal{N}$ 的一一对应。”:
- 一个巨大的转折,否定了前面的推断。这说明无限的世界里,大小确实是有不同等级的。
- “这些集太大了。”:
- 用非常直白的语言描述了原因。它们的“无限”程度,比自然数的“无限”程度要高一个层次,以至于你永远无法将它们与自然数一一配对。
- “这样的集称为不可数。”:
- 给出了这类“更大”的无限集的正式名称:不可数集 (Uncountable Set)。
- 定义: 一个集合是不可数的,如果它是一个无限集,并且它不能与自然数集 $\mathcal{N}$ 建立一一对应。
- 换句话说,你永远无法将一个不可数集的所有元素不重不漏地排成一个(无限)列表。
- 可数集(已经知道的):
- 自然数 $\mathcal{N} = \{1, 2, 3, \ldots\}$
- 偶数 $\mathcal{E} = \{2, 4, 6, \ldots\}$
- 整数 $\mathbb{Z} = \{\ldots, -1, 0, 1, \ldots\}$
- 有理数 $\mathcal{Q}$
- 不可数集(即将证明的):
- 实数集 $\mathcal{R}$。这个集合包含了所有的整数、有理数,以及像 $\pi$ (3.14159...)、$\sqrt{2}$ (1.41421...) 这样的无理数。
- [0, 1]区间内的所有实数。令人惊讶的是,仅仅这个小区间内的实数,就已经是不可数的了。
- 误解: 认为“不可数”只是“我们还没找到列出它们的方法”。
- 澄清: 不是。不可数是一个否定性的证明。我们将要证明的是,不可能存在这样一种列出它们的方法。证明不是说“我试了A、B、C三种方法都失败了”,而是“对于任何一种你可能想到的列出方法,我都能指出它的漏洞”。
本段是一个重要的转折点。它首先指出了在学习了有理数集可数后容易产生的误判——即所有无限集都一样大。然后,它果断地否定了这一猜想,并正式引入了“不可数集”的概念,即那些“太大”而无法与自然数集建立一一对应的无限集合。
本段的目的是在可数无限之上,引入一个新的、更大的无限等级——不可数无限。它为康托尔的对角化论证设置了最终的目标:证明实数集就是这样一个不可数集的例子。这使得整个关于集合大小的讨论进入了高潮。
“无限”有两种。
- 第一种,可数的无限 (Countable Infinity): 就像一条无限长的路,路上每隔一米有一个标记(1, 2, 3, ...)。虽然路是无限长的,但你可以沿着它走,并且确信你最终会经过每一个标记。自然数、整数、有理数都是这种无限。
- 第二种,不可数的无限 (Uncountable Infinity): 就像一片无限大的、连续的雾。你无法在雾中“走过每一个点”。你随便走一步,无论多小,你都错过了无限多个点。实数就是这种无限。它是一种“连续”的、“无缝”的无限。
回到沙滩和沙粒的例子。
- 可数集: 想象沙滩上有一条无限长的线,所有的沙粒都整齐地排列在这条线上。你可以沿着线走,一颗一颗地捡起它们。
- 不可数集: 想象整个无限大的沙滩本身。沙粒不是排成一列,而是铺满了整个平面。你无法用一条线穿过每一颗沙粒。你随便画一条线,线上有可数的沙粒,但线外还有不可数的沙粒。不可数的量级远大于可数。
📜 [原文18]
实数集就是一个不可数集的例子。实数是具有小数表示的数字。数字 $\pi=3.1415926 \ldots$ 和
$\sqrt{2}=1.4142135 \ldots$ 是实数的例子。设 $\mathcal{R}$ 是实数集。康托尔证明了 $\mathcal{R}$ 是不可数的。在证明过程中,他引入了对角化方法。
这段话明确指出了第一个即将被证明为不可数的集合——实数集 $\mathcal{R}$,并点明证明方法就是对角化。
- “实数集就是一个不可数集的例子。”:
- 给出了不可数集的第一个,也是最经典的一个范例。
- “实数是具有小数表示的数字。”:
- 给出了实数 (Real Numbers) 的一个直观定义。它可以是有限小数(如0.5)、无限循环小数(如1/3 = 0.333...),或者无限不循环小数(如 $\pi$)。
- 在数轴上,实数与所有的点一一对应,没有任何“空隙”。
- “数字 $\pi=3.1415926 \ldots$ 和 $\sqrt{2}=1.4142135 \ldots$ 是实数的例子。”:
- 举了两个著名的无理数 (Irrational Numbers) 作为实数的例子。无理数是那些不能表示为两个整数之比的数,它们的小数表示是无限不循环的。正是这些“无限不循环”的数的加入,使得实数集从有理数集的可数“飞跃”到了不可数。
- “设 $\mathcal{R}$ 是实数集。”:
- 引入标准符号 $\mathcal{R}$ 来代表实数集。
- “康托尔证明了 $\mathcal{R}$ 是不可数的。”:
- 重申了这是康托尔的重大发现。
- “在证明过程中,他引入了对角化方法。”:
- 点明了对角化方法与证明实数集不可数之间的直接历史联系。之前我们用对角线遍历证明了有理数可数,现在我们将看到一个名字相似但思想有别的“对角化论证”来证明实数不可数。这是两种不同的技术。
- 实数示例1 (有理数):
- $1/2 = 0.5$ (有限小数)
- $1/8 = 0.125$ (有限小数)
- $1/3 = 0.33333...$ (无限循环小数)
- $4/7 = 0.571428571428...$ (无限循环小数)
- 实数示例2 (无理数):
- $\sqrt{2} = 1.41421356237...$ (无限不循环小数)
- $\pi = 3.14159265358...$ (无限不循环小数)
- $e = 2.71828182845...$ (无限不循环小数)
- 对角线遍历 vs 对角化论证:
- 对角线遍历 (Dovetailing): 是一种构造性的方法,用来证明某个集合是可数的。它通过一种巧妙的顺序,成功地将集合元素排成了一个列表。
- 对角化论证 (Diagonalization Argument): 是一种反证法,用来证明某个集合是不可数的。它假设该集合可以被排成一个列表,然后通过构造一个不在列表中的“幽灵”元素,来推导出矛盾。
- 这两个名字里都有“对角线”,但用途和逻辑完全相反。一个是“扫全”,一个是“找茬”。
本段正式将实数集 $\mathcal{R}$ 作为不可数集的代表推向前台,并明确指出,康托尔正是通过发明对角化方法来证明 $\mathcal{R}$ 的不可数性的。它为接下来的核心证明设定了具体的目标和方法。
本段的目的是完成从一般概念(不可数集)到具体实例(实数集)的聚焦,并正式将“对角化”这一术语与即将到来的证明联系起来,让读者准备好迎接一个全新的、基于反证法的证明思路。
我们已经知道有理数像一条无限长的路上每隔一段距离就有的标记,虽然标记之间还有空隙,但所有标记可以被编号。现在,实数集是把这条路上所有的空隙都“填满”了,它是一条连续的路本身。康托尔的证明就是要说明,你无法给这条连续的路上的“每一个点”都进行编号。
想象一条河流。
- 有理数集: 就像河里漂浮的树叶。虽然树叶有无限多片,而且看起来很密集,但你理论上可以派一只小船,按照某种路线(对角线遍历),把每一片树叶都捞起来并编号。
- 实数集: 就像河水本身。你无法“捞起每一个水分子并编号”。水是连续的,你随便捞一勺,里面都有无限多的水分子,而且勺与勺之间还有无限多的水分子。对角化就是要证明,这种“连续”的体量,是无法被离散的自然数所“数尽”的。
📜 [原文19]
定理 (THEOREM) 4.17
$\mathcal{R}$ 是不可数的。
证明:为了表明 $\mathcal{R}$ 是不可数的,我们表明 $\mathcal{N}$ 和 $\mathcal{R}$ 之间不存在一一对应。该证明采用反证法。假设 $\mathcal{N}$ 和 $\mathcal{R}$ 之间存在一个一一对应 $f$。我们的任务是表明 $f$ 未能按其应有的方式工作。为了使其成为一一对应, $f$ 必须将 $\mathcal{N}$ 的所有成员与 $\mathcal{R}$ 的所有成员配对。但我们将发现 $\mathcal{R}$ 中存在一个 $x$,它未与 $\mathcal{N}$ 中的任何事物配对,这将是我们的矛盾。
这是康托尔对角化证明的开端。本段阐述了证明的整体思路——反证法。
- “$\mathcal{R}$ 是不可数的。”:
- 这是定理4.17的陈述,即我们要证明的结论。
- “证明:为了表明 $\mathcal{R}$ 是不可数的,我们表明 $\mathcal{N}$ 和 $\mathcal{R}$ 之间不存在一一对应。”:
- 根据定义4.14,证明“不可数”就是证明“不能与 $\mathcal{N}$ 建立一一对应”。这是一个否定性的证明目标。
- “该证明采用反证法。”:
- 反证法 (Proof by contradiction): 一种间接证明方法。要证明命题P为真,我们先假设P为假(即非P为真),然后从这个假设出发,通过一系列逻辑上无误的推导,得出一个矛盾(比如 $A$ 且 非$A$)。因为矛盾是不可能成立的,所以我们最初的假设(非P为真)必定是错误的。因此,P必须为真。
- 这是证明“不存在”这类命题的强大工具。
- “假设 $\mathcal{N}$ 和 $\mathcal{R}$ 之间存在一个一一对应 $f$。”:
- 这是反证法的第一步:做出与结论相反的假设。
- 我们假设 $\mathcal{R}$ 是可数的。这意味着,我们可以将所有的实数不重不漏地排成一个无限列表。这个列表就是一一对应 $f$ 的体现:
- $f(1)$ = 列表中的第一个实数
- $f(2)$ = 列表中的第二个实数
- ...
- $f(n)$ = 列表中的第n个实数
- 这个假设意味着,这个列表包含了所有的实数。
- “我们的任务是表明 $f$ 未能按其应有的方式工作。”:
- 阐明了推导出矛盾的具体方向。我们要证明这个一一对应 $f$ (或者说这个列表)名不副实。
- “为了使其成为一一对应, $f$ 必须将 $\mathcal{N}$ 的所有成员与 $\mathcal{R}$ 的所有成员配对。”:
- 重申了一一对应的满射性质:$\mathcal{R}$ 中的每一个元素都必须在这个列表里出现。
- “但我们将发现 $\mathcal{R}$ 中存在一个 $x$,它未与 $\mathcal{N}$ 中的任何事物配对,这将是我们的矛盾。”:
- 这是整个证明的核心和最精彩的部分。
- 策略: 我们将要构造一个特殊的实数 $x$。
- 这个 $x$ 的构造方法将保证它与列表中的第一个数 $f(1)$ 不同,与第二个数 $f(2)$ 不同,与第 $n$ 个数 $f(n)$ 也不同... 最终,它与列表中的任何一个数都不同。
- 矛盾:
- 一方面,我们假设列表(由 $f$ 定义)已经包含了所有的实数。
- 另一方面,我们又找到了一个实数 $x$,它不在这个列表中。
- 一个集合不可能既“包含所有实数”,又“不包含实数 $x$”。这个矛盾说明我们最初的假设——“存在这样一个列表 $f$”——是错误的。
- 因此,$\mathcal{R}$ 必然是不可数的。
- 反证法示例1 (证明 $\sqrt{2}$ 是无理数):
- 假设: $\sqrt{2}$ 是有理数。
- 推论: 那么 $\sqrt{2} = m/n$,其中 $m, n$ 是互质的整数。
- 推导: $2 = m^2/n^2 \Rightarrow m^2 = 2n^2$。这表明 $m^2$ 是偶数,所以 $m$ 也必然是偶数。设 $m=2k$。
- 代入: $(2k)^2 = 2n^2 \Rightarrow 4k^2 = 2n^2 \Rightarrow n^2 = 2k^2$。这表明 $n^2$ 也是偶数,所以 $n$ 也必然是偶数。
- 矛盾: $m$ 和 $n$ 都是偶数,这与它们“互质”(没有除1以外的公因数)的假设相矛盾。
- 结论: 最初的假设是错误的。$\sqrt{2}$ 必然是无理数。
- 对角化证明的逻辑结构:
- 假设: 所有实数能被列成一个清单。
- 构造: 制造一个新实数 $x_{new}$,它和清单上第1个实数的第1位小数不同,和第2个实数的第2位小数不同,...
- 推论: $x_{new}$ 和清单上所有的实数都不同。
- 矛盾: 这个清单号称包含了“所有”实数,但 $x_{new}$ 却不在其中。
- 结论: 最初的假设是错误的。实数不能被列成清单。
- 证明的焦点: 证明的关键不在于找到一个具体的一一对应函数(这是证明可数时做的),而在于证明任何可能的一一对应函数都会失败。反证法通过假设存在一个任意的、未知的一一对应 $f$ 开始,证明了它的荒谬性,从而对所有可能的 $f$ 都有效。
本段清晰地勾勒出了即将展开的对角化证明的逻辑框架。它采用反证法,首先假设实数集 $\mathcal{R}$ 是可数的(即存在一个能列出所有实数的一一对应 $f$)。然后,证明的核心任务将是去构造一个特殊的实数 $x$,这个 $x$ 被精确地设计为与该假设列表中的每一个实数都不同,从而导致“列表已包含所有实数”的假设产生矛盾,最终证明实数集是不可数的。
本段的目的是让读者在进入具体的构造细节之前,先从宏观上理解整个证明的战略。通过清晰地阐述反证法的步骤和矛盾的来源,它为读者提供了一张路线图,使接下来的技术细节能够被正确地放置在整个逻辑框架中,而不是显得孤立和晦涩。
“唱反调”模型。
- 张三吹牛: “我的相册里有世界上所有人的照片!” (假设:列表是完备的)
- 你来找茬: 你指着张三自己说:“那你的照片在不在里面?”
- 张三的困境:
- 如果张三的照片在相册里,那这张照片里的人(张三)正在看着一本“没有他自己的照片”的相册,矛盾。
- 如果张三的照片不在相册里,那张三的牛皮“有所有人的照片”就破了,矛盾。
- 结论: 张三的牛皮吹破了。对角化的核心思想与此类似,都是通过构造一个“自我指涉”的悖论来戳穿一个“全集”的宣称。
你面对一个宣称能“列出所有可能的故事”的“故事大全”列表。
- 假设: 这个列表是完整的。
- 构造一个新故事: 你开始写一个新故事,故事的主角是一个人,他正在读这本“故事大全”。你的故事情节是这样设计的:
- 新故事的第一段,要和“故事大全”里第1个故事的第一段不同。
- 新故事的第二段,要和“故事大全”里第2个故事的第二段不同。
- ...
- 新故事的第n段,要和“故事大全”里第n个故事的第n段不同。
- 结论: 你写出的这个新故事,和列表里的任何一个故事都至少有一个段落不同。因此,你的新故事不在这个“故事大全”里。
- 矛盾: “故事大全”宣称包含了所有故事,但却没有你刚刚创作的这个故事。
- 最终结论: 能列出所有可能故事的“故事大全”是不可能存在的。这个构造新故事的方法,就是对角化。
📜 [原文20]
我们通过实际构造 $x$ 来找到这个 $x$。我们选择 $x$ 的每个数字,以使 $x$ 与与 $\mathcal{N}$ 中的元素配对的实数中的一个不同。最后,我们确信 $x$ 不同于任何已配对的实数。
我们可以通过举例来说明这个想法。假设存在一一对应 $f$。设 $f(1)=3.14159 \ldots, f(2)=55.55555 \ldots, f(3)=\ldots$,依此类推,只是为了编造一些 $f$ 的值。然后 $f$ 将数字1与 $3.14159 \ldots$ 配对,将数字2与 $55.55555 \ldots$ 配对,依此类推。下表显示了 $\mathcal{N}$ 和 $\mathcal{R}$ 之间假设的一一对应 $f$ 的一些值。
| $n$ | $f(n)$ |
|---|---|
| 1 | $3.14159 \ldots$ |
| 2 | $55.55555 \ldots$ |
| 3 | $0.12345 \ldots$ |
| 4 | $0.50000 \ldots$ |
| $\vdots$ | $\vdots$ |
我们通过给出其小数表示来构造所需的 $x$。它是一个介于0和1之间的数字,因此其所有有效数字都是小数点后的小数位。我们的目标是确保对于任何 $n$, $x \neq f(n)$。为了确保 $x \neq f(1)$,我们让 $x$ 的第一位数字与 $f(1)=3.14159 \ldots$ 的第一个小数位1不同。我们任意地将其设为4。为了确保 $x \neq f(2)$,我们让 $x$ 的第二位数字与 $f(2)=55.555555 \ldots$ 的第二个小数位5不同。我们任意地将其设为6。 $f(3)=0.12 \underline{3} 45 \ldots$ 的第三个小数位是3,所以我们让 $x$ 是任何不同的数字——例如4。以这种方式沿着 $f$ 表的对角线继续,我们得到 $x$ 的所有数字,如下表所示。我们知道 $x$ 不是任何 $f(n)$,因为它与 $f(n)$ 在第 $n$ 个小数位上不同。(一个小问题出现了,因为某些数字,例如 $0.1999 \ldots$ 和 $0.2000 \ldots$,即使它们的小数表示不同,也相等。我们在构造 $x$ 时从不选择数字0或9来避免这个问题。)
| $n$ | $f(n)$ | |
|---|---|---|
| 1 | $3.14159 \ldots$ | |
| 2 | $55.55555 \ldots$ | |
| 3 | $0.12 \underline{3} 45 \ldots$ | $x=0.4641 \ldots$ |
| 4 | $0.500 \underline{0} 0 \ldots$ | |
| $\vdots$ | $\vdots$ |
这一长段是对角化论证的核心,它通过一个具体的例子,展示了如何构造那个特殊的、不存在于假设列表中的实数 $x$。
- “我们通过实际构造 $x$ 来找到这个 $x$。”:
- 这不是一个存在性证明(只证明存在但不指出是什么),而是一个构造性的证明(明确给出构造方法)。
- “假设存在一一对应 $f$ ... 下表显示了...一些值”:
- 根据反证法的假设,存在一个能列出所有实数的列表 $f$。这里为了便于理解,给出了这个假设列表的一个具体例子。
- $f(1) = 3.14159\dots$
- $f(2) = 55.55555\dots$
- $f(3) = 0.12345\dots$
- $f(4) = 0.50000\dots$
- 这个列表只是一个示意,对角化的逻辑对任何可能的列表都成立。
- “我们通过给出其小数表示来构造所需的 $x$。”:
- 开始构造那个“捣蛋鬼”实数 $x$。我们一位一位地来确定它的小数部分。
- 为了简化,我们构造的 $x$ 是一个 0 到 1 之间的小数。即使我们只证明 (0, 1) 区间内的实数是不可数的,也就足以证明整个实数集 $\mathcal{R}$ 是不可数的。
- “我们的目标是确保对于任何 $n$, $x \neq f(n)$。”:
- 明确了构造 $x$ 的唯一目标:让它和列表里的每一个数都不同。
- “为了确保 $x \neq f(1)$,我们让 $x$ 的第一位数字与 $f(1)=3.14159 \ldots$ 的第一个小数位1不同。我们任意地将其设为4。”:
- 关键步骤1: 盯着列表的第1行 ($f(1)$) 的小数点后第1位。
- $f(1)$ 的小数点后第1位是 1。
- 我们构造的 $x$ 的小数点后第1位就必须不等于1。我们可以选2, 3, 4, 5, 6, 7, 8 中任何一个,这里选了 4。
- 现在我们知道 $x = 0.4...$。无论 $x$ 后面是什么,它的小数点后第1位是4,而 $f(1)$ 的是1,所以我们保证了 $x \neq f(1)$。
- “为了确保 $x \neq f(2)$,我们让 $x$ 的第二位数字与 $f(2)=55.555555 \ldots$ 的第二个小数位5不同。我们任意地将其设为6。”:
- 关键步骤2: 盯着列表的第2行 ($f(2)$) 的小数点后第2位。
- $f(2)$ 的小数点后第2位是 5。
- 我们构造的 $x$ 的小数点后第2位就必须不等于5。这里选了 6。
- 现在 $x = 0.46...$。我们保证了 $x \neq f(2)$,因为它在小数点后第2位上与 $f(2)$ 不同。
- “$f(3)=0.12 \underline{3} 45 \ldots$ 的第三个小数位是3,所以我们让 $x$ 是任何不同的数字——例如4。”:
- 关键步骤3: 盯着列表的第3行 ($f(3)$) 的小数点后第3位。
- $f(3)$ 的小数点后第3位是 3。
- 我们构造的 $x$ 的小数点后第3位就必须不等于3。这里选了 4。
- 现在 $x = 0.464...$。我们保证了 $x \neq f(3)$。
- “以这种方式沿着 $f$ 表的对角线继续...”:
- 命名来源: 这个过程被称为对角化,因为我们用来构造 $x$ 的每一位数字,都恰好是跟列表形成的矩阵的“对角线”上的数字($f(1)$的第1位,$f(2)$的第2位,$f(3)$的第3位...)进行比较和作对。
- “我们知道 $x$ 不是任何 $f(n)$,因为它与 $f(n)$ 在第 $n$ 个小数位上不同。”:
- 一般化结论: 对于列表中的任意第 $n$ 个数 $f(n)$,我们构造的 $x$ 在小数点后第 $n$ 位上的数字,就是特意取得与 $f(n)$ 的小数点后第 $n$ 位不同。
- 因此,$x$ 与 $f(1)$ 不同,与 $f(2)$ 不同,...,与 $f(n)$ 不同,... 它与列表中的每一个数都不同。
- “(一个小问题出现了...我们在构造 $x$ 时从不选择数字0或9来避免这个问题。)”:
- 这是一个技术上的严谨性处理。
- 问题: 实数的小数表示不是唯一的。例如,$0.1999...$ 和 $0.2000...$ 其实是同一个数。
- 风险: 如果我们构造的 $x$ 是 $0.4999...$,而列表中的某个 $f(k)$ 是 $0.5000...$,我们可能会错误地认为它们不同,但实际上它们是同一个数。
- 解决方案: 在构造 $x$ 的每一位时,我们只从 {1, 2, 3, 4, 5, 6, 7, 8} 中选择,刻意避开 0 和 9。这样构造出来的 $x$ 就不可能以无限的0或9结尾,从而保证了它的小数表示是唯一的,避免了上述的歧义。
假设的列表 $f$:
$f(1) = 3.14159\dots$
$f(2) = 55.55555\dots$
$f(3) = 0.12345\dots$
$f(4) = 0.50000\dots$
$f(5) = 8.12942\dots$
...
构造 $x = 0.d_1 d_2 d_3 d_4 d_5 \dots$:
- $d_1$: $f(1)$ 的小数点后第1位是 1。我们选 $d_1 = 4$ (不等于1)。
- $x=0.4...$
- $d_2$: $f(2)$ 的小数点后第2位是 5。我们选 $d_2 = 6$ (不等于5)。
- $x=0.46...$
- $d_3$: $f(3)$ 的小数点后第3位是 3。我们选 $d_3 = 4$ (不等于3)。
- $x=0.464...$
- $d_4$: $f(4)$ 的小数点后第4位是 0。我们选 $d_4 = 1$ (不等于0)。
- $x=0.4641...$
- $d_5$: $f(5)$ 的小数点后第5位是 2。我们选 $d_5 = 3$ (不等于2)。
- $x=0.46413...$
...
这个被构造出来的实数 $x=0.46413...$
- 它不等于 $f(1)$ (因为第1位小数不同)。
- 它不等于 $f(2)$ (因为第2位小数不同)。
- 它不等于 $f(3)$ (因为第3位小数不同)。
- ...
- 它不等于任何一个 $f(n)$。
我们找到了一个不在假设的“完整列表”中的实数。矛盾产生。
- 整数部分: 我们构造的 $x$ 在0和1之间,但列表中的数 $f(n)$ 可以是任意大小的实数。这有影响吗?没有。因为 $x$ 与 $f(n)$ 只要有一位小数不同,它们就肯定不是同一个数。整数部分是什么完全不影响论证。
- 选择规则: 构造 $x$ 的第 $n$ 位小数 $d_n$ 时,只要它不等于 $f(n)$ 的第 $n$ 位小数(并且不是0或9)即可。规则可以很简单,比如:“如果 $f(n)$ 的第 $n$ 位是 $k$,我的 $d_n$ 就是 $(k \pmod 8) + 1$”。这个规则保证了结果在1到8之间,并且与 $k$ 不同(除非 $k$ 恰好等于 $(k \pmod 8) + 1$,可以设计更完美的规则,比如"如果k是1,我选2;如果k不是1,我选1")。
本段是对角化论证的核心执行步骤。它通过一个实例,生动地展示了如何利用一个假设存在的“所有实数的列表”来构造一个新实数 $x$。构造的方法是让 $x$ 的第 $n$ 位小数与列表中第 $n$ 个实数的第 $n$ 位小数故意不一样。这个沿着对角线“捣蛋”的构造过程,保证了 $x$ 与列表中的每一个实数都不同,从而证明 $x$ 不在该列表中。这直接与“列表包含所有实数”的初始假设相矛盾。
本段的目的是将对角化证明从抽象的逻辑框架落实到具体的操作层面。通过一个清晰的、可跟随的例子,它让读者能够自己“动手”构造出那个导致矛盾的元素,从而深刻理解对角化为何能成为一个有效的反证法工具。这是整个证明中最关键、最需要动手理解的部分。
“叛逆者”模型。
假设有一个“完美服从俱乐部”,宣称俱乐部里的每个人都绝对服从。成员按 1, 2, 3, ... 编号。
规则: 第 $n$ 号成员必须服从第 $n$ 条命令。
假设: 俱乐部是“完美服从”的。
构造一个叛逆者 $x$: 这个人 $x$ 的行为准则是:“对于第 $n$ 条命令,我的做法要和第 $n$ 号成员的做法相反。”
提问: 这个叛逆者 $x$ 是不是俱乐部成员?假设他是第 $k$ 号成员。
矛盾:
- 作为第 $k$ 号成员,他必须服从第 $k$ 条命令。
- 但根据他的行为准则,他对第 $k$ 条命令的做法,必须和第 $k$ 号成员(也就是他自己)的做法相反。
- 他必须同时“服从”又“不服从”第 $k$ 条命令。这是不可能的。
结论: 叛逆者 $x$ 不可能是俱乐部成员。因此,“完美服从俱乐部”的宣称是假的,因为它无法包含这个叛逆者。
理发师悖论的变体。
假设: 村里有一个理发师,他立下规矩:“我给且只给村里所有不给自己理发的人理发。”
提问: 理发师要不要给自己理发?
矛盾:
- 如果他给自己理发,他就属于“给自己理发的人”,根据规矩,他不应该给自己理发。
- 如果他不给自己理发,他就属于“不给自己理发的人”,根据规矩,他恰好应该给自己理发。
结论: 这样的理发师和他立下的规矩,在逻辑上不可能存在。对角化论证与此共享了“自我指涉”导致悖论的核心。我们构造的那个数 $x$,就像这个理发师,它的定义依赖于整个列表,最终导致它自身无法被列表所容纳。
4.4 不可识别语言的存在性
📜 [原文21]
前面的定理对计算理论有着重要的应用。它表明有些语言是不可判定的,甚至不是图灵可识别的,原因在于语言是不可数的,而图灵机只有可数个。因为每台图灵机只能识别一种语言,并且语言的数量多于图灵机的数量,所以有些语言不被任何图灵机识别。这样的语言是图灵不可识别的,正如我们在以下推论中所述。
这一段将刚刚证明的关于集合大小的纯数学结论(实数集不可数),应用到计算理论中,得出了一个关于语言和图灵机的惊人推论。
- “前面的定理对计算理论有着重要的应用。”:
- 说明定理4.17(实数集不可数)不仅仅是一个数学趣闻,它将成为我们理论体系中的一个关键工具。
- “它表明有些语言是不可判定的,甚至不是图灵可识别的...”:
- 提出了一个比 $A_{\mathrm{TM}}$ 的不可判定性更强的结论:甚至存在图灵不可识别的语言。
- 图灵不可识别 (Turing-unrecognizable): 意味着不存在任何图灵机,能够在该语言的所有成员上停机并接受。对于不属于该语言的字符串,机器可以拒绝或循环;但对于属于该语言的字符串,机器也可能拒绝或循环。这是一个比“不可判定”更强的“不可解”性质。
- “...原因在于语言是不可数的,而图灵机只有可数个。”:
- 这是整个论证的核心,一个简单的“鸽笼原理”应用。
- 语言是不可数的: 所有可能的语言(字符串的集合)形成的集合,其“数量”是不可数的。
- 图灵机只有可数个: 所有可能的图灵机,其“数量”是可数的。
- 鸽笼原理 (Pigeonhole Principle): 如果你有 $n$ 个鸽笼和 $m$ 只鸽子,且 $m > n$,那么至少有一个鸽笼里有多于一只鸽子。在这里,语言是“鸽子”,图灵机是“鸽笼”。
- “因为每台图灵机只能识别一种语言,并且语言的数量多于图灵机的数量,所以有些语言不被任何图灵机识别。”:
- 将鸽笼原理应用到当前场景:
- 每个图灵机 ($M$) 对应一个它能识别的语言 ($L(M)$)。我们可以把这看作是把一只叫“$M$”的鸽子放进一个叫“$L(M)$”的鸽笼里。
- 我们有不可数多只“鸽子”(语言)。
- 我们只有可数多间“鸽笼”(图灵机)。
- 因为不可数远大于可数,所以必然有大量的“鸽子”(语言)没有自己的“鸽笼”(图灵机)。
- “这样的语言是图灵不可识别的,正如我们在以下推论中所述。”:
- 对这些没有图灵机能识别它们的语言,给出了正式的名称:图灵不可识别。
- 预告了接下来会有一个正式的推论来总结这个论证。
- 鸽笼原理示例:
- 鸽子: 5个人。
- 鸽笼: 4把椅子。
- 结论: 必然至少有一个人没座位,或者至少有两个人挤在一把椅子上。在这里,我们关心的是前者。
- 计算理论应用:
- 鸽子 (语言): 无限多,且是“连续”的无限(不可数)。
- 鸽笼 (图灵机): 无限多,但只是“离散”的无限(可数)。
- 结论: 必然有不可数多的语言,没有图灵机能识别它们。
- 证明的非构造性: 这个论证是非构造性的。它强有力地证明了图灵不可识别语言的存在性,但它没有指出任何一个具体的图灵不可识别语言是什么。它只是一个纯粹的数量对比论证。我们稍后会通过其他方法构造出具体的例子(如 $\overline{A_{\mathrm{TM}}}$)。
- “识别一种语言”: 每个图灵机都唯一确定一个它所能识别的语言(即所有能让它停机并接受的字符串组成的集合)。不同的图灵机可能识别同一种语言(就像一个问题可以有多种解法),但这不影响论证。即使多个鸽子能进同一个笼子,只要鸽子比笼子多太多,就一定有鸽子无家可归。
本段将集合论中关于可数与不可数的结论,创造性地应用到了计算理论上。通过一个优雅的鸽笼原理论证,它指出:由于所有可能语言的集合是不可数的,而所有可能图灵机的集合是可数的,因此必然存在无法被任何图灵机所识别的语言。这直接证明了图灵不可识别语言的存在性。
本段的目的是展示理论知识的力量和不同数学分支之间的深刻联系。它使用一个看似与计算机无关的纯数学工具(不可数性),直接导出了关于计算极限的一个根本性结论。这个论证非常简洁、深刻,是数学之美在计算机科学中的一次完美体现。它也为后续讨论“不可识别”的语言(如 $\overline{A_{\mathrm{TM}}}$)提供了理论上的存在性保证。
“命名”模型。
- 图灵机就像是“名字”(比如“张三”、“李四”...)。所有可能的名字,只要是有限长度的字符串,都是可数的。
- 语言就像是“想法”。所有可能的想法,其数量是不可数的。
- 每个名字只能代表一个想法。
- 因为“想法”比“名字”多得多得多,所以必然存在无法被命名的“想法”。这些无法被命名的想法,就是图灵不可识别的语言。
你有一个颜料盒(图灵机),里面有可数无限多种颜色(红1, 红2, 蓝1, ...)。
你想画出世界上所有的画(语言)。
一幅画是由画布上的点和颜色构成的。即使我们只考虑一个1x1的画布,上面的每个点都可以被涂上不同的颜色,其所有可能的“画作”组合是不可数的(类似于实数)。
- 颜料(图灵机): 可数多。
- 画作(语言): 不可数多。
- 结论: 你的颜料盒里的颜色,无论如何都无法组合出世界上所有的画。必然有大量的画,是你永远画不出来的。这些画不出来的画,就是图灵不可识别的语言。
📜 [原文22]
推论 (corollary) 4.18
有些语言是图灵不可识别的。
证明:为了表明所有图灵机的集是可数的,我们首先观察到任何字母表 $\Sigma$ 的所有字符串 $\Sigma^{*}$ 的集是可数的。对于每个长度的有限数量的字符串,我们可以通过写下所有长度为0、长度为1、长度为2等字符串来形成 $\Sigma^{*}$ 的列表。
所有图灵机的集是可数的,因为每个图灵机 $M$ 都有一个编码成字符串 $\langle M\rangle$。如果我们简单地省略那些不是合法图灵机编码的字符串,我们就可以得到所有图灵机的列表。
为了表明所有语言的集是不可数的,我们首先观察到所有无限二进制序列的集是不可数的。无限二进制序列是0和1的无限序列。设 $\mathcal{B}$ 是所有无限二进制序列的集。我们可以通过使用类似于定理4.17中用于表明 $\mathcal{R}$ 是不可数的对角化证明来表明 $\mathcal{B}$ 是不可数的。
设 $\mathcal{L}$ 是字母表 $\Sigma$ 上的所有语言的集。我们通过给出与 $\mathcal{B}$ 的一一对应来表明 $\mathcal{L}$ 是不可数的,从而表明这两个集的大小相同。设 $\Sigma^{*}=\left\{s_{1}, s_{2}, s_{3}, \ldots\right\}$。 $\mathcal{L}$ 中的每种语言 $A$ 在 $\mathcal{B}$ 中都有一个唯一的序列。该序列的第 $i$ 位是1,如果 $s_{i} \in A$,如果 $s_{i} \notin A$,则为0,这被称为 $A$ 的特征序列。例如,如果 $A$ 是字母表 $\{0,1\}$ 上所有以0开头的字符串的语言,其特征序列 $\chi_{A}$ 将是
函数 $f: \mathcal{L} \longrightarrow \mathcal{B}$,其中 $f(A)$ 等于 $A$ 的特征序列,是一对一的且是满射的,因此是一一对应。因此,由于 $\mathcal{B}$ 是不可数的, $\mathcal{L}$ 也是不可数的。
因此,我们已经表明所有语言的集不能与所有图灵机的集建立一一对应。我们得出结论,有些语言不被任何图灵机识别。
这个推论是对上一段鸽笼原理论证的详细展开和形式化证明。它分为两大部分:证明图灵机集可数,和证明语言集不可数。
第一部分:证明所有图灵机的集合是可数的
- “...任何字母表 $\Sigma$ 的所有字符串 $\Sigma^{*}$ 的集是可数的。”:
- 基础: 任何程序/机器的描述,最终都是一个字符串。所以我们先证明所有可能的字符串是可数的。
- 证明方法: 按长度排序(字典序)。
- 长度为 0 的字符串: $\epsilon$
- 长度为 1 的字符串: 0, 1
- 长度为 2 的字符串: 00, 01, 10, 11
- ...
- 因为每个长度下的字符串数量都是有限的,我们可以把这些有限的组合一块一块地拼接起来,形成一个无限的列表。这就证明了 $\Sigma^*$ 是可数的。
- “所有图灵机的集是可数的,因为每个图灵机 $M$ 都有一个编码成字符串 $\langle M\rangle$。”:
- 每个图灵机的设计(状态、转移函数等)都可以用一种标准格式写成一个字符串,即 $\langle M\rangle$。这个字符串属于 $\Sigma^*$。
- 所有可能的图灵机编码的集合,是所有字符串集合 $\Sigma^*$ 的一个子集。
- 定理: 可数集的任何子集也都是可数的。(或者有限,或者可数无限)。
- 因此,所有图灵机的集合是可数的。我们可以想象,在上面那个所有字符串的列表中,我们逐一检查每个字符串,如果它是一个合法的图灵机编码,就把它保留下来,否则就划掉。剩下的就是一个所有图灵机的列表。
第二部分:证明所有语言的集合是不可数的
- “...所有无限二进制序列的集是不可数的。”:
- 无限二进制序列: 一个无限长的0和1的序列,如 01101001...。
- 设这个集合为 $\mathcal{B}$。
- 证明方法: 使用与证明实数集不可数完全相同的对角化论证。
- 假设 $\mathcal{B}$ 是可数的,即可以列出所有无限二进制序列 $b_1, b_2, b_3, \dots$。
- 构造一个新的序列 $b_{new}$,使其第 $i$ 位与 $b_i$ 的第 $i$ 位相反(0变1,1变0)。
- $b_{new}$ 与列表中的任何一个序列都不同,导出矛盾。
- 因此 $\mathcal{B}$ 是不可数的。
- “设 $\mathcal{L}$ 是字母表 $\Sigma$ 上的所有语言的集。我们通过给出与 $\mathcal{B}$ 的一一对应来表明 $\mathcal{L}$ 是不可数的...”:
- 策略: 证明所有语言的集合 $\mathcal{L}$ 与所有无限二进制序列的集合 $\mathcal{B}$ 大小相同。既然 $\mathcal{B}$ 是不可数的,那么 $\mathcal{L}$ 也必然是不可数的。
- “设 $\Sigma^{*}=\left\{s_{1}, s_{2}, s_{3}, \ldots\right\}$。”:
- 我们已经知道所有字符串的集合 $\Sigma^*$ 是可数的,所以我们可以把它排成一个列表 $s_1, s_2, s_3, \dots$。
- “$\mathcal{L}$ 中的每种语言 $A$ 在 $\mathcal{B}$ 中都有一个唯一的序列。该序列的第 $i$ 位是1,如果 $s_{i} \in A$,如果 $s_{i} \notin A$,则为0,这被称为 $A$ 的特征序列。”:
- 这是构造一一对应的关键。
- 对于任何一种语言 $A$ (它本质上是 $\Sigma^*$ 的一个子集),我们可以构造一个无限二进制序列,称为它的特征序列 (Characteristic Sequence) $\chi_A$。
- 构造规则: 看着排好序的字符串列表 $s_1, s_2, s_3, \dots$。
- 如果 $s_1$ 在语言 $A$ 中,$\chi_A$ 的第1位就是1;否则是0。
- 如果 $s_2$ 在语言 $A$ 中,$\chi_A$ 的第2位就是1;否则是0。
- ...
- 如果 $s_i$ 在语言 $A$ 中,$\chi_A$ 的第 $i$ 位就是1;否则是0。
- 例子:
- $\Sigma^*$ 的列表: $\epsilon, 0, 1, 00, 01, \dots$
- 语言 $A$: 所有以0开头的字符串。$A = \{0, 00, 01, \dots\}$
- 特征序列 $\chi_A$:
- $s_1 = \epsilon$: 不在 $A$ 中 -> 第1位是 0。
- $s_2 = 0$: 在 $A$ 中 -> 第2位是 1。
- $s_3 = 1$: 不在 $A$ 中 -> 第3位是 0。
- $s_4 = 00$: 在 $A$ 中 -> 第4位是 1。
- $s_5 = 01$: 在 $A$ 中 -> 第5位是 1。
- ...
- 所以 $\chi_A = 01011...$
- “函数 $f: \mathcal{L} \longrightarrow \mathcal{B}$ ... 是一个一一对应。”:
- 我们定义一个函数 $f(A) = \chi_A$。
- 一对一 (单射)?: 是。如果 $A_1$ 和 $A_2$ 是两种不同的语言,那么它们所包含的字符串集合必然不同。这意味着至少存在一个字符串 $s_k$,它在一个语言里而不在另一个里。因此,它们的特征序列 $\chi_{A_1}$ 和 $\chi_{A_2}$ 在第 $k$ 位上必然不同。
- 满射 (满射)?: 是。对于任何一个无限二进制序列 $b \in \mathcal{B}$,我们都可以构造出一个对应的语言 $A_b$。构造方法是:如果 $b$ 的第 $i$ 位是1,就把字符串 $s_i$ 加入 $A_b$。这样构造出的 $A_b$ 的特征序列正好就是 $b$。
- 既然是一一对应,且 $\mathcal{B}$ 是不可数的,那么 $\mathcal{L}$ 也是不可数的。
第三部分:结论
- “因此,我们已经表明所有语言的集不能与所有图灵机的集建立一一对应。”:
- 语言集: 不可数。
- 图灵机集: 可数。
- 一个不可数集和一个可数集之间不可能存在一一对应。
- “我们得出结论,有些语言不被任何图灵机识别。”:
- 应用鸽笼原理,得出最终结论。
- $\Sigma^{*}$: 字母表 $\{0,1\}$ 上所有可能字符串的集合,按标准顺序列出。
- $A$: 一个语言的例子,即 $\Sigma^*$ 的一个子集。这里是所有以'0'开头的字符串。
- $\chi_{A}$: 语言 $A$ 的特征序列。这是一个无限长的二进制序列。它的每一位都回答了一个“是/否”问题。
- 第 $i$ 位为 $1$ 意味着“列表 $\Sigma^*$ 中的第 $i$ 个字符串是否属于语言 $A$?”的答案是“是”。
- 第 $i$ 位为 $0$ 意味着答案是“否”。
- 这个例子直观地展示了任何一个语言(一个字符串的子集)和一条无限二进制序列之间存在着唯一的对应关系。
- 无限的层次: 这个证明是理解“无限”有不同大小的关键。可数无限(如 $\mathcal{N}, \mathcal{Q}$)是“最低”等级的无限。不可数无限(如 $\mathcal{R}$, $\mathcal{L}$)是一个比可数无限“大得多”的等级。康托尔的理论还揭示了存在比实数集更大的无限集合,形成了一个无限的“无限等级”的阶梯。
- 计算与存在: 这个证明是关于“存在性”的,而不是“计算性”的。它利用集合大小的差异,而非计算过程,来证明不可识别语言的存在。
推论4.18 对鸽笼原理论证给出了严谨的细节。它首先证明了所有图灵机的集合是可数的,因为每个图灵机都可以被一个字符串编码,而所有字符串的集合是可数的。接着,它通过构造“特征序列”,建立了所有语言的集合 $\mathcal{L}$ 与所有无限二进制序列的集合 $\mathcal{B}$ 之间的一一对应。由于 $\mathcal{B}$ 可以通过对角化被证明是不可数的,所以 $\mathcal{L}$ 也是不可数的。最后,由于语言(鸽子)的数量是不可数的,而图灵机(鸽笼)的数量是可数的,必然存在没有图灵机能够识别的语言。
本推论的目的是为上一段的直观论证提供坚实的数学基础,使结论无可辩驳。它一步步地、严谨地证明了“鸽子”和“鸽笼”的数量差异,是理解计算理论中许多核心结论的基础。这个证明本身也是一个极好的例子,展示了如何将在一个领域(集合论)发展的工具和概念,应用到另一个看似无关的领域(可计算性理论)并产生深刻的见解。
假设你想给地球上的每一粒沙子都起一个独一无二的名字,名字只能由英文字母组成。
- 名字(图灵机): 所有可能的名字(有限长度的字母串)的集合是可数的。你可以把它们按长度和字母表顺序列出来。
- 沙子(语言): 假设沙子的数量是不可数的(这只是一个比喻)。
- 结论: 你永远不可能完成这个任务。当你的名字列表用尽时(理论上),还有数不清的沙子没有被命名。这些没有名字的沙子,就是图灵不可识别的语言。
想象你有一支画笔,这支画笔只能画出直线(图灵机)。所有可能的直线,你可以用它们的斜率和截距(有理数)来描述,所以所有可能的直线的集合是可数的。
现在,你想用这些直线去“描绘”一个三维的、充满复杂曲线的雕塑(所有语言的集合)。
这个雕塑的表面是如此复杂和丰富,其表面的点的数量是不可数的。
你用可数的直线,去描绘一个有不可数细节的物体,必然会漏掉绝大部分的细节。那些直线永远无法触及和表达的曲线和形态,就是图灵不可识别的语言。
55. 一个不可判定的语言 (AN UNDECIDABLE LANGUAGE)
📜 [原文23]
现在我们准备证明定理4.11,$A_{\mathrm{TM}}$ 语言的不可判定性:
证明:我们假设 $A_{\mathrm{TM}}$ 是可判定的并得到矛盾。假设 $H$ 是 $A_{\mathrm{TM}}$ 的一个判定器。在输入 $\langle M, w\rangle$ 上,其中 $M$ 是一个图灵机,$w$ 是一个字符串,如果 $M$ 接受 $w$,则 $H$ 停机并接受。此外,如果 $M$ 不接受 $w$,则 $H$ 停机并拒绝。换句话说,我们假设 $H$ 是一个图灵机,其中
这是证明 $A_{\mathrm{TM}}$ 不可判定性的核心部分的开始。本段采用反证法,首先清晰地陈述了与待证结论相反的假设。
- “现在我们准备证明定理4.11,$A_{\mathrm{TM}}$ 语言的不可判定性”:
- 经过前面关于可数性、不可数性和对角化的漫长铺垫,现在终于回到了本节最初的目标。
- 公式 $A_{\mathrm{TM}}$:
- 重申了我们要研究的语言的定义,提醒读者它的构成:所有“图灵机 $M$ 成功处理输入 $w$”的记录 $\langle M, w\rangle$ 组成的集合。
- “证明:我们假设 $A_{\mathrm{TM}}$ 是可判定的并得到矛盾。”:
- 明确了证明策略为反证法。
- 待证结论: $A_{\mathrm{TM}}$ 是不可判定的。
- 反证假设: $A_{\mathrm{TM}}$ 是可判定的。
- “假设 $H$ 是 $A_{\mathrm{TM}}$ 的一个判定器。”:
- 将上述抽象的假设具体化。如果 $A_{\mathrm{TM}}$ 是可判定的,那么根据可判定语言的定义,必然存在一个图灵机,我们称之为 $H$ (Hypothetical,假设的),它能判定 $A_{\mathrm{TM}}$。
- “在输入 $\langle M, w\rangle$ 上... 如果 $M$ 接受 $w$,则 $H$ 停机并接受。此外,如果 $M$ 不接受 $w$,则 $H$ 停机并拒绝。”:
- 详细描述了判定器 $H$ 的完美功能。
- 关键能力: 对于任何给定的图灵机 $M$ 和输入 $w$,$H$ 都能在有限时间内给出答案。
- 回答正确:
- 如果 $M$ 在 $w$ 上最终会接受,$H$ 就输出“接受”。
- 如果 $M$ 在 $w$ 上最终会拒绝,或者 $M$ 会陷入无限循环,$H$ 都能洞察这一切,并最终停机输出“拒绝”。这就是 $H$ 最神奇的地方:它有能力检测出无限循环!
- “换句话说,我们假设 $H$ 是一个图灵机,其中...”:
- 用一个分段函数的形式,更数学化、更精确地总结了 $H$ 的行为。
- $H(\langle M, w\rangle)$: 表示图灵机 $H$ 在输入字符串 $\langle M, w\rangle$ 上的最终输出结果。
- $\text{accept}$: $H$ 停机并进入接受状态。
- $\text{reject}$: $H$ 停机并进入拒绝状态。
- if $M$ accepts $w$: 条件1。这个条件覆盖了 $M$ 在 $w$ 上运行并停在接受状态的情况。
- if $M$ does not accept $w$: 条件2。这个条件覆盖了两种子情况:
- $M$ 在 $w$ 上运行并停在拒绝状态。
- $M$ 在 $w$ 上永不停机(无限循环)。
- 核心假设: 判定器 $H$ 的强大之处在于,它总能区分这两种情况并给出统一的 reject 答案,并且它自身永远不会陷入无限循环。
根据我们的假设,这个万能的判定器 $H$ 可以做到:
- 示例1:
- 输入: $\langle M_1, w_1 \rangle$,其中 $M_1$ 是检查 "00" 的程序, $w_1$ 是 "101001"。
- 由于 $M_1$ 接受 $w_1$,$H$ 会运行一会,然后输出 accept。
- 示例2:
- 输入: $\langle M_2, w_2 \rangle$,其中 $M_2$ 是寻找奇完美数的程序, $w_2$ 是任意字符串。
- 我们知道 $M_2$ 会在 $w_2$ 上无限循环,因此 $M_2$ does not accept $w_2$。
- 根据假设,$H$ 能够在有限时间内分析出 $M_2$ 将会无限循环,然后 $H$ 会停机并输出 reject。这是 $H$ 最不可思议的能力。
- H vs U: 不要把假设的判定器 $H$ 和之前我们构造的识别器 $U$ 搞混。
- $U$ 是一个模拟器,它是真实存在的。当 $M$ 循环时,$U$ 也跟着循环。
- $H$ 是一个假设存在的“先知”或“神谕”。当 $M$ 会循环时,$H$ 不会跟着循环,而是会直接告诉你“它会循环”(通过输出reject)。我们接下来的目标就是证明这个“先知”不可能存在。
本段为对角化证明 $A_{\mathrm{TM}}$ 不可判定搭建了舞台。它遵循反证法的经典开局,假设 $A_{\mathrm{TM}}$ 是可判定的,并由此推断存在一个全能的图灵机 $H$。这个 $H$ 被定义为一个完美的“问题解决者”,它能接收任何图リング机 $M$ 及其输入 $w$ 的描述,并在有限时间内准确判断 $M$ 是否会接受 $w$,尤其重要的是,它能检测并处理 $M$ 的无限循环情况。
本段的目的是清晰、无歧义地树立一个“靶子”。通过详细定义这个假设的、功能强大的判定器 $H$,为后续构造一个能“击败”它的悖论性机器 $D$ 提供了明确的前提。整个证明的成败,就在于从“$H$ 存在”这个假设出发,能否推导出逻辑上的不可能。
假设有一个“万能代码审查员” $H$。你把任何一段程序代码 $M$ 和它的输入数据 $w$ 交给他。
- 如果程序 $M$ 能在输入 $w$ 上正常运行并成功结束,审查员 $H$ 会给你一个“通过”的印章。
- 如果程序 $M$ 会因为错误而崩溃,或者更糟的,会陷入死循环,审查员 $H$ 都能在有限时间内发现这个问题,并给你一个“不通过”的印章。
本段就是把这个理想中的“万能代码审查员” $H$ 的存在性,作为我们即将要推翻的假设。
你找到了一位自称能预测未来的“大师” $H$。
他的能力是:你给他任何一个人的照片 $M$ 和这个人的一个计划 $w$(比如“创业开公司”),他都能告诉你这个人最终是会“成功”(接受)还是“失败”(不接受)。
关键是,即使这个人的计划会导致他一生都在原地打转、毫无进展(无限循环),大师 $H$ 也能一眼看穿,并告诉你“他会失败”。
反证法的思路就是:我们先假设这位大师真的存在,然后我们去设计一个让他自己都无法预测自己命运的诡异问题,从而证明他是在吹牛。
📜 [原文24]
现在我们构造一个以 $H$ 为子程序的新图灵机 $D$。这个新图灵机调用 $H$ 来判定当 $M$ 的输入是它自己的描述 $\langle M\rangle$ 时 $M$ 会做什么。一旦 $D$ 获得此信息,它就会做相反的事情。也就是说,如果 $M$ 接受,它就拒绝;如果 $M$ 不接受,它就接受。以下是 $D$ 的描述。
$D=$ “在输入 $\langle M\rangle$ 上,其中 $M$ 是一个图灵机:
- 在输入 $\langle M,\langle M\rangle\rangle$ 上运行 $H$。
- 输出与 $H$ 输出相反的结果。也就是说,如果 $H$ 接受,则拒绝;如果 $H$ 拒绝,则接受。”
这一段是对角化证明中至关重要的一步:利用假设存在的判定器 $H$,来构造一个新的、行为怪异的图灵机 $D$ (Diagonal or Devil)。$D$ 的设计充满了“自我指涉”和“唱反调”的意味。
- “现在我们构造一个以 $H$ 为子程序的新图灵机 $D$。”:
- 构造 (Construct): 我们正在设计一台新的机器。
- 子程序 (Subroutine): 我们假设 $H$ 是一台存在的机器,所以我们可以在我们的新机器 $D$ 的设计中“调用”它,就像在编程中调用一个函数一样。$D$ 的内部逻辑包含了一个对 $H$ 的调用。
- “这个新图灵机调用 $H$ 来判定当 $M$ 的输入是它自己的描述 $\langle M\rangle$ 时 $M$ 会做什么。”:
- 这是 $D$ 的核心行为,也是“自我指涉”的第一次出现。
- $D$ 的输入只有一个:一个图灵机 $M$ 的描述 $\langle M\rangle$。
- $D$ 做的事情是,把这个输入 $\langle M\rangle$ 复制一份,形成一个输入对 $(\langle M\rangle, \langle M\rangle)$。
- 然后,$D$ 把这个输入对喂给它的子程序 $H$。它是在问 $H$ 一个非常特殊的问题:“嗨,大师H,请帮我看看,如果让机器 $M$ 运行在它自己的描述 $\langle M \rangle$ 上,它会接受吗?”
- 因为我们假设 $H$ 是万能的,所以 $H$ 总能给出一个“接受”或“拒绝”的答案。
- “一旦 $D$ 获得此信息,它就会做相反的事情。”:
- 这是 $D$ 的“捣蛋鬼”或“叛逆”天性的体现。$D$ 完全不关心 $M$ 到底做了什么,它只关心 $H$ 对此的看法,然后跟这个看法反着来。
- “也就是说,如果 $M$ 接受,它就拒绝;如果 $M$ 不接受,它就接受。”:
- 更准确地说,应该是:如果 $H$ 的结论是“$M$ 接受 $\langle M \rangle$”,那么 $D$ 就拒绝。如果 $H$ 的结论是“$M$ 不接受 $\langle M \rangle$”,那么 $D$ 就接受。
- “以下是 $D$ 的描述。”:
- 给出了 $D$ 的形式化算法描述。
- "$D=$ ‘在输入 $\langle M\rangle$ 上...’”:
- 输入: $\langle M \rangle$,一个图灵机的编码。
- 步骤1: “在输入 $\langle M,\langle M\rangle\rangle$ 上运行 $H$。”
- $D$ 准备 $H$ 的输入。$H$ 需要两个参数(一个机器,一个输入),$D$ 把自己的唯一输入 $\langle M\rangle$ 同时用作 $H$ 的两个参数。
- $D$ 启动 $H$ 并等待结果。因为 $H$ 是判定器,所以这一步保证在有限时间内结束。
- 步骤2: “输出与 $H$ 输出相反的结果。...”
- $D$ 检查 $H$ 的输出。
- 如果 $H$ 的输出是“接受”,$D$ 就进入自己的拒绝状态并停机。
- 如果 $H$ 的输出是“拒绝”,$D$ 就进入自己的接受状态并停机。
- 重要观察: 因为 $H$ 总是在有限时间内停机,并且 $D$ 在 $H$ 停机后只做一步简单的相反操作,所以 $D$ 本身也是一个判定器!$D$ 对于任何合法的输入 $\langle M \rangle$ 都会在有限时间内停机。
让我们看看 $D$ 如何处理两个不同的输入:
- 示例1: 输入为 $\langle M_1 \rangle$
- 假设存在一个图灵机 $M_1$,当它以自己的描述 $\langle M_1 \rangle$ 为输入时,它会停机并接受。
- $D$ 的行为:
- $D$ 收到输入 $\langle M_1 \rangle$。
- $D$ 调用 $H(\langle M_1, \langle M_1 \rangle\rangle)$。
- 因为 $M_1$ 接受 $\langle M_1 \rangle$,所以万能的 $H$ 会停机并输出 accept。
- $D$ 看到 $H$ 输出了 accept,于是它执行相反操作:停机并输出 reject。
- 结论: $D(\langle M_1 \rangle) = \text{reject}$。
- 示例2: 输入为 $\langle M_2 \rangle$
- 假设存在一个图灵机 $M_2$,当它以自己的描述 $\langle M_2 \rangle$ 为输入时,它会陷入无限循环(因此不接受)。
- $D$ 的行为:
- $D$ 收到输入 $\langle M_2 \rangle$。
- $D$ 调用 $H(\langle M_2, \langle M_2 \rangle\rangle)$。
- 因为 $M_2$ 不接受 $\langle M_2 \rangle$,所以万能的 $H$ 会停机并输出 reject。
- $D$ 看到 $H$ 输出了 reject,于是它执行相反操作:停机并输出 accept。
- 结论: $D(\langle M_2 \rangle) = \text{accept}$。
- 不要被“在自己的描述上运行”搞糊涂: 这在现实中是完全可能的。一个编译器(本身是个程序)可以编译它自己的源代码。一个文本编辑器可以打开它自己的可执行文件(虽然显示的是乱码)。这在计算理论中是一个合法的、常见的操作,即将程序本身也视为一种数据。
- $D$ 的本质: $D$ 是一台“唱反调机”。你给它一个机器 $M$ 的描述,它就去预测 $M$ 在面对自己时的行为,然后做出完全相反的反应。
本段完成了对角化证明中最核心的构造步骤:利用假设存在的全能判定器 $H$,我们设计并构造了一个新的图灵机 $D$。$D$ 的工作模式是:接收一个机器 $M$ 的描述 $\langle M \rangle$,然后利用 $H$ 去预测 $M$ 在输入 $\langle M \rangle$ 上的行为,并做出与该行为完全相反的决定。这个被精心设计出来的“叛逆者”$D$,即将被用来引出最终的矛盾。
本段的目的是制造出那个能够引发悖论的“特殊元素”。在证明实数不可数时,我们构造了一个特殊的“数”。在这里,我们构造了一台特殊的“机器”$D$。这台机器是整个证明的“弹药”,它的存在完全依赖于 $H$ 的存在。下一步,我们将把这颗“弹药”射向它自己,从而引爆逻辑矛盾。
回到“万能代码审查员” $H$ 的例子。
我们现在写了一个新程序 $D$。$D$ 的代码逻辑如下:
```python
6D 的伪代码
def D(program_code_M):
7调用万能审查员 H
8提问:如果 M 运行在它自己的代码上,H 的审查结果是什么?
result_from_H = H(program_code_M, program_code_M)
if result_from_H == "通过":
9H说会通过,我就故意失败
crash_and_burn() # 拒绝
else: # result_from_H == "不通过"
10H说不会通过,我就故意成功
return "成功" # 接受
```
这个程序 $D$ 就是一个“杠精”程序。
回到“能预测未来的大师” $H$ 的例子。
我们现在找到了一个“杠精” $D$。他的行为准则是:
- 找到大师 $H$。
- 给大师看任何一个人 $M$ 的照片。
- 问大师:“如果让 $M$ 执行一个‘审视自己’的计划,他会成功吗?”
- 如果大师说“会成功”,杠精 $D$ 就立刻宣布“审视自己”这件事是失败的。
- 如果大师说“会失败”,杠精 $D$ 就立刻宣布“审视自己”这件事是成功的。
现在,最关键的问题来了:如果让这个“杠精” $D$ 去审视他自己,会发生什么?这就是下一步要讨论的。
📜 [原文25]
不要被在一个机器上运行它自己的描述这种概念所困扰!这类似于运行一个程序并以它自己作为输入,这在实践中偶尔会发生。例如,编译器是一个翻译其他程序的程序。一个用 Python 编写的 Python 编译器,用它自己作为输入来运行也是有意义的。总而言之,
这一段首先安抚读者,解释“程序以自身为输入”这个概念的合理性,然后用一个分段函数精确总结了上一段构造的机器 $D$ 的行为。
- “不要被在一个机器上运行它自己的描述这种概念所困扰!”:
- 作者预见到读者可能会觉得这个概念很奇怪、很抽象,甚至有点“黑魔法”的感觉,所以主动站出来进行安抚和解释。
- “这类似于运行一个程序并以它自己作为输入,这在实践中偶尔会发生。”:
- 将抽象的理论概念与现实中的编程实践联系起来。
- 任何程序,其本质都是存储在磁盘上的一个文件,一串二进制数据。因此,任何程序都可以像读取普通文本文件或图片文件一样,去读取另一个程序文件,包括它自己的文件。
- “例如,编译器是一个翻译其他程序的程序。一个用 Python 编写的 Python 编译器,用它自己作为输入来运行也是有意义的。”:
- 给出了一个非常经典和具体的例子:自举编译器 (Bootstrapping a compiler)。
- 编译器 (Compiler): 一个将高级语言代码(如Python源码)翻译成低级语言代码(如机器码)的程序。
- 场景: 假设你用Python语言写了一个新的、更牛的Python编译器,我们称之为 NewPythonCompiler.py。
- 自举过程:
- 这个过程就完美地诠释了“一个程序以自己为输入”的现实意义。
- “总而言之,”:
- 在消除了读者的疑虑之后,回到主线,对机器 $D$ 的功能给出一个最终的、简洁的数学描述。
- $D(\langle M\rangle)$: 机器 $D$ 在输入 $\langle M \rangle$ 上的最终输出。
- accept if $M$ does not accept $\langle M\rangle$: $D$ 接受它的输入 $\langle M \rangle$,当且仅当机器 $M$ 不接受它自己的描述 $\langle M \rangle$ 作为输入。
- reject if $M$ accepts $\langle M\rangle$: $D$ 拒绝它的输入 $\langle M \rangle$,当且仅当机器 $M$ 接受它自己的描述 $\langle M \rangle$ 作为输入。
- 与H的关系: 这个公式是对 $D$ 行为的直接描述,它已经“内化”了 $H$ 的作用。$D$之所以能知道 "$M$ accepts $\langle M \rangle$" 与否,正是通过调用 $H(\langle M, \langle M \rangle \rangle)$ 来实现的。这个公式是 $D$ 最终表现出的外部行为。
- 示例1 (文本编辑器打开自己):
- 你在Windows上有一个 Notepad.exe 程序。
- 你可以通过命令行运行 Notepad.exe Notepad.exe。
- 结果是:记事本窗口会打开,里面显示的是 Notepad.exe 这个二进制文件的内容(一堆乱码)。
- 这个操作是完全合法的,程序 Notepad.exe 以它自己的文件内容作为了输入数据。
- 示例2 (哈希函数计算自己):
- 一个计算文件MD5哈希值的程序 md5.exe。
- 你可以运行 md5.exe md5.exe 来计算这个程序文件自身的MD5值。
- 这也是一个程序以自身为输入的例子。
- 逻辑层面 vs 实现层面: 在计算理论中,我们更关心这种操作在逻辑上的可能性。D 调用 H,H 模拟 M,这一切都是在图灵机的形式化模型下进行的。编译器自举的例子只是为了帮助我们建立直觉,理解其并非天方夜谭。
本段起到了承上启下的作用。首先,它通过列举编译器自举等现实中的例子,打消了读者对“程序以自身为输入”这一概念的疑虑,强调了其合理性和实践性。然后,它用一个简洁的分段函数,完美地概括了我们构造出的“捣蛋鬼”机器 $D$ 的核心行为:对于任何输入机器 $\langle M \rangle$,$D$ 的输出与 $M$ 在其自身描述 $\langle M \rangle$ 上的输出行为正好相反。
本段的目的是为最终的矛盾推导铺平道路。通过让读者坦然接受“程序处理自身”这个设定,并清晰地记下机器 $D$ 的“反转”行为准则,它确保了在下一步——将 $D$ 应用于 $D$ 自身时,读者能够毫无障碍地跟上逻辑的跳跃,并清楚地看到悖论的产生。
本段是在说:“我知道让一个角色去读一本‘关于他自己’的书听起来很meta,很烧脑,但这种事情在文学作品里(比如《苏菲的世界》)是有的,而且是关键情节。所以,请先接受这个设定,然后我们来看好戏。”
你正在给一个AI机器人编程,这个机器人叫 $D$。你给它的核心指令集(就是上面的公式)是:“无论何时你被要求评估一个机器人 $M$(包括评估你自己),你都要先预测出 $M$ 评估自己的结果,然后给出和那个结果完全相反的最终评价。”
本段就是在跟你确认:“你确定要给机器人D下达这么一个‘拧巴’的指令吗?这在逻辑上是允许的哦。”
📜 [原文26]
当我们用它自己的描述 $\langle D\rangle$ 作为输入来运行 $D$ 时会发生什么?在这种情况下,我们得到
无论 $D$ 做什么,它都被迫做相反的事情,这显然是一个矛盾。因此,图灵机 $D$ 和图灵机 $H$ 都不可能存在。
这是整个证明的高潮和终点。通过将精心设计的“捣蛋鬼”机器 $D$ 应用于其自身,我们引爆了逻辑矛盾。
- “当我们用它自己的描述 $\langle D\rangle$ 作为输入来运行 $D$ 时会发生什么?”:
- 这是最关键的提问,是对角化论证的“将军”时刻。
- 我们已经接受了“机器可以以自身描述为输入”。
- $D$ 本身也是一个图灵机。因此,它的描述 $\langle D \rangle$ 是一个合法的字符串,可以作为任何图灵机的输入,当然也包括 $D$ 自己。
- 我们现在就把 $D$ 的“照片” $\langle D \rangle$ 喂给 $D$ 自己。
- “在这种情况下,我们得到...”:
- 我们只需将上一段总结的 $D$ 的行为通式中的“$M$”替换为“$D$”,就可以得到 $D$ 在输入 $\langle D \rangle$ 时的行为。
- $D$ 的通式是:$D(\langle M\rangle)$ 接受 $\iff$ $M$ 不接受 $\langle M \rangle$。
- 将 $M$ 换成 $D$:$D(\langle D\rangle)$ 接受 $\iff$ $D$ 不接受 $\langle D \rangle$。
- 这就得到了下面这个惊人的公式。
这个公式描述了一个逻辑上的绝境,一个悖论。让我们来分析它:
- 情况一:假设 $D$ 在输入 $\langle D \rangle$ 时,最终停机并接受。
- 即 $D(\langle D \rangle) = \text{accept}$。
- 但根据公式的第二行,如果 "$D$ accepts $\langle D \rangle$",那么 $D(\langle D \rangle)$ 的结果应该是 reject。
- 所以,如果 $D$ 接受 $\langle D \rangle$,那么它必须拒绝 $\langle D \rangle$。这是一个直接的矛盾。
- 情况二:假设 $D$ 在输入 $\langle D \rangle$ 时,不接受它。
- 即 $D(\langle D \rangle) \neq \text{accept}$ (这包括了停机拒绝,或无限循环)。
- 但根据公式的第一行,如果 "$D$ does not accept $\langle D \rangle$",那么 $D(\langle D \rangle)$ 的结果应该是 accept。
- 所以,如果 $D$ 不接受 $\langle D \rangle$,那么它必须接受 $\langle D \rangle$。这同样是一个直接的矛盾。
- “无论 $D$ 做什么,它都被迫做相反的事情,这显然是一个矛盾。”:
- 对上述悖论的总结。机器 $D$ 在处理输入 $\langle D \rangle$ 时,陷入了一个逻辑上的死循环。它的行为定义要求它做出与自身行为相反的行为。这在逻辑上是不可能存在的。
- 这就像一个说“我正在说的这句话是谎话”的人。
- “因此,图灵机 $D$ 和图灵机 $H$ 都不可能存在。”:
- 这是反证法的最后一步,得出结论。
- 我们推导出了一个逻辑矛盾。这意味着我们最初的某个假设一定是错误的。
- 让我们回溯我们的假设链:
- 既然 $D$ 的存在导致了逻辑矛盾,那么 $D$ 就不可能存在。
- 如果 $D$ 不可能存在,那么我们用来构造它的“原材料”——机器 $H$ ——也必然不可能存在。
- 如果判定器 $H$ 不可能存在,那么我们关于“$A_{\mathrm{TM}}$ 是可判定的”这个最初的假设,就是错误的。
- 最终结论: $A_{\mathrm{TM}}$ 必然是不可判定的。证明完毕。
这里的“数值示例”更应是逻辑场景的代入。
- 理发师悖论:
- 规则: 理发师给且只给所有不给自己理发的人理发。
- 问: 理发师给自己理发吗?
- 分析:
- 若他给自己理发 -> 他违反了“只给不给自己理发的人理发”的规则。
- 若他不给自己理发 -> 他符合“不给自己理发的人”的条件,按规则他必须给自己理发。
- 矛盾: 无论他做什么,都违反规则。
- 结论: 这样的理发师不可能存在于这个村子里。
- “杠精”程序员 $D$ 的最终下场:
- 我们把“杠精”程序 $D$ 的代码 D.py 交给它自己去审查。
- D("D.py") 开始运行。
- 它的第一步是调用 H("D.py", "D.py")。
- $H$ 开始分析 $D$ 在输入 D.py 时会发生什么。
- 如果 $H$ 预测 $D$ 会成功,它就告诉 $D$ “会成功”。$D$ 收到后,立刻故意失败。所以 $H$ 预测错了。
- 如果 $H$ 预测 $D$ 会失败,它就告诉 $D$ “会失败”。$D$ 收到后,立刻故意成功。所以 $H$ 也预测错了。
- 矛盾: 全能的审查员 $H$ 无论如何都无法正确预测 $D$ 在自己身上的行为。但我们假设 $H$ 是永远正确的。这个矛盾证明了 $H$ 不可能存在。
- 矛盾的根源: 必须清楚,矛盾并不是出在图灵机的模型上,而是出在我们“假设 $H$ 存在”这一行为上。计算模型本身是无辜的,是我们对它提出了一个它无法满足的过高要求(要求它能解决停机问题)。
- 证明的适用范围: 这个证明是完全普适的。它不依赖于图灵机的具体编码方式,也不依赖于我们构造 $D$ 时如何选择“相反”的操作。只要存在一个判定器 $H$,就必然可以构造出一个引发悖论的 $D$。
本段是对角化证明的“收官”部分。通过将“捣蛋鬼”机器 $D$ 应用于其自身的描述 $\langle D \rangle$,我们构造了一个经典的逻辑悖论:$D$ 接受 $\langle D \rangle$ 当且仅当 $D$ 不接受 $\langle D \rangle$。这个无法解决的矛盾证明了机器 $D$ 本身是不可能存在的。由于 $D$ 的构造完全依赖于假设的判定器 $H$ 的存在,因此 $H$ 也必然不存在。最终,根据反证法,我们得出结论:$A_{\mathrm{TM}}$ 是不可判定的。
本段的目的是完成整个反证逻辑链的闭环。通过将前面所有的铺垫和构造汇集于一点,并引爆其内在的逻辑矛盾,它以一种无可辩驳的方式,摧毁了“$A_{\mathrm{TM}}$ 可判定”的初始假设,从而雄辩地证明了定理4.11。
“许愿神灯”悖论。
你对神灯许愿:“我的下一个愿望将不会被实现。”
- 神灯的困境:
- 如果神灯实现了这个愿望,那么“下一个愿望不会被实现”就成真了,但神灯刚刚实现了它,矛盾。
- 如果神灯不实现这个愿望,那么“下一个愿望不会被实现”就是假的,意味着这个愿望应该被实现,矛盾。
- 机器 $D$ 对 $H$ 的挑战,本质上就是向 $H$ 提出了这样一个悖论式的愿望。
你建造了一个“绝对唱反调机器人” $D$。它的程序是:“分析对方接下来说的话的真伪,并做出相反的陈述。”
现在,你让这个机器人 $D$ 去分析它自己的下一句话。
$D$ 准备说一句话,我们称之为 $S$。在说出口之前,它必须先分析 $S$ 的真伪,然后做出相反的陈述。
- 如果 $S$ 是真话,那么 $D$ 必须说一句假话。
- 如果 $S$ 是假话,那么 $D$ 必须说一句真话。
让 $S$ = “我将要说的这句话是假话”。
- $D$ 分析 $S$:如果 $S$ 是真话,那么“我将要说的这句话是假话”是真的,所以 $S$ 必须是假话,矛盾。
- $D$ 分析 $S$:如果 $S$ 是假话,那么“我将要说的这句话是假话”是假的,所以 $S$ 必须是真话,矛盾。
机器人 $D$ 的处理器会因为这个逻辑死循环而冒烟。它的存在是不可能的。
📜 [原文27]
让我们回顾一下这个证明的步骤。假设图灵机 $H$ 判定 $A_{\mathrm{TM}}$。使用 $H$ 构建一个图灵机 $D$,它接受输入 $\langle M\rangle$,其中 $D$ 接受其输入 $\langle M\rangle$ 当且仅当 $M$ 不接受其输入 $\langle M\rangle$。最后,在 $D$ 上运行 $D$ 本身。因此,这些机器采取以下行动,最后一行是矛盾。
- $H$ 接受 $\langle M, w\rangle$ 当且仅当 $M$ 接受 $w$。
- $D$ 拒绝 $\langle M\rangle$ 当且仅当 $M$ 接受 $\langle M\rangle$。
- $D$ 拒绝 $\langle D\rangle$ 当且仅当 $D$ 接受 $\langle D\rangle$。
这一段是对刚刚完成的证明进行了一次简洁的复盘,提炼出了最核心的逻辑步骤和关系。
- “让我们回顾一下这个证明的步骤。”:
- 表明这是一个总结性的段落,帮助读者巩固理解。
- “假设图灵机 $H$ 判定 $A_{\mathrm{TM}}$。”:
- 步骤1: 整个反证法的起点,即假设存在一个能解决停机问题的判定器 $H$。
- “使用 $H$ 构建一个图灵机 $D$,它接受输入 $\langle M\rangle$,其中 $D$ 接受其输入 $\langle M\rangle$ 当且仅当 $M$ 不接受其输入 $\langle M\rangle$。”:
- 步骤2: 利用 $H$ 作为工具,构造出“捣蛋鬼”机器 $D$。这里对 $D$ 的行为描述得非常精确:$D(\langle M\rangle)$ 的结果与 $M(\langle M\rangle)$ 的结果正好相反。
- “最后,在 $D$ 上运行 $D$ 本身。”:
- 步骤3: 触发悖论的关键动作,让 $D$ 对自己进行操作。
- “因此,这些机器采取以下行动,最后一行是矛盾。”:
- 下面三行是对三台机器($H$, $D$, 和作用于自身的 $D$)行为的最终概括。
- “- $H$ 接受 $\langle M, w\rangle$ 当且仅当 $M$ 接受 $w$。”:
- 这是对判定器 $H$ 功能的定义。它是“诚实的预言家”。
- “- $D$ 拒绝 $\langle M\rangle$ 当且仅当 $M$ 接受 $\langle M\rangle$。”:
- 这是对机器 $D$ 行为的概括。注意,这里用“拒绝”来描述,它等价于前文的“如果 $M$ 接受 $\langle M \rangle$ 则拒绝,如果 $M$ 不接受 $\langle M \rangle$ 则接受”。如果 $M$ 接受, $D$ 就拒绝;如果 $M$ 不接受,$D$ 才接受。所以这行描述是准确的。它是“唱反调者”。
- “- $D$ 拒绝 $\langle D\rangle$ 当且仅当 $D$ 接受 $\langle D\rangle$。”:
- 将上一行的通用规则中的 $M$ 特例化为 $D$ 本身,直接得到了这个赤裸裸的矛盾。这个陈述在逻辑上是荒谬的,就像说“天下雨当且仅当天下不下雨”。
我们用 true 代表“接受”,false 代表“不接受”。
- H的行为: H(M, w) = M(w)
- D的行为: D(M) = !M(M) (其中 ! 是逻辑非)
- 最后的悖论:
- D(D) = !D(D)
- 让 x = D(D),那么 x = !x。
- 如果 x 是 true,那么 true = !true,即 true = false,矛盾。
- 如果 x 是 false,那么 false = !false,即 false = true,矛盾。
- 这个简单的逻辑表达式 x = !x 完美地捕捉了悖论的核心。
- 理解“当且仅当”: “A 当且仅当 B” (A iff B) 意味着 A 和 B 必须同真同假。而 “$D$ 拒绝 ... 当且仅当 $D$ 接受 ...” 意味着 (D拒绝) 和 (D接受) 必须同真同假。但 “拒绝” 和 “接受” 是互斥的,不可能同真同假,所以矛盾。
本段用三句高度浓缩的陈述,提炼了 $A_{\mathrm{TM}}$ 不可判定性证明的全部精华。它清晰地展示了从一个看似合理的假设($H$ 的存在),如何合乎逻辑地构造出一个行为相反的机器 $D$,并最终在将 $D$ 应用于自身时,如何不可避免地导向一个自我毁灭的逻辑矛盾。
本段的目的是为读者提供一个“记忆锚点”。复杂的证明过程很容易忘记,但这个三步走的、高度概括的版本很容易被记住。它就像一个“电梯演讲”,让读者可以在30秒内向他人清晰地解释这个深刻证明的核心思想。
[直觉心-智模型]
这是一个三步的逻辑推理:
- 公理(假设): 存在一个绝对诚实的人 $H$。
- 构造: 我们找到一个绝对的“杠精” $D$,他的原则是:对于任何一个人 $M$,$H$ 对 $M$ 的评价是什么,$D$ 对 $M$ 的评价就正好相反。
- 悖论: 我们问这个“杠精” $D$:“你对自己的评价是什么?”。他的回答必然与他自己的原则相冲突。
- 结论: “杠精” $D$ 不可能存在,因此我们找到他的前提——“诚实人” $H$ 的存在——也必然是假的。
想象一个愿望清单:
- 我希望:有一个能实现任何愿望的神灯 $H$。
- 我希望:创造一个“许愿机器人” $D$,它的功能是:找到神灯 $H$,让它预测“如果我许愿要X,愿望能实现吗?”,然后机器人 $D$ 就许一个与 X 相反的愿-望。
- 我希望:让这个机器人 $D$ 去许一个关于“它自己能否许愿成功”的愿望。
最后一步必然导致逻辑崩溃,从而证明第一个愿望(神灯 $H$ 的存在)是不可能实现的。
5.1 证明中的对角化元素
📜 [原文28]
定理4.11的证明中的对角化在哪里?当你检查图灵机 $H$ 和 $D$ 的行为表时,它就会变得显而易见。在这些表中,我们列出了所有图灵机( $M_{1}, M_{2}, \ldots$)在行中,以及它们的所有描述( $\left\langle M_{1}\right\rangle,\left\langle M_{2}\right\rangle, \ldots$)在列中。条目说明给定行中的机器是否接受给定列中的输入。如果机器接受输入,则条目为“接受”,如果它拒绝或循环,则为空白。我们编造了下图中的条目来说明这个想法。
| $\left\langle M_{1}\right\rangle$ | $\left\langle M_{2}\right\rangle$ | $\left\langle M_{3}\right\rangle$ | $\left\langle M_{4}\right\rangle$ | $\ldots$ | |
|---|---|---|---|---|---|
| $M_{1}$ | accept | accept | |||
| $M_{2}$ | accept | accept | accept | accept | |
| $M_{3}$ | $\ldots$ | ||||
| $M_{4}$ | accept | accept | |||
| $\vdots$ | $\vdots$ |
图 4.19
条目 $i, j$ 为接受,如果 $M_{i}$ 接受 $\left\langle M_{j}\right\rangle$
这一段通过引入一个二维表格,直观地揭示了刚刚完成的证明与康托尔对角化论证在结构上的相似性。
- “定理4.11的证明中的对角化在哪里?”:
- 一个设问。到目前为止,我们只看到了逻辑推导,并没有像之前证明实数不可数时那样明显地构造一个“沿着对角线”不同的对象。本段就是要揭示这个隐藏的对角化结构。
- “当你检查图灵机 $H$ 和 $D$ 的行为表时,它就会变得显而易见。”:
- 答案在于将机器的行为可视化。
- “在这些表中,我们列出了所有图灵机( $M_{1}, M_{2}, \ldots$)在行中,以及它们的所有描述( $\left\langle M_{1}\right\rangle,\left\langle M_{2}\right\rangle, \ldots$)在列中。”:
- 构建表格:
- 行: 代表所有的图灵机。因为我们证明了图灵机集是可数的,所以我们可以将它们排成一个列表 $M_1, M_2, M_3, \dots$。
- 列: 代表所有图灵机的编码。这些也是可数的,我们按与行相同的顺序列出 $\langle M_1 \rangle, \langle M_2 \rangle, \langle M_3 \rangle, \dots$。
- 这个表格是一个无限大的方阵。
- “条目说明给定行中的机器是否接受给定列中的输入。”:
- 表格内容: 表格中第 $i$ 行、第 $j$ 列的条目,记录的是图灵机 $M_i$ 在输入 $\langle M_j \rangle$ 上的运行结果。
- 这个表格描绘了一个“所有图灵机相互作用”的全景图。
- “如果机器接受输入,则条目为“接受”,如果它拒绝或循环,则为空白。”:
- 定义了表格条目的填写规则。这是 $M_i$ 的真实行为。
- “我们编造了下图中的条目来说明这个想法。”:
- 图4.19 展示了这个表格的一个假想的、具体的样子。
- 解读图4.19:
- (行1, 列1) 是 accept: 意味着 $M_1$ 接受输入 $\langle M_1 \rangle$。
- (行1, 列2) 是 空白: 意味着 $M_1$ 不接受输入 $\langle M_2 \rangle$ (拒绝或循环)。
- (行2, 列1) 是 accept: 意味着 $M_2$ 接受输入 $\langle M_1 \rangle$。
- 表格的对角线:
- 这张表的主对角线(从左上到右下)上的条目分别是:
- (行1, 列1): $M_1$ 在输入 $\langle M_1 \rangle$ 上的行为。
- (行2, 列2): $M_2$ 在输入 $\langle M_2 \rangle$ 上的行为。
- (行 $i$, 列 $i$): $M_i$ 在输入 $\langle M_i \rangle$ 上的行为。
- 对角线上的行为,正是机器“以自身描述为输入”时的行为,这是我们构造 $D$ 的关键所在。
- 根据图4.19的虚构数据:
- $M_1(\langle M_1 \rangle)$ -> 接受
- $M_2(\langle M_2 \rangle)$ -> 接受
- $M_3(\langle M_3 \rangle)$ -> 不接受 (空白)
- $M_4(\langle M_4 \rangle)$ -> 不接受 (空白)
- 表格的存在性: 这个无限大的表格是一个理论上的构造,我们无法在现实中完整地画出它。但它的存在性是建立在图灵机集是可数的这一事实之上的。只要能列表,就能画表。
本段通过将所有图灵机对自己和其他图灵机编码的行为组织成一个无限的二维表格,为揭示证明中的对角化本质提供了可视化工具。表格的行和列都是所有图灵机的列表,表格的条目 $(i, j)$ 代表机器 $M_i$ 对输入 $\langle M_j \rangle$ 的行为。这个表格的对角线,即条目 $(i, i)$,代表了机器作用于自身描述时的行为,这正是我们构造“捣蛋鬼”机器 $D$ 时所关注的核心问题。
本段的目的是在抽象的逻辑证明和康托尔经典的对角化图像之间建立一座桥梁。通过引入这个表格,它使得读者可以将证明 $A_{\mathrm{TM}}$ 不可判定的过程,与之前证明实数不可数的过程进行类比,从而更深刻地理解两者在底层逻辑结构上的同构性。
想象一个“社交网络”的行为矩阵。
- 行/列: 网络里的每一个人 $P_1, P_2, \dots$。
- 条目 $(i, j)$: 代表 $P_i$ 对 $P_j$ 的看法(比如“喜欢”或“不喜欢”)。
- 对角线: 条目 $(i, i)$ 代表 $P_i$ 对自己的看法(“自恋”或“自卑”)。
- 我们构造的机器 $D$ 就是一个专门和对角线上的人唱反调的“杠精”。
你有一张巨大的棋盘,代表所有可能的图灵机相互作用的结果。
- 你让第 $i$ 号机器人($M_i$)去处理第 $j$ 号机器人的蓝图($\langle M_j \rangle$)。结果记录在 $(i, j)$ 格子里。
- 对角线就是每个机器人处理自己蓝图的结果。
- 图4.19 就是这张记录了所有“真实结果”的棋盘。
📜 [原文29]
在下图中,条目是在与图4.19对应的输入上运行 $H$ 的结果。因此,如果 $M_{3}$ 不接受输入 $\left\langle M_{2}\right\rangle$,则 $M_{3}$ 行和 $\left\langle M_{2}\right\rangle$ 列的条目为拒绝,因为 $H$ 拒绝输入 $\left\langle M_{3},\left\langle M_{2}\right\rangle\right\rangle$。
| $\left\langle M_{1}\right\rangle$ | $\left\langle M_{2}\right\rangle$ | $\left\langle M_{3}\right\rangle$ | $\left\langle M_{4}\right\rangle$ | $\cdots$ | |
|---|---|---|---|---|---|
| $M_{1}$ | accept | reject | accept | reject | |
| $M_{2}$ | accept | accept | accept | accept | $\ldots$ |
| $M_{3}$ | reject | reject | reject | reject | |
| $M_{4}$ | accept | accept | reject | reject | |
| $\vdots$ | $\vdots$ |
图 4.20
条目 $i, j$ 是 $H$ 在输入 $\left\langle M_{i},\left\langle M_{j}\right\rangle\right\rangle$ 上的值
这一段展示了假设存在的判定器 $H$ 会生成什么样的行为表格。
- “在下图中,条目是在与图4.19对应的输入上运行 $H$ 的结果。”:
- 图4.20 与 图4.19 的行列定义完全相同,但条目的含义不同。
- 图4.19 的条目是“真实结果”($M_i$ 对 $\langle M_j \rangle$ 的实际行为,可能是 accept 或 空白(拒绝/循环))。
- 图4.20 的条目是“判定器 $H$ 的预测结果”($H$ 对输入 $\langle M_i, \langle M_j \rangle \rangle$ 的输出,只可能是 accept 或 reject)。
- “因此,如果 $M_{3}$ 不接受输入 $\left\langle M_{2}\right\rangle$,则 $M_{3}$ 行和 $\left\langle M_{2}\right\rangle$ 列的条目为拒绝...”:
- 解释了两个表格的关系。因为我们假设 $H$ 是一个完美的判定器,所以 $H$ 的输出必须与真实结果完全一致。
- $H$ 接受 $\langle M_i, \langle M_j \rangle \rangle \iff M_i$ 接受 $\langle M_j \rangle$。
- $H$ 拒绝 $\langle M_i, \langle M_j \rangle \rangle \iff M_i$ 不接受 $\langle M_j \rangle$ (包括拒绝或循环)。
- 所以,图4.20 本质上是图4.19 的“填空版”。所有 空白 的地方都被 $H$ 准确地识别并填上了 reject。
- 图4.20的解读:
- 这是一个“完美”的表格,没有任何空白。每一格都有一个确定的 accept 或 reject 答案。
- 它的存在,完全建立在“$H$ 存在”这个假设之上。
- 对角线上的值现在是:
- accept (在 (1,1) 处): $H$ 预测 $M_1$ 接受 $\langle M_1 \rangle$。
- accept (在 (2,2) 处): $H$ 预测 $M_2$ 接受 $\langle M_2 \rangle$。
- reject (在 (3,3) 处): $H$ 预测 $M_3$ 不接受 $\langle M_3 \rangle$。
- reject (在 (4,4) 处): $H$ 预测 $M_4$ 不接受 $\langle M_4 \rangle$。
- 对比图4.19和图4.20中 (行1, 列2) 的条目:
- 图4.19 (真实行为): 空白。意味着 $M_1$ 实际上在输入 $\langle M_2 \rangle$ 上拒绝或循环。
- 图4.20 ($H$的预测): reject。因为 $H$ 是完美的,它正确地预测到了 $M_1$ 的不接受行为。
- 对比图4.19和图4.20中 (行1, 列1) 的条目:
- 图4.19: accept。$M_1$ 接受 $\langle M_1 \rangle$。
- 图4.20: accept。$H$ 正确地预测到了这一点。
- 表格的真实性: 图4.19 代表了“客观现实”,尽管我们可能无法完全知晓所有空白格的真相(因为停机问题)。图4.20 代表了一个“理想化的预测”,它的存在性是我们正在质疑的。
本段通过图4.20,展示了如果一个完美的判定器 $H$ 存在,那么关于所有图灵机相互作用的“行为表”将会是什么样子。这个表格是完整的、没有歧义的,所有原来因为“无限循环”而无法确定的行为,都被 $H$ 准确地判定为了“reject”。这张完美的表格,尤其是它的对角线,是我们构造矛盾的关键。
本段的目的是将假设的判定器 $H$ 的行为进行可视化,并为下一步引入“捣蛋鬼” $D$ 的行为做准备。$D$ 的构造逻辑就是针对这个完美的图4.20的对角线进行“反转”。
回到“社交网络”矩阵。
- 图4.19: 真实的喜好关系。有些人对别人的看法是“说不清/没想好”(空白/循环)。
- 图4.20: 假设存在一个“读心神探” $H$。他能看透所有人的心思。他制作的这张表格,把所有“说不清”的关系都明确标为“不喜欢” (reject)。这张表是完整的、全知的。
回到“机器人下棋”的棋盘。
- 图4.19: 真实的比赛结果。有些棋局,两个机器人水平相当,可能会下成无限循环的和棋(空白)。
- 图4.20: 假设存在一个“棋神” $H$。他能预测任何两个机器人对弈的结果。他制作的这张结果表,把所有无限循环的和棋都直接判定为“非赢”(reject)。这张表里只有“赢”和“不赢”两种结果。
📜 [原文30]
在下图中,我们将 $D$ 添加到图4.20中。根据我们的假设,$H$ 是一个图灵机,$D$ 也是。因此,它必须出现在所有图灵机的列表 $M_{1}, M_{2}, \ldots$ 中。请注意, $D$ 计算的是对角线条目的相反。矛盾发生在问号处,该处的条目必须与自身相反。
| $\left\langle M_{1}\right\rangle$ | $\left\langle M_{2}\right\rangle$ | $\left\langle M_{3}\right\rangle$ | $\left\langle M_{4}\right\rangle$ | ⋯ | $\langle D\rangle$ | ⋯ | |
|---|---|---|---|---|---|---|---|
| $M_{1}$ | accept | reject | accept | reject | accept | ||
| $M_{2}$ | accept | accept | accept | accept | … | accept | |
| $M_{3}$ | reject | reject | reject | reject | reject | ||
| $M_{4}$ | accept | accept | reject | $\underline{\text { reject }}$ | accept | ||
| ⋮ | ⋮ | ⋱ | |||||
| D | reject | reject | accept | accept | ? | ||
| : | ⋮ | ⋱ |
图 4.21
如果 $D$ 在图中,问号处就会发生矛盾
这是整个对角化可视化论证的最后一步,图穷匕见,矛盾被清晰地展示在表格中。
- “在下图中,我们将 $D$ 添加到图4.20中。”:
- 图4.21 是基于图4.20的扩展。
- “根据我们的假设,$H$ 是一个图灵机,$D$ 也是。因此,它必须出现在所有图灵机的列表 $M_{1}, M_{2}, \ldots$ 中。”:
- 这是至关重要的一步。既然 $D$ 是一个合法的图灵机,那么它必然是图灵机列表中的一员。
- 假设 $D$ 就是列表中的第 $k$ 个图灵机 $M_k$。那么表格中就应该有一行是“$D$ 行”,也有一列是“$\langle D \rangle$ 列”。
- “请注意, $D$ 计算的是对角线条目的相反。”:
- 回顾 $D$ 的定义:$D(\langle M_i \rangle)$ 的结果是 $H(\langle M_i, \langle M_i \rangle \rangle)$ 的相反。
- $H(\langle M_i, \langle M_i \rangle \rangle)$ 正是图4.20中对角线上第 $i$ 个条目的值。
- 所以,$D$ 的行为(即 $D$ 这一行的数据)是通过“反转”图4.20的对角线来生成的。
- 让我们来生成 $D$ 行:
- 对角线第1个值是 accept -> $D$ 行第1列的值是 reject。
- 对角线第2个值是 accept -> $D$ 行第2列的值是 reject。
- 对角线第3个值是 reject -> $D$ 行第3列的值是 accept。
- 对角线第4个值是 reject -> $D$ 行第4列的值是 accept。
- ... 这就是图4.21中 $D$ 行的由来。
- “矛盾发生在问号处,该处的条目必须与自身相反。”:
- 问号在哪里?它在 $D$ 行和 $\langle D \rangle$ 列的交叉点。
- 这个问号代表的值是 $H(\langle D, \langle D \rangle \rangle)$,也就是判定器 $H$ 对 $D$ 在自己描述上运行的预测结果。
- 让我们来分析这个问号:
- 从 $D$ 行的定义来看: $D$ 行的第 $D$ 列(即问号所在的这一格),是对角线上第 $D$ 个元素的反面。而对角线上第 $D$ 个元素,正是问号自己!所以,问号的值 = 非 问号的值。
- 从 $D$ 机器本身的行为来看: 问号的值,是 $H$ 对 $D(\langle D \rangle)$ 的预测。而 $D(\langle D \rangle)$ 的行为,被定义为 $H(\langle D, \langle D \rangle \rangle)$ (即问号的值)的相反。所以,$D$ 的真实行为是问号的反面。因为 $H$ 必须做出正确的预测,所以问号必须等于 $D$ 的真实行为,也就是问号必须等于它自己的反面。
- 结论: 无论从哪个角度看,问号所在格子的值都必须等于它自己的反面 (accept iff reject)。这是一个尖锐的、无法回避的逻辑矛盾。
看图4.21:
- $D$ 行的值是这样得到的:
- reject (第1列) = NOT (accept (对角线第1个))
- reject (第2列) = NOT (accept (对角线第2个))
- accept (第3列) = NOT (reject (对角线第3个))
- accept (第4列) = NOT (reject (对角线第4个))
- 现在看 ? 这个格子。它在 $D$ 行,也在对角线上。
- 根据 $D$ 行的生成规则,? 的值必须是对角线上 ? 这个值的反面。
- ? = NOT(?)。
- 这就是悖论。
- D 不在列表里?: 有人可能会想,如果 $D$ 不在 $M_1, M_2, ...$ 的列表里,不就没有这个悖论了吗?但这不可能。因为我们证明了所有图灵机的集合是可数的,所以任何一个合法的图灵机(比如 $D$)都必然在这个列表的某个位置。这个论证是无法逃避的。
本段通过可视化的表格,将对角化证明的矛盾点聚焦到了一个具体的格子——“问号”上。通过分析“捣蛋鬼”机器 $D$ 的行为(反转对角线)和它自身也必须是表格中一行的事实,我们发现 $D$ 行与 $\langle D \rangle$ 列交叉处的条目必须是其自身值的否定。这个无可否认的逻辑悖论,直观且有力地摧毁了整个表格(以及判定器 $H$)存在的可能性。
本段的目的是为整个证明画上一个直观、清晰、令人印象深刻的句号。相比于纯粹的符号推导,这张带有“问号”的表格使得对角化的思想跃然纸上。它让读者能够“看”到悖论是如何产生的,从而将抽象的逻辑和康托尔的几何直觉完美地结合在了一起。
回到“社交网络”和“读心神探” $H$ 的例子。
- 神探 $H$ 制作了一张完美的“喜好关系”表(图4.20)。
- 现在网络里来了一个“杠精” $D$。他的交友原则是:看一遍神探的表的对角线(即每个人对自己的看法),然后 $D$ 对每个人的看法,都和那个人对自己的看法相反。
- 因为 $D$ 也是网络的一员,所以神探的完美关系表里也必须有 $D$ 这一行和 $D$ 这一列。
- 矛盾就出现在 ($D$ 行, $D$ 列) 这个格子里。这个格子记录了 $D$ 对 $D$ 的看法。
- 根据杠精 $D$ 的原则,他对 $D$ 的看法,必须和 $D$ 对自己的看法(也就是这个格子本身的值)相反。
- 所以这个格子的值必须是它自身的反面。这是不可能的。
- 结论:能制作出完美关系表的“读心神探” $H$ 不可能存在。
你是一个画家,要画一幅包含了“世界上所有可能的画”的画廊的画。
- 你把所有画(可数的,假设)编号为 $P_1, P_2, \dots$。
- 你的大画廊里,第 $i$ 行就挂着画 $P_i$。
- 现在,你开始画一幅新的“捣蛋画” $D$。你设计的规则是:
- $D$ 的左上角区域,要和 $P_1$ 的左上角区域颜色相反。
- $D$ 的中心区域,要和 $P_2$ 的中心区域颜色相反。
- ...
- $D$ 的第 $i$ 个区域,要和 $P_i$ 的第 $i$ 个区域颜色相反。
- 你画好了这幅画 $D$。
- 问题: $D$ 这幅画,应该挂在画廊的哪一行?
- 假设它挂在第 $k$ 行。那么 $D=P_k$。
- 但根据 $D$ 的创作规则,它的第 $k$ 个区域必须和 $P_k$ 的第 $k$ 个区域颜色相反。
- 所以 $D$ 不可能等于 $P_k$。
- 矛盾: 你画出的这幅画 $D$ 和画廊里的任何一幅画都不同。所以这个“包含了所有画”的画廊,实际上并没有包含所有画。这个宣称是自相矛盾的。
116. 一个图灵不可识别的语言 (A TURING-UNRECOGNIZABLE LANGUAGE)
6.1 从不可判定到不可识别
📜 [原文31]
在上一节中,我们展示了一种不可判定的语言——即 $A_{\text {TM }}$。现在我们展示一种甚至不是图灵可识别的语言。请注意, $A_{\text {TM }}$ 不能用于此目的,因为我们已经证明 $A_{\text {TM }}$ 是图灵可识别的(第202页)。以下定理表明,如果一种语言及其补集都是图灵可识别的,那么该语言就是可判定的。因此,对于任何不可判定的语言,它或它的补集都不是图灵可识别的。回想一下,一种语言的补集是由所有不属于该语言的字符串组成的语言。如果一种语言是图灵可识别语言的补集,我们称之为协同图灵可识别的。
这一段引入了计算理论中又一个重要的语言类别——图灵不可识别语言,并提出了一个关键定理,将可判定性与可识别性联系起来。
- “在上一节中,我们展示了一种不可判定的语言——即 $A_{\text {TM }}$。”:
- 回顾已知结论:$A_{\text{TM}}$ 是我们第一个证明了的不可判定语言。
- “现在我们展示一种甚至不是图灵可识别的语言。”:
- 提出新的、更高的目标:寻找一个连图灵可识别都做不到的语言。
- 这标志着我们进入了“不可解问题”的更深层次。
- 回顾:
- 可判定: 存在一个图灵机,对所有输入都停机并给出“是”或“否”。
- 可识别: 存在一个图灵机,对所有“是”的输入能停机并回答“是”,对“否”的输入可以回答“否”或无限循环。
- 不可识别: 不存在任何图灵机能做到上述“可识别”的要求。
- “请注意, $A_{\text {TM }}$ 不能用于此目的,因为我们已经证明 $A_{\text {TM }}$ 是图灵可识别的”:
- 排除了一个可能的错误想法。$A_{\text{TM}}$ 虽然不可判定,但它属于“半可解”的图灵可识别语言类。我们需要找一个比它“更难”的语言。
- “以下定理表明,如果一种语言及其补集都是图灵可识别的,那么该语言就是可判定的。”:
- 这是本段最重要的部分,提出了一个核心定理(定理4.22)。
- 补集 (Complement): 对于一个定义在字母表 $\Sigma^*$ 上的语言 $L$,它的补集 $\bar{L}$ 包含所有在 $\Sigma^*$ 中但不在 $L$ 中的字符串。$\bar{L} = \Sigma^* - L$。
- 定理内容:
- 设语言为 $A$。
- 条件1: $A$ 是图灵可识别的。
- 条件2: $\bar{A}$ (A的补集) 也是图灵可识别的。
- 结论: 如果这两个条件同时满足,那么 $A$ 一定是可判定的。
- “因此,对于任何不可判定的语言,它或它的补集都不是图灵可识别的。”:
- 这是上述定理的逆否命题,逻辑上等价。
- 定理 (原命题): (A可识别 AND $\bar{A}$可识别) $\implies$ A可判定。
- 逆否命题: (A不可判定) $\implies$ NOT (A可识别 AND $\bar{A}$可识别)。
- NOT (P AND Q) 等价于 (NOT P) OR (NOT Q)。
- 所以逆否命题展开就是:如果 $A$ 是不可判定的,那么要么 $A$ 是不可识别的,要么 $\bar{A}$ 是不可识别的(或者两者都是)。
- 这个推论给我们提供了一条寻找不可识别语言的明确路径:找到一个不可判定的语言,然后检查它和它的补集。
- **“
回想一下,一种语言的补集是由所有不属于该语言的字符串组成的语言。如果一种语言是图灵可识别语言的补集,我们称之为协同图灵可识别的。”**:
- 协同图灵可识别 (co-Turing-recognizable): 这是一个新的术语定义。
- 语言 $L$ 是协同图灵可识别的 $\iff$ 其补集 $\bar{L}$ 是图灵可识别的。
- 直观意义:
- 对于一个可识别语言,我们能确切地验证“是”的答案(机器停机接受)。
- 对于一个协同图灵可识别语言,我们能确切地验证“否”的答案。因为要判断一个字符串 $w$ 是否属于 $L$,我们可以把它喂给 $\bar{L}$ 的识别器。如果这个识别器接受了 $w$,我们就百分之百确定 $w \in \bar{L}$,从而百分之百确定 $w \notin L$。
- 因此,定理4.22可以被重新表述为:一个语言是可判定的,当且仅当它既是图灵可识别的,又是协同图灵可识别的。
- 定理应用示例:
- 语言A: $A_{\text{DFA}}$ (判断DFA是否接受字符串)。我们知道它是可判定的。
- 根据定理, $A_{\text{DFA}}$ 必须是图灵可识别的(显然是的,判定器就是一种识别器),并且它的补集 $\overline{A_{\text{DFA}}}$ 也必须是图灵可识别的。
- $\overline{A_{\text{DFA}}}$ 是什么?它是所有使得DFA $B$ 不接受 $w$ 的 $\langle B, w\rangle$ 的集合。我们也可以轻易为它构造一个判定器(只需模拟DFA运行后,将接受和拒绝状态的判断反过来即可),因此它也是可识别的。定理成立。
- 寻找不可识别语言的路径:
- 我们已知 $A_{\text{TM}}$ 是不可判定的。
- 我们已知 $A_{\text{TM}}$ 是图灵可识别的。
- 将 $A_{\text{TM}}$ 代入定理4.22的逆否命题:因为 $A_{\text{TM}}$ 不可判定,所以要么 $A_{\text{TM}}$ 不可识别,要么 $\overline{A_{\text{TM}}}$ 不可识别。
- 我们已经知道 $A_{\text{TM}}$ 是可识别的,排除了第一种可能。
- 因此,唯一的结论是:$\overline{A_{\text{TM}}}$ 必须是图灵不可识别的。
- 这样,我们就找到了第一个图灵不可识别语言的具体例子。
- 对称性: 可判定语言的集合对于“取补集”这个操作是封闭的。如果 $L$ 可判定,则 $\bar{L}$ 也可判定。
- 非对称性: 图灵可识别语言的集合对于“取补集”这个操作是不封闭的。我们即将看到,$A_{\text{TM}}$ 是可识别的,但其补集 $\overline{A_{\text{TM}}}$ 却不是。
本段为寻找图灵不可识别语言提供了关键的理论工具——定理4.22。该定理指出,一个语言是可判定的,充要条件是它和它的补集都是图灵可识别的。其重要的推论(逆否命题)是:任何不可判定的语言,其自身或其补集必然是图灵不可识别的。同时,本段引入了“协同图灵可识别”这一术语,用来描述那些补集是图灵可识别的语言。
本段的目的是在“不可判定”和“不可识别”之间建立一座逻辑桥梁。它展示了如何利用一个语言及其补集的性质,来精确判断该语言在可计算性层级中的位置。这为我们从已知的不可判定语言 $A_{\text{TM}}$ 出发,逻辑地推导出第一个不可识别语言 $\overline{A_{\text{TM}}}$ 铺平了道路。
想象一个法院系统。
- 可识别语言 (有罪推定): 检察官(识别器)负责寻找证据证明嫌疑人“有罪”(属于语言)。如果找到了铁证,就判有罪。如果找不到,案子就可能无限期地拖延下去(循环)。
- 协同图灵可识别语言 (无罪推定): 辩护律师(补集的识别器)负责寻找证据证明嫌疑人“无罪”(属于补集)。如果找到了铁证(比如完美的不在场证明),就判无罪。如果找不到,案子也可能无限期拖延。
- 可判定语言 (完美法院): 法官(判定器)是全知的。他既能看到检察官的所有证据,也能看到辩护律师的所有证据。因为一个人要么有罪要么无罪,所以两者必有一方能提供铁证。因此,法官总能在有限时间内做出“有罪”或“无罪”的最终判决。
- 定理4.22说的就是:一个案子是可判定的,当且仅当它既能被“有罪推定”也能被“无罪推定”。
你有一对特殊的“化学试纸”。
- 试纸A (识别器): 遇到“酸性”液体(语言成员)会变红。遇到中性或碱性液体,它没反应或溶解了(循环)。
- 试纸B (补集的识别器): 遇到“碱性”液体(补集成员)会变蓝。遇到中性或酸性液体,它没反应或溶解了。
定理4.22说的是:
- 如果你想判断一种未知液体是“酸性”还是“碱性”(可判定问题),你需要同时拥有试纸A和试纸B。
- 你把两张试纸同时放进液体里。
- 如果试纸A变红,你就知道是酸性。
- 如果试纸B变蓝,你就知道是碱性。
- 由于任何液体要么是酸性要么是碱性(假设中性不存在),所以两张试纸中必然有一张会变色。你总能得到答案。
- 如果一个问题是不可判定的(比如 $A_{\text{TM}}$),那就意味着你不可能同时拥有能检测它和它的补集的两张完美试纸。
6.2 可判定性、可识别性与协同可识别性的关系
📜 [原文32]
定理 (THEOREM) 4.22
一种语言是可判定的当且仅当它是图灵可识别的且是协同图灵可识别的。
换句话说,一种语言是可判定的,当且仅当它和它的补集都是图灵可识别的。
证明:我们需要证明两个方向。首先,如果 $A$ 是可判定的,我们可以很容易地看到 $A$ 和它的补集 $\bar{A}$ 都是图灵可识别的。任何可判定的语言都是图灵可识别的,可判定的语言的补集也是可判定的。
另一方面,如果 $A$ 和 $\bar{A}$ 都是图灵可识别的,我们设 $M_{1}$ 为 $A$ 的识别器, $M_{2}$ 为 $\bar{A}$ 的识别器。以下图灵机 $M$ 是 $A$ 的判定器。
$M=$ “在输入 $w$ 上:
- 在输入 $w$ 上并行运行 $M_{1}$ 和 $M_{2}$。
- 如果 $M_{1}$ 接受,则接受;如果 $M_{2}$ 接受,则拒绝。”
并行运行这两台机器意味着 $M$ 有两条磁带,一条用于模拟 $M_{1}$,另一条用于模拟 $M_{2}$。在这种情况下,$M$ 轮流模拟每台机器的一个步骤,直到其中一台接受。
现在我们表明 $M$ 判定 $A$。每个字符串 $w$ 要么在 $A$ 中,要么在 $\bar{A}$ 中。因此, $M_{1}$ 或 $M_{2}$ 必须接受 $w$。因为当 $M_{1}$ 或 $M_{2}$ 接受时 $M$ 就会停机,所以 $M$ 总是停机,因此它是一个判定器。此外,它接受 $A$ 中的所有字符串,并拒绝不在 $A$ 中的所有字符串。所以 $M$ 是 $A$ 的一个判定器,因此 $A$ 是可判定的。
这一段给出了定理4.22的完整证明。证明分为两个方向。
第一部分:证明 "如果 $A$ 可判定,则 $A$ 和 $\bar{A}$ 都可识别"
- “证明:我们需要证明两个方向。”:
- “当且仅当” (if and only if) 的证明标准,需要分别证明 P -> Q 和 Q -> P。
- “首先,如果 $A$ 是可判定的...”:
- 这是第一个方向的证明(从“可判定”推向“可识别且协同可识别”)。
- 假设: $A$ 是一个可判定语言。这意味着存在一个判定器 $M_A$,它在任何输入上都停机,并且接受 $A$ 中的字符串,拒绝不在 $A$ 中的字符串。
- “...我们可以很容易地看到 $A$ 和它的补集 $\bar{A}$ 都是图灵可识别的。”:
- 证明 $A$ 可识别: 因为 $M_A$ 是一个判定器,它本身就满足识别器的定义(对属于A的字符串停机并接受)。所以 $A$ 是图灵可识别的。
- 证明 $\bar{A}$ 可识别: 我们可以基于 $M_A$ 构造一个 $\bar{A}$ 的判定器 $M_{\bar{A}}$。$M_{\bar{A}}$ 的逻辑是:在输入 $w$ 上运行 $M_A$;如果 $M_A$ 接受,则 $M_{\bar{A}}$ 拒绝;如果 $M_A$ 拒绝,则 $M_{\bar{A}}$ 接受。因为 $M_A$ 总停机,所以 $M_{\bar{A}}$ 也总停机,它是一个判定器。既然 $\bar{A}$ 是可判定的,它自然也是图灵可识别的。
- 结论: 这个方向的证明比较直接,因为可判定性是比可识别性更强的性质。
第二部分:证明 "如果 $A$ 和 $\bar{A}$ 都可识别,则 $A$ 可判定"
- “另一方面,如果 $A$ 和 $\bar{A}$ 都是图灵可识别的...”:
- 这是更关键、更具构造性的第二个方向。
- 假设:
- $A$ 是图灵可识别的,意味着存在一个识别器 $M_1$。
- $\bar{A}$ 也是图灵可识别的,意味着存在一个识别器 $M_2$。
- “以下图灵机 $M$ 是 $A$ 的判定器。”:
- 目标: 利用 $M_1$ 和 $M_2$ 作为“零件”,来构造一个更强大的机器 $M$,并证明 $M$ 是 $A$ 的判定器。
- "$M=$ ‘在输入 $w$ 上...’”:
- 描述了新机器 $M$ 的算法。
- 步骤1: “在输入 $w$ 上并行运行 $M_{1}$ 和 $M_{2}$。”:
- 这是整个构造的核心技巧。我们不能先运行 $M_1$ 再运行 $M_2$,因为如果 $w \notin A$, $M_1$ 可能会无限循环,导致我们永远没有机会运行 $M_2$。
- 并行 (In parallel): 图灵机是单线程的,如何实现“并行”?通过轮流模拟 (Dovetailing)。
- $M$ 的磁带被分成两部分(或使用两条磁带)。
- 在第一条磁带上,模拟 $M_1$ 在 $w$ 上的一步计算。
- 在第二条磁带上,模拟 $M_2$ 在 $w$ 上的一步计算。
- 再回到第一条磁带,模拟 $M_1$ 的第二步。
- 再回到第二条磁带,模拟 $M_2$ 的第二步。
- ...如此交替进行。
- 步骤2: “如果 $M_{1}$ 接受,则接受;如果 $M_{2}$ 接受,则拒绝。”:
- 在并行模拟的过程中,$M$ 不断检查 $M_1$ 和 $M_2$ 的状态。
- 只要发现 $M_1$ 进入了接受状态,$M$ 就立刻停止整个模拟,自己进入接受状态并停机。
- 只要发现 $M_2$ 进入了接受状态,$M$ 就立刻停止整个模拟,自己进入拒绝状态并停机。(因为 $M_2$ 接受 $w$ 意味着 $w \in \bar{A}$,也就是 $w \notin A$)。
- “现在我们表明 $M$ 判定 $A$。”:
- 验证 $M$ 的功能:
- M是否总停机?:
- 任何一个字符串 $w$,要么属于 $A$,要么属于 $\bar{A}$。
- 如果 $w \in A$,$M_1$ 根据定义保证会在有限步骤后接受。
- 如果 $w \in \bar{A}$,$M_2$ 根据定义保证会在有限步骤后接受。
- 所以,对于任何输入 $w$,两个模拟中必然有一个会在有限时间内结束。一旦有一个结束,$M$ 就会停机。
- 结论:$M$ 总是在有限时间内停机,所以它是一个判定器。
- M是否正确判定A?:
- 如果 $w \in A$,$M_1$ 会先接受($M_2$ 可能循环或拒绝),此时 $M$ 接受 $w$。正确。
- 如果 $w \notin A$ (即 $w \in \bar{A}$),$M_2$ 会先接受($M_1$ 可能循环或拒绝),此时 $M$ 拒绝 $w$。正确。
- 最终结论: 我们成功地构造了一个 $A$ 的判定器 $M$。因此,如果一个语言和它的补集都是图灵可识别的,那么这个语言就是可判定的。证明完毕。
- 场景: 假设语言 $A$ 是“所有偶数长度的二进制串”,$\bar{A}$ 是“所有奇数长度的二进制串”。
- $M_1$: 识别偶数长度串的机器。
- $M_2$: 识别奇数长度串的机器。
- (这是一个简单的例子,因为 $A$ 本来就是可判定的,这里只是为了说明 $M$ 的工作流程。)
- 输入 $w = "1010"$ (长度为4,偶数)
- $M$ 开始并行模拟 $M_1("1010")$ 和 $M_2("1010")$。
- Step 1: $M_1$ 走一步, $M_2$ 走一步。
- Step 2: $M_1$ 走一步, $M_2$ 走一步。
- ...
- Step 4: $M_1$ 读完字符串,进入接受状态。
- $M$ 检测到 $M_1$ 接受了,于是 $M$ 立刻停机并接受。
- 输入 $w = "101"$ (长度为3,奇数)
- $M$ 开始并行模拟 $M_1("101")$ 和 $M_2("101")$。
- ...
- Step 3: $M_2$ 读完字符串,进入接受状态。
- $M$ 检测到 $M_2$ 接受了,于是 $M$ 立刻停机并拒绝。
- 这个例子展示了 $M$ 如何通过“赛跑”的方式,等待两个识别器中必然会获胜的那个,从而做出最终判决。
- 并行的重要性: 再次强调,如果不是并行执行,而是串行(先完整运行$M_1$,再运行$M_2$),这个构造就会失败。因为如果 $w \in \bar{A}$,$M_1$ 可能会循环,导致 $M$ 永远无法开始运行 $M_2$。并行是这个证明的灵魂。
- 识别器与判定器: 这个证明揭示了判定器与识别器的深层关系。一个判定器可以看作是两个“互补”的识别器的组合。它能同时从“是”和“否”两个方向寻找证据,并保证总能找到一个。
本段严谨地证明了定理4.22:一个语言 $A$ 是可判定的,当且仅当 $A$ 和其补集 $\bar{A}$ 都是图灵可识别的。证明的关键在于“如果”方向的构造:通过并行运行 $A$ 的识别器 $M_1$ 和 $\bar{A}$ 的识别器 $M_2$,我们构造了一个新的图灵机 $M$。因为任何输入 $w$ 必然会被 $M_1$ 或 $M_2$ 中的一个在有限时间内接受,所以 $M$ 总是停机,从而成为一个完美的判定器。
本段的目的是提供一个坚实的理论基石,它将可判定性这个强大的性质,分解为了两个较弱的、关于可识别性的性质。这个定理本身在计算理论中非常重要,同时它也是我们发现第一个图灵不可识别语言的直接跳板。
“天使与魔鬼”模型。
你要判断一个灵魂 $w$ 是上天堂($\in A$)还是下地狱($\in \bar{A}$)。
- 天使 $M_1$ (A的识别器): 负责在灵魂中寻找“善”的证据。找到了就带他上天堂。找不到就一直找下去。
- 魔鬼 $M_2$ ($\bar{A}$的识别器): 负责在灵魂中寻找“恶”的证据。找到了就拖他下地狱。找不到就一直找下去。
- 上帝 $M$ (判定器): 让天使和魔鬼同时开始工作(并行)。
- 任何一个灵魂,要么是善的,要么是恶的。所以天使和魔鬼中必然有一个能完成他的任务。
- 上帝只要等待,看到天使成功了,就判定“上天堂”;看到魔鬼成功了,就判定“下地狱”。
- 因为总有一个会成功,所以上帝的审判(判定)总能在有限时间内结束。
你在一个岔路口,不知道该往左走(去A城)还是往右走(去非A城)。
你有两个机器人信使,$M_1$ 和 $M_2$。
- $M_1$ 的任务是:沿着左边的路一直走,如果最终到达了A城,就发个信号回来。
- $M_2$ 的任务是:沿着右边的路一直走,如果最终到达了非A城,也发个信号回来。
你不知道哪条路是死胡同(无限循环)。
你的策略(判定器 $M$)是:同时派出两个机器人。然后你就在原地等待。因为路最终要么通向A城要么通向非A城,所以两个机器人中必然有一个会最终到达目的地并发出信号。你一收到信号,就知道该怎么走了。
6.3 $\overline{A_{\text {TM }}}$ 的不可识别性
📜 [原文33]
推论 (corollary) 4.23
$\overline{A_{\text {TM }}}$ 是图灵不可识别的。
证明:我们知道 $A_{\text {TM }}$ 是图灵可识别的。如果 $\overline{A_{\text {TM }}}$ 也是图灵可识别的,那么 $A_{\text {TM }}$ 将是可判定的。定理4.11告诉我们 $A_{\text {TM }}$ 是不可判定的,所以 $\overline{A_{\mathrm{TM}}}$ 必然不是图灵可识别的。
这是本节的收尾,利用刚刚证明的定理4.22,轻松地推导出了第一个图灵不可识别语言的具体例子。
- “$\overline{A_{\text {TM }}}$ 是图灵不可识别的。”:
- 这是推论4.23的陈述。
- $\overline{A_{\text {TM }}}$ 是 $A_{\text {TM }}$ 的补集。它是由所有满足“图灵机 $M$ 不接受字符串 $w$”的编码对 $\langle M, w \rangle$ 组成的集合。
- “证明:我们知道 $A_{\text {TM }}$ 是图灵可识别的。”:
- 前提1: 这是我们在本节开头部分就已经证明了的。我们构造了通用图灵机 $U$ 作为 $A_{\text {TM }}$ 的识别器。
- “如果 $\overline{A_{\text {TM }}}$ 也是图灵可识别的...”:
- 前提2 (反证法的假设): 我们假设 $\overline{A_{\text {TM }}}$ 是图灵可识别的。
- “...那么 $A_{\text {TM }}$ 将是可判定的。”:
- 应用定理4.22: 定理4.22说:如果一个语言($A_{\text {TM }}$)和它的补集($\overline{A_{\text {TM }}}$)都是图灵可识别的,那么这个语言($A_{\text {TM }}$)就是可判定的。
- 基于前提1和前提2,我们直接应用这个定理,得出结论:$A_{\text {TM }}$ 是可判定的。
- “定理4.11告诉我们 $A_{\text {TM }}$ 是不可判定的...”:
- 矛盾来源: 我们刚刚推导出的结论“$A_{\text {TM }}$ 是可判定的”,与本节的核心定理4.11“$A_{\text {TM }}$ 是不可判定的”发生了直接的、尖锐的矛盾。
- “...所以 $\overline{A_{\mathrm{TM}}}$ 必然不是图灵可识别的。”:
- 结论: 既然我们的推导导致了矛盾,那么一定是某个前提出了问题。
- 前提1“$A_{\text {TM }}$ 是图灵可识别的”是我们已经证明了的事实,没有问题。
- 定理4.22也是我们刚刚证明了的,没有问题。
- 那么问题只能出在前提2,即我们的反证法假设“$\overline{A_{\text {TM }}}$ 是图灵可识别的”上。
- 这个假设必须是错误的。
- 因此,$\overline{A_{\text {TM }}}$ 必然不是图灵可识别的。证明完毕。
- 已知事实 A: $A_{\text{TM}}$ 是图灵可识别的 (有识别器 $U$)。
- 已知事实 B: $A_{\text{TM}}$ 是不可判定的 (定理4.11)。
- 已知事实 C: (L 可识别 AND $\bar{L}$ 可识别) $\iff$ L 可判定 (定理4.22)。
- 反证开始:
- 假设: $\overline{A_{\text{TM}}}$ 是图灵可识别的。
- 结合 事实 A ( $A_{\text{TM}}$ 可识别 ) 和我们的假设 ( $\overline{A_{\text{TM}}}$ 可识别 )。
- 应用 事实 C 的 -> 方向,我们得出结论:$A_{\text{TM}}$ 是可判定的。
- 这个结论与 事实 B ( $A_{\text{TM}}$ 不可判定 ) 相矛盾。
- 反证结束: 我们的初始假设是错误的。
- 最终结论: $\overline{A_{\text{TM}}}$ 不是图灵可识别的。
- 非对称性: 这个推论深刻地揭示了图灵可识别语言类和协同图灵可识别语言类之间的不对称性。
- $A_{\text{TM}}$ 属于“可识别但不协同可识别”的语言。
- $\overline{A_{\text{TM}}}$ 属于“协同可识别但不可识别”的语言。
- 而可判定语言必须同时属于这两类。这三类语言共同构成了所谓的“算术层次结构”的底层。
推论4.23 以一种非常简洁和优雅的方式,给出了第一个图灵不可识别语言的具体例子——$\overline{A_{\text {TM }}}$。其证明是一个经典的反证法:首先假设 $\overline{A_{\text {TM }}}$ 是可识别的,然后利用已知的 $A_{\text{TM}}$ 是可识别的,再结合定理4.22,便会导出“$A_{\text {TM }}$ 是可判定的”这一结论。这与我们已经证明的“$A_{\text {TM }}$ 是不可判定的”(定理4.11)相矛盾。因此,最初的假设必为假,$\overline{A_{\text {TM }}}$ 只能是图灵不可识别的。
本推论的目的是将前面所有的理论成果(定理4.11 和 定理4.22)结合起来,最终落地,产出一个具体的、里程碑式的成果:一个被明确指出的图灵不可识别语言。这标志着我们对不可解问题的探索又深入了一层,从“半可解”(可识别但不可判定)进入到了“完全不可解”(不可识别)的领域。
“证据”模型。
- $A_{\text{TM}}$ (停机并接受问题): 这是一个“只需要找肯定证据”的问题。你要证明一个程序会停机并接受,只要耐心地运行它,如果它真的停机接受了,你就拿到了证据。所以它是可识别的。
- $\overline{A_{\text{TM}}}$ (不停机或拒绝问题): 这是一个“需要找否定证据”的问题。你要证明一个程序永不停机接受。
- 如果它停机并拒绝了,你找到了证据。
- 但如果它无限循环,你如何证明它是“永不”停机,而不是“还没”停机?你无法在有限时间内找到“它永不停机”的“铁证”。
- 因为你无法为所有“无限循环”的情况都提供“铁证”,所以你无法构造一个能识别所有属于 $\overline{A_{\text{TM}}}$ 的情况的识别器。因此,$\overline{A_{\text{TM}}}$ 是不可识别的。
寻找“白乌鸦”和“非白乌鸦”。
- 语言A (白乌鸦): 要证明世界上存在白乌鸦(可识别),你只要找到一只就行。找到了,任务就完成了。所以“白乌鸦存在”是可识别的。
- 语言 $\bar{A}$ (非白乌鸦): 要证明“所有乌鸦都是黑的”(即识别“非白乌鸦”这个补集),你需要检查世界上所有的乌鸦,发现没有一只是白的。对于一个无限的世界,这个任务是完不成的。你检查了10亿只都是黑的,你也不能保证第10亿零一只不是白的。
- $\overline{A_{\text{TM}}}$ 就类似于这个“所有乌鸦都是黑的”的问题。你无法通过有限的观察来下一个关于“所有情况”或“永恒”的结论,因此它是不可识别的。
127. 练习 (EXERCISES)
本章节旨在通过具体问题,巩固和应用本章学习到的关于可判定性、可识别性以及集合论的知识。
7.1 练习 4.1
📜 [原文34]
${ }^{\text {A }}$ 4.1 对于以下 DFA $M$,回答所有部分并给出理由。
a. $\langle M, 0100\rangle \in A_{\mathrm{DFA}}$ 吗?
b. $\langle M, 011\rangle \in A_{\mathrm{DFA}}$ 吗?
c. $\langle M\rangle \in A_{\text {DFA }}$ 吗?
d. $\langle M, 0100\rangle \in A_{\text {REX }}$ 吗?
e. $\langle M\rangle \in E_{\text {DFA }}$ 吗?
f. $\langle M, M\rangle \in E Q_{\text {DFA }}$ 吗?
首先,我们需要分析给定的DFA $M$。
- 状态: $\{q_1, q_2\}$
- 起始状态: $q_1$
- 接受状态: $\{q_2\}$
- 字母表: $\{0, 1\}$
- 转移函数:
- $\delta(q_1, 0) = q_1$
- $\delta(q_1, 1) = q_2$
- $\delta(q_2, 0) = q_1$
- $\delta(q_2, 1) = q_2$
这个DFA接受什么样的语言?
- 要想到达接受状态 $q_2$,必须输入一个 '1'。
- 一旦到达 $q_2$,只要后续输入是 '1',就会停留在 $q_2$。
- 如果从 $q_2$ 输入一个 '0',会回到 $q_1$。
- 因此,这个DFA接受所有以 '1' 结尾的字符串。$L(M) = \{w \mid w \text{ ends with a 1}\}$。
现在我们逐一回答问题。
a. $\langle M, 0100\rangle \in A_{\mathrm{DFA}}$ 吗?
- 问题含义: 判断DFA $M$ 是否接受字符串 "0100"。
- 模拟运行:
- $q_1 \xrightarrow{0} q_1$
- $q_1 \xrightarrow{1} q_2$
- $q_2 \xrightarrow{0} q_1$
- $q_1 \xrightarrow{0} q_1$
- 结果: 最终停在状态 $q_1$,$q_1$ 不是接受状态。
- 答案: 否。因为 $M$ 不接受 "0100",所以 $\langle M, 0100\rangle \notin A_{\mathrm{DFA}}$。
b. $\langle M, 011\rangle \in A_{\mathrm{DFA}}$ 吗?
- 问题含义: 判断DFA $M$ 是否接受字符串 "011"。
- 模拟运行:
- $q_1 \xrightarrow{0} q_1$
- $q_1 \xrightarrow{1} q_2$
- $q_2 \xrightarrow{1} q_2$
- 结果: 最终停在状态 $q_2$,$q_2$ 是接受状态。
- 答案: 是。因为 $M$ 接受 "011",所以 $\langle M, 011\rangle \in A_{\mathrm{DFA}}$。
c. $\langle M\rangle \in A_{\text {DFA }}$ 吗?
- 问题含义: 这是一个类型错误的问题。$A_{\text{DFA}}$ 的成员是形如 $\langle B, w \rangle$ 的字符串,其中 $B$ 是一个DFA,$w$ 是一个待检查的字符串。而这里的输入 $\langle M \rangle$ 只有一个部分,它是一个DFA的编码,而不是一个编码对。
- 答案: 否。输入 $\langle M \rangle$ 的格式不符合 $A_{\text{DFA}}$ 的定义。$A_{\text{DFA}}$ 的成员必须是“机器+字符串”的编码对。
d. $\langle M, 0100\rangle \in A_{\text {REX }}$ 吗?
- 问题含义: $A_{\text{REX}} = \{\langle R, w \rangle \mid R \text{ is a regular expression and } L(R) \text{ contains } w\}$。这个问题本身也是类型错误的。它的第一个成员 $\langle M \rangle$ 是一个DFA的编码,而不是一个正则表达式的编码。
- 答案: 否。输入 $\langle M, 0100 \rangle$ 的格式不符合 $A_{\text{REX}}$ 的定义,因为 $M$ 是一个DFA,不是一个正则表达式。
e. $\langle M\rangle \in E_{\text {DFA }}$ 吗?
- 问题含义: $E_{\text{DFA}} = \{\langle A \rangle \mid A \text{ is a DFA and } L(A) = \emptyset\}$。这个问题是在问:DFA $M$ 接受的语言是否为空集?
- 分析: 我们已经知道 $L(M)$ 是所有以 '1' 结尾的字符串。这个集合显然不是空的,例如它包含 "1", "01", "11" 等。
- 答案: 否。因为 $L(M) \neq \emptyset$,所以 $\langle M \rangle \notin E_{\mathrm{DFA}}$。
f. $\langle M, M\rangle \in E Q_{\text {DFA }}$ 吗?
- 问题含义: $EQ_{\text{DFA}} = \{\langle A, B \rangle \mid A \text{ and } B \text{ are DFAs and } L(A) = L(B)\}$。这个问题是在问:DFA $M$ 和 DFA $M$ 自己所接受的语言是否相等?
- 分析: 这是一个平凡的问题。任何一个对象都等于它自身。因此 $L(M)$ 必然等于 $L(M)$。
- 答案: 是。因为 $L(M) = L(M)$,所以 $\langle M, M \rangle \in EQ_{\text{DFA}}$。
7.2 练习 4.2 - 4.9
(由于篇幅和重点,此处对后续练习进行简要解释和思路说明)
4.2 判定DFA和正则表达式是否等价
- 语言: $EQ_{\mathrm{DFA,REX}} = \{\langle A, R \rangle \mid A \text{ is a DFA, } R \text{ is a regex, and } L(A)=L(R)\}$.
- 证明可判定:
- 构造一个DFA $B$,使得 $L(B) = L(R)$。这个算法是已知的(汤普森构造法将正则表达式转为NFA,子集构造法将NFA转为DFA)。
- 现在问题转化为了判定两个DFA($A$ 和 $B$)是否等价。
- 判定 $L(A)=L(B)$ 的算法是已知的:构造一个新的DFA $C$,它接受的语言是 $(L(A) \cap \overline{L(B)}) \cup (\overline{L(A)} \cap L(B))$(即对称差)。
- 然后检查 $L(C)$ 是否为空。$E_{\mathrm{DFA}}$ 是一个可判定的问题。如果 $L(C)$ 为空,则 $L(A)=L(B)$。
- 因为所有步骤都是可判定的算法,所以整个问题是可判定的。
4.3 判定 $ALL_{\mathrm{DFA}}$
- 语言: $ALL_{\mathrm{DFA}}=\left\{\langle A\rangle \mid A\right.$ 是一个 DFA 且 $\left.L(A)=\Sigma^{*}\right\}$。
- 证明可判定:
- 一个DFA $A$ 接受所有字符串,当且仅当它的补语言为空,即 $L(\bar{A}) = \emptyset$。
- 构造DFA $\bar{A}$ 的算法是:将 $A$ 的所有接受状态变为非接受状态,所有非接受状态变为接受状态。
- 现在问题转化为判定 $L(\bar{A})$ 是否为空,即判断 $\langle \bar{A} \rangle$ 是否属于 $E_{\mathrm{DFA}}$。
- $E_{\mathrm{DFA}}$ 是一个可判定的问题(通过检查从起始状态是否能到达任何一个接受状态)。
- 因此,$ALL_{\mathrm{DFA}}$ 是可判定的。
4.4 判定 $A \varepsilon_{\mathrm{CFG}}$
- 语言: $A \varepsilon_{\mathrm{CFG}}=\{\langle G\rangle \mid G$ 是一个生成 $\varepsilon$ 的 CFG $\}$。
- 证明可判定:
- 这是一个标记算法。
- 首先,标记所有形如 $A \to \varepsilon$ 的规则中的变量 $A$。
- 然后,重复以下步骤直到没有新的变量被标记:如果有一条规则 $B \to C_1 C_2 \dots C_k$,并且所有 $C_i$ 都已经被标记了,那么就标记变量 $B$。
- 算法结束后,检查起始符号 $S$ 是否被标记。如果是,则 $G$ 可以生成 $\varepsilon$。
- 这个过程一定会在有限步内结束,因为变量的数量是有限的。所以是可判定的。
4.5 证明 $\overline{E_{\mathrm{TM}}}$ 是图灵可识别的
- 语言: $E_{\mathrm{TM}}=\{\langle M\rangle \mid M$ 是一个 TM 且 $L(M)=\emptyset\}$ (空语言问题)。
- 补集: $\overline{E_{\mathrm{TM}}}=\{\langle M\rangle \mid M$ 是一个 TM 且 $L(M)\neq\emptyset\}$。即,图灵机 $M$ 至少接受一个字符串。
- 构造一个识别器 $R$ for $\overline{E_{\mathrm{TM}}}$:
- 输入是 $\langle M \rangle$。
- $R$ 需要判断是否存在一个字符串 $w$ 能被 $M$ 接受。
- 由于 $w$ 的可能性是无限的,而 $M$ 在某个 $w$ 上还可能循环,所以我们需要一个并行的策略。
- 将所有可能的输入字符串按标准顺序列出: $s_1, s_2, s_3, \dots$。
- $R$ 进行如下的交错模拟 (Dovetailing):
- 模拟 $M$ 在 $s_1$ 上运行1步。
- 模拟 $M$ 在 $s_1$ 上运行2步,同时模拟 $M$ 在 $s_2$ 上运行2步。
- 模拟 $M$ 在 $s_1, s_2, s_3$ 上各运行3步。
- ... 在第 $k$ 阶段,模拟 $M$ 在前 $k$ 个字符串 $s_1, \dots, s_k$ 上各运行 $k$ 步。
- 停机条件: 在任何阶段,只要发现任何一个模拟(比如 $M$ 在 $s_i$ 上的模拟)进入了接受状态,$R$ 就立刻停机并接受。
- 分析:
- 如果 $L(M) \neq \emptyset$,那么至少存在一个字符串 $s_i$ 和一个步数 $k$,使得 $M$ 在 $s_i$ 上运行 $k$ 步后会接受。我们的交错模拟过程保证总有一天会达到这个阶段,所以 $R$ 会停机并接受。
- 如果 $L(M) = \emptyset$,那么没有任何模拟会进入接受状态,$R$ 将永远运行下去。
- 这完全符合图灵可识别的定义。因此 $\overline{E_{\mathrm{TM}}}$ 是图灵可识别的。
- (注: $E_{\mathrm{TM}}$ 本身是不可判定的,甚至不是图灵可识别的)。
4.6 函数性质判断
- 函数 $f$:
- a. 一对一? 否。因为 $f(1)=6$ 且 $f(3)=6$,不同的输入映射到相同的输出。
- b. 满射? 否。因为输出值域是 $\{6, 7\}$,目标集 $Y$ 中的元素 8, 9, 10 没有被击中。
- c. 一一对应? 否。因为它既不是一对一也不是满射。
- 函数 $g$:
- d. 一对一? 是。每个输入 1, 2, 3, 4, 5 都映射到不同的输出 10, 9, 8, 7, 6。
- e. 满射? 是。目标集 $Y = \{6,7,8,9,10\}$ 中的每一个元素都被击中了。
- f. 一一对应? 是。因为它既是一对一又是满射。
4.7 证明所有二进制序列集 $\mathcal{B}$ 不可数
- 这是一个标准的对角化证明,与证明实数集不可数几乎完全相同。
- 反证假设: 假设 $\mathcal{B}$ 是可数的,可以列成一个列表 $b_1, b_2, b_3, \dots$。
$b_1 = 01101...$
$b_2 = 11010...$
$b_3 = 00101...$
...
- 构造一个新的序列 $b_{new}$。$b_{new}$ 的第 $i$ 位定义为与 $b_i$ 的第 $i$ 位相反 (0变1, 1变0)。
- $b_{new}$ 的第1位与 $b_1$ 的第1位(0)相反,为1。
- $b_{new}$ 的第2位与 $b_2$ 的第2位(1)相反,为0。
- $b_{new}$ 的第3位与 $b_3$ 的第3位(1)相反,为0。
- ...
- $b_{new} = 100...$
- 矛盾: 这个构造出来的 $b_{new}$ 与列表中的任何一个序列 $b_i$ 都至少在第 $i$ 位上不同。所以 $b_{new}$ 不在列表中。但这与“列表包含所有序列”的假设相矛盾。
- 结论: $\mathcal{B}$ 是不可数的。
4.8 证明 $T=\{(i, j, k) \mid i, j, k \in \mathcal{N}\}$ 可数
- 这是将证明有理数可数的对角线遍历法从二维扩展到三维。
- 思路: 我们可以将三元组 $(i, j, k)$ 按其三个分量之和 $S = i+j+k$ 进行分组。
- 和为 3 的: (1, 1, 1) - 只有1个。
- 和为 4 的: (1, 1, 2), (1, 2, 1), (2, 1, 1) - 有3个。
- 和为 5 的: ... - 有有限个。
- 因为对于任何一个和 $S$,满足 $i+j+k=S$ 的正整数三元组 $(i,j,k)$ 的数量都是有限的。
- 我们可以先列出和为3的所有三元组,再列出和为4的所有三元元组,依此类推。
- 这样就构成了一个包含所有 $T$ 中元素的不重不漏的无限列表,因此 $T$ 是可数的。
4.9 证明“大小相同”是等价关系
要证明是等价关系,需证明满足自反性、对称性和传递性。
- 自反性 (Reflexivity): 任何集合 $A$ 与其自身大小相同。
- 证明: 需要找到一个从 $A$到 $A$ 的一一对应。恒等函数 $f(a)=a$ 就是一个完美的一一对应。所以满足自反性。
- 对称性 (Symmetry): 如果 $A$ 与 $B$ 大小相同,则 $B$ 与 $A$ 大小相同。
- 证明: $A$ 与 $B$ 大小相同意味着存在一个一一对应 $f: A \to B$。因为 $f$ 是双射,所以它的反函数 $f^{-1}: B \to A$ 存在且也是一个一一对应。因此 $B$ 与 $A$ 大小相同。满足对称性。
- 传递性 (Transitivity): 如果 $A$ 与 $B$ 大小相同,且 $B$ 与 $C$ 大小相同,则 $A$ 与 $C$ 大小相同。
- 证明: 存在一一对应 $f: A \to B$ 和 $g: B \to C$。我们需要证明存在一个一一对应 $h: A \to C$。构造函数 $h(a) = g(f(a))$(即函数复合)。
- 因为 $f$ 和 $g$ 都是单射,所以它们的复合 $h$ 也是单射。
- 因为 $f$ 和 $g$ 都是满射,所以它们的复合 $h$ 也是满射。
- 因此 $h$ 是一个一一对应。所以 $A$ 与 $C$ 大小相同。满足传递性。
- 结论: 因为满足三性,所以“大小相同”是一种等价关系。
13行间公式索引
- 语言 $A_{\mathrm{TM}}$ 的定义:
- 假设的判定器 $H$ 的行为:
- 构造的“捣蛋鬼”机器 $D$ 的行为:
- 将 $D$ 应用于自身时产生的悖论:
- 语言与其特征序列的对应关系示例:
[[END_OF_RESPONSE]]所有解释内容已全部输出完毕。